
基于角色分离的中文事件抽取研究
2022-08-15 07:10张旭朱艳辉曾志高欧阳康孔令巍
山西大学学报(自然科学版) 2022年4期
张旭 ,朱艳辉,曾志高,2,欧阳康,2,孔令巍 ,2
(1.湖南工业大学 计算机学院,湖南 株洲 412007;2.湖南工业大学 智能信息感知及处理技术湖南省重点实验室,湖南 株洲 412007)
0 引言
信息抽取技术旨在快速从海量文本数据中获取有价值的信息,体现了人工智能赋能的价值;事件抽取是指从包含事件信息的非结构化文本句中自动识别出事件类型以及事件参与者的技术[1],其作为信息抽取的一项子任务,在智能问答、信息检索、舆情监控等人工智能应用中提供着重要支撑。
根 据 ACE(Automatic Content Extraction)2005[2]对事件抽取任务的定义,面向非结构化文本进行事件抽取通常被划分为两个子任务,即事件检测和事件元素抽取。事件检测目标是检测文本包含的所有事件并对其进行分类,它又可以视为触发词抽取和分类,触发词是描述事件发生的核心单词(通常为动词或名词);事件元素抽取的目标是识别出与当前事件相关联的元素实体,并将实体归类为在事件中扮演的角色。对于图1所示的事件样例,“出生”是“生活-出生”这一事件类型的触发词,“金庸”“1924年”“浙江嘉兴”这三个事件元素分别在该事件中扮演“人物”“时间”“地点”的角色。
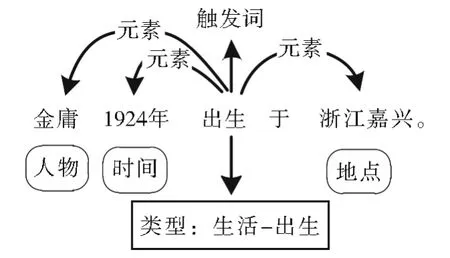
图1 事件抽取标注结果Fig.1 Annotation result of event extraction
通过对数据集的统计,发现一个普遍存在的现象,如图2所示,在 DuEE[3]数据集中,事件类型“产品行为-下架”中不同角色出现频率(蓝色条形图)有较大偏差;同时当前角色“下架产品”与其他角色同时出现的频率(橙色条形图)也存在一定差别。
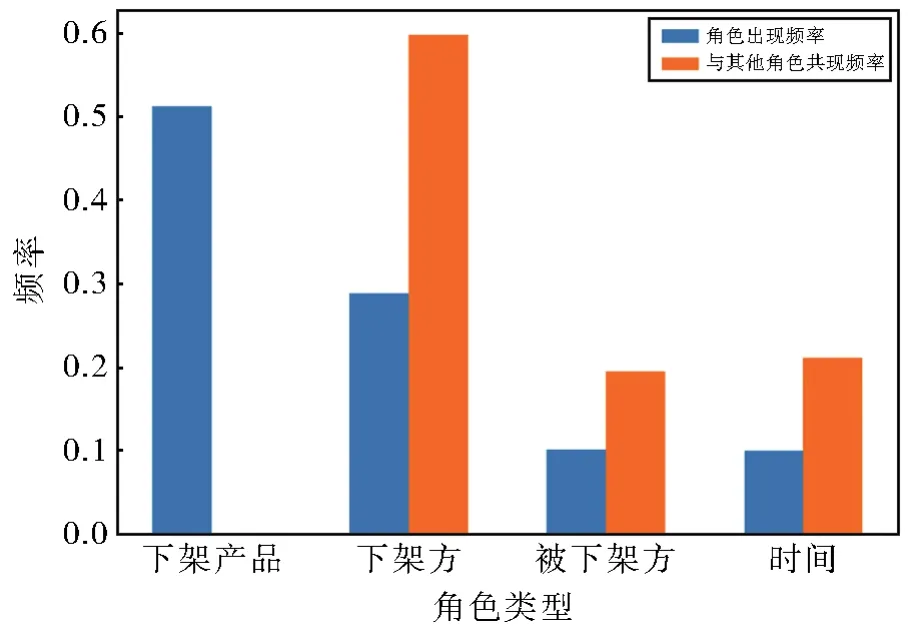
图2 元素角色统计分布Fig.2 Statistic distribution of arguments roles
针对上述现象,本文提出两种猜想:不同的角色在事件中的“辨识度”不同,出现频率高的角色更能代表该类事件;在同一类型事件中,共现频率高的角色之间关系更紧密。
此外,在对事件元素进行角色分类时,不可避免地会遇到角色重叠的问题,即同一元素实体在事件提及中扮演不同角色,例如,DuEE中“C罗神奇依旧!三球助葡萄牙淘汰瑞士晋级欧洲国家联赛决赛”这一事件,事件元素“葡萄牙”在“晋级”事件中扮演“晋级方”的角色,同时它在“胜负”事件中又扮演“胜者”的角色。据统计,ACE2005数据集中角色重叠的事件句占比8%左右;DuEE中大约有7%的事件有角色重叠问题。然而目前绝大部分研究如果成功预测出元素对应多个角色中的一个,就视为分类正确,因此难以提高元素抽取效果,同时元素识别还存在边界检测不清晰的问题。针对上述问题,本文对近些年的事件抽取任务进行了相关研究,并提出相关解决方案。
1 相关工作
自然语言处理领域关于事件抽取的研究可以追溯到20世纪70年耶鲁大学Wilensky[4]提出使用结构化的知识表示来描述上下文中固定的事件序列信息。随着MCU(Message Under⁃standing Conference)、ACE等一系列国际评测会议的开展,学术界和工业界对事件抽取的发展越来越关注,得益于此,事件抽取的技术和语料都得到一定程度的进步与丰富。
由于事件句子结构复杂,且存在多事件、触发词和元素分布离散等问题,因此事件抽取任务存在一定难度。早期研究人员[5-7]的工作思路主要聚焦于“模式匹配”“统计机器学习方法”,针对事件抽取任务,基于文本结构和语义构造了多种输入特征,但由于过分依赖于人工构造特征工程和模式化的设计,此类方法的泛化能力较差;近年来,神经网络因可以自动学习特征表示,被广泛应用于事件抽取任务,Chen等[8]使用 DMCNN(Dynamic Multi-Pooling Convolutional Neural Networks)根据候选触发词和事件元素自动化学习来表征事件信息的特征;Feng 等[9]和 Nguyen 等[10]提出使用 RNNs(Recurrent neural networks)获取更丰富的语义表示信息,拓展了用于事件抽取任务的神经网络种类;Liu等[11]引入依存句法结构来增强信息流,使用GCN来生成每个token的向量表示,最后通过自注意力机制(self-attention)实现触发词和元素联合抽取;Liu等[12]提出无触发词进行事件检测,将其建模为文本分类任务,解决了触发词标注困难的问题;Wang等[13]引入层次概念的思想进行事件元素抽取,不同事件元素共享高层次概念,描述了元素之间的相关性。
综上所述,当前事件抽取研究投入大量工作改进模型结构,取得一定成效,本文认为有监督学习下静态数据所提供的信息不可忽视,对于解决引言中所提问题有很高的参考价值,本文主要做出以下贡献:
1)首次在事件抽取领域引入命名实体识别领域基于外部词典的SOTA(state of the art)模型 Flat-lattice transformer[14],有利于模型获取语料之外的先验信息,提高触发词与事件元素的识别效果。
2)事件元素识别阶段,将事件类型、实体边界和类型作为输入显式地插入原始句子,并共享位置信息,缓解元素边界检测不清晰的问题。
3)为解决元素角色重叠,本文使用一种基于“角色分离”的分类方法,具体地,将元素识别和角色分类视为一阶段的任务,即多组角色二分类器预测每个候选事件元素实体边界及其角色;最后引入TF-IDF[15]统计方法,根据数据集提供的角色“辨识度”作为损失函数的计算权重。
4)当前,相较于英文事件抽取,面向中文的事件抽取研究进展速度较慢,其主要原因是中文文本处理难度较大(需要分词、语义和句法结构复杂)。本文在ACE2005中文数据集和DuEE数据集上进行了一系列相关实验,实验结果表明本文所提方法能在中文事件抽取上取得较好性能。
2 事件抽取模型
当前主要存在两类事件抽取模型:pipeline模型和joint模型。本文将事件抽取视为两阶段的任务,基于角色分离的事件抽取模型结构如图3所示,包括事件检测器和事件元素抽取器:(1)第一阶段的事件检测视为序列标注任务,目标抽取事件句中的所有触发词,同时对其进行分类。(2)利用触发词信息、实体类型和边界信息丰富原有特征表示,作为第二阶段事件元素抽取器的输入特征,使用自注意力机制进行信息的全局聚合,再通过片段式指针标注的方法,使用多组角色分类器检测事件元素起始位置同时预测其角色。(3)最后根据角色“辨识度”改进原有损失函数,提升元素抽取器的性能。本节按如下顺序具体介绍相关方法:Flat模型简介、触发词抽取器、元素抽取、损失函数优化方法。

图3 基于角色分离的事件抽取模型结构Fig.3 Structure of event extraction model based on role separation
2.1 Flat Model
依循ACE事件抽取步骤,触发词抽取与事件元素抽取任务均涉及命名实体识别技术,命名实体识别可以视为事件抽取的基础任务,其效果好坏将直接影响事件抽取结果。中文由于缺少自然分隔符,在命名实体识别上存在以下问题:(1)基于词的方法需依赖分词工具进行分词,难以避免触发词的错误匹配;基于字的方法虽然避免了分词,但无法利用词汇信息(2)有效的序列位置和方向信息对于NER任务很关键[16]。
Lattice结构可以有效引用词汇信息以及避免分词错误,引入词汇的好处在于可以强化实体边界、丰富序列表示[17],但Lattice结构复杂且多变,RNN结构难以建模长距离依赖关系,无法利用GPU并行计算,并且推理速度较慢。Flat模型基于 Transformer[18],通过设计位置编码融合Lattice结构,可无损引入词汇信息,有效地刻画span之间的相对位置信息,有助于Flat准确定位实体位置,同时具有优秀的并行计算能力。
将Flat模型迁移到事件抽取任务拥有以下好处:(1)Transformer结构利用 self-attention对句子中的长距离依赖进行建模,使得字符能直接与任意词汇交互,在触发词抽取阶段能充分利用候选事件元素的单词信息。(2)Flat设计了四种相对距离表示,能捕获触发词与触发词之间、触发词与元素之间、元素与元素间的位置关系。(3)引入词典信息有利于强化实体边界,缓解触发词和元素边界识别不清晰的问题。
2.2 触发词抽取
触发词抽取任务目标是从事件句中识别并抽取出触发事件的单词,本节介绍基于Flat的触发词抽取过程。
给定输入句子S={c1,c2,…,cn},其中ci代表第i个字符,经过词典[17]匹配后得到Lattice序列S*={c1,c2,…,cn,wi,j,…},其中wi,j代表由{ci,…,cj}所构成的候选元素;同时针对每个字符或词汇设计两种位置索引:开始位置Head和结束位置Tail,用于表示span首尾字符在原序列中的位置。
如图4所示,Flat-lattice结构由不同长度的区间(字符或单词)组成,为编码候选触发词与候选元素的相对位置信息;使用Head[i]和Tail[i]表示区间xi的首尾位置,对于区间xi和xj,设计四种相对位置关系表示为:
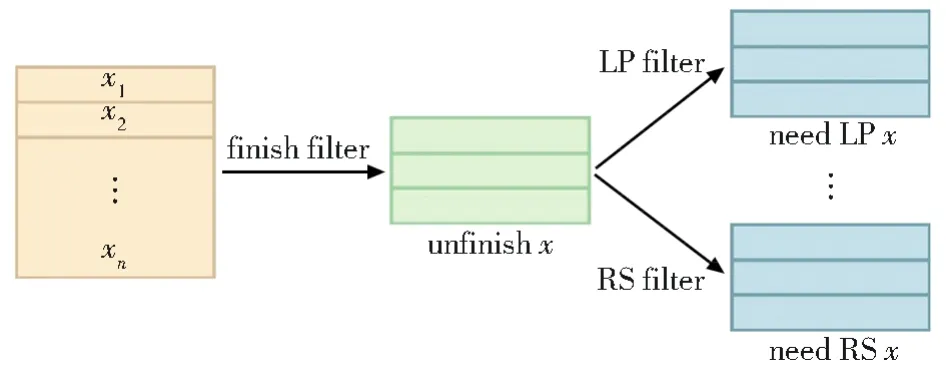
图4 Flat-Lattice有向无环图结构Fig.4 Directed acyclic graph structure of Flat-Lattice

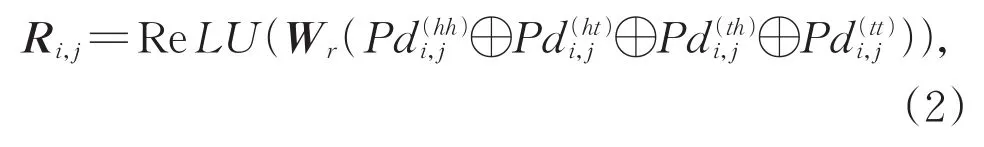
其中Wr是可学习参数,⊕表示拼接操作,Pd计算方式如式(3)和式(4):
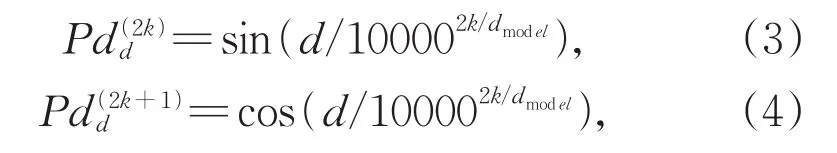
其中,k为位置向量维度的索引,dmodel表示隐藏层维度。然后使用自注意力机制的变体来利用候选触发词与候选事件元素间的位置编码:


输出解码阶段,本文仅针对原字符序列S,使用 CRF(Conditional Random Field)输出最优标签序列。
2.3 事件元素抽取
给定事件类型,事件元素抽取器的目标是抽取构成该事件的所有事件元素并对其分类;相比于触发词抽取,元素抽取更为复杂,具体地需考虑以下几点:一个句子中会有多个候选元素(句中的所有命名实体),需判断是否每个候选元素都参与了事件;元素角色重叠问题,即多事件句中同一元素在不同事件中扮演不同角色;事件中不同角色的辨识度区别;元素与触发词间的依赖,元素与元素间的依赖关系。
如图5所示,元素抽取器结构主要由三部分组成:(1)输入表示层:将触发词抽取结果、候选元素实体类型与原始输入实例拼接。(2)实例编码层:同样使用Transformer进行编码,将句子信息聚合成统一实例嵌入。(3)角色解码层:使用多组二分类器针对每个元素进行角色分类,并对预测结果和真实标签间的误差添加权重因子。

图5 元素抽取器模块结构Fig.5 Structure of argument extraction module
2.3.1 输入表示
Pipeline模型的优势在于可以无损失引入触发词抽取的结果,对于判断当前元素角色,触发词触发的事件类型信息具有重要价值[1]。如图5中Input模块所示,对于输入长度为n序列S={c1,c2,t1,t2,…,cn},其中t1,t2代表组成触发词的字符;本文将事件类型(Event-type,ET)、实体类型(Entity-type,ENT)“显式”地插入在S句尾作为模型输入[16],以缓解元素边界检测不清晰的问题。
对于实体类型标签,B-ENT、I-ENT、EENT分别对应实体类型为ENT的开始、中间、结束位置,S-ENT表示类型为ENT的单字符实体;并通过设计位置表示(position,pos)串联字符与实体类型间的联系,具体地,设定组成触发词的字符ti位置标记为0,当前字符cj的位置是其与ti的相对位置di,j,范围为[-n,n],ET与触发词ti共享位置表示,同样地,ENT与候选元素位置保持一致。
2.3.2 输入特征编码
对2.3.1中的ET、ENT输入进行编码,类似于词向量,每个值对应向量都随机初始化并通过反馈网络进行优化。
编码层同样使用Flat,其中位置编码计算方法如下:

后续计算同2.2保持一致。
2.3.3 解码输出
如图5所示,为解决角色重叠的问题,本文使用多组角色二分类器实现“角色分离”,预测每个元素实体的边界及其角色,每个角色分类器得到两组预测结果(开始、结束标签列表),用于判断当前句中字符是否为角色r的开始或结束位置。
字符xi被预测为角色r的开始概率(Start logits)和结束位置概率(End logits):
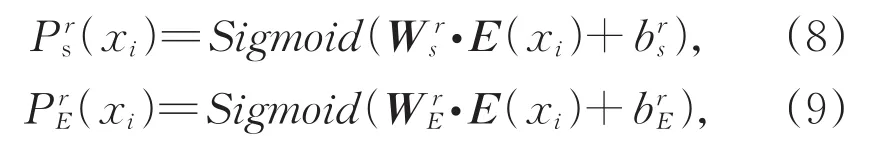
其中,下标S代表起始位置,下表E代表结束位置。为分类器的可训练权重,为偏置项。

2.3.4 损失计算
二分类模型通常使用交叉熵函数(Cross Entropy,CE)进行误差计算,对于所有角色二分类器检测元素起始与结束位置的损失分别如下:

表1展示了DuEE事件类型“产品行为-下架”最终得到的角色辨识度分值,可以观察到最能代表这类事件的角色是“下架产品”,而“时间”由于出现在绝大部分事件类型中,因此辨识度较低。

表1 角色辨识度分值Table 1 Scores of roles' recognitions
对于给定的事件类型e,偏置损失为:
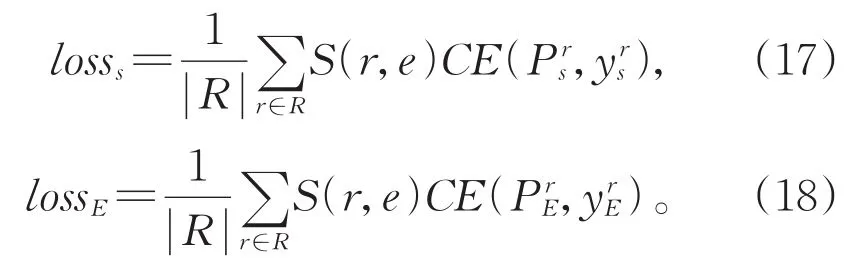
最终取二者均值作为最终损失函数。
3 实验
3.1 实验数据及评价指标
3.1.1 数据集
为了评估本文所提模型效果,在以下两个数据集进行一系列实验:ACE2005中文事件抽取数据集和DuEE数据集,其中ACE2005作为事件抽取领域使用最广泛的数据集,包含了8大类33小类事件类型的共计633篇文章,为了保证对比实验的严谨性,本文采用与基线方法[20-24]一致的语料划分方法,随机抽取534篇作为训练集、33篇作为验证集、66篇作为测试集。DuEE包含8大类65小类事件类型,将原始数据集划分为训练集(10 766个样本)、验证集(1 345个样本)、测试集(1 345个样本)。
根据实验组对数据集的统计情况显示,两个数据集都存在事件类别分布不均匀的现象。对于事件数量较少的事件,模型难以从训练集样本中学习到足够的知识表示,因此,如何挖掘有效的特征信息显得尤为重要。
3.1.2 评价指标
触发词检测:如果一个触发词在文本的位置、所属的事件类型与标注结果完全匹配,视为其预测成功。
事件元素抽取:一个事件元素被正确识别当且仅当元素在文本的位置、所属角色类型与标注结果完全匹配。
最终本文采用准确率(Precision,P)、召回率(Recall,R)以及(F1 measure,F1)值衡量事件抽取模型的性能。
3.2 实验设计
本文使用哈尔滨工业大学LTP命名实体识别工具标注DuEE事件句中预定义类别的实体,包括句中的人名、地名、机构名。由于ACE2005语料已经标注句中实体的实体类型,本文将其作为已知信息直接使用。
实验组的设计上,本文在序列建模层除了使用Flat,另外也引入了性能强大的预训练模型Bert-wwm[25]用于获取更丰富的语义特征表示。
为同基线方法字词向量维度保持一致,本文两组实验超参数设置如表2和表3所示。
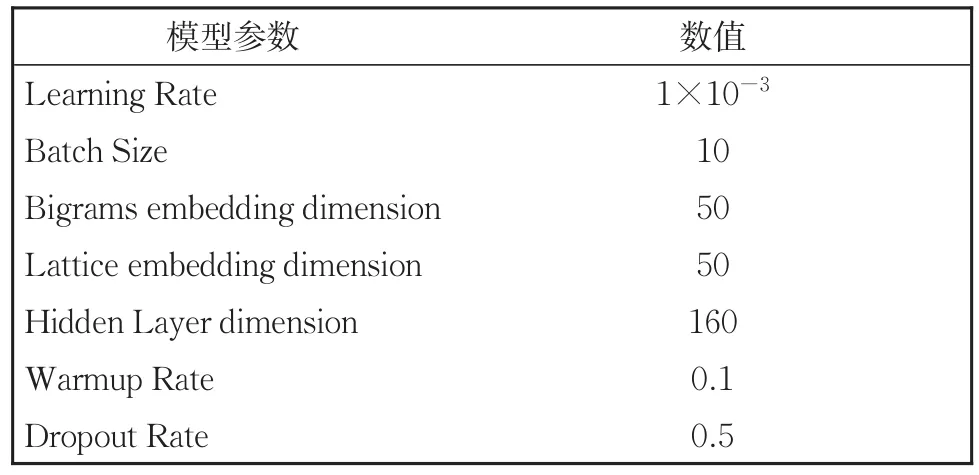
表2 基于Flat事件抽取模型实验超参数设置Table 2 Experimental hyper-parameter settings of event extraction model based on Flat

表3 基于Bert事件抽取模型实验超参数设置Table 3 Experimental hyper-parameter settings of event extraction model based on Bert
本文从如下四个方面进行实验以验证所提方法的有效性:
1)与基准模型的对比效果;
2)特征挖掘的合理性;
3)元素抽取所设损失函数的有效性;
4)角色重叠事件的识别效果。
3.3 实验结果
3.3.1 与基准模型的对比实验
本文使用Flat版本、Bert版本中文事件抽取模型,在ACE2005和DuEE两个数据集上,共进行四组实验,选择如下方法进行对比:
1)Chen’s baseline[20]:该方法利用一系列从字符层面到文章层面的特征辅助事件联合抽取。
2)NPN[21]:提出一种混合表示方法用以学习触发词内部结构组成,解决触发词不匹配的问题。
3)TLNN[22]:针对触发词检测任务,提出TLNN框架动态融合字词信息,并通过语言知识库纠正触发词多义。
4)MRC-EAE[23]:该方法利用触发词和元素角色设计多种问题模板,以阅读理解方式进行元素抽取。
5)MTL CRF[24]:采用分类训练策略为每类事件分别训练一个基于CRF的事件抽取联合模型,解决联合模型中事件元素多标签的问题;并用多任务学习方法对各事件子类进行相互增强的联合学习。
以上中文事件抽取方法涉及多方位研究,包括但不限于:输入特征表示、触发词结构、触发词歧义、联合抽取模型,因此对比实验结果可靠性更高。
由于本文暂未搜集到有关DuEE的事件抽取工作,因此仅参考官方测评基于预训练模型的Baseline。
事件抽取对比实验结果如表4和表5所示。本文模型在两个数据集上都展现出稳定的性能,其中Flat版本在ACE2005上事件元素识别和分类的F1值分别为58.2%、55.0%,高出MTL CRF 0.8%和1.9%,优于MRC-EAE元素分类F1值0.6%;Bert版本在DuEE三个任务的F1值分别高出Baseline 3.7%、4.1%、4.9%。分析主要原因如下:
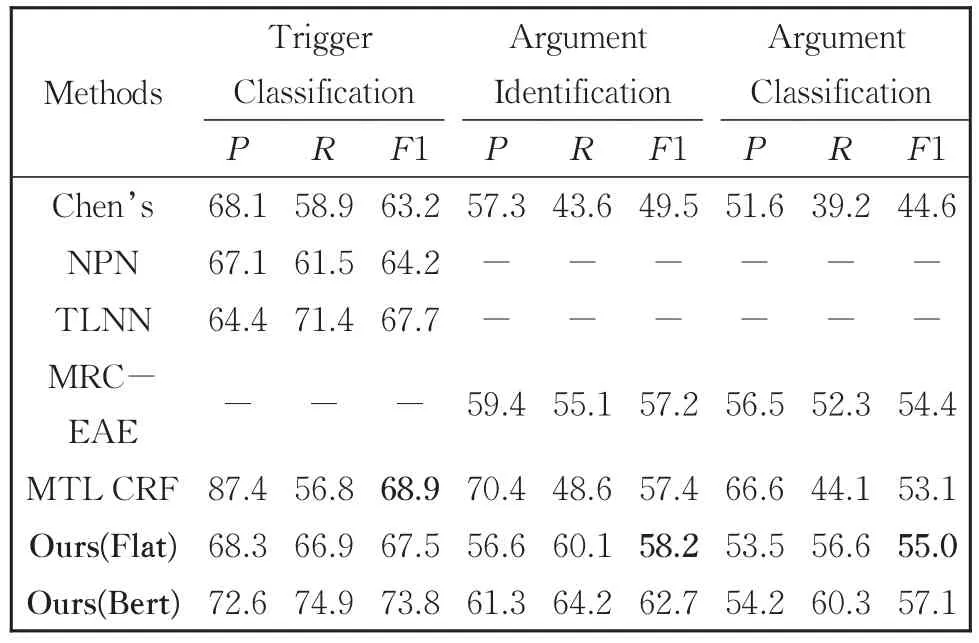
表4 ACE2005数据集的模型效果对比Table 4 Performances of various models on ACE2005 testing set

表5 DuEE数据集的模型效果对比Table 5 Comparison of model performance on DuEE
(1)触发词抽取阶段,Flat引入先验词典信息,增强了模型对触发词边界的识别能力,并通过位置编码融合候选元素信息,为触发词分类提供了有效的支撑。
(2)在元素识别阶段,将事件类型和“BIES”标签的候选元素实体类型信息融入对应字符向量表示中,能缓解元素边界检测错误的问题;多组角色分类器通过“角色分离”的方式,更加有效解决了角色重叠的问题,而NPN、TLNN存在标签冲突的问题,对于多事件的情况只能预测其中一个。
(3)预训练模型通过在大规模语料上进行长时间自监督学习训练,以获取通用的语言知识,再通过微调的方式针对性地迁移到具体的下游任务,展现了优秀的性能表现。
3.3.2 特征挖掘对元素抽取的作用
为验证Flat版本特征挖掘的合理性,本文使用多种特征组合分别检验其在两个数据集上的元素抽取性能表现,实验结果表6所示。
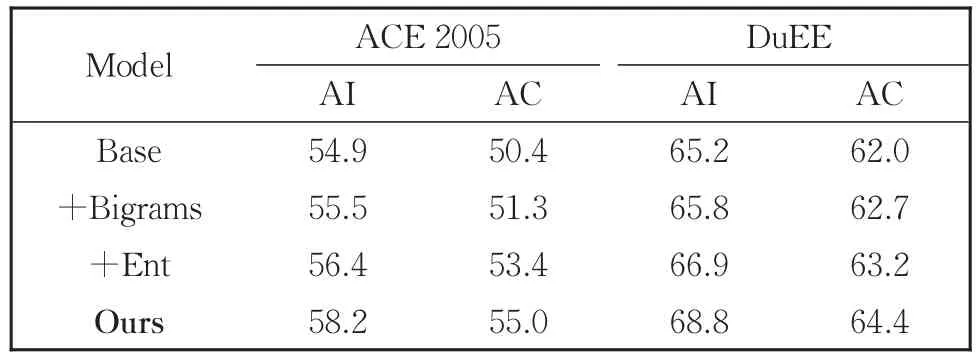
表6 基于不同特征设计(特征递增)的实验结果Table 6 Experimental performances based on different featural designs
表6中AI代表元素识别,AC代表元素角色分类,对于输入序列S={c1,c2,…,cn},各个实验组特征设计如下:
1)Base特征基于Flat Lattice结构,使用字词混合特征表示,字符ct的特征xt组成表示为:xt=[ec(ct);ew(ct)];
2)Bigrams在Base基础上为S中每个字符增加bigrams特征:xt=[el(ct);eb(ct)];
3)Ent特征同基线模型[21-22],直接将字符对应实体类型向量拼接在该字符向量表示上:xt=[el(ct);eb(ct);et(ct)],实体类型向量维度设为5;
4)Ours为2.3.1节所提方法,将事件类型和实体类型直接拼接在S上作为输入,使用位置编码共享特征信息。
分析表6实验结果可以看出,增加Bigrams特征和增加Ent特征均对元素抽取效果有不同程度提升,这表示提取有意义的特征表示对于元素抽取有积极作用;对于ACE2005实验组,Ent相比Bigrams在两个任务上的F1值分别提升0.9%、2.1%,DuEE的Ent实验组F1值相比Bigrams分别提升1.1%、0.5%,表明含有边界的实体类型信息能缓解元素边界检测错误,提升元素分类效果;本文最终方法在ACE2005两个任务上F1值相比于Ent提升了1.8%、1.6%,在DuEE上表现相比于Ent提升了1.9%、1.2%。这是由于本文方法避免引入大量非实体信息,更高效地将事件元素实体信息融合在元素字符输入表示中。
3.3.3 损失函数对比实验
损失函数是用来判定实际输出与期望输出的差异程度,为模型提供优化方向。为验证本文所提损失函数是否有效,选取常见损失函数进行对比,为保证对比实验可靠性,本小节所有实验组均使用ACE2005数据集及Bert版本事件抽取模型。
图6和图7中CE代表交叉熵损失函数,其特点是当预测输出与样本真实标签差距增大,损失函数呈类似指数级别增长。

图6 训练过程损失值变化Fig.6 Changes of loss value during training
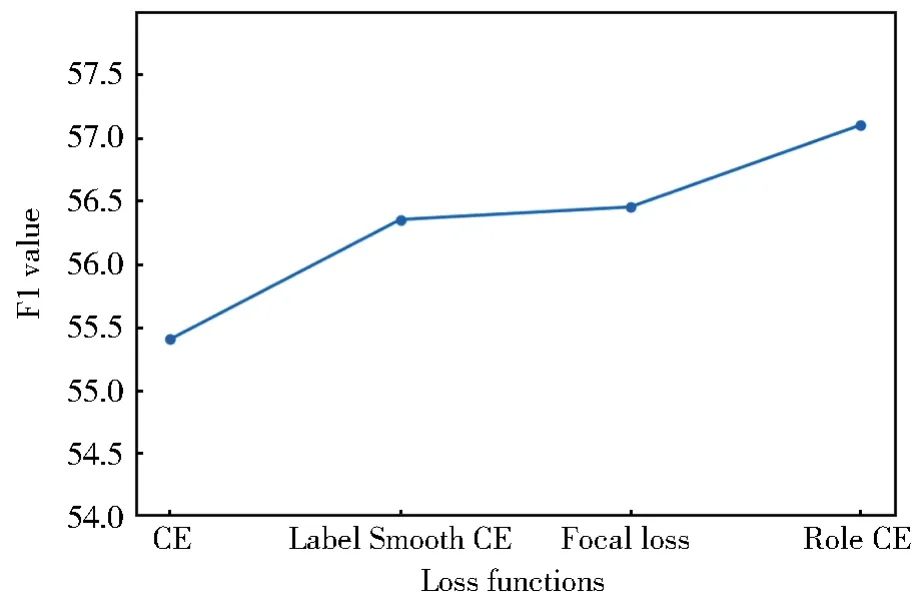
图7 角色分类F1值对比Fig.7 Comparison of F1 score on role classification
Label Smooth CE是在CE上改进,在原有标签上增加惩罚因子,改善由于标签one-hot的方式导致的网络过拟合现象。
Focal Loss[26]最早提出是用于解决目标检测中的样本类别不均衡问题,即负样本数量太大,占总loss的大部分,影响模型优化方向;该方法通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。
Role CE为本文所提损失函数,特点是从数据集的统计出发,得到不同角色的辨识度分值,为不同类别样本损失分配不同的权重。
观察图7不同损失函数在角色分类上的F1值变化可以看出,基于CE方法改进的损失函数相比于原始CE方法均有不同程度效果提升,其中Role CE表现最优。实验结果显示,Role CE相比于其他三种方法分别提升1.7%、0.8%、0.7%,验证了本文所提损失函数的有效性。
3.3.4 元素角色预测实验结果
为衡量本文模型是否有效解决角色重叠问题,对模型在两组测试集的预测结果进行统计,结果如表7所示,其中Samples代表测试集样本总数,RO(Roles Overlap)代表测试集中有角色重叠现象的句子个数,P-RO代表角色重叠的元素预测正确的句子个数。

表7 预测结果统计Table 7 Statistics of the prediction results
由表7可知,ACE2005测试集样本总数为734条,DuEE测试集样本总数为1 345条,其中,元素角色重叠的标注样本分别占比8.3%、6.6%(按照ACE2005、DuEE的顺序,后文亦如此),Flat识别含有角色重叠样本的准确率分别为:70.5%、71.9%;Bert为77.5%、80.9%。综合上述表现,本文基于“角色分离”的元素抽取方法是可行的,能有效解决角色重叠问题。
4 结论
本文面向中文事件抽取,提出一种Pipeline解决方案,先通过引入词典的序列标注方法检测触发词,再使用自注意力机制将触发词和含有边界的实体类型信息融入实例输入中,提高元素实体识别的准确性,多组角色二分类网络分别识别句中元素的起止位置,并根据静态数据统计得到的角色辨识度重新定义损失函数。实验结果表明,与已有的方法相比,本文方法有效解决了角色重叠问题,并在两个数据集上展现了良好的性能。未来的工作将发掘更为通用的角色特征及表示方法,同时考虑角色间的关联性,提高模型的泛化能力。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
电脑知识与技术(2019年29期)2019-12-16
小学生学习指导(低年级)(2019年12期)2019-12-04
电脑爱好者(2019年8期)2019-10-30
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
当代陕西(2019年5期)2019-03-21
21世纪商业评论(2018年3期)2018-03-02
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
