
数据驱动的运载火箭氧涡轮泵异常分析方法
2022-08-15 02:03:50王婧雨刘巧珍宋征宇
宇航学报 2022年7期
王 冠,王婧雨,刘巧珍,宋征宇
(1. 北京宇航系统工程研究所,北京 100076; 2. 中国运载火箭技术研究院,北京 100076)
0 引 言
氧涡轮泵作为火箭发动机的心脏,在航天领域起着至关重要的作用。因此,对于氧涡轮泵进行健康监测是一项非常必要的研究。
发动机健康监测分为启动阶段监测与稳态过程监测。利用氧涡轮泵的转速及相关的流量、压力、温度等缓变参数信号,建立设备的运行模型,用于检测启动过程设备的异常状态,对于发动机稳态过程可结合时域、频域以及时频域特征用基于神经网络或相似模型的方法进行系统的研究,在此基础上总结形成能够明显表征氧涡轮的运行异常与特性退化的精确模型。最终使用真实数据监测发动机启动状态下氧涡轮泵的异常状态。
然而氧涡轮真实数据存在数据量大,数据参数多,工况复杂,标签模糊不完整的问题,导致许多有监督的机器学习模型在真实数据上的应用受到限制。因此无监督学习逐渐被应用到工业设备的故障监测诊断以及健康监测上。而模糊聚类是将模糊数学理论与无监督学习中的聚类方法相结合的一种数据分析算法,在工业设备的故障检测诊断应用中大放光彩。文献[1]提出了一种结合模糊聚类和协同训练的轴承故障识别方法,通过对样本进行模糊聚类选择无标记样本,然后再用加权K近邻算法对多个分类器分类不一致的无标记样本重新分类并进行协同训练,有效解决了有监督模型训练时无标记样本无法被有效利用而导致其所隐藏的空间有序性信息利用度低的问题。文献[2]提出了一种基于模糊聚类的电子设备故障诊断方法针对电子装备多个传感器状态信息采用模糊聚类的方法进行融合,进而对于观测数据运用模糊聚类方法进行故障诊断,推理故障模式的方法,有效解决多传感器采集的数据异构异源,且存在错误数据,数据缺省的问题。文献[3]提出了一种基于多维退化特征和Gath-Geva模糊聚类算法的技术,经过实验证明该方法能够准确聚类轴承等机械设备的退化情况。文献[4]提出了一种利用变分模态分解(Variational mode decompo-sition, VMD)和改进模糊聚类算法相结合的机械故障诊断新方法,用于解决工业设备轴承故障振动信号具有强噪声、非线性、非平稳特性并致使故障特征信息难以提取的问题。另外相比传统的聚类方法,文献[5]指出模糊聚类利用隶属度来进行聚类,避免了非此即彼的判别方法,适于应对真实场景中工业设备故障的多样性、复杂性,以及不同类型故障响应数据存在重叠而导致的故障的不确定性难题。
另外,氧涡轮真实数据为时序数据,而LSTM网络被广泛应用于时序数据的分析和预测。由于LSTM网络能够通过门来控制信息参数的传输状态,使网络能够记住重要的信息,过滤遗忘掉相对冗余的信息,从而能够比传统循环神经网络有着更好的表现,也因此LSTM网络在时序预测领域占据着重要的地位。许多学者都尝试利用LSTM网络应用在工业设备的故障预测中去,文献[6]提出一种基于时序数据对工作面设备进行故障预测的方法,该方法将故障预测因素作为LSTM预测模型的输入、故障模式作为输出,将迟滞时间段引入LSTM预测模型,实现了迟滞性故障的超前预测。文献[7] 提出一种基于S-时间熵和LSTM的轴承早期故障预测方法,通过S-时间熵刻画轴承性能退化,再采用LSTM网络对滚动轴承早期故障阶段进行预测。文献[8]通过对历史监测数据进行训练学习,建立风电齿轮箱正常运行时的油温监测LSTM模型,通过对预测残差进行评估计算设定相应的检测阈值;然后通过模型残差分析和阈值比较实现齿轮箱故障状态的检测和预测。文献[9]在数据驱动的往复式压缩机设备故障预测应用中,通过对比BP、RNN、LSTM三种网络的预测效果,得出LSTM的预测准确率最高。
纵观国内外的火箭发动机故障检测技术研究进展,从最传统的红线阈值检测与报警的方法发展到基于数据驱动的神经网络故障检测方法。传统的红线阈值检测与报警的方法是根据历史数据确定阈值范围,该方法难以发现隐性的安全隐患,而且受历史经验影响。而基于数据驱动的神经网络故障检测方法则更加高效智能,但这方法对于数据的需求较高,不但需要大量的数据进行训练,而且对数据标签的要求也较高,准确完善的数据标签更有利于提高神经网络故障检测方法的准确率。然而真实的火箭发动机监测数据往往缺乏准确完善的数据标签,这成为火箭发动机故障检测技术研究的一大难点。
本研究提出了一种基于模糊聚类和LSTM网络的氧涡轮泵数据异常分析方法。首先通过模糊聚类对工况复杂,标签不完整的数据样本进行预分类,并将分类结果与真实标签进行比对调整,得到完整的标签并且能分析特征贡献度,为之后LSTM网络的特征筛选和训练打下基础。之后通过LSTM网络对氧涡轮泵数据进行预测,并自动计算误差阈值来判断试车异常,再进行正反测试验证异常阈值判据的可靠性,实现了氧涡轮泵数据驱动的自动故障检测预警,且相较于红线阈值检测方法准确率提升7%。
1 算 法
本研究提出一种基于模糊聚类特征分析与LSTM预测模型相结合的氧涡轮燃气路数据异常分析流程,算法具体流程如图1所示。在数据层,首先对于氧涡轮真实数据进行数据预处理,将数据进行规范化,构建统一的数据存储模式并整理缺省值和不完整标签,以便之后进行数据分析处理。在分析层,通过模糊聚类的方法对预处理后的数据样本进行预分类,并通过与已有的真实标签比对,分析不同参数在异常分析中的贡献度,同时对缺失的标签进行一个合理的完善,以支持下一步的LSTM预测训练。在特征层,根据模糊聚类分析特征贡献度的结论,对数据进行进一步的特征提取,特征提取包括时域特征提取和EEMD分解。在预测层,将数据按不同工况分别用LSTM网络进行时序预测。在判据层,将预测结果与真实数据进行比对,计算预测误差均值,并根据误差采用非超参数阈值计算来获取阈值判据,用于氧涡轮设备故障预测。最后通过正反测试,分别利用正常车次和异常车次进行训练,然后将测试的故障检测结果和真实标签对比来验证阈值判据的可靠性和可行性。
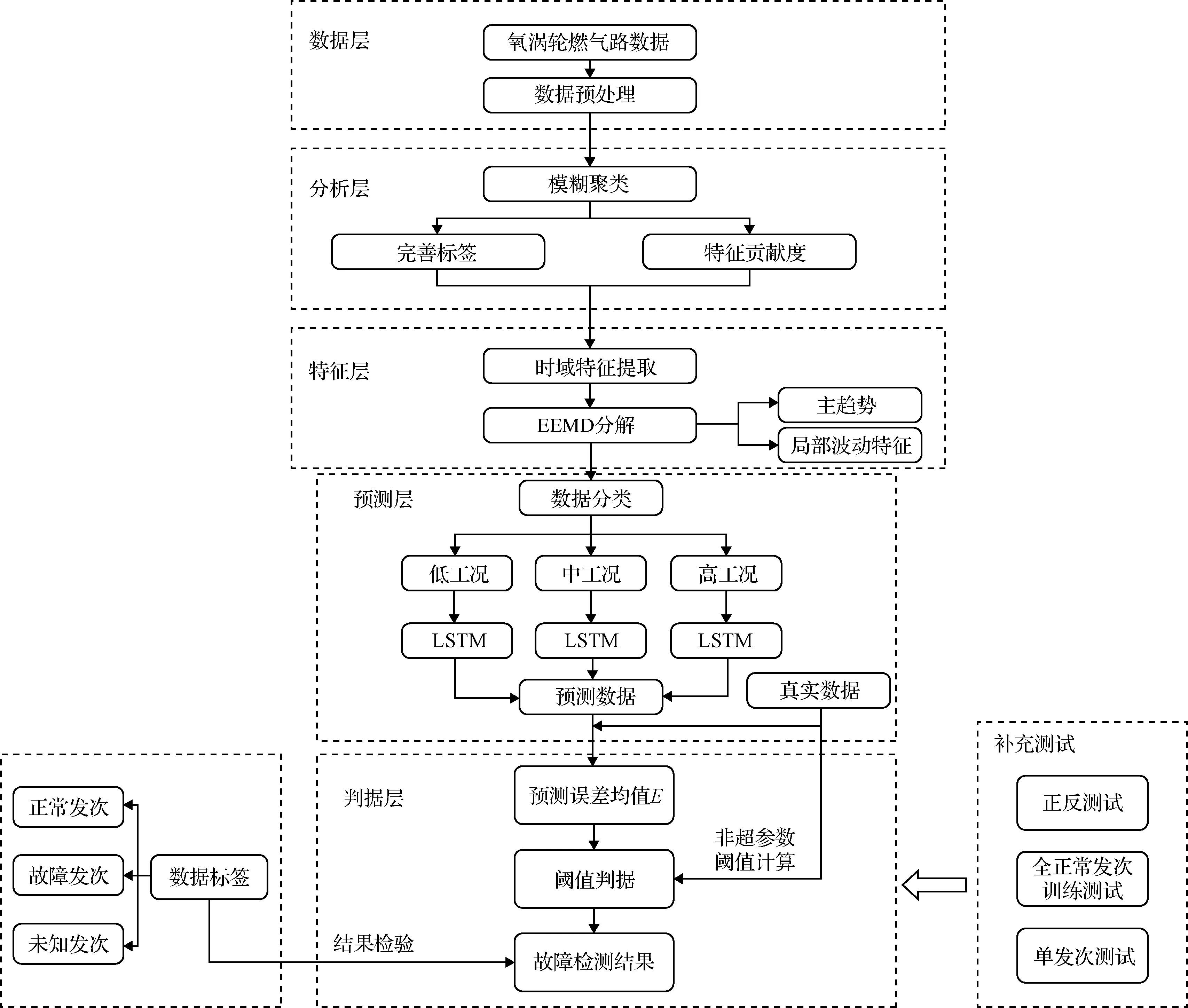
图1 氧涡轮泵数据异常判据分析流程Fig.1 Analysis flow of oxygen turbopump data anomaly criterion
1.1 数据层
数据预处理的目的主要是为了将异源异构的数据进行划分和统一,使其规范化,构建统一规范的数据库,以便于后面的数据处理。数据预处理也会影响后续数据分析的结果,预处理也是数据分析的重要步骤之一。数据预处理步骤包括启动稳态数据划分、工况划分、样本分割、参数预筛选。
1)启动稳态数据划分
由于发动机启动过程的特性涉及发动机本身几大组件及试车台液路系统和控制系统的瞬态特性,其描述十分复杂、加之启动过程的随机干扰比较严重,物理模型预测准确率偏低,和稳态过程的数据呈现出不同的时空特性,所以有必要将启动数据和稳态数据划分开,以便于对启动数据和稳态数据分别进行分析。
2)工况划分
稳态数据又可以分为高工况、中工况、低工况,不同工况的缓变参数数据会呈现不同时域特征,所以也有需要对其进行划分,分别分析。
3)样本分割
样本分割的主要目的在于扩充样本,由于氧涡轮泵真实数据存在试车次数少,试车时间长的特点。以某型号大推力液体火箭发动机第19台设备试车数据为例,一共有6次试车,而每次试车时长在500 s左右,测点采样频率为100 Hz,所以导致数据呈现样本数量少,单个样本包含数据多的特点,而样本数量少容易造成分类结果容易受偶然性干扰,而单个样本数据量大则会造成数据分析时计算资源消耗大,计算时间长的问题。因此我们采用数据滑动窗口的方法对数据进行样本分割,增加样本数量,减少单个样本的数据量。
4)参数预筛选
数据预处理中的参数预筛选与特征层的特征筛选不同,参数预筛选不考虑特征贡献度,只是为了处理缺省值造成样本选取的参数不同导致其无法进行聚类或神经网络训练。通过数据整理,我们最终选定以下四项氧涡轮燃气路缓变参数进行重点分析:燃气发生器室压(),燃气喷嘴压力(),氧涡轮入口压力(),氧涡轮出口压力()。
1.2 分析层
主要采用模糊C均值聚类(FCM)对数据进行分析。由于氧涡轮真实数据存在标签不完整的问题,这就导致有监督学习的应用受到限制。而模糊C均值聚类是一种无监督学习方法,不依赖于数据标签,而且相较于传统的聚类方法,像K-means聚类,FCM提供了更加灵活的聚类结果。FCM对每个对象和每个簇赋予一个权值,叫隶属度,用于指明对象隶属于该簇的程度。算法的目标是最小化目标函数:
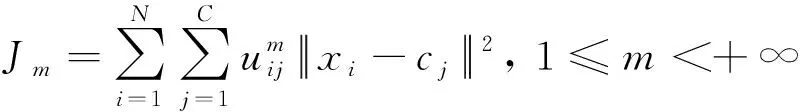
(1)

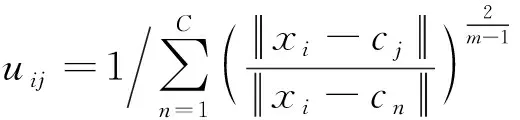
(2)
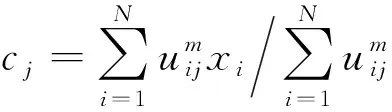
(3)
FCM算法给每个样本赋予属于每个簇的隶属度函数。通过隶属度值大小来将样本分为C类,由于要进行异常分析,所以我们分为两类,正常和异常。详细算法步骤如下:
1)初始化隶属度矩阵,初值随机生成;
3)更新隶属度矩阵:
5)输出,终止程序。
1.3 特征层
特征层主要负责特征提取,根据模糊聚类分析得出的特征贡献度结论,我们对数据进行进一步的特征筛选,挑选出与异常关联性强的特征。然后进行特征提取,特征提取包括时域特征提取和EEMD分解。
时域特征提取指的时对每一项参数时序数据进行计算得到标准差、偏度、波形因子、峰值因子、裕度因子,并将其作为时域特征。计算共识如下:
标准差:
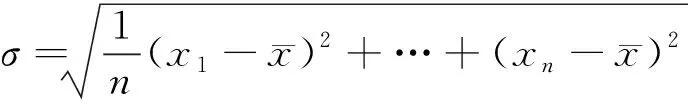
(4)
偏度:

(5)
波形因子:

(6)
峰值因子:
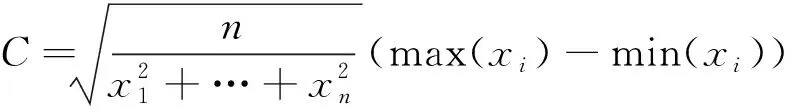
(7)
裕度因子:

(8)
在目标识别领域常使用多尺度的特征图来预测目标,其使用具有较大感受野的高层特征信息预测大的物体,具有较小感受野的低层特征信息预测小目标。借助多尺度模型的思想,在故障识别上用EEMD模态分解将数据分解为主趋势和局部波动分别进行预测,最终将预测结果进行特征融合以实现故障诊断。其思路如图2所示:
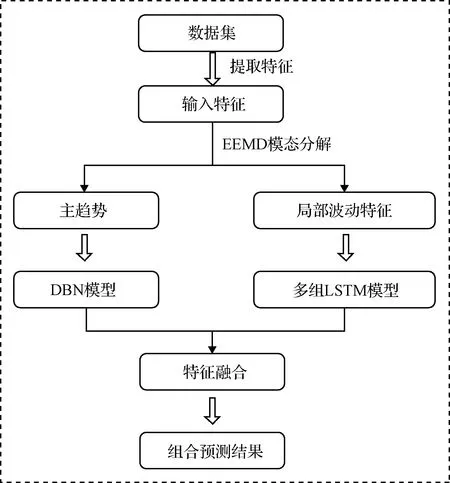
图2 基于多尺度特征的故障诊断Fig.2 Fault diagnosis based on multi-scale features
经验模态分解(EMD)是对非平稳信号进行分析的方法,它将信号分解为本征模态函数(IMF)和余量,自适应地表示信号中的局部特征和全局趋势。EEMD的原理是进行多次重复EMD分解信号的过程,在每次分解过程中都向原始信号加入零均值、固定方差的白噪声,有效地解决了模态混叠现象。
1.4 预测层
LSTM网络常用于时间序列的预测,通过比较预测序列和实际值的误差是较为流行的故障检测方法。在对复杂系统进行监测时,上百个传感器参数的期望值随环境因素和工况的变化而变化,对这些传感器参数的自动监测需要一种快速、通用和无监督的方法来确定预测值是否异常。一种常见的方法是对过去平滑误差的分布进行高斯假设。然而,当参数假设被违反时,这种方法便不再适用,因此无需对参数分布做出假设的就能有效识别异常的方法更为通用。基于距离的方法虽然无须对参数做出假设,但其通常涉及较高的计算成本。此外,这些方法往往更关注的是发生在正常值范围内的异常。在故障的检测中,异常高或异常低的平滑预测误差是值得关注的。基于LSTM网络和自适应阈值的故障检测方法为每一次预测值()计算预测误差:
()=|()-()|,
所有的误差形成一个一维向量=[-,…,-1,],其中为用于评估当前误差的历史误差值个数。然后对误差集进行平滑处理,以抑制基于LSTM的预测经常出现的误差峰值(即使这种行为是正常的,也会导致误差值的急剧峰值)。然后使用指数加权平均(EWMA)产生平滑误差。为了评估数值是否为标称值,我们为它们的平滑预测误差设置一个阈值,平滑误差高于阈值的值对应的值被分类为异常。
算法的流程如下:
1)LSTM网络学习时序数据做预测
2)收集每一步的误差构成误差向量
3)对误差做加权平均的平滑处理
4)根据平滑后的数据计算阈值
5)平滑误差高于阈值的值对应的值被分类为异常
1.5 判据层
判据层需要根据预测层的预测结果与真实数据的误差获取阈值判据。为了定性形成阈值计算方式,我们采用了非超参数的阈值计算方法,其步骤如下:
1)LSTM学习时序数据做预测,计算单个样本点点的预测误差。
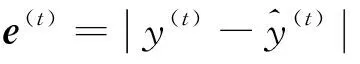
(9)
2)每次取时间长度为的值进行异常检测。
=[(-),…,(-1),()]
(10)
3)对误差做加权平均的平滑处理。通过加权平均(EWMA)对误差做平滑处理来抑制LSTM预测中常出现的误差峰值。

(11)
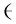
该阈值计算方式计算的阈值经测试能准确判断发次是否存在故障。阈值计算方式具体如下:
1)首先通过计算误差的均值和方差得到一系列阈值集合:
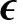
(12)
其中,()为均值,()为方差。
2)从阈值集合中挑选一个阈值:
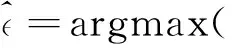
(13)
式中:为均值,为方差,
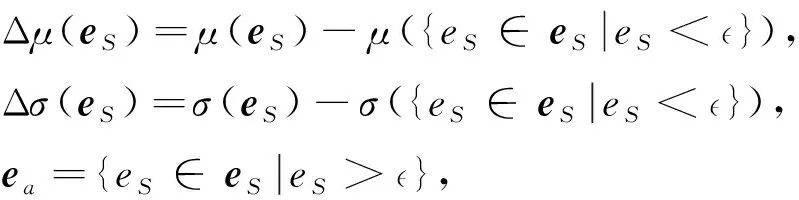
||为异常值连续序列的个数。
2 实 验
此次实验主要采用某型大推力液体火箭发动机氧涡轮缓变参数进行数据分析实验。其中某型大推力液体火箭发动机第16台设备试车2次,经下台分解检查均正常;某型大推力液体火箭发动机第19台设备试车6次,前4次试车均正常关机,试车后下台分解检验设备正常,然后在未更换重新组装后(除轴承、螺钉螺母等分解必换件外)又进行了2次试车均正常关机,再次分解后发现氧涡轮泵盘轴存在裂纹。因此可判断第6次试车异常,第5次试车无法判断;某型大推力液体火箭发动机第32台设备共试车6次,第6次试车中途发动机执行自动紧急关机,试车分解后发现氧涡轮泵盘轴存在裂纹,因此判断某型大推力液体火箭发动机第32台设备第6次试车无法判断,前五次试车无法判断。
此次试验主要采用以下四项参数来进行实验分析,燃气发生器室压(),燃气喷嘴压力(),氧涡轮入口压力(),氧涡轮出口压力()。这四项参数为氧涡轮缓变参数,采样频率为100 Hz。其中燃气发生器室压力传感器测点位于燃气发生器身部,测量精度分别为±0.7%,±2%;燃气喷嘴压力传感器测点位于主燃气喷嘴前总装导管,测量精度为±0.7%;氧涡轮入口压力传感器测点位于氧涡轮进气壳体上,测量精度分别为±0.7%,±2%;氧涡轮出口压力传感器测点位于氧涡轮排气壳体上,测量精度为±0.7%。
2.1 模糊聚类特征分析
此次实验我们在样本分割时选择滑动窗口的时长为5 s,步长为5 s。因为经过比对,窗口滑动步长对于实验分析的影响不大,而时长如果过大,会导致数据样本数量减少,而时长过短会导致样本丧失一些时空特征,从而造成聚类分析结果产生干扰。
首先我们通过工况划分将不同工况的数据进行分析,模糊聚类将样本聚类为两簇,根据每个样本在两簇中的隶属度权值按投票制将样本归为其中一簇,即样本属于隶属度高的一簇。以下是某型大推力液体火箭发动机第19台设备6次试车的氧涡轮出口压力参数不同工况的模糊聚类分析结果:

图3 某型大推力液体火箭发动机第19台设备不同工况数据模糊聚类分析结果Fig.3 Results of fuzzy clustering analysis under different working conditions of the 19th oxygen turbopump of a large-thrust liquid launch vehicle engine
其中,样本真实标签用不同图例表示,包括正常,异常和无法判断三类样本。通过模糊聚类分析结果可得中工况数据分析结果最吻合某型大推力液体火箭发动机第19台设备前四次试车正常,第5次试车无法判断,第6次试车异常的真实标签。
然后通过模糊聚类分析某型大推力液体火箭发动机第19台设备中工况不同参数数据,此次实验重点分析的参数包括燃气发生器室压(),燃气喷嘴压力(),氧涡轮入口压力(),氧涡轮出口压力()。以下是不同参数模糊聚类分析结果。
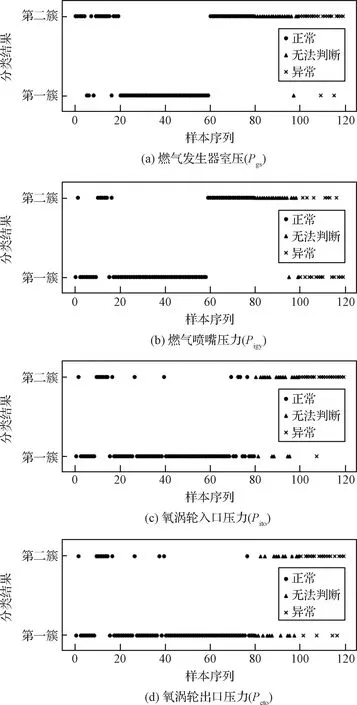
图4 某型大推力液体火箭发动机第19台设备中工况不同参数模糊聚类分析结果Fig.4 Results of fuzzy clustering analysis of different parameters in medium working conditions of the 19th oxygen turbopump of a large-thrust liquid launch vehicle engine
通过比对不同参数模糊聚类分析结果可得氧涡轮入口压力,氧涡轮出口压力两项参数的分析结果最符合某型大推力液体火箭发动机第19台设备的真实标签。
因此通过模糊聚类分析,最终得到以下两个结论:1)对于标签不明确的某型大推力液体火箭发动机第19台设备第5次试车,模糊聚类分析结果表明该次试车数据特征与第6次试车更为接近,因此可判断第5次试车为异常;2)经模糊聚类结果与真实标签比对,可判断中工况氧涡轮入口压力,氧涡轮出口压力两项参数对于异常分析的贡献度较大,为之后的LSTM故障预测提供了参数筛选方案。
2.2 LSTM预测模型检测故障
首先我们需要构建LSTM故障预测模型。在模糊聚类中已知氧涡轮入口压力(),氧涡轮出口压力()两项参数对于异常分析的贡献度较大,我们将燃气路、涡轮泵数据中5个高相关参数变量作为输入,氧涡轮出口压力参数作为输出,以此来构建LSTM网络模型。
LSTM网络结构由三个网络单元(Cell)以及一个全连接层(Dense)构成。全连接层最终的输出维度设定是1维,也即所需要的预测数据结果。训练过程优化器采用Adam,损失函数为均方误差(MSE),学习率为0.001,训练迭代次数为30个全数据集(epoches),批尺寸(batch_size)为32。
将某型大推力液体火箭发动机第19台设备前3次试车作为训练样本训练LSTM故障预测模型,后3次试车作为测试样本。以下是LSTM故障预测模型对于氧涡轮出口压力()测试样本的拟合结果:
对预测拟合结果进行预测误差的量化分析,某型大推力液体火箭发动机第19台设备6次试车的误差均值依次为0.0273、0.0385、0.0485、0.0361、0.0897、0.1004,可以看出#19-5,#19-6有最大的误差均值,且#19-5与#19-6正常发次能有较好的区分。
为了进一步验证上述结果,展开了反测试来补充实验。以上试验采用某型大推力液体火箭发动机第19台设备前3次试车作为训练样本,也就是将正常车次作为训练样本,称为正测试。之后我们采用异常车次做为训练样本进行预测,称为反测试。反测试预测将诶过误差均值见表1。

表1 第19台设备试车正反测试预测误差均值Table 1 The mean of positive and negative detection prediction errors of the No.19 oxygen turbopump test run
根据正反测试预测误差的量化分析结果,发现可以通过设定阈值的方法对异常车次进行判断。然而若进行人工设定阈值,不仅会导致人工介入影响流程自动化,还会导致主观影响最终故障预测的准确性。所以为了减少人工介入,我们采用非超参数阈值计算方法来确定阈值判据。
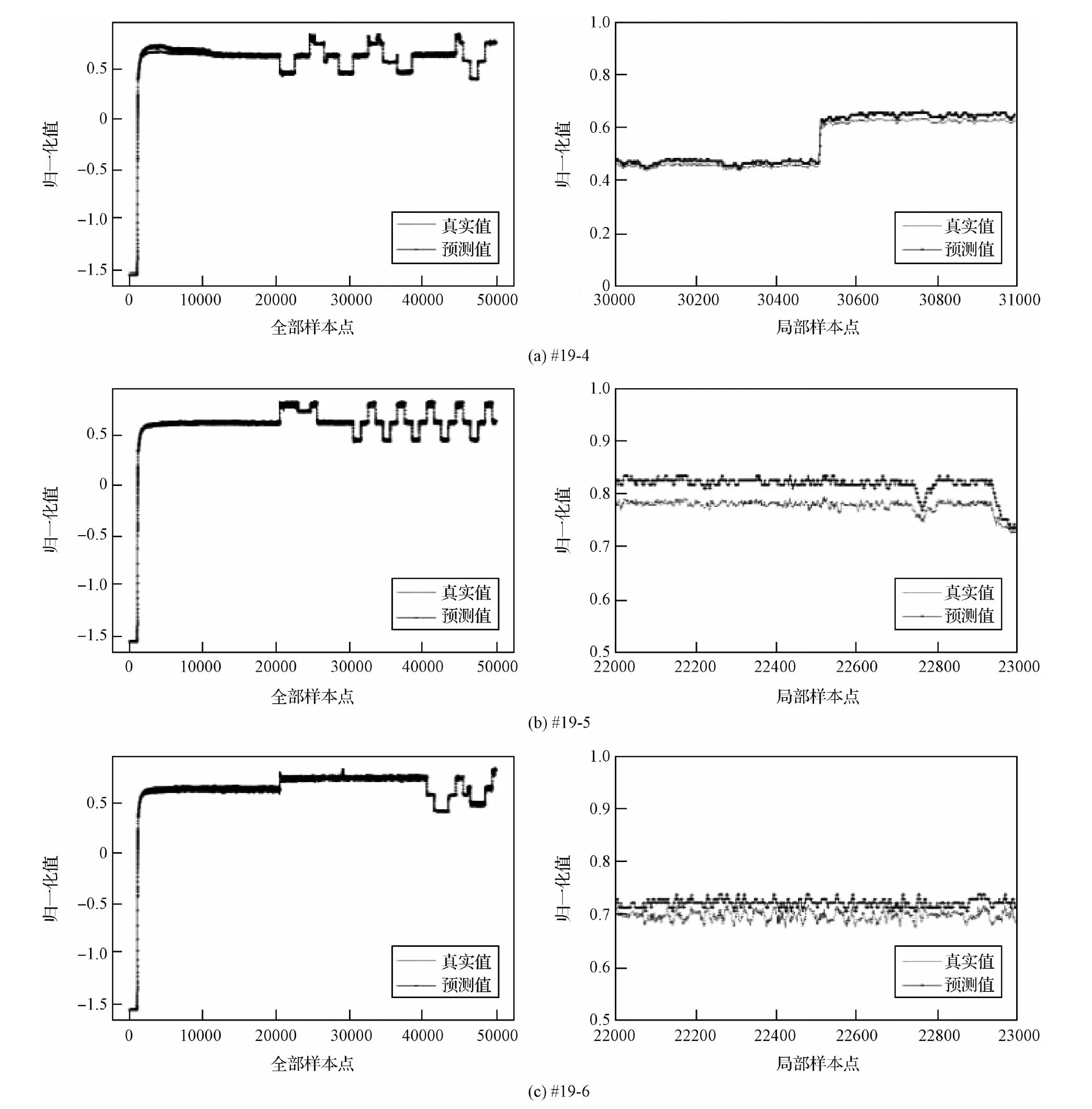
图5 LSTM故障预测模型预测Peto参数拟合结果Fig.5 Fitting results of Peto parameters predicted by LSTM fault prediction model
为了验证非超参数阈值计算方法的可靠性,我们采用#19-1试车数据来计算阈值,并对某型大推力液体火箭发动机第19台设备6次试车进行故障检测。以下是采用LSTM预测误差阈值判断异常的实验结果:
从该实验结果来看,计算的预测误差阈值能比较有效地检测异常试车。为了进一步试验在其他车次的情况下是否也能同样适用,我们对第32台设备试车也进行了同样的试验,实验结果如下:
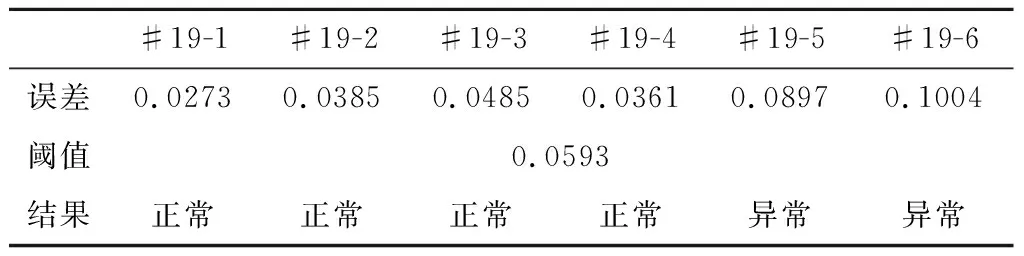
表2 以#19-1试车计算阈值检测第19台设备试车异常结果Table 2 Abnormal detection results of No.19 oxygen turbopump detected with the threshold of #19-1 test run calculation
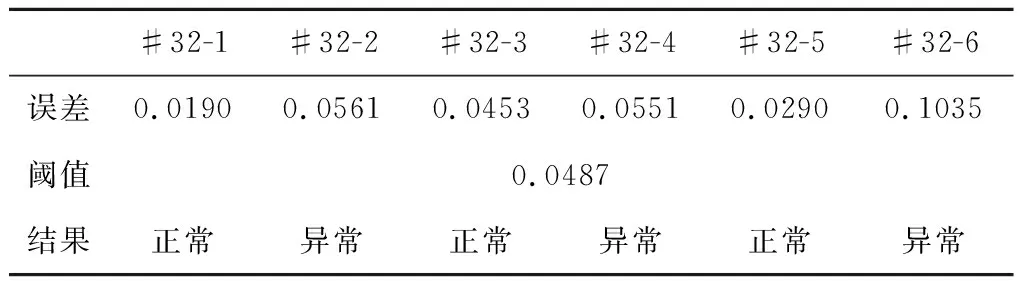
表3 以#32-1试车计算阈值检测第32台设备试车异常结果Table 3 Abnormal detection results of No.32 oxygen turbopump detected with the threshold of #32-1 test run calculation
在第32台发动机的试验中虽然存在误报的情况,但不存在漏报的情况。最后为保证在跨车次的情况下,LSTM预测误差阈值判断试车异常的可靠性,我们采用某型大推力液体火箭发动机第16台设备所有试车样本#16-2,#16-3作为正常训练样本训练LSTM模型,然后对某型大推力液体火箭发动机第19台设备和第32台设备试车样本进行测试,检测异常,试验结果表明,在跨车次的情况下,LSTM预测误差阈值判断试车异常方法依然有着很好的表现,能够正确的区分出正常车次和异常车次。
最后将模型与在实际工程应用中仍被广泛使用的红线阈值检测方法作比较,比对结果如下表所示:
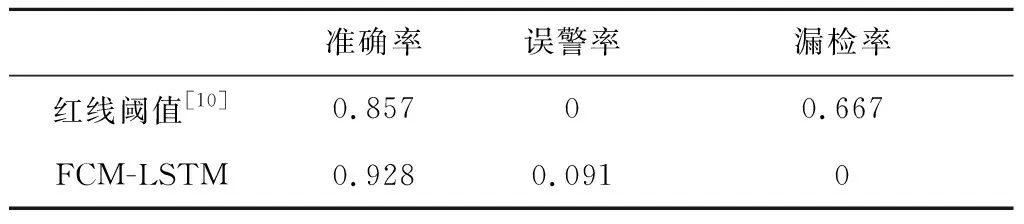
表4 红线阈值检测方法与FCM-LSTM故障检测模型实验结果比对表Table 4 Comparison between the red line threshold detection method and FCM-LSTM fault detection model experimental results
结果表明,FCM-LSTM故障检测模型相较于传统的红线阈值检测方法准确率更高,准确率提高7%,大大减少了漏检率。通过进一步分析检测结果,发现红线阈值检测方法只能发现较为严重的故障,比如第19台设备存在的隐性安全隐患较难发现。而FCM-LSTM故障检测方法能提前检测出发动机试车数据中潜在的隐患,及早预警。
综合所有LSTM预测模型检测故障试验结果,表明成功构建并训练了一个可以预测正常试车情况下氧涡轮泵参数特征的LSTM模型,可以利用预测模型模拟正常试车样本氧涡轮泵参数变化,并通过与真实试车数据参数变化进行误差均值计算,自动计算误差阈值,来判断试车是否发生异常,并报警提醒。在28车次真实液体火箭发动机试车数据中的表现相较传统关键参数红线阈值检测方法,准确率提升从85.7%提升至92.8%,且漏检率由66.7%降为0,为发动机预见性维修提供能力支撑。
3 结 论
本研究提出了一种基于模糊聚类和LSTM网络的氧涡轮泵数据异常分析方法。首先运用模糊聚类算法对工况复杂、标签不完整的数据样本进行预分类,合理推断出无标签历史数据的分类情况,并分析出氧涡轮入口压力,氧涡轮出口压力两项参数对于异常诊断的贡献度权重较高,为神经网络预测模型选定拟合参数建立基础。之后通过LSTM网络对发动机健康情况进行预测,将燃气路、涡轮泵等高相关参数变量作为输入,将氧涡轮出口压力参数作为输出,对其进行预测拟合,并自动计算误差阈值来判断试车异常,再通过正反测试和跨车次试验验证提升异常阈值判据的可靠性。在真实发动机数据中的综合表现优于传统方法,能够更早、更准确、不漏检的对异常征兆进行预警。
所以,该氧涡轮泵数据异常分析方法在液体火箭发动机实时故障诊断与健康管理的实际应用场景中能起到利用海量历史数据挖掘潜在隐患、及早发现地面试车测试中的异常情况与趋势的作用,为技术人员排查故障与预见性维修提供更为充足的时间,提前规避渐发故障与破坏性结构故障所带来的巨大损失。
综上所述,本研究实现了某型大推力液体火箭发动机氧涡轮泵数据驱动的自动故障检测报警,不仅分析出了在氧涡轮异常分析中起重要判别作用的特征参数,而且该方法在大推力液体火箭发动机氧涡轮健康监测系统中作为实时故障诊断功能模块为整体系统提供异常检测能力,为后续实现火箭启动段牵制释放和飞行在线重构提供可能。
猜你喜欢
汽车维修与保养(2019年7期)2020-01-06 03:30:34
铁路通信信号工程技术(2019年6期)2019-01-17 18:56:14
电子测试(2017年15期)2017-12-18 07:19:27
经营者·汽车商业评论(2016年12期)2017-03-08 02:31:39
太空探索(2016年9期)2016-07-12 09:59:51
智能系统学报(2015年4期)2015-12-27 09:38:39
汽车维护与修理(2015年6期)2015-02-28 12:17:26
电子设计工程(2015年6期)2015-02-27 12:04:53
发明与创新(2015年37期)2015-02-27 10:40:26
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
