
混合帝国竞争算法求解带多行程批量配送的多工厂集成调度问题
2022-08-13 08:22唐捷凯金怀平向凤红
电子学报 2022年7期
唐捷凯,胡 蓉,钱 斌,金怀平,向凤红
(1.昆明理工大学信息工程与自动化学院,云南昆明 650500;2.昆明理工大学云南省人工智能重点实验室,云南昆明 650500)
1 引言
在经济全球化趋势下,大量企业的生产模式已由传统集中式向分布式转变,并进一步构建起集生产和运输为一体的供应链[1~3].为应对分布式供应链所带来的车辆成本上升,则要提高车辆的利用率,使用相同车辆分批次多行程运输已成为必然趋势[4~6].基于上述背景,研究带多行程批量配送的多工厂集成调度问题(Multi-Factory Integrated Scheduling Problem with Multi-Trip Batch Delivery,MFISP_MTBD)具有重要的经济效益.
当前生产和运输集成调度问题的研究主要有两类.第一类为单工厂生产与运输配送集成调度问题,现有研究分别对带多行程运输[7]、批量运输[7,8]和多车型运输[9]等约束条件的此类问题进行了建模与求解.第二类为多工厂生产与运输配送集成调度问题[1,10].由文献调研可知,目前对于第二类集成调度问题的研究还十分有限,且尚未考虑实际生产中广泛存在的各工厂间生产效率差异与多行程运输等约束条件.因此,建立考虑上述约束条件的MFISP_MTBD 数学模型,并设计求解该问题的有效算法具有重要的理论价值和实践意义.
贝叶斯概率模型是一种基于贝叶斯统计推断所提出的统计概率模型[11],该概率模型继承了先验分布这一独特的统计学特征.因其良好的统计推断效果[12],近年来基于该模型的学习型智能算法[13]被广泛用于求解可重入作业车间调度问题[14]、低碳分布式流水线调度问题[15]和带时间窗的车辆调度问题[16].
帝国竞争算法(Imperialist Competitive Algorithm,ICA)是一种具有高效全局搜索能力的群智能算法,已被广泛应用于求解生产调度[17,18]、路径规划[19]等领域的问题.然而,ICA 的同化机制在一定程度上导致其存在过早收敛的问题[20],针对该问题现有算法的主要改进可以分为两类.第一类为引入接受差解的机制,在一定程度上缓解ICA 的过早收敛[20,21].第二类为引入概率模型对ICA 同化机制进行优化[22],使之成为学习型智能算法.然而,现有学习型ICA 所采用的二维概率模型仅能学习编码间的相邻关系信息,却无法学习编码所在的位置信息.因此,将贝叶斯概率模型与ICA 相结合将更加有利于引导帝国对解空间进行更加高效且深入的探索.
本文研究了MFISP_MTBD 的建模与求解.针对实际供应链体系中各工厂间生产效率差异与多行程运输等约束条件,建立以最小化加工与运输总成本为目标的MFISP_MTBD 模型.根据MFISP_MTBD 特性提出基于多行程标签机制的两阶段编解码策略,同时设计新型启发式规则以提升初始种群的质量.设计基于贝叶斯统计推断的混合帝国竞争算法(Hybrid Bayesian statistical inference-based Imperialist Competitive Algorithm,HBICA)对其进行求解.该算法一方面引入基于贝叶斯概率模型的学习型同化机制,实现优质解的高效学习与算法全局的高效引导;另一方面设计“殖民掠夺”变邻域局部搜索机制进行有侧重的深入搜索.通过仿真实验和算法对比验证了HBICA 求解MFISP_MTBD 的有效性.
2 MFISP_MTBD的问题描述
2.1 符号定义
MFISP_MTBD 涉及的有关数学符号定义如表1所示.
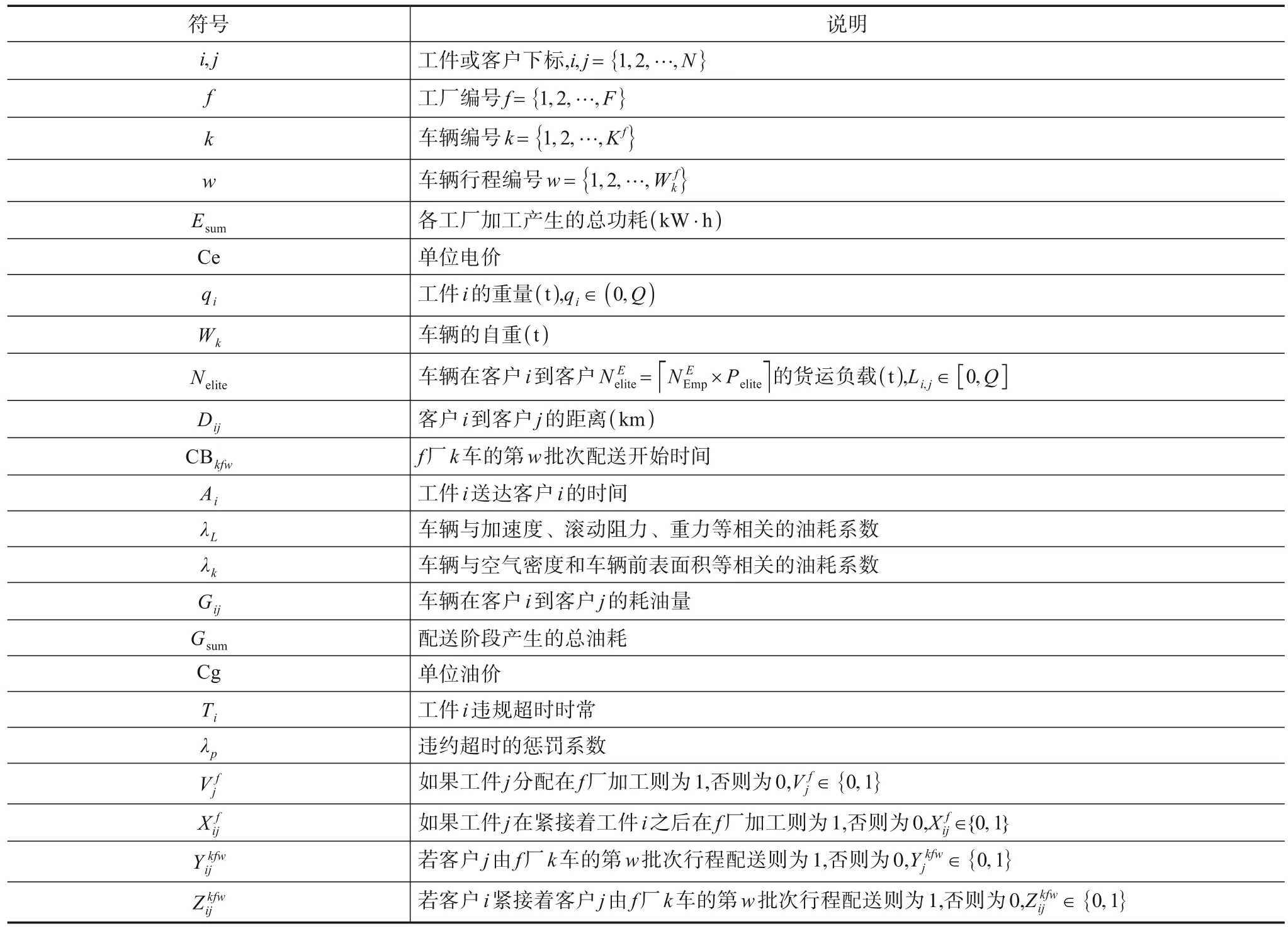
表1 符号表
2.2 问题模型
MFISP_MTBD可描述为:将N个客户的工件订单分配至F个分布在不同地理位置且具备加工能力的工厂分别按照πf的顺序进行加工,工件加工完成后通过各工厂的车队按照的顺序分批配送给客户.该模型主要分为生产阶段和配送阶段.在生产阶段,各工厂加工具有相同的单位能耗Ep(kW·h),但各工厂对同一工件存在差异化的加工时间Pif.所有工件均可安排在任意工厂进行加工,工件被分配至某一工厂后便不能再次分配至其他工厂,各工厂在同一时间只能加工一个工件.不同工件之间相互独立且在加工时不允许发生抢占.在配送阶段,各工厂的车队拥有足够数量具有相同速度V和载重约束Q的同质车辆,启用新车辆的固定成本为FC.已启用的车辆在配送计划批次中工件都完工后从工厂出发将工件送达客户并返回,当车辆返回工厂后经过时长为tm的维护后,在CRkfw时刻即可开始新的行程.各工厂依据工件的完工时间Ci、截止交货期di等约束,灵活规划车辆数量和每辆车各批次运输路线将工件配送给客户.MFISP_MTBD示意图如图1所示.
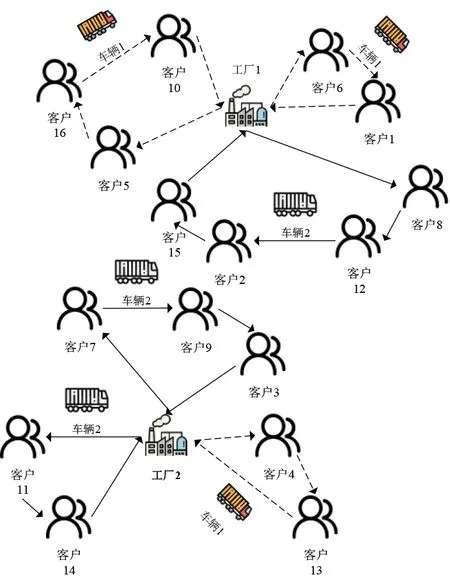
图1 MFISP_MTBD示意图



MFISP_MTBD 的优化目标为在集成调度问题中找到最优排序π*,使得总成本ΤC最小.

其中,式(1)保证每一个工件都被分配到一个工厂.式(2)和式(3)保证每一个工件都有一个前置和后续工件在工厂中被加工.式(4)和式(5)计算各工件在生产阶段的完工时间.式(6)计算所有工厂在生产阶段产生能耗的总和.式(7)保证每一个工件都被分配到所在工厂的一个配送行程.式(8)和式(9)保证每一个客户都有一个前置和后续客户在配送行程中被服务.式(10)保证配送行程均满足车辆载重约束.式(11)~(15)计算配送行程的往返时间及各工件送达客户的时间.式(16)和式(17)计算各车在配送行程中各路段的货运负载.式(18)计算各车在配送行程中各路段产生的油耗[8].式(19)计算所有车在配送行程中产生的总油耗.式(20)计算各工件总违规超时时长.式(21)计算由工厂能耗费用、车辆油耗费用、车辆固定成本以及违规超时惩罚所组成的总成本.
3 HBICA求解MFISP_MTBD
MFISP_MTBD 的本质是一个复杂的组合优化问题,高效求解此类问题的关键在于如何针对问题特性设计合理的编解码策略和改进算法设计.
HBICA 中,国家π就是原问题的一个解;定义为HBICA 第G代的国家种群,其中Nna为NPop 的规模,PImp为初始化中 殖民国家在Nna的占比,NImp为NPop 中殖民国家的规模,NCol为NPop 中殖民地的规模;定义EmpPopE(G)为第G代第E帝国的国家种群,EmpPopE(G)=为该帝国所包含的国家数量为该帝国的殖民国家为该帝国殖民地.
3.1 编码与解码
3.1.1 国家编码与解码
在编码过程中,每个国家编码π首先按工厂编号递增的顺序依次将各厂的工件加工顺序录入,然后在工厂工序间插入取值为(N,N+F)的(F-1)个工厂分隔符.以规模为N=8,F=3 的问题为例,编码9 与10 为工厂分隔符,其编码如图2所示.

图2 编码示意图
在解码过程中,针对优化目标为最小化ΤC 的MFISP_MTBD 设计了一种融合了多行程标签[4]的新型解码策略.该解码策略分为2 个阶段,首先在π中通过识别工厂分隔符依次读取各工厂工件的加工顺序;然后以各工件完工时间作为释放时间,按照先完工先运输(First Completed First Transported,FCFT)的规则,以最大化利用车辆为目标对车辆路径进行规划.具体步骤如下所示:
步骤1:若当前解码位置α=0,则将当前工厂编号设置为f=1,分配到工厂的工件数Nf=0,令α=α+1;转至步骤2.
步骤2:若π(α)≤N,则将π(α)置于πk中的第Nf+1位,令α=α+1,Nf=Nf+1;若π(α)>N,则令当前工厂编号f=f+1,令Nf=0,α=α+1.转至步骤3.
步骤3:若α≤(N+F-1),按照式(1)~(5)计算得到πf(Nf)的完工时间,转至步骤2;若α>(N+F-1),令F=f,f=1,工厂启用车辆数为k=0,转至步骤4.

步骤7:若Nf>δf+1,则转至步骤5;否则,转至步骤8.
步骤8:若f+1 ≤F,令f=f+1,k=0,转至步骤4;否则,输出加工序列和运输序列.
3.1.2 资源编码与解码
针对本文提出的“殖民掠夺”变邻域搜索,HBICA将与各国家π相对应的局部搜索具象为资源个体Λ.每个Λ 均由9 种不同的邻域搜索操作LSs排列而成,其邻域搜索操作次数为η,且同一Λ 中允许出现相同的LSs.解码Λ 时,对π从左到右依次执行Λ 中的邻域搜索操作.每执行完一次邻域搜索操作,就将得到的新解与旧解进行对比,若新解优于旧解,则用新解替换旧解,否则,舍弃新解.以η=5 的资源个体Λ 为例,其示意图如图3所示.

图3 资源个体示意图
3.2 初始化帝国
3.2.1 初始化国家
本文针对MFISP_MTBD 这类问题的性质[1],设计启发式规则产生高质量初始解,其步骤如下:
步骤1:随机生成包含全部工件的工件序.
步骤2:从左到右依次取出工件,按式(6)~(21)计算其插入各工厂加工序的最后所带来的ΤC增量.
步骤3:将当前工件安排在ΤC 增量最小的工厂进行加工.若尚有工件未分配工厂,则转至步骤2,否则,输出由启发式规则生成的新国家.
同时为兼顾初始种群的质量和分散性,根据启发式规则使用概率PH来随机选择启发式规则生成与随机生成两种方式对NPop(1)进行初始化.然后,随机生成Nna个资源个体并与NPop(1)各国家建立一一对应的关系.
3.2.2 构建帝国
构建帝国首先需要计算所有初始国家的ΤC,将NPop(1)中ΤC 较小的NImp个国家作为殖民国家存入各帝国种群EmpPopE(1)中的同时将对应的资源个体存入帝国资源域ERPopE(1)中的
然后将殖民国家力量进行归一化,并以此划分殖民地,其具体计算如式(23)~(25)所示:

其中,式(23)为初始殖民国家数量(即初始帝国数量)的计算式,PImp为初始殖民国家占比;式(24)为殖民国家的实力PΤC的计算式;式(25)为获取殖民地的概率PE的计算公式,且
最后,依据PE以轮盘赌的方式依次将NCol个殖民地及其资源个体分别划分至EmpPopE(1)与ERPopE(1)从而完成初始帝国的构建.
3.3 同化
HBICA 的同化阶段是通过在各帝国使用贝叶斯网络学习精英国家的结构信息,分别构建NImp个贝叶斯概率模型,继而通过采样各帝国所属贝叶斯概率模型更新全部殖民地以实现同化.其中,精英国家为各帝国中按ΤC 递增排序的前Nelite个国家,其中Nelite的计算如下:
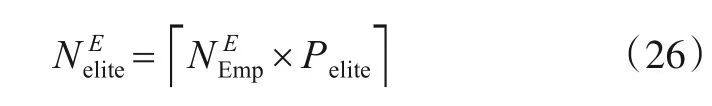
式(26)为每个帝国中精英国家的数量计算式,其中Pelite为精英国家占比.
3.3.1 构建贝叶斯概率模型


图4 精英国家贝叶斯网络图
显然,上述贝叶斯概率模型存在如下问题:(1)在后续采样过程易产生非法解,例如N1,3→N2,2→N3,1→N4,3;(2)部分定向弧概率为0,则意味着在更新殖民地时将永远无法得到此序列,这将不利于算法跳出局部最优解;(3)部分定向弧概率为1,则新殖民地在此节点的序列均相同,这将导致算法过早收敛.
针对上述问题,本文对初始化贝叶斯网络进行了以下改进:(1)赋予所有可行的定向弧权重该操作在避免产生非法解的同时提升了国家的多样性;(2)引入最低国家数量标准γ,其中γ=则挑选当前帝国中精英国家构造贝叶斯网络;否则,以殖民国家为原型随机使用LSs生成个虚拟国家扩充至帝国,再挑选其中的精英国家构造贝叶斯网络,该操作有助于提升小规模帝国搜索的有效性.
3.3.2 采样
为了提高采样的执行效率,本文结合贝叶斯概率模型的特点,提出了一种融合了禁忌表的轮盘赌采样方式,其采样步骤如下:
步骤1:建立与编码长度相同的禁忌表Τabu=[Φ1,Φ2,…,ΦN+F-1],令∀Φ=Τrue.使用轮盘赌的方法选择第一个节点N1,i,将N1,i存入新国家编码第1 位,令Φi=False,国家编码位置x=2.
步骤2:将满足Φj=Τrue 的Nx-1,i到Nx,j定向弧权重归一化计算P(Nx,j|Nx-1,i),继而使用轮盘赌选择下一节点Nx,j.
步骤3:将Nx,j存入新国家编码第x位,令Φj=False,i=j,x=x+1.若x<N+F,则跳转至步骤2;否则,输出国家编码替换旧殖民地.
3.4 革命
殖民地革命作为一种对殖民地国家编码的操作方式,其无序扰动策略使某些国家在解空间中的位置产生突变,增加了算法的搜索范围并预防整个搜索进程过早进入局部最优[3].
具体来说,首先对所有殖民地以PR的革命发生概率随机判断是否革命;然后对发生革命的殖民地随机选择邻域搜索操作LSs进行扰动,若扰动后殖民地ΤC发生改善,则更新殖民地;最终,在各帝国中选出该帝国当前最优国家成为新的殖民国家,从而实现对各帝国的革命.
3.5 殖民掠夺
将局部搜索作为优化工具融入ICA,将有利于提升国家的适应度,进而促进算法性能的加强[16].然而,使用局部搜索势必造成算法计算复杂度的提升,占用较多计算资源,进而降低算法迭代效率.因此,设计合理的局部搜索的分配规则将有助于提升局部搜索策略使用效率的提升.故本文提出了“殖民掠夺”变邻域局部搜索机制,该机制利用9种针对MFISP_MTBD 设计的邻域搜索操作动态构建局部搜索,并通过资源竞争与掠夺来对局部搜索进行分配,从而实现了局部搜索合理高效的运用.
3.5.1 邻域搜索操作
本文设计9种不同的邻域搜索操作,如下所示:
(1)LS1:国家编码序列交叉操作,从国家编码序列中随机选择2位进行交换.
(2)LS2:国家编码序列前向插入操作,从国家编码序列中依次随机选择2位,将先选中的编码插到后选中的编码之前.
(3)LS3:国家编码序列逆序操作,从国家编码序列中随机选择2 位,将包含所选2 位及其之间的编码颠倒排列顺序.
(4)LS4:国家编码序列相邻交换操作,从国家编码序列中随机选择一位,以相同的概率随机选择其与其向前或向后相邻的编码进行交换.
(5)LS5:工厂加工序列交叉操作,随机选择一个Kf≥2的工厂,再从该工厂加工序中随机选择2位进行交换.
(6)LS6:工厂加工序列前向插入操作,随机选择一个Kf≥2的工厂,再从该工厂加工序中随机选择2位,将先选中的工件插到后选中的工件之前.
(7)LS7:工厂加工序列逆序操作,随机选择一个Kf≥2的工厂,再从该工厂加工序中随机选择2位,将包含所选2位及其之间的工件颠倒排列顺序.
(8)LS8:车辆行程服务序列交叉操作,随机选择2个车辆行程服务序列,将2个车辆行程所包含的工件全部交换.
(9)LS9:车辆行程服务序列逆序操作,随机选择一个车辆行程服务序列,将该车辆行程服务序列的工件颠倒排列顺序.
在此基础上进一步将邻域搜索操作组合成不同的局部搜索并作为HBICA 的资源个体Λ 提供给国家使用,将有利于Λ 对国家在多种邻域结构下持续的优化,从而实现对解空间深入有效的搜索.
3.5.2 资源竞争与掠夺
HBICA 将帝国内部的国家按编号依次连接,通过在各帝国内部展开资源竞争与掠夺实现细致而有侧重的局部搜索.其具体步骤如下所示:
步骤1:令帝国编号E=1,国家编号i=1.
步骤2:当i=1时,令
步骤6:在E帝国内进行殖民关系转换操作,依次使用弱势国家的Λ对进行优化.
3.6 帝国竞争与删除
帝国竞争的本质是各帝国按照帝国实力EΤCE对殖民地的争夺.帝国实力由殖民国家实力与殖民地实力2部分所组成,其具体计算如下:

在帝国竞争过程中,首先确定最弱小的帝国,并从中割让一块殖民地.然后其余帝国依据帝国实力以轮盘赌的方式决定殖民地的新归属,其具体计算如下:

其中,EΤPE为E帝国获取殖民地的概率.
由于HBICA 在同化中使用贝叶斯概率模型学习精英国家结构信息.因此,若割让的殖民地满足成为新帝国精英国家的条件,则最弱小帝国的部分优质结构信息也将被新帝国所接纳.故HBICA 选择而不是传统的作为被割让的殖民地,进而保证被割让殖民地信息有更高的概率被新帝国贝叶斯概率模型学习,从而实现帝国间的优质信息交互.
在完成帝国竞争后,HBICA进入帝国删除阶段.即检查此时最弱小帝国所拥有的殖民地数量,若该帝国丧失全部的殖民地,则该帝国的殖民国家将沦为殖民地并划归其他帝国,至此该帝国灭亡.
3.7 帝国重构
针对HBICA 帝国兼并速度加快的特点,设计了“帝国重构”扰动机制.即算法在未满足终止条件前,若所有国家兼并为单一帝国,则在保留国家种群中具有最优秀ΤC 值的NImp个编码不同的国家作为新的殖民国家,并重新划分由初始化国家操作重新生成的殖民地以实现帝国的重新构建.
该扰动机制有助于提升算法后期对多个优质解区域同时搜索的能力,减缓过早收敛,从而实现HBICA 的整体性能.
3.8 算法流程
据算法描述,HBICA算法流程如图5所示.
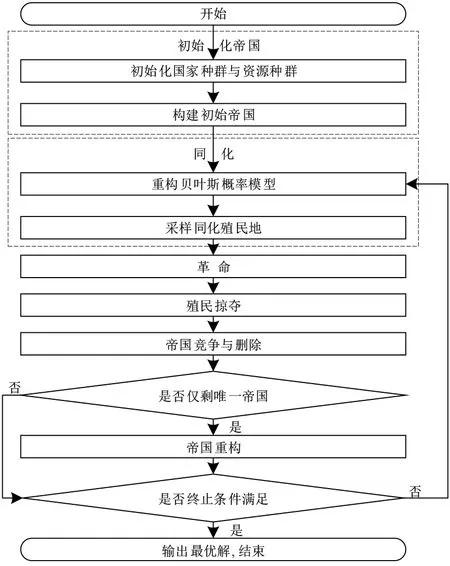
图5 HBICA流程图
4 实验分析与比较
由于目前尚无适合MFISP_MTBD 的标准算例,本文所有的测试算例均在Gharaei 等[1]为解决MFISP_BD所提供的数据分布区间上随机生成共计27 个按照N×F组合的测试算例.所有算法和实验均由Delphi 2010编程实现,操作系统为Windows 10,CPU为2.90 GHz,内存为16 GB.
4.1 参数设置
在HBICA 中,启发式规则使用概率PH、初始殖民国家占比PImp、精英国家占比Pelite和资源个体的邻域搜索次数η为关键参数.本文对中等规模问题(90×6)采用实验设计(Design Of Experiment,DOE)[24]行实验分析,得出HBICA 的最佳参数组合为PH=0.4,PImp=0.020,Pelite=0.3,η=6.
4.2 仿真结果比较与分析
本节将每种算法放在各测试问题上以相同时间((N×F×100)ms)下独立运行21次.其中,AVG为算法独立运行21次输出最优结果的平均值,Average为所有规模问题通过相关算法获得的每个性能指标输出结果的平均值,NB 为所有规模问题通过相关算法获得的每个性能指标最优值的总数,在各指标下的占优值用粗体进行标识.
4.2.1 验证算法改进的有效性
为验证HBICA 中“贝叶斯概率模型同化机制”与“殖民掠夺”自适应变邻域局部搜索机制2 种关键改进的有效性,本节将HBICA 与ICA 及其变形算法进行比较,其结果如表2 所示.其中,ED_ICA 为采用二维概率模型同化机制的ICA,B_ICA 为采用贝叶斯概率模型同化机制的ICA.

表2 ICA、ED_ICA、B_ICA与HBICA的有效性对比结果
由表2 可知,B_ICA 解的质量相较于ED_ICA 与ICA 有明显的提升,验证了贝叶斯概率模型同化机制的有效性.HBICA 解的质量相较于B_ICA 有显著的提升,验证了“殖民掠夺”变邻域局部搜索机制的有效性.
4.2.2 HBICA与其他算法的比较
为验证HBICA 的有效性,将HBICA 与近年来求解相关问题的有效算法(IWOA[10]、HGA[4]和TS[8])进行对比,各算法比较结果如表3所示.
由表3可知,HBICA在大部分问题上的测试结果都明显优于对比算法,表明HBICA 是求解MFISP_MTBD的有效算法.HBICA 一方面利用贝叶斯概率模型同化机制实现对优质解信息的高效学习与殖民地的再建构,有利于快速发现问题解空间中优质区域;另一方面利用“殖民掠夺”引导局部搜索对优质解区域进行集中优化,有利于算法对优质解区域进行较深入的搜索,从而能高效地发现复杂问题的优质解.因此,HBICA能在上述实验中取得较好结果.

表3 HBICA与3种有效算法的对比结果
5 结论
为综合考虑存在于多工厂供应链的实际运输中常见的车辆重复使用情况,本文提出了一种基于贝叶斯统计推断的混合帝国竞争算法,求解以最小化总成本为目标的MFISP_MTBD.首先,设计了基于多行程标签机制的新型编解码策略,并构造新型启发式规则以提高初始解的质量.然后,采用贝叶斯概率模型学习机制替换标准帝国竞争算法中的同化机制,将各种群向优质解区域进行快速引导.其次,采用“殖民掠夺”变邻域局部搜索机制,实现对优质区域细致而有侧重的搜索.最后,通过在不同测试问题上的仿真实验与算法比较,验证了HBICA是求解MFISP_MTBD的有效算法.
猜你喜欢
农业工程学报(2022年7期)2022-07-09
历史教学问题(2021年4期)2021-11-05
逻辑学研究(2021年3期)2021-09-29
中学生数理化·高一版(2021年3期)2021-06-09
英美文学研究论丛(2021年2期)2021-02-16
辽宁省博物馆馆刊(2020年0期)2020-08-13
计算机应用与软件(2018年12期)2018-12-13
中学生数理化·中考版(2015年10期)2015-09-10
黑龙江史志(2014年9期)2014-11-25
数学教学通讯·初中版(2014年2期)2014-03-21
