
RTL级可扩展高性能数据压缩方法实现
2022-08-13 08:22陈晓杰周清雷
电子学报 2022年7期
陈晓杰,李 斌,周清雷
(1.数学工程与先进计算国家重点实验室,河南郑州 450001;2.郑州大学计算机与人工智能学院,河南郑州 450001)
1 引言
随着信息技术的迅速发展,5G网络逐步普及,接入互联网的设备将迅速增长,根据相关统计和预测,到2025 年,接入互联网的设备将达到5 000 亿[1].通信设备的急剧增加导致数据量呈现爆炸式的增长,为了应对海量数据的处理,逐步形成了在边缘计算、内存计算、智能计算等模式下,以数据为中心的新一代计算网络.但是,大量的网络数据带来的网络负载和存储问题仍然制约着网络性能的进一步发展.
数据压缩技术在满足用户获取原信息的同时,通过有效的编码,能够减少数据量,在数据的存储管理和网络数据传输方面得到了有效的应用[2,3].数据压缩分为有损压缩和无损压缩,前者主要应用于视频和图像,即使某些数据的丢失对于用户的感官也没有太大的影响,代表的算法有基于离散余弦变换的数据压缩、基于小波的数据压缩和基于线性预测编码的数据压缩等.后者主要应用于数据正确性要求较高的场景,代表的算法有LZ77、RLE(Run-Length Encoding)、Snappy 等.其中LZ77 算法较复杂,且需要消耗较大的内存和计算资源[4],RLE 主要应用于位图压缩[5],通用性较低,而Snappy 是Google 开源的压缩/解压缩库,在满足一定压缩率的条件下,具有较高的压缩速度,已经被应用到内存数据库和电子探测器的高容量数据压缩方面[6,7].
为了降低数据存储和网络数据传输的限制等问题,同时满足接收端获取完整的数据,采用Snappy 无损压缩算法对数据进行压缩处理.传统的数据压缩算法主要以软件的形式在CPU 上进行实现,压缩速度较低,并且应用场景有限,而GPU 主要应用于密集型计算的任务,能耗较高.FPGA 具有低功耗、可重构、能效低等特点,近几年被广泛应用于边缘神经网络的加速[8]、高速的数据加密[9]、并行数据压缩[10]等,在FPGA 上实现数据压缩算法能够在有限带宽的限制下,极大的提高数据传输速度[11].因此,本文首先分析Snappy 数据压缩算法的结构特征和算法流程;然后针对Snappy 算法进行RTL 级实现,并采用多种有效方法进行深度优化,例如专用并行数据匹配、访存优化、流水线技术等,同时,采用轮询策略、流水线数据转换等实现多通道的数据压缩算法,使算法能够动态扩展,进一步提高算法性能;最后通过算法实现、性能测试、性能对比等实验,验证本文实现方法的加速效果和性价比.
2 数据压缩原理及算法分析
Snappy 压缩算法是基于hash 值运算的字典匹配压缩,如果两组数据计算hash 值的结果相同,则两组数据相等的概率较大.最初版本Snappy 算法流程首先将待压缩数据分为32 KB 大小的块分别进行压缩,然后在32 KB 数据中对每字节数据与其相邻的3 字节数据计算hash 值,并在字典中获取有相同hash 值的数据,进行匹配、压缩,最后对处理后的数据进行编码输出.但是,原始的算法压缩及硬件实现效果较差.
Xilinx 在高端数据板卡Alveo U200 中对Snappy 算法进行了改进实现[12],降低了压缩率,压缩速度达到了10 GB/s,但是Xilinx 是由高级编程语言实现压缩算法,只能应用在特定FPGA 芯片,可移植性较低,因此,本文对Xilinx改进后的Snappy算法进行RTL级实现,在不损失算法压缩率的情况下,提高压缩速度和算法可移植性.改进后的Snappy算法处理框架如图1所示.
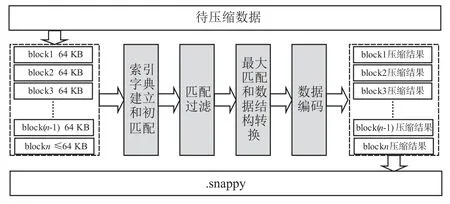
图1 Snappy数据压缩框架
首先对数据划分为64 KB 大小的block 块,然后对每个块进行四个阶段的处理,完成数据的压缩和编码,最后将每个块的压缩结果写入Snappy 文件,四个处理阶段是整个算法的核心,也是本文分析和实现的重点,详细分析如下:
(1)索引字典建立和初匹配.
初匹配阶段是数据扩充阶段,用于获得匹配的可能性,这一阶段对输入的字节数据进行处理,计算对应的匹配偏移offset和匹配长度len.
首先初始化索引字典和滑动窗口,索引字典的内容包含3 字节的索引值和6 字节的数据,存储结构如图2所示,索引值是6字节数据中第一个字节数据在block块的位置index.
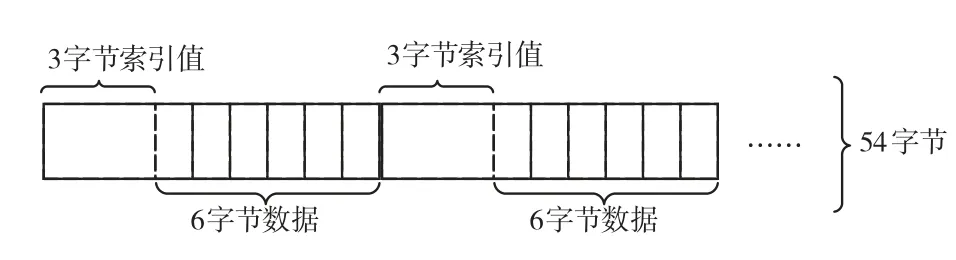
图2 索引字典存储结构
其次,依次读取待压缩内容,并写入滑动窗口,根据滑动窗口内容计算哈希值,以哈希值为字典索引,读取索引位置内容,并将窗口内容和索引值写入哈希值对应的字典中.
然后将读取内容与窗口内容进行匹配,此时匹配的最大长度为6字节.
最后,以当前的数据Dn、匹配偏移offset 和匹配长度len 共同构成Vn并输出,其中offset 由索引值之差计算,处理结构示意图如图3所示.
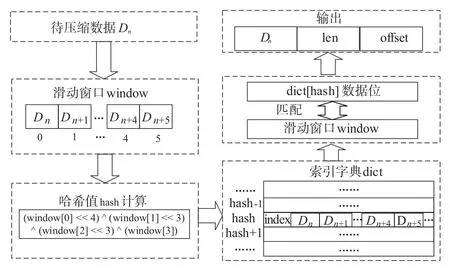
图3 压缩第一阶段处理结构图
图3 中索引字典的每行存储6 组数据,每组数据的长度是54 字节,存储在字典中同一行的6 组数据具有相同的hash 值,例如在字典中的hashNum 地址对应的值包含6组数据,表示为Bh~Bh+5,每组数据的内容如式(1)所示.

当计算滑动窗口的值满足hash(window)=hashNum时,则将匹配窗口的值和6 组数据进行匹配,同时更新hashNum 地址对应的字典行,行内数据变为Bh+1、Bh+2、Bh+3、Bh+4、Bh+5、index、window.以上即完成字典的更新,在这个阶段每组数据的最大匹配长度为6,每个数据都有输出,代表了其自身和之后的5个数据与具有相同哈希值组的最大匹配.
(2)匹配过滤.
首先填充比较窗口,每个窗口存放的值是第一阶段输出的三部分组成的值.然后,读取窗口0 的值Vn,并将窗口左移,同时,读入一组数据Vn+6,重新填满比较窗口.最后,将Vn与窗口中的每个值进行条件过滤.如果满足,原样输出,否则将匹配长度与匹配偏移赋值为0.其中,过滤条件为Vn的匹配长度与比较窗口位置相加大于比较窗口值的匹配长度.处理结构如图4所示.
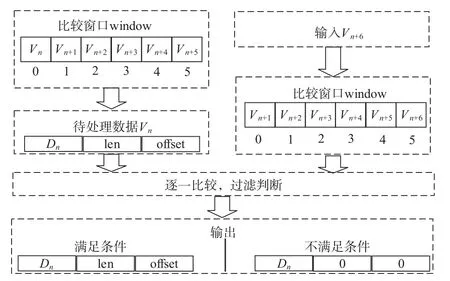
图4 压缩第二阶段处理结构图
这一阶段是获取最优匹配的可能性,并将匹配效果较差的数据设置为0匹配.
(3)最大匹配和数据结构转换.
这一阶段是数据压缩阶段,通过前两阶段的筛选,此时可以将匹配数据进行压缩,处理过程是逐个读取Vn,获取匹配偏移,然后通过偏移从匹配字典中读取数据进行最大匹配,并将匹配数据丢弃,从而完成压缩,匹配分为三种情况:
1)没有匹配,则原样输出;
2)有匹配,且偏移offset≤16 K,则依次读取数据,并丢弃,只记录匹配长度,最大匹配长度为64;
3)有匹配,且偏移offset>16 K,则根据匹配长度,读取相应数据进行丢弃;
此时,可得到数据Dn,改变后的匹配长度len,以及匹配偏移offset.
进一步将数据进行转换,如果len 为0,则将数据Dn单独输出,此时offset 为0,同时,增加未压缩字符计数litCount,共同作为匹配信息输出.如果不为0,则将数据Dn丢弃,只输出匹配数据len 和offset,且litCount 为0.转换后的数据分为数据Dn和匹配信息match_info(len,offset,litCount).
4)数据编码阶段.
根据litCount、len、offset 的值按照Snappy 规则进行编码,编码格式内容如图5所示.
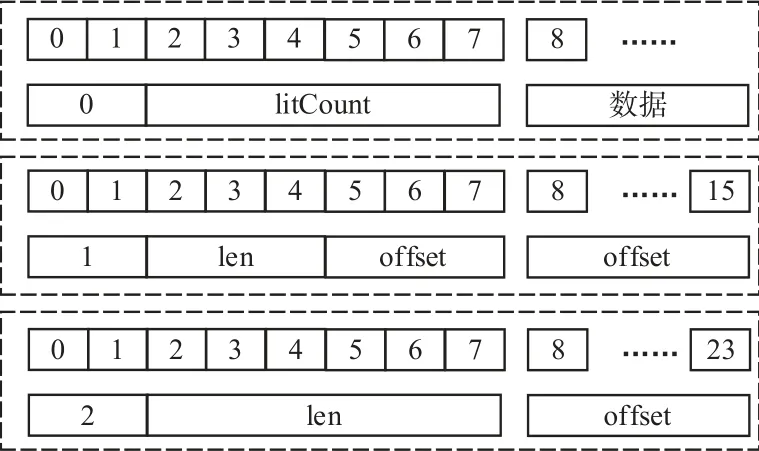
图5 编码格式
图5 中每个虚线框内的上方表示编码bit 位的索引,下方为编码内容,从上到下为三种编码格式:
(1)数据未压缩;
(2)len<12,offset<2048;
(3)211≤offset≤216并且len≤64,或者,11<len≤64 并且offset<211.
从算法流程可以看出Snappy 算法的计算量较小,但是包含了大量的数据比较和匹配,并且需要大容量字典存储数据,因此,要实现高效的Snappy 算法需要对算法的关键路径、存储需求以及实现结构进行优化.
3 并行Snappy压缩算法实现
为了满足算法的计算、存储、通信需求,实现高性能的Snappy 算法,本文结合FPGA 的芯片资源分布,布局布线的特点,以及频率对时序的影响等,对算法的关键路径、存储需求以及实现结构等多方面进行细粒度优化.
3.1 定制化并行数据匹配
Snappy算法的前两个阶段都包含6次数据匹配,是整个算法的关键路径,消耗较长时间,因此,需要对窗口的数据匹配进行优化.
对于第一个阶段的数据匹配,将滑动窗口数据与来自于索引字典中的6组数据分别进行匹配,匹配如算法1所示.

算法1 中主要的消耗时间为两层循环,即6 个字节的匹配时间tbyte_match和6组数据的匹配时间tdata_match,总时间为6tbyte_match×6tdata_match.而每组数据匹配时相互独立,因此,可进行并行匹配,并行匹配如算法2所示.

算法2 中步1~10 是通过generate 生成器并行化6个模块,则6tdata_match可在1个tdata_match时间内完成.步3~8 是并行字节匹配,消耗时间为1tbyte_match,由于是并行匹配,只能获得每个字节是否匹配,因此,增加flag作为匹配标记,并以flag为function_long函数的输入,求得每组数据的匹配长度len,最后以len 为输入,通过function_max 函数,求得最终匹配长度.在RTL 实现中,函数function_long 和function_max 通过组合逻辑进行实现,消耗时间较少,因此,通过并行匹配,关键路径消耗的总时间为1tbyte_match,极大的减少了时间复杂度.
在并行匹配的过程成,包含两步操作,赋值和匹配,布线路径从compare 到flag,如果在一个时钟内进行实现,消耗大量的查找表资源,增加时序影响,因此,添加buff_com和buff_win寄存器用于中间缓存,减少FPGA布局布线的路由复杂度,同时,将字节匹配的过程分为数据赋值和匹配两个模块,RTL实现如算法3所示.

通过增加寄存器资源减少查找表资源,使并行匹配消耗的物理时间为2个时钟周期,定制化并行匹配硬件实现结构如图6所示.时钟clk贯穿6个并行模块,在每个模块内,第一个时钟完成寄存器赋值,第二个时钟进行逻辑运算,实现匹配判断,并通过时序逻辑在较短的时延内计算匹配长度,从而两个时钟可完成并行匹配.
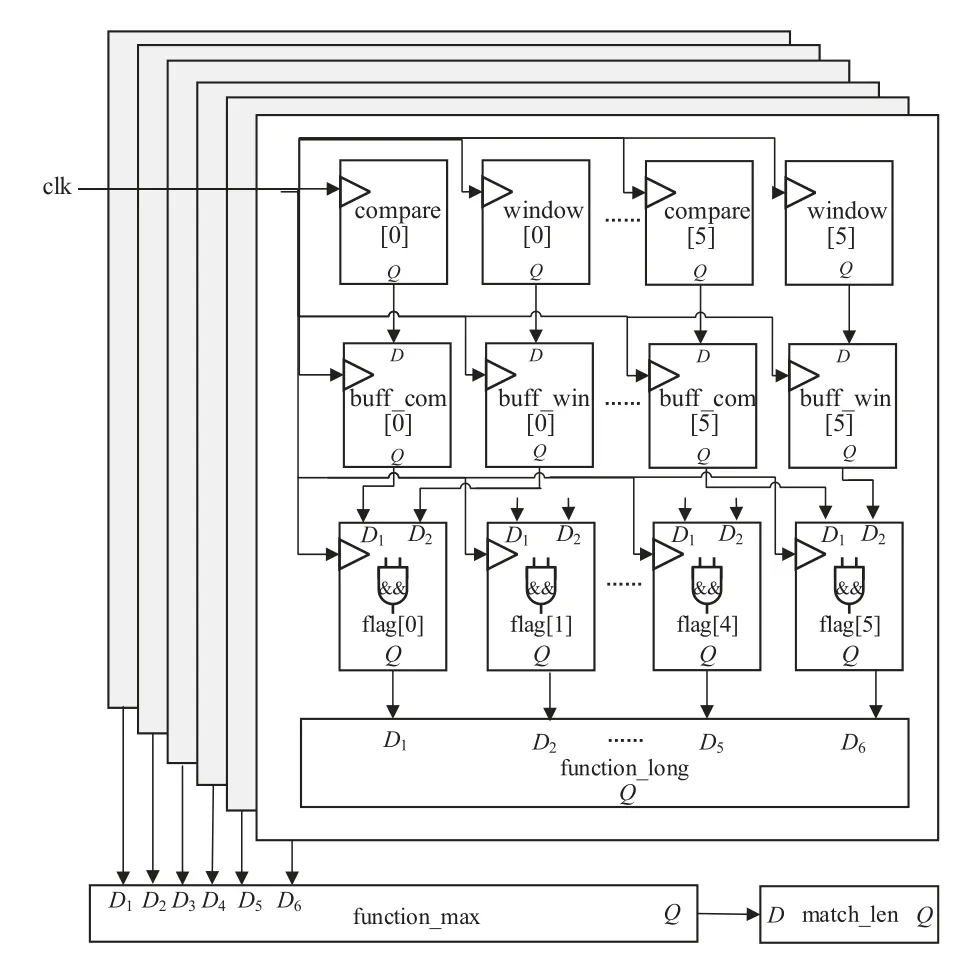
图6 定制化并行匹配硬件实现结构
3.2 细粒度串并混合结构
Snappy 算法对每个字节数据进行多次处理,具有重复性,在数据压缩过程中,数据具有单向流动性,FPGA 的各种逻辑计算单元具有独立性,通过时钟驱动可实现资源的并行,因此,Snappy 压缩算法可在FPGA上采用流水线进行实现.
数据压缩的前三个阶段在实现中共细分为15个子任务模块,第一阶段分别为读数据、写滑动窗口、哈希值计算、读字典、数据匹配和输出缓存,其中数据匹配经过优化后分为寄存器赋值和并行匹配,共7 个子任务.第二阶段分别为读窗口数据、每个窗口的条件过滤匹配和最后的输出缓存,同样,过滤匹配也分为寄存器赋值和并行匹配,共4 个子任务.第三阶段分别为接收数据、读字典、匹配、数据转换,共4 个子任务,即处理1字节数据需要经过15个子任务.
在编码阶段,由于数据是经过压缩后的数据,数据量变小,并且在不同的条件下处理两种数据,采用流水线实现会增加计算复杂度,消耗大量的计算资源,因此,在这一部分的实现上采用串行的状态机进行实现,而在处于读取明文的处理状态中,最大需要64 次读取数据,通过计数器控制可进行连续读取,即使在没有压缩的极端情况下,仍然可满足要求.Snappy 实现结构如图7所示.

图7 Snappy算法实现结构
图7 中流水线数据压缩部分表示压缩过程中的15个子运行模块,数据从输入到输出一共需要消耗15 个时钟,并且15个子模块并行计算,形成15级流水线.通过连续的读取数据,15个时钟之后,每个时钟处理一组数据,相当于每个字节数据只需要1 个时钟,极大的提高了算法性能.
通过细粒度的串-并混合的结构设计,实现Snappy算法,能够最大的提高算法性能,同时,编码阶段采用了串行实现,在满足条件的情况下,可减少资源的利用和电路的负载,从而降低功耗.
3.3 面向硬件的多级缓存优化
随机存取存储器(Random Access Memory,RAM)包含地址线和数据线,将指定的数据写入指定的地址内,且读取数据后不会造成数据丢失.先进先出存储器(First In First Out,FIFO)没有地址的约束,实现较简单,主要用于数据缓存.因此,利用RAM 和FIFO 分别对字典实现和访存进行存储优化.
(1)字典实现
Snappy 压缩算法中第一、三阶段中都包含对字典的操作,通过计算索引并从索引位置存取数据,字典的空间较大,在FPGA 中实现字典可采用寄存器和Block RAM 进行实现,而前者消耗了有限的寄存器资源和查找表资源,对于较大的字典使得资源利用不充分.Block RAM 是FPGA 上专用存储单元,分布在逻辑计算资源的边界上,因此,采用Block RAM 实现字典,操作结构如图8所示.
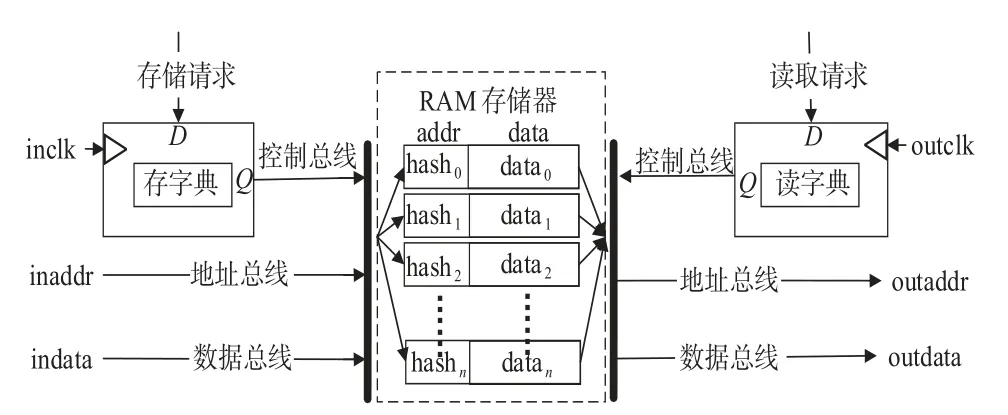
图8 字典实现及操作结构
Block RAM 实现的字典操作结构中,当有存储请求时,通过时钟inclk 触发执行,在控制总线作用下,将数据indata存储到地址inaddr;当有读取请求时,通过时钟outclk 触发执行,从地址outaddr 读取相应数据outdata,存储器中索引地址与hash 值一一对应.进行流水线计算过程中,读写操作分别只需要一个时钟即可完成,满足高性能的数据操作要求,具有较大的存储和通信效率.
(2)访存优化
由于FPGA 内没有足够的存储单元,而数据压缩需要数据存储到本地或者实时的传输到FPGA 中,并且压缩的数据是连续的,因此,利用内存DDR 与FPGA 的连接,将待压缩的数据存储到DDR 中,进行压缩时,直接从内存存取数据.FPGA 与DDR 之间通过IP 核MIG(Memory Interface Generator)进行连接,采用AXI4 通信协议实现物理层面数据传输,为了满足Snappy 算法高速的数据输入,需要对访存进行优化,实现FPGA 与DDR的高效数据传输,实现结构如图9所示.

图9 访存优化结构
FPGA与DDR之间设计多级缓存机制进行优化,首先,添加读内存缓存模块,在该模块中预先计算待压缩数据的地址并存储在fifo_addr_rd 中,通过读控制状态机读取地址,再利用AXI4 协议从DDR 中读取数据.其次,将读取的数据写入fifo_data_rd 中,Snappy 算法根据FIFO 的空满信号读取数据.然后,添加写内存控制模块,并将压缩后的数据存入fifo_data_wr 中,最后,预先计算写内存地址,并存入fifo_addr_wr,写控制状态机通过AXI4协议根据地址将相应数据写入DDR中.
DDR 与Snappy算法之间增加了两个缓存控制模块和多级缓存,使算法的实现与地址之间进行解耦和,数据之间只存在FIFO操作,并且操作的端口相互独立,最大化的减少各模块之间的相关性,从而降低布线路由的复杂度.
Snappy 压缩算法在FPGA 上仅占用较小部分的计算与存储资源,并且随着工艺的提升,芯片资源也在不断增加,因此,采用多通道并行方法,当有大量的数据需要压缩处理时,对数据进行划分,通过逻辑控制将多个Snappy 算法并行处理,实现最优性能.同时也可提高算法在不同芯片上的可扩展性.
内存具有地址映射的功能,包含控制总线、数据总线和地址总线,数据存储内存的位置和大小可预先计算,因此,设计的第一步是不同通道的数据划分,Snappy 算法将待压缩的数据按照64 KB 大小进行block划分,数据是连续的,对于不同的通道,通过地址偏移将处理通道与待压缩数据进行一一对应,多通道实现如图10所示.
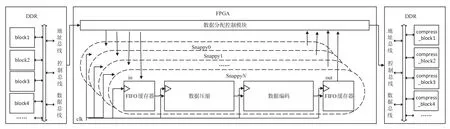
图10 多通道并行结构
在整个结构中,FPGA 内包含一个主控制模块,用于将内存的数据进行划分,并计算不同block 的大小和偏移地址,然后按照Snappy 返回的偏移地址从内存中获取数据,顺序存入到不同通道对应的FIFO中,并启动相应的Sanppy 算法进行压缩.压缩结束后,主控制模块将压缩后的数据顺序写入内存指定位置.
主控制模块与DDR 的交互只有一个通道,而与算法之间具有N个并行通道,因此,从内存取数据的速度speedDDR与Snappy的压缩速度speed应该满足式(4).
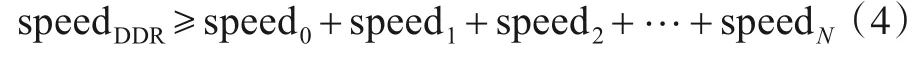
FPGA 与DDR 之间通过AXI4通信协议实现物理层面的高速数据传输,支持突发式数据传输,即一次请求响应的交互中,可以传输多组数据,每组数据为256位,突发长度(Burst length)在1 和255 之间.因此,采用顺序轮询策略进行访存操作的数据存储,结构如图11所示.
图11 中starti_addr_offsetj表示第i个通道、第j组数据的偏移地址,首先,主控制模块顺序从地址FIFO中读取地址,然后AXI4协议顺序从DDR 读取数据并存入数据FIFO 中,最后主控制模块通过轮询状态机将数据传输到相应Snappy 算法中.假设整个FPGA 实现的频率为100 MHz,则单位时间内压缩数据量如式(5):
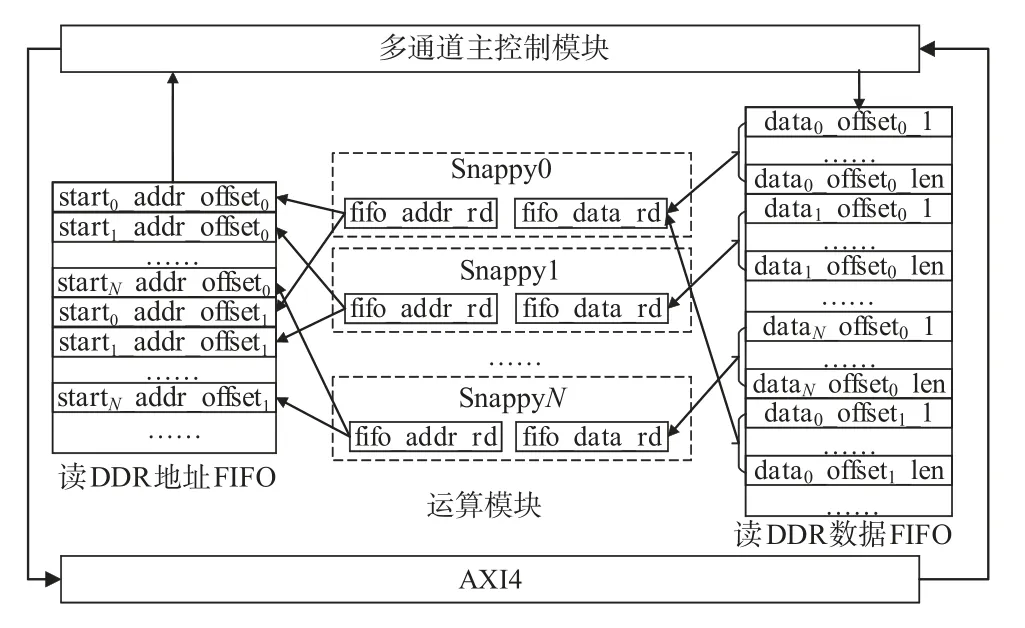
图11 访存数据轮询存储结构
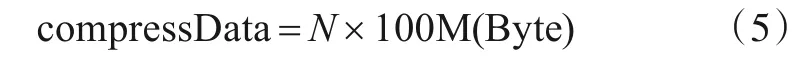
内存数据传输量如式(6):

其中len 表示突发传输长度,timedelay表示从内存传输一次数据的总消耗时间,只需满足式(7):
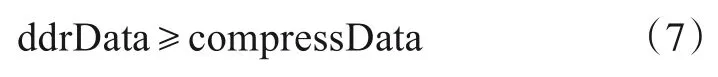
也即式(8)所示:

由于采用的是轮询策略,则单个压缩通道在单轮数据输入满足式(9):
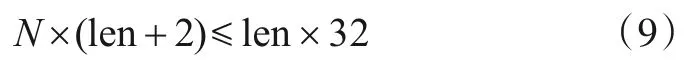
前者表示轮询一周需要的时间,len+2 表示轮询单个通道需要的时间,状态转换和FIFO 启动需要消耗两个时钟,后者表示轮询一次传输的数据量,只有满足公式才能保证单通道内连续的数据输入.最大通道数和突发长度根据实际板卡性能进行可变的扩展,满足上述要求,从而实现FPGA最大数据压缩性能.
3.4 基于移位器的流水线数据转换
FPGA 与DDR 通信数据位宽是多字节,而Snappy算法是单字节处理,因此,需要对Snappy 算法接收到的数据快速转化为单字节进行处理,压缩后的数据同样需要将单字节数据快速拼接为多字节数据输出.
多字节转换单字节的原理是将多字节数据经过移位器处理,从而获得单字节数据,硬件实现如图12所示.
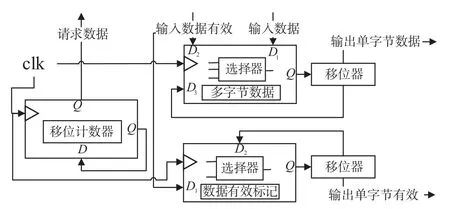
图12 单字节转换硬件实现原理
各处理模块以时钟clk 为触发条件并行计算,移位计数器是在一定时间内请求数据;移位器将多字节数据每次向右移动8 位,输出单字节数据和移位后的数据;多字节数据处理中,通过输入数据是否有效,从而判断接收的数据是移位后的数据或者是输入数据;数据有效标记是与输出的单子节数据一一对应,表示输出数据有效.当有大量的数据需要处理时,每个时钟都有数据输出.
本文中,处理的数据为32字节,RTL 实现的并行处理如算法4 所示,其中valid 表示数据有效,算法分为两个部分,第一部分添加计数器,32 个周期获取一组输入,第二部分则是输出赋值,由于FPGA 是并行计算,只要有输入时钟,各模块运算不会终止,因此,增加flag标记,表明数据的有效.两部分并行处理,通过算法4 的实现,使数据转换能够流水线的连续输出.

单字节转换为多字节可通过对算法4进行修改,首先输入单字节数据,然后对数据进行移位拼接,最后依据计数器输出.通过对数据转换的高速实现,使Snappy算法从输入到输出形成连续的数据处理链,在流水线的处理中,满足各个部件的满负载运行.
4 实验结果与分析
本文采用的硬件为Zynq-7035,搭载的FPGA芯片包含逻辑单元(Logic Cells)270 K、查找表(LUT)171900、500(17.6 Mb)存储大小的Block RAM以及343 800个触发器(Flip-flops)等,与FPGA连接的内存DDR存储为1 GB,并且内存数据的数据通信带宽最高为50 Gb/s,硬件板卡有PCIE通道,可将PC机数据传输到板载内存中.
FPGA与DDR之间支持突发式数据传输,而不同突发长度影响请求响应信号,从而导致实际的数据带宽存在差异.为了满足Snappy 算法的性能最优,需要保证数据能够满足Snappy 的输入,因此,对FPGA 与DDR之间的数据通信,设计不同突发传输大小并进行测试,在不同时钟频率下,结果如图13所示.
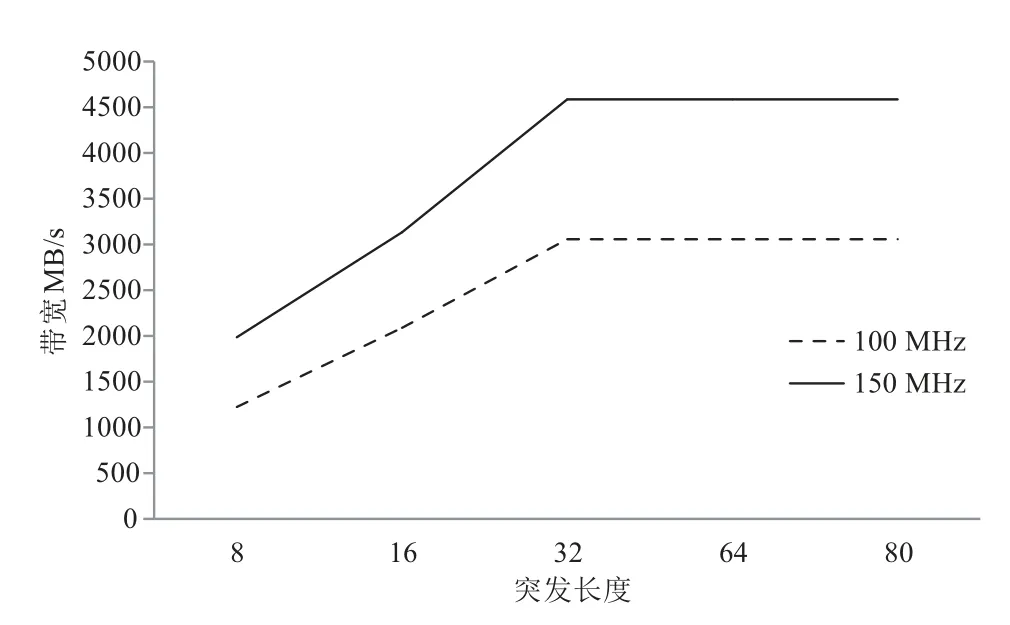
图13 在不同频率下FPGA与DDR通信带宽
从图13 中可以看出随着突发长度的增长,通信带宽成正比增长,当突发长度大于32时,通信带宽在测试板卡中趋于平稳,即使在100 MHz 的时钟频率下,带宽达到3 057 MB/s,因此,将DDR 与FPGA 的突发传输长度设计为32,可满足数据压缩的通信传输要求.
在单通道下,对Snappy 算法的RTL 实现进行综合布线,实现频率为148 MHz,各主要模块所占资源结果如表1 所示.从表1 的资源占用可以计算出Snappy 核心算法模块占总资源的1.1%,资源占用量较小.
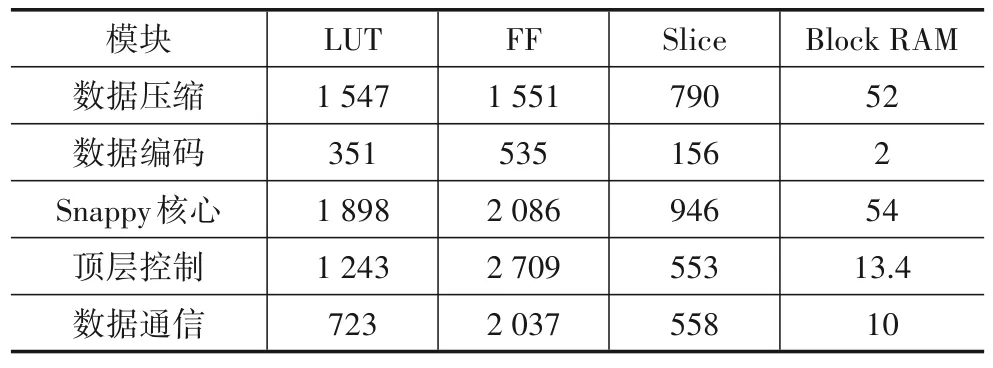
表1 主要模块资源占用
在单通道计算模式下对不同数据进行压缩,压缩速度如表2 所示.从表2 可以看出在FPGA 上优化实现的算法在性能上基本达到了实际的频率,即采用串-并混合的优化结构达到了与全流水线相同的性能.
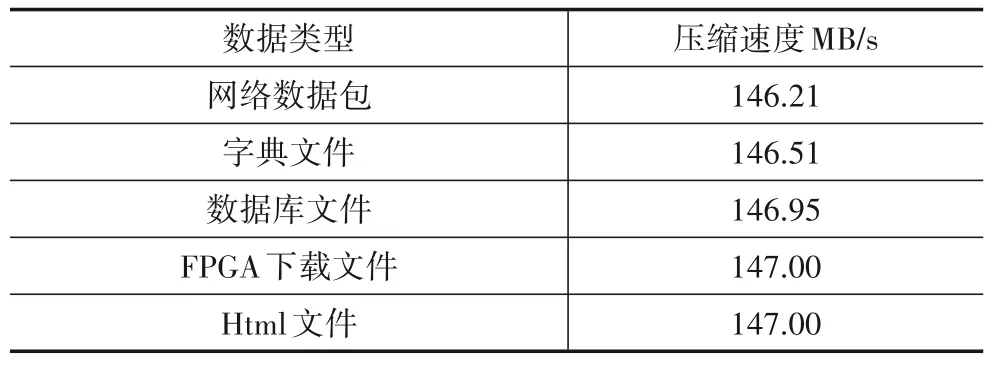
表2 不同数据压缩速度
以单通道算法的资源使用量为参考,可以计算出FPGA 芯片的总资源满足四通道并行的Snappy算法,实现结果的资源占用如表3所示.
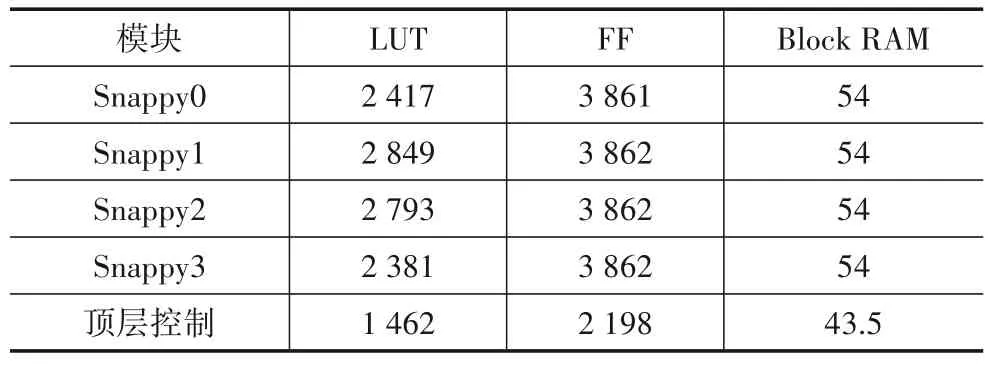
表3 四通道下Snappy算法资源占用
由于核心算法增加了3倍,使软件自动化布线的复杂度增加,需要增加资源的占用从而增加布线的成功率,因此,在四通道下资源比单通道下占用较多,但是,与整片芯片相比仍然具有较小的资源占用率,最后实现的频率为139 MHz,压缩性能与不同CPU 进行对比,结果如图14所示.
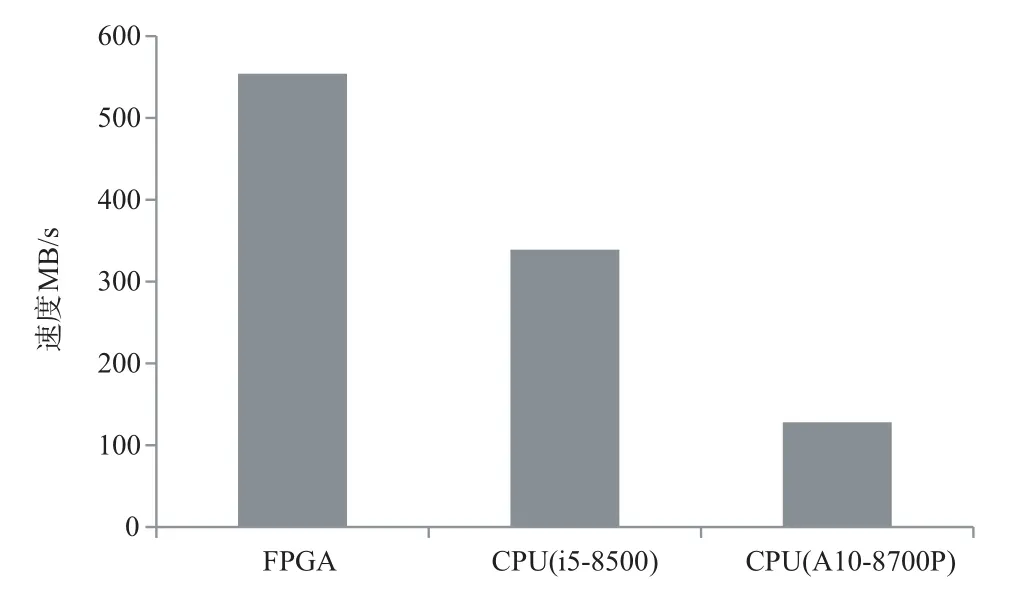
图14 不同芯片性能对比
从图14中可以看出本文实现的结果与CPU相比具有较高的性能优势.
加速比(Speed up)是衡量加速效果的指标之一,指的是程序串行运行的时间与并行运行的时间的比值[13],计算如式(10):

其中data 为待压缩数据的数据量,通过计算可得FPGA与CPU(i5-8500)的加速比为1.634,具有较高的加速效果.
研究者对于RTL 级的Snappy 算法研究较少,而LZ4 算法与Snappy 算法具有类似的压缩方法,因此,将Snappy算法与LZ4算法进行对比,如图15所示.

图15 性能对比
图15中不同文献采用的芯片为28 nm,与同类型算法相比,在相同工艺的硬件上,本文实现的压缩算法在性能上具有较大的优势.
Xilinx 公司给出了在FPGA 上实现Snappy 单个执行核的资源结果,与本文实现的单通道结果对比如表4所示.
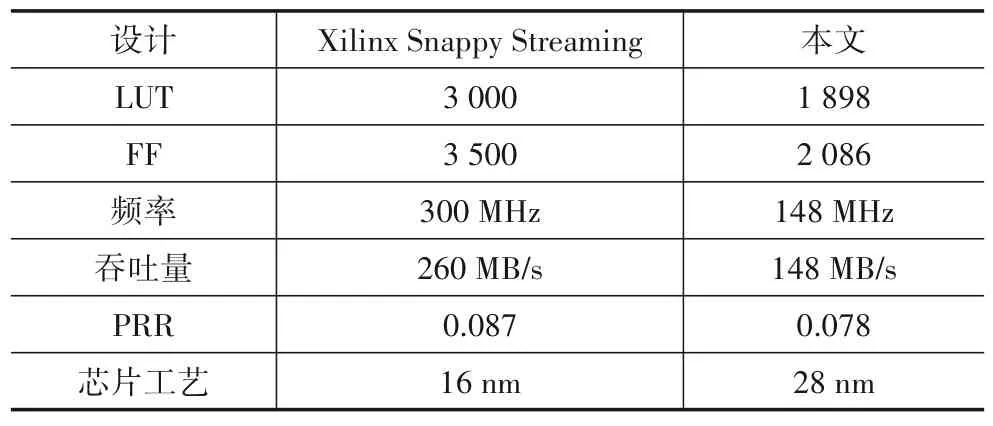
表4 不同板卡单核算法对比
表4 中PRR 是性能资源比(Performance Resource Ratio),表示单个LUT 资源的性能,数值越大,资源利用率越高.由于所使用的芯片工艺差别较大,本文实现的性能频率略低,使得PRR 略低于Xilinx 的结果,但是在资源占用方面,LUT 资源与Xilinx 给出的结果下降了36.7%,具有较大的资源优势.
Xilinx 在Alveo U200 上通过多通道并行实现了高性能的Snappy 压缩算法,与本文的结果进行对比,如表5所示.

表5 不同板卡对比
从表5中可以看出本文的实现性能略低,但是综合的性价比要高于U200,表明本文所提方案具有较大的可行性和实际应用价值.
5 结束语
随着信息技术的迅速发展,网络上的数据量呈爆炸式增长,同时,FPGA 作为计算设备、网络设备、存储设备得到了广泛应用,为了解决网络负载和数据存储问题,在有限带宽下提高数据发送量,同时增加数据存储量.提出了在FPGA 上实现Snappy 算法,通过多种FPGA 优化方法进行RTL 编码,实现的结果占用面积较少、性能较高.通过对算法的扩展,可将算法应用到边缘设备、数据中心等要求性能更高的数据处理领域.
猜你喜欢
销售与市场(营销版)(2021年10期)2021-11-21
现代电子技术(2020年21期)2020-12-07
小学阅读指南·低年级版(2019年11期)2019-07-01
销售与市场(营销版)(2019年6期)2019-06-21
计算机应用与软件(2018年10期)2018-10-24
小天使·一年级语数英综合(2017年11期)2017-12-05
数字技术与应用(2017年3期)2017-05-17
读者(2016年14期)2016-06-29
电脑知识与技术(2014年13期)2014-07-18
城市建设理论研究(2012年35期)2012-04-23
