
ELMo‐CNN‐BiGRU 双通道文本情感分类模型
2022-08-12 02:29王梓宇赵伟超
计算机工程 2022年8期
吴 迪,王梓宇,赵伟超
(河北工程大学信息与电气工程学院,河北 邯郸 056038)
0 概述
文本情感分类是自然语言处理领域的重要分支,广泛应用于舆情分析、内容推荐等任务,能帮助用户快速获取、整理和分析相关信息,并对带有情感色彩的主观性文本进行分析、处理、概括和推理。目前,深度学习技术[1]和注意力机制得到快速发展并且在文本分类领域取得了一定的研究进展。在利用深度学习技术实现自然语言处理的过程中,常用word2vec、Glove 等词嵌入方式表示原始文本信息,从而有效捕捉句法和语义相关信息。文献[2]提出一种基于卷积神经网络(Convolutional Neural Network,CNN)的情感分类模型CNN_Text_word2vec,引入word2vec 来训练每个单词上的分布式单词嵌入,通过多个不同大小的卷积核来学习文本特征。文献[3]提出卷积神经网络和长短期记忆(Long Short-Term Memory,LSTM)网络模型CNNLSTM,采用word2vec训练初始单词向量,利用CNN 提取文本局部特征,通过LSTM 捕获序列之间的长期依赖关系。文献[4]提出一种基于深度卷积神经网络的文本情感分类模型,堆叠多个卷积层,并利用全局最大池化构建情感分类模块。文献[5]提出MTL-MSCNNLSTM 模型,将多尺度CNN 和LSTM 相结合,有效利用处理不同尺度文本的局部和全局特征。文献[6]提出MF-CNN 模型,结合多样化的特征信息,利用句中的情感特征优化情感分类结果。针对现有深度学习技术在文本情感分类任务中特征提取能力不足的问题,研究人员提出了一系列解决方案。文献[7]提出一种双通道卷积神经网络模型,将扩展文本特征和语义特征分别输入到多通道的CNN 模型中,增强模型的情感特征提取能力。文献[8]提出一种基于深度学习的词汇集成双通道CNN-LSTM 情感分析模型,将CNN 和双向长短期记忆(Bi-directional Long Short-Term Memory,BiLSTM)分支以并行方式组合在一起提取特征。文献[9]提出一种卷积神经网络和长短期记忆结合的模型,串联CNN 和LSTM 两个模型提取文本情感特征。文献[10]提出Multi-Bi-LSTM 模型,对现有的信息生成不同的特征通道,利用BiLSTM 学习句子中的情感倾向信息。注意力机制本质上与人类的选择性机制类似,其目标是从众多信息中选择出对当前任务目标更关键的信息,被广泛应用于自然语言处理、图像与语音识别等各种不同类型的深度学习任务中,可有效提高模型分类效果。文献[11]提出一种多通道卷积神经网络模型,采用3 种通道进行卷积操作,利用字向量发现文本深层语义特征。文献[12]提出一种基于RNN 和CNN 并融入注意力机制的新模型。文献[13]利用区域LSTM 来调整不同信息对分类结果的影响程度,并实现了区域划分。文献[14]提出一种基于递归神经网络(Recurrent Neural Network,RNN)的情感分析方法,将预处理后的文本数据输入到一个或者多个RNN 中,利用注意力机制进行处理。文献[15]对不同注意力模块进行独立训练,用以提取各类文本情感特征。文献[16]提出基于注意力机制的AT-DPCNN 模型,利用CNN 进一步提取注意力输入矩阵的特征。文献[17]提出一种基于注意力的双向CNN-RNN 模型,利用注意力机制给双向特征提取层赋予权重。文献[18]在利用多头注意力机制的同时加入位置编码,采用图卷积网络获取文本的情感信息。
上述模型由于采用传统的静态词向量进行建模,导致上下文相似但情感极性不同的词语映射到向量空间相邻位置,影响情感分类效果,因此本文充分考虑不同上下文中的一词多义现象,并且兼顾提取全局特征与局部特征,提出一种ELMo[19]-CNN-双向门控递归单元(Bi-directional Gated Recurrent Unit,BiGRU)双通道文本情感分类模型。将动态词向量与静态词向量相结合,以实现不同上下文语境中的一词多义效果。采用注意力机制处理输入向量,得到内部词之间的依赖关系。构建CNN-BiGRU 双通道结构,并行提取数据的局部和全局特征,以实现特征的完整提取。
1 相关知识
1.1 ELMo 预训练模型
文献[19]提出的ELMo 是一个双层双向的LSTM 模型,分别有一个前向和一个后向语言模型,前向LSTM 和后向LSTM通过和计算获得,其中(c1,c2,…,cn)表示n个文本序列。ELMO 预训练模型结构如图1所示,其中E表示文本语料的词向量。利用大量语料训练ELMo 模型结构,获得预训练模型。将ELMo 预训练模型生成数据的动态词向量与Glove预训练模型生成的静态词向量进行堆叠嵌入,作为ELMo-CNN-BiGRU 模型的输入特征。
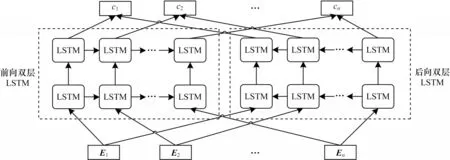
图1 ELMo 预训练模型结构Fig.1 ELMo pretrained model structure
1.2 注意力机制
注意力机制是一种权重分配机制,通过调整权重系数来修改文本特征的关键程度。权重系数越大,表示该信息越重要,对文本情感分类结果影响越大。本文采用自注意力(Self-Attention)机制,仅关注自身信息更新训练参数,降低对外部信息的依赖程度,更好地获取信息的内部关联关系。
1.3 双通道深度学习模型
构建CNN 和BiGRU 双通道模型,同时获取输入信息的局部特征和全局特征。双通道结构可以有效弥补CNN 和BiGRU 模型各自缺陷,充分捕捉局部和全局的情感特征,优化文本情感分类结果。
1)局部特征获取。采用CNN 获取输入信息的局部特征。通过卷积层抽取信息特征,获取评论文本信息的局部语义特征。利用多尺度卷积核,采用不同尺度的卷积过滤器来帮助模型进行特征学习,获得不同距离单词间的特征信息。经过卷积层提取文本的特征信息后,输入最大池化层中进行特征降维。
2)全局特征获取。采用BiGRU 获取输入信息的全局特征,并且充分考虑上下文信息,更好地捕捉文本中的语义信息。BiGRU 中的GRU 单元结构如图2 所示,GRU 单元在t时刻的更新门rt、重置门zt、当前记忆内容hc、当前时间的最终记忆ht更新过程如下:

图2 GRU 单元结构Fig.2 GRU unit structure
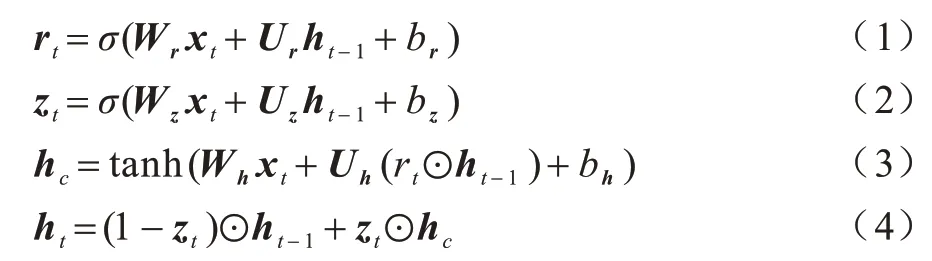
其中:xt为输入向量;σ、tanh 为激活函数;ht-1是t−1 时刻隐藏层状态信息;Wr、Wz、Wh、Ur、Uz、Uh为权重矩阵;br、bz、bh为偏置值;⊙符号是向量间点乘运算。
2 ELMo-CNN-BiGRU 模型
本文提出一种ELMo-CNN-BiGRU 文本情感分类模型。首先,对原始评论文本数据进行去停用词、无用标签、特殊符号等预处理操作。然后,在词嵌入操作过程中,采用ELMo 和Glove 模型分别生成动态词向量和静态词向量,将两种词向量进行堆叠嵌入作为模型的输入向量。其次,利用自注意力机制处理输入向量,获取信息的内部关联关系。再次,利用双通道的CNN 和BiGRU 模型分别提取局部和全局特征。最后,将双通道提取的特征进行拼接,经全连接层处理后,输入分类器进行文本情感分类操作。ELMo-CNN-BiGRU 模型框架如图3 所示。
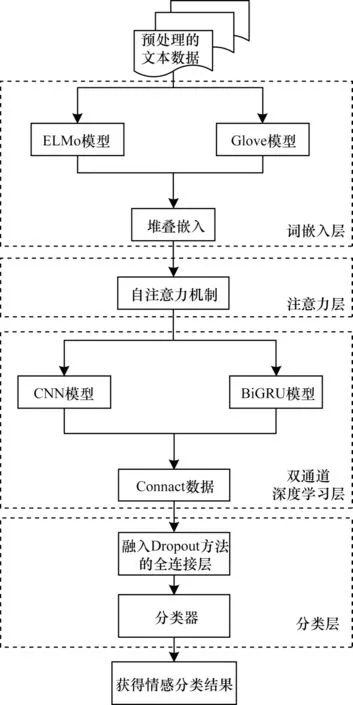
图3 ELMo-CNN-BiGRU 模型框架Fig.3 ELMo-CNN-BiGRU model frame
2.1 词嵌入层
由于静态词向量生成后不会发生改变,因此在应对不同上下文中一词多义情况时存在局限性。动态词向量会随着模型训练在不同上下文中做出调整,其初始化会影响到文本情感分类的收敛速度和最终结果。单独使用静态词向量和动态词向量其中的一种均存在一定的问题。为了在更精准地表示文本词向量的同时加快模型收敛速度,并优化文本情感分类结果,采用Glove 模型生成的静态词向量与ELMo 预训练模型生成的动态词向量,以堆叠嵌入的方式作为模型的输入向量。利用ELMo 预训练模型进行词嵌入操作,应对不同上下文中一词多义的情况,使用堆叠嵌入的方式融合两种词向量,能够有效优化文本情感分类结果。
Glove 模型生成词的向量为wg,具体公式如下:

其中:t表示词向量wg的维度。
ELMo 模型生成的词向量为we,具体公式如下:

其中:T表示词向量we的维度。
将wg与we堆叠生成的词向量,作为模型隐藏层的输入数据iinput,具体公式如下:

2.2 注意力层
采用Self-Attention 机制得到内部的词依赖关系,具体公式如下:

其中:dk为输入词嵌入向量的维度;W为输入信息。
将堆叠嵌入的特征向量,输入到由Self-Attention机制构建的注意力层,进一步在双通道深度学习层中获取局部与全局特征。
2.3 双通道深度学习层
ELMo-CNN-BiGRU 模型采用双通道结构,其中CNN 通道用来捕获评论文本数据的局部特征,BiGRU 通道用来获取评论文本数据的全局特征。该结构可以同步综合考量评论文本数据的局部和全局特征,在提取文本数据全局情感倾向特征的同时,捕获文本的局部情感特征,从而更全面地获取文本的情感特征,有效优化文本情感分类结果。
2.3.1 CNN 通道
ELMo-CNN-BiGRU 模型利用CNN 通道获取文本数据的局部特征,其中CNN 通道由卷积层和池化层两部分组成。
1)卷积层
卷积层采用3 种不同大小的卷积核,获得不同距离词序列之间的特征来提取更全面的局部信息。在CNN 通道中,利用卷积核进行一维卷积操作,将词嵌入矩阵转化为一维向量,采用ReLU 函数作为卷积层的激活函数。卷积操作能提取词语序列的特征,从词语序列Xi:i+h−1中提取特征图,具体公式如下:

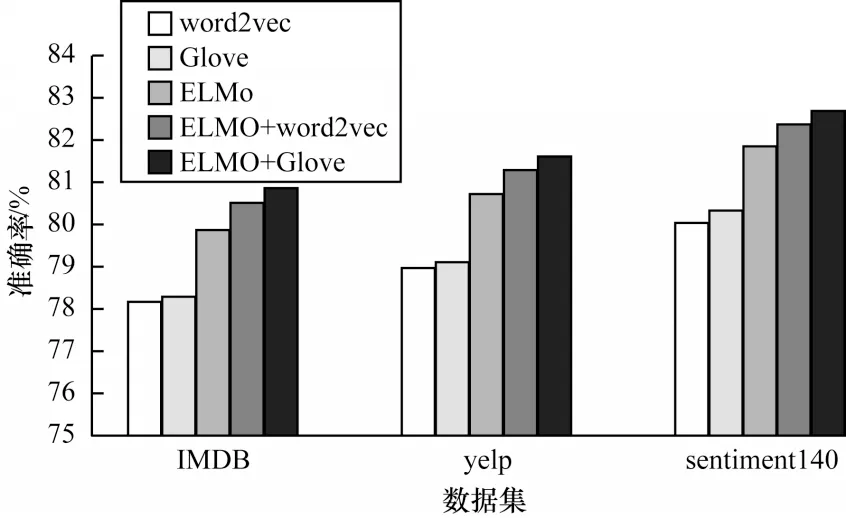
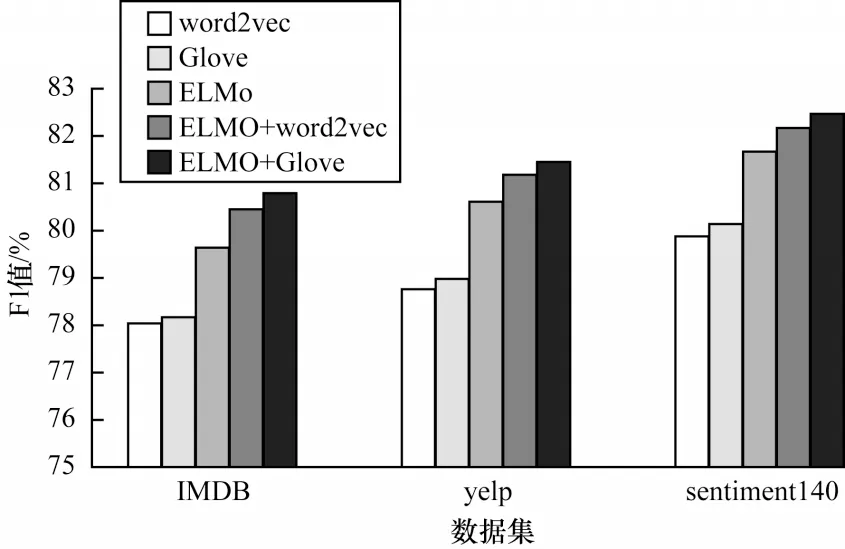
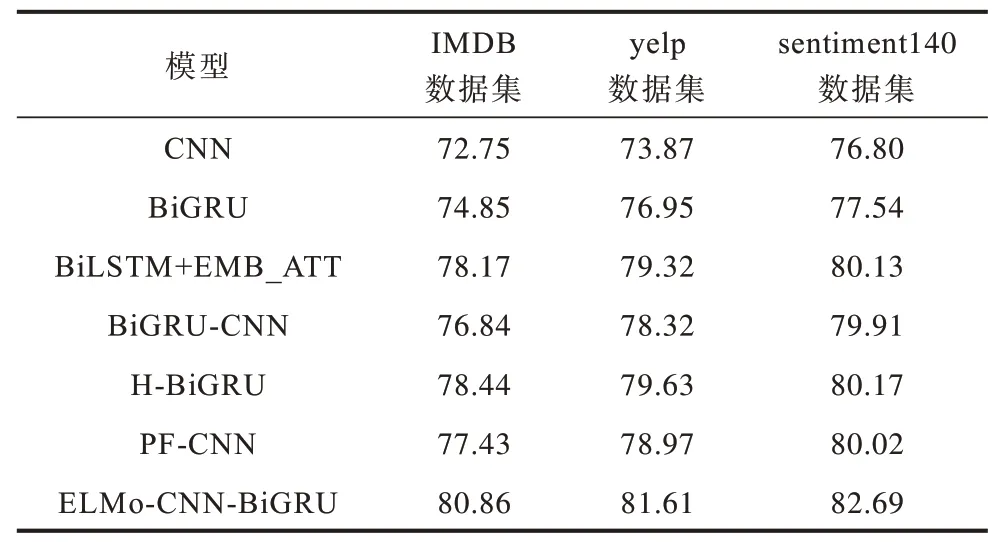
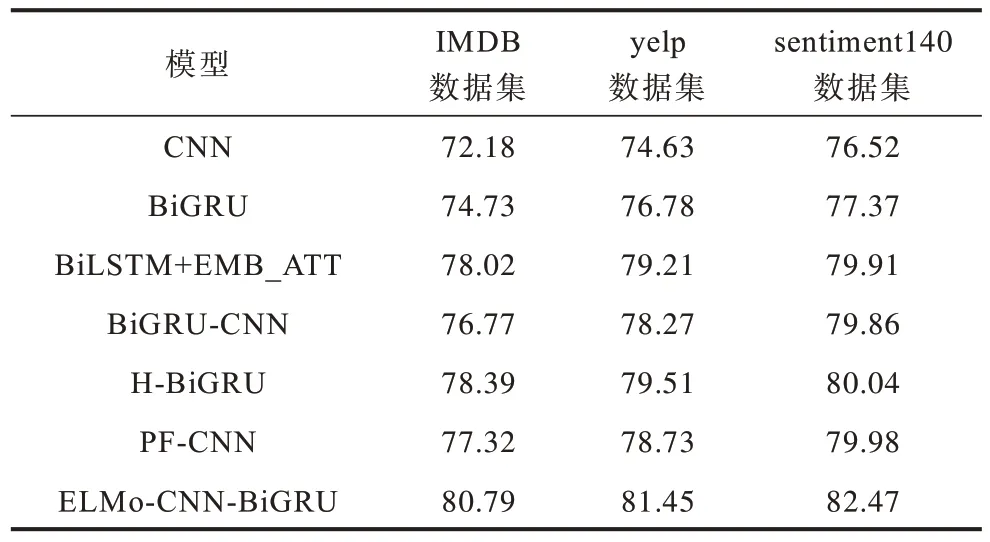
其中:b∊Rk为偏置项,k为向量的维度;f为非线性函数ReLu;W∊Rhd表示卷积核,h(h 2)池化层 采用最大池化法提取特征图(Zmax)中池化区域最大的特征值,可对特征信息进行降维,具体公式如下: 2.3.2 BiGRU 通道 BiGRU 通道用于提取数据的全局特征。在BiGRU 模型中,t时刻当前隐藏层ht由前向隐藏层和后向隐藏层加权求和得到,具体计算如下: 其中:xt表示当前隐藏层的输入向量表示(t−1)时刻前向隐藏层状态表示t−1 时刻后向隐藏层状态;wt、vt分别表 示t时 刻BiGRU 所对应的前向隐藏层和后向隐藏层的相关权重值;bt表示t时刻隐藏层状态的偏置值。 将双通道的特征数据进行拼接后,输入到全连接层中,通过在全连接层前融合Dropout 方法缓解模型过拟合现象。利用softmax 函数对文本进行情感分类,具体公式如下: 其中:a、b分别为全连接层的权重矩阵和偏置值;y为双通道拼接后的向量数据;Y为利用Dropout 方法处理后的向量。 ELMo-CNN-BiGRU 文本情感分类流程具体如下: 1)将文本D同时输入ELMo 预训练模型和Glove 预训练模型,生成对应的词向量Se=[w1,w2,…,wx]、Sg=[w1,w2,…,wX],其中文本D由x个句子{d1,d2,…,dx}组成,文本中第i个句子由j个单词{c1,c2,…,cj}组成,x和X为Glove 和ELMo 所生成的词向量的维度。 2)将生成的词向量进行堆叠式嵌入,得到模型的输入向量iinput=[Se,Sg]。 3)将词嵌入层生成的向量输入自注意力层进行处理。 4)将自注意力机制层中的数据分别输入双通道的CNN 层和BiGRU 层,分别得到两个通道的隐藏层表示。 5)拼接双通道的特征向量并输入带有Dropout机制的全连接层,经过全连接层处理后使用softmax函数进行分类,获得情感分类的最终结果。 在Colaboratory 云平台上进行模型搭建,采用Python编程语言和keras框架进行实验。在IMDB、yelp、sentiment140 数据集上,将ELMo-CNN-BiGRU 模型与6 种模型进行性能对比,此外,针对ELMo-CNN-BiGRU模型,将在迭代次数、词向量维度、词向量嵌入方式和通道结构这4个方面进行对比实验,以验证ELMo-CNNBiGRU 双通道文本情感分类模型的有效性。实验所用数据集中训练集和测试集的数据量比例为8∶2,具体统计信息如表1 所示。 表1 数据集统计信息Table 1 Data set statistics 将句子最大长度设置为100。对于小于最大长度的句子,采取补零操作;对于大于最大长度的句子,采取截断操作。采用Adam 函数作为模型的训练优化函数,Adam 函数的学习率设置为0.000 1。在ELMo-CNN-BiGRU 模型的CNN 通道中,多通道CNN 选取的卷积核窗口大小分别设置为2、3、5,采用Dropout 机制应对模型可能会发生的过拟合现象。BiGRU 模块采用Tanh 作为神经元的激活函数,CNN模块采用ReLU 函数作为卷积操作的激活函数。超参数设置如表2 所示。 表2 超参数设置Table 2 Hyperparameter setting 采用准确率(A)和F1 值(F)作为评价指标,用来测试ELMo-CNN-BiGRU 及其对比模型性能。准确率和F1 值的计算公式分别如下: 其中:P表示精确率;R表示召回率;TTP表示实际标签是真,模型预测结果为真的文本数量;FFN表示实际标签为真,但是模型预测结果为假的文本数量;FFP表示实际标签为假,但是模型预测结果为真的文本数量;TTN表示实际标签为假,模型预测结果也为假的文本数量。 为验证ELMo-CNN-BiGRU 模型性能,首先测试迭代次数对实验结果的影响,其次测试不同词向量维度、词向量嵌入方式、通道结构下的模型准确率和F1 值,最后将ELMo-CNN-BiGRU 与CNN、BiGRU等6 种文本情感分类模型进行对比实验。 3.4.1 迭代次数对比 在IMDB、yelp、sentiment140 这3 个数据 集上,ELMo-CNN-BiGRU 模型的准确率和F1 值随着迭代次数的变化趋势如图4、图5 所示。 图4 ELMo-CNN-BiGRU 模型在3个数据集上的准确率对比Fig.4 Comparison of the accuracy of the ELMo-CNN-BiGRU model on the three data sets 图5 ELMo-CNN-BiGRU 模型在3 个数据集上的F1 值对比Fig.5 Comparison of F1 value of ELMo-CNN-BiGRU model on three data sets 由图4、图5 可知:在第10 次迭代前,ELMo-CNNBiGRU 模型的准确率和F1 值总体呈现缓慢上升趋势,这是由于模型刚开始训练,权重参数在初始化阶段,需要增加迭代次数才能训练出提升模型分类效果的参数;在第10 次迭代后,ELMo-CNN-BiGRU 模型的准确率和F1 值在IMDB、yelp、sentiment140 这3 个数据集上普遍呈现较快上升趋势,这是由于经过迭代训练,模型已经训练出部分能提升模型分类效果的有效参数,进而加快了迭代速度;在第20次迭代后,ELMo-CNN-BiGRU模型在准确率和F1 值上普遍处于平稳状态,这是由于模型要达到拟合状态,结果变化不明显;在IMDB、yelp、sentiment140 这3 个数据 集上,ELMo-CNN-BiGRU 模型的准确率和F1 值的变化趋势相近,这表明ELMo-CNN-BiGRU 模型面对有差异数据时,分类结果具有一定的稳定性。 综上所述,在3 个数据集上,ELMo-CNN-BiGRU模型在sentiment140 数据集上取得了最优结果,这是由于该模型使用的ELMo 模型更适合处理短文本数据,在较短的文本上能获得更好的分类效果。 3.4.2 词向量维度对比 词向量维度对模型性能具有一定的影响。词向量维度越大,所表示的信息量越大,但会淡化词语之间的联系,然而词向量维度过小,则会产生无法有效区分词语的问题,因此需要选择合适的词向量维度。在3 个数据集上,对ELMo-CNN-BiGRU 模型使用不同维度的词向量进行实验测试。本文使用ELMo 模型和Glove模型堆叠的方式生成词向量,其中ELMo分别生成256、512、102 4 维的向量,Glove 分别生成50、100、200 维的向量,将两者堆叠后产生不同维度的词向量。在3 个数据集上,当词向量维度不同时,ELMo-CNN-BiGRU模型的准确率与F1 值对比结果如图6、图7 所示。 图6 词向量维度对ELMo-CNN-BiGRU 模型准确率的影响Fig.6 Effect of word vector dimension on the accuracy of ELMo-CNN-BiGRU model 图7 词向量维度对ELMo-CNN-BiGRU 模型F1 值的影响Fig.7 Effect of word vector dimension on F1 value of ELMo-CNN-BiGRU model 由图6、图7可知:ELMo-CNN-BiGRU 模型在3 个数据集上的准确率和F1 值都在词向量维度为612时达到最优效果。此时,ELMo 模型词向量维度为512、Glove模型词向量维度为100,因此词向量维度并非越大效果越好,过大反而会导致模型的性能下降。在词向量维度到达612之前,模型的性能震荡上升,在612 维度后模型的性能震荡下降。可见,ELMo-CNNBiGRU 模型性能变化不稳定,震荡改变是由于本文的词向量采用堆叠嵌入,动态词向量与静态词向量对模型性能的影响程度不同。 3.4.3 词向量嵌入方式对比 采用ELMo 和Glove模型分别生成动态词向量与静态词向量,堆叠后作为模型的输入向量,为验证堆叠嵌入方式的优势,将其与word2vec、Glove、ELMo、ELMo+word2vec 进行对比,在采用不同的词向量嵌入方式时,预训练模型的准确率与F1 值结果如图8、图9 所示。由图8、图9 可知:ELMo 和Glove 堆叠嵌入方式明显优于其他4 种词嵌入方式;与传统静态词向量嵌入方式相比,动态词向量与静态词向量堆叠嵌入方式能根据不同的上下文调整词向量,使得模型在准确率和F1 值上取得更好的效果;与ELMo和word2vec 堆叠嵌入方式相比,Glove 充分考虑全局信息,在实际应用中效果更好。 图8 不同词向量嵌入方式对ELMo-CNN-BiGRU 模型准确率的影响Fig.8 Effect of different word vector embedding modes on the accuracy of ELMo-CNN-BiGRU model 图9 不同词向量嵌入方式对ELMo-CNN-BiGRU 模型F1 值的影响Fig.9 Effect of different word vector embedding modes on the F1 value of ELMo-CNN-BiGRU model 3.4.4 通道结构对比 ELMo-CNN-BiGRU 模型采用双通道结构,将数据送入双通道结构,能更好地捕捉文本数据的全局与局部特征。在3 个数据集上分别进行双通道结构与CNN-BiGRU 串行结构的准确率和F1 值对比,实验结果如图10、图11 所示。 图10 双通道结构对模型准确率的影响Fig.10 Effect of dual-channel structure on model accuracy 图11 双通道结构对模型F1 值的影响Fig.11 Effect of dual-channel structure on model F1 value 由图10、图11 可知,双通道结构较串行结构可有效提升模型性能,在IMDB、yelp、sentiment140这3个数据集上,准确率分别提升了2.91、3.08、3.28个百分点,F1 值分别提升了2.87、2.98、3.13 个百分点。 3.4.5 文本情感分类模型对比 将ELMo-CNN-BiGRU 模型与如下6 种模型进行对比实验: 1)CNN,采用卷积层提取特征,池化层降低特征维度。 2)BiGRU,在门控递归单元的基础上,采用双向结构进行情感分析。 3)BiLSTM+EMB_ATT[20],使用注 意力机制学习句子的情感倾向权重分布,利用LSTM 获取文本的语义信息。 4)BiGRU-CNN[21],引入注意力机制,将BiGRU和CNN 串行叠加构建情感分类模型。 5)H-BiGRU[22],利用BiGRU 编码表示词向量和句向量,采用注意力机制加权求和获得数据的最终表示形式。 6)PF-CNN[23],分段提取句子特征,并融合词性特征与词向量区分同义词。 文本情感分类模型的准确率和F1 值对比结果如表3、表4 所示。 表3 准确率对比结果Table 3 Accuracy comparison results % 表4 F1 值对比结果Table 4 F1 value comparison result % 由表3、表4 可知:BiGRU 由于能够获取评论文本的语义信息和双向的上下文信息,较CNN 在准确率和F1 值上获得更好的结果;BiGRU-CNN 在BiGRU和CNN 串联处理特征信息的基础上,融入注意力机制,较CNN 和BiGRU 模型更 优;ELMo-CNN-BiGRU模型采用动态词向量技术进行词嵌入,通过BiGRU 和CNN 双通道并行提取特征,能够同时获得原始文本信息的全局特征和局部特征,与采用串联结构的BiGRUCNN 模型相比,评论文本情感分类准确率和F1值均有所提高;ELMo-CNN-BiGRU 采用自注意力机制,对原始评论文本信息进行权重处理,能够对重要信息投入更多关注,有效解决一词多义问题,与H-BiGRU、BiLSTM+EMB_ATT、PF-CNN模型对比,在评论文本情感分类方面具有更好的性能表现;ELMo-CNN-BiGRU模型在3 个数据集上的准确率和F1 值均为最优,与对比模型中情感分类性能最优的H-BiGRU 模型相比,准确率分别提升了2.42、1.98、2.52个百分点,F1值分别提升了2.40、1.94、2.43 个百分点。 本文提出一种ELMo-CNN-BiGRU 双通道文本情感分类模型。在输入层,融合静态词向量和动态词向量进行堆叠嵌入,使得文本信息表示能够较好地根据上下文调整语义。利用自注意力机制为文本信息分配权重,获得文本内部的词依赖关系,并将其输入到BiGRU-CNN 双通道中,更全面地获取文本数据的局部与全局特征。最终使用softmax 分类器,实现文本情感分类。实验结果表明,在IMDB、yelp 和sentiment140 这3 个数据集上,ELMo-CNN-BiGRU 模型相较于CNN、BIGRU、BiLSTM+EMB_ATT、PF-CNN、BiGRU-CNN和H-BiGRU 模型具有更优的情感分类性能。下一步将建立细粒度情感分类模型,并且通过融合注意力机制,识别结构更复杂的评论文本的情感倾向。

2.4 分类层
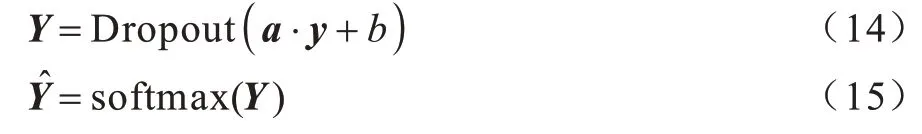
2.5 文本情感分类流程
3 实验结果与分析
3.1 数据集与实验环境设置
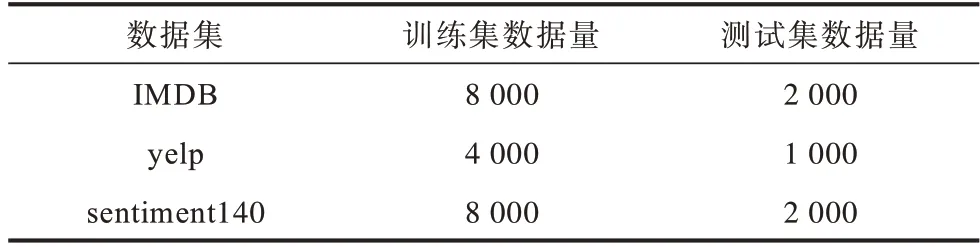
3.2 超参数设置

3.3 评价指标

3.4 结果分析
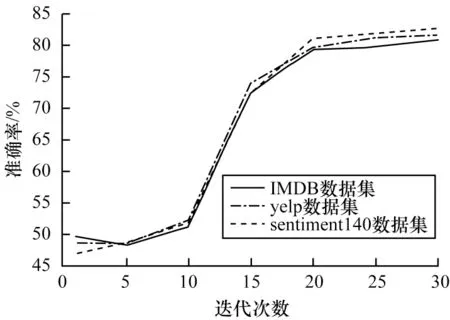
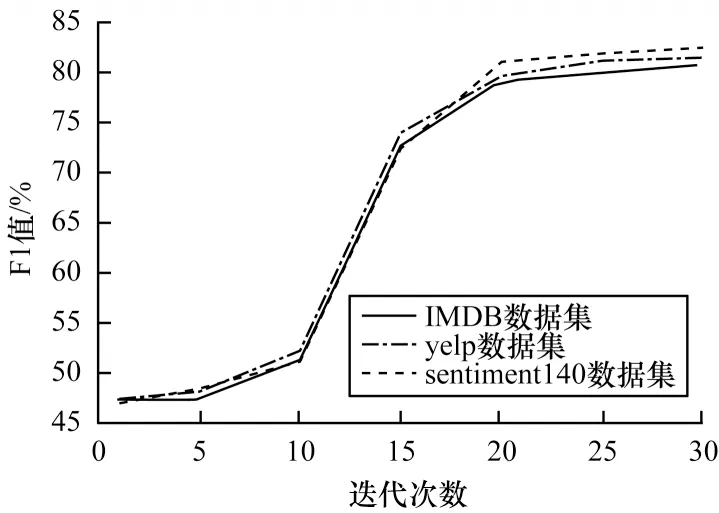

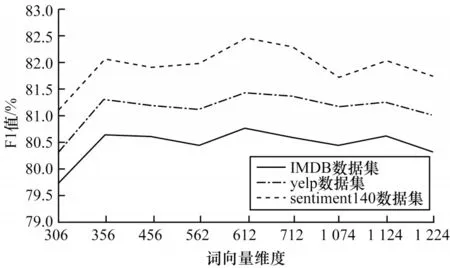


4 结束语
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
昆明医科大学学报(2021年4期)2021-07-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
就业与保障(2021年23期)2021-04-06
农业科技与信息(2021年2期)2021-03-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
健康体检与管理(2021年10期)2021-01-03
电子制作(2018年10期)2018-08-04
高中生学习·高三版(2016年9期)2016-05-14
