
结合栈式监督AE 与可变加权ELM 的回归预测模型
2022-08-12 02:29张雪英李凤莲陈桂军黄丽霞
计算机工程 2022年8期
闫 静,张雪英,李凤莲,陈桂军,黄丽霞
(太原理工大学信息与计算机学院,太原 030024)
0 概述
回归分析是一种确定两种或两种以上变量间相互依赖的定量关系的统计分析方法,根据已知过程变量与目标变量间的相关性,建立基于历史过程数据的回归预测模型。由于目标变量总是受一个或多个过程变量的影响,且每个过程变量对目标变量的影响不同,因此根据过程变量对目标变量的精准预测可以为过程监控、优化和控制提供重要的实时信息。回归预测模型多数采用不同的非线性结构来提取数据中包含的信息,常用模型包括主成分回归(Principal Component Regression,PCR)[1]、偏最小二乘回归(Partial Least Squares Regression,PLSR)[2]、人工神经网络(Artificial Neural Network,ANN)[3]和支持向量回归(Support Vector Regression,SVR)[4]。但对于大量高维、强相关性及高冗余的数据,这些模型的鲁棒性差、预测性能低,而提取输入数据的有效特征表示是建立回归预测模型的关键步骤。多层深度网络能够提取复杂数据的特征,但由于梯度消失和爆炸问题,深度网络并没有比浅层模型表现得更好,直到文献[5]提出通过无监督的逐层预训练和有监督的微调来学习深度网络模型,使得栈式自编码器(Stacked Auto-Encoder,SAE)成为广泛应用于数据分析[6]、图像处理[7]、语音识别[8]、模式识别[9]等领域的深度学习[10]模型。
深度学习可以通过学习深层非线性网络结构,实现复杂函数逼近,表征输入数据,并利用特征的逐层变换完成最终的预测和识别[11]。文献[12]将卷积神经网络(Convolutional Neural Network,CNN)与极限学习机(Extreme Learning Machine,ELM)相结合,提出CNN2ELM 模型,用于人脸图像的年龄预测,提高了预测鲁棒性。文献[13]将栈式降噪稀疏自编码器(sDSAE)与ELM 相结合,提出sDSAE-ELM 算法,利用sDSAE 产生ELM 的输入权重和隐含层偏置,降低噪声干扰,优化网络结构。文献[14]将SAE 与以小波函数为激活函数的ELM 结合,提出SAEWELM 模型并将其用于工业铝生产过程中的过度热预测,具有良好的鲁棒性和泛化能力。
针对回归预测问题,对SAE 和ELM 两部分进行改进再级联是改善回归预测效果的有效方法。文献[13-15]采用SAE 进行特征降维或特征提取,取得了较好的效果,但它们未考虑到数据间的相关性,不能反映出目标变量与其他过程变量之间的关系。目前,关于结合改进的SAE 和ELM 进行回归预测的研究也取得了一定成果,随机确定输入权值和隐含层偏置虽然能够提升网络速度[16],但不能根据输入数据与输出数据间的相关性大小进行合理赋值。本文构建一种基于栈式监督自编码器(Stack Supervised Auto-Encoder,SSupAE)与可变加权极限学习机(variable weighted Extreme Learning Machine,vwELM)的回归预测模型。利用栈式监督自编码器使SAE 以有监督的方式进行逐层预训练,提取与目标输出变量相关的高级特征,挖掘数据间的深层关联信息。采用可变权值的方式确定ELM 的输入权值和隐含层偏置,以提升算法的鲁棒性和泛化能力。在多个公共数据集及实际工业生产的多晶硅铸锭数据集上进行实验以验证SSupAE-vwELM模型性能。
1 栈式监督自编码器设计
1.1 栈式自编码器
自编码器(Auto-Encoder,AE)包括编码和解码两个过程,编码过程将输入x通过非线性激活函数映射到隐含层,解码过程将隐含层数据h转化为输出值z,再重构输入[17]。AE 网络结构如图1 所示。编码过程、解码过程、损失函数的表达式如式(1)~式(3)所示:


图1 AE 网络结构Fig.1 AE network structure
SAE 是通过多层无监督训练的AE 逐层堆叠而构造的一种深度网络结构,训练过程分为无监督预训练和有监督微调两个阶段[18],如图2 所示。SAE采用无监督的方式逐层预训练来初始化网络参数,在最后一层隐含层后加入BP 回归网络进行回归预测,使用目标变量数据y对权重和偏置进行整体微调,优化网络结构。
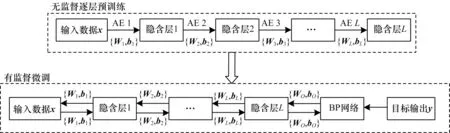
图2 SAE 训练过程Fig.2 SAE training process
1.2 栈式监督自编码器
栈式自编码器的预训练可以逐层学习到输入数据的高级抽象特征,但在实际应用中,SAE 的无监督预处理方式未考虑过程变量与目标输出间的相关性,所学习到的特征可能包含与目标输出无关的信息。针对这一问题,提出一种以有监督方式训练的监督自编码器(Supervised Auto-Encoder,SupAE),即在AE 编码与解码的基础上添加一层回归网络,AE在解码的同时通过回归网络进行回归预测,使得构成栈式监督自编码器(SSupAE)的每层SupAE 都以有监督的方式完成预训练,并使该深层网络在学习重构特征的同时将与目标输出变量相关的信息编码到该网络中,挖掘数据的深层特征。
SupAE 由编码器、解码器和预测目标输出的回归网络三部分组成,网络结构如图3 所示。SupAE的编解码过程与AE 相同,其中回归网络预测目标输出值的计算公式如式(4)所示:

图3 SupAE 结构Fig.3 SupAE structure

其中:本文使用的回归网络为BP 回归网络;Wr和br分别为BP 网络的权值矩阵和偏置向量为对目标变量真实值y的预测值。
在训练过程中,为了能够对解码重构输入与回归预测输出同时优化,使SupAE 获得更好的表示,SupAE的损失函数由重构误差、目标变量的真实值与预测值间的误差两部分组成,通过最小化这两部分的线性组合函数实现对数据的深层挖掘。假设训练集有N个样本{x,y}={(xi,yi)|xi∊,yi∊R,i=1,2,…,N},其中dx表示输入数据的维数,则SupAE 的整体代价函数如下:
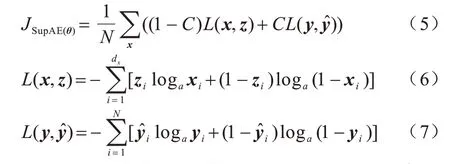
其中:L(x,z)为重构损失函数为目标变量的真实值和预测值间的误差损失函数,本文均使用交叉熵损失函数;C为0~1的常数,用来平衡L(x,z)与间的比例。通过平衡重构损失与回归预测值和真实值间的损失来提取输入数据的潜在特征,在一定程度上相当于一种隐式的数据增强,在代价函数中引入可以将目标变量值编码到隐含层中,同时将无监督学习的AE 转化为有监督学习的AE,使隐含层中包含更多数据的信息,提高模型的泛化能力。
利用反向传播算法结合梯度下降法,更新连接权值W和偏差b,求出使得式(5)达到最小值时的Wij和bi。更新公式具体如下:
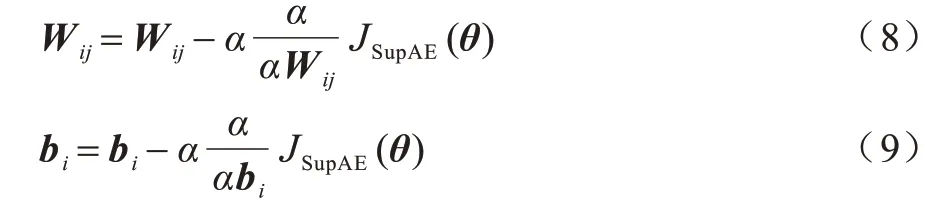
其中:α为学习率。通过这种更新权值的方式,获得最优的W和b,使得SupAE 隐层学习比较好的隐层表达。
SSupAE 是由SupAE 通过逐层堆叠构造的一种深度网络结构,如图4 所示,其输入是由每个样本对应的过程变量与目标变量值组成,在SupAE 进行逐层有监督预训练后,舍弃每层的回归网络和解码器(见图4 中点线矩形框部分),以前一个隐含层的输出作为后一个隐含层的输入,通过最小化联合损失函数(见图4 中点划线部分),并逐层堆叠以提取包含目标变量信息的高级特征。在最后一个隐含层后添加ELM 回归网络,使整个网络再次以有监督的方式进行微调,更新各层的权值和偏置,使该网络达到全局最优。

图4 SSupAE 结构Fig.4 SSupAE structure
2 栈式监督自编码器与可变加权极限学习机
2.1 极限学习机
ELM 是一种单隐含层前馈神经网络[19],ELM 的网络结构如图5 所示。假设训练集有N个样本则ELM网络模型可以表示如下:
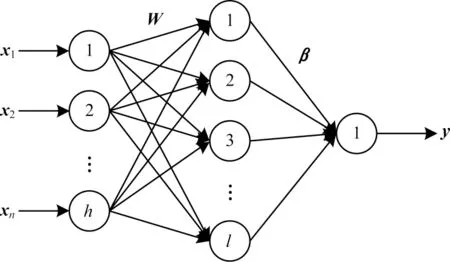
图5 ELM 网络结构Fig.5 ELM network structure

其中:W是输入层到隐含层的权值向量;b为偏置向量;g(·)是激活函数;β是隐含层到输出层的输出权值。ELM 的矩阵表达式如式(11)所示。ELM 网络的训练过程就是求解式(11)的最小二乘解β,如式(12)所示。输出权值矩阵β可由Moore-Penrose 广义逆公式求解得到,如式(13)所示。

其中:H表示隐含层的输出矩阵;Y表示样本目标输出的真实值矩阵;H†是H的广义逆,H†=(HTH)-1HT[20]。
2.2 可变加权极限学习机
ELM 网络随机确定初始输入权值和偏置,能够提高网络的学习速度,但是在隐含层节点个数一定的情况下,预测精度会受随机性影响[21],因此对权值和偏置进行合理赋值能够提升网络的预测性能。本文将输入变量与目标输出间的相关性融入ELM 网络,提出一种根据相关性确定权值与偏置的可变权值极限学习机。
针对回归预测问题,不同的输入变量对目标输出变量的影响不同,对不同变量赋予不同的权值,不仅可以提高ELM 训练的精度,而且可以有效提高模型的鲁棒性。对于有N个样本的训练数据集{x,y}={(xi,yi)|xi∊,yi∊R,i=1,2,…,N},样本中第j(j∊dh)个变量与目标变量值的相关系数计算公式如下:

其中:x(j)为训练集第j个变量的集合集,即x(j)={x1(j),x2(j),…,xN(j)}。协方差和方差的计算公式如下:
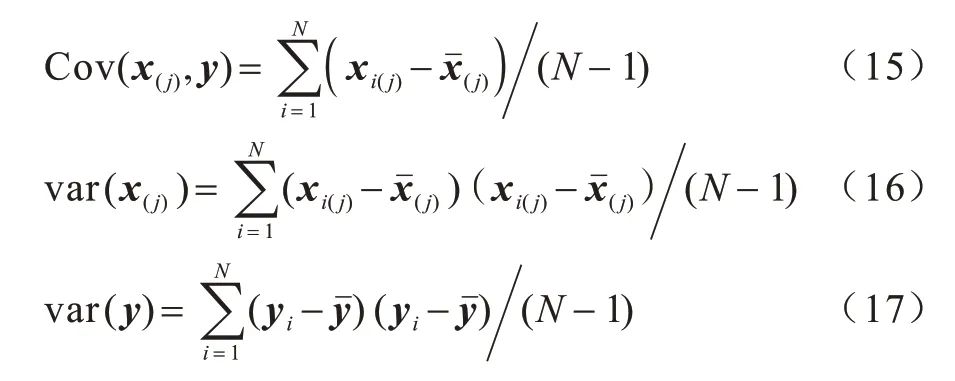

其中:λ(j)表示第j维变量的可变权值。
在对ELM 的输入权值和偏置进行初始化时,用可变权值λ(j)分别对相应的输入变量进行加权,则vwELM 网络模型表示如下:

综上,vwELM 算法的训练过程如下:
1)计算输入层输入变量与目标输出变量的相关系数,根据相关系数求得每个变量的可变权值。
2)确定隐含层神经元个数,对输入层和隐含层之间的连接权重W和偏置b进行加权初始化。
3)选择一个无限可微的函数作为隐含层神经元的激活函数,计算隐含层的输出矩阵H。
4)根据式(11)计算输出层权值β。
2.3 基于SSupAE-vwELM 的回归预测模型
理论上,SSupAE-vwELM 算法能比ELM 算法实现更精准的预测。一方面,利用SSupAE 网络对原始输入数据进行特征提取,所提取的特征包含了目标输出的相关信息。另一方面,vwELM 算法通过相关性分析对ELM 的权值和偏置加权,既克服了ELM因参数随机赋值产生冗余节点[22],又使其包含了目标输出的相关信息,有利于实现更加精准的预测。
SSupAE-vwELM 网络结构如图6 所示,将训练好的n层SupAE 进行堆叠形成SSupAE,以SSupAE的顶层作为vwELM 网络的输入进行回归预测。

图6 SSupAE-vwELM 网络结构Fig.6 SSupAE-vwELM network structure
1)特征提取。首先针对不同特征维数的数据集{xi,yi},将原始数据xi输入到SSupAE网络中,对SSupAE 网络的每个隐含层节点数设置合适的值,并对每层的SupAE 权重和偏置初始化,分别设置学习率、正则化参数和学习率、丢弃率。在训练中引入目标变量值yi使SSupAE 以有监督的方式完成训练,提取输入数据的深层相关特征。
2)回归预测。以SSupAE 所提取的特征作为vwELM 的输入,根据输入变量与目标变量yi值间的相关性计算对应的可变权值,对vwELM 的输入权值进行加权,训练vwELM 网络,得到输出权值。
SSupAE-vwELM网络训练与测试过程如图7所示。

图7 SSupAE-vwELM 网络训练与测试过程Fig.7 Training and testing process of SSupAE-vwELM
3 实验与结果分析
3.1 实验环境与评价指标
应用MATLAB R2014b 进行实验仿真,操作系统为Windows10,处理器为Intel Xeon E3-1535M,内存为32 GB。采用均方根误差(Root Mean Square Error,RMSE)、决定系数(R2)和程序运行时间3 个指标对模型回归性能进行评价,RMSE 和R2的计算公式如式(20)和式(21)所示:

其中:Nt为测试结果个数;yn和分别为真实值和预测值为测试集真实值的平均数。在回归预测中,RMSE 值越小,R²值越接近于1,预测越精确,本文通过RMSE 和R²对模型预测结果进行综合对比,验证模型的预测准确性。
3.2 公共数据集上的实验结果
3.2.1 数据集介绍
为验证本文所提SSupAE-vwELM 模型的有效性,选用10 个样本大小和属性维度不同的公共数据集,具体信息如表1 所示,其中,Abalone 数据集通过物理测量变量预测鲍鱼年龄,Air Quality 数据集是对意大利某严重污染区域的空气质量进行预测,Boston Housing 数据集通过影响房价的变量预测房价,Concrete 数据集通过混凝土成分预测混凝土的抗压强度,Stocks 数据集是预测10 家航天公司的股票价格,Bank 数据集是预测客户选择银行的概率,Computer Activity 数据集是预测电脑CPU 的运行时间,Kinematics 数据集是预测人体的运动数据,Wine Quality 数据集是预测葡萄牙北部葡萄酒的质量,Yacht Hydrodynamics 数据集是对帆船水力性能的预测。为了解决数据特征属性间数值量纲差异导致的计算问题,本文将所有数据归一化为[0,1],并将每个数据集按8∶2 的比例划分训练集和测试集。

表1 公共数据集信息设置Table 1 Setting of public dataset information
3.2.2 参数设置
为分析SSupAE-vwELM 模型中不同网络参数对整体回归预测性能的影响,以Concrete 数据集为例,对比不同网络层数的SSupAE 以及不同隐含层节点数的vwELM 对整体回归预测准确性的影响。SSupAE 的输入层节点数与归一化处理后的输入数据特征数保持一致,设置为8,预训练的batchsize 设置为80,epoch 设置为100;微调的batchsize 设置为8,epoch 设置为1 000。通过SSupAE 网络层数对比实验来确定网络结构,选取RMSE 及R²作为评价指标,将网络层数从3 变化到8,如图8 所示,可以看出5 层网络结构的RMSE 最小,真实值与预测值的拟合度最好,其中每层的隐含层节点数通过试错法确定,分别为40、30、20、10、5。
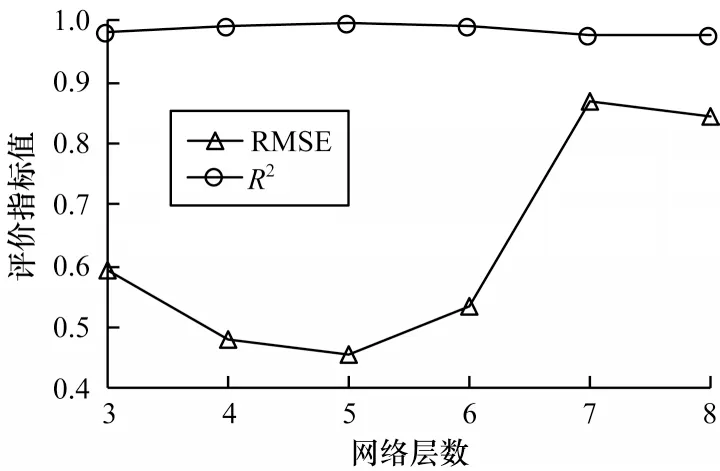
图8 不同网络层数的SSupAE 回归预测性能Fig.8 Regression prediction performance of SSupAE at different number of network layers
通过vwELM 网络隐含层节点数的对比实验确定隐含层节点数,同样选取RMSE 及R²作为评价指标,如图9 所示,将隐含层节点数从1 变化到50,可以看出隐含层节点数设置为35 时RMSE 最小,真实值与预测值的拟合度最好。

图9 不同隐含层节点数的vwELM 回归预测性能Fig.9 Regression prediction performance of vwELM at different number of hidden layer nodes
3.2.3 结果分析
为验证SSupAE-vwELM 模型的回归预测性能,将ELM、SAE-ELM、SAE-vwELM、SSupAE-ELM 及SSupAE-vwELM 模型的实验结果在10 个公共数据集上进行对比,其中,ELM 为未进行特征提取的回归预测模型,SAE-ELM 为使用SAE 进行特征提取后使用ELM进行回归预测的基础模型,SAE-vwELM为在SAEELM 模型基础上改进ELM 后的模型,SSupAE-ELM 为在SAE-ELM 基础上改进SAE 后的模型。采用五折交叉方式验证模型的预测效果,最终对5 次预测结果取平均值。实验结果如表2所示,其中最优结果加粗表示。

表2 公共数据集上的回归预测结果对比Table 2 Comparison of regression prediction results on public dataset
从表2 可知,在10 个公共数据集上SSupAEvwELM 模型相比其他模型的回归预测性能都有所提升。SSupAE-vwELM 模型的运行时间长于ELM及SAE-ELM 模型的主要原因在于SSupAE 的深层网络不仅能够重构原始数据,而且还将目标输出变量的信息编码到网络中,随着网络层数的增加,其深层非线性网络将原始数据一层一层抽象,所提取的特征更能描述对象本质且提高预测精度,并且通过结合vwELM 回归网络进一步优化了网络结构,提高了网络的鲁棒性和回归预测能力。由此可见,SSupAE-vwELM 模型运行时间长说明其相比于ELM 及SAE-ELM 模型提取的特征更加符合样本本质,鲁棒性更好。以Concrete 数据集为例,测试集上部分样本的预测值与真实值的对比结果如图10 所示,可以看出除第3 个和第9 个测试样本外,其余样本的真实值与预测值间的误差很小,可见本文模型的回归预测性能较好。
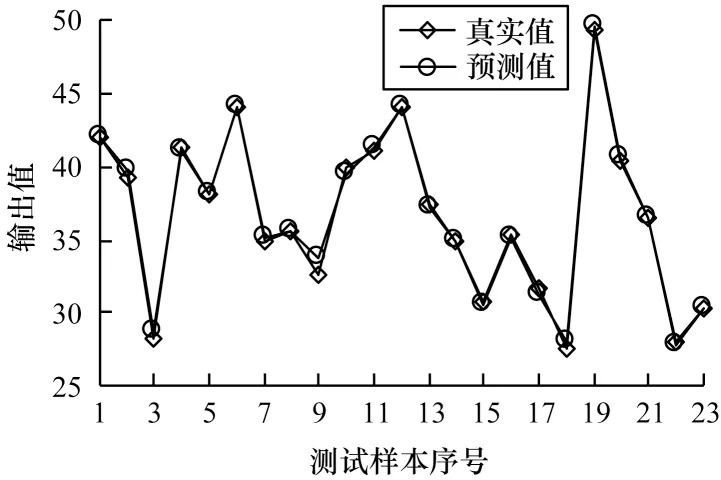
图10 测试集上的预测值与真实值的对比Fig.10 Comparison between predicted values and actual values on the test set
3.3 多晶硅铸锭数据集上的实验结果
为验证SSupAE-vwELM 模型的实用性,将其在工业多晶硅铸锭数据集上进行实验。多晶硅作为最主要的光伏产业材料之一,配料数据对多晶硅铸锭的电学性能和生产成本有着重要的影响,但由于每次生产所用配料的批次或重量的差异,会对质量产生影响,因此准确的配料分析和预测模型的建立至关重要[23]。少子寿命值即硅锭中少数载流子存活时间,通常被用作评价多晶硅铸锭的质量,根据配料对少子寿命值的准确预测可以有效地指导实际生产。工业上通常用工艺试验来预测产品质量,实现的成本高且难度大。因此,采用深度学习方法对多晶硅铸锭过程中的少子寿命值进行精准预测对提高产品质量具有重要意义。
本文使用的多晶硅铸锭数据集来源于山西某新能源技术有限公司的实际生产数据,该数据集包括G6 和G7 两种产品,每种产品包含非免洗原生多晶块料、碎多晶铺底、碎片、中料、提纯锭芯自产、提纯锭芯外购、循环料等7 个配料类别,通过属性值评价各种配料的质量,最终所需预测的目标变量为多晶硅的少子寿命值。本文所用到的数据集中G6 产品有500 个样本,G7 产品有391 个样本。表3 为部分G6 数据的示例。

表3 部分G6 数据示例Table 3 Partial G6 data examples
将多晶硅配料数据按8∶2 分为训练集与测试集,同样将ELM、SAE-ELM、SAE-vwELM、SSupAE-ELM及SSupAE-vwELM 模型的实验结果在G6 和G7 产品数据集上进行对比,实验结果如表4 所示。

表4 多晶硅铸锭数据集上的回归预测结果对比Table 4 Comparison of regression prediction results on polycrystalline silicon ingot dataset
从表4 可以看出,与ELM、SAE-ELM 模型相比,SSupAE-vwELM 模型虽然运行时间增加,但回归性能在多晶硅铸锭的G6 产品数据集中RMSE 降低了0.056 7、0.011 2,R²提升了0.489 3、0.290 3;在G7 产品数据集中RMSE 降低了0.010 8、0.006 3,R²提升了0.297 2、0.190 6。比较表2 和表4 中5 种模型的预测结果,在多晶硅铸锭数据集上的回归预测结果整体比公共数据集差,主要原因为在实际铸锭生产过程中,记录的不规范和缺失,导致数据中出现异常数据和缺失数据,且每次生产所用的配料的批次或成分的差异,使用同样质量的配料会出现不同少子寿命值的情况,导致最终的预测值与真实值的决定系数较低,但是表2 和表4 中SSupAE-vwELM 模型的预测结果优于其他模型结果的趋势是一致的。
4 结束语
为了学习输入数据的显著表征,实现对输出变量的精准预测,本文提出基于SSupAE-vwELM 的回归预测模型。利用SSupAE 提取与目标输出变量相关的高级特征,将所提取的特征作为vwELM 的输入数据,并根据原始数据的特征表示与输出数据间的相关性大小对ELM 的权值和偏置进行加权,解决了回归预测任务中目标特征提取不准确、预测精度低等问题。在多个公共数据集及实际工业生产的多晶硅铸锭数据集上的实验结果表明,与ELM及SAE-ELM模型相比,SSupAEvwELM 模型具有较强的鲁棒性和泛化性能。由于在实验过程中发现SSupAE 网络隐含层层数、节点数以及vwELM 网络隐含层节点数的设置对实验结果影响较大,因此后续将继续研究如何合理准确地设置网络参数,进一步提升SSupAE-vwELM 模型的回归性能,使其适用于实际工业生产。
猜你喜欢
汽车实用技术(2022年15期)2022-08-19
成都信息工程大学学报(2022年3期)2022-07-21
中国信息化(2022年5期)2022-06-13
邮电设计技术(2021年2期)2021-03-13
西安邮电大学学报(2020年1期)2020-12-17
计算机系统应用(2019年9期)2019-09-24
计算机与数字工程(2018年5期)2018-05-29
计算机测量与控制(2018年3期)2018-03-27
电子制作(2017年13期)2017-12-15
北京航空航天大学学报(2016年6期)2016-11-16
