
玉米大豆生长中后期遥感辨识的指示性特征研究
2022-08-11 05:45沈宇李强子杜鑫王红岩张源
遥感学报 2022年7期
沈宇,李强子,杜鑫,王红岩,张源
1.中国科学院空天信息创新研究院 遥感卫星应用国家工程实验室,北京 100101;2.中国科学院大学 资源与环境学院,北京 100049
1 引 言
遥感技术在农业领域方面最先投入应用并获得显著收益,它具有信息量大、快速、覆盖面积广的优势,是当前条件下及时准确监测粮食种植面积的最佳手段(贾坤等,2011;朱秀芳等,2007)。作物遥感分类与识别是监测农作物遥感面积、长势、产量及其他参数的基础。充分利用当前条件下的数据条件和特征信息是提高遥感农作物识别精度的主要策略,但是农作物遥感识别与面积估算的精度仍然有很大的提升空间(Jia 等,2012;任建强等,2015)。
玉米和大豆是两种主要的粮食作物,及时、有效地大面积监测两者的种植面积是进行产量精确预测和稳定市场价格的基础。目前,在遥感领域玉米和大豆的区分研究主要包含两个方面。(1)利用多时相影像构建时间序列光谱特征,通过特征的差异选择最优的区分时段或关键生育期对两者进行区分(封志明等,2014;李鑫川等,2013;刘佳 等,2015;潘耀忠 等,2011),(2)研究单波段光谱特征(如短波红外特征)对玉米和大豆区分的潜力或者多种植被指数特征综合提高玉米和大豆的识别精度(Dong 等,2016;李鑫川等,2013)。但是,这两个方面均有一些不足之处。首先,基于时间序列特征的方法至少需要获取一景生长后期的影像,推迟了玉米和大豆种植面积和分布信息获取的时间,无法满足当前实时和连续监测的需求。其次,玉米和大豆区分的潜在识别特征的研究常常只考虑了植被指数特征以及单波段光谱特征等方面(黄健熙等,2017;刘佳等,2016;王利民等,2018),很少涉及纹理特征以及其他特征参数,这不利于充分利用多源特征综合提高作物识别精度。最后,玉米和大豆的区分研究得到有效的遥感识别特征往往局限于单个实验区或者局部区域,在其他区域的适用性不得而知且不同实验区的最佳识别特征集也有不同,这不利于进行遥感作物面积监测的产业化进程。因此,对玉米和大豆生长中期的种植面积和分布的监测是有必要和有需求的,且综合不同实验区的多源特征信息得到玉米大豆区分的稳定的、固定的遥感识别特征集是有意义的。
有研究表明,利用特征优选的方法综合农作物植被指数特征和纹理特征,可以大幅提升作物识别与分类的精度(孙宁等,2010;王娜等,2017;王文静等,2017)。分类方法对玉米和大豆的识别也有重要的影响。遥感领域内常用的分类方法如最大似然法(MLC)(徐新刚 等,2008)、支持向量机(SVM)(刘庆生等,2014)、决策树(崔璐等,2019)等在进行玉米和大豆的分类问题中取得的分类精度并不理想。这主要是由于选择的分类器难以获取有效的分类特征,或者分类器对分类特征不敏感。随机森林分类算法是一种可以减少样本异常和分类误差的机器学习算法,它具有抗噪性能强,预测准确率高等优势,且不容易出现过拟合等优势(Wang 等,2017a)。刘毅等(2012)也充分比较了多种分类方法,发现随机森林是在作物识别与面积提取方面能取得比其他方法更优的结果,充分证明了该方法的有效性和对分类特征的敏感性。
本文选择玉米和大豆的生长发育中后期为主要的识别时相,以GF-1 影像为数据源,计算多种类型植被指数特征和纹理特征,利用特征优选方法分析多种遥感识别特征对玉米和大豆区分的敏感性,并结合随机森林分类方法在两个典型的种植区进行分类实验,本文研究目标是找到大豆和玉米生长发育中后期遥感区分的有效特征集,提高两者在该时期的分类识别精度。具体包括3个子目标:(1)筛选对玉米和大豆遥感区分具有积极意义的重要特征;(2)优选具有最大可能实现玉米和大豆遥感区分的特征子集;(3)优选具有不同区域适应性的玉米和大豆的指示性遥感识别特征,为大范围遥感应用推广提供参考。
2 研究区及数据
2.1 研究区概况
本文选取安徽省泗县和黑龙江省克东县两个典型的玉米和大豆种植区为研究区(图1)。泗县地处淮北平原东部(33°16′N—33°46′N,117°40′E—118°10′E),属暖温带半温润季风气候,四季分明,光照充足,雨量适中,雨热同期,主要种植夏粮作物玉米和大豆等。克东县位于黑龙江省北部(47°43′N—48°18′N,126°01′E—126°41′E),为中温带典型大陆性季风气候,冬季漫长、干燥、严寒;夏季温和多雨。夏粮作物主要有大豆、玉米和水稻(水稻有小部分)。两个研究区作物的生育期大致相同,黑龙江克东县的玉米为单季夏玉米,播种时间为6月初,收获时间为9月底,安徽省泗县地区的玉米为春玉米,5月中下旬播种,9月中下旬收获,两地的大豆种植时间和收割时间相差不大。并且两者的光谱信息在8月份之后变化不大且较接近(大豆处于结痂期、玉米处于开花期),利用遥感数据的原始波段光谱信息难以进行区分,且两地都有混种现象,增大了区分的难度。

图1 研究区以及采样地块信息Fig.1 Study area and plot information of samples
黑龙江地区的实际野外采样时间为是2017年8月17日,安徽省泗县地区的野外调查时间是2017年8月1日。实际地面调查主要采用在研究区内均匀布置样方的方式进行,泗县地区共布设了25 个采样区,克东县布置了20 个采样区,每个采样区大小平均为500 m×500 m,在采样区内主要记录各种地表类型的采样点,并结合遥感影像和Google Earth 参考影像勾绘对应的地块,调查记录的数据主要有作物类型、作物种植面积、地块经纬度以及实地拍摄的照片。通过汇总发现,泗县地表类型主要有玉米、大豆、林地、草地、城区、裸地以及未种植地等;克东地区主要地表类型为玉米、大豆、林地、草地、蔬菜种植地、城区以及少量水稻和其他地类。
2.2 实验区数据
2.2.1 遥感数据及预处理
玉米和大豆生长中后期的区分是该研究的目标,所以该文选取了覆盖玉米和大豆主要种植区的两景GF-1 16 m 宽幅影像,影像时相的选取依据是两地作物的物候信息表(表1),其中7月底至8月中下旬为大豆和玉米生长发育的中后期。黑龙江克东县地区的影像时相为2017年8月27日,安徽省泗县的影像为2017年8月17日,两幅影像均全覆盖研究区,且云量较少。

表1 实验区玉米和大豆的物候信息以及数据时相Table 1 Phenology information and data phase of corn and soybean in the experimental area
在分类实验过程中需要计算遥感影像的植被指数以及纹理特征等信息,因此需要进行遥感数据的预处理,其中关键步骤有:正射纠正、辐射定标、基于FLAASH 模型的大气纠正、影像裁剪等。其中正射纠正是基于ENVI 5.3 自带的DEM 数据进行,辐射定标的绝对定标系数来自于中国资源卫星网站2017年发布的数据。
2.2.2 辅助数据
该研究用到的辅助数据主要有黑龙江克东县和安徽泗县的矢量数据,黑龙江地区Google Earth 2017年8月18日的0.8 m 参考影像一幅,安徽泗县2017年9月3日0.8 m 参考影像一幅(两幅参考影像主要是为监督分类时样本选择的时候结合野外调查数据作参考,对选择的地块边界作进一步修正),同时还有两地区主要作物玉米、大豆的物候信息等。
3 研究方法
该研究旨在建立玉米和大豆生长季中期或后期的遥感识别方法,以更早准确获取其种植面积信息。研究设计了两种影像纹理特征算法,一为常用的基于灰度共生矩阵GLCM(Gray-Level Cooccurrence Matrix)的算法,另一种为改进型局部二值图模式ILBP (Improved LBP) 算法,其中ILBP 纹理和其他的局部二值图模式均对条带型纹理特征(如玉米制种田)(张超等,2017)具有较好的表征。在此基础上,结合随机森林分类方法,优选玉米和大豆遥感识别的最佳影像特征集合,优选方法采用基于卡方检验的特征优选。最后通过分析比较两个实验区最佳影像特征集合的差异和共同点,找到对玉米和大豆中后期遥感识别的指示性特征集,并分类实验与两个地区的最优分类结果做验证,验证指示性特征集的有效性和稳定性。图2为该研究的总体技术流程。

图2 总体技术流程Fig.2 Overall technical process
3.1 玉米和大豆遥感识别的影像分类特征
该研究以GF-1 的4 个波段的反射率作为基本的影像分类特征,同时计算了10 种植被指数和2种不同的影像纹理特征。
3.1.1 植被指数计算
该研究共选取了10 种常见且广泛应用的植被指数(表2),它们对作物识别有很大的潜力和贡献(田庆久和闵祥军,1998)。其中有些植被指数的参数是根据地面地物的覆盖度情况而定(吴朝阳和牛铮,2008)(表2)。表中“NIR”,“R”,“G”,“B”分别指代的是GF-1 在近红外、红、蓝和绿波段的反射率,“SR”和“VR”分别指代的是土壤和植被在红波段的反射率,“VNIR”指植被在近红外波段植被的反射率。

表2 植被指数计算方法信息Table 2 Vegetation index calculation method information
3.1.2 纹理特征计算
本文计算得到GF-1 影像的两种纹理特征灰度共生矩阵(GLCM) 纹理特征(Haralick,1982)和改进型局部二值图模式(ILBP)(Ojala 等,2001),它们在作物遥感分类与制图领域得到了较好的应用,并能够在一定程度上提升作物识别的精度(宋翠玉等,2011;郑淑丹等,2014)。
3.2 特征优选方法
该研究首先进行玉米和大豆遥感识别特征重要性的评估,在此基础上通过分类实验确定最佳特征子集。最后通过分析不同实验区最佳特征子集的共性和差异以及分类精度,确定玉米和大豆遥感识别的指示性特征子集。
特征变量重要性和特征选择在农作物遥感分类与识别中有着重要的地位(宋冬梅等,2015)。特征选择不仅仅是大幅减少数据维度的一种方法(刘笑笑等,2017),而且还能够帮助我们明确各种遥感识别特征与分类模型之间的敏感性并去除对分类体系贡献较小的特征集,进而提高分类效率和精度。特征选择是利用一系列的原理和规则,得到特征重要程度的相对关系,自动选择出对分类过程最重要的特征子集的过程。过滤式、封装式和嵌入式是特征选择的3 种典型模型(Dash 和Liu,1997)。过滤式特征选择模型相对于其他两种模型而言对遥感分类与识别有更广泛的应用,因为它直接明确了每个遥感识别特征与标签的相关性并以相对分值的形式进行表征,计算量小且效果明显(Hall和Smith,1999)。
该研究采用一种基于过滤式模型的特征选择方法,基于卡方检验的特征选择方法。卡方检验是一种用途很广的计数资料的假设检验方法,它属于非参数检验的范畴,可以基于数据出现频率计算自变量对因变量的相关性。在遥感分类特征选择过程中,可以用于计算某个影像特征对目标类别的重要性得分,得分越高表明该影像特征对分类的贡献越大。

式中,A是实际值,T为理论值,“ϰ2”用于衡量实际值与理论值的差异程度(核心思想)。
该研究首先利用基于卡方检验的SelectKBest方法从构建的光谱特征、植被指数以及纹理特征的特征空间中优选出K个特征(K值可以人为设定),并用于随机森林分类,通过分析特征个数(K)与分类精度的关系可以得到不同实验区的最佳遥感特征子集。然后,基于不同实验区区分玉米和大豆的最佳特征子集,分析对玉米和大豆区分贡献较大的特征类型及其差异,并结合该两种作物中后期的生理生化参数的差异,指出对玉米和大豆生育中后期的遥感指示性特征集。
3.3 遥感分类方法
该研究选取随机森林分类算法(RF)进行玉米和大豆的区分。随机森林分类算法是一种以结合弱分类器形成强分类器为主要思想的分类方法,具有抗噪能力强、受人为因素影响小以及较高的分类能力等优势,相对于其他分类器,如SVM 而言,设置的参数更少并且更容易。随机森林分类算法的基本思想是通过随机地有放回地抽取训练样本的技术,即bootstrap sample 重采样技术,不断地生成训练样本和测试样本,将训练样本输入到每棵分类树(弱分类器)中进行分类形成随机森林,最终对若干个弱分类器的分类结果进行投票选择,从而组成一个强分类器对影像进行分类和预测。
3.4 精度评价方法
该研究利用基于实际地面样本数据的混淆矩阵来计算玉米和大豆分类的精度。一方面使用kappa 系数和总体分类精度用来评价分类的整体精度,另一方面使用条件kappa 系数(Song 等,2012)来评价单类地物的分类精度。总体精度能够对玉米和大豆区分的整体效果进行评价,单类分类精度能够对衡量分类器对不同特征的敏感性以及间接的从错分和漏分角度评价分类效果。
3.5 实验设置
在两个实验区,该研究通过遥感识别特征集优选和随机森林算法,可以分别得到一组优选的分类特征集(A5 和B5)以及分类结果,然后设置了对照实验(A1、A2、A3 和A4),分析比较各种玉米大豆生长中期的特征集的遥感识别能力,当优选的特征子集的分类结果优于常规特征组合分类结果且分类精度达到一定水平,才能确认其有效可用(此时的优选特征子集即该实验区区分两者的最佳特征集),这是进行指示性特征集验证的基础。然后,设置指示性特征集验证实验(A6 和B6),通过与最佳特征集(A5 和B5)的分类精度与效果作对比,验证指示性特征集的有效性和稳定性。各个组别的特征组合信息如表3(A1—A6表示泗县各个实验组,B1—B6 表示克东县各个实验组)。

表3 实验方案特征组合信息Table 3 The information of feature combinations in different experimental groups
4 结果比较与分析
4.1 玉米和大豆遥感识别特征优选结果
该研究首先利用基于卡方检验的特征优选方法分别计算两个实验区内的50 个特征的重要性得分(图3、图4 中展示了前20 个特征的重要性得分)。可以发现不同的影像特征对于玉米和大豆的区分能力差异较大,如植被指数中RVI、DVI、TVI 等特征重要性得分相对较高,而红波段反射率(R)及其相关纹理特征(B3_mean,B3_Homogeneity,B3_Dissimiliarity)除B3_Entropy外均不太理想。

图3 泗县各个特征的重要性得分Fig.3 The importance score of each feature of Si County
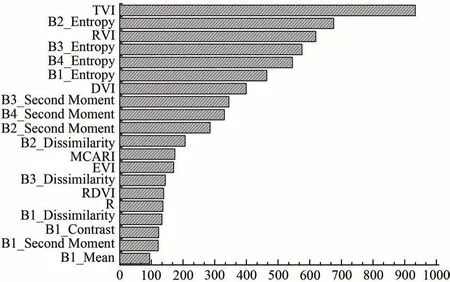
图4 克东县各个特征的重要性得分Fig.4 The importance score of each feature of Kedong County
该研究通过逐渐增加重要性较高的影像特征,分析影像特征数量K与分类精度的关系(图5、图6),可以发现:(1)随着优选特征的个数增加,玉米和大豆的整体辨识精度首先快速增加,并稳定在较高的水平(0.97),随着影像特征数量的继续增加,精度开始出现下降,并呈现波动的状态(0.93 左右),Kappa 系数的情形与此类似;(2)两个实验区的总体分类精度的最高水平分别出现在特征个数为17个(泗县)和15个(克东县);(3)分析能够产出最高精度的特征组合(表5),发现主要由植被指数(6 个)和GLCM 纹理特征(熵和二阶矩)为主,植被指数的特征重要性要高于纹理特征,ILBP纹理特征表现一般。
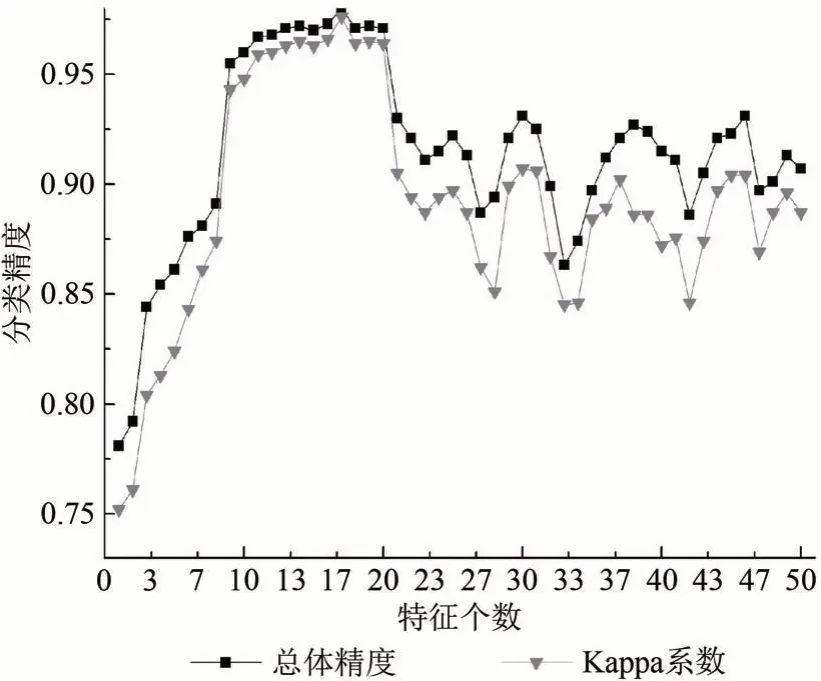
图5 泗县特征个数与分类精度的关系Fig.5 Relationship between the number of features and classification accuracy of Si County

图6 克东特征个数与分类精度的关系Fig.6 Relationship between the number of features and classification accuracy of Kedong County
比较两个研究区优选特征子集中植被指数发现具有一致性(表4),植被指数中的RVI,DVI,TVI,MCARI等均对分类精度有较大贡献。表明这些指数能够表征玉米和大豆两种作物的光谱差异。研究表明,生长季中后期玉米和大豆的叶面积指数有明显差异(大豆高于玉米)(宋开山等,2005),并且由于玉米对阳光的竞争力大于大豆,导致大豆在该时期叶绿素含量迅速降低,两者的生物量也会产生明显差别(韦柳佳等,2013)。两个实验区的玉米大豆种植情况不同,这是各个特征之间重要性得分高低的根本原因。克东地区的玉米和大豆多为大田种植,田块内大多为纯像元,植被指数与其他参数(如叶面积指数等)的相关性几乎不会受到混合像元的影响。而TVI与叶面积指数的相关性较RVI 和NDVI 更好(汤旭光 等,2010),所以对于克东县地区的玉米和大豆的区分而言,TVI的特征得分更高。泗县地区由于存在较多的混种和间种现象,且种植密度较大,植被指数与叶面积指数的相关性受到混合像元和高覆盖度植被指数敏感性饱和的影响,仅仅使用表征叶面积指数的植被指数进行两者的区分是不充分和不准确的。所以对于泗县地区而言,表征作物生物量和叶绿素含量的植被指数在该时期对两者的区分有更大的能力。植被指数RVI和DVI与作物的生物量和叶绿素含量的相关性比其他类型的植被指数更高(李卫国等,2017),所以泗县地区该两者特征的重要性得分更高。其次,植被指数中MCARI 与叶绿素的浓度相关性较好且克服了高覆盖度植被敏感性饱和的问题(吴朝阳和牛铮,2008),作为两者生长中期区分的补充数据,一定程度上能够增强两者辨识的精度。

表4 两个实验区的优选特征子集信息Table 4 The selected features of two different experimental areas
比较两个研究区优选特征子集中纹理特征发现具有相似性(表4),4个波段的二阶矩和熵在两个实验区的分类中表现突出,但略有差异。相异性和同质性也有贡献。有研究指出灰度共生矩阵中的信息熵和二阶矩对城镇用地和局部光谱反射率较一致的地物如水体等区分较好(彭光雄等,2007),而大豆玉米生育中期都处于生长茂盛期,大部分大块田中的作物长势较均匀,所以这两种纹理特征能够有效提高两者在中期的整体区分效果,特征得分相对于其他纹理而言较高。
4.2 玉米和大豆遥感识别效果
利用优选的玉米和大豆生长季中期遥感区分的最佳特征集,分别在两个实验区进行分类实验,并使用同样的遥感识别特征,即:TVI+RVI+DVI+MCARI+4 波段的熵特征+4 波段的二阶矩特征。通过分析各个实验组(见2.4 节)的玉米和大豆整体识别精度以及单类分类精度(图8、图9)。得到以下结果。
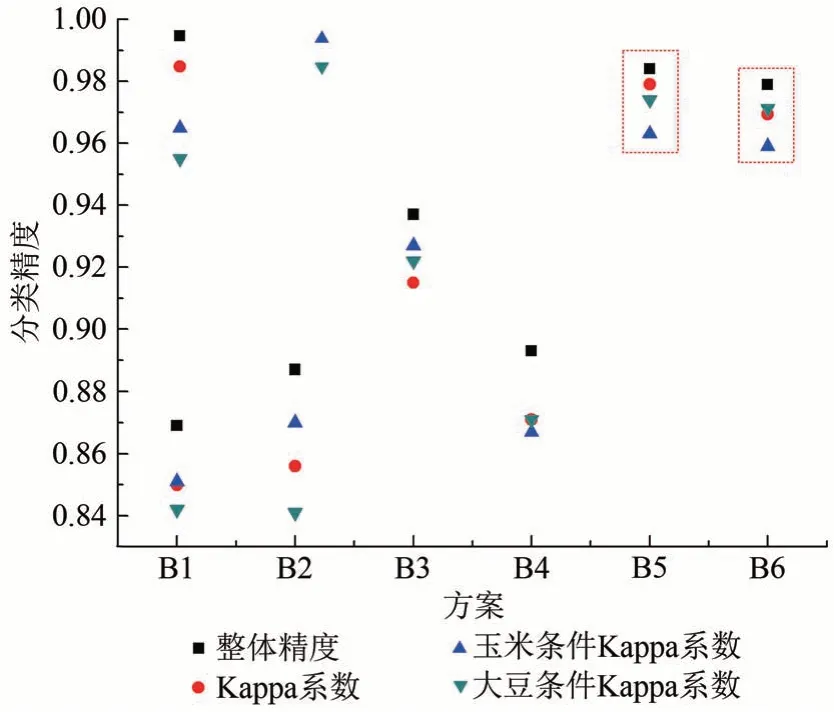
图8 泗县各实验组方案分类精度Fig.8 Classification accuracy of each experimental group

图9 泗县各实验组分类效果Fig.9 Mapping performance of each experimental group in Si County
(1)通过特征优选出的最佳特征子集(A5、B5)与随机森林分类器结合,能够得到比常规特征组合更高的分类精度。这主要是因为A5和B5综合了多种不同的遥感识别特征,且对多源特征进行了优选和剔除。
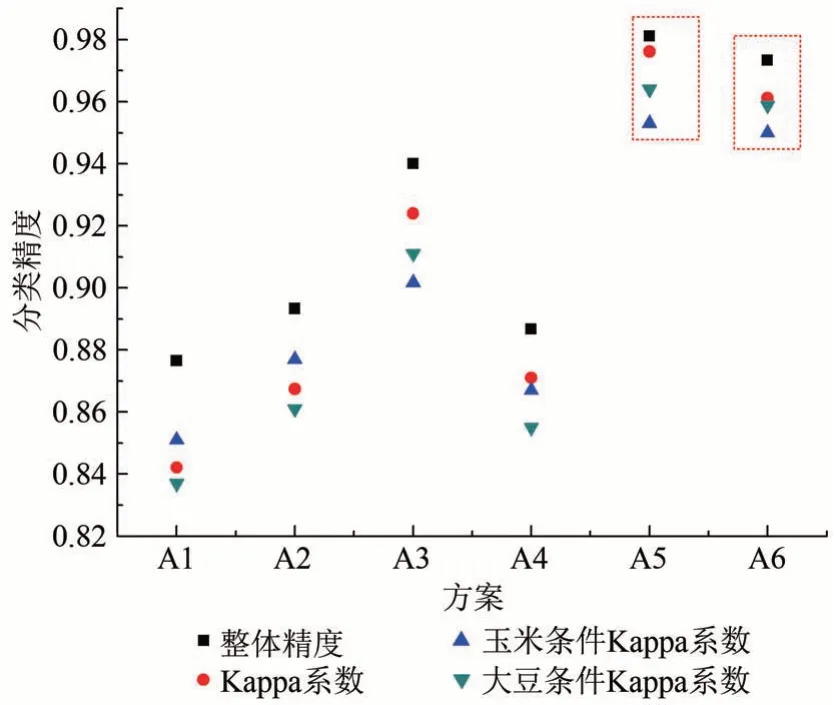
图7 泗县各实验组方案分类精度Fig.7 Classification accuracy of each experimental group
(2)简单的将纹理、光谱和植被指数特征融合(A4、B4)用于分类,精度提升不明显;多种特征之间的简单叠加如果不经过特征的有效选取,只会增加特征维数和导致数据冗余,最终对分类精度的提高贡献较小。
(3)植被指数的参与(A3、B3)相对于纹理特征(A2、B2)对分类精度的提升更大;因为纹理特征是基于光谱反射率计算的二级特征(Hasituya 等,2016),它对分类精度的提升作用较小。
(4)利用玉米和大豆中后期的指示特征集进行分类(A6、B6),发现在两个实验区的分类精度均接近最优分类精度,说明了该特征集具有效性,且能够适应不同实验区的种植制度差异,表现出较强的稳定性。
4.3 玉米和大豆遥感识别效果
图9、图10 为依据表3 分组信息进行随机森林分类的玉米大豆制图结果。通过局部分析发现以下结果。

图10 克东县各实验组分类效果Fig.10 Mapping performance of each experimental group in Kedong County
(1)植被指数的参与,在一定程度上能够提高玉米和大豆种植地块的完整性,并能改善制图精度和效果(图8 A3 和A1;图9 B3 和B1)。A3 和B3 中玉米和大豆的斑块更加完整和清晰,类别间的边界更加清晰明确。
(2)纹理特征的参与,可以有效地改善错分和“椒盐”现象。A2和B2中的孤立点现象明显得到了改善,说明纹理特征能使错分误差降低,并改善“椒盐”现象。
(3)基于最佳特征子集的随机森林分类制图效果最好(A5 和B5)。错分和漏分现象得到了极大改善,同类地物的田块准确完整地分成了一类,不同地类之间的边界清晰且几乎没有“椒盐”现象,说明分类器对优选出的特征子集有较好敏感性。
(4)基于该研究优选的玉米和大豆生长中后期指示性特征子集,可以获得几乎最佳的制图效果(A6 和B6),与最佳特征集(A5 和B5)得到的玉米和大豆制图结果几乎一致。
5 结 论
该研究选取了玉米和大豆典型的种植区域安徽泗县以及黑龙江克东县为研究区,首先结合不同的分类特征设置4个实验对照组,同时使用特征优选对多源遥感特征进行选择并结合随机森林算法进行分类,通过分析比较优选特征子集和各个实验对照组的分类精度验证优选子集对玉米大豆区分的有效性,以及对比不同实验区的优选特征子集的异同点,提出对玉米和大豆生长季中后期有指示性的特征集,并设计了分类实验,验证该特征集的有效性和稳定性。该研究旨在找到对玉米大豆作物生育中后期稳定的指示性识别特征集,为玉米和大豆中后期面积监测提供技术支撑。通过实验得出了以下3方面的结论。
(1)在玉米和大豆生长季中后期,可以找到具有高效辨识两种作物的遥感特征。植被指数RVI、DVI、TVI 和MCARI 能一定程度上表征玉米大豆在该阶段的冠层生理参数或光谱的差异(生物量、LAI 和叶绿素含量等等),从而提高两种作物的区分能力;纹理特征二阶矩和熵能够增加大块田中作物的辨识能力,提升两者的整体识别精度,实现玉米和大豆的中期面积监测估算。
(2)从多种类别的遥感影像特征中可以优选出最佳分类特征子集,得到玉米和大豆的最优识别效果,比仅仅使用原始波段特征分类的精度提升了近10 个百分点,总体分类精度能够平均达到97%,Kappa 系数能达到0.96,玉米和大豆的单类分类精度平均超过95%。
(3)该研究通过实验分析,考虑不同特征的物理意义和贡献,提炼出的玉米和大豆遥感区分的指示性特征集,可以得到几乎与优选出的最佳特征子集同样的分类精度和制图效果,且具有稳定性和有效性,较最佳特征集更具推广使用意义。指示性特征集包括了植被指数中的RVI,DVI,TVI,MCARI和纹理特征中的二阶矩和熵。
该研究存在的局限性在于,它是基于16 m 分辨率的GF-1 影像得出的,对于空间分辨率更高、光谱波段更丰富的遥感影像,如哨兵2 号10 m 数据或GF-2 4 m 等,需要进一步探究是否具有获得更好识别效果的指示性特征集。其次,本研究同时选择春玉米和夏玉米作为研究对象,在选择影像时间上应尽量选择两种玉米同一生育期内的影像,减少对结果的影响。同时应当指出,野外调查的时间应与遥感数据采集时相一致,减少在样本选择过程中由于时间差异较大光谱变化较快导致的样本类型不确定问题,并影响最终结果。
今后的工作着重建议聚焦在:(1)其他类型的作物遥感特征的加入,如微波后向散射特征,作物的生化特征等;(2)针对遥感数据不同空间分辨率问题,进一步探讨不同尺度对作物组合最佳分类特征的影响;(3)进行作物中前期的实验,进一步指出不同生育期的指示性特征集。
猜你喜欢
保健与生活(2019年7期)2019-07-31
小资CHIC!ELEGANCE(2018年33期)2018-11-08
作文评点报·低幼版(2018年17期)2018-07-12
Coco薇(2017年8期)2017-08-03
第二课堂(初中版)(2017年2期)2017-02-08
计算机时代(2016年12期)2017-01-14
Coco薇(2015年5期)2016-03-29
