
基于农业大数据应用的农产品质量监测研究
2022-08-09 03:27冯思辉魏霖静刘志祖
生产力研究 2022年7期
冯思辉,魏霖静,刘志祖
(1.甘肃农业大学 信息科学技术学院,甘肃 兰州 730000;2.临夏州农业技术推广服务中心,甘肃 临夏 731100)
一、引言
农业大数据是一种基于农业与大数据结合的智慧应用系统,也是未来大数据应用的一种趋势,对于推动农业生产发展,具有重要意义[1-3]。农业大数据可以结合农业生产的特点,比如周期性、季节性等,进行相关的搜索、存储、计算以及分析[4]。随着社会的发展,农业大数据应用的形式也日渐多样。其中,云计算、物联网等都为其提供了足够的技术支持,具有较强的价值[5]。
本文查阅与农业大数据相关的文献资料,对其观点进行总结,对于本文的研究,具有较强的现实意义。在现有的研究当中,内容十分丰富,具体如下:
1.农业大数据应用方面:何岩巍和李慧强(2021)[6]指出农业大数据的发展,需要大量的科研人员,投入到数据采集、数据优化当中,避免数据异构所造成的影响。谢楚鹏和温孚江(2015)[7]从协同机制的角度出发,对农业大数据的科学性进行了论证,认为农业大数据的应用需要建立多元的规范平台,形成针对性的动态监控,监控的内容包括:农业生产、农业投入、农业产出等。李道亮等指出,农业大数据未来需要与人工智能相结合,保证数据获取的敏捷性。李秀峰等认为农业大数据需要充分的表达农业生产的信息,建立数据综合查询系统。Tumpe 等(2021)[8]认为农业发展离不开大数据的应用,其结合天气预报等方面,给出了模型分析。Ji Luo 等(2021)[9]通过对季节性条件,基于云计算工具,分析了农业大数据对农业生产质量的影响。认为在农产管理与决策当中,通过大数据,可以提高生产劳作的效率和质量。
2.农业大数据平台方面:王一欢指出,可以利用大数据,构建专门的信息平台,采集和上传到云端的农场土壤、气象、生产等数据管理农场,借助于大数据平台和移动设备,提高了管理的精确性。李瑾等结合我国农业发展的现状,设计了通用型的农业大数据平台框架,包括:数据采集、数据分析、市场跟踪等[10]。Srikanta 和Kamaljit(2021)[11]构建了认为,需要将农业育种、畜牧业、农机作业、智慧生产管理、农产品质量安全追溯等方面的内容,融合到数据平台当中,形成统一管理,统一分析。
二、农业大数据农产品质量监测评估
(一)模型构建
本文在构建模型的过程中采用DEA 模型并按照三大原则来完成,第一大原则具体是实现分析目的,针对于对象的评价要展开具体详细地分析研究,一定要做到全面且客观,只要与此相关的全部对目标产生影响的因素都一定要分析到;第二大原则就是精简投入指标,DEA 模型,基于理论层面而言,能够有联系性的产出指标有数以千计,然而,指标的增长程度和效果之间呈现出了反比的关联性,所以,一般针对于投入产出指标的数量选取问题而言,一定要控制在决策单元个数的3 倍范围之内;第三大原则具体是一定要尽可能将数据收集成本考虑其中,在绩效评价内存在着大量的指标,所以相对应的搜集成本不好估量,一般都十分巨大,因为现实种种因素带来的限制性,所以只能在其中选择一部分可行的关键指标来开展并完成。在翻阅并借鉴大量资料,同时具体分析研究了技术难度,并基于DEA 模型选取确定的基本原则和调整公式基础上,本文最终确定了表1 这部分指标体系来展开具体分析。
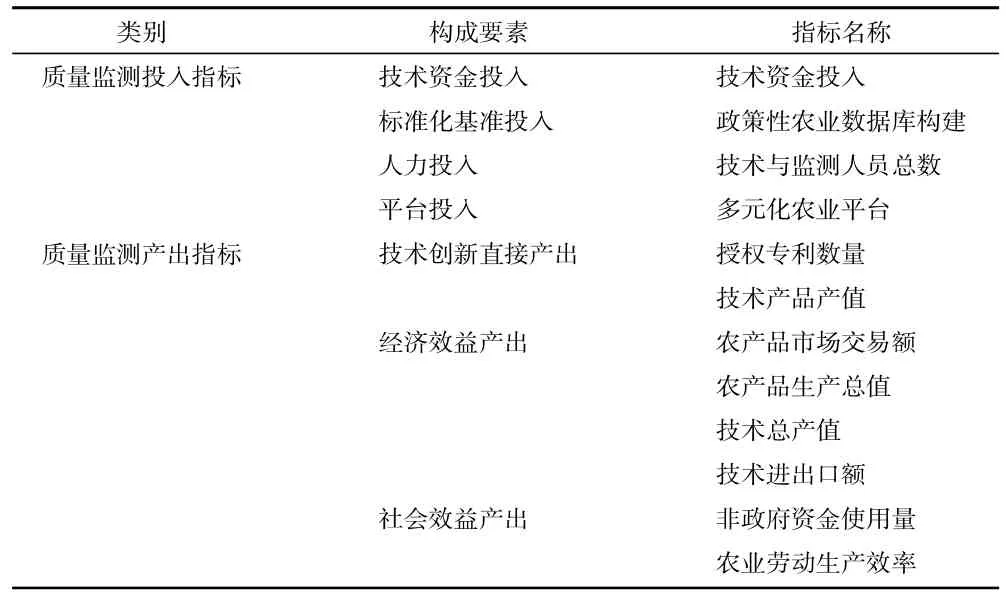
表1 大数据农业质量监测评价指标体系
由于农业大数据质量监测应用系统仍然处于探索阶段,相关的环节都不是十分的完善,因此,在指标的评估当中,可以选择主要的投入量和产出量,以最优选择为标准,进行设定。本文结合相关的文献,经过咨询专家的意见,对表1 所构建的指标进行取舍和综合判定。选择了最能够直观反映大数据农产品质量监测效果的投入和产出指标。分析投入指标与产出二者存在的相联系性,通过SPSS 19.0 进一步来完成校验过程。为了使得样本更为严谨化,本文重点考虑了相关系数≠1 的这部分指标。在一系列取舍考虑之后,最终,我们确定了投入和产出因素中分别三项指标,如表2 所示。

表2 大数据农业质量监测绩效评价投入产出指标
(二)数据获取
针对2015—2020 年农业部以及各省农业大数据应用中心、智慧农业研究院等发布的相关报告,形成了由1 987 个数据组成的平衡面板进行观测。研究使用的数据,技术资金投入数据源于企业查数据库,其余的相关指标来自于农业部以及农业大数据研究院、各地区农业生产企业、县域层面统计年鉴、各省商务厅、阿里研究院,个别缺失数据使用插值法补足。表3 是主要变量的描述性统计结果。

表3 变量描述性统计结果
(三)描述性检验
为了了解相关数据的准确性,本文对所搜集的变量进行了相关性检验,具体的结果如表4 所示。

表4 变量相关性分析结果
首先对于所有解释变量进行相关性分析,发现控制变量中经济效益和技术直接产出相关系数较大,可能存在自相关问题。为进一步检验解释变量间的相关性问题,下面进行VIF 检验,经检验表4 中所有VIF 值小于10,不存在多重共线性问题,可进行下一步回归。
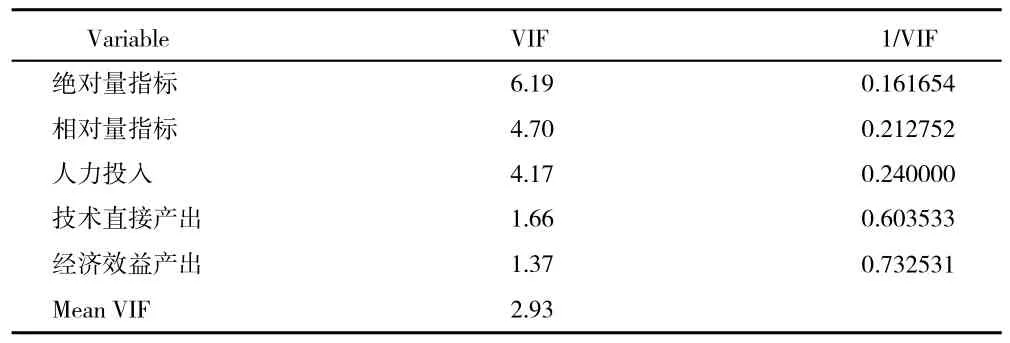
表5 VIF 检验结果
(四)分析结果
1.绩效变量分析。此处用到的工具是DEAP 2.1 软件,利用此进一步对上文中提到的指标来展开具体的计算过程,能够知道的是农业大数据监测对农产品影响的绩效统计结构,将五个主要评价指标纳入主体部分,由专家提供子模块,共计得到涉及到的子数据以及相关的模块主要有15 个。分别用DMU(1~15)代替,具体如表6、表7 所示。
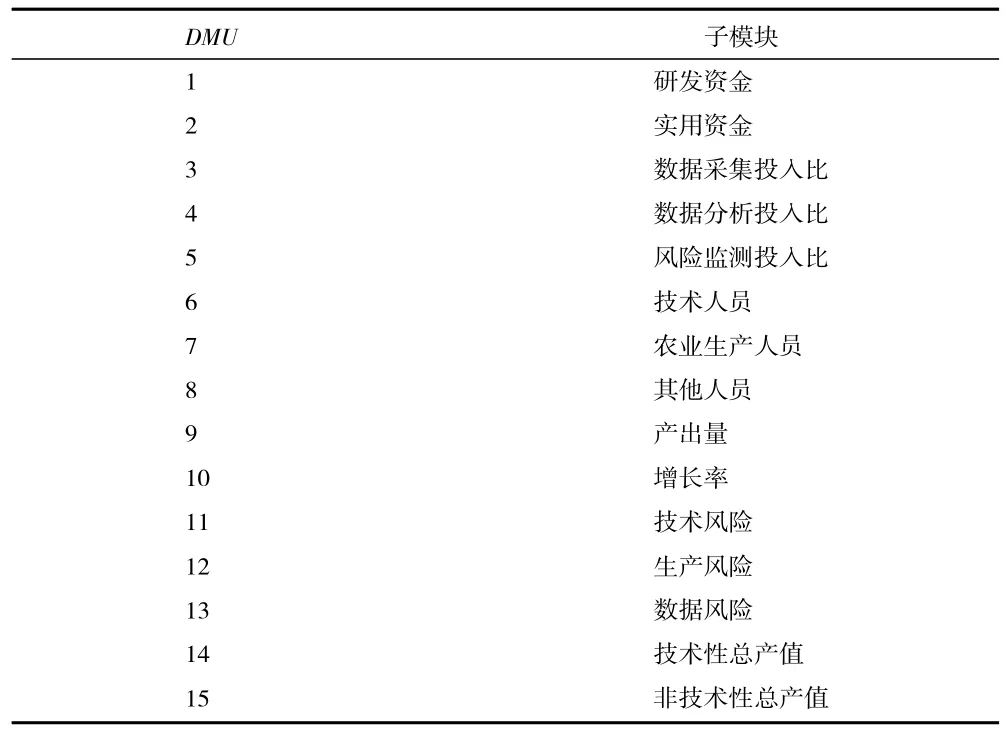
表6 大数据农产品监测投入产出子模块
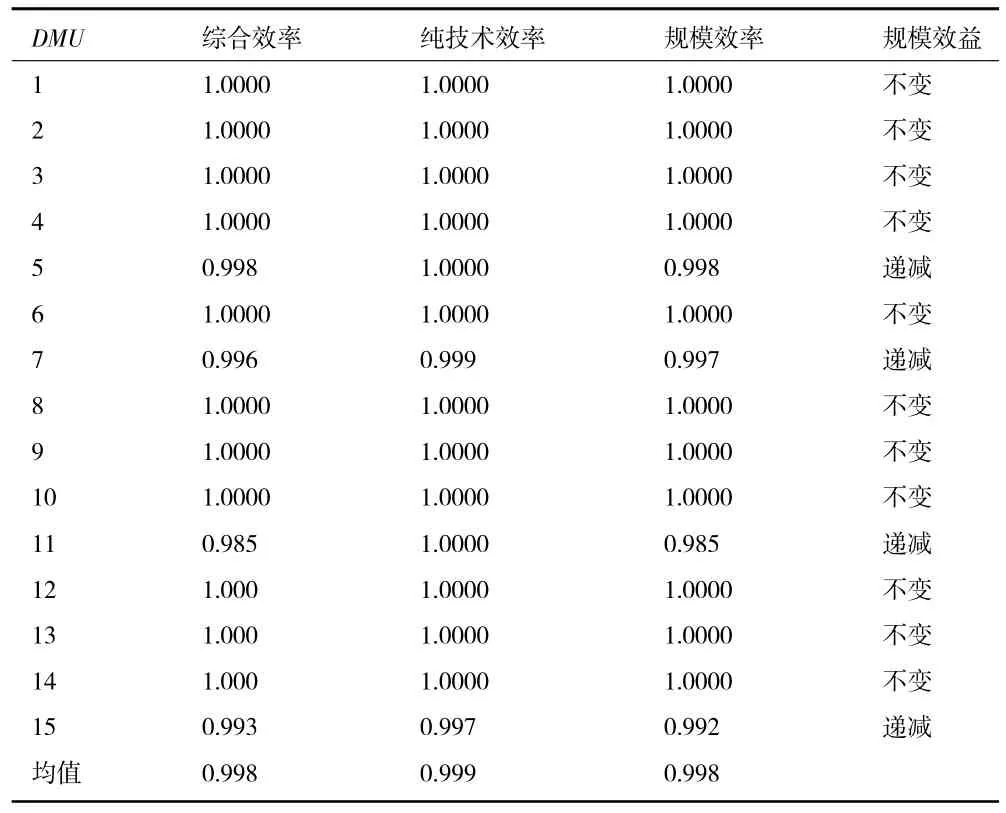
表7 大数据农产品监测投入产出绩效表
结果能够看得出:11 个单元的综合效率具体是1,这也就意味着EDA 是有效的,结果能够得知的是大数据监测投入产出目前具体处于尚可的状态。
纯技术效率X 规模效率=综合技术效率。综合技术效率涵盖了一系列内容,具体内容是分配优化、资源的使用率等等。在综合效率=1 的情况下,就能够得知的内容是目前的状态是最佳的。通过表6 能够得知的是,现阶段我国农业大数据监测的综合效率均值具体是0.998,一共有11 个目前已经能够处于最优状态中,并没有帕累托改进。综合效率=1 的时候,也就能够直接说明技术创新投入管理方面已经处于最优情况下了,没有再进行改进的必要性,但是如果发生了未达到1 的综合效率有4 个且不达标率已经处于26%的状态的话,那就能够直接说明还是需要再改进的。
2.松弛变量分析。就投入冗余值(S-)而言,能够做到的是衡量既定产出水平。在这一模型中的话,冗余值(S-)以及产出不足值(S+)这两个数值皆处于0 的状态,那就能够说明此时正是帕累托最优状态。针对投入量、产出量的不足与冗余这些方面来展开一系列具体的比对过程,进一步可以获取最终的研究结论。具体如表8 所示。
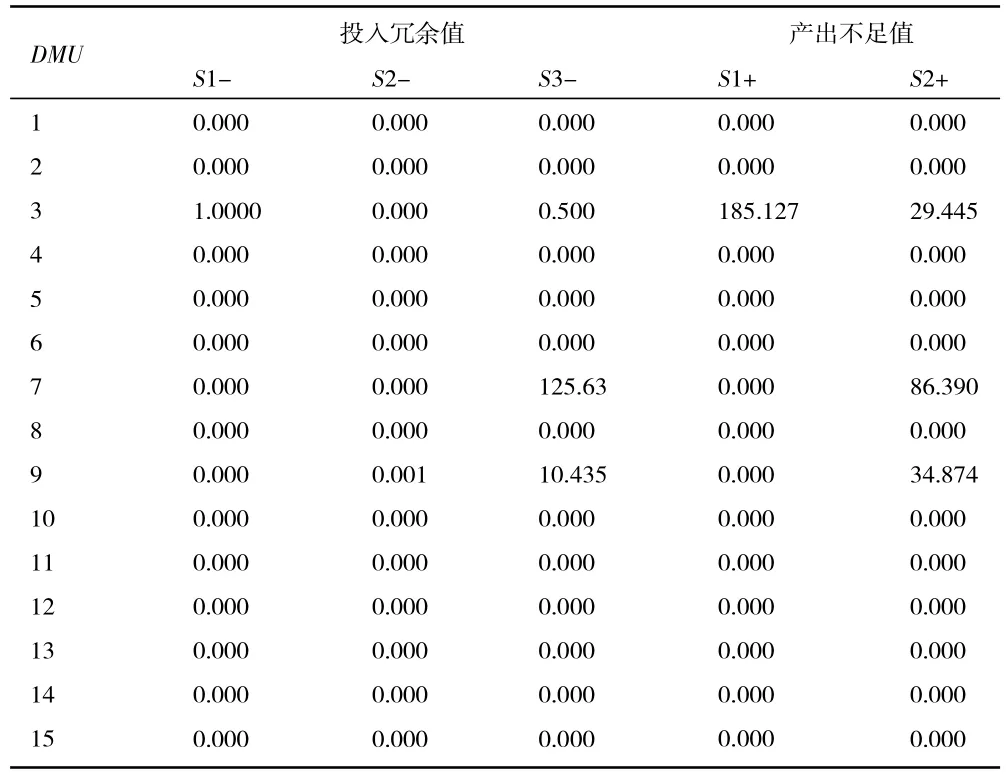
表8 大数据农业监测投入松弛变量值表
通过表8 能够得知的是,在这部分的15 个评价单元内,只有3 个评价单元需要进入到进一步改进的过程中,针对具体的产出指标不足值而言,有2 个需要改进,其他有1 个。整体而言,农业大数据对于农产品监测的功能得到有效的发挥,但是相关数据的统计均衡性以及具体原因,仍然需要进一步结合单个模块投影进行随机分析。
3.单个DMU 的投影分析。针对于DEA 不具备有效的导致性因素而言,投影能够做到对此展开具体研究探讨。所以,我们选取3、8、9 这3 个无效决策单元来进行投影的过程,具体的最终结果如表9所示。
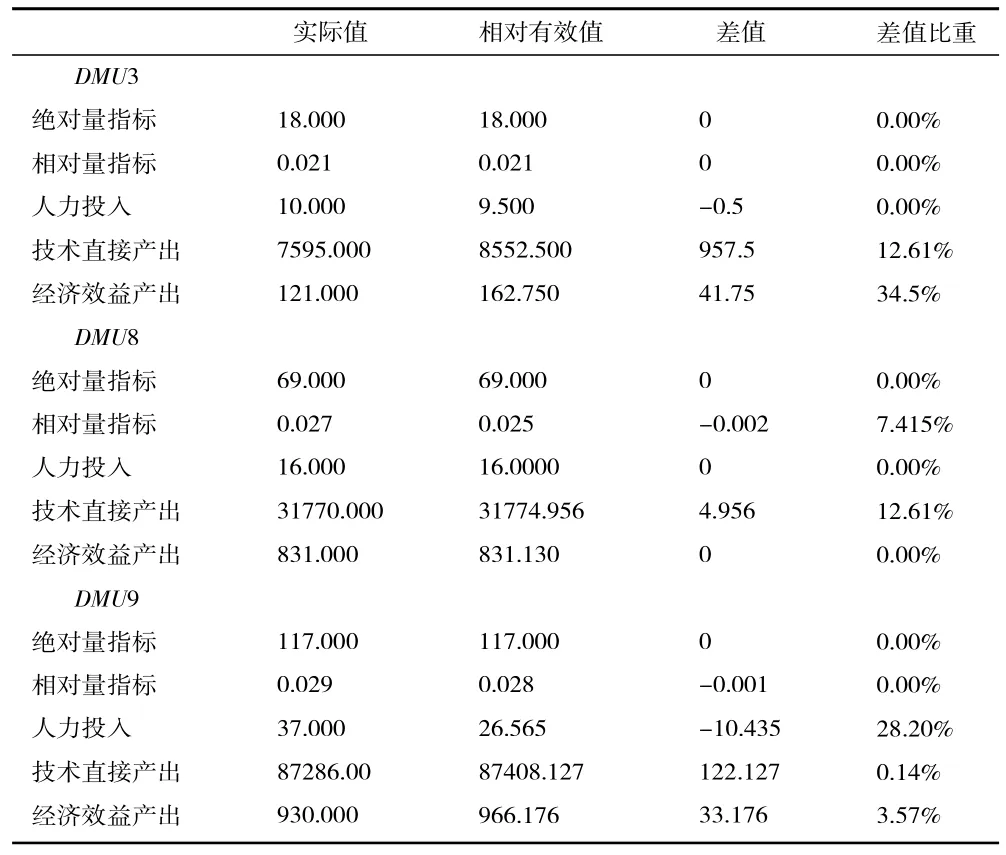
表9 部分数据投影结果
DMU3 投入指标中,相对值和实际值二者之间是一样的,这就能够直接体现出这一数值有效最优数量差值,存在差异,说明该数据指标需要进一步的改良。结合数据可以看出,在所选择的三个模块当中,目前农业大数据技术监测方面,除了绝对量指标外,在相对量指标、人力投入方面,都需要进一步的改进,这也是影响其作用发挥的主要原因。具体改进方面,需要利用技术,加大人力资源投入,通过政策,建构技术性平台形成指导。
三、农业大数据农产品质量监测策略分析
(一)加大农业技术人才和资金的投入,保持监测的高质量
第一,在人才的投入方面,各个地方需要结合地方经济和农业发展的特色,引入大量的计算机专业人才、农业生产人才、专家团队,负责大数据农业监测网络的建构和指导,将与农业生产相关的日常信息纳入其中[12]。同时,要积极的培育新型农民,增强其数据应用意识。加强对现阶段农业生产大数据监测的从业人员培训。
第二,在资金投入方面,需要通过计算投入产出的均衡数值,加大农业大数据网络建构的财政资金支持力度,增强影响力。建立国家—省—市—县—乡四级财政支持模式[13]。同时,提高资金的利用效率,做到专款专用,增强影响力,从而进一步提高思想认识。
(二)搭建多元化的数据获取平台
根据IDC 相关的数据统计,目前可联网的设备数量突破2 000 亿台,其中140 亿台能够连接并实现数据通信。在农产品质量监测的过程中,可以利用多种设备,通过不同的数据模型,获取不同的数据,进行统一的加工处理,实现24 小时常态化监控。在农产品的田头市场、产地市场、销售市场等,布设可以随时捕捉、整合、拆分农产品质量监测数据的移动设备,能够有效地解决农产品市场量多、数据分散的问题[14]。同时,还需要建立农产品多元控制平台,从化肥农药的使用、土壤情况、自然环境、生产情况、加工制造等环节出发,设置不同的模块,每个模块搜集不同的数据信息,使得质量监测的方式更加健全。比如化肥农药的使用,在农产品生长周期内,通过大数据模块,记录施肥的时间、地点、效果等基本数据,输入到数据库系统当中,并有智能监测设备作为参照,对农产品质量进行预测评估,设计最优方案,进行系统化的调整[15]。

表10 多元数据平台建构的内容
(三)构建大型模型系统
本文建立大型智能模型系统过程具体如下:第一,从传统的结构化处理,逐渐转向非结构性数据,从单一数据采集逐渐转向迭代数据采集,从批量处理逐渐转向流动处理,进而保证信息更新的及时、高效[16]。第二,制定更加符合实际的数据算法,根据农业生产的特点以及质量数据信息,制定个性化的推荐算法,将质量监测情况,及时反馈给农业生产人员。第三,需要充分的利用云计算,挖掘数据的价值,对农产品的各个环节,结合可移动设备、数据库信息等,找到农产品质量控制体系的发展轨迹以及农产品质量变化的本质规律[17]。建立质量与人员、技术、环境、资源等方面的关联,将大数据分解为小数据,逐一分析。具体的模型控制系统设计如图1所示。

图1 农业质量监测模型系统构成示意图
(四)搭建完善的预警平台,保证监测的可视化
首先,在农业生产的过程中,通过多维度可视化模拟、信息图表技术、云智能聚类等在平台当中的集合,对农产品的具体质量情况,以动画、视频、数据等方式展示出来[18]。由专业的人员进行预测,并找到可能存在的问题,并作出有效预警。其次,在农产品生产加工的过程中,将数据信息,通过各种媒介,公开化、透明化,并且搜集生产过程中的农产品筛选、运输、加工、销售等全流程数据信息,对每个环节通过数据标签归类处理,并利用模糊评价,得出综合结果,对可控风险因素进行预警并处理。第三,在市场销售的过程中,及时的搜集消费者的信息和需求情况,根据消费者的反馈,建立数据集成处理网络,将其生产、加工等环节衔接在一起,获得立体化的数据[19]。并借助于更为直观的形式,提交专业技术人员,进一步完善优化方案,具体如表11 所示。

表11 智慧化预警平台建构的内容
四、总结
大数据的高容量、高效率、高速度为农产品质量监测提供了更为有效的手段。基于大数据,构建大平台,获得大发展,已经成为我国现阶段农业生产的共识。在农产品质量监测的过程中,需要尽快转换思维,以数据为驱动,做好动态控制和信息预警。强化合作,积极联系各方面的技术专家,针对质量监测的关键问题进行讨论,合理的选择数据分析工具。本文主要针对农产品质量监测当中所涉及到的大数据应用模式进行了探究,从构建标准化的农业基准数据,保证监测精准性;搭建多元化的数据获取平台,保证监测常态化;构建大型模型系统,保证监测的可靠性给出合理的方案。
猜你喜欢
今日农业(2022年16期)2022-11-09
数学物理学报(2022年5期)2022-10-09
今日农业(2021年17期)2021-11-26
今日农业(2021年7期)2021-07-28
农产品市场周刊(2020年8期)2020-07-24
计算机应用(2018年12期)2019-01-08
商周刊(2018年26期)2018-12-29
互联网天地(2016年2期)2016-05-04
互联网天地(2016年1期)2016-05-04
中国工程科学(2015年7期)2015-02-27
