
基于光流残差的视频超分辨率重建算法
2022-08-09 05:48赖惠成钱绪泽
计算机工程与应用 2022年15期
吴 昊,赖惠成,2,钱绪泽,陈 豪
1.新疆大学 信息科学与工程学院,乌鲁木齐 830046
2.新疆大学 信号检测与处理自治区重点实验室,乌鲁木齐 830046
分辨率是图像质量的重要指标,如何提高图像和视频的分辨率,以呈现出更加清晰的视觉效果,成为近年来图像和视频处理领域研究的热点之一,现实中获取高分辨率图像的方法主要分为两种:一种是通过硬件的方式,减小成像像素元器件的尺寸,从而在先前相同的区域内获取更多的信息;另一种是通过软件来进行重构,来修复图像的细节信息以及去除噪声,这种方法被称作图像超分辨率技术,视频超分辨技术一般是由图像超分辨技术衍生而来[1]。
视频超分辨率技术的主要目的是将低分辨率视频转换为清晰的高分辨率视频,还原原始视频所忽略的信息,从而提高视频的质量,它不仅只是增加图像的像素数,还需要恢复图像视频的细节信息,随着人们对视频质量的要求越来越高,视频超分辨率在众多领域都有重要的研究和应用价值并且应用广泛,主要应用领域有医学图像处理、视频监控复原、遥感卫星图像的增强以及视频编解码[2-5]。
虽然单图像超分辨算法可以简单应用于视频超分辨任务中,但是存在明显的缺点:无法充分利用视频相邻帧的相关信息,图1表示图像超分辨率算法与视频超分辨率算法在放大倍数为4的视觉效果的对比图。视频超分辨存在着一个特点,那就是往一组相邻的低分辨帧存在相似性,也存在差异性,一般称多幅图像超分辨率算法为视频超分辨率算法[6]。

图1 图像与视频超分辨率算法的视觉效果对比图(×4)Fig.1 Comparison of visual effects between image and video super-resolution algorithm(×4)
对于超分辨率重建而言,存在一种不确定性的问题,那就是对于一幅低分辨率图像和视频而言,都可能由多个高分辨率图像以及视频下采样得到。而通过使用深度学习算法,可以直接学习从低分辨率端到高分辨率端的映射函数,从而对整个重建过程进行约束和引导。视频超分辨率算法主要分为:基于重建的方法[7-8]、基于样例的方法[9-10],以及基于重建和基于样例相结合的方法[11]。基于重建的多帧图像超分辨率算法首先要对邻近帧之间进行亚像素级精度的配准,然后通过帧与帧之间互补的信息来重建高分辨率图像。基于样例的多幅图像超分辨率算法通过使用机器学习以及深度学习的方法来学习低分辨率的视频帧与高分辨率的视频帧之间的非线性映射关系。本文就是基于重建和基于样例相结合的方法,通过深度学习的方法来学习端到端的非线性映射关系。
1 相关的工作
1.1 基于深度学习的图像超分辨率
Dong等[12]首次在2014年提出的超分辨率卷积神经网络(SRCNN),通过三层卷积网络构建了一个端到端的网络,证明了CNN具有学习LR和HR图像之间的非线性映射的能力,并且能够有好的精度和速度,深层CNN拥有提取多层次的特征的能力,但多数基于CNN的超分辨率模型不能完全利用这些特征。Kim等[13]在2016年提出了一种用于卷积神经网络的深度残差学习结构(VDSR),通过引入深度残差学习,他们只需要学习怎样去预测残差值,这使得深层网络的训练变得简单,从而使加深模型网络来提升模型的性能成为可能。Lim等[14]在2017年提出了EDSR模型在引入残差连接和残差块的同时,去除了BN层,因为BN层会对网络提取的特征进行归一化处理,从而丢失图片的高频信息。为了获得更接近真实效果的超分辨图像,Ledig等[15]首次在超分辨率领域引入对抗生成网络,利用生成网络与对抗网络相互竞争来学习,从而得到更好的图片效果。而彭宴飞等[16]在其基础上迁移支持向量机中的hinge损失作为目标函数,去掉了残差块和判别器中的批规范化层。唐家军等[17]针对单一网络存在层间联系弱以及不能充分利用分层特征等问题,通过构造多分支网络:一个子网络用来提取图像细节与运算,另一个子网络用来消除图像噪声以及降噪,从而来减小计算开销,稳定模型训练。
1.2 基于深度学习的视频超分辨率
近年来在视频超分辨率领域提出了多帧超分辨率技术,主要是利用输入帧之间的相关性来提高网络的性能指标。它一般考虑相邻低分辨率帧之间的亚像素运动,以多个低分辨率的视频帧作为输入,通过深度学习的方法来学习视频帧与视频帧之间的运动信息,从而输出高分辨率的视频帧。
大多数基于深度学习的视频超分辨率算法[18-20]一般包含特征提取、对齐、融合和重建等过程。首先在特征提取模块,一般通过使用浅层的卷积神经网络对视频帧进行特征提取,然后在对齐模块,一般通过运动估计和补偿来进行对齐和融合,为了更好地运用视频帧与帧之间信息,通常都会将参考帧与其相邻的几帧进行对齐与融合,但同时它是一项困难的任务,特别是相邻帧之间出现复杂的运动或视差时,比如视频中存在遮挡、复杂的运动等情况时,网络很难准确地得到相邻视频帧之间的的偏移量,如果在运动估计和补偿出现错误,很可能导致对齐和融合模块出现伪影和噪声。一般通常利用光流来预测中间帧和相邻视频帧之间的关系,然后通过它们相应的关系来进行运动补偿。因此,光流预测就显得至关重要,,Kappeler等[21]首次将光流法运用在运动补偿模块,并提出一种自适应运动补偿(AMC)方案,以减少噪声对视频帧的影响,并将相邻视频帧的特征在不同的卷积层进行堆叠,从而充分利用相邻帧之间的时空关联性,然后,Caballero等[22]提出了第一个用于视频超分辨率的端到端卷积网络框架(即VESPCN),首先利用传统的光流算法来估计相邻帧的位移偏差,用估计的位移偏差对相邻帧进行空间变换,将相邻的两帧进行对齐,然后将补偿后的低分辨率帧串联输入到卷积网络来重建高分辨率的视频帧,又因为超分辨率重建过程与相邻帧的估计都是通过卷积神经网络来实现的,所以它们构建成的网络可以进行端到端训练。然而这些方法都没有考虑到每一帧在不同尺寸的潜在视觉信息以及不同的视频帧或区域受到不完全对齐和模糊的影响。此外,输入帧的数量对网络也有影响,当减少输入到网络中的帧数,可以有效地提高网络建模复杂时间[23],但是输入帧数的减少也意味着网络可能收到的有用信息较少,网络的性能将受到进一步的限制。
本文采用光流残差网络来预测高分辨率光流,通过金字塔的网络结构以及密集残差块模块,对多个相邻帧进行特征提取和运动估计,可以获取被视频帧所忽略的局部信息以及每一帧在不同尺寸的潜在视觉信息,再通过融合模块来增强视频的连贯性和质量,从而构建一个端到端的视频超分辨率网络框架,通过和其他算法的对比,证明了光流残差网络能够拥有先进的性能。
2 视频超分辨率算法
2.1 算法框架
提出一种基于光流残差的视频超分辨率算法,它由三部分组成:光流残差估计模块(OFDNET)、运动补偿模块(motion compendation)和超分辨率融合模块(SRnet),如图2所示。将连续输入相邻两帧的低分辨率视频帧作为网络的输入,将经过超分辨率融合网络得到的高分辨率视频帧作为网络的输出。首先通过光流残差估计模块得到精确的高分辨率光流,使用亚像素卷积层将低分辨率的视频帧映射到高分辨率空间进行超分辨率的重建得到高分辨率的视频帧,然后在运动补偿模块上,将得到的高分辨率光流与输入视频的高分辨率帧进行运动补偿,得到相应的视频帧的集合,再将其输入超分辨率融合模块,将视频帧的集合进行深度的特征提取与融合,从而得到细节信息更加清晰的高分辨率视频帧。在所有的网络结构中,如何获得图像深层的细节信息是非常重要的,所以在光流残差估计模块和超分辨率融合模块,采用了深度残差的网络结构来增加卷积神经网络的深度,更好地利用视频帧之间的信息以及不同尺寸的潜在视觉信息,并且提出新的损失函数来训练网络,能够更好地对时域和空域进行建模和约束,同时能够更好解决因为光流法求解时存在较大误差,从而导致运动补偿后的结果出现伪影和噪声,进而影响超分辨性能的问题,并且在降低运动补偿误差的同时,也可以提高视频超分辨的精确度以及超分辨视频的质量。

图2 基于光流残差的视频差分辨率网络结构Fig.2 Video differential resolution network structure based on optical flow residu
2.2 光流残差估计网络
在光流残差估计模块(OFDNET),受到金字塔光流估计方法[24]的启发,设计一个3层的网络框架,利用深度残差的卷积神经网络对相邻帧进行特征提取以及预测高分辨率的光流,通过设计金字塔结构的卷积残差神经网络,对输入网络的多个低分辨视频相邻帧分别进行特征提取和融合。如图3所示,初始的光流为0,以相邻的两帧、作为输入,输出和与相对应光流,如公式(1)所示:FOFD表示光流残差估计过程,f(θ)表示在光流残差估计过程中的参数集。
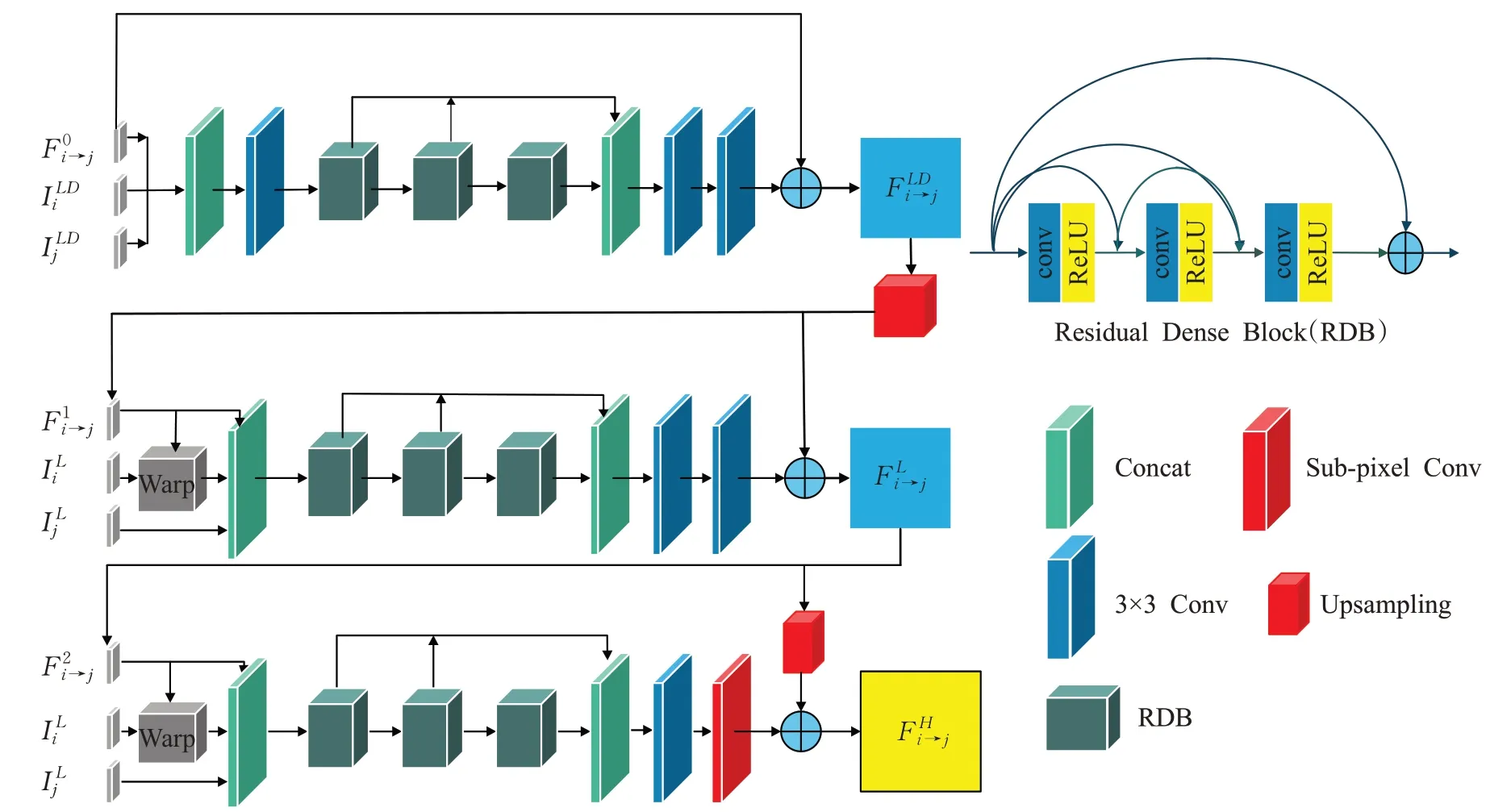
图3 光流残差估计网络框架Fig.3 Network framework of optical flow residual estimation

在第一层,首先对与进行采样因子为2的下采样得到与,然后,与初始的光流(初始值为0)连接一起经过3×3的卷积层进行浅层的特征提取(通道数为32),再接3个密集残差块(residual dense block),每个密集残差块都有3层(每层的参数如表1所示,通道数为32)得到深层的特征,后将RDB的输出融合在一起,通过2个卷积层,再与初始的光流叠加在一起得到预测光流。

表1 光流残差估计网络每一层网络的参数Table 1 Parameters of each layer of optical flow residual estimation network
在第二层,首先对进行采样因子为2的上采样得到,再按照将向进行变换,后与融合一起在,从而得到视频帧之间的相关性。后面的结构与第一层相似,最后再与相加后得到预测光流。
在第三层,与第二层基本相似,只是在特征融合前加上亚像素卷积层进行分辨率增强,然后与上一层预测光流进行上采样的进行相加后,得到高分辨率的光流(此次上采样的放大因子r与亚像素卷积层的放大因子相同)。每次经过一个卷积层时,后面都接个修正线性单元(rectified linear unit,ReLU)。其中每一层网络的具体参数如表1所示。
2.3 运动补偿模块
通过光流残差估计网络得到高分辨率的光流,通过使用亚像素卷积层进行分辨率的放大,如图4所示,首先通过一个卷积层将输入图片的通道数变为2×s×s(s为放大因子)再通过亚像素卷积模块将低分辨率的视频帧映射到高分辨率空间进行超分辨率的重建,从而得到与具有相同的维度的,如公式(2)所示:
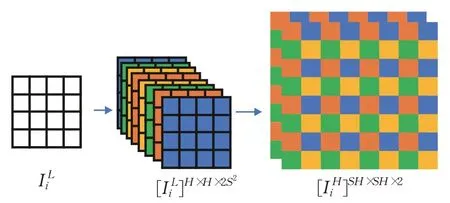
图4 亚像素卷积模块Fig.4 Sub-pixel convolutional module

其中,ps是一个周期筛选算子,它将H×W×2S2张量的元素重新排列为形状为SH×SW×2的张量,如公式(3)所示,其中H和W表示低分辨率视频帧的尺寸。
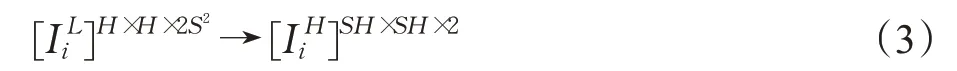
然后,将高分辨率的光流以及高分辨率视频帧进行运动补偿,从而得到相邻视频帧之间的相关性。首先使用根据光流的速度场(u,v)对将中的每一个像素进行移动,从而得到运动补偿后的视频帧集。如公式(4)所示:

2.4 超分辨率融合模块
在超分辨率融合模块,同样使用残差密集的网络结构,使用密集残差块(RDB)来提取高分辨率视频帧的所有分层特征层,来得到全局密集特征,从而在高分辨率空间将运动补偿后对得到的视频帧进行更好的融合。如图5所示。输入2N+1个连续的LR帧(,…,Ii L,…,),其中以Ii L作为输入的中间帧,通过运动补偿模块后,得到高分辨率帧的集合,将其输入到超分辨率融合模块中去,进行特征的融合,输出高分辨率帧ISR,如公式(5)所示:

图5 超分辨率重建的网络结构Fig.5 Super-resolution reconstruction of network structure

首先使用2个卷积层(CONV1~CONV2)来对图像进行浅层特征的提取,再通过3个密集残差块(RDB1~RDB3)(每个密集残差块都有3层,通道数为32)来提取深层特征,在每个RDB内部,都有一个全局短连接,从而使网络局域连续记忆;将上一个RDB地输出直接送到当前RDB的输入端,然后使用一个卷积层(CONV3)以及2个残差结构来进行浅层特征以及深层特征的结合,再通过将结合的特征以及RDB的分层特征进行融合,从而得到全局的密度特征,最后通过卷积层(CONV4)来进行通道数的转换,得到具有全局密度特征的高分辨率视频帧。
2.5 损失函数
损失函数分为两个部分:一个是超分辨率融合模块的损失函数LSR,它对训练网络的训练起决定性的作用,主要是通过计算超分辨率重建后的视频帧与原始的高分辨率视频帧的误差来训练网络;另一个是光流残差估计网络的损失函数LOFD,而主要是来约束光流,如公式(6)所示:

其中,a=0.1,对于超分辨率融合模块损失函数LSR,受到[25]的启发,使用L1以及LMS-SSIM来进行训练,并且使其使用其中参数的值,即β=0.84。LMS-SSIM代表多尺度结构相似损失函数,L1代表平均绝对误差(MAE),它是值目标值与预测值之差绝对值的和,表示了预测值的平均误差幅度。LMS-SSIM容易导致亮度的改变以及颜色的偏差,但它对局部结构变化的感知敏感,能保留高频信息(图像的边缘和细节),而损失函数L1能较好地保持亮度和颜色不变化。LSR损失函数定义如下:
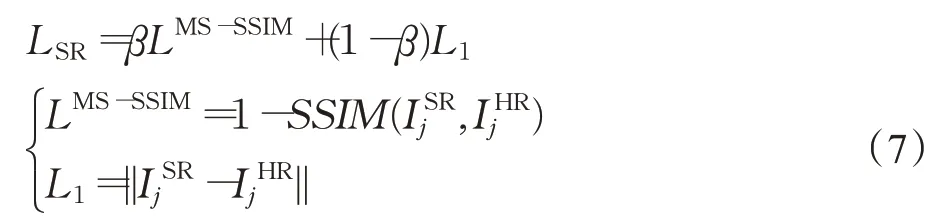
代表经过超分辨率融合后的视频帧,IHRj代表原始的高分辨率视频帧。
对于光流残差估计网络的损失函数LOFD,主要是用来约束光流估计过程,从而解决光流法求解时存在较大误差的情况。它的损失函数由三部分组成,分别对应它的三层网络结构,分别是L1i、L2i、L3i:
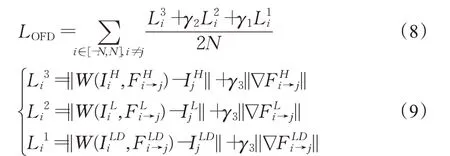
3 相关实验
3.1 实验数据与参数介绍
本文采用REDS数据中适用于超分辨的作为训练集,它包含了240个视频序列,每个序列均有100帧,使用Vid4数据集以及SPMCS数据集来测试本文的算法。
在训练与测试时,对高分辨率的视频帧使用4倍的双三次插值进行下采样,得到对应的低分辨率视频帧,将输入LR帧转换为YCbCR颜色空间,并只提取亮度通道作为网络的输入。在训练阶段,从LR视频剪辑中随机提取3个连续帧,并通过旋转和反射进行数据增强,从而提高了网络的泛化能力。本文使用Pytorch框架构建网络,网络参数初始化采用Kaiming初始化方法初始的学习率是10-4,训练30 000次,经过20 000次学习率变成之前的一半,使用Adam优化器。
3.2 实验结果与分析
首先在Vid4数据集与SPMCS数据集进行放大倍数为4的超分辨率重建实验,为了测试输出图像的准确性,在客观指标上使用PSNR/SSIM作为测试指标,对超分辨视频帧和原高清视频帧的亮度(Y)通道上逐帧求取PSNR和SSIM,PSNR和SSIM越高,表示重建视频帧的质量就越高,并且其中视频的运动幅度都不相同。
在Vid4数据集,与SPMC[26]、RCAN[27]和SOF-VSR[28]等视频超分辨率算法的性能进行了比较。对于RCAN和SOF-VSR使用作者提供的代码来生成结果,对于SPMC使用其论文中报告的结果。在测试时,分别去除每个视频中的第一帧和后一帧,然后再测试每个视频序列中亮度通道的平均PSNR和SSIM的值。测试的结果由表2所示。从表中可以看出,本文的算法中PSNR和SSIM的值都优于其他算法。

表2 不同的方法在Vid4数据集上的PSNR和SSIM(×4)Table 2 PSNR and SSIM(×4)on Vid4 data set by different methods
在SPMCS数据集上,每个视频的种类都不相同,比较30个不同的视频序列指标的平均值,在进行测试时,分别去掉第一帧和后二帧,然后再对比每个视频序列平均的PSNR和SSIM的值。测试的结果如表3所示。

表3 不同的方法在SPMCS数据集上的PSNR和SSIM(×4)Table 3 PSNR and SSIM(×4)on SPMCS dataset by different methods
图6表示不同的方法在Vid4数据集中calendar(第七帧)和foliage(第九帧)进行放大倍数为4的超分辨率重建后的视觉对比图。两幅图分别表示运动幅度较慢的场景(日历)以及相对较快的场景(轮胎)。从calendar中,可以看到通过RCAN所生成的图片中的字母仅仅只有轮廓,清晰度比较低,线条都过于平滑,里面缺少较多的细节以及边缘信息,而SPMC和SOF-VSR所生成的图片中的字母的与本文的算法相比都过于模糊;从foliage可以看出,本文算法所生成的图片中移动比较快的物体,比如轮胎部分中的纹理信息恢复的效果,也比其他算法更加清楚。

图6 不同的方法在Vid4数据集中进行放大倍数为4的超分辨率重建的效果图Fig.6 Super-resolution reconstruction of Vid4 data set by different methods with amplification factor of 4
图7表示不同的方法在SPMCS数据集中hdclub_003_001(第28帧)和hk001_001(第10帧)进行放大倍数为4的超分辨率重建的效果图,两幅图分别表示复杂的场景(城市)以及相对单一的场景(佛像)。从图中可以看出,RCAN和SOF-VSR所生成的图片较于本文的算法存在着一定的结构失真以及一些噪声,比如hdclub_003_001中的线条,RCAN中所生成图片与原图相比多了一条竖线,而SOF-VSR所生成的图片又过于模糊;虽然通过SPMC所生成的图片效果在某些方面比较好,比如hk001_001中脸的轮廓,但在细节信息比如红点又过于模糊。

图7 不同的方法在SPMCS数据集中进行放大倍数为4的超分辨率重建的效果图Fig.7 Super-resolution reconstruction of SPMCS data set by different methods with amplification factor of 4
在总体上可以看出本文的算法相较于其他算法,尤其是对图片中细节信息的恢复效果比其他算法都要好。在客观指标上,在Vid4数据集上PSNR要比其他算法高出0.31 dB,在SPMCS数据集上PSNR要比其他算法高出0.88 dB,并且SSIM在两个数据集上均有所提高,证明为了本文的网络来预测高分辨率的光流是有效果的。
4 消融实验
为了更好地分析光流残差估计网络作用、运动补偿模块机制的补偿的效果以及浅层特征和深层特征结合方式以及其有效性,对各个网络及其子模块的进行实验和验证。所有的实验都在Vid4训练数据上进行了300 000次的训练和测试。
4.1 光流残差估计网络的分析
与其他的算法相比,增加第一层与第三层的网络结构,主要是为了得到不同尺寸下的潜在视觉信息以及对光流进行低分辨率空间到高分辨率空间的转换。为了说明第一层与第三层的作用,分别去掉光流残差估计网络的第一层、第三层在Vid4数据集上作为对比实验。其中的PSNR、SSIM的指标如表4所示。NOFDETL1代表去除光流残差估计网络的第一层。NOFDETL3代表去除光流残差估计网络的第三层,此时得到的,将它与一起使用亚像素卷积模块进行超分辨率的重建,然后输入到超分辨率融合模块。从表4可以知道去除光流残差估计网络的第一层以及第三层后,PSNR分别从26.32 dB下降到25.80 dB以及25.60 dB。

表4 流残差估计网络在Vid4上的有效性验证Table 4 Validation of stream residual estimation network on Vid4
4.2 动补偿模块的分析
为了充分说明运动补偿模块的补偿效果,作为对比,去除运动补偿模块,其结果如表5所示。w和w/o分别表示有和没有运动补偿模块。从表5可知,如果没有运动补偿模块,PSNR分别从26.32 dB下降到25.46 dB。

表5 运动补偿模块在Vid4上的有效性验证Table 5 Validation of motion compensation module on Vid4
4.3 超分辨率融合模块的分析
在超分辨率融合模块,使用深度残差网络来进行浅层和深层特征的提取和融合。为了说明网络的效果,去除超分辨率融合模块中的残差结构,只提取其中的深层特征,其结果如表6所示。No sr和sr分别表示有与没有超分辨率融合模块中的残差结构。

表6 融合模块在Vid4上的有效性验证Table 6 Validation of fusion module on Vid4
4.4 损失函数的分析
本文损失函数由光流残差估计网络的损失函数以及超分辨率融合模块的损失函数组成。与其他算法相比,增加了对于光流残差估计网络的损失函数,来约束光流估计的过程,从而得到精确的光流。a的值代表光流残差估计网络的损失函数权重,如果a值过大,就可能影响超分辨率融合模块的损失函数LSR,从而影响网络的训练。因此取小于0.5的值进行实验,如表7。

表7 不同a值下Vid4实验结果对比Table 7 Comparison of experimental results of Vid4 at different a values
在a=0.1的条件下,对于光流残差估计网络的损失函数,其中γ1和γ2分别为对应光流残差估计网络的第一层与第二层的损失函数的权重(第三层的系数为1),因此γ1小于γ2并且都应该小于0.5。而γ3为L1正则化的系数,使用通用的值0.1,如表8。

表8 不同的γ1和γ2值下Vid4实验结果对比Table 8 Comparison of experimental results of Vid4 at differentγ1 andγ2 values
5 总结
本文提出一个基于光流残差的重建网络,利用视频中相邻帧间的相关性,在低分辨率空间通过光流残差估计网络来提取每一帧的特征,并利用深度残差的卷积神经网络来预测高分辨率的光流,再通过高分辨率的光流进行运动补偿,从而更加充分运用上下视频帧之间的互补信息以及同尺寸的潜在视觉信息,并将补偿后的视频帧集输入到超分辨率融合网络对视频帧进行更好的融合,使用和光流残差估计网络的损失函数以及超分辨率融合模块的损失函数来训练网络,从而提高精度,增强超分辨视频的清晰度。在公开数据集上的实验表明,对于复杂的场景以及不同运动幅度视频的重建效果在客观指标和视觉效果方面均有一定提高,但是对于处理某些不会变化的部分(比如视频的水印)的效果有待加强。未来可以考虑通过引入3D卷积[29]、可变性的ConvL-STM[30]来进行视频帧之间的时间信息提取与校准。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
导航定位与授时(2022年4期)2022-08-05
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
小型微型计算机系统(2021年12期)2021-12-08
北京航空航天大学学报(2020年10期)2020-11-14
导航定位与授时(2020年4期)2020-07-29
雷达学报(2020年3期)2020-07-13
北京航空航天大学学报(2019年9期)2019-10-26
太空探索(2016年3期)2016-07-12
