
基于YOLO的自动驾驶目标检测研究综述
2022-08-09 05:44茅智慧朱佳利
计算机工程与应用 2022年15期
茅智慧,朱佳利,吴 鑫,李 君
浙江万里学院 信息与智能工程学院,浙江 宁波 315100
交通是一个国家经济发展的重要基础产业。随着人们生活水平的提高,汽车已经成为人们日常出行的重要交通工具。据公安部统计,2021年我国汽车保有量达3.02亿辆[1]。但汽车提供方便的同时,全国的交通事故数量居高不下,据估计,90%的车祸是由人为失误造成的[2]。传统汽车驾驶需要驾驶者高度集中注意力,时刻注意周围环境的变换,然而疲劳、噪音、天气、心理等多方面因素都会影响驾驶者的判断,进而可能产生危险。作为未来汽车的发展方向,自动驾驶汽车拥有自主判断能力,能较大程度地减少人为失误。同时,自动驾驶汽车能更好地节能减排、减少污染[3],有良好的应用前景。
为使自动驾驶汽车能够安全稳定地运行在道路上,对于参与道路交通的各类目标,如:车辆、行人、交通标志、灯光、车道线等,自动驾驶车辆都需要做出实时精确的检测以及判断。对实时目标的精准检测、识别并做出判断是保证其运行的基础与核心。
目前,国内外学者围绕自动驾驶技术做了不同领域的综述,邓伟文等[4]综述了自动驾驶测试领域自动生成仿真场景的方法,吕品等[5]综述了自动驾驶数据处理的边缘计算技术,Zamanakos等[6]对基于激光雷达的目标检测进行了综述。本文则围绕深度学习的YOLO系列算法在自动驾驶目标检测识别中的应用进行综述,并对其在提升实时检测的效率与精度方面做出相应的总结与展望。
1 自动驾驶简述
自动驾驶汽车中的自动驾驶系统是多技术融合的产物。所谓自动驾驶即通过多种车载传感器(如摄像头、激光雷达、毫米波雷达、GPS、惯性传感器等)来识别车辆所处的周边环境和状态,并根据所获得的环境信息(包括道路信息、交通信息、车辆位置和障碍物信息等)自主做出分析和判断,从而自主地控制车辆运动,最终实现自动驾驶[7]。
根据车辆的智能性程度,2021年8月20日,工信部批准发布了GB/T 40429—2021《汽车驾驶自动化分级》标准[8]。该标准将自动驾驶划分为L0~L5等级,具体分级标准如表1所示。
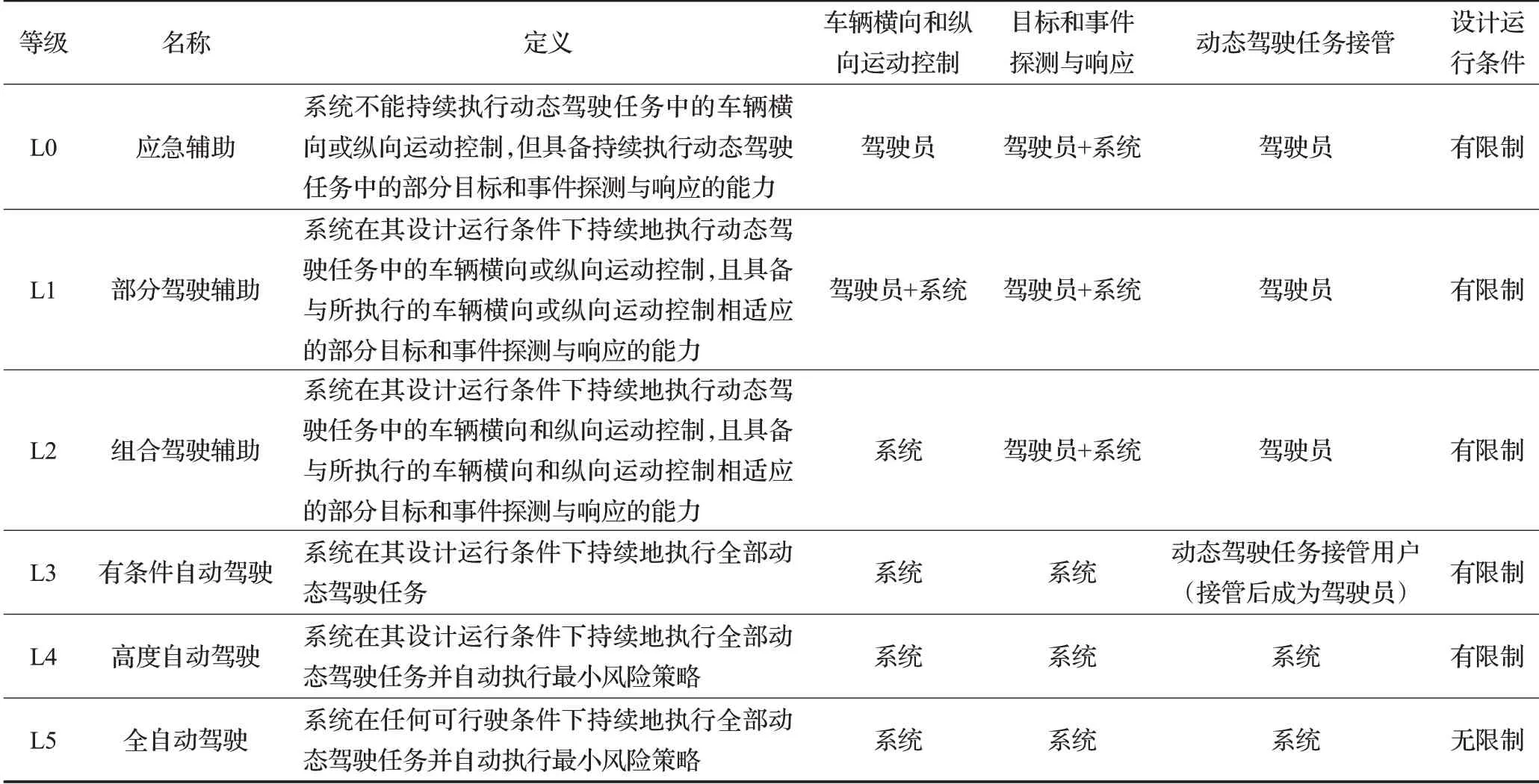
表1 GB/T 40429—2021《汽车驾驶自动化分级》标准Table 1 GB/T 40429—2021 Automotive driving automation classification standard
20世纪80年代,卡内基梅隆大学提出了最早的在结构化环境中驾驶的自动驾驶汽车项目[9],以及慕尼黑联邦大学提出高速公路驾驶项目[10]。1986年,全球第一辆由计算机驾驶的汽车NavLab1诞生,1992年,国防科技大学成功研制出中国第一辆无人驾驶汽车[11]。此后,DARPA大挑战[12-13]等项目不断推动自动驾驶的技术向前发展。
在学术界之外,汽车制造商和科技公司也开展了研究,开发自己的自动驾驶汽车。2000年,美国通用汽车开发了一套自动碰撞预警/防止系统,夜视和后视报警系统的应用使得汽车具备L0的应急辅助功能[14]。各种高级驾驶辅助系统,如自适应巡航控制(adaptive cruise control,ACC)、车道保持辅助和车道偏离警告技术,为现代汽车提供了部分自主权,车辆进入L1的部分驾驶辅助阶段;宝马、奔驰、大众、通用、特斯拉、上汽、吉利、小鹏等品牌汽车在2017年基本都已实现L2级别的整车落地与推广,该级别车辆一般搭载有的车道内自动驾驶、换道辅助、自动泊车功能;2020年后,多款汽车(奔驰、通用、特斯拉、吉利、小鹏等)开始导入L3与L4级别以上的自动驾驶[15]。但至今,L2级别的汽车依然是企业商业化发展的重点。这些技术不仅提高了现代汽车的安全性,使驾驶变得更容易,而且还为完全自主的汽车铺平了道路。在自动驾驶技术中,提升环境的感知能力能提供更安全的运行环境。
2 面向自动驾驶的目标检测
2.1 评价指标
在介绍目标检测的算法之前,需要了解在目标检测中常用的评价指标。在判断分类的精度一般使用准确度(accuracy)、精确度(precision)、召回率(recall rate)、AP(average precision)、mAP(mean average precision)等,在判断定位的精度一般使用交并比(intersection over union,IoU),在判断运行的速度时一般采用FPS(frames per second)。
假定待分类目标只有正例(positive)和负例(negative)两种,则有以下四个指标:(1)TP(true positive),被正确识别成正例的正例;(2)FP(false positive),被错误识别成正例的负例;(3)TN(true negative),被正确识别成负例的负例;(4)FN(false negative),被错误识别成负例的正例。
(1)准确度是指所有预测中预测正确的比例。
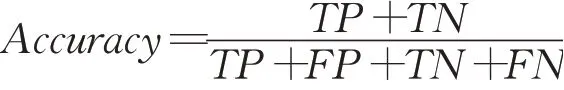
(2)精确率是指在所有检测出的目标中检测正确的概率。
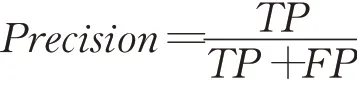
精确率是从预测结果的角度来定义。Accuracy针对所有样本,而Precision仅针对检测出来(包括误检)的那一部分样本。
(3)召回率是指所有的正样本中正确识别的概率。

(4)AP由P-R曲线和坐标围起来的面积组成,用于表示不同召回率下检测的平均正确性。mAP为各类别AP的平均值,用于对所有目标类别检测的效果取平均值。性能越好,比值越高。
(5)IoU表示的是“预测的边框”和原图片标注的“真实边框”的交叠率,是两者交集与并集的比值。比值达到1时预测的效果达到最佳。
(6)FPS是目标检测的速度性能评价指标,检测速度代表目标检测算法与模型的计算性能。FPS即每秒处理图片的帧数,数值越大代表检测速度越快。
2.2 目标检测算法
早期的自动驾驶车辆系统严重依赖精确的传感器数据,利用多传感器设置和昂贵的传感器(如激光雷达)提供精确的环境感知。这些自动驾驶车辆的参数由开发人员设置,并在模拟和现场测试后手动调整[16-17]。这种方法的缺点是需要大量时间手动调整参数[18],而且很难推广到新的应用场景。继深度学习广泛应用于图像分类和语音识别等领域后[19-20],人们开始将深度神经网络(deep neural networks,DNN)应用在自动驾驶车辆上,包括规划和决策[21]、感知[22]以及地图和定位[23]。
目标检测与识别是自动驾驶的感知系统的重要组成部分,在目标检测领域近10年具有代表性的算法如图1所示。基于深度学习的目标检测算法包含有Two-Stage目标检测算法和One-Stage目标检测算法两类。

图1 目标检测代表性算法Fig.1 Representative object detection algorithms
在深度学习的Two-Stage目标检测的经典主流算法主要有R-CNN[24]、SPP-Net[25]、Fast R-CNN[26]、Faster R-CNN[27]、R-FCN[28]以及NAS-FPN[29]等。Ross Girshick等[24]于2014年提出的R-CNN算法是第一个工业级精度的Two-Stage目标检测算法,后期基于分类的Two-Stage算法虽然在检测效果上有了很大提升,但是在算法的速度上,还是不能满足目标检测任务对于实时性的要求(如表2所示)。

表2 Two-Stage目标检测算法的优缺点及实时性Table 2 Advantages,disadvantages and real-time performance of Two-Stage target detection algorithm
随着One-Stage目标检测算法的提出,目标检测的效率得到了大幅度的提升,使将其应用于自动驾驶系统中的目标实时感知检测成为可能。One-Stage目标检测算法是学者们提出的新的一类基于回归思想的检测算法,其中典型的两类算法是SSD(single shot multibox detector)系列[30]和YOLO(you only look once)系列。2016年Redmon等人提出YOLO算法[31],开创性地将检测问题转化为回归问题,使用卷积神经网络来直接完成目标类别的判定和边界的预测。真正意义上实现了目标的实时检测,开启了目标检测One-Stage算法的新纪元。
YOLO系列算法满足了目标检测的实时性,但在检测精度上却做出了一定的牺牲,尤其是YOLO v1对于分布密集的小物体,更是极易出现漏检的情况。近几年Redmon团队不断改进YOLO算法,将其更新至YOLO v3[32-33]。2020年,Bochkovskiy等人[34]在此基础上改进并发布了YOLO v4,后续YOLO v5以及YOLO X版本的更迭,使得YOLO系列算法更适用于工程实践,其精度及实时性都得到改善(见表3),学者们开始将YOLO算法应用到自动驾驶目标的实时监测。

表3 One-Stage目标检测算法的优缺点及适用场景Table 3 Advantages,disadvantages and applicable scenarios of One-Stage target detection algorithm
2.3 YOLO算法在自动驾驶的应用
随着自动驾驶车辆和深度学习目标检测不断的研究,学者们将改进后的YOLO算法应用到自动驾驶车辆目标(车辆、行人、交通标志、灯光、车道线等)的实时监测中。
2.3.1 交通标志的检测
在交通安全中,交通标志识别的准确性在高级驾驶员辅助系统、自动驾驶车辆中发挥着关键作用。
Zhang等[35]通过添加新图像和变换图像扩展了中国交通标志数据集(CTSD),形成新的数据集CCTSDB(CSUST Chinese traffic sign detection benchmark),并在YOLO v2算法网络的中间层采用多个1×1卷积层,在顶层减少卷积层,降低计算复杂度。Yang等[36]同样选择了CCTSDB数据集,分别使用YOLO v3和YOLO v4训练训练集。通过测试对比为其在数据集测试中IoU的变化(如图2),YOLO v4在目标检测方面优于YOLO v3。

图2 IoU对比图Fig.2 Comparison of IoU
Dewi等[37]则使用生成式对抗网络(generative adversarial networks,GAN)生成更逼真和多样化的交通标志的训练图片,将合成图像与原始图像相结合,以增强数据集并验证合成数据集的有效性。使用YOLO、YOLO v3和YOLO v4迭代。图像混合后识别性能得到了提升,在YOLO v3上mAP(平均精度值)为84.9%,在YOLO v4 mAP为89.33%。
Mohd-Isa等[38]通过在YOLO v3框架中包含空间金字塔池化(SPP),进一步识别真实环境中的远小交通标志。Mangshor等[39]使用YOLO训练模型以进行识别五种警示交通标志,包括十字路口、右十字路口、左十字路口、马来西亚交通标志的学童横穿和碰撞。实时物体检测的测试结果在交通标志检测和识别上都达到了96.00%的准确率。
吕禾丰等[40]调整了YOLO v5算法的损失函数,使用EIOU(efficient intersection over union)损失函数代替GIOU(generalized intersection over union)损失函数来提高算法的精度,实现对目标更快速的识别;使用Cluster NMS(non-maximum suppression)代替Weighted-NMS算法,提高生成检测框的准确率。
在使用YOLO算法进行交通标志的研究过程中,一般分为以下方式进行改变:(1)扩建数据集或者强化数据集。文献[35]扩充了中国交通标志的数据集,文献[37]通过虚拟图片强化原有数据集,但是在实验过程中涉及识别的数据类型并不完全,标注识别的数据围绕三大类:指示标志、禁止标志、警告标志;(2)修改算法的损失函数或网络结构,通常在保证一定的检测速度优势的基础上提升原算法的检测精度,文献[38]添加池化层,文献[40]使用GIOU损失函数取代(如表4所示)。
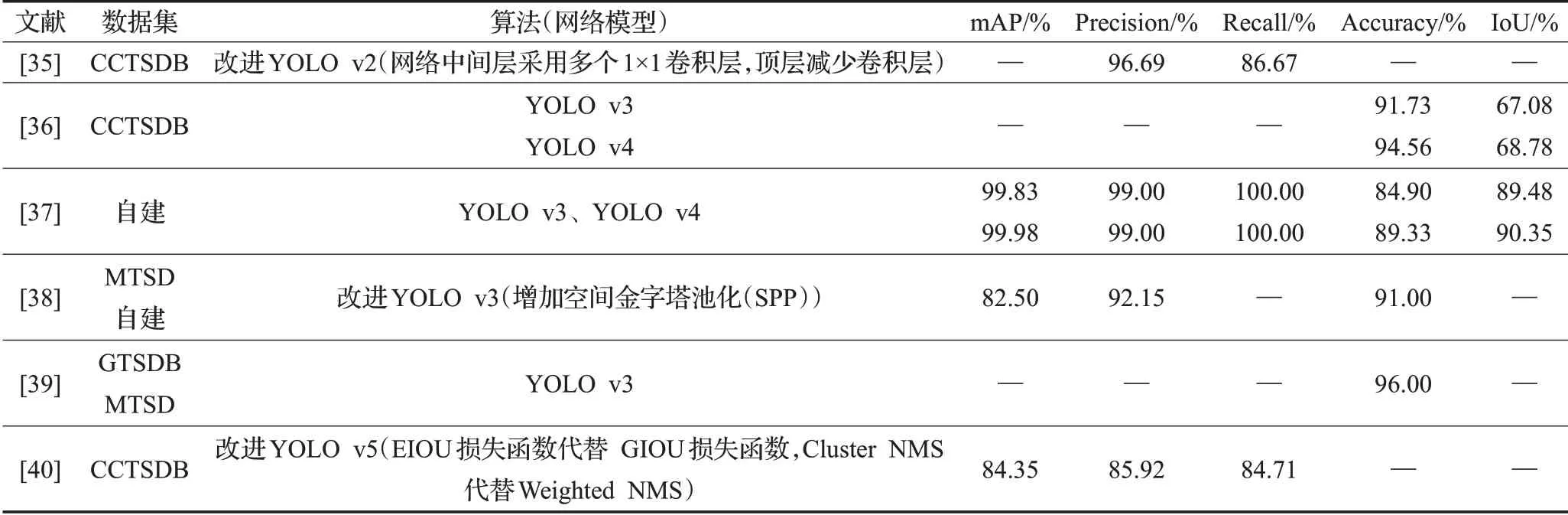
表4 交通标志的检测研究工作Table 4 Research work on detection of traffic signs
2.3.2 交通灯的检测
交通信号图像是道路上最重要的信息之一,交通信号灯检测是智能车辆和驾驶辅助系统的重要组成部分。
Jensen等[41]应用了实时目标检测系统YOLO,检测公共LISA交通灯数据集,该数据集包含大量在不同光照和天气条件下捕获的带标签的交通灯,达到了90%的准确率。Possatti等[42]使用YOLOv3模型,与智能汽车使用的先验地图相结合,识别预定义路线的相关交通灯。该实验的数据集分类过程中只考虑了两类对象:红-黄和绿交通灯。通过混合红色和黄色信号灯的方式,克服黄色样品的不足,实现实时的现实交通信号灯的检测。Gao等[43]使用YOLO v3和YOLO v4算法对道路上的交通信号图像进行检测和识别实验,结果表明,YOLO v4网络的准确率高于YOLO v3网络。
在交通信号灯的检测过程中,在较长时间内使用的公共数据集偏小,无法提供足够的标签来训练,深度神经网络。文献[41]通过合并样本的方式解决数据问题,文献[44]则创建了一个覆盖多种自然环境的大型的数据集。
2.3.3 交通车辆的检测
随着交通需求量的提升,道路交通压力也在不断的增加。不同的车辆类型都需要进行检测,包括机动车与非机动车。
叶佳林等[45]在YOLO v3框架下,设计特征融合结构和采用GIOU损失函数,降低非机动车漏检率,提高定位准确度。Zhou等[46]将毫米波雷达与摄像机信息融合,利用时空同步关联多传感器数据,通过YOLO v2算法实现深度融合对车辆的目标检测识别。张成标等[47]改动原YOLO v2网络框架,添加改进的残差网络(如图3)和Kelu激活函数来提高检测准确率,添加多尺度层来提升对图片中不同尺寸目标的检测精度。
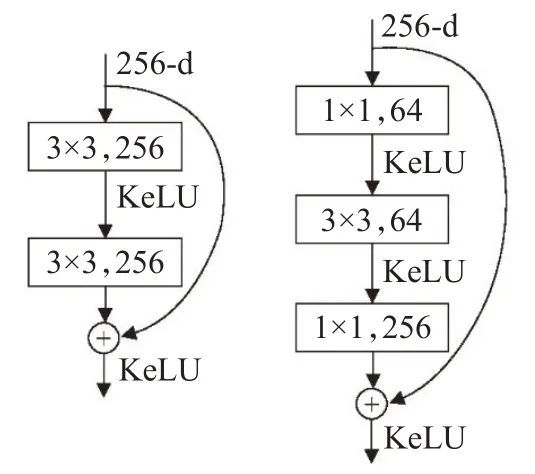
图3 改进残差结构对比图Fig.3 Comparison of improved residual structure
Chen等[48]提出YOLO v3-live,是在Tiny-YOLO v3的网络层结构上进行裁剪,量化网络中的网络参数,这种方式降低了嵌入式设备的计算复杂度,速度得到提升可以达到28 FPS,但是在同样的数据集上,mAP降低了18%。Wu等[49]在YOLO v5s神经网络结构的基础上,提出了YOLO v5-Ghost。调整了YOLO v5s的网络层结构。计算复杂度降低,更适合嵌入式设备。用该结构实现车辆和距离的实时检测,YOLO v5-Ghost的检测速度提高19 FPS,但是mAP降低3%。
在使用YOLO算法进行交通车辆的研究过程中,文献[45]使用GIOU损失函数,文献[47]添加KeLU激活函数来提升监测精度。文献[45]根据实际情况修改候选框的值、增加多尺度检测,能在一定程度上降低漏检率,提升不同尺度目标的检测精度(如表5所示)。上述文献所使用的数据集并不统一,测试出的准确度仅限参考。

表5 交通车辆的检测研究工作Table 5 Research work on detection of traffic vehicles
2.3.4 行人的检测
在交通中,行人同样是研究的重要部分。智能或无人驾驶车辆需要检测行人,识别他们的肢体运动,并了解他们行为的意义,然后再做出适当的响应决策。
Lan等[50]在YOLO v2的网络结构中,将穿透层连接数从16层改为12层,检测速度得到提升,同时由实验结果看降低了漏检率(Miss Rate)(如图4)。
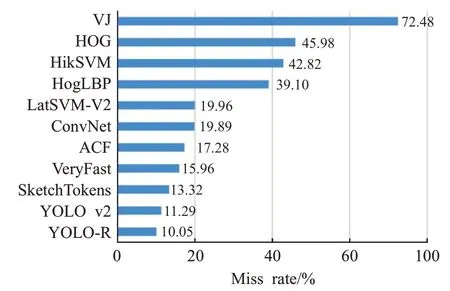
图4 各算法行人检测的漏检率比较Fig.4 Comparison of missing detection rates of pedestrian detection algorithms
高宗等[51]提出在原有的YOLO网络结构中,结合行人在图像中表现出小纵横比的特点,通过聚类选择合适数量和规格的候选帧,改变YOLO网络结构,调整候选帧在X轴和Y轴方向的分布密度,形成适合行人检测的网络结构。但是该方法将行人检测视为二分类问题,使得在行人动态变化的检测方面具有较大局限性。
郝旭政等[52]提出了一种基于深度残差网络和YOLO模型的行人检测与识别方法。Zhang等[53]的Caps-YOLO检测模型则基于YOLO v3,该模型采用dense connection代替了原有网络中的shortcut connection,构造了dense block组件,提高了feature map的利用率。同时采用向量神经元结合动态路由机制来实现该模型的检测功能,降低漏检和误检姿态复杂的行人的概率,在不同的数据集上精度提升1.81%~6.63%不等。Liu等[54]采用K-means聚类方法直接计算anchor使用数据集的帧大小。通过引入SE模块(squeeze-and-excitation networks,SENet)和集成DIOU(distance-IoU)损失函数。提高对智能驾驶系统中小尺度行人目标的检测精度。
Zhang等[55]基于Tiny-YOLOv3网络提出了在原有网络的基础上增加了三层卷积,提高了模型提取特征的能力;引入了1×1卷积核对特征进行降维,减少加深模型引起的计算量,保证了检测的实时性,但是仍存在漏检,小目标的识别不够准确问题。
进行行人的研究过程中,使用的数据集一般以PASCAL VOC为主,再与其他数据集结合,增大数据的样本集。在研究过程中会有增加或减少YOLO网络结构的操作,但是在现有的One-Stage的算法中,其精度还落后于Two-Stage的算法,减少网络层的方式能提高检测速度,却造成了精度的降低。虽然进一步修改网络结构是为提升精度或速度,但是在设计实施过程中还需更多的经验支撑(如表6所示)。

表6 行人的检测研究工作Table 6 Research work on detection of pedestrian
2.3.5 车道线的检测
实现高效的车道检测是无人驾驶车辆道路环境感知模块的重要组成部分之一,车道线检测的准确性同样影响到无人驾驶车辆的安全性。
Zhang等[56]构建了一个基于YOLO v3的两阶段学习网络,对YOLO v3算法的结构参数进行了修改,采用基于Canny算子的自适应边缘检测算法对第一阶段模型检测到的车道进行重新定位,并将处理的图像作为标签数据用于第二阶段模型的训练,提高复杂场景下车道检测的准确性。图5显示了KITTI和Caltech数据集上的P-R(精确召回)曲线的结果。基于YOLO系列的检测算法在车道检测方面优势明显,尤其是基于YOLO v3的S×2S结构模型表现最好。崔文靓等[57]在原YOLO v3的基础上,利用K-means++聚类算法优化网络anchor参数,并改进YOLO v3算法卷积层结构,使最终结果较原始算法平均检测准确率提升了11%。
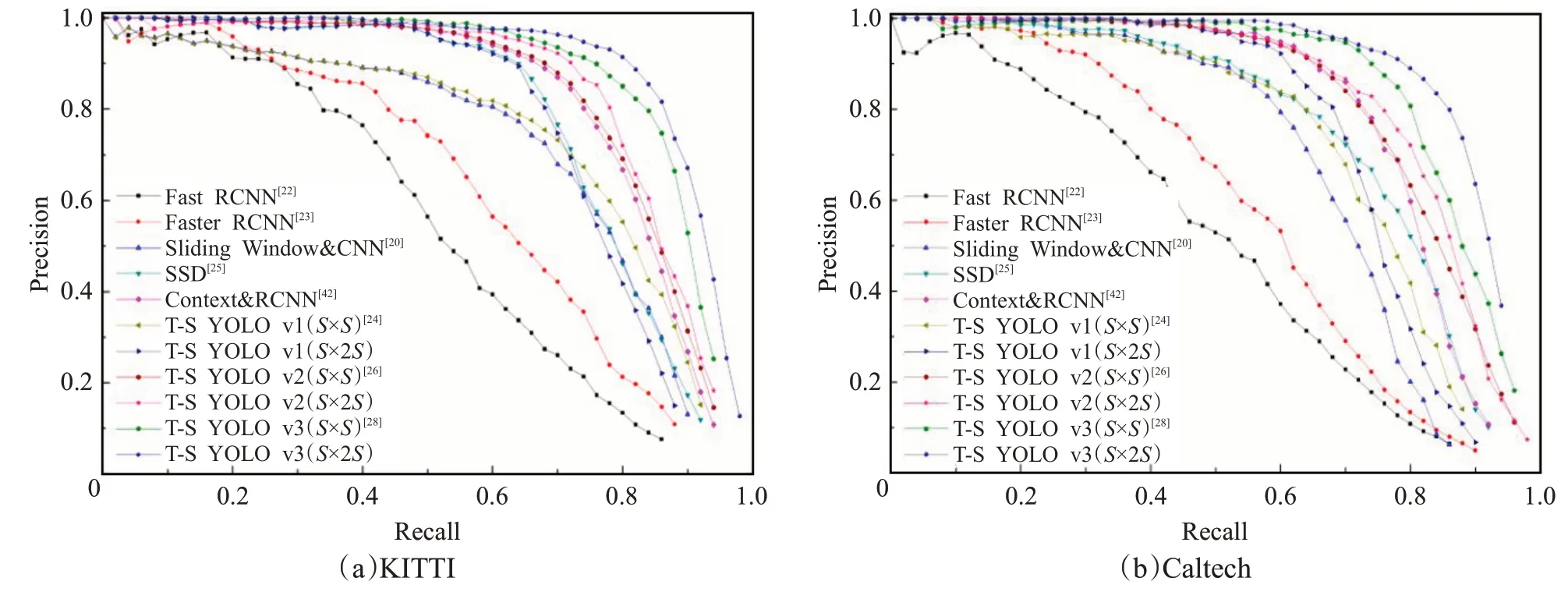
图5 两个数据集上不同算法的P-R曲线Fig.5 P-R curves of different algorithms on two datasets
Ji等[58]根据车道线图纵向和横向分布密度不一致的特点,将车道线图划分为S×2S网格,并简化网络将原YOLO v3算法中的卷积层从53层调整为49层,以及对簇中心距离和损失函数等参数进行了改动。最终平均检测准确率为92.03%,处理速度为48 FPS,该改动更适合于3车道线等小目标的检测。张翔等[59]同样采用S×2S网格密度的YOLO v3算法,并在双向循环门限单元(bidirectional gated recurrent unit,BGRU)的基础上,提出基于车道线分布关系的车道线检测模型(BGRU-Lane,BGRU-L)。最后利用基于置信度的D-S(Dempster-Shafer)算法融合YOLO v3(S×2S)和BGRU-L的检测结果,提高了模型检测小尺寸、大宽高比物体的准确度。
Deng等[60]采用MobileNetV3作为特征提取块,用引入了注意力机制CBAM(convolutional block attentionmodule)的YOLO v4和SegNet作为分支来检测车辆和车道线,适用于跟车场景的车辆和车道线多任务联合检测模型。
在进行车道线的研究过程中,文献[56]提出了一种标签图片的自动标注算法,丰富了数据集的同时提高了标注效率,文献[60]通过使用轻量级网络MobileNetV3提高网络检测速度,或者通过修改网络密度使算法更适用于车道线的检测。但是在对于大坡度以及复杂场景中的车道线的识别还存在局限性,需要进一步的进行研究(如表7所示)。
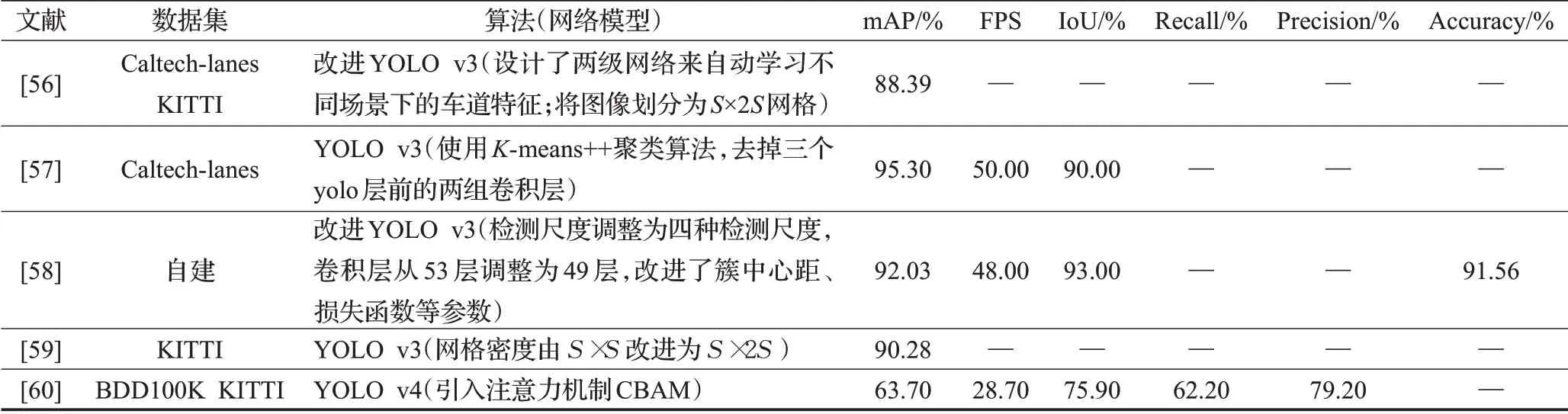
表7 车道线的检测研究工作Table 7 Research work on detection of lane line
3 应用挑战与发展方向
通过对基于YOLO算法的自动驾驶目标检测现状综述,了解到要拥有更精确和实时的检测效果,实现自动驾驶汽车的普遍推广应用,还面临众多挑战。本文针对这些挑战,提出如下可能的解决方案和潜在的发展方向:
(1)在检测上扩大目标检测的内容范围。以交通标志为例,道路设计的过程中,涉及到的交通路标远不止现阶段实验的标志,现阶段检测的交通标志以指示标志、禁止标志、警告标志为主,但是实际情况中还包含众多的指路标志和辅助标志。对于这些标志还需进一步扩展相关数据集、设计能够理解道路规则和其他道路使用者行为的自动驾驶车辆,以确保自动驾驶车辆在停车标志、减速标识、红灯及会车等情况自动降低车速,做出合理应答。
(2)在检测场景上进一步考虑多种复杂环境,有效控制复杂环境对检测效果的影响。仿真测试验证是现在自动驾驶测试领域的主要使用手段,仿真环境的可信度直接影响着测试结果的准确度,现阶段的仿真往往会忽略掉一些环境因素对其准确性的影响,在未来的仿真测试中考虑包括雾霾、大雨等自然环境干扰,添加场地、交通对其的影响,将实验室效果越接近自然且真实的环境,越能降低现场测试的成本。
(3)训练深度学习模型需要大量数据,庞大的计算量会降低检测速度,所以可以通过加入轻量级网络,如MobileNet系列、ShuffleNet系列等保证网络的实时性,同时通过改变参数和相关函数提升检测精度。
(4)自动驾驶车辆的通信资源宝贵,计算资源有限,当系统的计算资源出现不足时将严重影响自动驾驶车辆目标检测的精度。随着网络技术的发展,可以通过网络共享协同的方式,将周边不同车辆的检测内容进行共享,减少网络的数据处理量,进一步提升检测实时性。但同时也要注意关注信息冗余,减少不必要信息的共享,避免资源浪费。
4 结束语
深度学习方法助力着自动驾驶目标检测技术的快速发展,是未来的重要研究方向之一。本文综述了YOLO系列算法和自动驾驶车辆的发展历程及其在自动驾驶目标实时检测中的应用,将该方法应用到真实环境中还面临着许多挑战。
在交通标志的检测过程中由于数据集采集标注的问题,交通标志的识别类别不够完整;在交通灯的检测过程中,黄灯数据集偏小,对于深度学习的准确性产生了一定的影响;在车辆及行人的检测过程中,关注于改进网络结构以及损失函数;在车道线的检测过程中,会选择将算法的网格密度修改为S×2S。
通过不同的方式不断的改进自动驾驶目标检测的实时性与精确性,但是现阶段的实验结果还存在一定的局限性,同时在综述过程中发现文章关注的性能不同,导致罗列较多性能但是同样的性能对比却不多。同时新阶段YOLO系列的算法在不断更新,推出了YOLO-X版本,但是YOLO-v4后的研究论文还有一定的空缺,需要进一步从不同角度进行研究。
猜你喜欢
汽车实用技术(2022年9期)2022-05-20
卫星应用(2021年11期)2022-01-19
科学大众(2021年9期)2021-07-16
中国交通信息化(2020年11期)2021-01-14
学生天地(2020年5期)2020-08-25
汽车与安全(2017年7期)2017-09-12
小天使·一年级语数英综合(2017年3期)2017-04-25
莫愁(2017年9期)2017-04-07
汽车博览(2016年9期)2016-10-18
小天使·一年级语数英综合(2016年8期)2016-05-14
