
基于DNN-HMM的佤语语音声学建模*
2022-08-09 06:16贾嘉敏潘文林
计算机时代 2022年8期
贾嘉敏,程 振,潘文林,王 欣
(1.云南民族大学数学与计算机科学学院,云南 昆明 650500;2.云南民族大学电气信息工程学院)
0 引言
语言是人类彼此传递信息最便捷的工具,更是文化传承的重要载体。汉语和少数民族语言作为中华民族的文化基石,更是中华民族最为重要的符号象征。随着经济的发展和各民族文化的不断融合,对少数民族语言文化遗产的传承与保护愈加体现出无可替代的重要性;其中对于跨中缅边境的少数民族——佤族,为维护边境稳定、增强国家认同,对其语言的传承保护则更凸显重要。相比于语言资源较为丰富的藏语、维吾尔族语等语种,佤语由于缺乏有声语档及语料库资源的建设,其语音识别研究还处于起步阶段。
目前,对于佤语的语音识别研究工作中,陈绍雄等在HTK 平台上实现非特定人的佤语孤立词语音识别,建立训练HMM 模型验证其可行性;和丽华等使用基于多窗谱估计谱减法和能熵比法的语音端点检测复合算法对佤语语音进行仿真实验,其准确率为82%;王翠等利用傅里叶变换将佤语转换为对应的语谱图信息,将AlexNet 模型用于佤语语谱图识别,其识别精度达96%。杨建香基于ResNet网络的佤语语音语谱图识别率达90.2%,证明其模型系统具有良好的鲁棒性。这些工作都获得了相当不错的成果,但是这些工作主要是以孤立词的语谱图为识别单元进行分类研究,这样就存在明显的缺陷,即以孤立词为识别单元,随着语料库规模的不断扩大,新词也会不断出现,在佤语语音识别系统中可能会出现较多的未登录词(out of vocabulary,OOV)问题,所以建立覆盖佤语中所有孤立词的发音词典具有一定的难度。同时以数量规模庞大的孤立词为识别单元的话,模型的复杂度会随之更高,进而影响模型的识别性能。所以,结合佤语的语音特点,可将孤立词分解为更小的音素结构,其中佤语仅有214个音素。若以音素作为佤语语音识别系统的识别单元,随着语料库规模的扩大,识别单元的数量并不会再增加,可有效解决未登录词的问题。故本文在结合佤语语音特点的基础上,设计基于音素的佤语语音声学模型。
结合佤语语音的结构特点,本文选取音素作为佤语语音的识别单元,构建深度神经网络-隐马尔科夫模型(DNN-HMM)的佤语声学模型。为提高佤语语音特征的区分度并减少说话人口音对声学建模的影响,采用线性判别分析(Linear discriminant analysis,LDA)、最大似然线性变换(Maximum likelihood linear transformation,MLLT)和说话人自适应训练(speaker adaptive training,SAT)对模型输入的语音特征进行优化训练,从而提高佤语声学模型的鲁棒性。
1 模型介绍
1.1 深层神经网络
深层神经网络(Deep Neural Networks,DNN)是经典的前馈神经网络之一,主要由输入层、隐藏层和输出层三部分构成,DNN的结构如图1所示。其中,输入层为输入的语音声学特征,中间的隐藏层为多层感知器,其中相邻层的神经单元以全连接的方式传送信息,层与层之间的参数则通过误差反向传播(Back Propagation,BP)算法进行优化调整。输出层是一个线性的分类器,使用Softmax 函数对激活值进行归一化处理,得到声学的输出特征和每个神经元对应的概率。由于DNN 拥有更多层的非线性变换器,使其在处理语音声学特征方面,对语音等复杂信号建模的能力则更强大,优势更显著。
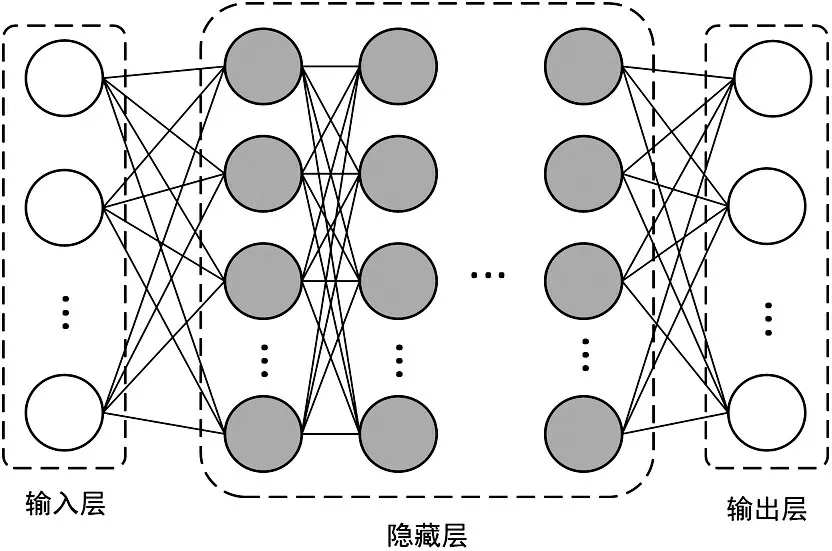
图1 DNN网络结构
1.2 DNN-HMM声学模型
声学模型是语音识别中最核心的部分,对最终的识别效果起着非常重要的作用。相较于传统的GMM-HMM 声学模型,DNN-HMM 模型使用DNN替换GMM 对输入语音信号的观测概率进行建模,将相邻的若干帧进行拼接得到包含更多信息的输入向量,更有利于利用语音相邻帧之间的结构信息。并且在训练过程中DNN会采用随机优化算法,使得到的声学模型更精确,更有利于提高语音识别的性能。因此,本文将采用DNN-HMM作为佤语语音识别的声学模型。
在佤语声学模型训练时,由于DNN-HMM 所需的每个孤立词的音素标记是由GMM-HMM 做强制对齐时得到的,因此在进行DNN-HMM 声学模型构建时,首先需训练得到GMM-HMM 模型。而且由于DNNHMM 与GMM-HMM 使用同样的HMM 模型,所以可将已经训练好的GMM-HMM 模型中的HMM 迁移到DNN-HMM 模型中的HMM。
DNN-HMM 模型使用内嵌的维特比算法进行训练,使用40 维的FBank 特征作为基于DNN-HMM 的佤语声学模型的输入,标注的音素信息为期望输出,利用之前训练好的GMM-HMM 模型,通过强制对齐给每一帧打上HMM 状态标签,然后依此标签训练DNN 模型参数,得到DNN 模型的softmax 输出,即HMM 模型对应的观测概率。但由于DNN 只能给出观测值输入到DNN 输出层之后在每个节点上的后验概率(q|o),故通过贝叶斯定理进行转换,得到观测概率(o|q):
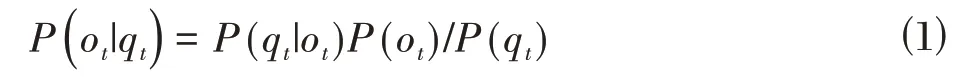
其中,o为输入语音特征,q为所有三音素状态的集合,(o)为观测概率,(q)为各状态的先验概率。至此,便完成了基于DNN-HMM 的佤语语音识别声学模型的构建。一个M隐层的DNN-HMM 结构如图2所示。
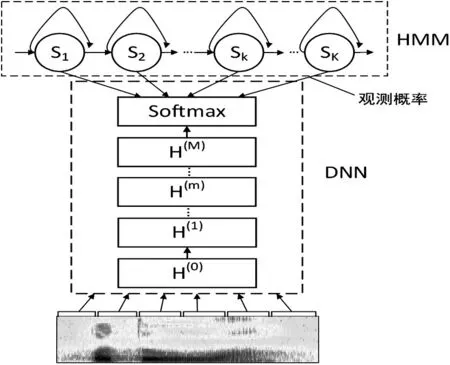
图2 DNN-HMM模型结构图
2 佤语语料库与识别基元的选择
语音语料库作为整个语音识别系统的基础,对于最终的识别性能和识别率具有极其重要的的作用。本文使用的语料库为在录音棚由二男二女录制的1000 个孤立词(每个词录制五遍)共计20000 条语音数据。重复朗读多遍的目的是使每个音素和三音素出现的次数增多,从而保证每种声学模型的健壮性。共生成包含214个音素的20000条佤语语音语料。
在本实验中,设置采样频率为16000Hz,采样精度为16位,声道为单声道。对于录音文件的命名规定为:说话人id_语音id_录制遍数id.wav。例如:PFA_45_01.wav 表示女性人员(People_Female)中的第一个人(A)录制第45 条语料的第一遍录音,PMB_254_04.wav 表示男性人员(People_Man)中的第二个人(B)录制第254条语料的第四遍录音。录制完成后,以人员编号为文件夹分别存放每人的录音。
佤语属南亚语系孟高棉语族佤德语支,没有声调,人们说话是一个音节一个音节说的,而每个音节由声母和韵母组成,其中声母部分由辅音音素构成,韵母部分则由元音音素构成。因此,音素为佤语语音学中最小的发音单元。根据佤语语音的结构特点,本文将选取音素作为佤语语音的识别单元。佤语语音共计214个音素,包含52个声母和162个韵母,其中单辅音有36个,复辅音有16 个;单元音78个,复元音84个。
由于佤语声学模型的设计与佤语的发音特点密切相关,若简单以单音素作为识别单元则容易忽略每个音素所受左右相邻音素的影响,不能准确的捕捉到音素的发音细节,本文考虑建立上下文相关的三音素模型,整个训练过程分为单音素模型的训练和三音素模型的训练。
3 实验
本文实验在Ubuntu20.04 系统上,采用kaldi 开源语音识别平台进行训练与测试,同时配置NVIDIA 的GPU 进行加速。实验主要是在/kaldi-truck/egs/wayu/s5/下进行。佤语语音识别的具体流程如图3 所示,本文将重点放在声学模型的训练及解码。
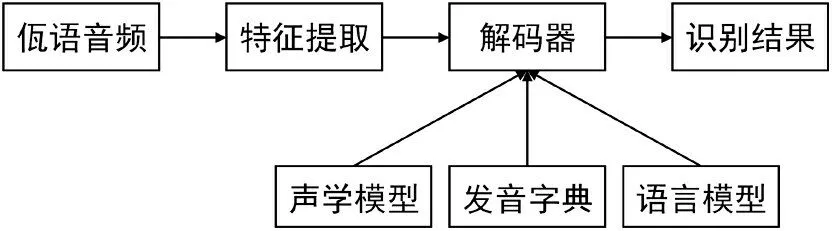
图3 佤语语音识别流程
3.1 数据准备
本文需识别出完整的佤语孤立词,对于将被识别的词,计算机必须有对应的发音规则与标注。为了把词与其发音一一对应起来,参照《佤汉大词典》建立语音词典,生成lexicon.txt、extra_questions.txt、nonsilence_phones.txt、silence_phones.txt 和optional_silence.txt五个文件。对于语音数据,使用kaldi生成声学模型所需的四个文件:wav.scp、text、utt2spk 和spk2utt。
在佤语声学模型构建中,为验证音素为识别单元的有效性,数据集的划分如下设计:佤语说话者共有4人,选取每个说话人的前900 个词为训练集,剩余100个词为测试集,其中保证前900 个词覆盖所需训练的全部音素。则共计18000 条语料作为模型的训练集,2000条为测试集。
3.2 佤语语音识别性能评判标准
本文采用词错误率作为佤语语音识别性能的评价标准,其中词错误率的计算方式为:
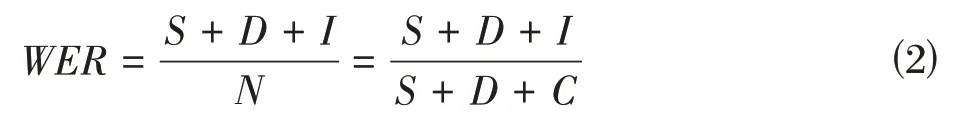
其中,代表被替代词的数量,代表缺失词的数量,代表插入词的数量,代表正确识别的词的数量,代表语料库中的总的单词数。
3.3 基于音素的声学模型训练
本文DNN-HMM 模型参数设置为:输入特征是40维FBank,并且相邻的帧由11帧窗口连接。DNN模块由4 个隐藏层组成,每个层有1024 个单元;采用交叉熵的标准训练,并使用随机梯度下降(SGD)算法来执行优化。Mini-batch的大小设定为256,初始学习率设定为0.008。具体的声学模型训练过程如下。
Step1:对于输入的佤语语音信号首先开始特征提取,选取MFCC 特征(存储13 维)作为网络的输入,并计算CMVN,存储每个说话人的均值、方差和帧数。
Step2:接着做语言模型的准备,本文采用的语料以孤立词为主,故使用基于音素的三元文法(Tri-Gram)模型作为语言模型进行建模,利用SRILM 工具训练生成phone.3gram.lm。
Step3:然后进行GMM-HMM 声学模型的训练,将提取的语音特征作为模型输入,以单音素作为声学模型的训练单元,训练单音素模型Mono,一共进行40次迭代,每两次迭代进行一次对齐操作,通过迭代训练,最后生成模型final.mdl。
Step4:在上一步的基础上进行三音素模型(Tri1)的训练,并将数据对齐完成之后,在Tri1模型的基础上依次进行LDA_MLLT 变换训练得到模型Tri2,再进行SAT 说话人自适应训练得到模型Tri3,逐步实现特征参数的优化训练。
Step5:在Tri3 的基础上,将GMM 替换为DNN 进行训练,调整网络的结构和参数,完成DNN 网络的训练,进而实现基于DNN-HMM 佤语声学模型的构建。
对上述所有得到的模型均做解码测试(decode),即对每个模型都进行WER 识别评分。其训练过程如图4所示。
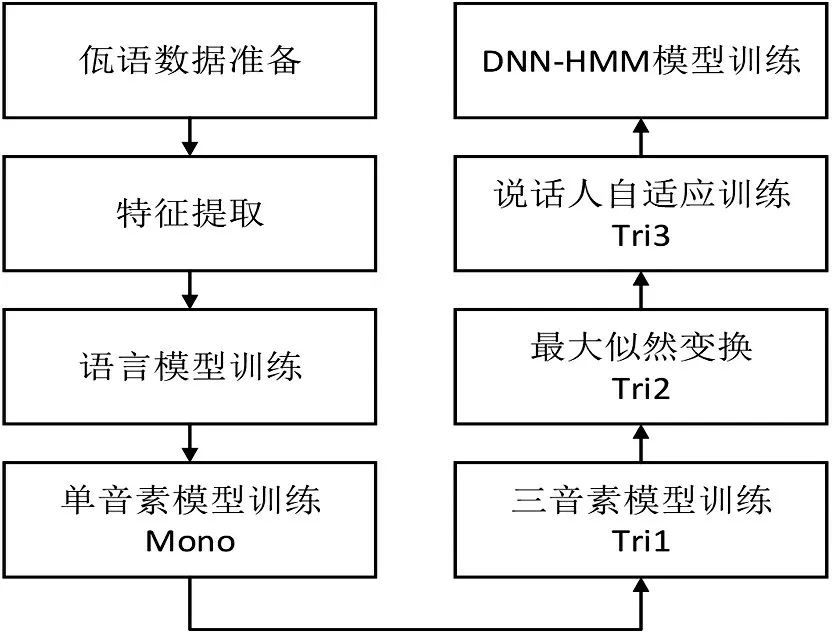
图4 佤语语音识别模型训练
3.4 结果分析
3.4.1 不同识别单元对识别性能的影响
为验证音素作为识别单元的有效性,实验选取不同的识别单元进行对比实验,分别以孤立词和音素作为识别单元。由于实验数据集以孤立词为主,不能构建孤立词的三音子模型,所以以孤立词的单音子模型和单音素模型(Mono)进行对比实验,结果如表1所示。从表中可以看出,当孤立词作为识别单元时,未登录词对佤语语音识别性能的影响很大,未登录词被系统识别时识别成其他孤立词,导致词错误率很高。当音素作为识别单元时,词错误率明显下降,模型识别的性能优势凸显。

表1 不同识别单元的识别性能对比
3.4.2 不同声学模型的对比分析
实验以音素作为识别单元,尝试多种声学模型的优化训练,并对每种声学模型分别构建解码图,使用decode.sh 以声学模型和测试数据为输入计算WER。将DNN-HMM 模型与传统的基于GMM-HMM 模型的四种声学模型(Mono、Tri1、Tri2、Tri3)进行实验对比,比较不同声学模型的词错误率,结果如表2 所示。从表中可看出,基于DNN-HMM 的声学模型明显优于GMM-HMM 模型,词错误率实现29.24%,更适合佤语语音信号的声学建模。

表2 不同声学模型的识别性能对比
4 总结
本文针对佤语语音识别声学模型的构建问题展开研究,提出了基于音素的佤语语音识别的总体框架,建立佤语语料库,采用FBank语音特征作为声学模型输入,利用DNN模型对佤语语音特征进行建模。实验表明,与GMM-HMM 模型相比,DNN-HMM 更适合声学建模,词错误率进一步降低,取得了较好的效果。但是,由于目前建立的佤语语料库规模比较小,识别性能并不够理想,所以接下来将进一步丰富佤语语音数据规模,扩充佤语句子语料库,在优化改进声学模型的同时探究语言模型,以进一步降低佤语词错误率。
猜你喜欢
北京教育·普教版(2020年9期)2020-10-09
家庭影院技术(2020年6期)2020-07-27
校园英语·中旬(2019年11期)2019-11-26
新课程·上旬(2019年1期)2019-03-18
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年10期)2018-11-02
疯狂英语·新策略(2018年7期)2018-08-29
教师·中(2017年3期)2017-04-20
试题与研究·教学论坛(2016年27期)2016-08-11
