
深度学习下的目标跟踪综述*
2022-08-09 06:16陈浩东蒋鑫张桓玮
计算机时代 2022年8期
陈浩东,蒋鑫,张桓玮
(南京理工大学计算机科学与工程学院,江苏 南京 210094)
0 引言
基于视频的目标跟踪是在得到视频序列中目标初始状态的情况下,预测后续序列中目标的大小、位置和方向等状态信息。视觉跟踪技术无论是在军用还是民用领域都具有重要的研究意义和广阔的应用前景。
本文主要内容如图1所示,主要贡献如下:
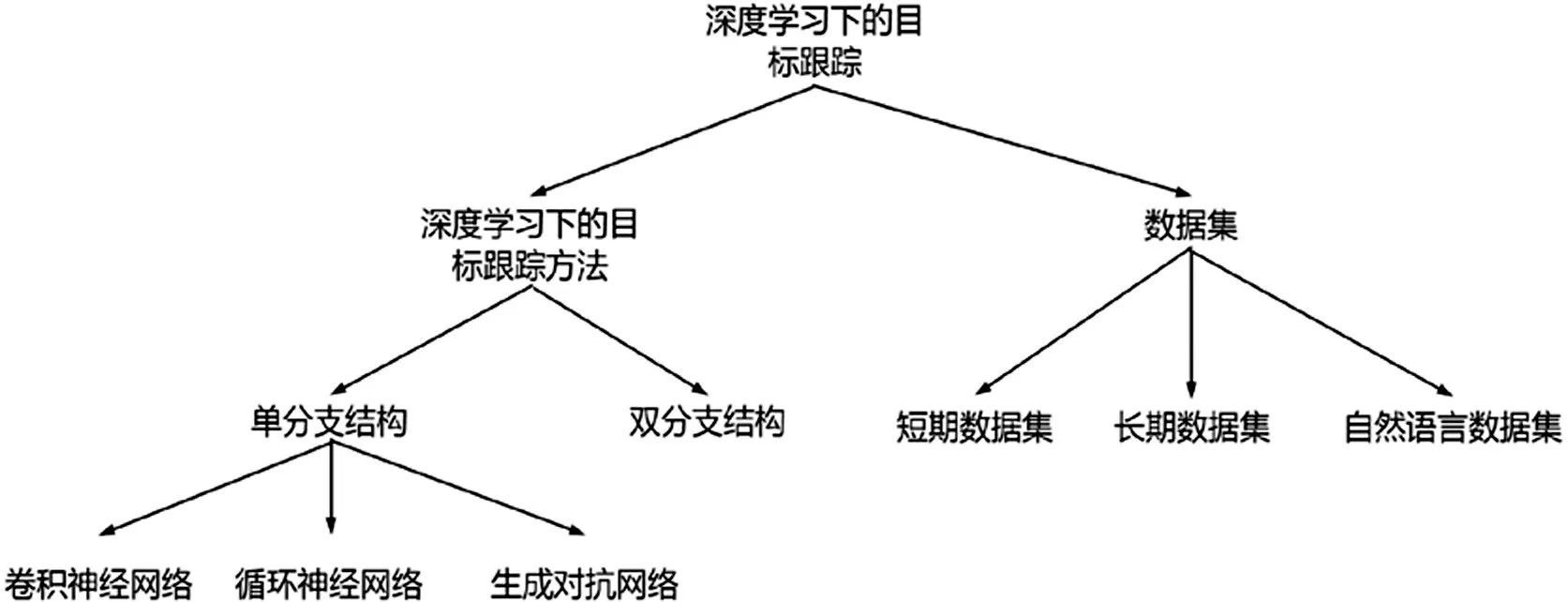
图1 深度学习下的目标跟踪方法
⑴以深度学习下目标跟踪方法的网络结构为出发点,对基于卷积神经网络、基于循环神经网络、基于对抗生成网络和基于孪生网络的目标跟踪方法的发展进行了总结。
⑵对常用的数据集进行的对比和分析,作为研究工作中选择数据集的一个参考。
⑶总结了目前目标跟踪领域存在的问题,展望了视觉目标跟踪技术的发展趋势。
1 目标跟踪方法
1.1 单分支网络
1.1.1 卷积神经网络
卷积神经网络(CNN)方法在计算机在计算机视觉领域取得突破后,一系列基于CNN 的方法被提出,它们的研究动机可以归为以下几点。
使用大数据预训练的卷积神经网络:MDNet和UCT,它们使用ResNet等深度卷积网络提取图像特征。
融合多层深度图像特征:Wang 等人在FCNT 中发现顶层的特征包含更多的语义信息可以用作检测器,较低层携带更多判别信息,可以更好的将目标与具有相似外观的干扰物区分开来。基于以上发现,Wang等人提出了融合多层深层图像特征的FCNT。
相关滤波方法:这类方法将模型与相关滤波方法结合,发挥了CNN的特征表征能力和相关滤波的速度优势。C-COT将CNN 与相关滤波结合后,取得了极大的轰动,ECO还针对相关滤波方法的计算复杂度问题进行优化。
1.1.2 循环神经网络
MemTrack引入了可动态更新的动态存储网络,由具有注意力机制的LSTM 控制的外部记忆块适应外观变化。SANet在模型的学习过程中利用RNN结构对对象的自结构进行编码,不仅提高了模型区分类间背景对象的能力,还提高了类内类似干扰项的能力。
1.1.3 生成对抗网络
生成对抗网络(GAN)虽然难以训练和评估,但还是有基于深度学习的方法利用GAN 生成训练样本VITAL针对基于检测的跟踪中存在的正样本过少负样本过多的问题,使用GAN来增加特征空间中的正样本,以捕获时间跨度内的各种外观变化。
1.2 双分支网络
双分支网络即孪生网络,基于孪生网络的目标跟踪算法思想是学习一个鲁棒的外观模型,并训练一个相似度匹配函数,通过相似度匹配函数寻找到当前帧的目标区域。孪生网络的研究动机可以划分为研究判别性目标表示和自适应目标变化两部分。
1.2.1 判别性目标表示
孪生网络为了得到更具判别性的深度图像特征并提升外观模型的,孪生网络采用了以下方法。
⑴采用更深层的神经网络:Zhang 等人提出了SiamDW 算法,通过设计一个残差结构消除深度网络带来的负面影响,同时调整了主干网络的步长和感受野,将ResNet引入了孪生网络,在SiamFC上进行了实验验证,取得了较原始模型更优异的性能。
⑵融合多层深度图像特征:Fan 等人提出了使用了级联区域推荐网络(RPN)的C-RPN。C-RPN 通过多层RPN 网络,逐层筛选其中属于负样本的anchor,将模型视为正样本的anchor 输入到下一层的RPN 网络,在复杂的背景下如存在相似语义障碍物时能够取得更加鲁棒的表现。
⑶精确的目标估计:Zhang 等人提出的Ocean基于像素级的训练策略:将在真实边界框内的所有像素视为正样本,边界框外视为负样本,训练出的回归网络即使目标只有一个小区域被识别为前景,也能预测目标对象的尺度。
⑷向深度图像特征施加注意力:Yu等在SiamAttn在目标分支和搜索分支中分别做self-attention 操作,实现对通道和特殊位置进行关注。在搜索分支和目标分支之间进行了cross-attention计算,让搜索分支学习到目标信息。此外,类似工作还有TranT和STARK,它们向深度特征施加注意力的方式如表1所示。

表1 目标跟踪方法提出的施加注意力的方法
⑸ 利用性能更强的相似度匹配函数:Chen 等人提出的TransT 通过将原本孪生网络跟踪器的相关运算(如深度互相关)替换成了Transform-er中的attention运算,有效地解决了孪生网络中相关性计算的局部线性匹配问题。此外,类似的工作还有STARK和SiamGAT,它们的相似匹配函数如表2所示。

表2 目标跟踪方法提出的相似匹配函数
1.2.2 自适应目标外观变化
⑴在线更新方法:Zhang等人提出了UpdateNet,通过训练得到UpdateNet 的参数,将初始模板、上一帧计算模板和上一次计算出的模板输入到网络中,得到新的模板,用新的模板进行相似性计算。
⑵将跟踪视为检测任务:Voigtlaender 等人将Faster R-CNN应用到目标跟踪上,利用一个来自第一帧的重检测模型和来自历史帧的重检测模型,对当前帧进行检测,以得到最终目标位置。
2 数据集
随着目标跟踪领域的发展,规模越来越大、场景越来越多的目标跟踪数据集被提出,如图2所示。根据数据集中单个视频序列的长度可分为短期目标跟踪数据集和长期目标跟踪数据集。短期目标跟踪数据集如OTB2015、VOT2017、UAV123、TrackingNet、GoT-10k等,长期目标跟踪数据集包括LaSoT、OxUvA等。此外,Wang等人提出了自然语言规范跟踪的多媒体数据集:TNL2K 数据集,表3 主要总结了上述数据集的信息。

图2 深度学习下数据集的发展
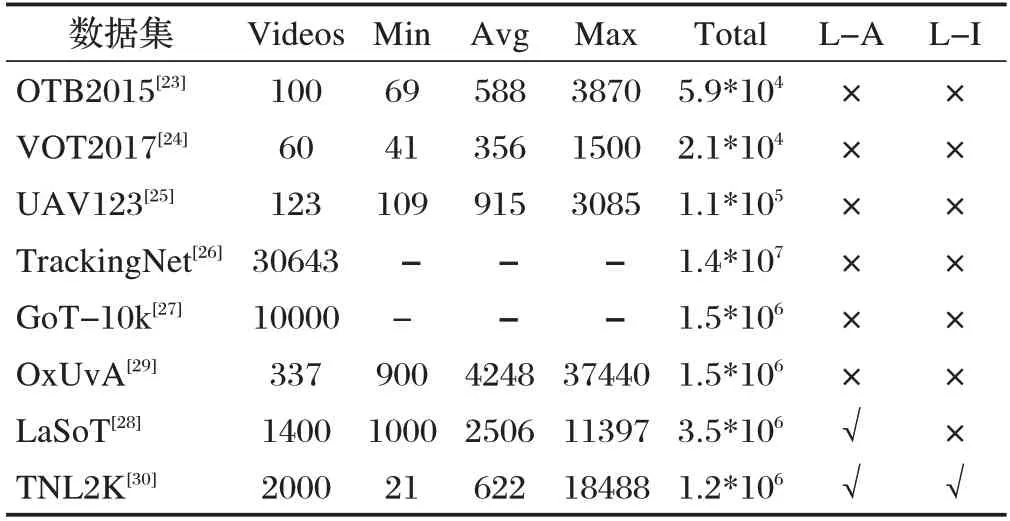
表3 不同数据集信息对比
⑴OTB数据集
OTB 数据集包含光照变化、目标尺度变化、遮挡、目标形变等总共11 种视觉属性,此外还包含25%的灰度图像。OTB 数据集将精确图、成功图、鲁棒性评估作为数据集对模型的评价指标。鲁棒性评估包括一次性评估、时间鲁棒性评估和空间鲁棒性评估。
⑵VOT数据集
VOT 数据集包含相机移动、光照变化、目标尺寸变化、目标动作变化和遮挡等6种视觉属性。VOT数据集的主要评估指标为预期平均重叠、准确率和鲁棒性。
⑶UAV123数据集
UAV123 数据集是Mueller 等人在2016 年提出的基于无人机视角的低空目标跟踪数据集,与OTB,VOT等使用常规摄像机拍摄的数据集存在本质区别。UAV123 数据集包括纵横比变化、背景干扰、摄像机移动、完全遮挡、光照变化等总共12种视觉属性。UAV123数据集采用与OTB 数据集相同的模型评估策略。
⑷TrackingNet数据集
TrackingNet 数据集接近真实世界的目标跟踪任务,密集的数据注释使目标跟踪模型的设计能更偏重于挖掘视频序列中目标的运动信息。TrackingNet 使用OTB 数据集中采用的一次评估策略,并将成功率和精度作为评估指标。
OxUvA 中视频序列的平均时长超过2 分钟,且OxUvA 中超过一半的视频都包含目标消失的情况,贴近真实世界的情况,对目标跟踪模型的性能提出了更高的要求。
值得注意的是OxUvA 每30 帧才标注1帧,因此,虽然OxUvA数据集的数据量非常大,但它适合用于模型评估,而不是用于训练。
GoT-10k 数据集总共包含563 种目标类别和87种运动模式。GoT-10k提供了目标对象的可见率,表示目标对象可见的大致比例。可见率为发展处理遮挡问题的跟踪方法提供了便利。模型评估上,Huang 等人选择具有明确含义且简单的指标:平均重叠和成功率作为数据集的评估指标。
LaSoT 包含1400 个视频序列,包含70 种目标类别,每个类别包含20 个视频序列,减少目标类别给目标跟踪模型带来的影响;每个视频序列都包含户外场景的各种挑战;每个视频序列平均长度超过2500 帧。此外重要的一点在于LaSoT 除传统的BBox 注释外,还为每个视频序列添加了自然语言注释,使其能够用于自然语言辅助目标跟踪任务。
TNL2K 包含了17种视觉属性,总计2000个视频。在注释方式上,每个视频使用自然语言注释,指示了第一帧中目标对象的空间位置、与其他对象的相对位置、目标属性和类别,使其能够用于自然语言规范目标跟踪任务,并为该视频中的每一帧注释一个边界框。评价指标上依旧采用了流行的准确图和成功图。
3 总结
回顾基于深度学习的目标跟踪算法的发展,很多在目标跟踪上取得成就的技术都是来自深度学习的其他领域的理论,如自然语言、注意力机制等。如何更好的利用这些已引入的理论以及如何从其他领域引入新的理论,将是基于深度学习的目标跟踪算法现在以及未来的研究热点。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
电子制作(2019年19期)2019-11-23
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
质量与标准化(2015年9期)2015-07-10
海军航空大学学报(2015年4期)2015-02-27
浙江人大(2014年5期)2014-03-20
