
基于解耦表征变分自编码机的雷达目标识别算法
2022-08-08 03:08:30张晏合臧月进徐铭晟
空天防御 2022年2期
张晏合,臧月进,陈 渤,徐铭晟
(1.西安电子科技大学雷达信号处理国家级重点实验室,陕西西安 710071;2.上海机电工程研究所,上海 201109)
0 引 言
雷达作为战场中的“眼睛”,能够利用电磁波对其作用范围内的空中目标、陆地目标以及海洋目标进行检测、监视和识别。现代战争日益趋向“高技术化”,如何精准地进行攻防对抗是关键。随着远程打击平台的作战范围越来越大,仅获取目标的位置信息往往无法满足现代军事需求。如何对雷达所获取的回波信号进行准确的分析、处理,提取更多有效的信息,并据此信息做出判断,实施精准反击,在战争的走向中发挥着重要的作用。因此,雷达自动目标识别技术(radar automatic target recognition,RATR)受到了极大的重视。
雷达高分辨距离像(high resolution range profile,HRRP)是宽带雷达信号获取的关于目标的散射点子回波在雷达视线上的矢量和,如图1所示(图中圆圈代表目标散射点),它包含了诸如目标尺寸、物理结构等丰富的目标结构信息,并且易于获取,因此被广泛地用于雷达自动目标识别领域中。
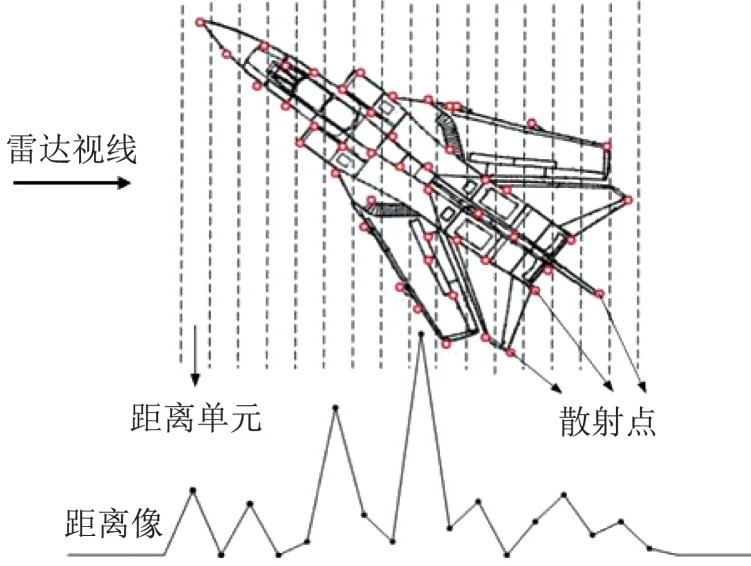
图1 飞机目标的HRRP样本图[2]Fig.1 Representation of HRRP samples from aircraft targets
在RATR 中,有效的特征不仅可以减少系统的复杂性,也可以显著提升识别方法的性能。因此,如何提取有效的特征成为雷达自动目标识别的核心问题。针对这一问题,雷达自动目标识别的学者们进行了广泛的研究。文献[3]中采用基于双谱特征的HRRP 识别方法,有效地减少了噪声对识别的影响。文献[4]采用了高阶谱特征,并提出了基于欧式距离的度量标准提升了识别性能。文献[5]利用了平移初相稳健的快速傅里叶变换幅度特征,完成了HRRP 的识别工作。这些方法均取得了不错的识别性能,但是这些人工设计的特征通常依赖研究人员对数据的认知,在缺乏先验知识的情况下,难以保证这些方法的性能。此外这些模型多为浅层模型,在任务场景更加复杂的情况下,并不能提取有效的特征信息。因此,如何自动提取有效的特征成为RATR热门研究方向。
近年来,经网络的判别模型方法被广泛应用于机器学习任务,并在RATR中获得了优异的性能表现。这些方法可以分为两大类。第一大类中,神经网络被用于判别模型,直接用于对HRRP数据的识别工作,如文献[6]提出了基于注意力机制的循环神经网络高分辨距离项目标识别方法,文献[7]提出了基于卷积神经网络的高分辨距离项目标识别方法,但是这些方法的识别率并不高。第二大类中,神经网络被用来提取较好的HRRP数据表征以提升后续分类器的识别性能,例如:文献[8]提出了堆栈纠正自编码机(stacked corrective autoencoder,SCAE)的结构提取HRRP特征,该模型不仅考虑了单帧样本信息,也考虑了平均像信息;文献[9]对变分自编码机结构进行改进,提出了稳健变分自编码机(robust variational auto-encoder,RVAE),它相对于变分自编码机能提取更加稳健的特征,并能利用这些特征完成后续的分类工作;文献[10]提出了可学习先验变分自编码机(variational auto-encoder with learnable prior,LP-VAE),该模型借鉴了训练数据的标签信息,其提取的特征信息显著提升了RATR的识别率。但是,这些方法在对隐表征建模的时候并没有考虑各类表征间的联系。
为了解决上述问题,本文提出了解耦表征变分自编码机模型来提取高分辨距离像表征。该模型以变分自编码机模型(variational auto-encoder,VAE)作为基本组件,在原有的变分自编码机模型基础上,对类间共性表征和各类特性表征分别建模,并采用变分下界进行优化,使各类特性表征有更强的可分性。在实测数据上的实验结果表明,通过该方式提取的特征能显著提升雷达高分辨距离像的识别性能。
1 变分自编码机简介
变分自编码机是一种概率生成模型。通过该模型可以得到观测数据的隐表征。观测数据与隐表征的联合概率分布为

由于式(3)中的期望求解较为复杂,我们使用采样的方法对变分证据下界进行近似的估计,其表达式如下:
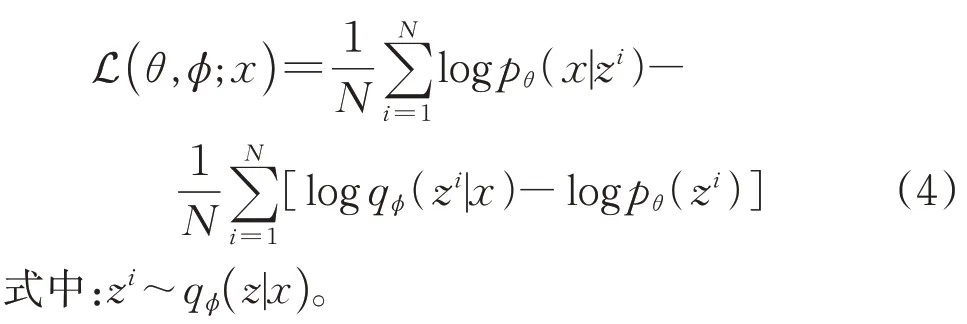
变分自编码机由编码器网络和解码器网络两部分构成,其基本结构如图2所示。
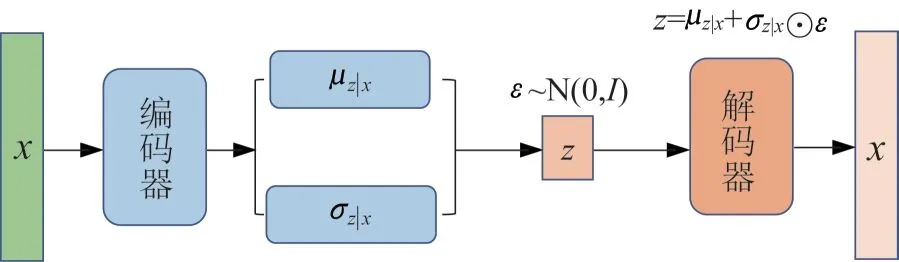
图2 变分自编码机结构Fig.2 The architecture of variational auto-encoder
编码器代表近似后验分布q(|)的充分统计量;解码器代表观测数据的条件概率分布p(|)的充分统计量。在训练中,观测数据通过编码器生成q(|)的充分统计量:均值μ和标准差σ。利用重参法,通过引入由标准高斯分布产生的,产生对应的表征。最后模型由解码器得到观测数据的条件概率分布p(|)的充分统计量,重构出观测数据。该模型通过前文所述的最大化证据下界进行网络参数的优化。当网络训练完成后,可以使用编码器得到观测数据的表征。
2 解耦表征变分自编码机
在雷达HRRP目标识别任务中,数据表征对于分类器的性能影响巨大。由于变分自编码机的先验分布被设计成一个较为朴素的标准正态分布,这会导致编码器生成的雷达HRRP的数据表征可分性不高,影响分类器的分类性能。本文针对变分自编码机的不足,创新性地提出了解耦表征变分自编码机,该模型假设观测数据的隐表征由两部分独立变量构成,第一部分为,代表类间共性表征;第二部分为,代表各类特性表征。
对于雷达HRRP 数据的类间共性表征的先验分布,模型仍遵循变分自编码机采用的标准正态分布建模,其先验分布为

式中:∈R表示经过one-hot 编码后的样本类别;代表样本类别数;∈R表示一个可学习参数矩阵,其中表示z的维度。通过这种方式,不同类对应的表征将不再共享同一种先验分布。
因此,解耦变分自编码机的似然为

可以看到,目标优化函数包含3部分:第1部分为重构误差,此项反映了模型样本生成点的似然函数;第2项为类间共性隐表征误差;第3项为各类隐表征误差。
在训练过程中,模型中的各类特性表征对应的先验分布在一定迭代训练过程中往往会产生互相接近的情况,从而影响后续提取的各类特性隐表征的可分性。针对以上问题,模型对各类特性表征对应的先验分布引入了条件限制,即限制各类特性表征的先验分布的距离大于某个常数。

通过完成对式(8)的优化过程,模型可以得到近似后验分布q(|),并将其用于后续的分类工作。
图3展示了解耦自编码机的基本结构。编码器代表近似后验分布q(|)与q(|)的充分统计量;解码器代表观测数据的条件概率分布p(|)的充分统计量。通过这种对隐变量解耦建模的方法,模型学到的雷达HRRP 数据各类特性表征有较高的可分性。利用该表征,可以提高分类器的分类性能。
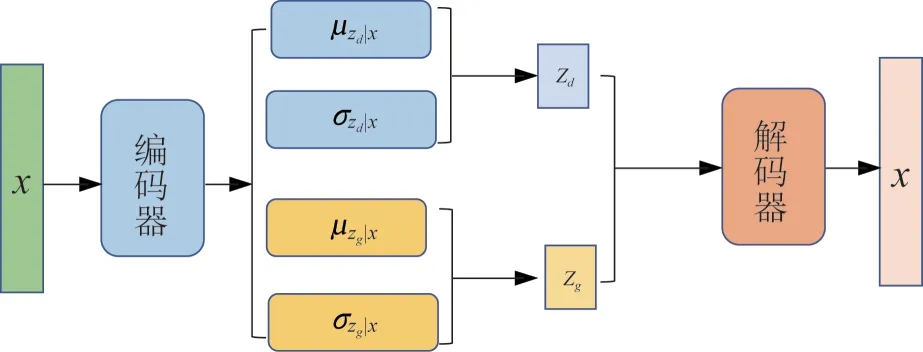
图3 解耦变分自编码机结构Fig.3 The structure of variational auto-encoder with disentangled representation
3 实验结果
3.1 实验数据源
本文的实验结果均基于西安电子科技大学数据库中逆合成孔径雷达(inverse synthetic aperture radar,ISAR)的实测飞机数据。该雷达工作时的中心频率为5.520 GHz,信号带宽为400 MHz。数据包含3 类飞机目标,分别为“雅克(Yark)-42”,“奖状(Cessna)”和“安(An)-26”。飞机具体参数详见表1。“雅克-42”,“奖状”,“安-26”的飞机轨迹在地面的投影如图4 所示。为了保证训练集数据基本能覆盖测试集数据的方位角信息,本文选择“雅克-42”的第2 段及第5 段,“奖状”的第6段及第7段,“安-26”的第5段及第6段数据作为模型的训练集,其余段作为测试集。训练样本个数为140 000 个,测试样本个数为5 200 个,样本维度为256。
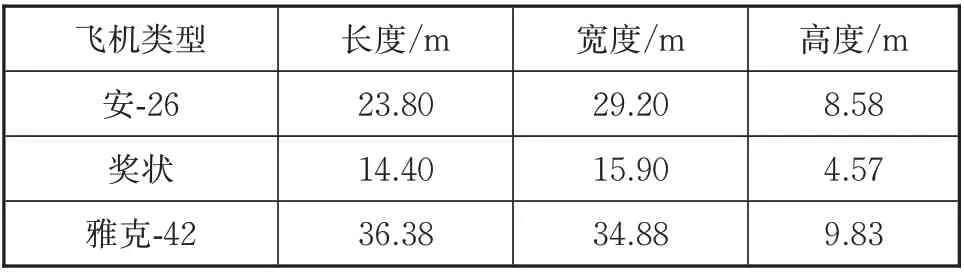
表1 ISAR实测数据的飞机参数Tab.1 Parameters of aircraft based on ISAR data
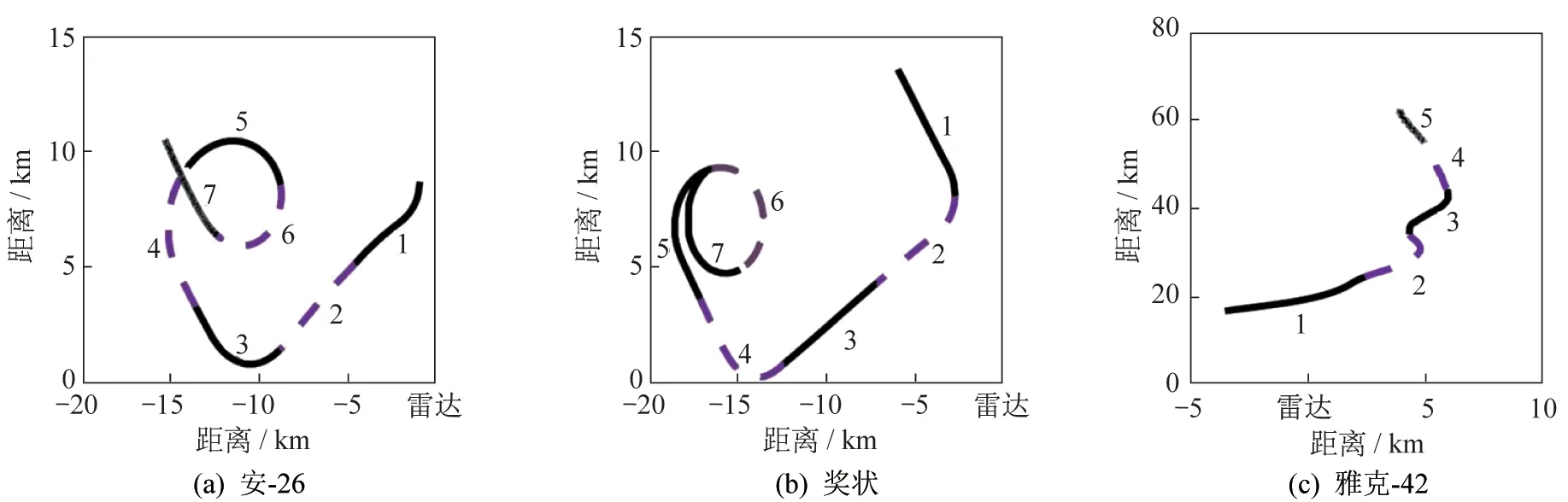
图4 飞行轨迹在地面的投影Fig.4 Projections of target trajectories onto the ground plane
3.2 网络模型
实验中使用的网络模型采用类似文献[10]的结构,包含编码器部分和解码器部分。编码器由2 个卷积层、2 个池化层、2 个批量归一化层和4 部分全连接层组成;卷积层特征图为32,卷积核大小为9,步长为1;池化层采用最大池化法;对于每部分全连接层,隐层输出维度分别为500、250、60。解码器部分由全连接部分和反卷积部分两部分构成:全连接部分由两个隐单元为64 的全连接层构成;反卷积部分分为两层,第1 层反卷积核为4,步长为2,特征图为32,第2 层反卷积核为4,步长为2,特征图为1。网络采用LeakyRelu 作为激活函数,并采用Adam 优化器优化模型参数,学习率设置为0.001。
遵循文献[8-10]的方式,在模型训练完成之后,将解耦表征变分自编码机得到的解耦表征作为训练数据,训练线性支持向量机(support vector machines,SVM)作为分类器,进行雷达HRRP数据的识别工作。图5 所示为解耦变分自编码机网络结构,其中:μ与σ分别为特性表征的近似后验分布的充分统计量;μ与σ分别为类间共性表征的近似后验分布的充分统计量。
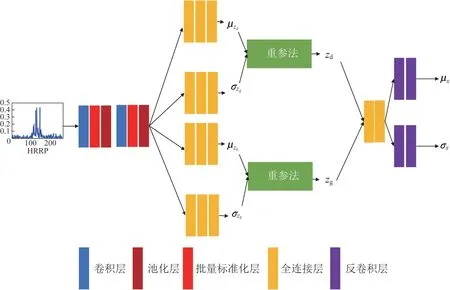
图5 解耦变分自编码机网络结构Fig. 5 The network architecture of variational auto-encoder with Disentangled Representation
3.3 可视化结果
图6 中(a)、(b)、(c)分别展示了三类飞机对应的样本点在原始HRRP 数据、解耦表征变分自编码机提取的类间共性表征和解耦表征变分自编码机提取的各类特性表征的主成分分析(principal component analysis,PCA)的二维投影图。从图6 可以看出,3 类不同飞机的原始数据和模型所提取的类间共性表征,其投影点重叠在一起,可分性不强。而模型提取的各类特性表征重合度小,可分性强。因此采用该模型提取的各类特性表征进行分类工作可以提升识别性能。
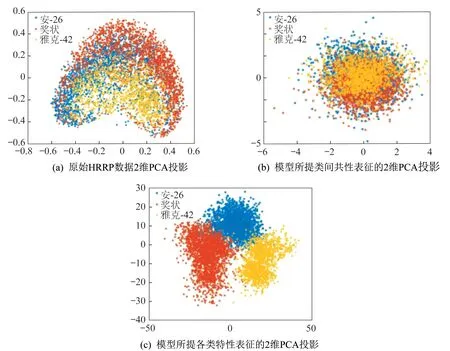
图6 解耦表征变分自编码机的可视化性能分析Fig.6 The visual performance analysis of variational auto-encoder with disentangled representation
3.4 识别率实验结果
为了验证本文提出的解耦表征变分自编码机模型的有效性,将其与MCC、AGC、LDA、PCA、DBN、SDAE、SCAE、TCNN、CNN-LPVAE 等模型进行对比,表2 展示了本文提出的解耦表征变分自编码机模型与多个模型识别率的对比结果。从表2 可以看到,在浅层模型中,PCA 方法识别率最高,但还是低于深度模型算法。这说明深度模型相对于浅层模型,其提取的特征更具有表达力。在这些深度模型中,解耦表征的变分自编码机模型又取得了最高的识别率,这也表现了该模型提取的各类特性表征的可分性较强,验证了模型的有效性。
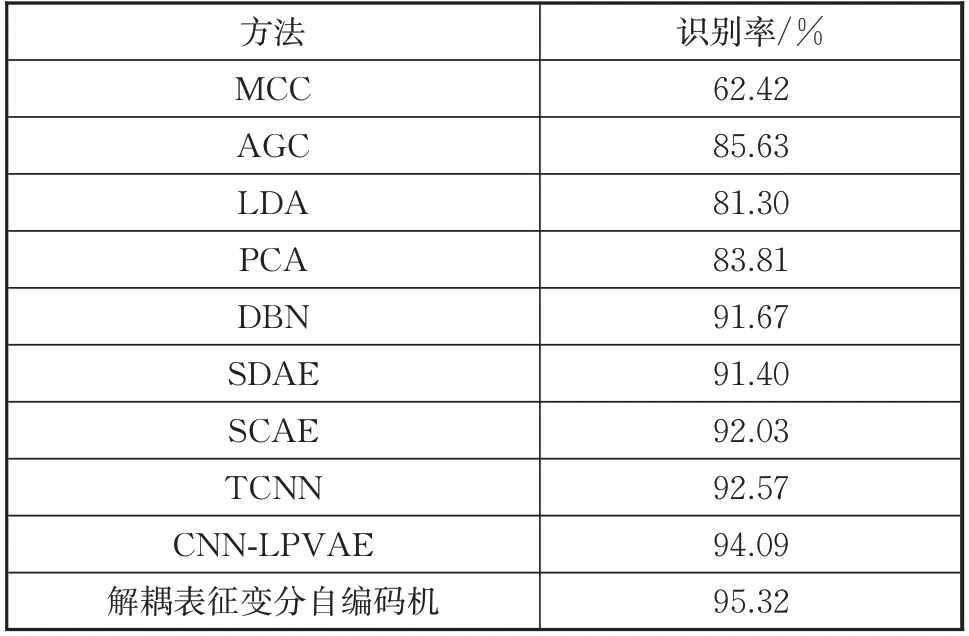
表2 解耦表征变分自编码机与各方法识别性能对比Tab.2 Comparison of recognition performance between variational auto-encoder with disentangled representation and other methods
为了分析模型参数对识别性能的影响,图7 展示了解耦表征的变分自编码机模型的识别性能随各类特性表征维度的变化情况。从图中可以看出,解耦表征变分自编码机在各类特性表征维度为60 的时候识别性能最优,为95.32%。这是因为在隐层维度低的时候,模型参数较少,不能较好地表现出类间特性表征。而如果隐层维度较高,模型又易过拟合,导致识别率下降。
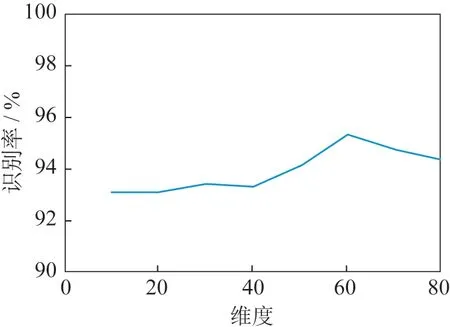
图7 解耦表征变分自编码机模型的识别率与隐层维度的变化曲线Fig. 7 Change curve between recognition rates of variational auto-encoder with disentangled representation and hidden layer dimension
4 结束语
在雷达高分辨率距离像识别任务,传统的深层网络通常忽略了HRRP 数据内部的特性,提取的数据表征可分性不强,因此在实际应用中不能取得满意的效果。针对这一问题,为了充分考虑不同高分辨距离项样本隐空间之间的类间共性表征和各类特性表征,本文提出了解耦变分自编码机模型。该模型利用编码机的编码结果,提取了样本隐变量的各类特性表征。利用该类间特性表征可以显著提高分类器的识别性能。实测数据的实验验证了该算法提取各类特性表征的可分性。未来,将进一步研究该算法在更为复杂的环境中的目标识别性能,以验证算法的稳健性。
猜你喜欢
大自然探索(2023年7期)2023-08-15 00:48:21
无线互联科技(2020年22期)2021-01-11 13:52:34
弹箭与制导学报(2020年2期)2020-09-01 02:08:56
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
小学生学习指导(低年级)(2018年12期)2018-12-29 11:13:24
传感器与微系统(2018年7期)2018-08-29 00:44:42
中国交通信息化(2018年3期)2018-06-13 03:27:58
自动化学报(2017年4期)2017-06-15 20:28:55
中国交通信息化(2016年2期)2016-06-06 07:28:02
