
基于循环生成对抗网络的人脸素描合成
2022-08-04 01:26葛延良孙笑笑王冬梅王肖肖
吉林大学学报(理学版) 2022年4期
葛延良, 孙笑笑, 张 乔, 王冬梅, 王肖肖
(东北石油大学 电气信息工程学院, 黑龙江 大庆 163318)
作为图像风格迁移的一个重要分支, 人脸素描合成(face sketch synthesis, FSS)目前得到广泛的关注[1]. 人脸素描合成是指将人脸转化为相对应的素描图像[2], 其在生活、 刑事侦查、 数字娱乐、 漫画制作[3]及电影制作等领域应用广泛.
图像的风格迁移方法主要有两种: 基于图像迭代和基于模型迭代[4]. 图像迭代方法主要包括基于最大均值差异、 基于Markov随机场和基于深度图像类比. 模型迭代方法在图像风格迁移方面有较大优势, 特别是卷积神经网络[5]和生成对抗网络的不断发展[1], 极大提高了人脸素描合成的图像质量. 其中基于卷积神经网络的图像风格迁移[6], 实现了局部连接、 权值分担、 特征提取和封装, 缺点是迁移缺乏泛化能力, 可能导致图像模糊甚至失真[7]. 生成对抗网络(generative adversarial networks, GAN)很好地解决了上述问题. Goodfellow等[8]首次提出了生成对抗网络, 极大提高了生成图像的速度和清晰度[9], 同时降低了网络的复杂度, 但整个过程是全监督学习, 而全监督网络要求训练人脸到素描风格迁移模型有较大的成对数据集, 准备成对数据集既困难又昂贵, 同时具有时间和空间的局限性; Gulrajani等[10]提出了ImprovedGAN, 对GAN进行了结构更改和训练, 主要集中于半监督学习和更好的图像生成, 训练结构稳定的GAN[11]; Isola等[12]提出了“Pix2pix”网络模型, 风格迁移效果显著, 但要求图片必须成对; 在此基础上, Zhu等[13]提出了循环生成对抗网络(cycle-generative adversarial networks, CycleGAN), 在该网络中提出基于对称GAN模型, 其在损失函数中加入周期一致性损失, 使输入图像在不配对的情况下生成不同风格的图像, 完成无监督学习的高质量风格传递任务. 本文使用循环生成对抗网络框架, 将其应用于人脸素描合成, 实验得到了更优质的素描图片.
1 循环生成对抗网络模型

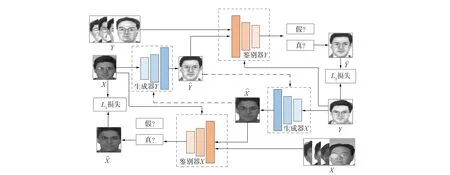
图1 CycleGAN生成模型结构Fig.1 Generative model structure of CycleGAN
本文定义两个相同的PatchGAN[12]作为鉴别器. 鉴别器采用四组卷积层+正则化+Leaky ReLU激活函数形式和一组卷积层+谱归一化+Leaky Relu激活函数形式, 每个卷积层的卷积核大小均为4, 步长为2, 通道数依次为64,128,256,512, 最后一层每个分割块通过Sigmoid输出为真的概率, 然后用BCE损失函数计算得到最终的损失[12]. PatchGAN对于图像风格迁移后的图片保持高细节的清晰化. 鉴别器网络结构如2所示.

图2 鉴别器网络结构Fig.2 Discriminator network structure
2 预备知识
2.1 U-Net模块
循环生成对抗网络的生成器采用卷积神经网络学习图像特征, 本文受文献[14]的启发, 将U-Net结构应用于生成器中. U-Net结构本质上是一个编码器-解码器网络, 在完全对称的编码器和解码之间进行常规的跳跃连接, 以结合图像高级和低级语义[15]. 本文以VGG16模块组成U-Net的结构作为生成器主框架,X(i,m)表示位于U-Net网络层不同位置的VGG16模块, 其中i表示模块位于第i行,m表示模块位于第m列, 其结构如图3所示.
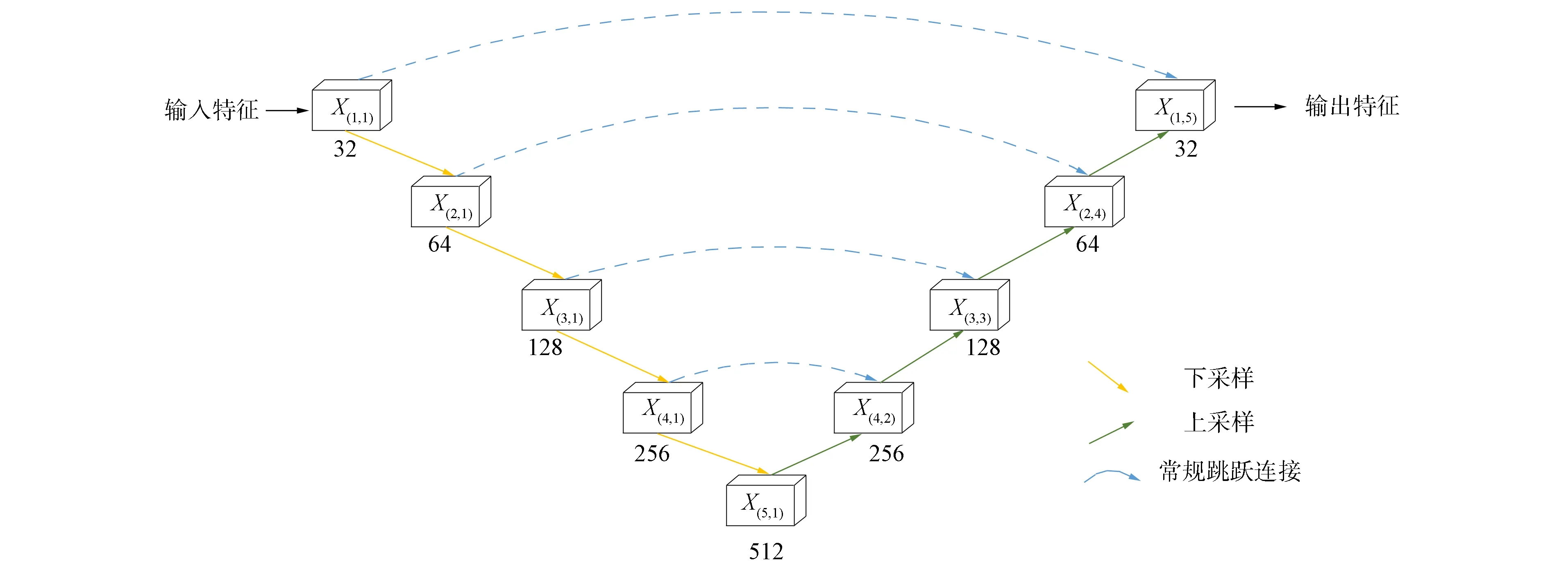
图3 U-Net结构模型Fig.3 Structural model of U-Net
2.2 空洞卷积
常见的图像分割算法通常使用池化层和卷积层增加感受野, 特征图缩小再放大的过程会导致精度损失, 因此本文引入空洞卷积(dilated convolution)[16], 可在增加感受野的同时保持特征图的尺寸不变, 如图4(A)所示. 图4是标准的 3×3 卷积(扩张率为1), 该卷积的感受野是卷积核覆盖3×3区域. 当扩张率为2时, 感受野RFn可利用
RFn=RFn-1+(i-1)×d
(1)
计算, 其中RFn-1表示上一层的感受野,i表示卷积核大小,d表示步长.图像特征提取过程中, 在保证特征图一定分辨率的前提下, 获得较大的图像特征感受野.由图4(B)可见, 此时的卷积核大小为2×(3-1)+1=5, 与图4(A)叠加得到图4(C)的感受野相当于7×7网格所覆盖的区域.
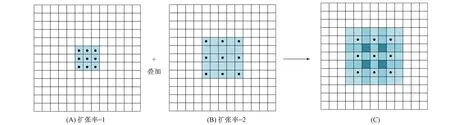
图4 空洞卷积感受野示意图Fig.4 Schematic diagram of dilated convolution receptive field
2.3 自注意力模块
由于目前的网络结构在图像特征提取过程中存在均匀分布的特点, 而卷积运算将图片进行局部分割, 在进行深层特征提取与迁移时, 局部与整体会有差异. 本文受文献[17]工作的启发, 通过自注意力机制建立像素之间的关联, 提高对图像高频信息和图像风格保持的能力. 本文引用通道自注意力模块(channel self-attention module, CSAM)和空间自注意力模块(spatial self-attention module, SSAM). CSAM结构如图5所示. SSAM通过每个位置特征的加权总和, 选择性地聚集每个位置的特征, 其结构如图6所示.
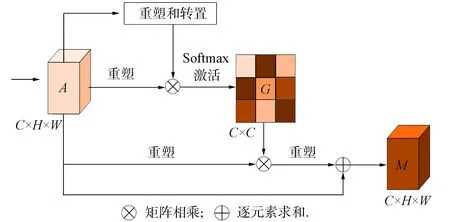
图5 通道自注意力模块的结构Fig.5 Structure of channel self-attention module
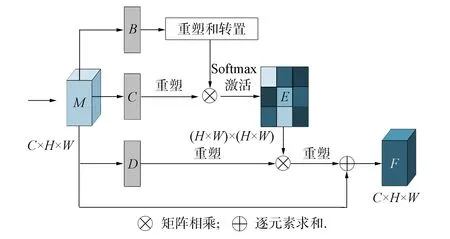
图6 空间自注意力模块的结构Fig.6 Structure of spatial self-attention module
3 改进的生成网络模型
3.1 多尺度特征聚合模块
本文设计多尺度特征聚合模块(MFFB), 结构如图7所示. 将图像特征并行输入通过3个3×3的空洞卷积[16], 分别以2,4,8的采样率并行采样, 同时将输入与一个全局平均池化(GAP)相乘, 将得到的4个不同尺度的特征在通道维度上叠加到一起, 最后再通过1×1的卷积进行特征融合和通道数恢复.

图7 多尺度特征聚合模块Fig.7 Multi-scale feature fusion block
3.2 上采样和下采样模块
本文上采样模块和下采样模块设计采用相同的结构, 如图8所示. 分别在下采样保持最大池化提取特征和反卷积上采样的同时, 与一个3×3的卷积层进行并联, 并在通道维度上进行特征叠加, 最后通过Relu激活函数达到快速收敛, 使采样过程增加对图像细节特征信息的获取.
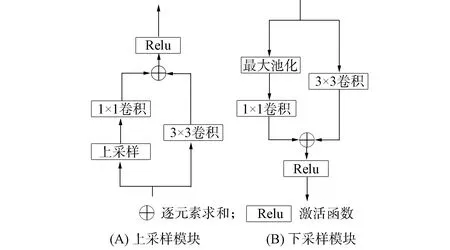
图8 上采样和下采样模块Fig.8 Up sampling module and down sampling module
3.3 像素自注意力模块
本文建模像素自注意力模块(pixel self-attention module, PSAM)通过自注意力机制建立像素之间的关联, 以提高对图像高频信息和图像风格保持的能力, 如图9所示. 输入的图像特征表示为3维C×H×W, 其中C表示通道维度,H×W表示位置维度.对于输入特征为C×H×W的特征A, 先在空间维度上进行压缩,A通过重塑后特征图与A重塑和转置的特征图进行矩阵相乘后通过Softmax函数得到像素大小为C×C通道注意图G; 同理使转置后的G与转置后的A进行矩阵乘法, 并乘以尺度系数β, 再次转置后与A逐元素相加得到特征图M,β初始化为0, 并逐渐学习分配更多的权重.得到特征图M后在通道维度上进行压缩, 首先, 分别通过3个卷积层得到分割后的特征图B,C,D, 然后分别重塑成C×N,N=H×W表示像素的大小; 其次, 特征图B通过转置后与重塑后的C进行矩阵相乘后, 通过Softmax函数得到像素大小为N×N的空间注意图E; 同理使转置后的E与转置后的D进行矩阵乘法, 并乘以尺度系数α, 再次转置后与M逐元素相加得到特征图F,α初始化为0, 并逐渐学习分配更多的权重.

图9 像素自注意力模块Fig.9 Pixel self-attention module
通过CSAM与SSAM进行级联组成像素自注意力模块, 不仅捕捉了任意两个通道特征图之间的通道依赖关系, 还挖掘了任意两个位置之间的空间依赖性, 通过训练网络自主学习两个位置之间的特征相似性权重.
人力资源:截至目前为止,西矿企业在册员工达一万五千多人,但在公司职工中硕士学位以上的有147人,高级职称以上的有184人,其中享受国务院政府特殊津贴专家、青海省优秀专家等有18人,在全员中的占比较小,仍然缺乏高学历高技术人才,在人力资源方面竞争优势不大,所以公司应通过绩效管理、薪酬福利等方式吸引优秀人才为公司服务。
3.4 生成器网络结构
本文在CycleGAN生成器网络基础上进行改进, 结构如图10所示. 首先, 用VGG16模块组成U-Net网络代替生成器中的全卷积神经网络, 模型中使用改进后的上采样和下采样模块, 使网络下采样采用最大池化和上采样反卷积时, 能减少图像特征的损耗; 其次, 在编码器与解码器进行常规跳跃连接过程中添加MFFB, 可在保持一定图像特征分辨率的情况下, 具有较大的感受野, 多尺度的捕捉上下文信息, 使得U-Net结构的每个解码器层都融合了来自编码器中的小尺度和同尺度的特征图, 减少图像细节信息的损失, MFFB不仅改善了网络对图像边界细节信息的提取, 并且可从图像特征中提取有用信息; 再次, 在解码器端进行多尺度密集跳跃连接, 通过解码器端的X(1,5)与X(3,3),X(4,2),X(5,1)模块进行密集跳跃连接; 同理X(2,4)与X(4,2),X(5,1)及X(3,3)与X(5,1)模块都采用密集跳跃连接的方式, 使得U-Net结构内部形成多尺度的密集跳跃连接, 对图像的不同尺度特征信息进行多次的复用和提取, 以提高网络浅层特征利用率及深度特征的兼容性, 从而成功地捕捉图像的几何特征和细节纹理信息, 使U-Net结构的每个解码器层都融合了来自编码器中的小尺度和同尺度的特征图; 最后, 图像信息的提取集中在第五层的X(5,1)模块, 此时通道数最多, 使X(5,1)和X(1,5)模块进行级联操作, 在该过程中建模PSAM, 实现方法是通过网络训练, PSAM自动学习使不同的图像特征获得与之匹配的权重, 从而完成对原始特征的重新标定, 实现多层次交叉模态特征融合, 并降低了低质量图像特征的冗余和噪声.
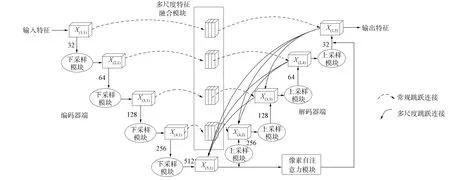
图10 生成器合成过程网络结构Fig.10 Network structure of generator synthesis process
3.5 训练过程
CycleGAN学习从X→Y的映射, 如果映射关系设为G, 则学习到的图像即为GX, 然后用鉴别器判断是否是真实图像, 从而形成生成对抗网络.其损失函数为
LGAN(GX,DY)=EY[logDY(y)]+EX[log(1-DY(GX(x)))],
(2)
其中GX计划生成与目标域中的图像完全无法区分的假图像GX(x), 而DY试图区分真假图像.对于映射函数GY:Y→X和鉴别器DX, 本文定义一个类似的对抗性损失LGAN(GY,DX).
基于CycleGAN中两个GAN的对称性, 所有X都可由G映射到Y空间的图像上, 反之亦然.所以为避免损失无效, 本文不能直接使用该损失进行训练.因此重新定义一种损失函数, 其假设生成的图像可以被合成回原域.对于X域的图像, 本文训练的目的是X→GX(x)→GY(GX(x))≈X; 对于Y域的图像, 本文训练的目的是Y→GY(y)→GX(GY(y))≈Y.CycleGAN模型的关键是使用循环一致性损失的监督, 其损失函数表示为
Lcyc(GX,GY)=EX[GY(GX(x))-x1]+EY[GX(GY(y))-y1].
(3)
CycleGAN结构还加入了本体映射损失(identity loss). CycleGAN使用Identity loss的目的是在迁移过程中保持原色调, 约束生成器更接近真映射, 本文引入的损失函数表示为
Lil(GX,GY)=EX[GX(x)-x1]+EY[GY(y)-y1].
(4)
从而在整个CycleGAN网络中的总目标损失函数表示为
L(GX,GY,DX,DY)=LGANX+LGANY+λcycLcyc+λilLil,
(5)
其中λcyc和λil是控制循环损失和本体映射损失的参数.
4 实 验
为验证本文人脸素描合成网络框架的性能, 本文在包含人脸手绘素描和人脸照片的数据集CUFS[18]和CUFSF[19]上进行训练. 数据集CUFS包含606对彩色人脸照片, 用于研究人脸草图合成和人脸素描识别, 其包括来自香港中文大学(CUHK)学生数据库的188对面孔, 其中88对用于训练, 100对用于测试; 来自AR数据库的123对面孔, 60对用于训练, 63对用于测试; 来自XM2VTS数据库中的295对人脸面孔, 其中150对用于训练, 145对用于测试. 数据集CUFSF分别包括1 194对黑白人脸照片和素描, 其中挑选400对用于训练, 694对用于测试, 因为草图更抽象化及与原始照片没有很好的对齐, 增加了实验的复杂性. 实验环境为Ubuntu操作系统计算机, NVIDIA 1080 Ti显卡, Pytorch1.9环境下运行.
4.1 参数设置
由于受实验设备条件限制, 在实验过程中训练集的人脸图像被裁剪成256×256大小, batch_size为5, 实验迭代次数为200次, 生成器和鉴别器使用Adam算法进行优化, 优化学习率为0.000 2, 为减少网络的震荡, 存储几张生成图像作为缓冲更新鉴别器.
4.2 实验结果与分析
为验证本文实验对人脸素描合成的有效性, 在相同的硬件环境下, 本文对比了FCN算法[20]、 MWF算法[21]、 CycleGAN算法[13]、 CA-GAN算法[22]和本文算法分别在数据集CUFS和CUFSF上生成的人脸素描图像.
在客观评价指标上, 采用的图像质量评估指标分别为: 结构相似指数(structural similarity index measure, SSIM)[23], 其从亮度、 对比度和结构相似三方面衡量待评图像的质量; 特征相似度测量(feature similarity index measure, FSIM), 其是在SSIM上的延伸, FSIM算法[23]能根据一张图片中不同像素所占的百分数不同而给予合适的权重指数, 与肉眼的视觉感知一致性较高, 聚焦合成素描图像的低层次特征与手绘图像的区别; 结构共现纹理的测试(Scoot Measure)[24], 其针对类视觉系统具有快速评估两张面部素描之间感知相似性的能力, 空间结构和共线纹理是面部素描合成中两个普遍适用的感知特征, 结构共线纹理测试同时考虑空间结构和共线纹理, 指标数值越大, 说明与手绘素描图相似度越高, 重构的人脸素描与手绘素描之间的差异越小, 效果越好. 不同网络架构在数据集CUFS和CUFSF上生成的素描图像进行测评的结果分别列于表1和表2.

表1 不同网络架构在数据集CUFS上素描图像评估结果对比

表2 不同网络架构在数据集CUFSF上素描图像评估结果对比
由表1可见, 本文算法相比于FCN,MWF,CycleGAN,CA-GAN算法训练得到的人脸素描图像, 其各项指标均有提高. 本文算法与效果相对较好的CA-GAN网络训练得到的人脸素描图像相比, 其SSIM和FSIM值分别提高0.011 2和0.002 5, Scoot Measure提高0.009 3. 由表2可见, 本文算法与效果相对较好的CA-GAN网络训练得到的素描图像相比, 其SSIM和FSIM值分别提高0.010 4和0.016 2, Scoot Measure提高0.025 6. 实验结果证明了本文算法在人脸素描图像合成方面的有效性.
下面从主观视觉上对比实验结果. 各算法在数据集CUFS和CUFSF上测试生成的人脸素描图片如图11所示. 由图11可见, 不同算法的重建素描效果图在主观视觉上, MWF和FCN算法重建的图像主观上能辨析人脸 , 但其纹理模糊; CycleGAN算法重建的图像线条更丰富, 但边缘较模糊; CAGAN算法重建的素描图像面部表情稍微失真, 但整体轮廓更清晰; 本文算法重建的人脸素描图像能恢复出更好的轮廓边缘信息, 且线条含有更多的细节信息, 发丝和五官轮廓更清晰, 呈现出笔绘的线条感. 实验结果表明, 本文算法基于人脸照片重建的素描图像取得了最好的素描风格重现, 感官视觉和客观指标上均优于对比算法.

图11 在数据集CUFS和CUFSF上各算法的视觉对比结果Fig.11 Visual comparison results of each algorithm on CUFS data set and CUFSF data set
综上所述, 针对在人脸素描图像合成过程中存在人脸边缘和细节纹理模糊、 面部表情失真等问题, 本文结合CycleGAN算法的优点, 提出了一种多尺度自注意机制的循环生成对抗网络用于人脸素描图像合成. 该网络通过建模PSAM, 使网络在对图像特征进行提取时, 网络自动学习图像特征信息的权重, 通过学习不同特征通道之间的重要关系提升网络性能, 使素描风格迁移获得更好的表达; 该网络采用U-Net结构的生成器, 并改进内部连接方式和采样结构, 在获得较大感受野的情况下提取多尺度的特征信息, 利用空洞卷积设计MFFB. 将该网络与其他经典算法进行实验对比的结果表明, 本文算法不仅主观上重建了较好的视觉效果, 进一步纠正了网络生成的人脸素描图像在细节纹理、 几何特征和边缘特征方面的表现能力; 在客观评价指标上, 本文取得的较高的FSIM和Scoot Measure值, 也证明了本文算法在人脸素描图像合成方面的有效性.
猜你喜欢
社会科学战线(2022年7期)2022-08-26
少儿美术·书法版(2021年9期)2021-10-20
奥秘(2021年5期)2021-06-15
歌剧(2020年4期)2020-08-06
雨露风(2020年8期)2020-04-26
时代英语·高一(2017年5期)2017-11-14
读者(2016年23期)2016-11-16
米娜·女性大世界(2016年8期)2016-08-17
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
