
特征图自适应知识蒸馏模型
2022-08-04 01:20:32吴致远崔楚朋杨宗敏薛欣慧
吉林大学学报(理学版) 2022年4期
吴致远, 齐 红, 姜 宇, 崔楚朋, 杨宗敏, 薛欣慧
(1. 吉林大学 计算机科学与技术学院, 长春 130012; 2. 中国科学院 计算技术研究所, 北京 100190;3. 吉林大学 符号计算与知识工程教育部重点实验室, 长春 130012)
深度卷积神经网络在图像分类[1-2]、 物体检测[3]、 语义分割[4]等视觉领域应用广泛. 目前大多数方法集中于提高特定数据集上的推断准确率, 使得网络架构日趋复杂化. 嵌入式和移动设备由于受计算资源和存储空间的限制, 对紧凑型神经网络需求迫切. 模型压缩方法以较小精度损失为代价, 大幅度减小网络的参数规模与推断开销. 网络减枝[5]、 参数量化[6]、 张量分解[7]等现有压缩方法分别从冗余淘汰、 权重复用、 后端重构等方面直接对成型的网络进行后端压缩, 在一些小型数据集上取得了一定成效.
知识蒸馏是基于模型迁移学习的重要分支, 是一种在复杂神经网络提示下训练紧凑神经网络的技术[8], 为构建高效准确的紧凑型神经网络提供了一种与模型压缩方法相异的新思路. 在知识蒸馏过程中, 复杂网络和紧凑网络分别扮演着“教师”和“学生”的角色. 教师网络由于过参数化的特性, 易收敛到较优的解[9], 但参数规模庞大, 推断代价昂贵; 学生网络虽可通过增加深度的方法在维持参数规模基本不变的前提下提升容量, 但局部解和难于训练的问题导致其直接训练后推断效果通常较差, 难以满足实际应用过程中对推断精度的要求. 知识蒸馏充分挖掘了大型网络特征提取能力强、 预训练网络阶段性输出语义信息丰富的特点, 利用其辅助学生网络进行训练, 可有效提高学生网络的收敛速度与精确度.
早期的知识蒸馏方案将教师网络输出调整后的软标签与硬标签的加权平均作为学生网络训练的监督数据[10]. 由于不同类别之间的相似度不同, 高熵的软标签能比硬标签提供更丰富的语义监督信息[11], 因此在教师网络的指导下, 学生网络通常能收敛到较好的解. 之后的工作开始致力于通过教师网络的隐藏层输出(称为特征图)提示学生网络训练实现知识迁移. FitNet[12]采用卷积回归的方法, 将教师网络隐藏层输出尺寸匹配到学生网络中间尺寸, 用于训练窄而深的学生网络, 希望学生网络学习一个基于教师网络中间输出变换的表示方案. He等[13]使用自编码器重构教师网络的中间输出, 通过最小化自重构损失使编码后的教师网络中间特征能较好地恢复原本的语义信息, 并利用编码的特征作为学生网络前半部分训练的监督数据. 但来自学生网络和教师网络的特征图通常具有不一致的上下文和不匹配的特征. 现有方法对教师网络特征图采取变换, 其结果通常不适合作为学生网络用于预测最终目标的中间特征. 教师网络和学生网络架构不同导致二者参数线性空间和对应阶段数据分布式表达程度存在差异, 如果在各自架构的基础上, 参数收敛到了良好的空间, 二者推断出的隐藏层特征图所蕴含的语义表示信息将存在较大的领域偏差, 因此将教师网络特征图经过恰当的变换成为适合于学生网络的监督特征成为基于隐藏层输出提示知识蒸馏的关键. 同时, 教师网络提供的用于监督的特征确定了学生网络训练时优化的目标导向, 但其常与实际应用需求存在偏差.
文献[12]提出了将回归器损失与教师网络中间输出特征相关联, 收敛后的回归器学习到的映射方案倾向于将教师网络的隐藏层输出特征转化为某种兼顾教师网络和学生网络需求的中间表示. 改进特征映射方案的归纳偏好有利于教师网络传递更有价值的知识, 文献[13]提出了重构特征自编码器经过训练后, 编码器映射到学生网络的特征能较好地恢复教师网络特征的语义信息. 但学生网络的隐藏层输出无需恢复教师网络的特征图, 用于精确推断的学生网络监督特征会使知识蒸馏更有效. 虽然采取领域自适应方法, 通过显式地在教师网络监督学生网络训练的过程中加入对该问题理解的先验知识, 可一定程度上缓解教师网络和学生网络特征图中上下文和特征语义信息的不匹配性, 但类似方法都只是从人类的角度出发, 通过加入人类对深度神经网络解决视觉问题的理解提升推断效果, 所需的难以理解的抽象语义信息并未被充分挖掘.
利用神经网络自身在正确目标驱动下实现适合学生网络监督特征的自适应搜寻, 并利用其作为学生网络的提示, 有利于提升模型的收敛速度与准确率. 基于此, 本文提出一个特征图自适应知识蒸馏模型. 首先, 使用特征图适配器实现教师网络特征图与学生网络特征图的尺寸和通道数匹配、 特征同步变换以及监督特征自适应搜索. 其次, 在此基础上, 提出特征图自适应知识蒸馏策略: 通过特征图适配器替换方法构建自适应教师, 并在学习率限制条件下进行训练, 在尽可能维持预训练教师网络的特征提取与表达方案的同时提升监督特征的泛化能力; 自适应教师隐藏层输出提示学生网络训练, 实现教师网络特征表示的知识迁移; 进一步基于延拓法[14]和课程学习[15]的思想对学生网络进行约束训练, 以保证优化的大部分时间花费在效果良好的参数空间. 最后, 在数据集cifar-10上验证特征图自适应知识蒸馏模型的有效性. 实验结果表明, 该模型提高了0.6%的训练准确率, 降低了6.5%的训练损失, 并且节省了94.4%的训练时间.
1 特征图自适应知识蒸馏模型
针对教师网络和学生网络之间上下文不一致和特征不匹配导致迁移效果较差的问题, 本文提出一个特征图自适应知识蒸馏模型, 其整体框架如图1所示. 由图1可见, 该模型由教师网络、 学生网络和特征图适配器构成. 教师网络架构复杂但推断准确, 且预先经过训练; 学生网络结构紧凑, 未经训练, 具有进行高效准确推断的潜力. 由于网络架构的差异, 对应阶段教师网络大于学生网络的隐藏层特征图分辨率. 特征图适配器用于替换教师网络的标注模块(替换后的教师网络称为自适应教师), 以学习知识迁移策略, 为学生网络提供合适的监督特征.
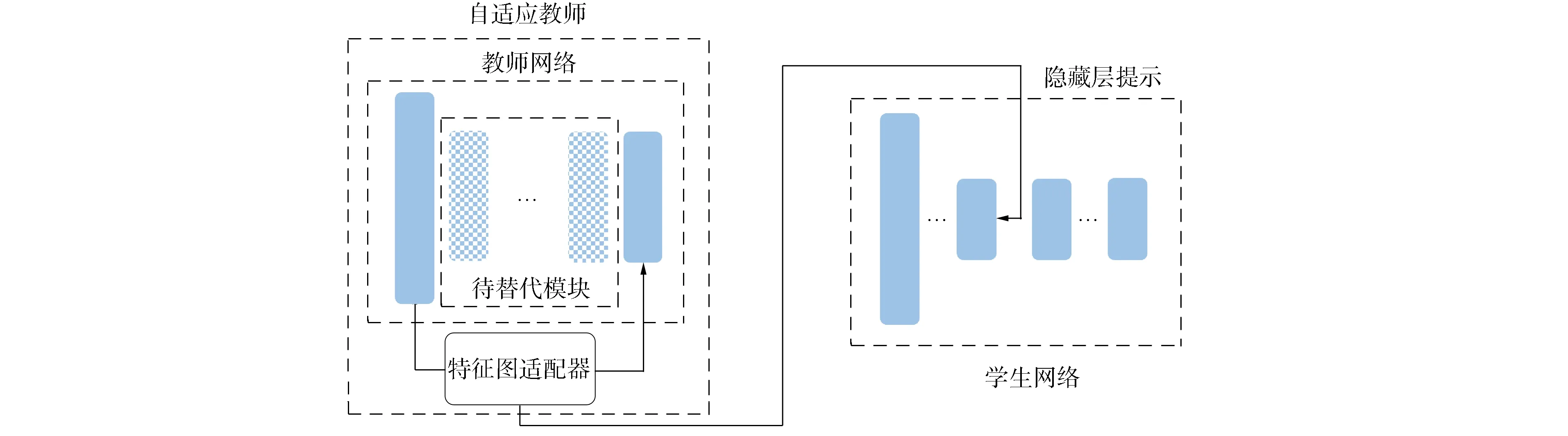
图1 特征图自适应知识蒸馏模型整体框架Fig.1 Whole framework of activation map adaptation knowledge distillation model
在适合用于学生网络隐藏层监督特征自适应搜索过程中, 在学习率限制的条件下对自适应教师进行训练, 迁移知识的策略在训练过程中被特征图适配器自动学习; 以特征图适配器中间部分为界, 将自适应教师一分为二, 用前部隐藏层输出特征图作为学生网络优化目标, 通过优先学习简单的概念提升学生网络后续优化效果.
1.1 特征图适配器
作为特征图尺寸匹配、 特征同步变换及自适应匹配的关键技术, 特征图适配器由过渡模块与解析模块堆叠形成, 其中下采样和上采样过渡模块分列适配器的左、 右两侧, 如图2所示. 特征图适配器用于替换教师网络中的标注模块, 以构建自适应教师.
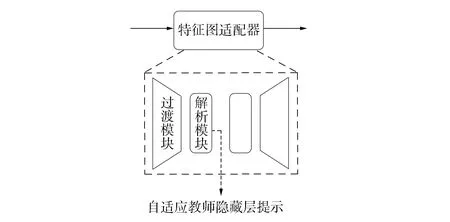
图2 特征图适配器Fig.2 Activation map adaptor
引入特征图适配器有如下优点: 1) 特征图适配器中间输出与学生网络提示断点处的输出尺寸相同, 因此可直接监督学生网络进行训练, 由于特征图适配器训练过程中以最小化预测损失为目标, 中间输出的特征倾向于最有利于解析出高精确度的结果; 2) 特征图适配器学习的内容可近似为从给定基本特征到给定抽象特征的变换, 而给定的二者可视为学习过程中所依赖的先验知识, 在训练过程中有帮助作用. 训练完毕, 自适应教师所学得的特征表达具有迁移给学生的潜力. 监督学生训练的过程即为帮助学生网络搜寻良好初始权重的过程.
教师网络提示数据与学生网络待监督隐藏层输出尺寸相匹配是教师直接提示学生训练实现知识迁移的充要条件. 过渡模块主要用于匹配特征图尺寸. 面对相同问题, 在教师和学生网络特征分布式表达程度相近阶段, 前者的特征图尺寸通常大于后者. 重构拟在教师网络提示阶段前调整其卷积层的规格, 然后尽快恢复正常的特征图大小. 因此, 过渡模块设有用于下采样和上采样两种类型, 并分别在提示阶段前后被使用. 过渡模块的总体设计思路如图3所示.
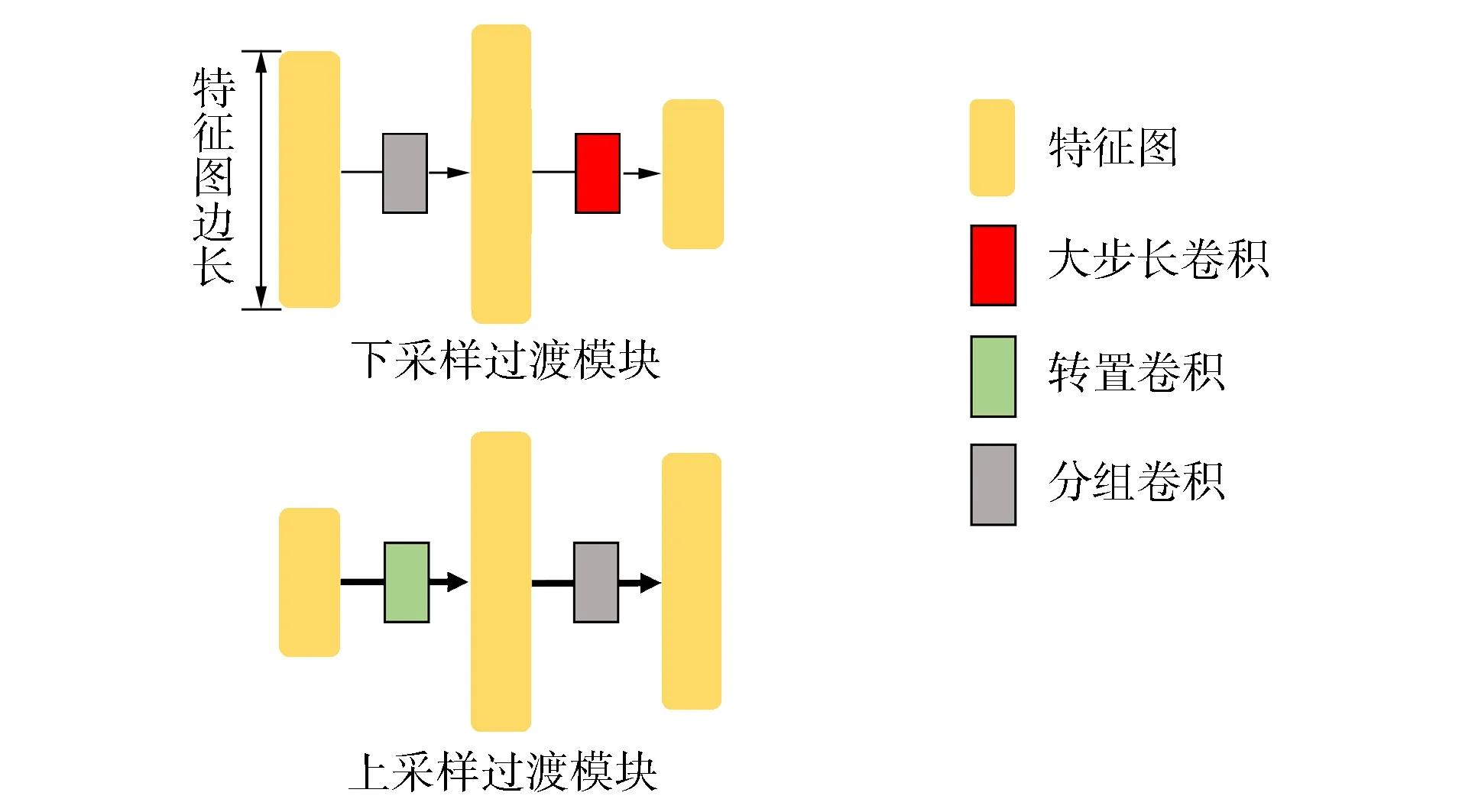
图3 过渡模块Fig.3 Transition module

以采样的形式直接对特征图尺寸进行匹配会导致晦涩的推断语义表示, 因而需要采用某种机制对特征进行提炼与修饰. 基于此, 本文提出增加解析模块, 与过渡模块的堆叠提高了自适应教师的准确性, 从而为后续的知识迁移提供更可靠的监督特征.
1.2 特征图自适应知识蒸馏策略
1.2.1 构建教师网络和学生网络
参数冗余的教师网络常能收敛到良好的解, 且具有较高的推断精度; 学生网络具有部署在存储和计算资源受限环境中的应用需求, 参数规模和计算资源消耗是首要考虑的因素. 因此, 本文在研究过程中选择已有推断结果准确的网络架构作为教师网络; 利用紧凑型模块对优秀网络架构的部分模块进行替换, 以此构建学生网络.
1.2.2 训练自适应教师
有效知识蒸馏有两个前提条件: 整体或部分学生网络接受尺寸匹配的监督数据; 该数据能更好地反映阶段或全局优化目标. 为此, 本文采取如下策略训练教师网络:
1) 标注教师网络中间的部分模块, 标注块的前、 后部分分别记为TF和TB; 在学生网络相应的阶段设置提示断点, 将学生网络分成两部分, 分别记为SF和SB;
2) 使用特征图适配器替换教师网络的标注块, 重构后的教师网络, 即自适应教师, 记为AT; 要求以两个过渡模块为分割线的适配器前半部分(记为AF)的输出尺寸与学生网络的SF输出尺寸相同;
3) 冻结TF的权重, 对TB采用小学习率, 使用增强数据对自适应教师进行训练; 对于整个自适应教师, 只有特征图适配器采用正常学习率进行训练.
对于图像分类任务, 定义N,M分别为批处理大小和待分类类别的数量.本文采用交叉熵作为自适应教师的训练损失.多分类问题的交叉熵损失Llog定义为

(1)
其中yic为输出结果第i个样本的第c个类别的分类置信度,ylabel和ypred分别表示数据集标签及网络的推断结果.
1.2.3 基于隐藏层提示的蒸馏
延拓法和课程学习思想表明, 选取正确的初始化权重对于训练阶段的参数优化具有正面影响; 学习复杂概念时优先学习简单的概念有利于提升最终的学习效果. 基于此, 本文采用隐藏层提示策略, 即把经过TF和AF映射后的监督数据(yTF-AF)作为SF(输出记为ySF)的优化目标, 以最小化像素平均相对熵损失LPAKL实现教师网络知识迁移给学生网络的前半部分:
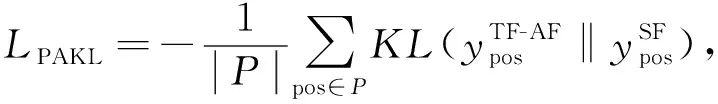
(2)
其中P为SF的隐藏层输出特征图,ypos为隐藏层输出特征图pos位置对应的灰度值,KL为Kullback-Leibler散度.
1.2.4 约束优化
知识迁移完成后仍需通过进一步优化实现精确的推理. 与常规训练时网络权重接收随机初始化的情况不同, 本文中学生网络预先经过部分训练, 存储有可靠与泛化性的推断语义表示. 为充分利用其中有用的信息, 本文以交叉熵作为损失函数, 先在冻结SF的前提下进行训练, 然后采用小学习率对学生网络整体进行训练, 以防止破坏其中潜藏的结构化知识.
1.3 模型的形式化描述
算法1特征图自适应知识蒸馏.
输入:WT,WS,WAF,WAB,n,m,i,j,g,LP,LH,X,ypred;
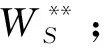


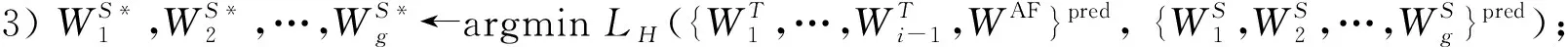

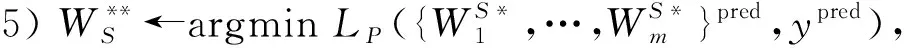
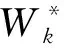
2 实验验证
2.1 数据集
本文采用在计算机视觉表示学习中广泛使用的数据集cifar-10进行实验验证. 该数据集为图像分类数据集, 种类覆盖了客观世界中常见的物体, 例如飞机、 汽车和鸟等. 数据集cifar-10的尺寸为32×32×3; 类别数为10; 训练集为50 000; 测试集为10 000.
2.2 实验过程
2.2.1 网络架构
本文采用MuxNet[2]作为教师网络, 该网络预先经过训练. 通过对ResNet20[1]进行修改实现学生网络的架构: 在网络的分类器前增加一个残差模块, 并使用Ghost Module替换所有的卷积层. 修改后的网络为轻量级网络, 且具有高精度推断潜力. 教师网络和学生网络架构如图4所示, 其中标明了教师网络待替换模块和学生网络迁移断点. 学生网络的参数列于表1, 其中Ghost Basic Block为Ghost Module[16]替换Basic Block[1]中卷积层后的紧凑型模块. 未经特殊说明, 本文中卷积层均采用一个像素的0填充.

图4 教师和学生网络架构Fig.4 Architecture of teacher and student network

表1 学生网络参数
2.2.2 解析模块的选择
综合考虑网络容量和特征分布式表达程度, 本文采用残差模块[17]作为解析模块. 特征图适配器的参数列于表2, 其中分组卷积均采用16个通道为一组的编组方式.

表2 特征图适配器参数
2.2.3 数据增强与网络训练
自适应教师采用随机梯度下降法进行训练, 动量和批处理大小分别设为0.9和128. 采用用于正则化的权重衰减策略, 衰减率设为3×10-6. 教师网络的训练采取如下策略: 首先采用弱增强的训练数据对教师网络进行训练; 然后逐步提高数据增强的强度, 并采用进一步优化策略, 如随机旋转、 随机裁剪、 水平随机翻转以及色彩、 亮度、 明暗对比度扰动的数据增强策略. 训练过程中, 先采用3×10-3的学习率, 然后迭代逐步降至10-4. TB的学习率始终为常规学习率的10%.
在知识迁移阶段, 在实际操作过程中将教师网络和学生网络的隐藏层输出均标准化为均值0、 方差1, 通过最小标准化后二者输出的相对熵对学生网络进行提示. SB的训练同样采用3×10-3的学习率, 微调整个网络时采用3×10-5的学习率, 其他超参数与训练自适应教师时相同. 为形成对比, 本文对于未经知识迁移的学生网络采用相同的训练策略.
2.3 实验结果
损失与正确率随迭代次数的变化曲线分别如图5和图6所示. 由图5和图6可见, 在相同训练条件下, 采用特征图自适应模型经过知识迁移后的学生网络明显具有更快的收敛速度、 更低的推断损失及更高的准确率. 迁移后的网络在100次迭代前即达到了较高的推断精度, 即正确率达78.2%; 而未经迁移的网络在相同条件下需超过1 800次迭代才能达到相近的效果. 在2 500次迭代的训练尺度下, 经过知识蒸馏的网络的准确率和损失都有所改进, 分别提高了0.6%和降低了6.5%. 实验结果表明, 本文提出的特征图自适应知识蒸馏模型可有效提升紧凑型神经网络的推断精度和收敛速度.
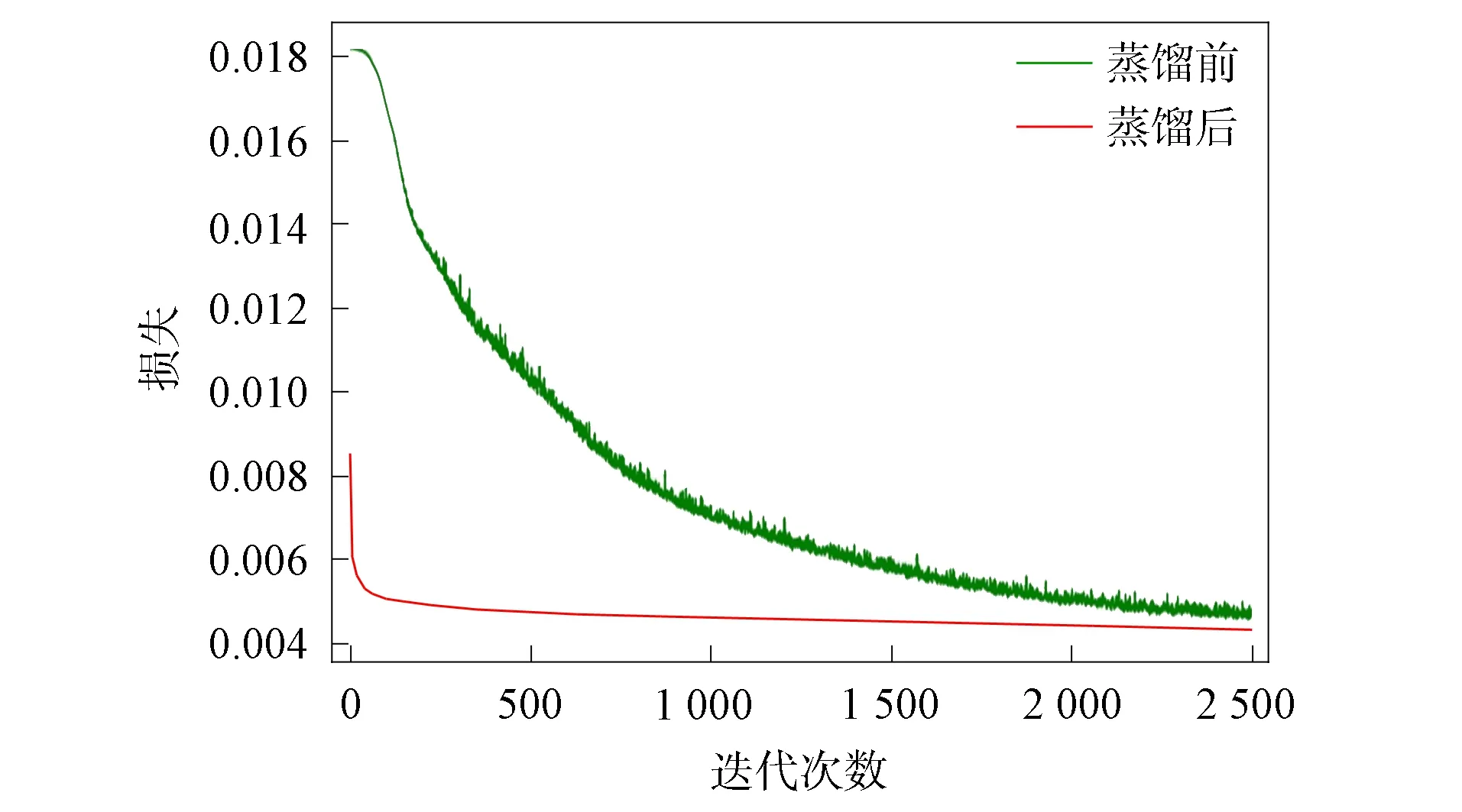
图5 损失随迭代次数的变化曲线Fig.5 Change curves of loss with number of iterations

图6 正确率随迭代次数的变化曲线Fig.6 Change curves of accuracy with number of iterations
综上所述, 为提升用于嵌入式和移动设备的紧凑型神经网络的推断精确度和收敛速度, 本文提出了一个特征图自适应知识蒸馏模型. 该模型的核心思想是利用本文提出的特征图适配器替换教师网络的部分模块, 在训练过程中自适应地学习迁移知识的策略. 实验结果表明, 该模型能产生有效用于学生网络监督的跨模型知识, 对于学生网络正确率的提高、 损失的降低、 训练速度的提升具有显著作用.
猜你喜欢
人大建设(2020年4期)2020-09-21 03:39:12
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
电子测试(2017年11期)2017-12-15 08:57:45
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
人大建设(2017年2期)2017-07-21 10:59:25
水利技术监督(2017年3期)2017-06-09 06:55:34
人大建设(2017年9期)2017-02-03 02:53:31
地矿测绘(2015年3期)2015-12-22 06:27:26
轻兵器(2015年20期)2015-09-10 07:22:44
