
长期记忆增强的时间感知序列推荐算法
2022-08-04 01:26:44陈继伟汪海涛朱兴翔
吉林大学学报(理学版) 2022年4期
陈继伟, 汪海涛, 朱兴翔, 姜 瑛, 陈 星
(1. 昆明理工大学 信息工程与自动化学院, 昆明 650504; 2. 国家电投云南国际电力投资有限公司, 昆明 650100)
传统推荐算法将用户交互记录存储在二维评分矩阵中, 通过填充矩阵空缺实现预测, 能挖掘用户的长期稳定偏好[1]. 与传统推荐算法不同, 序列推荐将用户交互历史视为物品序列, 而不仅是一组物品, 捕获用户物品交互的动态信息, 从而准确预测用户下次交互物品. 序列推荐考虑更多的是交互信息, 因此得到更准确的推荐结果, 同时也更符合真实的应用场景[2]. 近年来, 越来越多基于深度学习(DL)的方法被用于建模用户动态偏好, 但大多数基于深度学习的序列推荐算法都未足够关注长期偏好学习以及长期偏好和近期偏好的动态融合. 当用户意图不明确时, 动态结合用户的长期偏好和近期偏好, 有利于提升推荐结果的多样性和推荐系统的用户体验[3]. 时间信息包含重要的上下文语义, 一些序列推荐算法用自注意机制嵌入绝对时间, 将时间信息整合到物品嵌入表示中, 并取得了较好的实验结果[4-5]. 通过这种简单方式利用交互的时间信息, 不能完整捕获用户物品交互基于时间的多种模式, 许多时间相关的关键信息在很大程度上被忽略. 本文主要考虑时间信息在序列推荐中的影响. 基于广泛观察和研究, 发现用户行为基于两种基本时间模式: 绝对时间模式和相对时间模式. 前者突出用户时间敏感行为, 表现为人们可能在特定的时间点经常与特定产品交互, 如人们在一天中各时段播放的音乐通常不同, 在早晨和傍晚播放舒缓静谧的音乐, 中午播放流行音乐. 后者表示时间间隔如何影响两种行为之间的关系, 如用户常会在购买手机后的某个特定时间段内购买手机壳, 或购买同一日用品呈现某种周期性的间隔[6].
传统序列推荐算法, 主要关注用户的短期兴趣, 且常忽略交互的时间信息. 基于此, 本文提出一种长期记忆增强的时间感知序列推荐算法LatRec, 结合了传统推荐算法和序列推荐算法的优势. 该算法建模用户物品交互的时间信息, 通过多时间嵌入模式, 充分捕获用户物品交互的时间信息; 根据用户意图动态融合用户的长期偏好和近期偏好, 缓解序列推荐算法用户长期偏好建模能力不足的问题. 在真实数据集上进行仿真实验的结果表明, LatRec算法较对比的其他序列推荐算法在性能上有一定提高.
1 预备知识
1.1 非序列推荐算法
传统推荐算法利用协同过滤(collaborative filtering, CF)捕获用户偏好[7-8], 根据用户与用户或者物品与物品之间的相似性为用户提供感兴趣的物品. 矩阵分解(matrix factorization, MF)将用户和物品映射到同一向量空间, 通过用户和物品的向量内积衡量用户对物品的偏好程度[9]. 基于物品邻域的方法通过物品相似矩阵计算物品和用户历史交互物品的相似性表示用户对物品的偏好[10-11]. 近年来, 深度学习的发展促进了推荐算法的变革. Salakhutdinov等[12]在Netflix Prize上提出了一个两层的受限Boltzann机(restricted Boltzmann machines, RBM)用于协同过滤, 是深度学习用于推荐算法的早期尝试. 此外, 神经协同过滤(neural collaborative filtering, NCF)通过多层感知(multilayer perceptron, MLP)而不是内积估计用户偏好[13]. 基于深度学习的推荐算法旨在从整合辅助信息(如文本、 图像等)中学习到分布式物品表示, 提高推荐算法的性能. TimeSVD++[14]和BPTF[15]将时间信息用于矩阵分解中.
1.2 序列推荐算法
传统推荐算法常忽略用户物品交互的顺序, 而用户偏好和物品特性都是动态的, 从用户的交互序列中获取用户的偏好至关重要[1]. 早期的序列推荐算法利用Markov链(Markov chains, MCs)从用户交互历史中获取序列模式. Shani等[16]将推荐生成形式化为一个序列优化问题, 并使用Markov决策过程(Markov decision processes, MDPs)解决该问题; Rendle等[17]通过个性化的Markov链分解(factorizing personalized Markov chains, FPMC)将MCs和MF相结合, 同时建模用户的短期偏好和长期偏好. FPMC通过矩阵分解建模用户的长期偏好, 同等对待每个交互物品, 本文通过注意力机制将较多的注意力权重分配给对下次交互影响预测更重要的物品, 忽略对下次交互预测无关或影响较小的物品. 目前, 循环神经网络(RNN)及其变体门控循环单元(gated recurrent unit, GRU)、 长短时记忆网络(long short-term memory, LSTM)在用户行为序列的建模中应用广泛. 这些方法的基本思想是利用循环神经网络和损失函数将用户交互历史编码到一个向量中, 用于表示用户偏好, 并据此进行预测. 其中包括基于会话的GRU[18]、 基于注意力机制的GRU[19]、 改进损失函数(BPR-max, TOP1-max)和采样策略的GRU[20]. 基于RNN的序列推荐算法同等对待交互序列中的每个物品, 与用户对不同商品具有不同兴趣偏好的实际不符, 同时基于RNN的序列推荐算法不利于捕获用户的长距离依赖. 除循环神经网络, 其他神经网络也被用于序列推荐. Tang等[21]提出了一种卷积序列模型(Caser)使用水平和垂直卷积滤波器学习序列模式, 采用简单的学习用户潜在表示和连接操作, 无法很好地平衡用户的长期偏好和动态偏好. 注意力机制已在机器翻译和文本分类领域充分显示了其优秀的序列建模能力[22], 可利用注意机制提高推荐的性能. 如Li等[23]通过在GRU中加入注意力机制同时捕获用户的序列行为和基于会话的主要意图. 上述工作将注意力机制作为原始模型的一个组成部分, 但Transformer[22]和BERT[24]完全建立在注意力机制上, 并在文本序列建模方面取得了较好的结果. 因为它的高效性, 纯粹基于注意力的神经网络建模序列数据的应用越来越广泛, Kang等[4]利用两层Transformer decoder(称为SASRec)捕获用户的序列行为, 并在多个公共数据集上取得了较好的结果. 为更好地学习用户的交互历史, 许多性能优秀的序列推荐算法被相继提出. 尽管这些算法都具有出色的性能, 但大多数都忽略了交互的时间信息. 而交互的时间信息包含重要的上下文语义, 对下一项交互预测具有重要意义. Time-LSTM为LSTM配备了几种形式的时间门, 以更好地模拟用户交互序列中的时间间隔[25]. TiSASRec[26]利用注意力机制成功地合并了时间信息, 但其仅用一种简单的时间嵌入方法将时间信息整合到物品嵌入表示中, 无法完整捕获用户物品交互关于时间的序列模式.
2 长期记忆增强的序列推荐算法设计
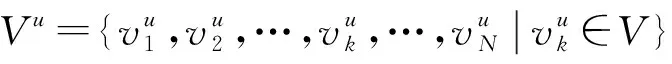
长期记忆增强的序列推荐算法由嵌入层、 近期偏好学习网络、 长期偏好学习网络和动态融合网络四部分组成.模型框架如图1所示.

图1 模型框架Fig.1 Model framework
2.1 嵌入层
在物品数组V中, 每个元素都有一个物品索引.与原方法类似[4,27], 使用查询操作和一个可学习的物品嵌入表MI∈(|V|+1)×h, 将交互物品序列嵌入为Eitem∈N×h, 其中h表示隐藏层的大小,MI保存|V|个物品的嵌入向量和[MASK]标记.
对于T, 每个元素都包含一个时间戳值, 时间序列与交互物品序列一一对应.本文提出绝对时间嵌入和相对时间嵌入两种嵌入T的方法.绝对时间嵌入是一个点态的概念, 将完整的时间戳信息描述为标识用户物品交互的独立变量.引入绝对时间嵌入将序列中的绝对时间信息编码为Ep, 绝对时间嵌入类似于在文献[4]中使用的可学习位置嵌入, 在Mp∈N×h中每个时间信息都有一个相应的嵌入式, 提取交互物品对应的时间信息得到Ep.相对时间嵌入是一个成对的概念, 侧重于描述每对用户行为之间的时间间隔.该信息反映了前一种行为对后者的影响, 不同的对可能表现出不同的模式.相对时间嵌入利用时间差异信息将序列中每个交互对之间的关系编码为ER.首先, 定义一个时间差异矩阵D∈N×N, 矩阵中元素的取值定义为dij=(ti-tj)/τ, 其中τ为一个可调节的参数, 然后利用sin函数将dij转化为隐藏层向量θij∈1×h, 计算公式为
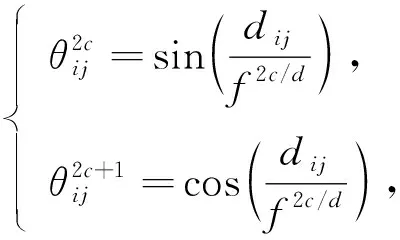
(1)
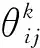
2.2 近期偏好学习网络

2.2.1 自注意力机制层
多头自注意力机制由文献[22]提出, LatRec的动态偏好学习模块同样基于该结构.单层自注意力机制的计算公式为
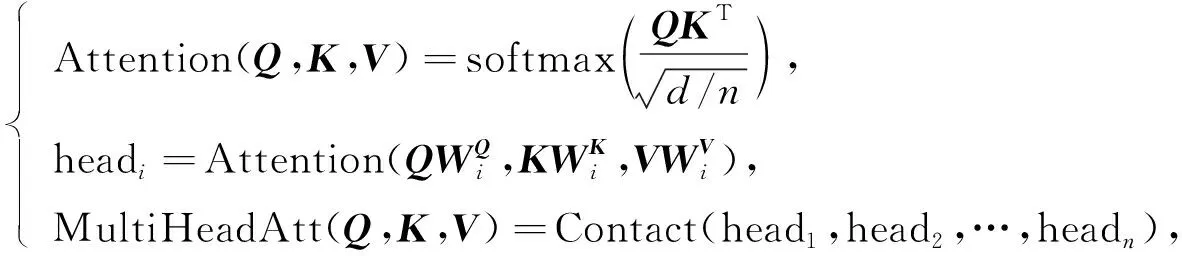
(2)
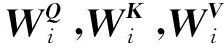
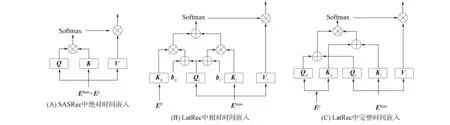
图2 单个自注意力机制层的计算过程Fig.2 Calculation process of a single self-attention mechanism layer
2.2.2 前馈神经网络
继自注意力层后, LatRec将自注意力层输出输入点状的前馈神经网络, 将前馈神经网络作为单独一层, 表示为
FFN(x)=GELU(xW1+b1)W2+b2,
(3)
其中W1∈h×2h,b1∈2h,W2∈2h×h,b2∈h都是可学习的参数.为方便训练, 与前述工作相同为每个子层引入残差连接:
y=x+Dropout(Attention(LayerNorm(x))),
(4)
z=y+Dropout(FFN(LayerNorm(y))).
(5)
堆叠b个这样的层, 给定最后一层的输出(o1,o2,…,oL)∈L×h, 从顶部自注意力模块获取输出向量oL∈1×d作为用户的动态偏好表示.
2.3 长期偏好学习网络
SASRec因为捕获用户动态偏好的优秀性能而得到广泛关注, 但由于SASRec保留了位置信息和因果约束, 不利于用户长期稳定偏好的捕获, 因此本文通过引进长期偏好表示增强SASRec[4].
本文的长期偏好学习网络由两部分组成: 1) 简单的前馈神经网络(FNN), 负责为当前序列Vu中的每个物品生成注意权重; 2) 注意力复合函数, 负责计算基于注意力的用户长期兴趣.
首先定义用户的序列表示m0, 计算公式为
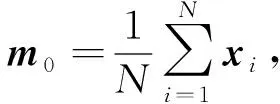
(6)
其中xi∈d表示第i个物品Vi∈Vu的嵌入向量.用于注意力权重计算的FNN计算公式为
αi=W0σ(W1xi+W2xt+W3m0+ba),
(7)
其中xt表示最后一次点击的物品,W0是一个加权向量,W1,W2,W3表示权重矩阵,ba表示偏置向量,σ(·)表示Sigmoid函数,αi表示物品xi的注意力权重.由式(6)可见, 交互序列中物品xi的注意力权重基于嵌入目标项xi、 最后点击物品xt和序列表示m0, 因此它可以基于用户的当前动态捕获用户的长期稳定偏好.
在得到注意力系数向量α=(α1,α2,…,αN)后, 基于注意力的用户长期偏好m根据如下公式计算:
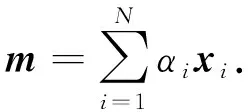
(8)
对于同一用户序列长期偏好表示相同, 式(7)中的相应参数(8)在训练阶段只更新一次, 增加一个Dropout层在训练期间将长期偏好推广到所有步骤, 长期偏好表示矩阵m∈N×d为
ml=Dropout(m),l∈{1,2,…,N}.
(9)
2.4 动态融合网络
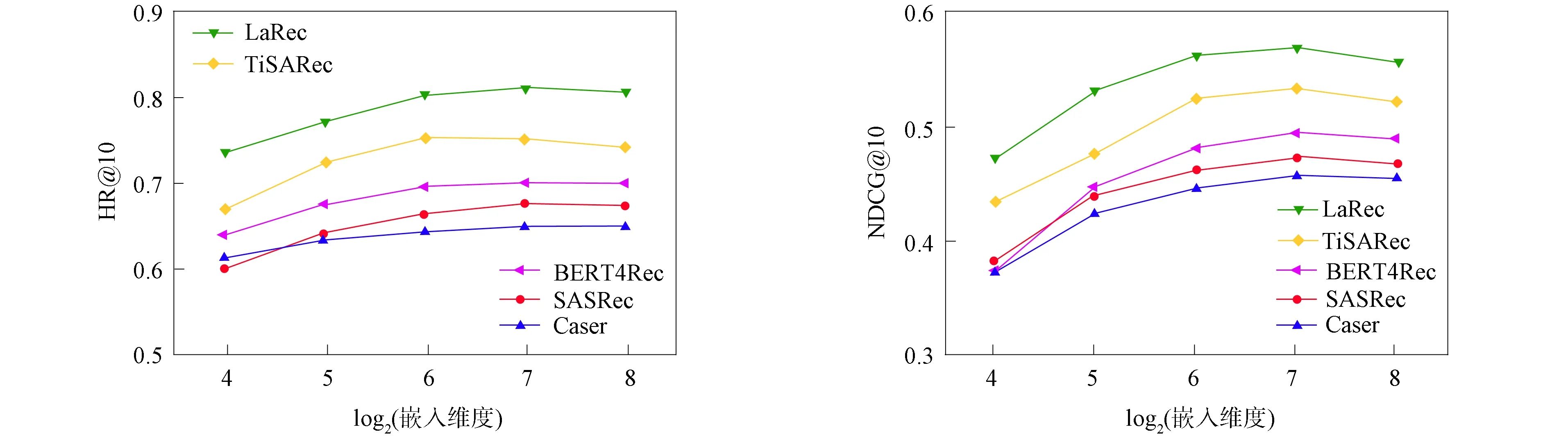
为有效结合长期偏好和短期偏好, 可考虑连接或求和.但为处理序列推荐中用户意图不明确的问题, 受神经项目相似性(NAIS)[28]启发, 提出物品相似门控模块.通过建模近期偏好表示oL, 长期偏好表示ml与最近交互物品xt之间的相似性计算长期偏好表示和近期偏好表示的权重.定义门控函数g的输出值作为近期偏好表示的权重, 并将其限制为0 g=σ([xt,ml,oL]WG+bG), (10) 其中WG∈3d×1和bG∈分别表示可学习的权重和偏差.本文使用Sigmoid函数σ(ξ)=1/(1+e-ξ), 所以g的取值范围为(0,1).用户u在第t步的最终偏好表示为近期偏好向量oL和长期偏好向量ml的加权和, 计算公式为 pl=oL⊗g+ml⊗(1-g), (11) 其中⊗表示点积运算.LatRec中g的取值范围可从(0,1)扩展为[0,1].当g=1时, 用户的最终偏好表示为用户的动态偏好表示; 当g=0时, 用户最终的偏好表示为用户的长期稳定偏好表示. 2.5.1 偏好预测 由如下公式计算用户u下次交互物品的概率预测: (12) 其中xi表示第i个候选物品的向量表示,rl+1,i表示第(l+1)次交互物品为xi的概率. 2.5.2 模型训练 本文使用Adam优化器, 通过最小化交叉熵损失函数训练本文的序列推荐模型, 损失函数为 (13) 本文采用MovieLens-1M和Amazon-Beauty两个来自不同领域、 稀疏程度不同的公开数据集作为实验数据, 验证本文算法的推荐性能. 首先根据用户将交互记录分组, 并根据交互的时间戳信息升序排列, 形成用户的交互序列; 然后将交互次数小于5的用户和物品过滤[4,26-27]. 经过处理后各数据集的静态特征列于表1. 表1 数据集静态特征 3.2.1 评价指标 采用广泛使用的leave-one-out评估方法评价LatRec推荐算法的推荐性能. 对于每个用户交互序列, 将用户交互序列的最后一个交互物品作为测试集, 倒数第二个交互物品作为验证集, 其他交互物品作为训练集. 与其他经典的序列推荐模型设置相同, 将随机抽取的100个尚未被指定用户交互过的物品作为负样本[4,26-27]. 与用户实际交互物品排列在一起作为LatRec模型的输入, 让模型对其排序. 为评价排序表, 本文利用下列两个通用的评价指标: HR@10(命中率), 刻画正确推荐物品在测试物品中所占的比例, 表示为 (14) 其中:N表示用户的总数量; hits(i)表示第i个用户访问的值是否在推荐列表中, 是则为1, 否则为0; @10表示推荐列表中物品的个数为10. NDCG@10(归一化折损累计增益), 不仅考虑HR(命中率), 而且考虑排列顺序. 给位于推荐列表前端的命中物品分配高分, 位于推荐列表末端的命中物品分配低分, 表示为 (15) 其中rank表示命中物品在推荐列表中的位置. 3.2.2 实验环境设置 本文实验的硬件环境为Intel core i7 CPU, 16 GB内存, Nvidia 1060 Ti显卡. 软件环境为Window10操作系统. 编程环境为Python3.6.1. 嵌入层和预测层的物品嵌入向量相同, 本文用PyTorch实现序列推荐模型, 利用Adam优化器优化模型, 学习率设为0.001, 物品嵌入向量、 时间嵌入向量的维度均设为64. mini-batch大小分别设为128, 对于数据集MovieLens-1M和Amazon-Beauty将Dropout率分别设为0.2和0.5. 最大序列长度N在数据集MovieLens-1M和Amazon-Beauty上分别设为200和50. 1) POP方法, 其将所有物品根据受欢迎程度排序, 受欢迎程度取决于交互的数量; 2) BPR方法, 其将Bayes个性化排序与矩阵分解模型相结合, 是最先进的非序列推荐算法, 基于隐式反馈信息[29]; 3) FPMC方法, 其结合矩阵分解和Markov链, 可同时捕获序列信息和长期用户偏好[17]; 4) Caser方法, 在时间和潜在空间中将一系列最近交互的物品视为一个“图像”, 捕获L个最近交互物品的高阶Markov链[21]; 5) SASRec方法, 是一种基于Transformer体系结构的序列推荐方法[4]; 6) BERT4Rec方法, 其采用深度双向注意力机制建模用户行为序列, 取得优秀的序列推荐性能[27]; 7) TiSASRec方法, 其利用注意力机制成功地合并时间信息, 将时间信息整合到物品嵌入表示中, 但无法完整地捕获用户物品交互关于时间的完整序列模式[26]. 为保证不同方法对比的公平性, 本文根据原文献的源代码, 用PyTorch实现BPR,IRGAN和FPMC方法. 对于Caser,SASRec,BERT4Rec方法, 使用原有的源代码, 对于所有模型中的通用超参数, 用网格搜索在验证集上寻找最优参数设置, 考虑潜在向量维度的取值范围{16,32,64,128,256},l2正则化参数的取值范围{1,0.1,0.01,0.001,0.000 1}, Dropout率的取值范围{0,0.1,0.2,0.3,…,0.9}. 所有其他超参数设置和初始化策略与原文献保持一致, 并使用验证集调整超参数. 给出每种方法在其最优超参数设置下的结果. 下面对本文提出的LatRec推荐模型做整体性能分析. 本文算法与对比方法基于评价指标HR@10和NDCG@10的性能比较列于表2. 表2 不同方法的整体性能对比结果 由表2可见: 1) 基于流行度的POP方法推荐性能较好, 这主要基于人们通常倾向于选择较受大众欢迎的物品, 大众的选择倾向常引起物品的热度提升, 给用户推荐流行度较高的物品会取得较好的推荐结果, 但推荐缺乏个性化; 2) BPR作为目前性能较优秀的非序列推荐算法, 在序列推荐任务中, 基于序列的推荐算法在两个数据集中的推荐性能都较BPR好, 充分显示了捕获用户交互序列模式的有效性; 3) Caser,SASRec和BERT4Rec方法性能较FPMC方法更优秀, 充分显示了深度神经网络潜在特征的学习能力和序列任务建模能力; 4) LatRec方法在两个数据集上显示出较基线方法更优秀的推荐性能, 得益于对时间信息的多模式嵌入, 注意力机制对时间信息和序列信息的捕获, 此外长期记忆增强同样提升了LatRec方法的推荐性能. 3.5.1 多时间嵌入模式以及长期记忆增强的有效性分析 本文采用绝对时间嵌入和相对时间嵌入两种方式建模用户物品交互的时间信息. 使模型不仅对绝对的时间信息敏感, 且其能捕获用户物品交互关于时间的周期性变化. 将该模型在数据集MovieLens-1M上进行各部分有效性验证, 首先分别构造模型LatRec的变体LatRec1和LatRec2, LatRec1用与SASRec类似的时间信息嵌入方式, LatRec2对长期偏好表示进行遮掩操作. 模型其他部分与原模型相同, 采用与原模型相同的参数进行训练, 并与原模型进行推荐性能比较, 实验结果列于表3. 表3 多时间嵌入模式及长期记忆增强的有效性分析 由表3可见, 采用多时间嵌入模式和长期记忆增强有效提高了推荐算法的性能. LatRec1的推荐性能较SASRec有所提高, 证明长期记忆增强的有效性. 本文提出的多种时间嵌入模式, 不仅对绝对时间信息敏感, 且其能捕获用户物品交互的周期性变化, 有效建模用户交互的时间特征. 这基于用户喜欢在某个特定的时间段看某个特定类型的电影, 或者用户重复看某部电影或某种题材的电影呈现出某种时间上的周期性规律. LatRec2表现出较SASRec优秀的推荐性能, 证明了LatRec模型多种时间嵌入模式设计的有效性. 同时LatRec表现出较SASRec更好的推荐性能, 充分验证了多时间嵌入模式以及用户长期偏好与用户近期偏好动态结合的有效性. 基于注意力机制序列特征的建模能力以及潜在特征的捕获能力, 能捕获用户的长期稳定偏好和近期偏好, 并通过动态融合将用户的长期偏好和近期偏好相结合, 使推荐结果更准确、 更多样. 3.5.2 嵌入维度分析 保持其余最优参数设置不变, 嵌入维度d的取值范围为16~256. 在不同维度分别进行实验, 获取衡量指标NDCG@10和HR@10的值, 考察嵌入维度d对序列推荐算法性能的影响. 实验结果如图3所示. 图3 嵌入维度分析结果Fig.3 Analysis results of embedding dimension 由图3可见, 随着嵌入维度的增加, 推荐算法的性能度量指标逐渐增大. 当达到某一特定值再增加嵌入维度时, 度量指标基本不再发生改变, 逐渐收敛. 并不是嵌入维度d值越大, 推荐算法的性能越好. 嵌入维度过大可能会导致数据稀疏, 增大训练难度, 此外嵌入维度过大也可能会导致发生过拟合. 本文提出的LatRec推荐模型在各嵌入维度都取得了较基线方法更优秀的推荐结果, 充分验证了本文算法的推荐性能. 当嵌入维度达到64时, 继续增加维度推荐算法的度量指标基本不再发生变化或略有下降, 所以在本文的其他实验中将嵌入维度设为64. 综上所述, 通过对基于注意力机制的推荐算法进行分析和改进, 本文提出了一种长期记忆增强的时间序列感知推荐算法LatRec. LatRec算法充分考虑了影响用户交互预测的时间、 序列信息、 动态融合用户的长期稳定偏好表示和近期动态偏好表示. LatRec算法充分挖掘了用户的潜在喜好, 使推荐的结果呈现多样性, 提升了推荐系统的用户体验. 但由于该算法采用多个神经网络和多种时间嵌入模式, 使算法的训练需花费较长的时间, 对运行设备的运算速度也有一定要求.2.5 模型预测和训练
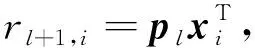
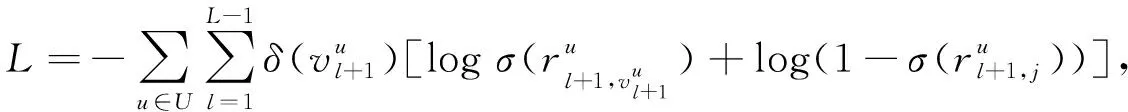
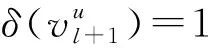
3 实 验
3.1 数据集的构造

3.2 实验设置


3.3 对比方法
3.4 算法整体性能分析

3.5 算法分析

猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
中华诗词(2019年7期)2019-11-25 01:43:00
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
灯与照明(2016年4期)2016-06-05 09:01:45
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:24
小天使·一年级语数英综合(2015年8期)2015-07-06 06:23:32
