
针对苹果树叶病害图像分类的小样本学习方法
2022-08-04 01:26:44王紫薇范丽丽赵宏伟
吉林大学学报(理学版) 2022年4期
李 蛟, 王紫薇, 范丽丽, 赵宏伟
(1. 吉林大学 图书馆, 长春 130012; 2. 吉林省商务信息中心, 长春 130061;3. 吉林大学 计算机科学与技术学院, 长春 130012)
病原体和昆虫是威胁苹果园安全的主要因素. 目前, 苹果园的病虫害检测主要依赖于农作物顾问的人工检查[1-2], 而使用人力进行观察既慢又提高了生产成本, 且在大田间区域连续监视所有植物效率较低. 因此, 自动检测植物病害目前已被广泛关注.
计算机成像技术和机器学习的发展在加快植物病害诊断方面显示了极大的潜力[3]. 数码相机可捕捉具有疾病症状的高质量图像, 计算机视觉方法可利用有症状的数字图像对疾病进行分类[4-5]. 随着深度学习在计算机视觉领域内的发展, 基于图像的植物病害检测已引起广泛关注. 深度卷积神经网络(DCNN)[6]在图像分类和检测问题上性能较好. 利用该网络对图像特征进行提取, 已实现了均匀设置下拍摄的农作物病叶图像的分类[7-8]. 目前, 使用计算机视觉在更复杂的摄影条件下进行农作物病害的识别研究已有很多成果[9-10]. Amara 等[11]利用LeNet 卷积神经网络作为基本架构从健康的叶片中检测和区分了香蕉斑点病; Dubey等[12]使用K-means聚类算法检测苹果树叶受感染的部分, 并利用支持向量机根据颜色、 纹理和形状对健康和受感染的苹果树叶进行分类, 此外, 还设计了多种支持向量机提取特征, 在植物病害分类中具有巨大潜力. 卷积神经网络与迁移学习相结合可获得良好的性能, 该学习使用如AlexNet[3],VGG[13],ResNet[4]等预先训练的模型, 然后更新参数. 目前, 基于迁移学习的苹果树叶病害检测已有很多方法[14-16], 但迁移学习方法之间的差异很小, 并且这些方法的设计, 尤其是利用深度卷积神经网络方法, 在很大程度上依赖于丰富的标签数据, 但对于苹果树叶病害识别, 病害种类多且形态各异, 数据集的获取和标记需大量的人力和生产成本.
本文以常见特征相似的苹果树叶锈病、 黑星病以及混合病害为研究对象, 考察卷积神经网络在小样本下的分类问题. 首先, 使用卷积神经网络学习输入图像在特征空间的非线性映射, 获得每个图像的特征向量; 其次, 根据特征向量求出中心点、 所有点距离中心点的平均距离及几个簇的半径; 再次, 根据点到簇中心的距离与半径的关系, 找出离群候选集, 计算离群候选集中因子的局部可达密度, 并根据密度值确认离群因子进行剔除; 最后, 将剩余的特征点作为支持集, 并求取嵌入空间中支持集的平均值, 根据查找最近的类原型, 即可对嵌入式查询点进行分类.
1 算法实现
1.1 符号表示
在小样本分类中, 将n个类别的样本定义为s={(x1,y1),(x2,y2),…,(xn,yn)}, 其中每个x1∈D表示每个样本的D维特征向量, 而yi∈{1,2,…,K}表示相应的标签,Sk表示类别为k的一组样本.
1.2 模 型
网络利用嵌入函数fø:D→M计算每个类别的M维表示ck∈M, 其中ø为嵌入函数中的可学习参数.根据类中所有样本的特征表示, 计算得到每一类中心点的均值向量:
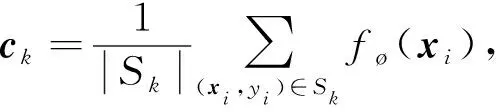
(1)
其中|Sk|表示类别为k的一组样本的样本数目,fø(xi)表示样本xi的特征表示.以ck为类中心点, 分别求出每个类别中其他点与中心点距离的平均值为

(2)
其中d(·,·)表示两个样本特征向量之间的欧氏距离.在每一类别中, 计算每个样本与中间点之间的距离d(ck,xi), 并将d(ck,xi)与Ri进行比较.如果d(ck,xi)>Ri, 则将该样本放入离群点候选集.
为方便表示, 将样本和每一类的中心都视为点.将中心点定义为O, 其他样本点定义为x.dw(O)为点O的第w距离,dw(O)=d(O,x), 其表示点x是距离O最近的第w个点.图1为第w距离示意图.由图1可见, 点x6为距离中心O最近的第6个点,w=6.定义Nw(O)为点O的第w距离邻域,Nw(O)={x′∈D{O}|d(O,x′)≤dw(O)}, 即Nw(O)包含所有到点O第w邻域距离的点, 易得Nw(O)≥w, 图1中点O的第6距离邻域为N6(O)={x1,x2,x3,x4,x5,x6,x7}.
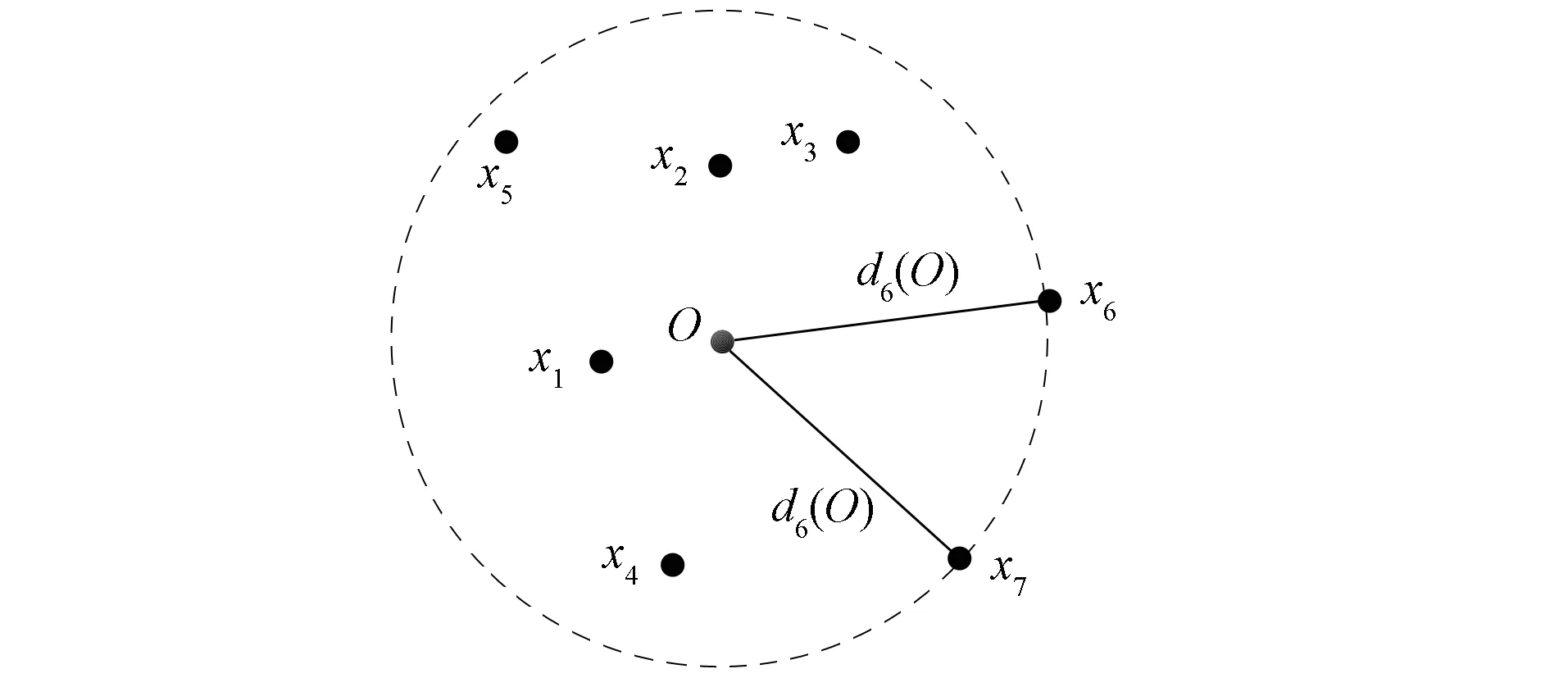
图1 第w距离示意图Fig.1 Schematic diagram of w-th distance
根据以上定义, 计算点O的第w邻域内所有点到O的平均可达距离, 即局部可达密度为
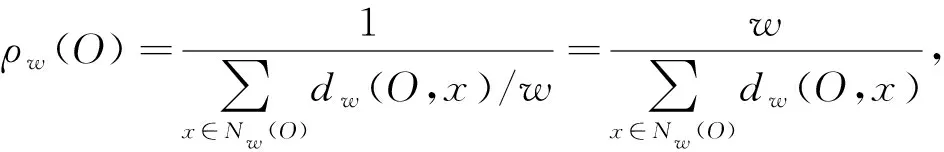
(3)
其中dw(O,x)为点x到点O的第w可达距离, 其至少是点O的第w距离.如果点O与邻域点属于同一类别, 则可达距离为较小的dw(O), 局部可达密度大; 反之, 局部可达密度小.根据局部可达密度, 可计算局部离群因子, 其计算公式为
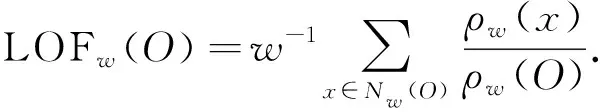
(4)
局部离群因子表示点O的邻域Nw(O)内其他点的局部可达密度与点O的局部可达密度之比的平均数.如果该值接近1, 说明O的邻域点密度相似,O可能与邻域属于同一类别, 如果该值小于1, 说明O的密度高于其邻域点密度,O为密集点; 如果该值大于1, 说明O的密度小于其邻域点密度,O可能是异常点.找到异常点后, 将异常点剔除.
在每一类别中, 对剔除异常点的其他特征向量根据式(1)再次求取中心点的均值向量.对于每个需要分类的样本点x, 计算其属于类别k的概率为

(5)
这里取距离的相反数是因为相距最小的最优可能是该样本对应的类.此分布是基于查询集中样本的嵌入与该类重构特征之间距离上的Softmax.小样本学习阶段的损失函数为
(6)
2 实验与分析
2.1 实验数据
数据集MiniImageNet是评估小样本学习方法性能的基准. 该数据集是从ImageNet中随机选择的子集, 仅包含100个类别的60 000张图像, 每个类别有600张图像. 本文参照文献[17]中的数据分割策略, 使用其进行网络预训练.
苹果树叶病数据集[18]是在美国纽约州未喷洒农药的商业种植园中, 利用佳能Rebel T5i DSLR相机和智能手机在各种光照、 角度、 表面和噪声条件下拍摄的, 数据集的复杂度较高. 其包含3 651张高质量的带标签RGB图像, 分别为雪松苹果树叶锈病、 苹果树叶黑星病、 复杂疾病(同一片树叶中有一种以上疾病)和健康的苹果树叶. 其中雪松苹果树叶锈病图片1 200张、 黑星病图片1 399张、 复杂疾病图片187张、 健康树叶图片865张, 样本的不平衡增加了数据集的复杂性. 数据集的类别图片如图2所示. 为进行分类评估, 本文将80%的数据集进行训练, 剩余的20%用于测试.

图2 数据集中4种类型的样本图像示例Fig.2 Examples of four types of sample images in data set
2.2 实验平台和参数设置
本文实验环境为Xeon(R)CPU E5-2620 V3, NVIDIA(R)Titan X显卡, GPU的内存为12 GB, 驱动程序为418.67, CUDA为10.1版本, 操作系统为Ubuntu 18.04 LTS, Pytorch版本为v1.0.0. 主体网络为AMDIM(ndf=192, ndepth=8, nrkhs=1 536), 维度设为1 536, 学习率为0.000 2.
2.3 实验结果
2.3.1 剔除离群点
为验证剔除离群点对分类效果的影响, 在训练时进行对比实验, 分别在存在离群点和剔除离群点时对网络进行训练, 实验结果列于表1. 由表1中损失值和准确率的变化易见, 剔除离群点后网络更容易收敛, 并且分类准确率更高.
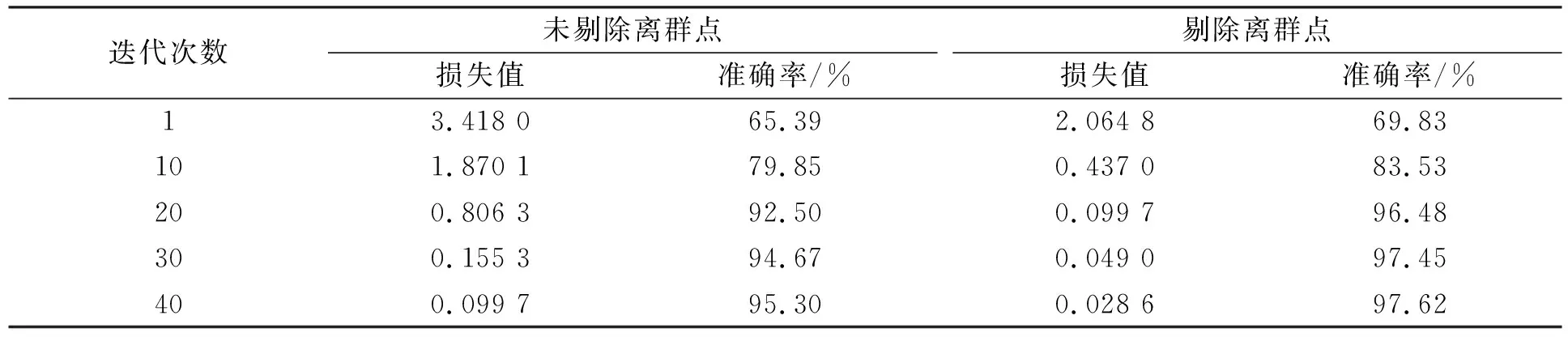
表1 剔除离群点与未剔除离群点的性能比较
2.3.2 分类性能
利用支持向量机(SVM)[19],AlexNet,GoogLeNet[20],VGGNet-16和ResNet学习模型, 对苹果树叶病害数据集进行训练, 学习率设为0.001, 选择SGD作为优化算法, 实验结果列于表2.

表2 不同方法的性能比较
由表2可见: 本文方法能充分利用信息量大的样本, 在测试集上的准确率达97.62%, 高于其他模型; AlexNet模型具有良好的分类能力, 平均准确率为92.30%; GoogLeNet具有多个Inceptions, 并具有多维特征提取的能力, 但其网络不受苹果树叶病理图像特征的调节, 最终分类准确率达94.17%; ResNet-20作为残差神经网络, 其准确率为94.42%; VGGNet-16通过迁移学习实现了96.50%的准确率; 带有SGD优化器的SVM模型的准确率为55.23%. 实验结果表明, 传统方法在很大程度上依赖专家设计的分类特征提高识别精度, 而专家经验水平对分类特征的选择有较大影响. 与传统方法相比, 本文小样本学习网络可从多个维度自动提取最佳分类特征, 而且还可以学习从边缘、 角和颜色等低层特征到高层语义的分层特征.
综上所述, 本文针对传统分类方法中存在苹果树叶病害样本数量少和缺乏标签的问题, 利用小样本学习方法和卷积神经网络对苹果树叶病害图像进行了分类实验. 首先, 使用LOF将离群因子选出并剔除, 对剩余的样本求得特征均值, 根据查询样本与均值的关系确立样本类别. 其次, 将本文模型与传统卷积神经网络模型进行性能对比, 结果表明: 本文模型不需要大量有标签的样本, 避免了样本不平衡和背景不均匀对分类结果的影响, 鲁棒性强; 对光照、 焦点等变化的适应性较好; 训练模型容易迁移, 可用于其他小样本的识别.
猜你喜欢
吉林大学学报(理学版)(2020年3期)2020-05-29 06:32:16
自动化学报(2018年7期)2018-08-20 02:59:04
周口师范学院学报(2016年5期)2016-10-17 06:36:47
中国房地产业(2016年9期)2016-03-01 01:26:47
新校长(2016年8期)2016-01-10 06:43:59
作文评点报·低幼版(2015年5期)2015-05-30 10:48:04
商事法论集(2014年1期)2014-06-27 01:20:42
西安交通大学学报(2014年8期)2014-04-16 05:07:06
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
上海电机学院学报(2014年3期)2014-02-28 14:29:45
