
基于深度学习的植物种子萌发差异检验
2022-08-04 10:37:50曾祥潘广东省广州市白云区景泰小学
中国信息技术教育 2022年15期
曾祥潘 广东省广州市白云区景泰小学
孙丽君 山东省淄博第二中学
吴俊杰 北京师范大学物理系
种植活动是劳动教育的重要组成部分,育种则是种植的开端。在育种过程中,土壤pH是影响种子萌发的重要因素之一,pH发生变化,引起农业减产。在不同pH条件下种子萌发的差异怎样判断呢?这就需要进行检验。通过种子萌发实验,取得实验数据;对实验数据进行分析检验就可以获知不同pH条件下种子萌发有没有存在差异。
本实验研究采用对照实验,选取两组不同pH条件下的种子进行萌发实验,实验过程定时拍照记录;再利用深度学习目标检测算法识别照片中的发芽种子,取得实验数据;最后使用R语言对两组数据进行检验,让学生体验用深度学习解决实际问题的过程。
●设计思路
本实验以不同pH条件下萌发绿豆种子为实验样本,通过深度学习的目标检测算法识别种子发芽,获取种子萌发数据。实验过程经历目标检测数据集制作、模型训练、使用模型预测等一系列步骤,最后使用R语言工具进行数据检验。
目标检测是深度学习重要的应用领域之一,其中出现了许多先进的算法,如R-CNN、SSD、YOLO等。本实验选用目前最新的YOLOv5(v6.1),其特点是识别准确率高、速度快。
此外,实验过程中拍摄的种子培养皿照片,通常可达数百万像素。种子在整张照片中所占比例很小,属于小目标,如果将这些照片直接识别,YOLOv5会按比例将照片长边缩小为640像素,照片中的小目标将丢失许多图像细节,导致识别效果很差,甚至出现无法识别的情况,因此,需要采取辅助手段提高识别效果。经过查询发现,已有多种解决方案可实现提高识别效果。本实验选用SAHI(Slicing Aided Hyper Inference)辅助识别发芽种子,SAHI支持使用YOLOv5模型识别,省去其他工具需要转换模型文件的操作,使用更简便,其工作原理是将原始图像切割成若干张,再进行识别,识别完成后,将识别结果融合输出。
●实验准备
在市场购买绿豆,选取籽粒饱满、大小匀称的种子作为实验材料。为了降低实验难度、提高实验的易操作性,只选取两组样本进行对照实验,每组配备100颗种子。其中实验组在碱性条件萌发,对照组在中性环境萌发。碱性条件使用碳酸氢钠兑纯净水,pH值调整为7.5;中性环境使用纯净水,pH值为7。准备拍照用手机、安装YOLOv5及R语言等软件的计算机。
●实验过程
1.准备模型训练样本
高质量的训练样本是人工智能模型训练的首要条件。在购买绿豆种子后先尝试萌发,这样既可以检验种子能否成活,还能采集到样本照片。种子用温水浸泡2小时,然后将其均匀放置在平铺了三层吸水纸的培养皿中,吸水纸保持湿润。24小时后有部分种子发芽,开始拍摄照片,旋转培养皿从不同角度拍摄。12小时后重复拍摄一遍。
原始照片要用图片处理软件裁切成若干张640×640像素图片,每张图片含有5~10颗种子。用Labelimg对裁切后的图片进行标注,设置yolo标签格式,用标记框把已发芽的种子框选,注意控制选择范围,要把种子和种芽框选在内。要取得较好的模型训练效果,样本数量应在300以上。
2.训练模型
使用YOLOv5训练模型的指令如下:
python train.py --data data/(训练样本yaml配置文件) --cfg models/yolov5s.yaml --workers 0 --batch-size 4 --epochs 50
训练时间因不同计算机配置和训练次数从几小时到十几小时不等。在训练完成后对模型进行测试,看能否识别出发芽的种子,指令如下:
python detect.py --source=“data/(发芽种子jpg文件路径)” --weights=“runs/train/exp/weights/best.pt”
模型训练和预测过程如图1所示。

图1 模型训练与测试
3.采集数据
将两组种子分别放入pH7.5碳酸氢钠和pH7纯净水中,浸泡2小时后沥干,均匀放置在铺有吸水纸的培养皿中。每隔2小时拍摄一次照片,连续拍摄48小时。超过48小时长出胚叶会增加实验的复杂性,暂不记录。
拍摄完成后取得两组实验照片,每组25张。用SAHI对两组照片进行预测,识别出发芽的种子,取得发芽数据。SAHI操作指令如下:
sahi predict --source data/(图片文件夹路径) --model_type yolov5 --model_path weights/(模型文件路径) --model_device cpu --export_pickle --project resources
将识别结果保存在resources文件夹中,效果如图2所示。
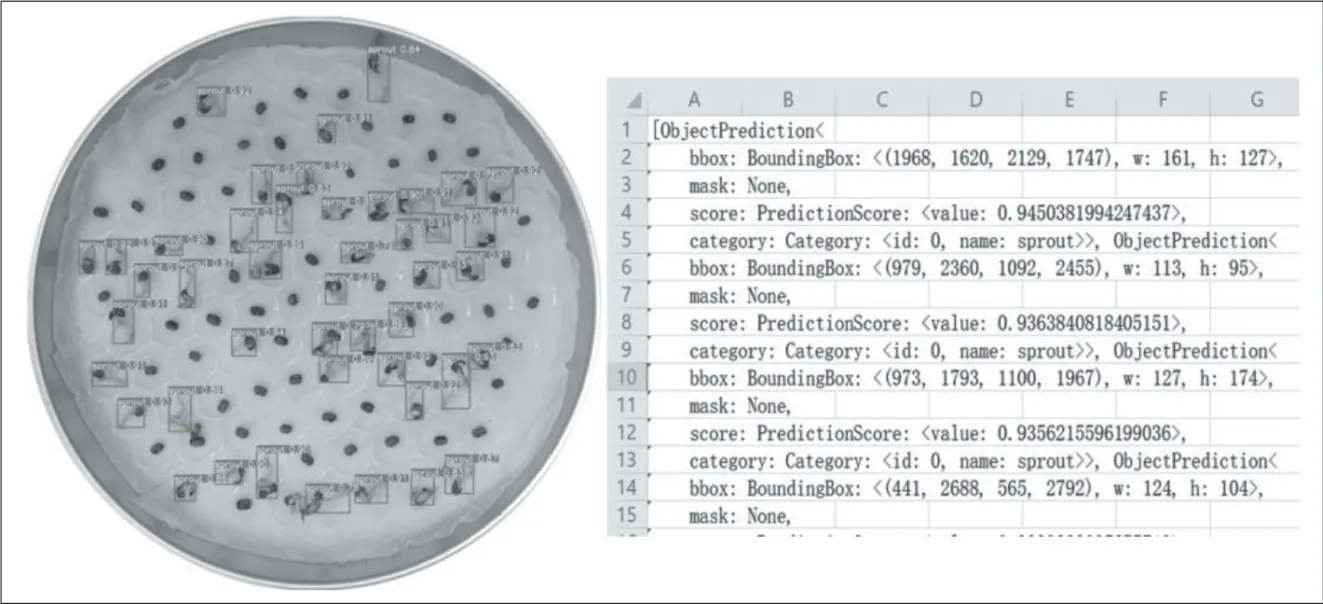
图2 SAHI识别结果
将识别数据进行整理,把置信度达到0.5或以上的识别结果视为种子发芽,将每张图片的发芽数量记录到电子表格中。
4.数据分析
比较两组实验数据是否存在差异,可以使用R语言进行检验。在进行差异检验之前要先对数据进行正态性检验,再根据检验结果选择适当的差异检验方法。
(1)正态性检验
由于每组实验数据为25个,属于小样本,因此正态性检验选择了适合小样本的SW检验。检验指令和结果如图3所示。

图3 SW正态性检验结果
从检验结果可知,两组数据的p-value均小于0.05,说明两组数据都不符合正态分布。
(2)差异性检验
由于两组实验数据都不符合正态分布,两者属于独立的小样本,因此检验这两组数据差异应采用两独立样本非参数检验。针对两独立样本非参数检验,R语言提供了wilcoxon秩和检验。检验指令和结果如图4所示。
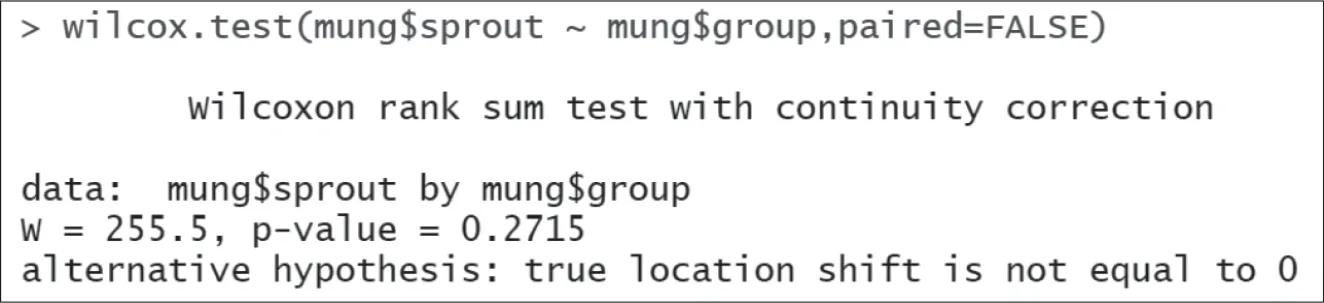
图4 wilcoxon秩和检验
从计算结果得知,p-value=0.2715,显著性水平α=0.05,p-value大于显著性水平,说明拒绝原假设(原假设是两组样本数据有明显差异),因此两组实验数据并没有明显差异。
●总结
从实验结果发现,两组实验绿豆种子浸泡了不同pH值液体,对发芽率并没有影响,这跟其他专家实验结果不一致。究其原因可能是使用的液体pH相差太小,没有使用pH8或者以上的液体进行浸泡,或者浸泡时间太短等。这还有待于今后进一步实验验证。
本实验采用了YOLOv5及SAHI深度学习工具,完成了模型的训练和预测,对发芽种子进行识别,最后用R语言工具进行数据分析。这一方法还可以在各种实验项目中使用,如在细胞实验中对不同细胞种类识别和计数等。
猜你喜欢
数学年刊A辑(中文版)(2023年4期)2024-01-04 05:47:32
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
理化检验-化学分册(2020年12期)2020-03-02 12:07:24
儿童时代·幸福宝宝(2019年9期)2019-10-28 18:04:52
中国特种设备安全(2018年10期)2018-12-18 02:16:46
幼儿园(2018年15期)2018-10-15 19:40:36
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
莫愁·家教与成才(2017年7期)2017-07-11 21:31:47
数学学习与研究(2017年3期)2017-03-09 18:12:42
山东工业技术(2016年15期)2016-12-01 05:30:56
