
基于PSO-ELM算法的红外目标模拟器校准数据拟合方法研究
2022-08-03 02:42张馨怡陈振林
计算机测量与控制 2022年7期
张馨怡,陈振林
(海军航空大学,山东 烟台 264001)
0 引言
红外辐射计主要用于红外目标的辐射照度等辐射特性的准确测量,不同拟合方法会对测量精度产生较大影响。对于红外目标模拟器校准装置,很多因素都可能导致校准数据呈现出非线性的特点,主要可分为两大类[1-5]:系统自身所带来的非线性和环境引入的非线性。导致系统自身带来非线性的主要因素包括:光学系统中,镜面加工精度、孔径、焦距、光轴偏转角度等;探测器的灵敏度;系统电路对电信号进行放大处理时,电信号进入不同放大器。环境引入的非线性一般难以预测,主要由背景辐射的变化导致。
在红外目标模拟器的校准数据处理中,最常见的方法是最小二乘法(LS,ordinary least squares)。但最小二乘法只注重寻找局部极值点,找到的并不一定是全局最优解。而且最小二乘法很难精确拟合标准辐射源辐射和探测器实际测量辐射照度之间的非线性关系。文献[6]在最小二乘法的基础上提出偏最小二乘-投影寻踪回归法(PLSPP,partial least squares regression projection pursuit),主要利用降维的方法用较少的因素描述数据,但此方法更适用于大规模数据集,且对于非线性数据的处理仍不理想。之后,文献[7-8]针对数据非线性的问题提出了基于粒子群优化的自适应支持向量回归算法(PSO-ASVM,particle swarm optimization-adaptive support vector regression),但同样存在一些弊端,支持向量机算法非常难以训练。
相较于最小二乘法,神经网络算法的容错性以及对复杂非线性数据处理性能较好,但传统的bp神经网络(BPNN,back propagation neural network)速度较慢,且易陷入局部最优解。相较于bp神经网络,极限学习机(ELM,extreme learning machine)具有其独特的优越性,前人的研究表明,ELM的精度更高,具有较好的泛化能力,处理速度更快[9]。但由于该算法参数设置往往是通过个人经验和简单调整,难以得到最优拟合精度,所以文中采用粒子群算法(PSO,particle swarm optimization)对ELM参数进行优化。PSO-ELM与传统的机器学习算法相比,具有更高的预测精度和更强的泛化能力。本研究的目的如下:
1)解决ELM模型随机参数对预测结果的影响;
2)提高红外目标模拟器校准数据精度。
1 模型建立
1.1 ELM-PSO算法
BP神经网络是典型的多层前馈神经网络,采用梯度下降法对网络进行训练,但梯度下降法有一定的局限性,在训练过程中需要设置各种参数值。此外,在迭代过程中需要调整网络的权值,使得模型的计算速度较慢,而且往往收敛于局部最小值,拟合精度不高。ELM针对这些不足进行改进,它实际上是一个基于单隐层前馈神经网络(SLFNs,single-hidden layer feedforwa-rd neural network)的网络结构,只有一个输入层、一个隐含层和一个输出层[10-11]。基于反向传播法,多层前馈神经网络在迭代过程中需要更新权值,但ELM算法在迭代过程中不需要更新的随机初始权值,因为它的训练过程是基于输出权值和随机生成的输入隐含层参数(权值和阈值)。因此,不需要像传统方法那样调优所有的网络参数,从而可以克服基于梯度的方法的许多问题,如学习速率、局部最小值和学习时间。它解决了现有基于神经网络的算法训练速度慢和过拟合的问题。
前人的研究表明,ELM的精度最高,处理时间比SVM和BPNN分别快1180倍和809倍。ELM具有较好的泛化能力,处理时间较BPNN快[12-13]。
设训练样本集是一组点{xi,ti},其中i=1,2,…,N。具有L个隐藏神经元和激活函数h(x)的标准SLFNs的数学模型/一般估计函数可表示成如下形式:
(1)
这里,j=1,2,…,N,ωi=(ωi1,ωi2,...,ωiD)T,代表连接第i个隐藏神经元和输入层的权重向量;βi=(βi1,βi2,...,βiK)T代表连接第i个隐藏神经元和输出层的权重向量,bi是第i个隐藏神经元的阈值。
具有L个隐藏神经元和激活函数h(x)的标准SLFNs模型的可以写成矩阵形式:
Hβ=T
(2)
其中:
H称为神经网络的隐层输出矩阵;H的第i列是第i个隐节点对输入x1,…,xN的输出,若已知激活函数h(x)、ωi、bi和xi,就可以直接计算出H。

(3)

如果ωi和bi预先确定,根据式(3),则可以把训练过程等价于一个求线性系统Hβ的问题:
(4)
这个方程具有唯一的解,β由下式计算可得:
β=H+T
(5)
其中:H+为H广义逆矩阵。
因此,ELM算法的拟合精度很大程度上依赖于激励函数h(x)以及ωi和bi的选取。当预先给定一个激励函数时,随机选取的不同权值ωi和阈值bi会产生不同的隐层输出矩阵H,可能导致不同的训练误差。所以可以将优化过程描述为以下形式:
(6)
其中:β=H+T。
当给定训练数据集的激活函数h(x)和隐藏神经元数L时,可以通过以下步骤建立ELM:
1)初始化输入权值、阈值和隐藏节点数;
2)计算隐含层输出矩阵H;
3)利用广义逆矩阵H+计算隐含神经元到输出层的权值向量β;
4)计算回归输出。
ELM模型虽然具有良好的模型性能和快速的学习速度,但由于一般随机确定模型参数,缺乏泛化能力。通常情况下,ELM模型随机调整权值和阈值,可能导致模型无法得到最优解,增加了拟合过程中的不确定性。因此,利用优化算法确定ELM模型的初始参数可以避免非最优解,提高模型性能。PSO算法和遗传算法(Genetic Algorithm,GA)是两种广泛使用的参数优化算法,都属于群体搜索算法,通过群体之间的合作来完成搜索。与GA算法相比,PSO算法的性能更好,速度更快[16]。本文采用PSO算法对ELM初始参数进行优化。
PSO算法是一种基于速度和位置两种信息的搜索算法,利用个体之间的信息共享从而得到最优解,不需要设置大量参数且易于实现。PSO算法的参数或可能的解集包含在一个向量xi(k)中,该向量称为群粒子,表示其在可能解搜索空间中的位置。粒子维度是参数的数量。随机设定粒子的初始位置xi(0)及其速度vi(0)。然后计算每个粒子的适应度函数值,并根据这些值更新速度和位置。该算法更新粒子的位置和速度,表示为:
vi(k+1)=ω·vi(k)+c1·r1·(pibest-xi(k))+
c2·r2·(gbest-xi(k))
(7)
xi(k+1)=xi(k)+vi(k+1)
(8)
c1,c2为学习因子;r1,r2为[0, 1]范围内的随机数;pibest、gbest表示粒子k在个体及群体中的极值位置;ω为惯性权重,通过调整ω的值可以实现对全局搜索和局部搜索的能力,本文采用线性递减权值(linearly decreasing weight,LDW)策略,表示为:
ω=(ωini-ωend)(Gk-g)/Gk+ωend
(9)
其中:ωini为初始设定的惯性权重,Gk为最大迭代次数,g为当前迭代次数,ωend为迭代完成后的惯性权重,惯性权重的引入极大的提高了PSO性能。
在初始迭代中,粒子群中的每个粒子根据自身的记忆和经验在整个区域内分别寻找最优解,并将其作为当前个体极值。在此算法中是多个粒子同时移动的,每个粒子将自身搜寻到的个体最优解与其他粒子共享并进行对比,找到最适当的解,作为整个粒子群的当前全局最优解。每个粒子的当前位置xi(k)和速度vi(k)将根据其在上一步中的状态、粒子的局部最优解位置pibest和全局最优解位置gbest进行调整。并随着迭代的进行逐渐缩小其搜索范围。在初始阶段,该算法对合理区域进行探索性搜索,在最后的迭代中,改进了最佳解。
在ELM预测模型中,为了以尽可能少的隐含层节点的情况下达到尽可能高的预测精度,需要对输入权值ωi和阈值bi进行优化。在基于混合PSO-ELM的方法中,利用PSO算法实现了ELM方法中的优化机制以获得输入权值和阈值的最优参数,粒子维数D及粒子群中第i个粒子θi表示为:
D=t(n+1)
(10)
(11)

1.2 算法流程
基于PSO-ELM的红外目标模拟器校准数据拟合可详细描述如下。
1)读取实验所得不同波段内的温度及其对应辐射照度数据,将数据集随机划分为训练集和测试集,并对样本数据进行归一化预处理;
2)设置PSO相关参数:粒子群规模N、最大迭代次数Gk、学习因子c1和c2;并对粒子速度和位置进行初始化,设第i个粒子初始位置xi(0)及其速度vi(0);
3)将粒子位置和训练集代入式(12),计算适应度函数值,寻找局部最优解位置pibest和全局最优解位置gbest;
(12)
4)设终止条件为当前迭代次数g>Gk或全局最优解满足最小界限。若不满足终止条件,则更新PSO算法的粒子速度和位置,并重复步骤3),更新pibest、gbest;若满足终止条件,则可得到最优网络初始权值和阈值;
5)将最优网络初始权值和阈值带入ELM模型进行训练,计算隐含层输出矩阵H;
6)通过式(5)即利用广义逆矩阵H+计算隐含神经元到输出层的权值向量β;
7)更新权值和阈值;
8)判断是否满足终止条件,即判断当前隐藏节点数是否大于搜索限制的隐藏节点数,若不满足终止条件则继续训练ELM网络,即重复步骤5)~步骤7);若满足终止条件则得到最优ELM模型,并输出当前拟合结果。
基于PSO-ELM的红外目标模拟器校准数据拟合流程图,如图1所示。
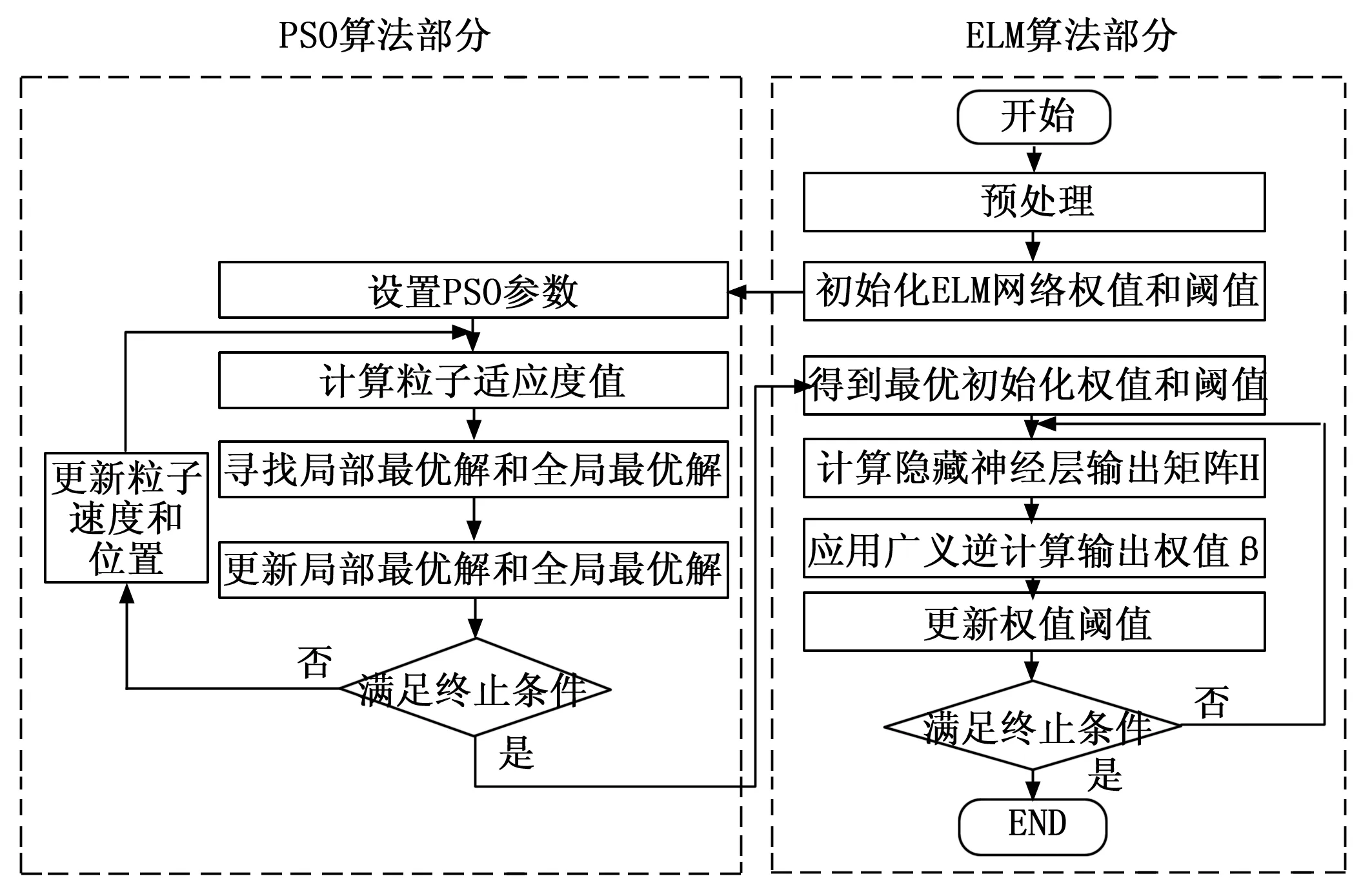
图1 PSO-ELM数据处理流程
通过对数据进行预处理,可以减少或消除可能的极值、非正态分布或数量级的剧烈变化。PSO方法根据适应度函数搜索输入权值和阈值的最优参数,采用均方根误差(RMSE)作为主要适应度因子。
2 仿真分析
2.1 实验步骤
本节将PSO-ELM模型应用于红外目标模拟器校准的数据拟合,样本数据集通过实验室搭建的红外目标模拟器校准装置进行实验获得。过对不同数据拟合方法的比较,验证了PSO-ELM方法在实际标定中的有效性。红外目标模拟器校准装置包括标准黑体辐射源、平行光管、精密转台平面镜、红外辐射计和计算机[17-18]。
实验步骤如下:
1)在实验室环境下,测试背景信号,并记录背景辐射的响应电压V0
2)设置标准黑体辐射源辐射温度为T,将其作为校准数据的自变量,并计算所对应的光谱辐射照度Eb(λ,T)和标准积分辐射照度Eλ,T,其中
(13)

(14)
3)测试目标的响应电压Vt
4)计算辐射照度响应度,将其作为校准数据的因变量
R(λ,T)=Eλ,T×(Vt-V0)
(15)
5)利用PSO-ELM方法得到校准数据的因变量和自变量之间的关系;
为验证校准数据具有非线性的特点,设置标准黑体辐射源温度范围为100~1 000 ℃,分别对1~3 μm、3~5 μm、8~14 μm波段进行测试。对测试数据进行拟合,结果如图2所示。

图2 辐照度随波长分布图
如图2所示,在1~3 μm、3~5 μm、8~14 μm三个波段下,温度和辐射照度之间都具有强非线性。红外辐射计的响应主要取决于探测器的探测能力[19],探测器的响应随着温度的升高而增长,并且根据维恩位移定律,黑体辐射的峰值波长随黑体温度的升高而向短波方向移动[20-21]。除此之外,探测器采用制冷型MCT探测器,随着黑体辐射源温度升高会使其性能下降[22]。由于上述数据呈现非线性特性以及实验数据样本小的限制,红外辐射计标定中常用的传统数据拟合方法不能达到足够的拟合精度。
2.2 评价指标
为了评价该模型回归精度,本文以决定系数R2、平均相对误差MRE作为预测结果的评价指标。评价公式如式(16)~(17)所示。
(16)
(17)

2.3 结果分析
为了验证本文所提的方法在红外目标模拟器校准上的可靠性,将PSO-ELM方法与其他传统的数据分析方法进行了仿真对比。本文分别采用PSO-ELM,GA-ELM,ELM算法进行仿真,仿真对比结果如图3~5所示。
为了验证PSO-ELM算法在拟合红外目标模拟器校准数据上的性能,将实验得到的96组样本数据通过随机函数进行预处理,使样本数据处于无序排列状态,并随机选取其中51组数据作为训练集,剩余45组数据作为测试集,分别使用单一ELM模型、GA-ELM模型和PSO-ELM模型对红外目标模拟器校准数据进行拟合。
PSO算法设置粒子群规模为20,最大迭代次数为100,最小速度为-1,最大速度为1,当波段为1~3 μm、3~5 μm时c1=c2=2,当波段为8~14 μm时学习因子c1=2.5、c2=2,学习因子通过正交实验多次测试确定最优参数。
GA算法参数设置个体数目为20,最大遗产代数为100,变量的二进制位数为10,代沟为0.95,交叉概率为0.7,变异概率为0.01。
采用3种算法进行对比实验,并比较这 3 种算法的拟合结果,验证不同拟合方法在处理红外目标模拟器校准数据时的性能。拟合结果如图3~5所示,拟合误差分布如图6~8所示,相关的评价指标计算结果如表1所示。

图3 1~3 μm数据拟合结果

图4 3~5 μm数据拟合结果
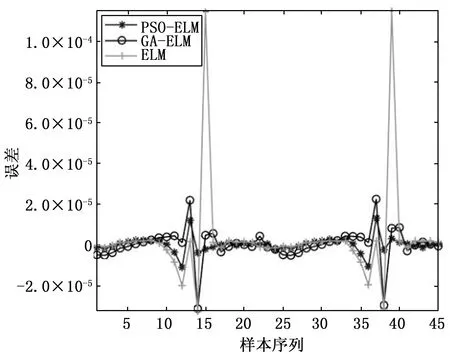
图5 8~14 μm 数据拟合结果
如图3~5所示,在3个波段内ELM模型拟合误差明显大于另外两种模型,主要偏差出现在辐照度峰值部分,即标准黑体辐射源温度较高、系统接收入射辐射较高时。GA-ELM相较于ELM拟合精度有所提高,对于辐照度峰值部分的拟合也更优于ELM,但是在辐照度较低时在真实值上下波动较为明显,当标准黑体辐射源温度较低、系统接收入射辐射较低时稳定性更差。
可以明显看出,GA-ELM算法和PSO-ELM算法可以获得比ELM算法更好的拟合结果,对ELM初始权值和阈值进行优化可以有效提高拟合精度和稳定性。但GA-ELM方法出现振荡现象,尤其是当校准点数量较少且拟合数据非均匀分布时。为了提高拟合精度,将基于PSO-ELM的方法应用于红外目标模拟器的校准中。
将PSO-ELM方法与GA-ELM方法、ELM方法的拟合误差进行比较,验证了PSO-ELM方法的性能。
如图6~8所示,在3个波段下,ELM模型的拟合误差均存在峰值。出现峰值的原因有二:1)校准数据本身具有较强的非线性,且背景辐射会影响辐照度值,这对拟合模型的稳定性和准确性造成了一定影响;2)ELM算法中的随机参数对模型的拟合稳定性有较大的影响。然而, ELM模型本身并不能求解随机参数。基于以上两个原因,ELM算法在红外目标模拟器校准数据拟合的过程中可能存在较大的误差。为了减少拟合结果中的峰值,需要选择最优的模型参数。PSO-ELM模型和GA-ELM模型的拟合性能均优于ELM模型,也可以证明参数优化提高了ELM模型的预测精度和稳定性。

图6 1~3 μm数据拟合误差

图7 3~5 μm数据拟合误差
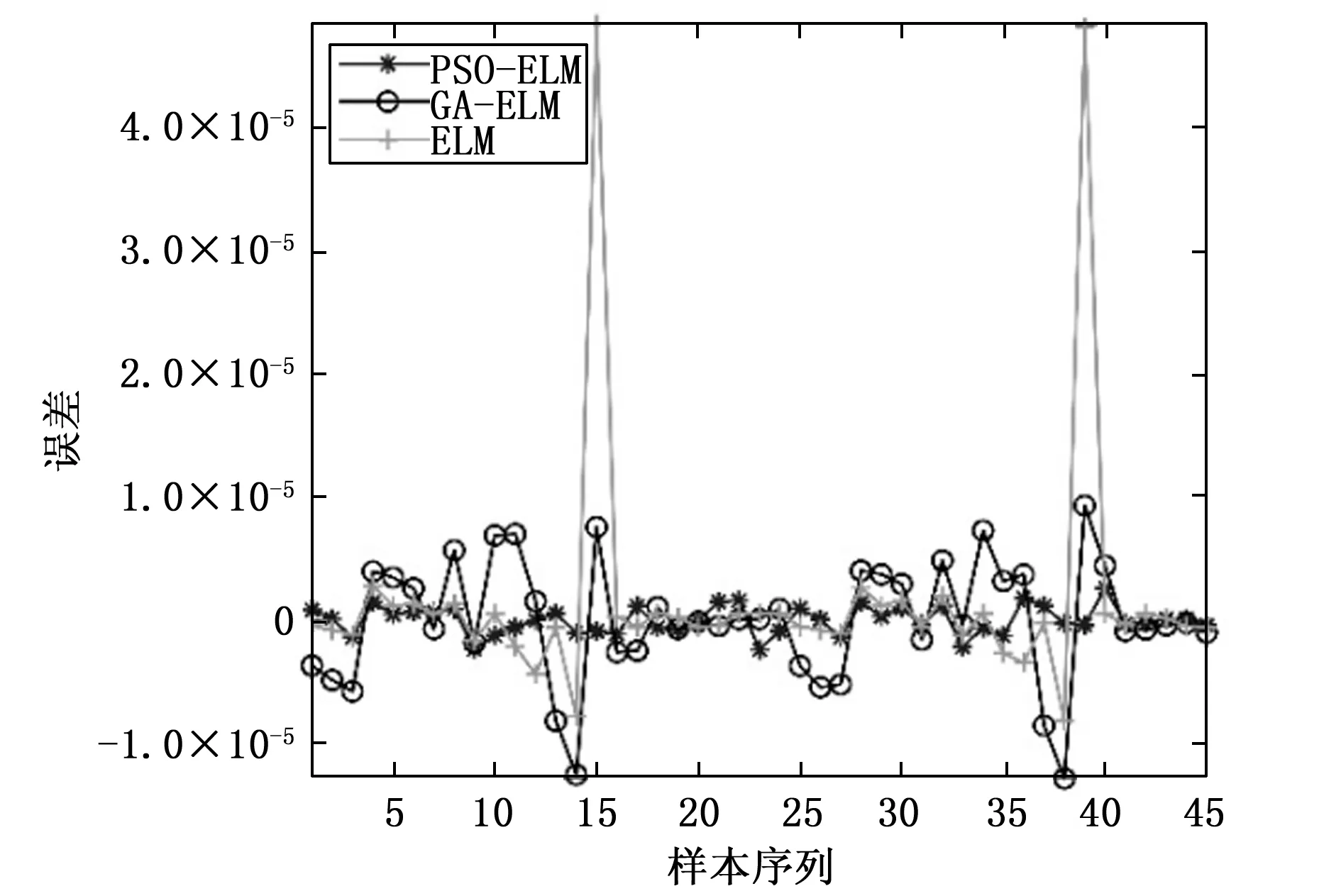
图8 8~14 μm 数据拟合误差
3种算法模型的拟合性能在辐照度较低的部分更好,随着标准黑体辐射源温度升高,拟合误差也逐步增大,可能造成这种现象的原因是校准数据的后半部分校准点的数量限制。当使用较少的校准点时,拟合误差将增加。PSO-ELM方法的优越性能在辐照度较高时相对于另外两种算法更为明显,但也受到拟合数据数量的限制。
如表1所示,ELM在3个波段的拟合精度都较低,由于随机产生初始参数,容易出现欠拟合现象;GA-ELM在中短波红外表现较好,但在长波红外范围内性能下降较为明显,且模型较为复杂,在样本数较少时会发生过拟合现象;PSO-ELM算法鲁棒性好,在3个波段都可以较为准确地拟合红外目标模拟器校准数据,在1~3 μm、3~5 μm、8~14 μm三个波段,决定系数分别为0.992 5、0.991 3、0.981 4,平均相对误差分别为0.124 2%、0.715 7%、0.747 4%。

表1 评价指标计算结果
通过以上对比,证明了优化初始参数的ELM算法在处理非线性数据上的有效性,由于GA-ELM和PSO-ELM都对ELM初始权值和阈值进行优化,但PSO算法优化的性能明显优于GA算法,可能导致这种现象的原因是两种算法原理的差异,发现基于 PSO-ELM 的算法的数据拟合准确率高于另外两种算法。
3 结束语
针对红外目标模拟器校准数据呈现非线性的特点,本文提出了一种PSO优化的ELM算法:
1)利用PSO算法搜索ELM模型的随机参数,解决了ELM模型随机参数影响拟合精度的问题,利用PSO算法可得到最优权值和阈值,进而得到最优拟合精度;
2)将PSO-ELM模型应用于红外目标模拟器校准数据,拟合出输入参数(标准黑体辐射源的辐射温度)与输出参数(辐射照度)之间的非线性关系,进行仿真实验;
3)选取决定系数(R2)和平均相对误差(MRE)作为精度评判标准,对PSO-ELM模型性能进行了验证;
4)通过与ELM算法和GA-ELM算法进行对比,证明PSO-ELM性能优越性。
实验结果显示模型的决定系数及平均相对误差均优于对比的其他建模方法,PSO-ELM模型在延续 ELM 泛化能力强和学习速率高的基础上,通过 PSO 克服了 ELM 输入权值矩阵与阈值对于预测结果的影响,具有操作简便、预测精准及适用性广泛的优点。结果表明PSO-ELM方法在红外目标模拟器校准非线性数据处理方面具有很好的效果。
猜你喜欢
现代电子技术(2022年11期)2022-06-14
汽车实用技术(2022年5期)2022-04-02
建材发展导向(2021年19期)2021-12-06
现代计算机(2021年10期)2021-05-28
故事作文·高年级(2021年4期)2021-05-06
现代计算机(2021年3期)2021-03-24
创新时代(2017年10期)2017-11-09
科技视界(2016年1期)2016-03-30
物联网技术(2015年7期)2015-07-21
