
机场不正常事件实体检测与识别方法研究
2022-08-03 02:42侯启真袁天一王罗平
计算机测量与控制 2022年7期
侯启真,袁天一,王罗平
(中国民航大学 电子信息与自动化学院,天津 300300)
0 引言
民航安全是民航业长久的主题[1],在美国的航空安全自愿报告系统(ASRS,aviation safety reporting system)获得成功后,全世界众多国家纷纷开始建立适合自身实际的航空安全自愿报告系统,我国创建了中国民用航空安全自愿报告系统[2]。该系统所收集的报告中含有报告人所见所闻的民航安全隐患故障,需要总结归纳引发故障的原因和控制故障发生的措施来防止重大事故的发生,从而保障民航系统安全运行。随着时间积累,报告数量不断增长,每份报告的非结构文本所含要素信息得不到充分分析,传统的事件分析方法面对大量的文本很耗费人力也很依赖分析人员的专业能力。
为了充分利用这些事件报告,需要检测并提取出文本中的事件本质要素,这些要素存在于非结构化的文本中,且这些要素正是影响着民航运行安全的风险要素,主要是人、机、环境的一些状态信息。而命名实体识别正是能够做到检测和识别此类文本要素的关键技术,命名实体识别是一项序列标记任务,中文命名实体识别就是将每个文字或符号检测为其对应的实体类别。随着深度学习的兴起,循环神经网络(RNN,recurrent neural network)较适用于处理命名实体识别这样的序列标注任务[3]。但是面对长文本序列,RNN的梯度消失与梯度爆炸的缺陷严重影响其序列标注效果。长短时记忆网(LSTM,long short-term memory)是一个特殊的循环神经网络,网络利用输入门、遗忘门和输出门来管理序列化数据[4-5],在命名实体识别任务上取得了较为优异的效果。在此基础上有人提出双向长短时记忆网络(BiLSTM,Bi-directional long short-term memory)来提高模型效果,同时结合在命名实体识别任务上表现较好的机器学习模型——条件随机场(CRF,condition random fields),可以使得该任务在通用领域数据集上达到更好的识别效果。近几年也有人在此模型的基础上引入自注意力机制,在一定程度上提升了模型识别能力。
机场不正常事件是航空安全自愿报告中描述事件与机场相关的文本报告,经过人工筛选,并进行预处理得到命名实体识别模型需求的非结构化文本形式。机场不正常事件命名实体识别技术的任务是从非结构化的机场不正常事件文本中将该领域文本特定的不同类别实体检测识别出来,以达到对机场不正常事件关键要素提取和分类的目的,得到结构化文本作为开展机场不正常事件分析总结控制措施的基础工作。然而由于机场不正常事件文本在表述方式、事件状况、专业用语等文本特点上与通用领域不同,且通用领域主要以人名、地名、机构名等简单实体为命名实体识别目标,所以通用领域常用的命名实体识别模型在本领域很难达到较好效果。
因此,针对以上问题,提出了更适合于机场不正常事件文本数据的命名实体识别模型BiLSTM_MSA_CRF(Bi-directional Long Short-Term Memory_Multi-Scale Self-Attention_ Condition Random Fields)模型。此外,为降低人工标注成本,根据模型自身特点,设计了样本选择策略,在降低人工标注数据量的同时更高效地提高了模型泛化能力。
1 机场不正常事件报告的构造特征
机场不正常事件报告文本从整个文本角度,文本长度偏长,每份报告300~700字。上下文具有很强的相关性,长距离相关性将影响着命名实体识别效果。由于上下文的相关性也帮助丰富文本中关键要素的语义信息,使其明显区别于通用领域文本的结构,如“…27号跑道发生跑道入侵事件,并未造成…”中“入侵”与“跑道”共同组合成一个词语“跑道入侵”有别于通用领域的常规用法,结合前文“27号跑道”这一地点词可以确定此处词语语义。
从单个实体角度,文中含有一定量的专业性用语,中英文缩写及其中英文全称,以及中文、字母、数字多种字符串组合在文本中交替出现,这些字符串可能表达航路、航班、扇区等信息(例如A326、SCS8997、ZSSSAR11),实体长度不等,实体间相互影响密切且交错。所需检测的实体种类也较多,多个实体种类之间比较相似,比如人的行为状态和其他生物的行为状态会有类似,需要结合语境进行区分。
2 数据标注规则
根据国际民航组织(ICAO)9859号文件[6],并结合机场不正常事件文本内容特点,充分考虑我国民航安全报告系统对故障防控的需求,设立了14个命名实体类别:时间、地点、方位、天气元素/能见度、航空器、航空器状态、航空器部件、航空器部件状态、设施、设施状态、人物类别、人类行为/状态、其他生物(不包括人类)、其他生物的状态。每个实体对应特定的编号,编号表如表1所示。
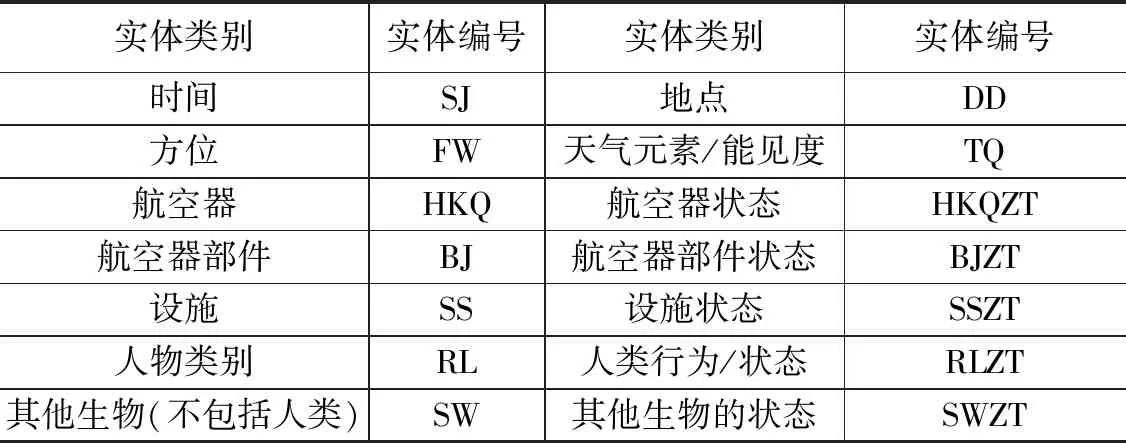
表1 命名实体类别编号
本文采用命名实体识别常用的BIO标注原则[7-8]对文本数据进行序列标注,即实体的开始标为B,实体的非开头部分标为I,非实体标为O。由于每段文本较长,为方便人工标注,采用{"text":"S","label":{e1:[Ne1],…,ek:[Nek],…,e|E|:[Ne|E|]}}标注方式,这种标注方式相对传统的BIO人工标注更简单便捷。其中,S代表文本序列,ek∈E是命名实体类别,Nek代表在S这一文本序列中属于ek这一实体类别的实体集合,人工标注完成的样本如图1所示。

图1 人工标注样本示例
数据处理程序中,将进行相应转换处理,程序经过如图2所示对人工标注数据进行相应处理,从而得到对应的BIO标注形式。

图2 BIO标注处理程序
3 命名实体识别方法和过程
依据各个领域现有命名实体识别模型[9-10],并分析机场不正常事件报告的构造特征,提出的适用于检测机场不正常事件要素信息的命名实体识别任务,主要分为4个部分:文本向量化,双向长短时记忆网络和多尺度注意力机制(MSA,multi-scale self-attention)提取上下文特征信息以获取文本中每个字的实体类别预测分数,条件随机场将获取的最优预测序列解码输出最终识别结果,总体模型框架如图3所示。
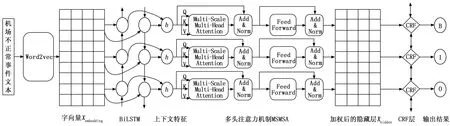
图3 机场不正常事件命名实体识别的BiLSTM-MSA-CRF模型构架
3.1 字向量化
需要将输入的句子中每个字表示成字向量,字向量的表示方式主要分为两种:独热表示和稠密表示。由于独热表示无法表示字与字之间的相关关系,逐渐被新生的稠密表示方式取代,Word2vec[11]正是目前较经典的字向量稠密表示方法。Word2vec可以表示字与字之间的相关关系,从而含有一定的语法和语义特征表示 ,进而从输入端提升命名实体识别模型的泛化能力。已知文本序列S={s1,s2,…,sm}有m个字,经过Word2vec处理后得到每个字si相对应的字向量表示形式xi,如式(1)所示:
xi=Ww2vvi
(1)
其中:Ww2v∈Rdx×|V|是由Word2vec训练得到的向量矩阵,dx是字向量的维度,|V|是输入字表的大小,vi是输入字si的词袋表示(独热形式)。由此得到一个向量序列x={x1,x2,…,xm},作为命名实体识别网络的字向量输入。
3.2 提取上下文信息
单向LSTM可随着序列信息的提取保留前文“值得记忆”的特征信息,而模型最后检测出的序列标签是结合前文的信息预测得出的,也就做到了结合上文的语境信息来做命名实体识别任务。为解决RNN在长文本序列标注任务上的缺陷,每个LSTM均包含着输入门、遗忘门和输出门这3个“门”单元结构,以降低梯度消失等问题的出现率。LSTM单元结构如图4所示。
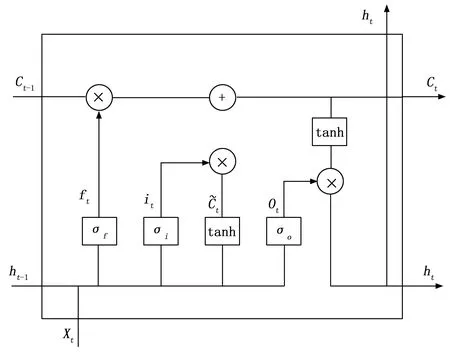
图4 LSTM单元结构
式(2)描述了LSTM具体计算过程。
it=σ[Wi·(ht-1,xt)+bi]
ft=σ[Wf·(ht-1,xt)+bf]
ot=σ[Wo·(ht-1,xt)+bo]
ht=ot⊙tanh[ct]
(2)
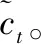
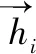
(3)
字向量经过BiLSTM提取一定的上下文特征,但并不足以准确检测每个字的对应标签。
3.3 结合层次结构的自注意力机制
尽管双向长短时记忆网络在一定程度上已经保留了上下文“重要”信息,已经可以做到较全面的处理,但是其依然没有对这些“重要”信息分清主次,即从BiLSTM中得到每个字向量对应的上下文特征向量,但并没有考虑到不同词语间的不同程度关系,也没有充分考虑到不同的词语对模型识别结果会产生不同程度的影响,所以识别效果更待提升,需要使用自注意力机制来帮助分配权重以解决此问题。所以结合了自注意力机制的命名实体识别模型更能够提取更加主要且与现有输出关联度更高的特征信息,避免过多提取次要关联信息而造成语义偏差,在对输入向量施加合适的权重系数后,模型识别结果会得到有效提升。
近年来,诸多领域为解决命名实体识别的这一问题引入了自注意力机制[14-16],尽管自注意力可以建模非常长的依赖关系,但深层的注意力往往过度集中在单个字上,且权重过于分散,并不能构成词语间的依赖关系,导致对局部信息的使用不足,对短序列自注意力相对有效,但其难以表示长序列,随着句子的长度增加自注意力的性能逐渐下降,从而导致信息表达不足,给模型完整地理解数据信息带来困难,在语境中应更主要以词与词之间的影响来作为特征,这样才更能提高模型识别效率。且基于自注意力机制的方法缺乏先验假设,需要很大的样本数据集才能训练出一个泛化能力较好的模型。本研究数据量有限,无法满足大样本数据集的要求。多尺度结构可以帮助模型捕捉不同尺度的特征,实现多尺度的常用方法是采用层次结构,通过层次结构,模型可以捕获较低层次的局部特征和较高层次的全局特征。多尺度多头注意力[17]的各个头具有可变尺度,头部的大小限制了自注意力的工作范围:大尺度包含更多上下文信息,小尺度更关注局部信息。
BiLSTM输出向量为hi,对应的序列矩阵为H={h1,h2,…,hn},其中H∈Rn×D,n为句子长度,D是hi的向量维度,式(4)描述了多尺度注意力的计算过程。
Cij(A,ωj)={Ai-ωj-1/2,j,…,Ai+ωj-1/2,j}
Q=H·WQ,K=H·WK,V=H·WV
headj(H,ωj)=Concat[headj(H,ωj)1,…,headj(H,ωj)n]
MSMSA(H,Ω)=Concat[head1(H,ω1),…,
headj(H,ωj),…,headN′(H,ωN′)]WO
(4)
其中:WQ,WK,WV,WO是可学习的参数矩阵,ω是每个头的尺度大小,ωj即为第j个头的尺度,共有N’个头,多尺度多头自注意力的所有头的尺度集合为Ω=[ω1,…,ωj,…,ωN′],C为给定位置提取上下文特征的函数。
多头多尺度注意力机制,在不同层分配了不同尺度的“头”,不同层中对应的尺度分配遵循式(5):
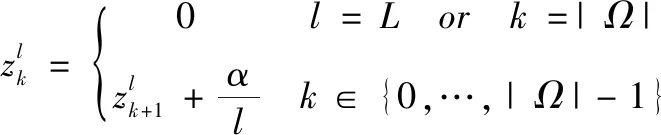
(5)
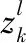
以上公式计算过程对于单个向量hi可以归结为式(6):
(6)
对应注意力计算结构图如图5所示。
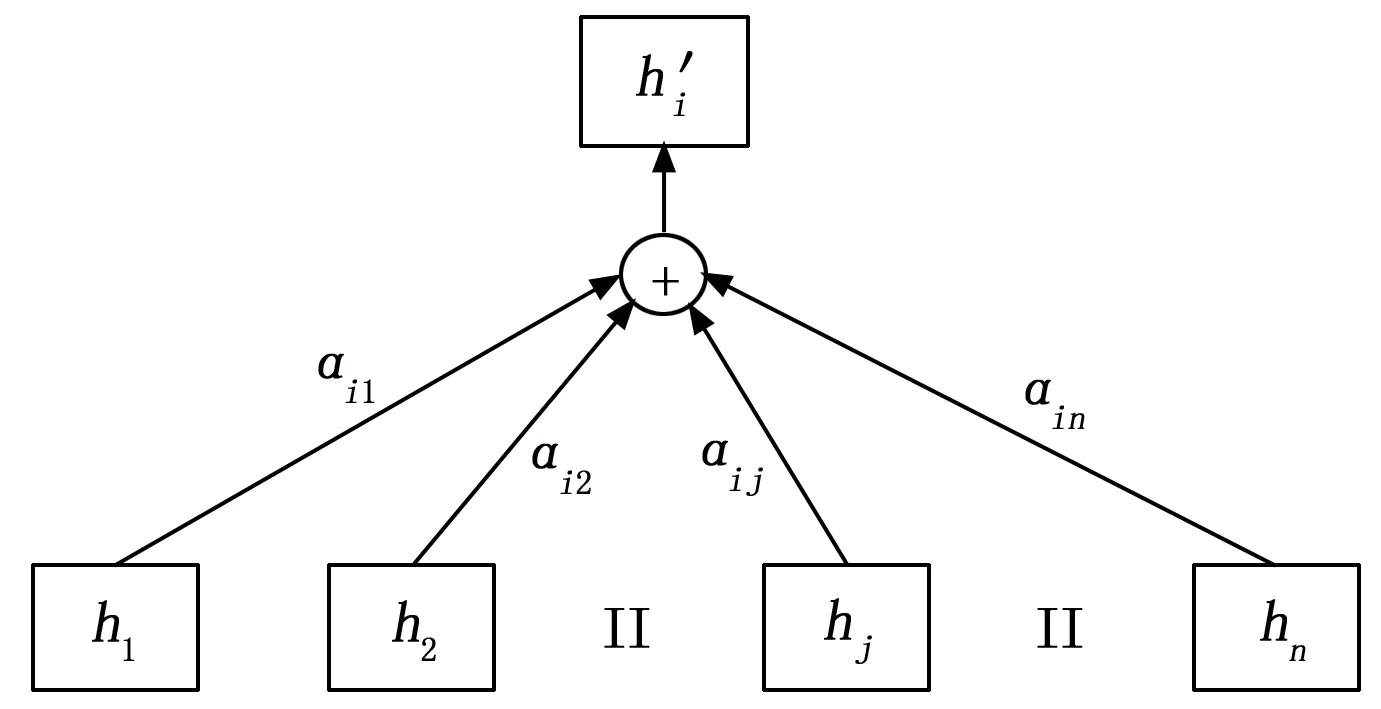
图5 注意力加权计算过程
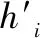
3.4 解码输出检测结果
CRF[18]解码过程中,将重新分配权重后的双向LSTM概率矩阵输出结果作为输入,获得预测序列标签。CRF模型关注输入序列各个相邻字的前后依赖关系,进而计算最优预测标签序列。借鉴王栋[19]等人使用CRF模型的思路,相关公式计算过程如下:
记句子序列为S={s1,s2,…,sm},其预测的标签序列为Y={y1,y2,…,ym},则序列预测得分矩阵计算如式(7):
(7)
其中:T代表状态转移矩阵,Tyi-1,yi为yi-1标签转移到yi标签的概率得分,Pi,yi是第i个字符被标记为标签yi的概率得分。文本序列S计算产生标记序列Y的概率如式(8)所示:
(8)
在训练过程的标记序列的似然函数如式(9)所示,通过极大似然估计的方法估计条件随机场的模型参数。
(9)
使用CRF对序列进行预测时利用维特比(Viterbi)算法求解最可能的序列标签,最终输出如式(10)所示的最优序列Y*。
(10)
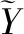
3.5 样本选择策略
由于模型所需标注训练样本数量较大,人工标注成本较高,且已有训练数据中各个类别的实体数量不均衡,以至出现比较稀疏的实体类别,从而导致模型对这些稀疏实体识别不准确,为检测出含有此类实体的高质量训练样本和提高人工标注效率,本文根据数据和模型本身特点,设计了基于不确定性的样本选择策略。该方法既能减低人工标注成本又能更高效地提高模型的泛化能力,基于不确定性的样本选择策略的核心思想是模型无法进行有效判断的样本[20-22]。结合现有命名实体识别模型,本文使用最优预测序列概率p(Y*|S)作为模型对未标注样本的不确定性评判依据,最优预测序列概率p(Y*|S)越低,模型对样本序列的标注越不确定,这类样本与已有训练数据相比含有稀疏实体较多,这类样本越值得加入训练集。基于不确定性的样本选择策略如式(11)。
D(Y*)={Y*|p(Y*|S)≤PD}
(11)
其中:D(Y*)是通过选择后得到的需人工标注的样本集,PD为模型最优预测序列概率阈值,当样本S对应的最优预测序列Y*的概率未达到阈值时,则将该样本加入需人工标注样本集,等待人工进行标注。使用该样本选择策略后,构成了与模型训练模块构成了闭环主动学习框架,如图6所示。
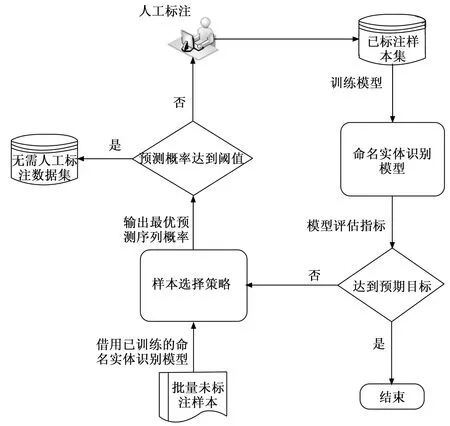
图6 融合样本选择策略的命名实体识别框架
4 实验结果与分析
4.1 实验数据准备
使用的数据来自于ASRS和中国民用航空安全自愿报告系统中与机场相关的航空安全自愿报告,选取的报告包含了2010~2021年间机场航空安全自愿报告10 536条,所有文本去除无效字符并整理格式后组成本实验机场不正常事件样本数据,数据以中文形式呈现,每篇报告500字左右。随机选取了7 000条样本进行人工标注,标注形式如图1所示,并随机将其分为5 000条文本的训练集和2 000条文本的测试集。剩余的未标注样本作为样本选择策略的实验数据。
4.2 实验环境、参数设置和评价指标
实验在Windows10(64位)系统中使用Python3.6作为编程语言,基于Pytorch框架对本文方法和对比实验方法进行程序实现。所有实验是在Intel Core i7-8700处理器、16 G内存、NVIDIA Quadro P2000 GPU硬件设备条件下进行的。表2是实验中模型参数设置情况。
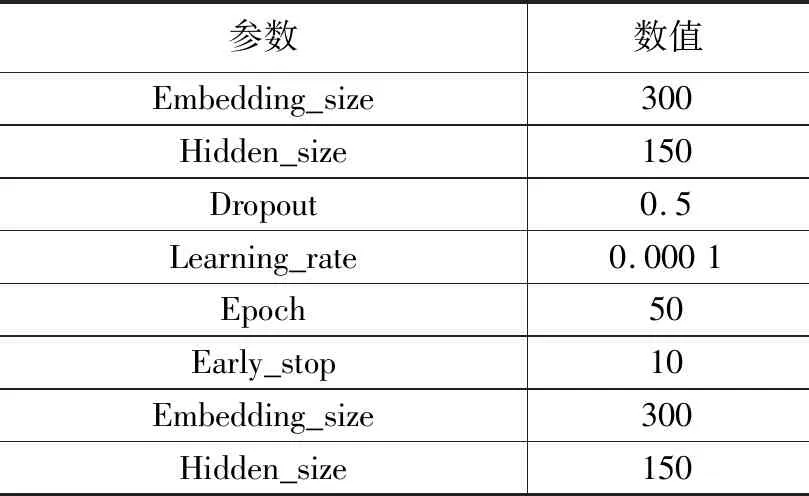
表2 模型参数设置
实验采用精确率P、召回率R和F1值对命名实体识别结果进行评价。3个评价指标的计算如下:
(12)
以下实验均通过计算不同模型在相同数据上的精确率P、召回率R和F1值进行对比。
4.3 实验结果对比与分析
实验一:加入多尺度注意力机制的命名实体识别模型在机场不正常事件文本数据上的识别效果需要对比通用领域的常用方法来验证,以证明多尺度注意力机制能够改善机场不正常事件文本命名实体识别效果。实验使用3.1节所提及的训练集和样本集分别训练BiLSTM_CRF模型、BiLSTM_self-attention_CRF模型以及本文提出的BiLSTM_MSA_CRF模型,为降低选取数据的偶然性,经过5次随机分配得到的训练数据和测试数据来分别训练3个模型,最终将模型得出的评价指标取平均值,并填写入表3中。
从表3可以看出,加入自注意力机制后,模型识别能力确有提升,但并不明显,这正是因为自注意力机制对于文段较长且识别结果很依赖上下文语境的文本并没有很好地发挥其捕捉上下文重要信息的作用,注意力过于分散在单个字上,没有充分利用词语级别的局部信息。而加入多尺度注意力机制后,识别效果有了明显提升,说明多尺度注意力能够改善自注意力的缺点,更适合机场不正常事件这种长文段的命名实体识别。
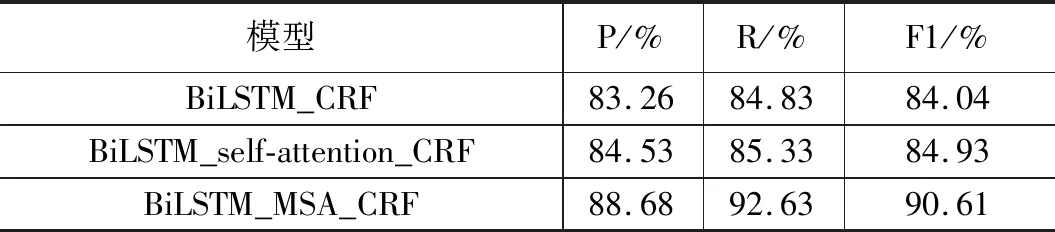
表3 固定样本集条件下不同模型的对比实验结果
为了降低人工标注成本且更高效地提升模型泛化能力,使用2.6节提出的样本选择策略进行对比实验。如图7所示,是阈值设为0.9时,提示需要标注的样本示例。

图7 样本选择策略下程序提示需要标注的样本示例
实验二:分别对比不同概率阈值PD对3种命名实体识别模型的影响,以寻找一个更合适的阈值。
实验步骤为:将前一次实验训练后的3种模型保存分别命名为BiLSTM_CRF、BiLSTM_self-attention_CRF和BiLSTM_MSA_CRF,选取4种不同最优预测序列概率阈值PD(分别为0.8、0.85、0.9、0.95),并分为4个批次逐渐增加选取样本,每个批次随机选取500条未标注样本,3种模型经样本选择策略后,挑选未达阈值的样本进行人工标注,加入训练集进行模型再训练,将不同阈值各个批次训练完成的模型区分开命名BiLSTM_CRFm(n),其中m=[0.8,0.85,0.9,0.95]为阈值,n=[1,2,3,4]为挑选样本批次,如BiLSTM_CRF0.8(1)代表设定阈值为0.8随机选取500条未标注样本,筛选出需要人工标注的样本加入训练集中对BiLSTM_CRF再训练而得到的模型;BiLSTM_MSA_CRF0.9(3)代表设定阈值为0.9在未标注样本集里随机选取500条未标注样本筛选出需要人工标注的样本累加到训练集中对BiLSTM_MSA_CRF再训练而得到的模型。对不同的样本需要标注的内容有一定的差异性,为防止因这种“参差不齐”的现象而引起的偏差,在所有未标注样本中随机进行5次抽选2 000条文本,各进行5次实验取平均值作为最终实验结果。实验结果如图8~13所示,每组的横坐标为使用样本选择策略选取备选样本的批次,即500(2)意为第二批次随机拿出500条未标注样本进行样本选择,图8,10,12纵坐标为每个批次筛选出需要人工标注的样本数量,图9,11,13纵坐标为对应批次训练后模型的F1值。
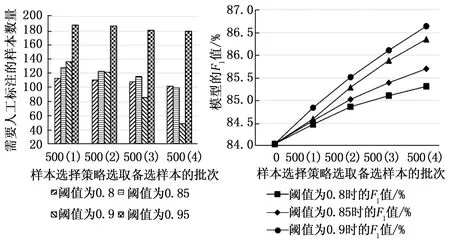
图8 不同阈值条件下BiLSTM_CRF模型需人工标注样本量对比 图9 不同阈值条件下BiLSTM_CRF模型随人工标记轮次F1值变化情况
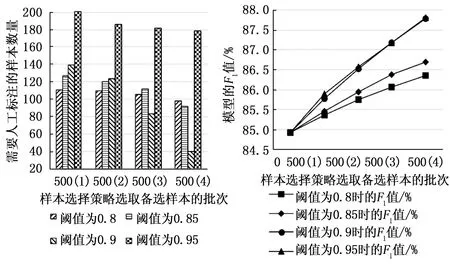
图10 不同阈值条件下BiLSTM_self-attention_CRF模型需人工标注样本量对比 图11 不同阈值条件下BiLSTM_self-attention_CRF模型随人工标记轮次F1值变化情况
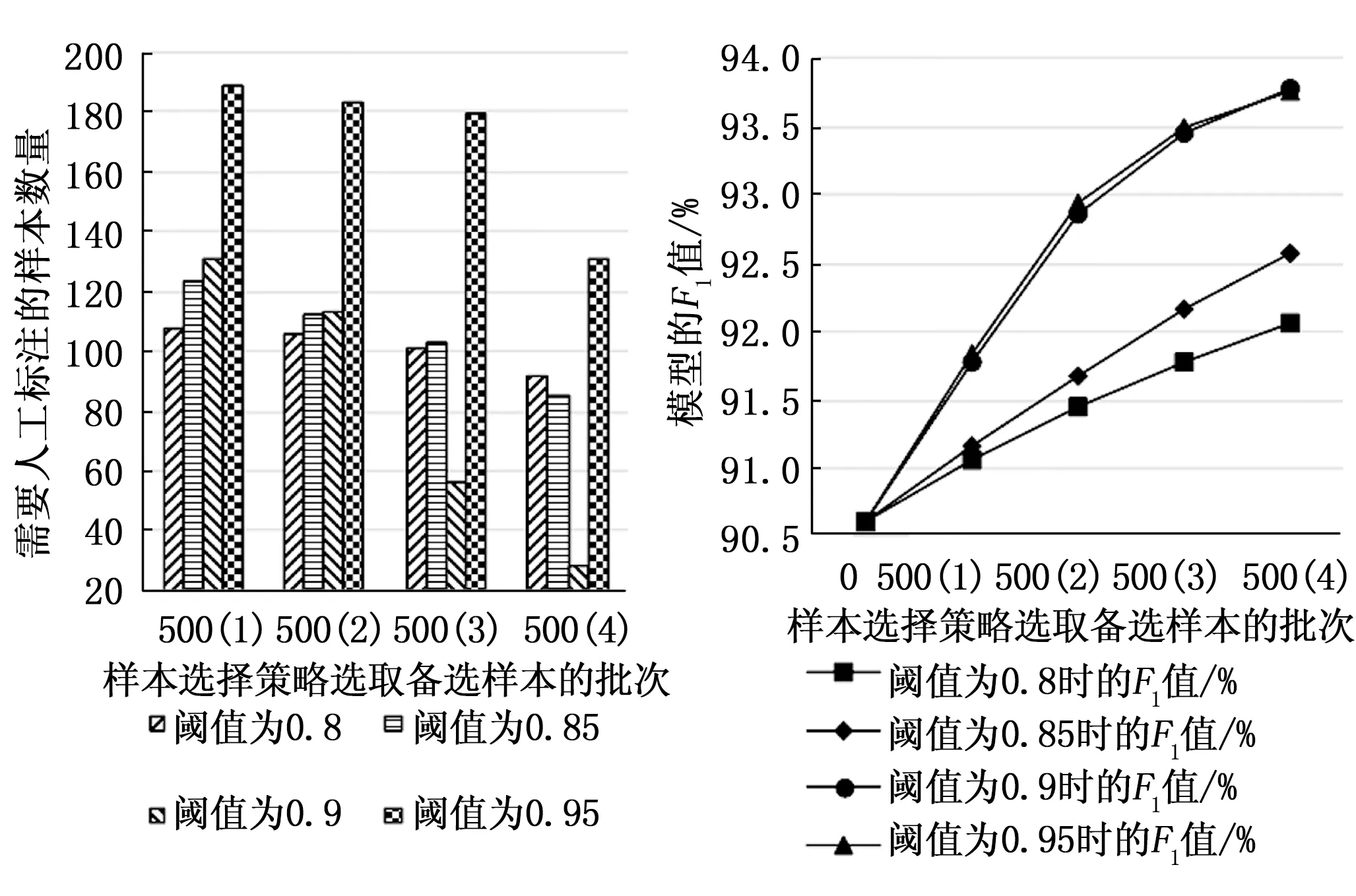
图12 不同阈值条件下BiLSTM_MSA_CRF模型需人工标注样本量对比 图13 不同阈值条件下BiLSTM_MSA_CRF模型随人工标记轮次F1值变化情况
由图8~13以及表4可以看出,随着样本选择策略的使用,3个模型的精确率P、召回率R和F1值均有提升,并且随着阈值的提升(由0.8到0.85再到0.9)模型的精确率P、召回率R和F1值在以更高的增长速率提升,并且增长趋势有提前趋于平稳的趋势,这是因为各个模型对大部分能够准确识别的未标注样本的预测分数主要集中在0.9以上,预测分数在0.9之下的样本正是模型不确定性较高的样本,需要加入训练集来提升模型的泛化能力。此外,随着阈值的提升(由0.8到0.85再到0.9)模型所需标注样本量也跟随着筛选批次逐渐减少,阈值为0.9时现象尤为明显。阈值为0.9和0.95时3个模型的评价指标上升趋势均几乎重合,模型所需标注样本量却有明显差异,模型预测分数能达到0.95的样本近乎少数,所以阈值设为0.95时3个模型需人工标记的样本量明显多于阈值设为0.9的情况,不过在阈值为0.95时,BiLSTM_MSA_CRF模型随着样本选择策略批次所需人工标记的样本量下降速度更明显些,也从一定程度上说明该模型预测分数高于0.95的样本数量要比另两种模型多。所以4个阈值相比,阈值0.9更适合作为本文的文本数据和本文所使用的命名实体识别模型。
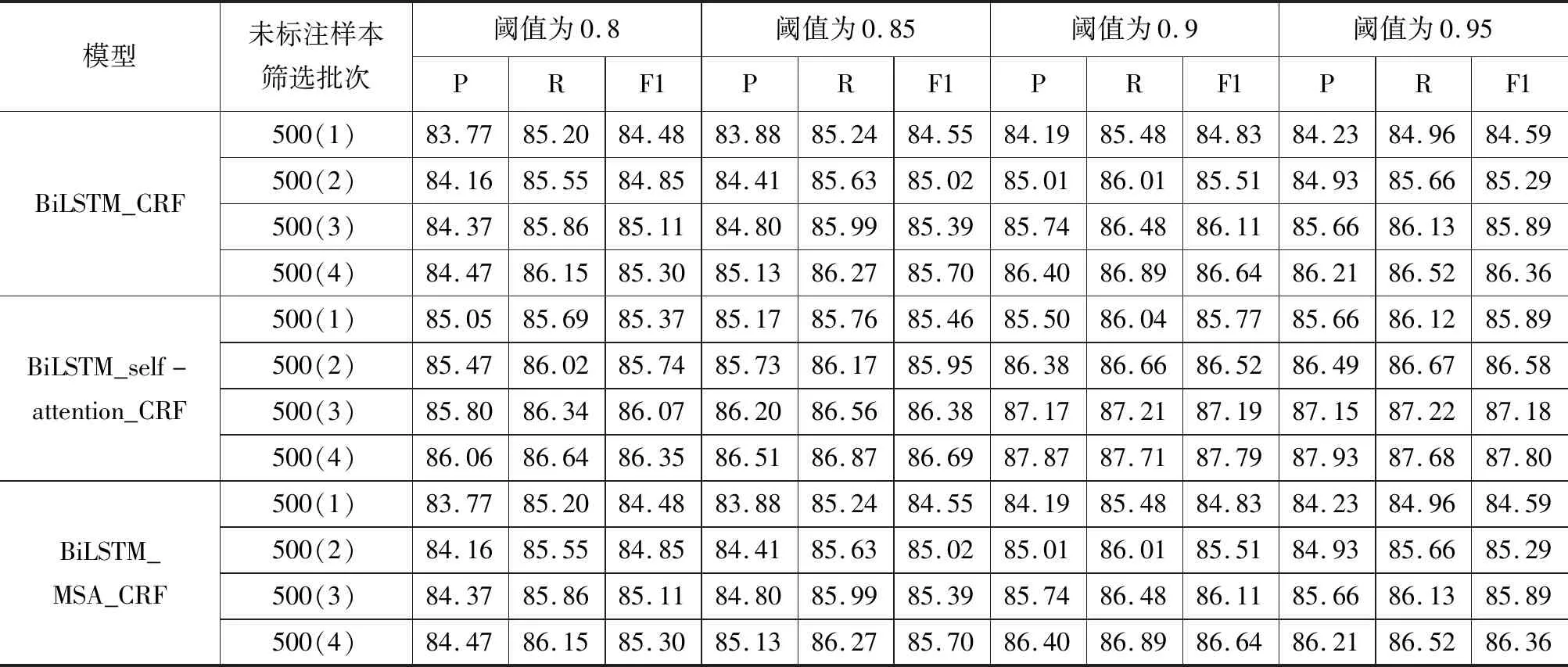
表4 不同阈值条件下3种模型评价指标变化对比
实验三:为了更加凸显样本选择策略的作用,在不使用样本选择策略的情况下,在上一个实验的同一批500条样本中随机选出与该批样本选择策略选出的样本数目相同的未标注样本加入训练集训练相应模型,实验结果如图14所示。
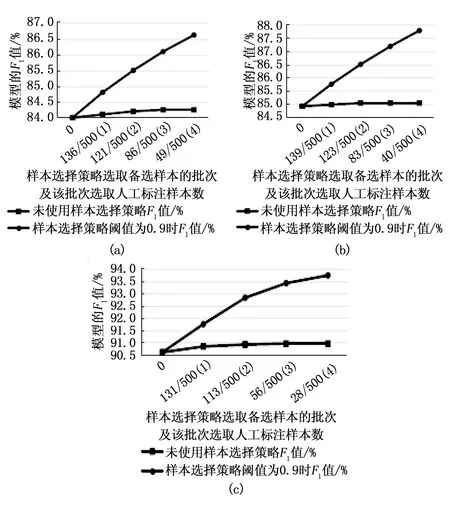
图14 BiLSTM_CRF、BiLSTM_self-attention_CRF、BiLSTM_MSA_CRF使用和未使用样本选择策略实验结果对比
从图14可以看出,在未使用样本选择策略的情况下,人工标注与阈值为0.9的样本选择策略相同数量的样本,模型识别能力的提升效果很不明显,与使用了样本选择策略差异很大,所以样本选择策略明显帮助我们在一批样本中检测出更能提升模型泛化能力的“有用”样本,人工标注后加入训练集,帮助模型“查漏补缺”。
5 结束语
经过上述3个实验的对比,在机场不正常事件数据上,本文提出的BiLSTM_MSA_CRF模型达到更好的识别效果,明显比BiLSTM_CRF、BiLSTM_self-attention_CRF提升了6个百分点的F1值。样本选择策略降低了人工标注成本,且帮助模型挑选了含有稀疏实体的样本来供给人工标注后加入训练数据,实验得出的F1表明该方法明显提升了模型识别效果。实验证明本文提出的方法是解决海量机场不正常事件的关键要素检测和识别的有效方法,可作为进一步分析大量机场不正常事件文本的基础工作,协助民航相关人员及时总结事故规律和关系、制定控制事故的措施。
猜你喜欢
军事文摘(2022年18期)2022-10-14
今日农业(2022年13期)2022-09-15
现代电子技术(2022年11期)2022-06-14
建材发展导向(2021年19期)2021-12-06
金桥(2021年5期)2021-07-28
现代计算机(2021年10期)2021-05-28
现代计算机(2021年3期)2021-03-24
哈哈画报(2021年11期)2021-02-28
华人时刊(2020年21期)2021-01-14
东方女性(2018年3期)2018-04-16
