
基于张量与姿态回归网络的多视角多人姿态估计
2022-08-01 04:03黄靖敏李万益林浩翔杨康明冯风炎郭泽佳
现代计算机 2022年11期
黄靖敏,李万益,林浩翔,杨康明,冯风炎,郭泽佳
(广东第二师范学院计算机学院,广州 510303)
0 引言
从多个视角估计三维人体运动形态是计算机视觉领域研究的热点问题,其目的是预测二维有限视角相应的三维姿态模型(骨架模型)。该三维姿态模型数据具有多方面的应用,例如,智能运动姿态三维重构或识别,基于姿态识别的无人驾驶控制等。
文献[8,9]提及,可以通过一些卷积神经网络(CNN)实现三维姿态估计,但其估计效果仍有所欠缺,一些遮挡、歧义、准确度等问题依然存在。三维姿态估计一般都通过估计相应视角的二维姿态,再通过二维姿态估计三维姿态,但这样的过程仍然需要性能更好的方法来实现。此外,如果二维姿态检测不准确,在真实的多视角视频中建立多个交叉视角的三维姿态模型是极其困难的,其姿态有映射歧义,使得难以识别判定。
针对以上问题,本文提出一种基于多视角二维图像信息收集且适用三维空间数据处理的姿态估计法,即张量与姿态回归网络估计法。两个网络都基于卷积神经网络(CNN)的架构,所提出方法的框架图如图1 所示。从图1 可知,本文所提出的方法含有3个模块,即各视角二维姿态的热图序列,热图序列的特征张量,神经网优化后的特征张量。通过3 个模块的计算后,可得出相应的含有相对空间位置的三维多人姿态。
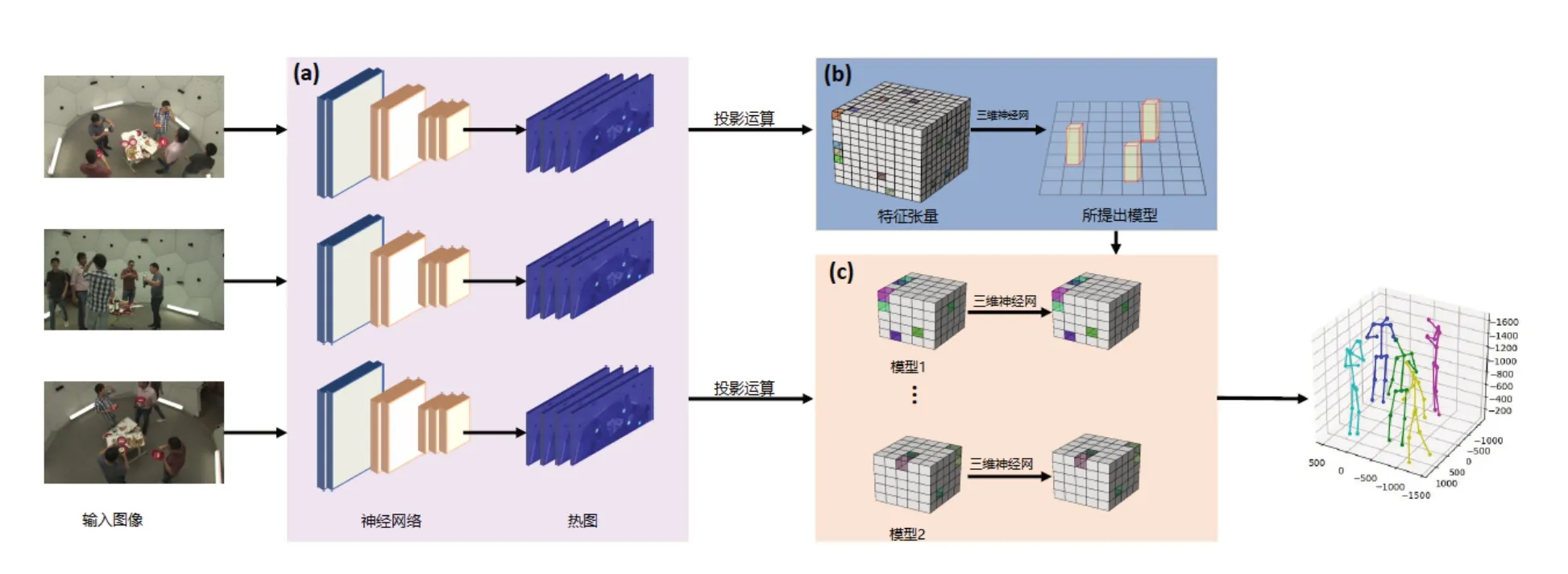
图1 张量与姿态回归网络估计法的算法框架图
对于所提出的方法,本文采用三种常用的数据库进行测试,其中有Campus,Shelf以及CMU Panoptic数据库。经过与其他一些方法的比较测试,我们发现所提出的方法具有比较理想的实验结果,且取得最好的实验结果,尤其是前两个数据库测试。此外,我们还发现所提出的方法经过训练可以准确地合成热图的特征张量。热图的选用是因为其是一个高级图像特征,它可以准确区分原始图像中的表征、光照等重要的特征。所以热图的选用很大程度上提高了该方法估计的准确率。下文将详细地对所提出方法进行讨论。
1 相关工作
本文分别简要回顾单人和多人三维姿态估计的方法,然后阐述所提出方法和以前方法的不同之处,并说明所提出方法的主要核心优点。
1.1 单人三维姿态估计
前期的一些估计方法可以分为分析法和预测法,其中有些模型是有参数的,有些则是无参数的。一些分析方法还建立了二维姿态与三维姿态的几何映射模型。当多视角的镜头拍摄完成后,三维姿态可以通过各个视角投影几何映射的计算进行确定,但是由于视角有限,计算过程中依然出现估计不够准确的问题,一些主要关键点依然出现歧义或错位。另一方面,如果在单视角的镜头下拍摄,歧义的姿态更加严重,一个二维图像可以对应很多种三维姿态。然而,之前的方法有提到使用低维姿态参数优化法去消除歧义,这些方法也只是让问题稍微得到了改善,在一定程度上提高了估计的准确度。在预测法中,提出相关神经网络模型解决歧义问题的看法,各种网络的改进版本由此而生,这些网络在某种程度上也提高了单人姿态估计的性能,相对之前的方法,取得了更准确的结果,但是对于多人姿态估计所涉及的问题就不那么适用了。
1.2 多人三维姿态估计
对于多人的三维姿态估计,这里有两个比较关键的问题需要解决。第一,需要在人群里识别属于个人的姿态关键点;第二,在二维关键点检测时,需要解决多人相互遮挡以及单人自遮挡的问题。在一些图形预测模型的文献[3,13]中提及如何解决以上问题,但很多参数都是预设的,尤其是多人交互的参数优化问题没有得到很好的解决,这些都影响了三维姿态估计的准确度。本文提出的方法能较好地解决以上问题,对于一些优化过程中的问题,出现的局部最优问题也可以较好地避免,而且无需预设二维图像中的人数,通过一些常用数据库的测试,可以看到本文所提的方法比前人的方法结果更好。
2 张量模型
为了解决以上问题,我们先提出一种特征张量模型,该模型装载了一定数据的局部张量,里面含有二维图像的热图数据,这些数据会对后面姿态回归网络的训练有巨大的作用。
2.1 特征张量网络
我们需要建立一个网络装载大量人体在三维空间的信息,将具有各个视角二维姿态的热图投影到三维空间的数据信息,其是一个离散数据模型,有助于后面姿态帧的细化。其网络构建示意如图2所示。
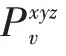
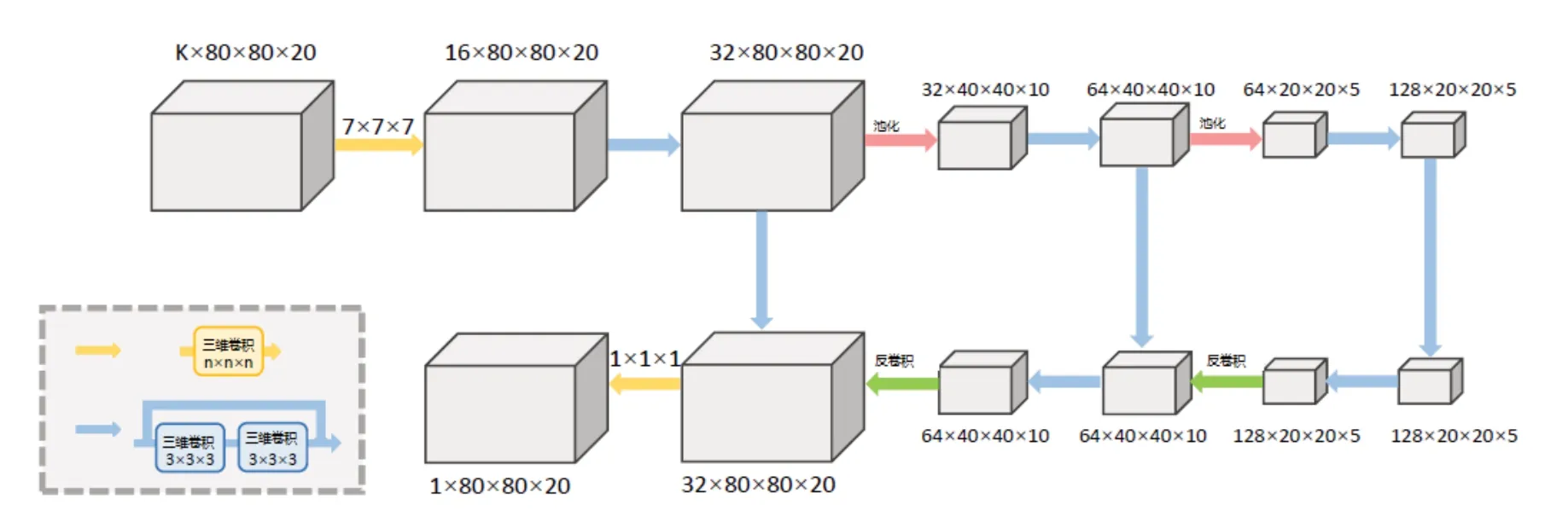
图2 特征张量网络
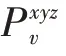

式(1)中,为视角个数。在一些更高级的融合方法中,可以分配一个权重到式(1)的计算,这样可以更好地反映每个视角在热图估计值的质量。在本文提出方法中设计权重平均,即所有因素同等重要。
2.2 边界边框的张量
在做三维姿态估计时我们要对各个视角的人体进行检测,这就需要对相应视角的人体位置边框进行检测,如图3所示。检测中有概率显示,越高的值表明位置越准确,数值低的表明检测效果不好,图3中的灰色框就是这样例子。

图3 对各个视角人体位置边界边框检测示意图
为了实现这样的检测,本文设计一个低维特征张量来描述这些边界边框的值,这些数据有助于我们构建一个全链接层来预测多人边界边框的值,得出置信值V。V∈R表示人体所在二维图像位置的概率值。据此,我们可以计算真实的热图值V 来评价误差。需要注意的是,真实姿态的根关键点及其边界边框是成对存在的,根据他们之间的距离可以计算出高斯分布概率值,这些数值就描述了边框边界位置是否准确。如果处于多人的场景,则可以通过式(2)来建立训练模型的损失函数:

式(2)中,我们设置2000 mm 的边界长度,这样可以足够覆盖人体姿态关键点的所有位置。
3 姿态回归网络
姿态回归网络的建立,是用于预测完整的三维姿态。
3.1 构建姿态特征张量
在空间位置张量建立的基础上,我们就可以对人体姿态进行三维空间定位了。这时,我们需要重新建立一个神经网络去估计姿态,特征参数设置为2000 mm×2000 mm×2000 mm,所检测的边界长度为2000/64=31.25 mm。需要注意的是,姿态网络可利用文献[14]的技巧去降低估计时的量化误差,来完成三维姿态估计。所有构建网络结构图类似于图2,这里不再赘述。
3.2 三维姿态估计
我们估计一个三维姿态的热图H∈R ,其中含有三维姿态的关键点,以此构建特征张量。每个关键点的三维坐标位置可以通过根节点的相对位置H来计算:

在式(3)中值得注意的是,我们不是获取姿态关键点J的具体空间位置,而是通过计算机相对根关键点的最大相对值来求。这样的计算方法有利于降低计算过程中的估计误差。
对于所估计的关键点,可以用式(4)来计算其与实三维模型关键点的误差:
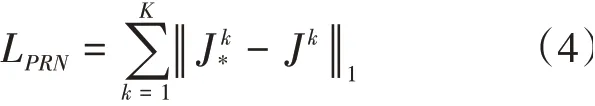
式(4)也可以和式(2)起到类似的作用,即可以用来作为姿态回归网络模型的损失函数。式(4)同样也可以设置权重进行训练,本文设置为相同的权重。
3.3 训练方法
本文对二维回归网络进行了20 个周期的训练。初始学习率设置为10,后面的几个训练周期下降为10和10。训练主干网络时,选用数据库为COCO数据库,这样无需调整太多参数。
4 实验评价
本 文 选 用 三 个 数 据 库Campus Dataset,Shelf Dataset及CMU Panoptic Dataset对所提方法进行测试。我们首先进行相应视角的二维姿态检测,测试结果如图4所示。所比较的方法采用HRNet,其测试结果如图4 上一排图所示,图4 下一排图为文本所提方法的测试结果。从测试结果可知,本文方法的检测结果比HRNet 要准确,HRNet 对一些不重要或不准确的目标也进行了检测,出现了一些不真实且不必要的二维姿态检测结果,相比之下,本文所提的方法检测更精准,其姿态的尺度和大小符合相应镜头的视角比例。

图4 二维姿态检测结果
根据所提的方法,从二维图像的检测估计其三维姿态结果如图5所示,最右侧的一列是其三维姿态估计结果。从图5结果可见,本文所提的方法可以很好地克服多人相互遮挡以及个人自遮挡问题,所估计出的三维姿态结果符合二维图像各个视角的动作逻辑。

图5 多视角估计多人三维姿态结果
与较新的研究方法比较,如文献[2]的快速鲁棒估计法,可以发现本文提出的方法效果更好、更准确,其结果如图6 所示。图6 中图A.1为真实数据,图A.2 为文献[2]的快速鲁棒估计法,图A.3 为本文提出的方法,从测试结果可知,对于部分人的二维姿态检测,文献[2]的快速鲁棒估计法在测试中发现有误,而本文提出的方法可以准确地检测出相应二维姿态的位置。检测过程中有些数据出现歧义,本文方法比文献[2]的快速鲁棒估计法处理得要好。图6 中图B.1 和图B.2 为本文所提方法的失败案例,原因是一些视角没有拍摄完全的人体姿态。

图6 其他多人姿态检测结果与估计失败案例
经过以上实验测试,可以发现本文所提的张量与姿态回归网络方法可以较好地估计多视角多人的三维姿态,其有克服多人遮挡、个人自遮挡以及数据歧义的估计性能。相比前期的一些研究方法,其估计效果更好。
5 结语
本文提出了一种基于张量与姿态回归网络来估计多视角多人的三维姿态。相比前期的研究方法,本文所提出方法更容易识别姿态的三维空间位置信息,而且对于克服各个视角的二维图像的噪声及缺失信息具有良好的稳定性。所提方法建立的特征张量模型对估计一般常见的人体运动形态具有良好的适用性,可以克服多人姿态估计的歧义及遮挡问题,且可估计出较准确的三维姿态模型。本文所提的方法在实验时,多视角镜头参数都是设置普通常用镜头的参数。经过实验测试,本文提出的方法具有良好的估计性能,且具有一定的实用参考价值。
猜你喜欢
电子乐园·下旬刊(2022年5期)2022-05-13
知识文库(2020年2期)2020-01-17
语文教学与研究(综合天地)(2018年10期)2018-12-24
广东教育·高中(2017年10期)2017-11-07
中学课程辅导·教学研究(2017年18期)2017-09-13
商界评论(2016年11期)2016-12-01
校园英语·下旬(2016年3期)2016-04-18
Coco薇(2016年2期)2016-03-22
新高考·高一物理(2015年5期)2015-08-18
读与写·下旬刊(2014年6期)2014-08-07
