
基于融合频域和时域特征的说话人识别
2022-08-01 04:01夏秀渝
现代计算机 2022年11期
龙 翔,夏秀渝
(四川大学电子信息学院,成都 610065)
0 引言
不同人说出的语音具有不同的声纹特点。根据这些特点,可以判断某段语音是若干人中的哪一个所说,即说话人识别。说话人识别主要分为说话人鉴别、说话人确认、说话人聚类等,具体应用在刑侦破案、智能客服、智能家居、金融服务等方面。
随着深度学习的蓬勃发展,和传统的说话人识别模型相比,基于神经网络的说话人识别模型识别精度更高。说话人识别主要由三个步骤组成:语音数据集的建立,说话人特征提取,说话人识别。目前已经有比较完善的语音库,如TIMIT 库、Thchs30 中文库;在特征提取方面,常用的语音特征参数有基音周期、共振峰、线性预测倒谱系数(Liner Prediction Cepstral Co⁃efficients,LPCC)、梅 尔 倒 谱 系 数(Mel Fre⁃quency Cepstral Coefficients,MFCC)等。通过研究,常见的MFCC、LPCC、GFCC 等参数能够进行识别,但是单一的特征参数不能囊括不同说话人的全部特点。文献[2]采取MFCC 与GFCC 混合特征参数进行训练,纯净语音识别准确率92%左右,较单独使用MFCC 或GFCC 识别准确率提高了10%。可以发现,根据不同语音特征参数的特点进行特征融合对提高识别精度具有重要的研究意义。由于不同说话人的感知特性主要反映在频域中,时域特征可以辅助频域特征参数进行清浊音、有声和无声段的区分。所以本文采取融合频域特征参数MFCC、MFCC一阶差分(ΔMFCC)、GFCC、GFCC 一阶差分(Δ GFCC)和时域特征参数短时能量作为神经网络训练参数。在说话人识别方面,动态时间规整法(Dynamic Time Warping,DTW)、矢量量化法(Vector Quantization,VQ)、隐马尔科夫模型(Hidden Markov Model,HMM)、人工神经网络法(Artificial Neural Network,ANN)等方法先后被广泛应用。典型的深度学习方法有全连接前馈神经网络(Deep Neural Networks,DNN)、卷积神经网络(Convolutional Neural Net⁃works,CNN)和循环神经网络(Recurrent Neural Network,RNN)。其中RNN 由于在处理时序数据方面的优势而被广泛应用于自然语言的识别和处理。1997 年,Hochreiter 和Schmidhuber首次提出了长短时记忆(Long Short Term Memory,LSTM)神经网络,作为RNN 网络的变形结构,LSTM 增加的门控单元能够有效地避免RNN 存在的梯度消失和梯度爆炸的问题,且能高效地抓取到语音信号的时序特性。但是LSTM只考虑了单向的时序数据,忽视了后文信息对前文信息的重要性。针对以上问题,本文识别模型采取双向长短时记忆(Bidirectional Long Short-Term Memory,BiLSTM)神经网络,其在LSTM 基础上添加了反向运算,考虑到了上下文信息间的关联性。
综上,本文采取一种基于融合频域和时域特征的说话人识别模型,旨在提高模型的识别准确率。实验表明,本文模型相较于其他模型具有更高的识别精度。
1 特征参数的提取
语音特征参数主要分为时域特征参数和频域特征参数。人类能够准确地分辨不同人说话的音色和音调,是因为人类的听觉系统对语音信号的音高、音强、声波的动态频谱具有较强的分析处理能力。所以频域分析在语音信号分析处理中尤为重要,时域分析次之。
频域特征参数MFCC 和GFCC 是利用人耳听觉模型建立的倒谱系数,但是只反映了语音参数的静态特性,ΔMFCC 和ΔGFCC 弥补了动态特征的缺失,时域特征参数短时能量用来表示语音信号能量的大小和超音段信息。
本 文 将13 维MFCC、13 维GFCC、13 维ΔMFCC、13维ΔGFCC 和1维短时能量进行拼接,组合成53维特征参数。
1.1 MFCC特征参数的提取
低频声音在内耳蜗基底膜上行波传递的距离大于高频声音,低音容易掩蔽高音,所以相较于高频信息,低频部分更易被人类感知,MFCC 就是根据这种特点设计的。
将线性频谱映射到基于听觉感知的Mel非线性频谱,然后再转换到倒谱上,最终形成MFCC 特征参数。线性频率与Mel 频率之间的转换公式如下:
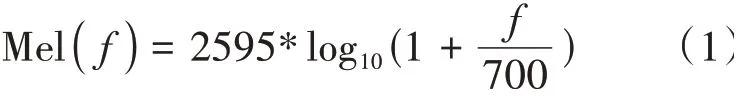
MFCC参数的提取过程流程如图1所示。

图1 MFCC的提取过程
流程包括了信号预处理(预加重、分帧、加窗),对预处理后的语音信号进行快速傅里叶变换,将信息转换到频域上,接着对每一帧频域数据计算其谱线的能量,然后计算通过Mel滤波器的能量并取对数,最后对数滤波器组能量求离散余弦变换(DCT)。相应的计算公式如下:
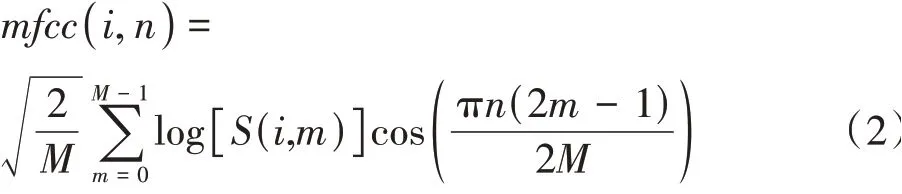
式中,(,)是Mel滤波能量;为梅尔滤波器的个数;为第帧;是DCT后的谱线。
1.2 GFCC特征参数的提取
人耳耳蜗中大部分的基底膜负责处理声音信号的低频部分。基底膜可以把不同频率的声音信号组成的混合音频,经过大脑分析滤除不被听者所重视的语音信息后,使听者接收到所需信号。GFCC 就是根据这种特点所设计的,Gammatone 滤波器的排列也是根据人类基底膜的排列,其表达式为:
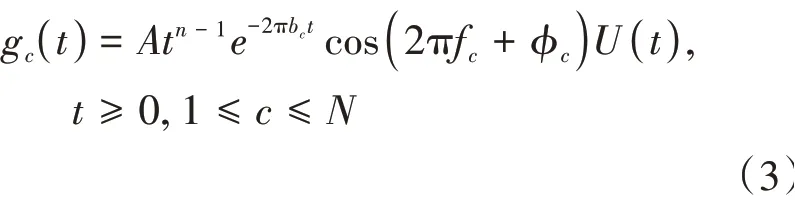
式中,为滤波器增益,为滤波器阶数,b为衰减因子系数,f为滤波器中心频率,()为阶跃函数,φ为偏移相位。
GFCC参数的提取过程流程如图2所示。
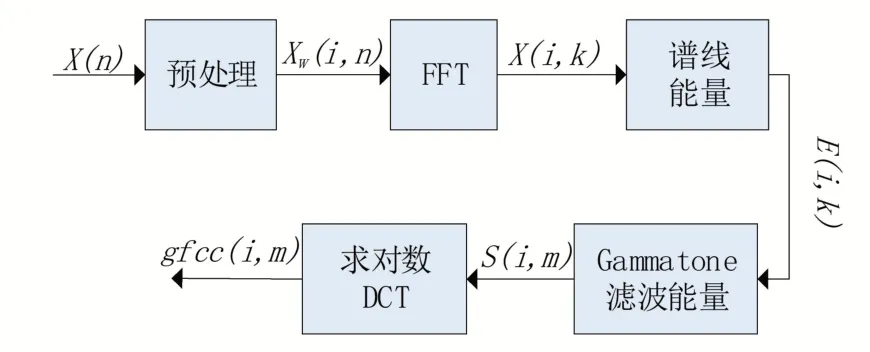
图2 GFCC的提取过程
GFCC 特征参数的提取流程和MFCC 提取流程类似,只是将求得的每帧谱线能量通过Gam⁃matone滤波器来替代Mel滤波器。
1.3 ΔMFCC和ΔGFCC的提取
MFCC 和GFCC 为语音信号的静态特征,不符合语音动态变化的特性,对MFCC 和GFCC 分别进行差分运算就得到了ΔMFCC 和ΔGFCC,Δ MFCC和ΔGFCC的运算公式分别为:
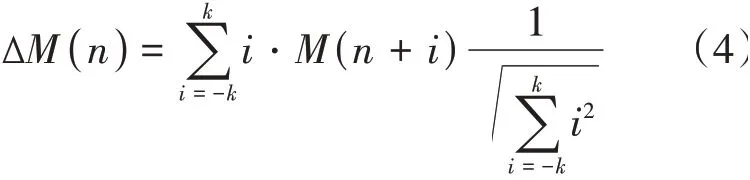
式中Δ()表示第个一阶差分,(+)表示第+个倒谱系数的阶数,表示差分帧的区间。
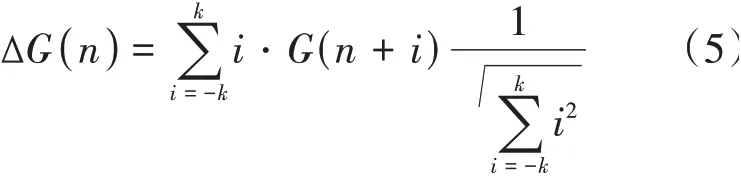
式中Δ()表示第个一阶差分,(+)表示第+个倒谱系数的阶数,表示差分帧的区间。
1.4 短时能量特征参数的提取
语音信号的能量变化比较明显,清音部分的能量要低于浊音,对短时能量分析可以描述语音的特征变化情况。语音信号的短时能量公式为:

式中()代表第帧语音信号的短时能量,y()代表第帧语音信号,代表帧数。
2 主成分分析法特征参数降维
上文提取的53维混合特征参数的维度过大,不仅会增大模型的时间复杂度和空间复杂度,还会产生多重共线性的问题,从而对模型训练的精度造成影响。所以本文通过主成分分析法(Principal Component Analysis,PCA)对上文混合特征参数进行降维。PCA 的任务是找到能够主要表示原始维度信息的成分,从而达到降维的目的。
假设一个样本空间位Y,对其进行降维的主要步骤有:
(1)首先求出样本均值

(2)计算样本空间的协方差矩阵

(3)计算协方差矩阵的特征值和特征向量,特征值按照从大到小的顺序排列


当特征值>1 时,说明该主成分所含有的信息较为充分,通常降维后只保留特征值>1 的主成分。因此,本文进行PCA 降维后保留前30维主成分组成本文目标特征参数。
(4)计算在每一维的投影
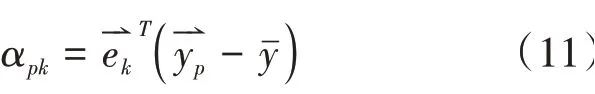
3 BiLSTM神经网络
人工神经网络是基于生物学的基本理论,模拟人类大脑的神经系统对复杂信息的处理机制的一种数学模型。其本质是由很多小的非线性函数组成的非线性函数网,网络反映的是输入特征参数与输出标签之间的对应关系。
目前神经网络的基本架构有深度学习网络、卷积神经网络、循环神经网络等。
DNN 由于都是全连接形式的结构,随着网络层数的增加,参数增长可能会出现爆炸的情况;CNN 尽管可以解决过度拟合和局部最优解的问题,但是在神经网络训练时,每一层的神经元进行的操作都只与前后毗邻的一层神经元直接相关,无法对有时序关系的信号进行建模;RNN 网络中神经元的输出依赖当前的输入和记忆,很好地模拟了人类拥有记忆的能力,但正是由于RNN 网络结构在自然语言处理方面的优越性,其网络结构较DNN 和CNN 复杂很多,在反向传播规模过大时会带来梯度爆炸和梯度消失的问题;而LSTM 神经网络只考虑了单向数据的信息,忽视了后文信息对前文的影响。
BiLSTM 神经网络,其在LSTM 基础上添加了反向运算,考虑到了上下文信息的互相影响。BiLSTM 神经网络的结构由正反向2 个LSTM 神经网络组成,LSTM的单元基本结构如图3所示。

图3 LSTM基本单元结构
图3 中x代表当前时刻的输入,h代表上一时刻的输出,C代表上一时刻的单元状态,h代表当前时刻的输出,C代表当前时刻的单元状态,代表Sigmoid 激活函数,tanh 代表tanh激活函数,f代表遗忘门,i代表输入门,C'代表单元状态更新值,O代表输出门。
遗忘门f决定了上一时刻的单元状态有多少需要保留到当前时刻,其计算公式如下:

式中,W代表遗忘门的权值,b代表遗忘门的偏置。
输入门决定了当前时刻网络的输入数据需要保存多少到单元状态,其计算公式如下:

式中,W代表输入门输出i的权值,b代表输入门输出i的偏置。
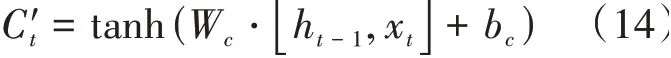
单元状态更新值C'计算公式如下:式中,W代表输入门单元状态的输出C'的权值,b代表输入门单元状态的输出C'的偏置。
输出门O决定了当前时刻的单元状态有多少需要输出到当前的输出值,其计算公式如下:

最终,整个单元的输出计算公式如下:

基于众多研究实验表明,BiLSTM 神经网络不仅能够很好地考虑到语音信号的时序关系,并且通过各种“门”的结构能够有效地解决长序列训练过程中的梯度爆炸、梯度消失和长距离依赖的问题,同时可以充分利用语音数据上下文的相互影响以提高模型识别准确率。所以本文选择BiLSTM 神经网络作为说话人识别的网络模型。
4 实验
4.1 实验设置
本文仿真实验在Pycharm 平台上实现,神经网络的框架采用tensorflow2.0,神经网络模型第一层为输入层,输入本文提取的目标特征参数;第二、三层为BiLSTM 层,每层256 个神经元;第四层为全连接层,神经元的数量等于说话人标签数;第五层为SoftMax 层,实现标签的分类。Batch_size 设置为128,迭代次数设置为100。
4.2 实验设计
本文基于TIMIT 英文语音库进行实验,语音库中包含美国8 个地区630 个人的纯净语音数据。实验采用不同地区50 个人的语音数据,每人10条语音,每条语音6 s左右。随机选取每个说话人的8 条语音作为训练数据,2 条语音作为测试数据,即训练数据400 条语音,测试数据100条语音,训练集:测试集比例为8 ∶2。
分 别采用13 维MFCC、13 维GFCC、13 维MFCC+13 维GFCC、13 维MFCC+1 维短时能量、13 维GFCC+1 维短时能量、13 维MFCC+13 维GFCC+1维短时能量、13维MFCC+13维ΔMFCC+13维GFCC+13维ΔGFCC+1维短时能量(53维混合特征参数)以及本文目标特征参数进行对比实验。
4.3 实验结果
图4和图5分别给出了各种特征参数在训练集和测试集上的准确率(accuracy)和误差(loss)曲线。
从图4 和图5 可以看出,所有参数在BiL⁃STM 模型上的准确率都随着迭代次数的增加而平稳上升,最终达到收敛。本文所提取的目标参数在训练集上的准确率在50 轮迭代后达到收敛,稳定在99.6%左右,在测试集上的最佳识别准确率达到99.61%。从实验结果可以看出,本文模型较文献[14]、文献[2]中模型的识别精度分别提高了7.50%和3.00%。表1 列出了个不同参数在训练集和测试集上的最佳识别率。
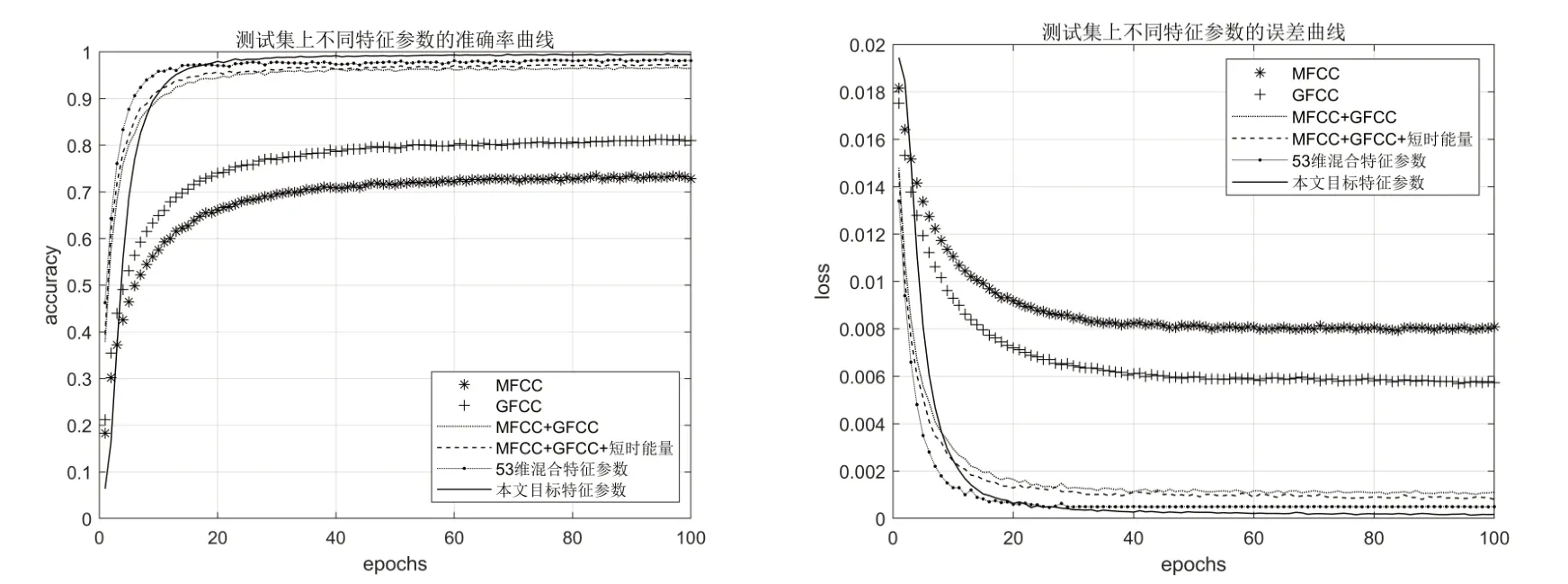
图4 测试集上不同特征参数的准确率和损失值的对比曲线
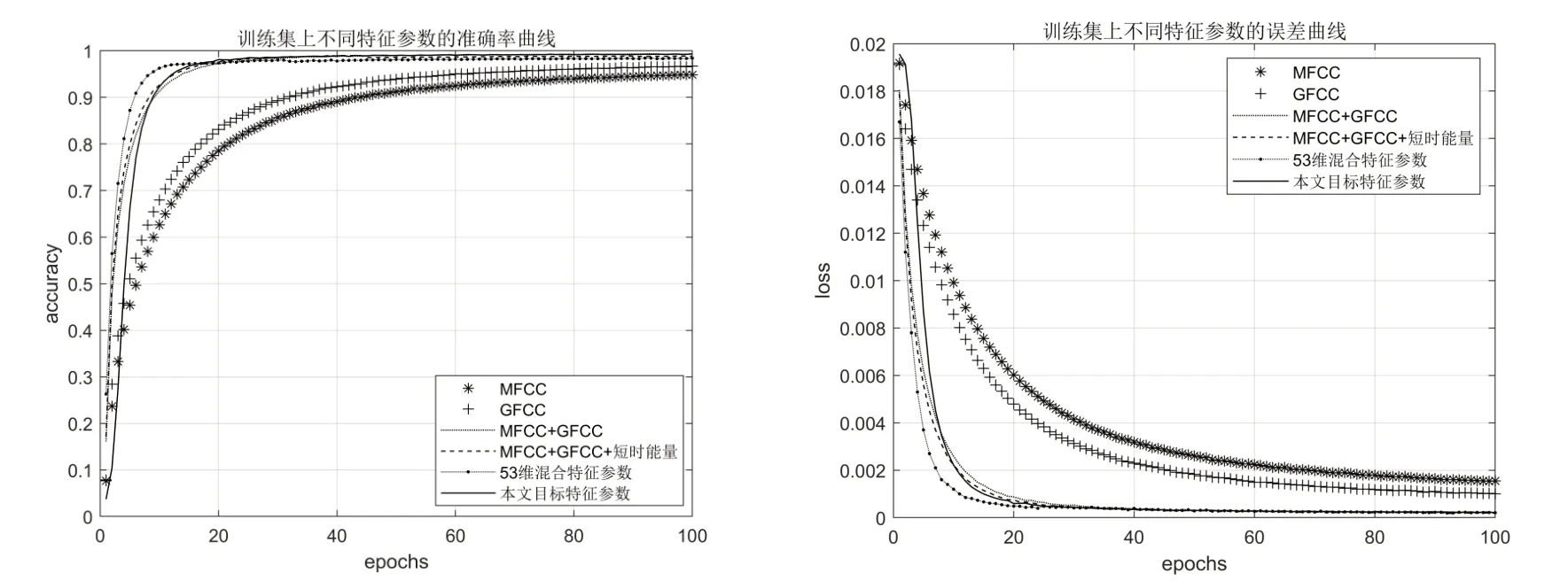
图5 训练集上不同特征参数的准确率和损失值的对比曲线

表1 训练集和测试集上不同特征参数的最佳识别率对比
从表1 可以看出,将时域特征参数(短时能量)和频域特征参数融合后,都比只采取频域特征进行训练的模型效果好。同时,对维度多的特征参数进行降维,既降低了模型训练的时间和空间复杂度,也降低了语音的无声段和背景噪声对识别精度的影响,提高了模型的识别准确率。
5 结语
结合语音特征参数的特点和深度学习在说话人识别领域的研究成果,本文提出基于融合特征参数-BiLSTM 的说话人识别研究方法,将不同特征参数和本文目标特征参数送入双向长短时记忆(BiLSTM)神经网络进行训练,最终得到一种识别精度高的说话人识别模型。实验结果表明,在TIMIT 数据库上,本文模型取得了99.61%的识别准确率。相对于其他特征参数和模型匹配的识别模型,本文提出的方法具有更高的识别精度。下一步研究可针对说话人识别的同时进行语音文本识别,以达到模型的广泛实用性。
猜你喜欢
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
振动工程学报(2019年2期)2019-05-13
软件(2017年6期)2017-09-23
物联网技术(2016年11期)2017-01-12
