
融合上下文特征和空洞空间金字塔池化的语义分割
2022-08-01 04:01刘东东马银平
现代计算机 2022年11期
刘东东,马银平
(南昌航空大学信息工程学院,南昌 330063)
0 引言
语义分割是计算机视觉的重要任务之一,目的是给图像中每个像素进行分类,使整幅图划分为几个特定的不同区域,进而完成分割的任务。目前语义分割被广泛应用到无人驾驶、医疗影像检测、地理信息系统等任务中。
2014 年,Long 等提出了全卷积神经网络(Fully Convolutional Network,FCN),首次将深度学习技术应用到图像语义分割任务中,在计算机视觉领域有着划时代的意义。FCN 网络相比于分类网络而言,去除了全连接层,使用卷积层代替,加入了上采样层用来恢复特征图的尺寸,最后获得一个和原始输出图像h,w 相同的二维热度图,用于对图像进行像素级别的分类。为了提升预测的精度,FCN 网络采用了一种跳跃连接的结构,将全局信息和局部信息连接起来,FCN 作为图像语义分割领域的开山之作,由于其优秀的分割性能,在FCN 网络的基础上诞生了很多优秀的语义分割网络,根据特征提取网络的不同大致可以分为两类:一类是使用VGGNet 作为语义分割特征提取网络,如FCN、SegNet、U-Net、DeepLab等;另一类是使用ResNet作为语义分割特征提取网络,如PSPNet、DeepLabV3+等。
本文采用ResNet-50作为语义分割的特征提取网络,在最后一个层(Layer)之后引入ASPP模块,用来获取不同感受野的特征图,在上采样过程中通过细化残差模块(Refinement Residual Block,RRB)对要融合的不同层的特征图进行处理,最后将输出特征的通道数压缩为分类的个数,对图像进行像素级别的预测。
1 网络结构
1.1 系统框架
本文提出的模型算法的框架如图1所示,主要由两部分组成,空洞空间金字塔(Atrous Spa⁃tial Pyramid Pooling,SAPP)模块和多特征融合上采样模块,模型的特征提取网络采用的是ResNet-50,网络的参数见表1。由于频繁的下采样会导致图像的特征信息丢失,所以在主干特征提取网络的最后一个Layer 后面添加了一个ASPP 结构,用来增加感受野并获取多尺度特征信息,在上采样的时候采用多层特征融合的方法用于进一步获取图像的上下文信息,使模型能够提取到更多有效的空间信息和语义信息。最后对特征图进行通道数的调整,将其调整为分类数,通过Softmax 分类器计算每个像素属于不同类别的概率值,输出分割的结果,完成语义分割任务。
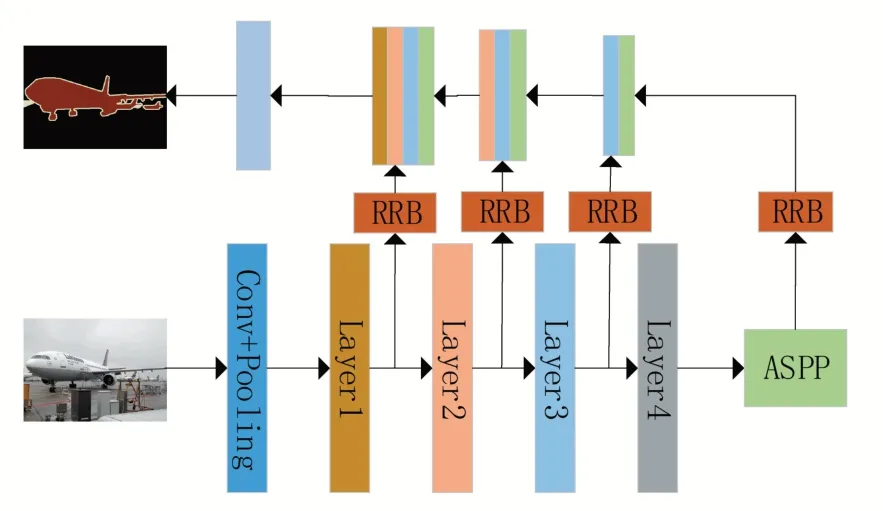
图1 融合上下文特征和空洞空间金字塔池化的语义分割
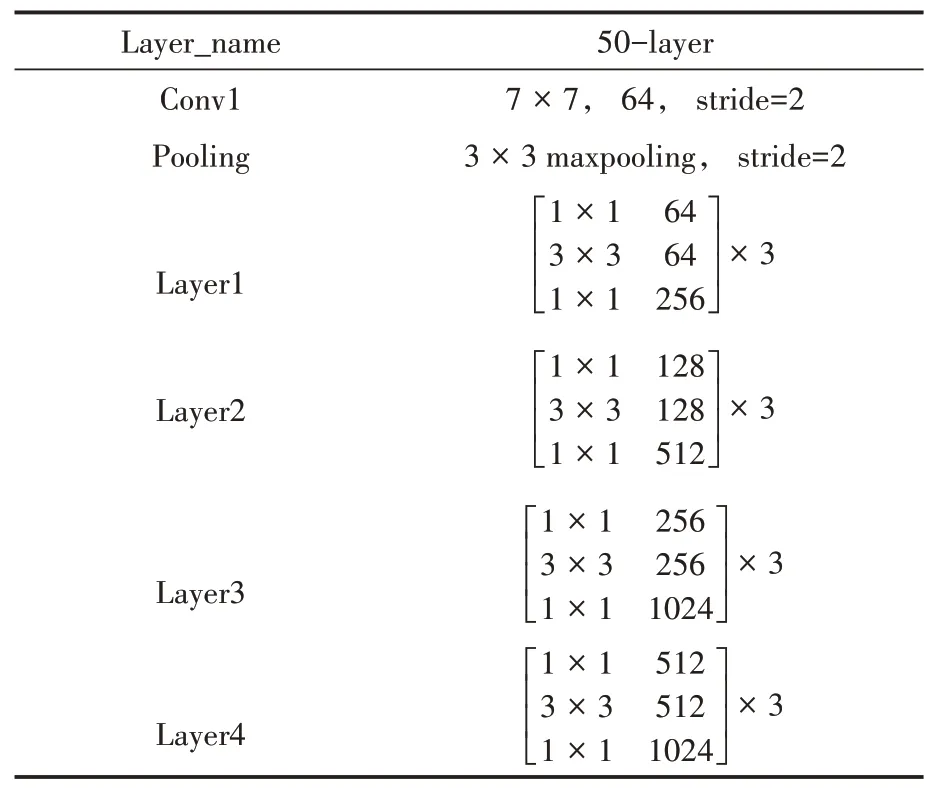
表1 ResNet-50 结构参数
1.2 空洞空间金字塔模块
ASPP 的思想来源于SPPNet,主要是为了解决目标的多尺度问题。通过设计不同的空洞率的多个并行卷积核组成类似金字塔样式,在给定的特征层上进行有效的重采样,空洞卷积也称为膨胀卷积,之所以采用膨胀卷积替代池化,一方面是因为不断的下采样不仅会丢失图像中很多的细节信息和空间位置信息,另一方面膨胀卷积可以保证在参数量不变的情况下,通过增大卷积核尺寸来扩大感受野的大小,并在获得更大感受野的同时保留更多的空间信息。
所谓膨胀卷积就是在标准卷积的基础上引入一个称为膨胀因子的超参数,膨胀因子表示的是卷积核之间的间隔数,标准卷积的卷积核之间的间隔数为1,即标准卷积的膨胀因子为1。当膨胀因子扩大时,卷积核之间的间隔使用0填充,膨胀卷积的感受野计算公式如式(1)所示:
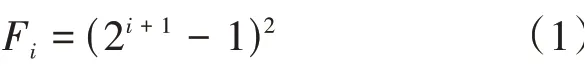
其中,F代表膨胀卷积的感受野大小,表示膨胀因子大小。
图2为膨胀卷积的示意图,图2(a)为标准的3 卷积,也就是膨胀因子为1 的卷积,其感受野大小= 3 × 3;图2(b)为膨胀因子为2 的3 × 3 卷积,其感受野大小为= 7 × 7;图2(c)为膨胀因子为3的3 × 3卷积,其感受野大小为= 15 × 15。通过上述可以看出,在学习参数相同的情况下,都是9个权重参数,我们可以通过设置膨胀因子来获得不同感受野的滤波器,增加网络对多尺度物体的适用性。
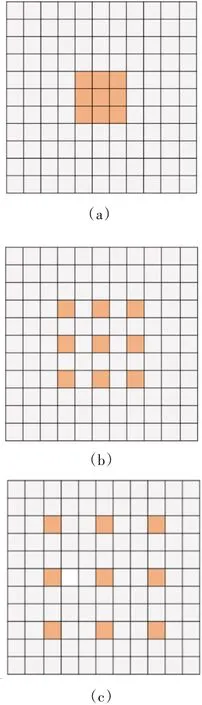
图2 膨胀卷积
本文在主干特征提取网络的最后一个Layer之后引入RRB-ASPP 模块,如图3 所示,用来获取多尺度感受野的特征图,然后ASPP 结构的输出通过RRB 模块进行通道数的调整,最后用于多层特征融合。
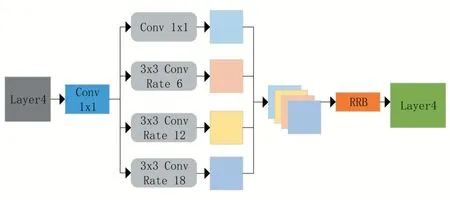
图3 带RRB-ASPP模块的主干网络结构
1.3 多层特征融合上采样模块
语义分割需要对不同空间尺度的信息进行融合,浅层网络提取到局部信息包含很多细节性的特征,深层网络提取到全局信息包含更多的语义,所以全局信息和局部信息对分割的精度都会产生影响。由于卷积神经网络的空间不敏感性,也会对语义级别的分割产生影响,因此本文采用了一种多层特征融合的上采样模块,如图4所示。

图4 细化残差模块
多层特征融合上采样模块在融合不同层的特征图时,通过一个细化残差模块RRB 先对每层输出的特征图进行处理,RRB 模块首先采用1 × 1 卷积对特征图的通道数进行调整,将不同隐藏层的通道数进行统一,都调整为256,另外还采用了残差结构对特征进一步提取,RRB 模块分别添加在ResNet-50 三个特征提取块之后,因为浅层特征的下采样过程比较少,所以保留的空间信息和边界等细节性信息比较多,在上采样的过程中融合不同特征层信息,能使分割效果更好。
2 实验与分析
2.1 实验环境与数据集描述
本语义分割模型使用PyTorch 深度学习框架搭建,实验环境配置见表2。

表2 实验环境配置
采用的数据集为PASCAL VOC2012 数据集,该数据集由训练集、验证集和测试集构成,包含 四 个 大 类 别, 分 别 为Person, Vehicles,Household,Animals,细分为20个小类别和一个背景类别,其中属于Vehicles 的有Car,Bus,Bicycle, Motorbike, Aeroplane, Boat, Train;属于Household 的 有Chair,Sofa,Dining table,TV,Bottle,Potted plant;属 于Animals 的 有Cat,Dog,Cow,Horse,Sheep,Bird。
2.2 评估指标
本文采用的是语义分割任务中常用的两种评估指标,平均像素精度()和平均交并比(),这两种评估指标能直接地反映出模型在语义分割任务中的性能。假设数据集中的类别个数为c,加上一个背景类别,总的类别数为+1,设p表示正确预测正样本的像素个数,p表示错误预测为正样本的像素数,p表示错误预测为负样本的像素个数。
平均像素精度(mean Pixel Accuracy,mPA)的计算公式如式(2)所示:
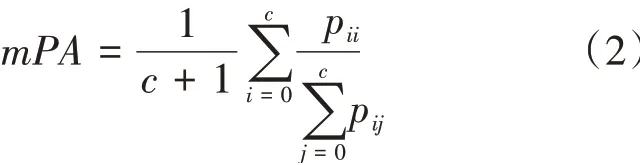
平均交并比(mean Intersection over Union,mIoU)的计算公式如式(3)所示:

2.3 实验参数与结果分析
实验中,首先对输入的图片进行随机尺度调整、随机裁剪以及随机翻转等一系列特征增强操作,采用了Adam 优化器,该优化器能够动态地调整算法中的使用学习率参数,初始学习率设置为0.01,采用Poly 学习率策略对学习率进行动态的调整,如式(4)所示:
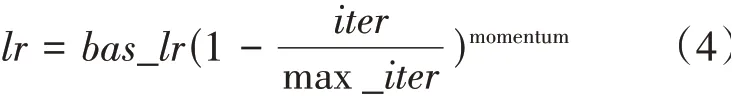
其中momentum 的值设置为0.9,迭代次数为500,batch_size为8。
为了进一步验证本文所提出网络实现的效果,与FCN,SegNet,DeepLabV2,PSPNet 等网络进行对比,在PASCL VOC 2012 数据集上语义分割性能对比结果见表3,相比于其他4 种方法,本文所提出的方法在性能上有一定的提升。
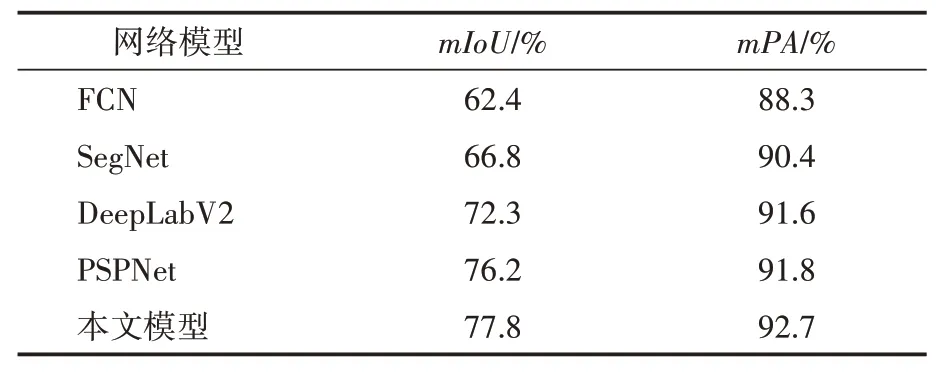
表3 网络分割结果
与FCN,SegNet,DeepLabV2,PSPNet 等网络的分割效果图对比如图5所示,从分割效果图可以看出,本文网络在分割的细节上有所提升,如在第一张效果图中对于路灯杆的分割比前面的网络要好;在第二张效果图中对于道路的分割效果也比前几种网络有所提升。
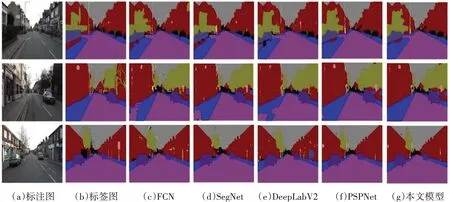
图5 网络分割效果图
3 结语
针对语义分割网络在进行语义分割的时候容易丢失边界和位置信息,造成图像分割的结果粗糙以及对像素类别的误判,提出融合上下文特征和空洞空间金字塔池化的语义分割方法。对比实验证明,本文提出的模型在PASCAL VOC 2012 数据集上,相比于FCN,SegNet,DeepLabV2,PSPNet 等网络在分割性能上有一定的提升。本文使用的backbone 是ResNet-50,在未来,我们可以考虑如何进一步改进特征提取网络来获得更好的分割性能。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
东疆学刊(2022年2期)2022-04-22
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
电机与控制学报(2018年9期)2018-05-14
中国新通信(2017年9期)2017-05-27
计算机应用(2016年10期)2017-05-12
