
基于改进YOLO v4光线模糊场景下交通标志检测
2022-07-29 06:17符祥远
计算机与现代化 2022年7期
申 智,徐 丽,符祥远
(长安大学,陕西 西安 710064)
0 引 言
随着当今社会科技的蓬勃发展,无人车走进了大众的视线。对于现在的无人车而言,人们不仅对自动驾驶交通标志检测[1-4]的速度有着很高的要求,而且对于交通标志检测的精确度要求也越来越高。有很多的交通事故是因为光线模糊导致交通标志看不清,这时的标志就不能起到预警和提醒的作用。因此保证在光线模糊场景下,交通标志检测所用时间没有太大增加的前提下,提高交通标志检测的精确度是十分重要的,这样可以大大减少交通事故发生的几率,进一步保证车上司机和乘客的安全。
目前对于交通标志的检测算法可以分为2类:单阶段[5]检测算法和双阶段检测算法。双阶段检测以Girshick等人[6]提出的R-CNN为代表,包括Fast R-CNN[7]、Faster R-CNN[8]、Mask R-CNN[9]和R-FCN[10]。单阶段检测以Redmon等人[11]提出的YOLO为代表,除此之外还有SSD[12]。它们最大的不同之处是R-CNN多了一步候选框生成阶段,生成ROI(Region of Interest)。从深度学习使用于交通标志检测开始,已经有了很长的一段时间,人们也在原有的基础上做出了很多的改进。就拿最近两三年来说,在交通标志检测与识别方面有:刘恋等人[13]在设计CNN网络时引入Inception结构的改进;Lee等人[14]提出了在构建CNN算法的基础上加入估计交通标志的位置和边界。
R-CNN因为要提取候选区域、特征与支持向量机(Support Vector Machine, SVM)进行目标的分类,尽管后续提出了改进方法提高了精确度和速度[15],但它的速度相对来说还是比较慢。YOLO却恰恰相反,从YOLO v1开始尽管经历了多次的优化和进步[16-17],但依然是速度快而精确度不高。YOLO v5[18]是在2020年6月10日发布的,根据Roboflow的研究表明,YOLO v5的训练非常迅速,在训练速度上远超YOLO v4,但是YOLO v5相对于YOLO v4的创新点很少,两者性能接近,YOLO v5的平均精度值甚至低于YOLO v4,所以在某种程度上YOLO v4仍然是目标检测的最佳框架。
为此,在YOLO v4[19]的基础上,本文提出一种基于改进YOLO v4的交通标志检测算法,在保证速度的同时提高检测的精确度。
本文主要使用改进的K-means++对数据集进行聚类,并且对网络结构做了优化。除此以外,还对YOLO v4的损失函数进行改进,改进的损失函数用于训练,以提高检测精度。同时使用MSRCR算法对网上公开的BelgiumTS交通信号数据集中光线模糊下的图片进行数据增强处理。将上述的方法结合在一起可以使最后的检测图片的精度大幅度提高。
1 YOLO v4算法
2020年提出的YOLO v4算法是在YOLO v3算法的基础上,融合了近些年来深度学习神经网络中具有优势的算法模型的思想和训练技巧,同时弥补了很多缺陷,实现了速度和检测精度上的完美提升。
YOLO算法做目标检测时,首先是将目标图片划分成S×S个格子,然后将矩阵送入深度神经网络中,对每个格子是否存在目标、目标的边框与类别进行预测,最后筛选出最合适的边框,得到预测结果。在YOLO v3中采用的是Darknet53特征提取网络,而在YOLO v4中,借鉴了跨阶段局部网络(CSPNet),对YOLO v3的特征提取网络进行了改进,构成了YOLO v4的特征提取网络CSPDarknet53。YOLO v4采用GSPDarknet特征提取网络,并使用Mish激活函数、Dropblock正则化方式;加入空间金字塔池化层(Spatial Pyramid Pooling, SPP)和PANet,SPP可以解决图片尺寸大小不一的问题,使得图片矩阵以固定值输出;对于检测头部分,YOLO v4继续采用YOLO v3算法的检测头(YOLO-Head),最终构成了“CSPDarknet53+SPP-PANet+YOLO-Head”的模型结构。YOLO v4网络结构如图1所示。
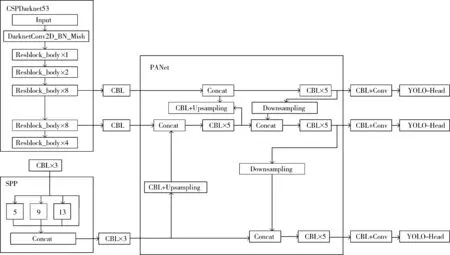
图1 YOLO v4网络结构图
2 改进的YOLO v4算法
2.1 对YOLO v4的网络结构进行改进
在YOLO v4中,PANet通过对不同特征层的语义信息进行处理,可以处理不同尺寸的目标。由于检测在光线模糊状态下的交通标志可能会出现局部细节缺失的效果,针对这一问题,本文提出对PANet改进:将浅层和深层特征与原始特征层融合,形成一个大小为104×104的特征层。在原本有13×13、26×26、52×52这3个特征层的情况下,增加一个新的特征层会造成网络结构中参数量增加,影响交通标志检测的速度。为了降低增加特征层对检测速度的影响,选择去除PANet中的路径增强结构。改进后的PANet便可以保证在提高交通标志检测精度的同时不影响交通标志检测的速度。
2.2 聚类先验框优化改进
原始的YOLO v4先验框是通过K-means算法聚类得到的。K-means[20-22]选取点所在的位置是随机的,可能会出现的结果只是局部最优但不是全局最优,而K-means++聚类算法是在原本的K-means算法基础上实现了优化[23],恰好弥补了局部最优而不是全局最优的不足。为了取得良好的训练效果,本文对先验框采用K-means++对交通标志数据集进行聚类分析。
传统的K-means++聚类算法采用欧几里得公式计算距离,先验框比较大的情况下会出现很大的误差,影响实验结果。所以本文采用交通标志真实框和交通标志预测框的交并比(Intersection Over Union, IOU)的方式表示距离。
(1)
d=1-IOU
(2)
其中,d为距离,btrue、bpredict分别为交通标志真实框和交通标志预测框。IOU越大说明2个框的重合度越高,当IOU为1时说明2个框完全重合。
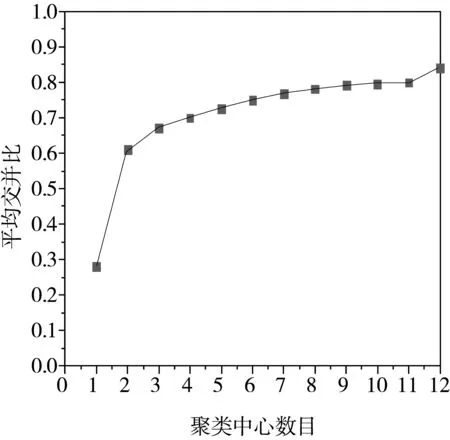
图2 先验框数量与IOU联系图
在实验过程中本文选取改变先验框数量来得到先验框数量与平均IOU之间的关系。根据图2的结果可以看出,随着先验框数量的增多,平均IOU数值也在不断增大。考虑到网络的计算量,本文选择9个候选框。
2.3 对训练集数据的增强处理
本文对训练集进行了MSRCR增强的处理,并且加入了色彩恢复因子,使得原来那些光线模糊下的图片达到了一个比较好的效果,之后再对MSRCR算法处理过的图片进行训练。
一般地,MSRCR算法是在单尺度的情况下对多尺度滤波进行加权处理。
(3)
其中,Ii(x,y)表示的是通道图像,Fk表示中心环绕函数,见公式(4):
(4)
其中ck表示色彩恢复因子。
在进行多尺度滤波结果加权的时候需要满足下面公式:
(5)
其中ωk表示第k个尺度的权值,通常ωk值为1/k。
检测图片用MSRCR增强,如果有噪声,图片会失真,使最后得到的图片质量大打折扣。针对这个问题,通过在实验中加入色彩恢复因子来解决。在实验中使用下面的方法:
RMSRCRi(x,y)=Ci(x,y)RMSRi(x,y)
(6)
f[I′i(x,y)]=klog[mI′i(x,y)]
其中,m代表受控制的非线性强度,k代表一个增益常量。
图3~图8是2组原始图像和经过MSRCR处理过的图像以及加入了色彩因子之后的图片,可以看出,在加入了色彩恢复因子之后图像的质量有了非常明显的改善。

图3 原始图像1

图4 MSRCR图像1

图5 加入色彩恢复因子的MSRCR图像1

图6 原始图像2

图7 MSRCR图像2

图8 加入色彩恢复因子的MSRCR图像2
2.4 边界框损失函数改进
公式(1)也可能会出现图9的情况。
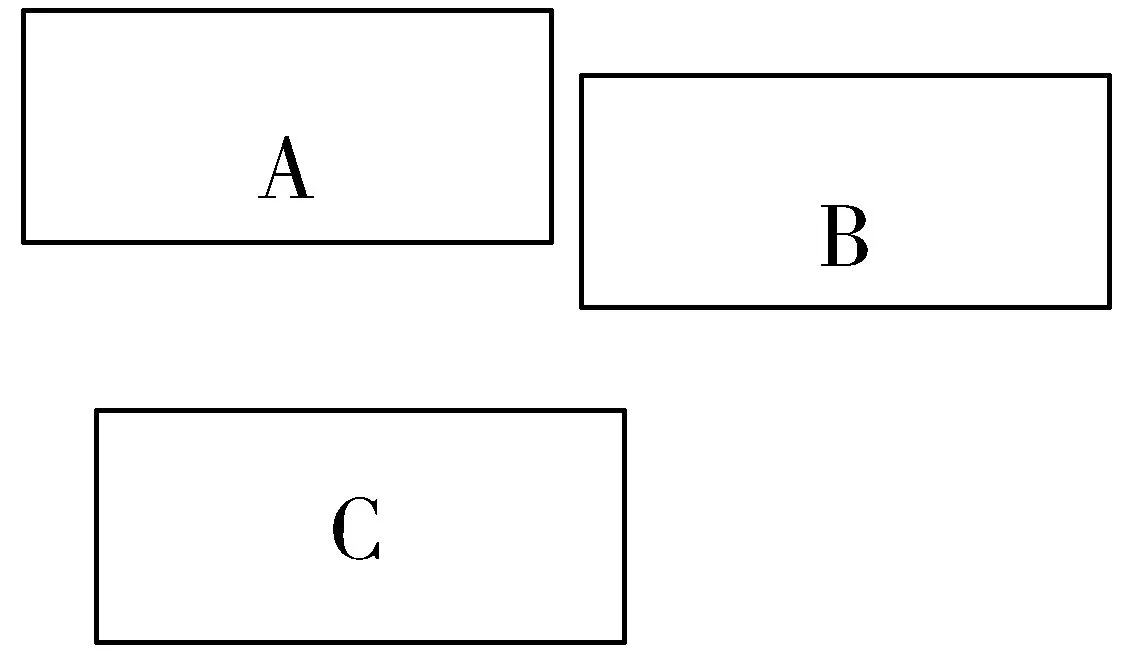
图9 框不相交的情况
3个框之间都没有交集,A和B与C两两的IOU都是0,但从图中可以明显看出A和B之间的距离更近。这时距离d都是1,不能进行训练。根据这种情况使用了DIOU,它的表达式如下:
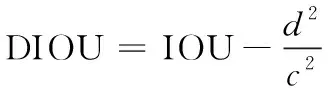
(7)
其中,c表示预测框与真实框闭包的对角线数值,d表示从预测框的中心点到真实框中心点的距离。此时的边界损失函数变成了如下公式:
d=1-DIOU
(8)
公式(8)中的DIOU将重叠率、边框距离这些因素都考虑在了里面,可以成功解决IOU在训练过程中可能会出现的发散问题。
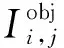

(9)
如果预测框和真实框相交,则和原来的IOU是相同的,当不相交时,改进的损失函数精确度就会体现出它的优越性。
3 实验与结果分析
3.1 实验配置
本文具体的实验配置如下:
电脑配置:操作系统为Windows,CPU为i5-9700,内存为8 GB,显卡为GTX 1080Ti,硬盘为1 TB+256 GB。
环境配置:学习框架为完全由C语言编写的轻量化学习框架Darknet,Python版本为3.7,CUDA为10.2,Visual Studio为2019版本,本次实验选择使用GPU来进行训练,初始学习速率为0.001,权重衰减为0.0005,动量为0.9。
3.2 实验数据集
本文选取来自比利时交通标志数据集——BelgiumTS交通信号数据集(包含62种交通信号)中的交通标志图片进行实验。其中选取BelgiumTSC_Training文件中的1002张作为训练集,并且对数据进行增广处理,选取训练集对应的交通信号类别在BelgiumTSC_Testing中的图片作为测试集。这些图片用软件labelImg[24]来标注,具体标注过程为:在labelImg.exe中打开需要标注的图片,点击Create RectBox按钮,将想要标注的交通标志框起来,再将对应的每一个类别的交通标志命名为合适的英文标签名称,点击保存之后选择下一张图片继续标注。为了保证数据标注的准确性,数据标注任务由2个人完成,每个人标注一半的图片之后检查另一个人标注的图片,如果标注过程中出现了问题便做出及时的修改。labelImg标注图片示例见图10。

图10 标注图片示例
在训练时,刚开始迭代的时候loss值为903.640015,在将近150次的时候loss值降到100以下,250次下降到1.385638,所以在绘制损失函数图时选择从第250之后开始绘图。从图11中可看出,在达到2000次的时候loss值趋于稳定,在0.014上下徘徊,终止训练。

图11 损失函数图
3.3 评价指标
为了分析实验结果,本文选取目标检测中经常使用的平均精度均值(mean Average Precision, mAP)和每秒帧数(Frame Per Second, FPS)来衡量网络的性能。计算公式如下:
(10)
FPS=frameNum/elapsedTime
(11)
其中,AP(Average Precision)为类别平均精度,frameNum为总帧数,elapsedTime为所用的时间。
3.4 实验结果与分析
对比原本的YOLO v4检测结果,从表1可以看出,使用了MSRCR算法进行数据增强之后精确度提高了0.58个百分点,在数据增强处理后,使用改进的YOLO v4算法的精度更是从91.37%提高到了93.23%。从表中前3组实验的结果来看,FPS始终没有太大的变化,并且改进后的YOLO v4与Faster R-CNN和SSD相比在mAP的数值上也有着巨大的优势。可见改进的YOLO v4优于原始的YOLO v4、Faster R-CNN和SSD。改进前和改进后的检测结果对比可见图12~图17。
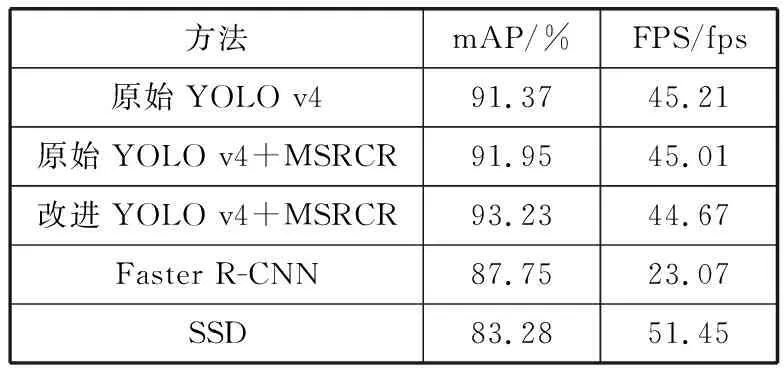
表1 不同网络结构对比表

图12 原始图3使用YOLO v4的检测结果

图13 原始图3使用MSRCR后的算法检测结果

图14 原始图3使用改进后YOLO v4+MSRCR检测结果

图15 原始图4使用YOLO v4的检测结果
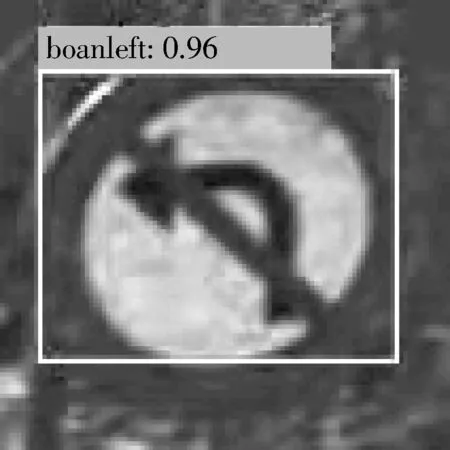
图16 原始图4使用MSRCR后的算法检测结果

图17 原始图4使用改进后YOLO v4+MSRCR检测结果
4 结束语
本文在原有的使用YOLO v4完成目标检测的基础上,在改进了K-means++聚类算法、PANet结构和损失函数的前提下,同时在训练数据集之前使用了加入色彩恢复因子的MSRCR进行数据增强处理。在检测BelgiumTS交通标志数据集光线模糊的图片时,图片检测的平均精确度有了比较明显的上升,说明了使用这种方法的有效性。因为BelgiumTS交通数据集中的交通标志图片都是只有一个交通标志的图片,所以对一张有多种交通标志的图像的检测是进一步要研究的方向,此外还可以对网络结构方面作进一步的改进来提升交通标志检测的效果。
猜你喜欢
中国卫生统计(2022年2期)2022-05-28
汽车实用技术(2022年9期)2022-05-20
矿山测量(2020年2期)2020-05-17
山东煤炭科技(2020年1期)2020-03-06
新教育时代·教师版(2017年30期)2017-09-12
岁月(2016年5期)2016-08-13
小天使·一年级语数英综合(2016年8期)2016-05-14
探测与控制学报(2015年4期)2015-12-15
小天使·一年级语数英综合(2014年7期)2014-06-26
中学生数理化·七年级数学人教版(2008年8期)2008-10-15
