
基于长短期记忆神经网络的容器云队列在线任务动态分配
2022-07-29 06:17徐胜超叶力洪
计算机与现代化 2022年7期
徐胜超,叶力洪
(广州华商学院数据科学学院,广东 广州 511300)
0 引 言
容器云是一种轻量级新型虚拟化技术[1],是云计算的深入和发展。容器云的核心问题是容器在线任务分配,即如何将其中的容器合理、均衡地分配到各个物理机节点上。容器云的出现和使用,极大地缓解了数据处理和运算压力,因此是很多企业内联网服务器的首选。然而,若容器云内部的任务不能被合理分配到可用的资源(物理机节点)上,极易造成个别物理机节点负载过大、能耗过高的问题,对此,众多学者进行了容器云任务分配问题的研究。
文献[2]基于李雅普诺夫函数提出容器云队列任务调度方法,构建云计算任务排队模型,采用李雅普诺夫函数分析任务队列长度的变化;基于任务QoS构建能耗最小化目标函数;通过李雅普诺夫优化方法求解目标函数,实现对容器云队列在线任务的整体调度。但该方法由于并非动态分配任务,寻优能力不足,因此分配合理性和资源均衡度不够理想。文献[3]提出带约束修复的容器云任务队列树形调度目标模型。采用约束修复方法将容器云中的异构任务和异构资源映射为统一向量;采用优先级综合多个子目标并将其归属于不同树形分支下的子空间,构建多任务均衡调度模型,实现容器云队列任务分配。但该方法经过映射构建的任务模型准确性不足,分配合理性较差,且任务队列由于映射需要长时间排队等候,导致拥塞,任务执行效率不佳。
为了解决上述分配方法分配合理性和资源均衡度较差、任务处理效率较低的问题,本文进行基于长短期记忆神经网络(LSTM)的容器云队列在线任务动态分配方法研究。由于长短期记忆神经网络搜索全局性更好,寻优能力更强,本文将其应用到容器云队列在线任务分配当中,求解任务分配最优方案。实验结果表明应用LSTM能使任务分配更加合理、更能节省能耗,减少任务排队长度和时间。
1 基于LSTM的容器云队列在线任务动态分配方法
结合长短期记忆神经网络进行容器云队列在线任务动态分配方法研究,其主要分为4个部分,即容器云队列在线任务模型描述、任务分配目标函数构建、约束条件设置以及长短期记忆神经网络求解,以期保障用户任务的有效执行。
1.1 容器云队列在线任务模型描述
容器云队列是由多个容器组成,而每个容器都代表一个排队模型,由此组成容器云队列,如图1所示[4-6]。

图1 容器云队列在线任务模型
在图1容器云队列在线任务模型中[7],容器队列的长度与网络任务量和容器总量存在密切关系。当单个容器内任务队列长度超过容器总容量时,容器队列长度会超过容器的处理能力,即会发生任务拥堵问题。针对这一问题,需要对容器云队列在线任务进行动态分配,提高任务处理效率[8]。
1.2 任务分配多目标函数构建
容器云队列在线任务动态分配目标函数是指通过分配要实现的目的表达式[9]。求出的这个表达式的解,就是可以满足目标需求的分配方案。基于此,任务分配目标函数构建是重点。
在以往的研究中,多数都是以单一目标为任务构建分配目标函数,虽然在后期,这种方法计算简便,且易求解,但是仅考虑一方面,而忽略其他方面,求出的任务分配方案只能实现一个目的,因此需要求出一个综合最优方案,即考虑多个目标,设置多目标函数[10]。
多目标函数中包括了3个单目标,即节点互补度、资源利用率以及能耗,对这3个目标进行优化可以使得分配方案更加合理[11]。多目标函数具体表达式为:
(1)
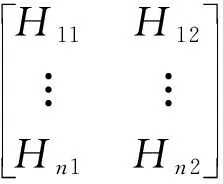
容器和物理机节点之间的资源消耗互补度取决于容器对CPU资源的需求和物理主机拥有资源的量,二者的匹配程度越高,资源消耗互补度越高;资源利用率取决于容器和物理机节点之间的匹配度,可以通过构建容器与物理主机的匹配值矩阵获得最大利用率方案[12]。物理机节点的能耗分为空闲能耗和满载能耗2种情况,两者的区别在于物理机节点的CPU利用率不同[13]。利用率越大,满载能耗越多,空闲能耗越少,有利于节省整体能耗。
1.3 约束条件
由于物理机、容器、时间、费用等资源有限,多目标优化方案的达成需要考虑一些约束条件。约束条件具体包括任务的执行时间约束、物理机节点处理能力约束以及容器分配费用约束。通过这些约束,为目标函数求解划定了范围[14]。具体表达式为:
(2)
式(2)中,Tj、Tj′分别代表物理机节点j开始和结束租赁的时间;T代表任务k执行时间;L0j(k,t)代表t时刻物理机节点j被占用的资源;N代表物理机节点数量;L1j(k,t)代表t时刻物理机节点j剩余可利用资源;ψ代表容器云队列长度;D代表物理机节点处理能力即动态分配能力;ζ代表单容器分配费用;B代表容器分配总执行费用;kN代表任务k需要的物理机节点数量;yjk(t)代表t时刻物理机节点j执行任务k时被占用的资源;m和n分别为容器i和节点j的数量。
为了避免物理机节点资源的浪费,必须保证每个节点都在执行任务,因此物理机节点执行任务结束的时间要大于节点开始执行的时间。当任务较多时,物理机节点被占用的资源要大于节点剩余的可利用资源,让资源充分利用。根据1.1节的容器云队列在线任务模型可知,避免发生任务拥堵问题需要对容器云队列在线任务进行动态分配,容器云队列长度要小于物理机节点处理能力。为了让执行费用的分配更加公平合理,不能让单容器消耗所有费用,因此单容器分配费用需要小于容器分配总执行费用。
1.4 长短期记忆神经网络求解多目标函数
在1.3节设置的约束条件下,利用长短期记忆神经网络对多目标函数进行求解,这是容器云队列在线任务动态分配方法研究的最后一步,也是核心步骤[15]。
与循环神经网络相比,长短期记忆神经网络学习能力更强,其结构模型如图2所示[16]。

图2 长短期记忆神经网络模型
长短期记忆神经网络主要包含3个门,即输入门、遗忘门和输出门[17]。当原始信息通过输入门进入到长短期记忆神经网络模型当中,同时输入给Cell节点和遗忘门。每个Cell节点利用遗传算法计算最佳时间步长、神经网络单元的数量以及单位时间3个参数,优化训练模型;同时原始数据在经过遗忘门筛选后,留下有价值的信息,通过输出门输出[18]。下面针对长短期记忆神经网络中3个门在任务分配多目标函数求解中的具体工作进行分析。
1)输入门。
输入门是信息进入长短期记忆神经网络中唯一的窗口,其作用是赋予容器队列任务分配相关参数进入长短期记忆神经网络的权限以及对输入信息的更新[19]。在任务分配相关参数经过输入门之后,得到结果。
2)遗忘门。
遗忘门是长短期记忆神经网络中核心部分。该部分蕴含了很多过滤规则,用于信息筛选,决定什么信息是有价值的,什么信息应该是丢弃的[20]。在遗忘门中,除了包含1.3节设置的约束条件外,还有一个偏置项,在空间任何维度,都可以进行遗忘门决策。
3)输出门。
输出门是结果输出的窗口,主要是通过将前一状态值、遗忘门概率结果,通过激励函数,输出最终的结果,即容器云队列在线任务动态分配方案[21]。
在利用长短期记忆神经网络求解多目标函数中,有一个关键问题需要解决,即在求解前需要对每个Cell节点设置3个关键参数,即timesteps(时间步长)、units(神经网络单元的数量)、predictsteps(预测多少单位时间)。这3个参数直接关系到长短期记忆神经网络的运行效率和精度[22-24]。在以往运算中,通常需要反复尝试,才能找到一定范围内的最优的参数值,不仅运算量大,速度也慢。针对这种情况,本文通过遗传算法求解这3个参数,以期提高多目标函数的求解精度。具体过程如图3所示。
首先初始化系统,并输入基础数据,进行标准化和数据清洗处理。然后对timesteps、units、predictsteps这3个参数进行编码,设置种群相关参数,将3个参数解码转换成十进制值形式。其次,确定长短期记忆神经网络拓扑结构。接着,将3个参数输入到长短期记忆神经网络中,进行前向运行与反向传播训练。然后,判断训练结果是否满足约束终止条件,若不满足,则继续训练;若满足,计算模型输出值与预期值之间的均方根误差作为适度值,公式为:
(3)
式(3)中,i=1,2,…,n表示反向传播训练次数;YS表示模型输出值;YK表示模型预期值。最后,根据种群规模判断适度值是否满足结束条件,若满足,输出timesteps、units、predictsteps;否则,获得参数编码阶段,进行遗传操作。
通过以上遗传算法的操作[25-27],得出最佳timesteps、units、predictsteps这3个参数,提高了LSTM运行精度,使得求解分配方案更加合理。
2 仿真测试与分析
为测试基于长短期记忆神经网络的方法在容器云队列在线任务动态分配求解中的应用效果,判断求解方案是否可以达到最优,以文献[2]方法和文献[3]方法作为对比方法。整个仿真测试以MATLAB软件作为辅助工具。
2.1 仿真测试环境
方法运行的测试环境为一个容器云平台,平台的软硬件环境参数如表1所示。

表1 实验软硬件环境参数
实验采用真实的维基媒体云计算服务网络任务负载24 h的数据(https://dumps.wikimedia.org/)进行仿真,该数据实时记录了每个小时网络终端用户访问维基媒体云服务的任务数。
为了模拟实际情况中大规模并发场景,在该容器云平台上,依次设置了不同容器数量和物理机节点数量。容器与物理机节点相关参数设置如表2所示。

表2 容器与物理机节点相关参数设置
本文使用的物理机节点数量是根据实际情况中大规模并发场景选取的最常用物理机节点数量。
2.2 LSTM相关参数设置与训练
LSTM求解时,设置的相关参数如下:
•timesteps(时间步长):35;
•units:185;
•predictsteps:50;
•训练精度:0.001;
•LSTM最大迭代次数:1000;
•遗传算法的最大迭代次数:100;
•种群规模:50,100,200,500;
•交叉率:0.52;
•变异率:0.01;
•染色体长度:6+6+8。
借助500个训练集样本对LSTM进行训练。
2.3 评价指标
对求解得出的容器云队列在线任务动态分配方案进行评价的指标有4个,即分配合理性、资源均衡度、最长队列长度以及能耗。
1)分配合理性。
分配合理性ω是指容器分配到物理机节点的方案合理性得分,即多目标优化方案的分配合理性,计算公式如下:
(4)
其中,k代表任务节点。
2)资源均衡度。

(5)
式中:Ei代表容器i对CPU资源的需求;N代表物理机节点数量;D代表物理机节点处理能力即动态分配能力。
表2中已列出了物理机节点处理能力D、单个容器分配执行费用。
3)最长队列长度。
最长队列长度ψmax是指按照分配方案分配后,容器等待分配的队列最长的长度值,计算公式为:
ψmax=(Tj′-Tj)·ψ
(6)
4)能耗值。
能耗值υ是指按照分配方案分配后,物理机节点的能耗值,根据公式(1)~公式(3),计算公式如下:
υ=N(Aj,max-Aj,p)
(7)
式中,Aj,p代表物理机节点j的空闲能耗;Aj,max代表物理机节点j的满载能耗。
其他参数值可参照1.1节、1.2节的内容和表2的数据计算。表2为基础参数设置,本文方法、文献[2]方法和文献[3]方法这3种方法的分配方式不同,因此无法在参数设置中提前赋值公式(1)~公式(4)中的所有参数。
2.4 结果与分析
分别利用本文方法、文献[2]方法和文献[3]方法得出分配方案,然后按照分配方案进行容器云队列在线任务分配到物理机节点上,比较物理机节点相关参数和仿真平台测得的数据,利用上述公式获得3种方法分配方案的物理机节点分配合理性、资源均衡度、最长队列长度以及能耗值,结果如表3所示。

表3 分配合理性、资源均衡度、最长队列长度和能耗值
从表3中可以看出,本文方法求出的分配方案应用下,分配合理性、资源均衡度、最长队列长度以及能耗值表现均要好于其他2种分配方案的应用效果,说明本文方法的分配方案更加合理。这是因为该方法通过长短期记忆神经网络求解任务动态分配目标函数,多目标函数联合应用下,使得云计算效果满足资源调度过程中的任何要求,反应过程更加迅速,分配合理性逐渐扩大,降低了任务阻塞现象,提高了任务处理效率。
3 结束语
本文提出一种基于长短期记忆神经网络的容器云队列在线任务动态分配方法,通过长短期记忆神经网络求解任务动态分配目标函数,逐渐完善分配方案,使得出的分配方案更加合理。然而,本文所使用的容器/物理机数量较少,因此有待扩大容器/物理机数量,在未来的仿真平台中,将对其进行进一步的深入研究。
猜你喜欢
昆钢科技(2022年2期)2022-07-08
中学生数理化·八年级物理人教版(2022年4期)2022-04-26
当代水产(2021年10期)2022-01-12
建材发展导向(2021年23期)2021-03-08
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
读者·校园版(2019年24期)2019-12-10
军营文化天地(2018年2期)2018-12-15
华人时刊(2018年15期)2018-11-10
