
基于YOLO v4的车辆目标检测算法
2022-07-29 06:17殷远齐邢远新
计算机与现代化 2022年7期
殷远齐,徐 源,邢远新
(长安大学信息工程学院,陕西 西安 710064)
0 引 言
车辆目标检测是智能交通的重要组成部分,同时也是目标检测领域的一个重要研究方向。传统的车辆目标检测算法[1]主要分为3类:1)帧间差分法[2],主要是利用视频序列中相邻2帧图片的差分运算结果获取目标,但是该算法需要设置合理的时间间隔,并且对于变化场景效果很差;2)背景差分法[3],主要是利用当前帧的图像与背景模型进行比较得到目标物体,不适用于复杂道路场景的检测;3)光流法[4],主要是利用视频前后帧图像之间像素的差异以及相邻2帧之间的关系来得到物体信息,该方法受光照影响较大且不同场景下的检测效果有较大差距。上述传统方法都存在鲁棒性差、泛化能力弱等缺陷。
近年来,深度学习的飞速发展为计算机视觉领域提供了新的解决方案,目标检测作为计算机视觉的一个重要分支取得了重大进展,针对行人、车辆、交通指示标志等目标进行检测的算法也得到了长足进步。
基于卷积神经网络的目标检测算法主要分为单阶段(one stage)和两阶段(two stage)2类。其中,R-CNN[5]是基于Region Proposal的检测算法,是two stage算法的代表。该方法先利用图像分割算法得到目标候选区域,再通过卷积神经网络对图像进行分类以及回归操作。Fast R-CNN[6]解决了R-CNN提取特征时间过长的问题,但在实际预测过程中候选框的选定依然占用了较多时间。在Fast R-CNN基础上,Faster R-CNN[7]中提出了锚框(anchor)的概念,并且加入了一个区域预测网络,可以直接产生候选区域,提升检测的精度和速度。上述two stage检测方法虽然可以充分提取图像特征,但都存在检测速度过慢的问题。YOLO系列[8-11]算法是端到端的检测算法,是one stage的代表性方法。这类方法直接将目标的分类及定位转化为回归问题,算法速度快,但检测准确率相对two stage算法较低。其中YOLO v4通过对YOLO v3主干特征提取网络、激活函数及损失函数的优化改进,是现阶段精度和速度表现都十分优异的目标检测算法之一。
本文主要研究交通场景中的运动车辆的检测问题,对检测速度有较高要求,所以选用端到端的YOLO系列算法。
使用YOLO系列算法对交通场景中的运动车辆进行检测,存在目标检测精度不高的问题,特别是对遮挡目标及小目标的检测准确率较差。针对该问题,本文提出一种改进的YOLO v4车辆目标检测算法YOLO v4-ASC(YOLO v4-Adam SGDM CBAM)。在CSPDarkNet53特征提取网络的尾端加入卷积块注意力模块(Convolutional Block Attention Module, CBAM)[12],对感兴趣目标特征赋予高权重,侧重提取有用特征信息,以提高模型对特征的表达能力;删除网络预测头(YOLO Head)中的类别信息,减少模型参数,从而减少计算时间。利用Adam+SGDM优化算法调优模型,避免模型陷入局部最优点并且提升模型收敛速度;删除模型分类损失,进一步优化模型。此外,本文利用K-Means聚类算法[13]对目标候选框进行聚类分析,得出更加合理的初始anchor设置。实验结果表明,本文方法获得了更高的检测精度。
1 YOLO v4-ASC
1.1 网络结构
本文的YOLO v4-ASC网络主要包括CSPDarkNet53主干特征提取网络、SPP模块(Spatial Pyramid Pooling Module)[14]、PANet(Path Aggregation Network)[15]、网络预测头YOLO Head和CBAM模块,模型结构如图1所示。
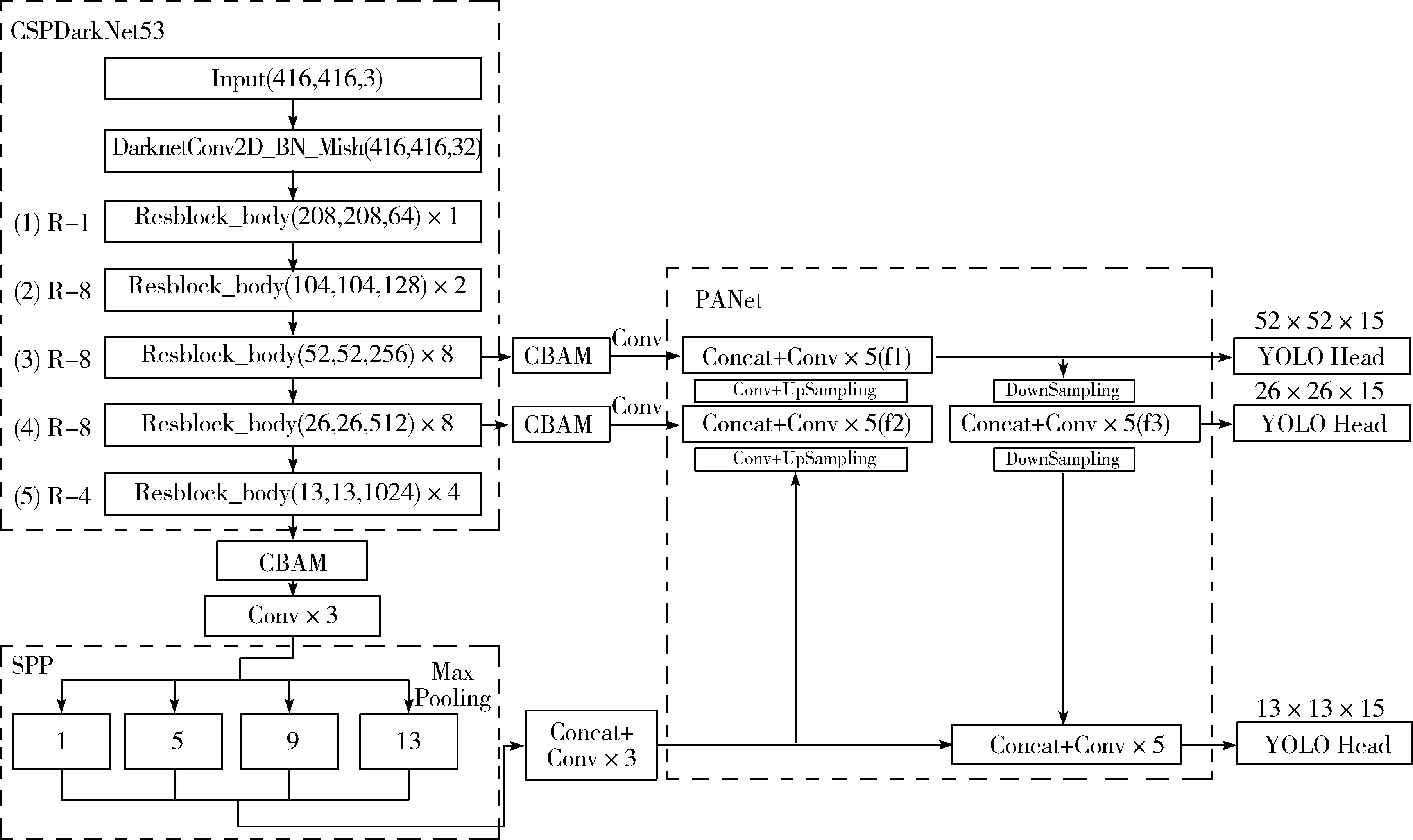
图1 YOLO v4-ASC网络结构图
CSPDarkNet53主干特征提取网络首先对输入的图像进行卷积[16]、批归一化[17]以及Mish函数[18]激活处理,然后经过5个R-n残差模块[19]得到输出特征。SPP模块主要是将CSPDarkNet53网络的输出特征进行4个不同池化核大小的最大池化操作,池化核大小分别为1×1、5×5、9×9、13×13。特征进行池化后进行堆叠得到新特征。上述操作能够有效增加特征的感受野,显著分离上下文特征。PANet主要是将SPP模块的输出特征进行多次上采样并与CSPDarkNet53的输出特征进行融合,提升模型的特征提取能力。在每个检测尺度都会得到一个YOLO Head,主要包括预测框中心点相对于网格单元左上角点的相对位置坐标、预测框的宽高、网格单元中存在目标的置信度以及对应多个目标类别的概率。
因为本文检测目标仅为车辆目标,可通过置信度直接进行判别,所以将3个YOLO Head的输出(13,13,18)、(26,26,18)、(52,52,18)精简为(13,13,15)、(26,26,15)、(52,52,15),从而减少了模型参数。
1.2 CBAM
由于卷积操作对不同特征图的每个通道赋予相同的权重,故缺乏对显著特征的描述能力。CBAM在训练过程中会压缩输入特征图的空间维数,分别通过通道注意力和空间注意力2个方面增强特征图中的有用特征。本文在CSPDarkNet53的3个输出后加入CBAM,以更精准地提取特征信息,弱化不感兴趣的特征信息,从而提升检测准确性。CBAM结构图如图2所示,其中⊗代表逐元素相乘。输入特征图F经过通道注意力模块(Channel Attention Module, CAM)得到注意力特征图Mc,将Mc和F做逐元素相乘操作,生成F′;F′再经过SAM模块得到空间注意力特征图Ms,最后将Ms和输入特征F′做逐元素相乘,生成特征F″。
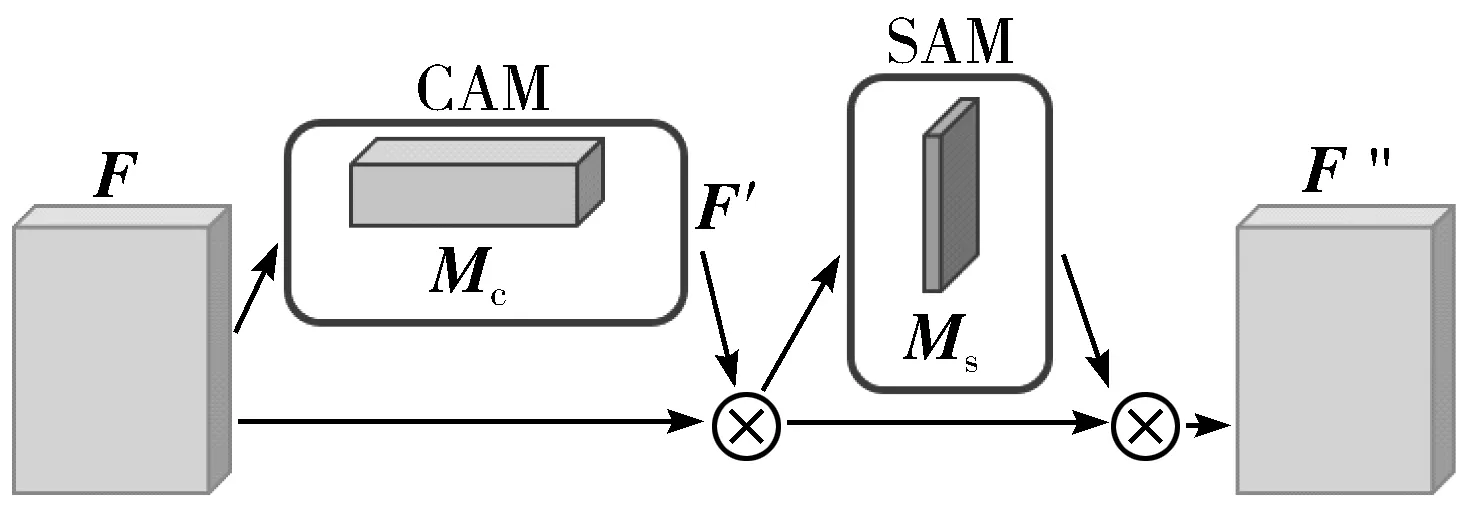
图2 CBAM结构图
CAM结构如图3所示。将输入的特征图F,分别经过全局最大池化(Global Max Pooling, GMP)[20]和全局平均池化(Global Average Pooling, GAP)[21],然后经过多层感知器(Multi Layer Perception, MLP)[22],将MLP的输出进行逐元素相乘并相加,再经过激活操作生成通道注意力特征图Mc。即:
Mc=σ(MLP(GAP(F))+MLP(GMP(F)))
(1)
其中,σ代表激活操作。

图3 CAM结构图
SAM结构如图4所示。将F′做基于通道的GMP和GAP操作,然后将这2个结果基于通道数做连接操作,再通过卷积操作,将通道数降为1,最后经过激活操作生成空间注意力特征图Ms。即:
Ms=σ(f7×7([GAP(F);GMP(F)]))
(2)
其中,f7×7代表7×7卷积。
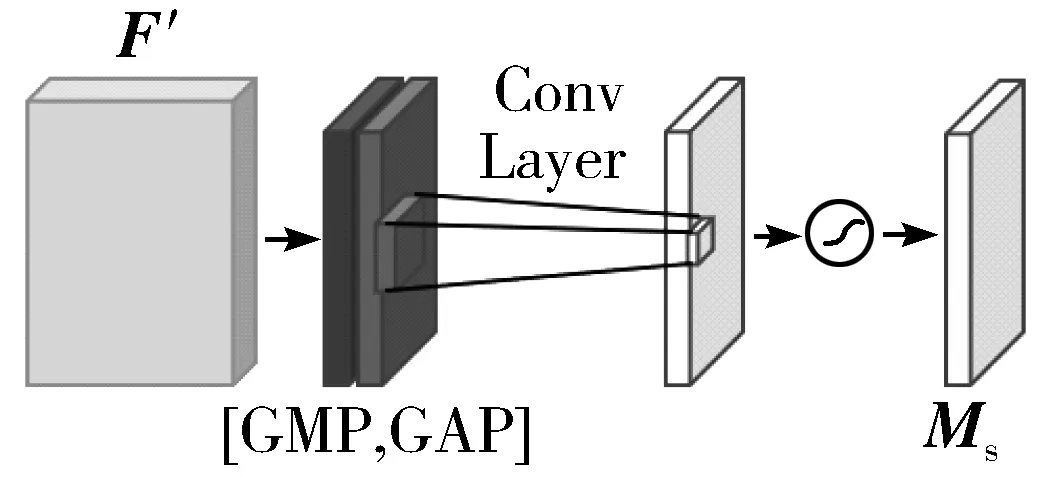
图4 SAM结构图
1.3 优化方法及损失函数改进
1.3.1 优化方法改进
YOLO v4的模型在训练过程中使用的优化方法是动量梯度下降法(Stochastic Gradient Descent with Momentum, SGDM)[23],是在随机梯度下降法(Stochastic Gradient Descent, SGD)[24]基础上加入了一阶动量。虽然SGDM优化效果较好,但是存在着前期优化速度过慢的问题,不利于快速收敛且容易陷入局部最优点。自适应矩估计(Adaptive Moment Estimation, Adam)[25]优化算法收敛速度较快,但是在训练后期会出现学习率太低,影响模型达到最优的问题。基于此,本文将两者结合,使用Adam+SGDM的优化方法,在训练前期使用Adam使模型快速收敛,后期使用SGDM调优模型参数,得到更优模型。
1.3.2 损失函数改进
YOLO v4的损失主要由3个部分组成:置信度损失Lconf、回归损失Lciou和分类损失Lcls。本文基于行车场景,车辆目标可以视作同种类别,所以本文将问题简化为目标和背景的二分类问题。因此,本文损失不包含分类损失,新的损失函数具体表示为:
Loss=Lciou+Lconf
(3)
(4)
(5)
(6)
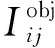
2 实验与结果分析
本文实验配置为操作系统Windows10,CPU型号Intel(R)Core(TM)i7-10700K @3.80 GHz,RAM内存大小为32 GB,显卡型号NVDIA GeForce RTX 3070,CUDA版本为11.1.1,使用Pycharm2021.2、Python3.7搭配Pytorch1.9.0(GPU)框架进行实验。
2.1 数据集及评价指标
2.1.1 数据集
BDD100K是目前发布的最大规模的自动驾驶数据集之一[28],该数据集包括晴天、雨天、白天及黑夜等多种场景中采集的图像样本。本文提取不同场景的样本共4000张,训练集、测试集和验证集的比例为8∶1∶1。提取出truck、car、bus标签对应的数据组成新的数据集BDD100K-Vehicle,其中数据集目标真值共计43661个,平均每张图像含有约11个目标,数据集部分样本如图5所示。

图5 数据集部分样本示例
2.1.2 评价指标
针对车辆目标检测问题,本文主要使用平均检测精度(Average Precision, AP)、每秒的传输帧数(Frame Per Second, FPS)及常用于二分类问题的衡量标准F1-score对检测结果进行评价。AP和F1-score结果与准确率(Precision, P)以及召回率(Recall, R)数值相关。
(7)
(8)
(9)
其中,TP(True Positive)表示正样本被预测为正样本的数量,FP(False Positive)表示负样本被预测为正样本的数量,FN(False Negative)表示正样本被预测为负样本的数量。以P和R分别为坐标轴建立坐标系,AP即为P-R曲线所围成的面积。
2.2 模型训练
2.2.1 anchor优化
YOLO v4中使用9个锚框(anchor)预测3个不同尺度大小的Bounding Box,Bounding Box的准确度影响最终的目标检测结果。原anchor的尺寸和数据集中目标的尺寸差异较大会导致检测模型的精度不高,而K-Means算法可以通过找寻聚类中心的方式得出合理的anchor位置信息。所以本文使用K-Means算法优化先验框尺寸大小。使用K-Means算法预测不同anchor数的目标检测准确率和参数量结果如表1所示。

表1 不同anchor数结果对比
由表1可以看出,anchor数为9时模型参数量较低且AP值最高,达到了70.05%,结合预测的Bounding Box数量及YOLO Head数量,最终确定anchor数目为9。通过K-Means算法对数据集中的车辆进行聚类,得出9个大小尺寸不同的anchor,其大小分别为(3,6)、(4,12)、(6,24)、(7,8)、(10,14)、(13,23)、(24,32)、(42,57)、(91,127)。
2.2.2 损失函数优化
本文对YOLO v4中的损失函数进行优化,模型优化方法使用SGDM,将训练损失绘制成loss曲线,实验结果如图6所示。

图6 不同损失函数对比结果图
从图6可以看出,与原损失函数曲线相比,优化后的损失函数曲线下降速率加快,并且在第150个epoch时loss曲线斜率趋于稳定,此时模型已经收敛。实验证明,损失函数优化后网络模型的收敛速度有所提升。
2.2.3 模型优化
分别采用SGDM、Adam、Adam+SGDM等3种不同优化方法对模型进行训练。首先将图像尺寸缩放为416×416,优化方法中动量(momentum)参数设置为0.9,权重衰减(weight decay)参数设置为0.0005,初始学习率设置为0.001。Adam+SGDM在训练的前50个epoch使用Adam优化方法快速降低损失,防止陷入局部最优点。之后将优化方法调整为SGDM,同时将学习率调整为0.01,且每经过5个epoch令其学习率变为原来的9/10,继续训练使模型达到最优。
训练损失(train loss)是训练过程中模型是否收敛的一个重要指数。模型损失越小,精度就越高,同时检测准确率也就越高。将不同优化方法的train loss绘制成loss曲线,结果如图7所示。

(a) 训练损失图
图7(a)为3种不同优化方法下得到的损失函数曲线,其中SGDM最终损失为3.45,Adam最终损失为1.72,Adam+SGDM最终损失为1.45。图7(b)显示的是图7(a)中的方框区域,可以更加直观地显示Adam+SGDM优化算法相较于其它2种优化方法的优势,第50至150 epoch的结果显示,在损失降到区间(1,2)时,Adam+SGDM仍比Adam低0.27,实验证明本文改进方法有明显提升。
2.3 不同优化方法对比
本文对使用不同优化方法的YOLO v4进行对比实验,置信度阈值设置为0.5,非极大值抑制[29]阈值设置为0.3。预测框与目标真实框的IoU阈值设置为0.5,当IoU值大于该阈值时判定为正确预测到目标所在的位置,实验结果如表2所示。
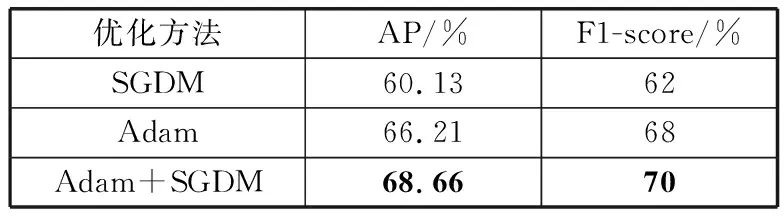
表2 不同优化方法结果对比
由表2可以看出,使用Adam+SGDM优化方法比使用SGDM优化方法的AP高8.53个百分点,F1-score高8个百分点;比使用Adam优化方法的AP高2.45个百分点,F1-score高2个百分点。
2.4 注意力模型对比
为了验证卷积注意力模块的有效性,将本文算法分别与未加入注意力机制的算法及加入SE[30]注意力机制的算法进行对比,将仅使用Adam+SGDM优化方法的YOLO v4记为YOLO v4-AS(YOLO v4-Adam SGDM),同时置信度阈值设置为0.5,非极大值抑制阈值设置为0.3,实验结果如表3所示。为更加直观地展示对比实验结果,将实验结果绘制成AP曲线,如图8所示。
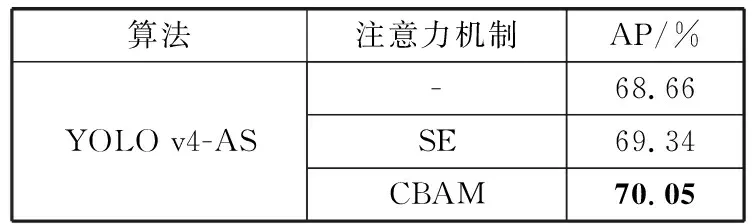
表3 注意力模型结果对比
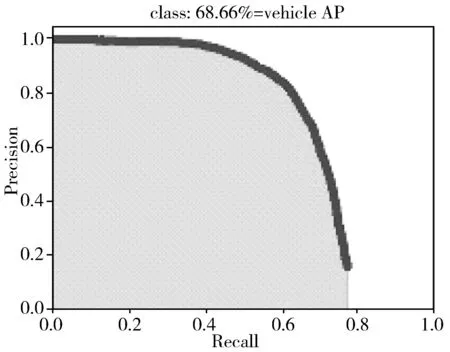
(a) YOLO v4-AS
图8(a)、图8(b)、图8(c)分别为YOLO-AS实验结果图、加入SE的实验结果图、加入CBAM的实验结果图。可以看出,与YOLO v4-AS相比,加入SE后AP提升了0.68个百分点,在YOLO v4-AS基础上加入CBAM后AP较YOLO v4-AS提升了1.39个百分点,较加入SE的YOLO v4-AS提升了0.71个百分点。上述实验结果表明,加入CBAM后算法检测精确度有所提升。
2.5 不同模型对比
为了验证本文提出模型的有效性,将本文算法分别与YOLO v4-tiny、YOLO v4、Faster R-CNN以及SSD[31]检测算法进行对比。置信度阈值设置为0.5,非极大值抑制阈值设置为0.3,实验结果如表4所示。
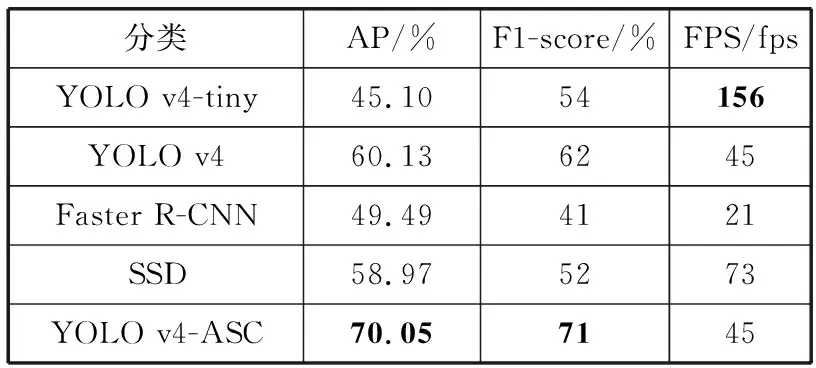
表4 不同模型结果对比
由表4可以看出,在检测精度方面,本文算法与2种轻量化算法SSD及YOLO v4-tiny相比,AP分别提升了11.08个百分点和24.95个百分点;F1-score分别提升了19个百分点和17个百分点;与Faster R-CNN及YOLO v4相比,AP分别提升了20.56个百分点和9.92个百分点;F1-score分别提升了30个百分点和9个百分点。虽然FPS不如YOLO v4-tiny和SSD这2种轻量级算法,但是本文算法的FPS达到了45,可以满足车辆目标检测的实时性要求。
使用YOLO v4-tiny、Faster R-CNN、SSD、YOLO v4及本文算法分别对数据集中不同天气不同场景下的目标进行检测,结果如图9所示。其中预测框中包含目标类别信息及置信度分数信息。可以看出,YOLO v4-tiny的检测结果受光照交通场景影响最严重,目标检测效果最差;使用Faster R-CNN得到的结果出现了对同一目标重复检测及目标错检的问题;使用SSD得到的结果虽然优于Faster R-CNN,但也存在部分目标漏检的问题;使用YOLO v4得到的结果改正了SSD的漏检问题,但同时存在对小目标的检测效果较差且置信度分数较低的问题。YOLO v4-ASC对于场景中的目标均能准确识别和定位,能够不受光照变化及场景变换的影响,有效解决小目标和部分遮挡目标的漏检及错检问题,而且置信度分数相较于其它算法更高。

(a) 原图
以上实验结果表明,本文算法在保证较高检测速度的同时,有效提高了目标准确率。
3 结束语
本文基于YOLO v4目标检测算法提出了一种YOLO v4-ASC算法。在YOLO v4网络结构中加入CBAM模块,使特征提取网络更加关注感兴趣目标,增强模型的特征表达能力;简化了损失函数,提高算法运行速度以及模型收敛速度;改进了模型优化算法,提高模型检测精度;使用K-Means聚类算法对数据进行聚类,得到更加合理的预设anchor尺寸。最终实验结果表明,本文算法在数据集上达到了70.05%的平均检测精度,检测速度达到了45 fps,可以满足实时检测要求。
后续工作也将围绕降低模型大小以及提升检测速度等方向展开,不断提高模型的泛化能力,提升模型在复杂场景中的性能。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
房地产导刊(2022年5期)2022-06-01
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
建材发展导向(2021年12期)2021-07-22
数学小灵通·3-4年级(2021年5期)2021-07-16
建材发展导向(2021年7期)2021-07-16
中学生数理化(高中版.高二数学)(2021年12期)2021-04-26
当代陕西(2019年10期)2019-06-03
今日农业(2019年15期)2019-01-03
共产党员(辽宁)(2015年2期)2015-12-06
