
融合用户兴趣和评论文本主题挖掘的推荐算法研究
2022-07-27 01:45丁丽,方晓
青海师范大学学报(自然科学版) 2022年1期
丁 丽,方 晓
(亳州职业技术学院 信息工程系,安徽 亳州 236800)
1 引言
随着大数据技术在各领域中的应用,尤其是互联网企业对数据利用程度越来越高,数据在企业生产中的作用不可替代,数据效用和价值得到充分的提升.项目推荐是大数据技术应用的主要领域,也是促进推荐算法研究与发展的动力.传统推荐算法思想则是根据历史数据对用户-项目二维关系进行评分,计算用户与项目兴趣度,推荐商品和服务.推荐系统中的数据稀疏性[1]和冷启动两大问题是本领域研究困难所在,协同过滤算法的并没有解决好这两大问题.
LFM是目前协同过滤推荐算法最常用的,LFM算法思想是通过矩阵分解(MF)和奇异值(SVD)方法降维来获得隐性数据特征,精确并提高用户对项目的评分,但推荐精度不是很理想.目前传统的信息推荐模型很难解决两个问题,一是用户的偏好是动态变化的,而用户模型很难改变;二是对异常数据的处理能力不足,例如错误偏好、恶意评价、特殊用户和物品.通过增加用户-项目的边缘信息方法优化信息推行模型,提升了模型对用户-项目的数据抽象能力,提高推荐的多样性.
用户行为数据作为推荐依据,用户喜好来自用户行为数据的分析计算,用户的喜好能够反映用户的兴趣特征.因此得到许多研究者的关注,用户的喜好主要在用户源标签和评论文本上体现,再之评论文本是解决评分数据稀疏的有效方法.因此挖掘用户产生的文本数据来提高推荐系统的精确性具有理论意义和应用价值,然而对用户产生评论文本的建模和有效融合评分矩阵是该类推算法的难点问题.
因此,本文提出一种用户兴趣特征算法,融合用户源兴趣标签和文本评论兴趣.本文主要的贡献如下:
(1)总结了传统的协同过滤算法的核心思想,对基于用户的协同过滤算法和基于项目的协同过滤算法的评分机制进行了数学表达.
(2)提出了基于用户兴趣特征的推荐算法UICTM,从构建用户兴趣特征集出发,用户兴趣分为用户标签兴趣和文本评论兴趣,利用TransR模型计算用户标签兴趣的相似度,而评论文本兴趣TMF分为用户评论文本兴趣和项目评论文本兴趣.UIFT是对用户行为产生的文件进行LDA分析,挖掘潜在主题,并且与矩阵分解的潜在因子相关联,并求解相关参数.
(3)优化了UIFT模型,引入了时间的因素,通过窗口期机制对评论文本实行不同的权重分配,得到UIFT+模型.
2 相关工作
2.1 推荐系统的形式化描述
在一个推荐系统中,项目集合I={i1,i2,…,in}和用户集合U={u1,u2,…,um},公式F计算用户ub∈U对于一个项目i∈I的偏好程度,即F:U×I→R,其中R为推荐的项目集合.目标是对于任意用户ub∈U,通过推荐算法得到推荐项目集合R(ub),如式(1):
(1)
2.2 协同过滤算法CF
协同过滤算法核心思想是:利用用户在系统中的历史行为数据,运用模型计算用户或项目的相似集合,将其项目推荐给用户.假设目标用户ub,利用用户的历史行为数据即用户对项目的评分矩阵,通过模型找到Top-n个相似度最高的项目推荐给用户ub.CF包括UBCF和IBCF两种协同过滤算法[2-5].
2.2.1 基于用户的协同过滤算法UBCF
UBCF算法原理是:在评分矩阵的基础上,找到与用户ub相近的用户集合Nub,用户相似度越高,表示两用户越相近.用户相似度计算方法有三种,表示如下:
(1)通过余弦求解用户ub与ud的相似度sim(ub,ud)[6],如公式(2):
(2)
其中:αub,αud分别表示m维对象空间上的评分向量.
(2)通过相关性求解用户ub与ud的相似度sim(ub,ud),如公式(3):
(3)
(3)在式(3)求解用户ub和用户ud之间的相似度时,没有统一的评分标准,导致喜好程度相同评分值不同的现象,为了修正缺陷,对用户的相似度进行微调,如式(4)[7]:
(4)
其中Iub和Iud分别为用户ub和用户ud评分的项目.
计算用户相似度来求解得到用户ub相邻的用户集合Nub,则用户ub对项目ik的预测评分Pub,ik可表示为式(5):
(5)

利用上述式(4)和式(5),对用户ub的未评分项目进行评分.依据评分的高低,从而找出Top-n推荐项目集.
2.2.2 基于项目的协同过滤算法IBCF
IBCF与UBCF相似,IBCF的核心思想是在用户对项目评分矩阵的基础上,找到项目it的相似项目集合Nit[8],然后计算当前用户ub对项目it的预测评分,找到Top-n的推荐项目集合[8-9].
用户ub对项目it的预测评分pub,it如式(6)
(6)

综上可以得到,传统的协同过滤算法适合与复杂非结构化的项目推荐;对内容异构度高的项目有很好的适应性,善于发现新的兴趣点,但是在数据稀疏和冷启动问题上没有很好解决.用户-项目评分矩阵是协同过滤算法的基础,数据稀疏以及新用户加入时,导致没有评分数据情况下,利用推荐算法得到的项目集是不精确的.
3 基于兴趣特征的推荐算法
3.1 算法的思想
用户是有兴趣特征即用户的偏好,而项目有它的属性特征.当用户的兴趣特征与项目的属性特征相匹配时,用户对此项目的偏好就会加强.在一个推荐系统中,用户的兴趣特征是由标签兴趣和评价文本的潜在兴趣特征所组成的.项目的属性特征是由描述项目的文档所表示,并在不同的上下文中,表示的语义不同.如何获取用户的潜在兴趣特征和项目的潜在属性特征是关键问题[10].
融合用户兴趣和评论文本主题挖掘的推荐算法UICTM分成三个步骤:
Setp1:利用TransR从用户的标签兴趣分析用户核心兴趣.
Setp2:对评论文本的主题挖掘并映射到评分矩阵中,然后进行预测评分.
Setp3:将预测评分与用户核心兴趣相组合,得到Top-n的推荐集合.
先定义数学符号,如表1所示:

表1 模型数学符号定义
3.2 算法的模型
详细介绍本文提出的模型UICTM.算法包括用户标签兴趣提取网络Nut和用户评论提取网络Nuc以及用户兴趣特征网络Nut-uc,Nut和Nuc分别负责对用户标签兴趣和用户评论文本特征进行提取.而Nut-uc是对Nut和Nuc的融合.
在一般的推荐系统中,用户在使用系统之前,需进行注册用户信息,标注用户在本系统中各个应用域的兴趣点,本文中称为源标签兴趣RIP.源标签兴趣RIP不一定能够反映用户的核心标签兴趣CIP,其主要原因有:
(1)推荐系统中给出的兴趣点细分隶属度不够.导致用户的RIP和CIP的相关度R(RIP,CIP)不强.
(2)推荐系统中随时间变化,用户的CIP得到迁移,即NIP.使得R(CIP,NIP)的值变大.
用户标签兴趣提取网络Nut模型的数学表达:
(7)
3.2.1 用户标签兴趣提取Nut模型
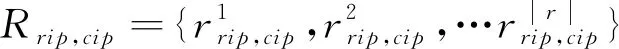
由于三元组有很强的表达能力,但是在数据稀疏、鲁棒性等问题中表现不足.因此我们将关系三元组用低维稠密的向量表示,从而语义相近的实体可以用向量表示,即可在低维度进行实体相似度计算.
利用TransR模型对三元的RIP和CIP用n维向量表示为VRIP和VCIP,关系用m维向量表示为VRrip,cip.对于三元组G={RIP,Rrip,cip,CIP},首先将n维度的VRIPVCIP运用投射矩阵Tn×m投影到m维空间,得到关系空间的m维实体VRIPm和VCIPm,.通过TransR模型得到公式:
VRIPm=VRIP×Tn×m
(8)
VCIPm=VCIP×Tn×m
(9)
同时得到他们的相似度:
f(VRIPm,VCIPm)=‖VRIPm+VRrip,cip-VCIPm‖
(10)
3.2.2 文本评论兴趣提取Nuc模型
(1)LDA模型
文本分析中概率生成模型LDA的核心思想是一种实现降维的技术算法,在高维空间中,对每个文本评论实现投影,出现许多重复的区域.通过标注来实现降维,减少重复区域,增加各类别内部的聚合,减少类别之间的距离和区分[11].
结合本文,设定在S维空间中,文本评论数据d实现降维,降维到L(S>L)维中,L为文本评论的主题数,利用概论方法计算文本评论数据d的l维主题分布,把文本评论数据集d视为由Nd各词w组成的序列[12-14].具体算法步骤为:
Setp1:计算每个主题的分布φl,即表示主题单词φl属于主题l的可能性.
Setp2:计算文档d中每个单词w在l上的分布主题Zd,l.
Step3:计算文档d在主题l上的主题分布φd,l.
Setp4:计算文本评论数据集D在主题l上的分布ρl(D/θ,φ),参见式(11):
(11)
(2)TMF模型
文本评论分为融合用户文本评论和融合项目文本评论,FTC是把某一个项目的所有文本评论组合一个文档,并作为主题发现模型的文本集[11],从中发现项目属性特征的分布.TMF模型把一个用户的所有评论组合一个文本集合,进行挖掘分析潜在主题分布δ,并与pi或qj映射.我们从文献[11]中分析得到,评分矩阵潜在因子数目与评论文本的因子数目相同,假设为L,并且潜在因子间的权重相同时,评分矩阵的潜在因子与文本评论的主题具有相关性参见式(12).
(12)
式(12)中,δi,l表示项目i潜在特征l上的主题,pi,l表示项目i潜在因子向量在特征l上的值,α为两者相关性控制系数.

(13)
其中:θi和θj分别为用户和项目的偏置量,pi和qj分别为用户i和项目j在l维潜在的特征向量,θg为全局偏置量.
TMF模型中式(12)是评分矩阵的潜在因子与文本评论主题的对应关系,TMF模型不需要对参数δ和p进行同时拟合,TMF优化的目标函数参见式(14):
(14)

(3)UIFT模型
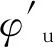
(15)
(16)

(17)
(18)
(19)
将式(17),(18)代入式(19)得到最小目标函数公式(20).

(20)
其中:Ω={χ,θi,θj,pi,qj},Θ={δ,δ′,s′,s}表示共同训练参数集Ω和Θ.在式(20)中无法求解Ω和Θ,运用梯度下降法对式(18)进行变换得到公式(21):
(21)
(4)UIFT+模型
用户的兴趣随时间变化发生改变,从一个时间窗口期分析,兴趣是稳定的.用户当前评论和打分能够反映当前时间窗口期的兴趣和爱好,间隔期越长,用户的评论反应当前的兴趣程度越低.
本文设置wu用户文本评论主题的正则项权重,wI项目文本评论的主题的正则项权重.用户的评分受到两个因素的制约,一个是项目的历史评价的影响,另一个用户自身偏好影响.wu权重和时间窗口期是相关的,因此用户文本评价集合Cu按照时间的窗口期T={t1,t2…tl}.Cu的分割长度为l,最小为1,即ti(t1,t2,…tl),设窗口期大小2l-1,可表示为
win(ti)={ti-l+1,…,ti-1,ti,ti+1,…ti+l-1}
(22)
当i=1和i=l时可得
win(ti)={ti,ti+1…ti+l-1}
(23)
win(ti)={ti-l+1,…ti-1,ti}
(24)
由式(23)和(24).将用户文本评价集合动态划分为Cu={Ci-l+1,…,Ci,…,Ci+l-1},通过LDA主题分析得到各窗口期的用户文本评价集合权重分别表示为wu={wu1,wu2…wuL},并对式(18)加以改进可得:
(25)
wu是由式(24)计算得到:
(26)
Lo(Cu,t)、Cu,t、Nc,u分别表示用户u在时间窗口期t的位置和评价文本以及文本数.∂为调节系数.
同理由式(17)得到:
(27)
用户评论文本数目Nc,u和项目评论文本数目Nc′,i与设置阈值a的关系如式(28):
(28)
3.3 UICTM算法分析
UICTM模型是融合了用户兴趣提取模型Nut和评论文本模型Nuc的双模态推荐算法,数学表达式为:
ηi=(1-k)ηNut+kηNuc
(29)
其中:ηNut为用户兴趣标签主题的相似度,ηNuc为评论文本主题的相似度,则文本评论与主题相似概率为pi,c,公式如下:
(30)
w为引入的权重,分别将公式(10)和公式(27)代入可得公式(31)
(31)
双模态推荐模型融合的关键是对不同模态的推荐结果赋予各自的权重,按照一定的规则标准计算各自的权重,权重来自输入数据与推荐结果的相关性.根据上述分析,按照以下步骤确定权重w.
步骤一:确定加权矩阵
(32)
其中:pi,j是第i模态推荐模型对第j个文本主题的相似概率,c为文本主题数.因此得到加权矩阵为:
(33)
其中:wi是第i中模态推荐模型的加权矩阵.

(34)
步骤三:依据最大值规则选取第k各文本主题为最终推荐概率,公式(35)所示:
(35)
其中:L为文本主题数目.
4 仿真实验
4.1 实验数据
通过python爬取亚马逊商品信息作为数据集,详细数据如表2所示,数据集80%为训练数据集,20%为测试数据集.

表2 实验数据集明细
数据集中包括字段有:商品标识、商品名称、时间、价格、用户标识、用户名、评论文本、兴趣标签词、评分、评论标题.
4.2 评估方法
推荐系统的常用评估方法是均方误差(MSE),在相关文献中还有均方根误差(RMSE)、平均绝对值误差(MAE),通过公式分析三种方法的评估结果具有同向性[12-14].均方误差(MSE)计算如式(36):
(36)
其中:Ω为测试样本集合,|Ω|为测试样本容量.
MSE反映推荐系统的质量,MSE值越小推荐质量越优.
预测评分与实际评分的一致的数目也是反映推荐系统质量的重要指标.作为本实验室的第二指标.定义推荐系统的准确度ACC计算如式(37)
(37)
其中:|Ω′|为测试样本中预测评分与实际评分一致性值,|Ω|为测试样本容量.
4.3 模型对比分析
下面对本文的FTC+模型与传统的推荐模型进行对比分析:
(1)CF推荐,是传统的协同过滤算法,计算用户的相似度或者是物品的相似度,对相似度的排序找到Top-n的相似对象,依据对象的喜好,推荐给相似对象的方法.
(2)TMF推荐,是本文中提出,将用户所有文本评论组合一个文档,得到主题建模和矩阵分解的潜在因子,构建推荐模型.
(3)UITF推荐,是本文提出,将项目文本评论和用户文本评论分别进行主题建模和矩阵分解的潜在因子,并进行相融合再进行构建推荐模型.
(4)UITF+模型推荐,是在UTF的基础上,参考时间因素,引入权重因子,进行构建推荐模型.
4.4 参数选择与实验分析
在给定的条件下,文本主题数L选取不同的值(L=6,L=12,L=24等).观察MSE和ACC的变化,如表3和表4:

表3 各算法在不同主题数下的均方误差MSE
4.4.1 实验1推荐准确度
表4统计出4个推荐算法在不同数目主题下ACC值.分析得到如下结论:

表4 各算法在不同主题数下的准确率ACC(%)
(1)UICTM极大地提高推荐质量,与TMF相比平均值减少9.79%,UITF+与UITF相比平均值减少2.72%.
(2)主题数在L=24和L=48下各推荐算法MSE值有明显增大,TMF变化-6.82%,UICTM变化-0.92%.
(3)基于项目评论文本融合用户评论文本的推荐模型UITF推荐质量优于基于用户评论文本的推荐模型TMF,且融合文本的推荐模型UITF和TMF两个模型都优于传统的CF模型.
(4)表5是各推荐模型在8类数据子集上的准确度ACC和MSE(L=6).

表5 8组数据子集下的预测准确度ACC和均方误差MSE(L=6)
统计得到,各推荐模型在母婴数据子集准确度最高且稳定.融合文本评论和用户兴趣的UICTM推荐模型在8类数据子集上最优.
4.4.2 实验2各推荐模型训练时间分析
本实验随机选择了母婴产品子类数据集作为各推荐模型的输入,分别得到TMF、UITF、UITF+和UICTM模型训练时间,如图1所示,其中L(L=6,L=12,L=24)表示潜在因子数量.

图1 母婴数据子集各模型训练时间
图1随着潜在因子数量L的增加,各模型训练时间都明显增长,各个模型训练时间趋势线指数增长明显,在实验1中各模型在母婴数据集上的推荐准确度较稳定,所以实验2选择L=6.UIMF和UIMF+在训练时间成本上比TMF更多,从实验1的结果可知,UIMF和UIMF+的推荐准确度高于TMF.融合文本评论和用户兴趣的UICTM模型训练时间成本最多,模型训练是系统应用的离线处理过程.因此,将UICTM模型应用在推荐系统中是可行的.
4.4.3 实验3 UICIM模型实验分析
本实验选取母婴产品数据子集作为输入,分别对式(31)中调节参数w取不同的值,观察UICTM(MSE)和UICTM(ACC)发生的变化.如图2和图3所示:

图2 母婴产品数据子集上MSE和ACC指标分析1

图3 母婴产品数据子集上MSE和ACC指标分析2
从图2得到在MSE和ACC指标UICTM上相对与UITF+分别降低0.006152和0.034341.
从图3得到在MSE指标UICTM上相对与UITF+降低0.012355,在ACC指标上UICTM相对与UITF+提升0.034341.
4.5 相关讨论
(1)数据集有8个数据子集,考虑到不同种类数据集属性对模型的推荐指标的影响,分别分析了各类数据集ACC和MSE在文本分类主题L=6条件下的变化.结果表明各模型在服装产品数据子集上推荐质量较低(见图4和图5),ACC和MSE的平均值分别为0.33875和0.36925.UICTM模型在书籍、音乐、食物和手机产品四个数据子集中推荐准确度ACC分别为0.683、0.674、0.524和0.769,整体表现优于其他推荐算法模型.

图4 四个子集上MSE变化

图5 四个子集上ACC变化
(2)评论文本的主题分析,从项目和用户两个维度进行LDA主题建模.
用UITF 算法模型将两者进行融合.考虑到时间因素对推荐质量的影响.把时间序列加入其中,改进UITF模型即UITF+模型.评论文本主题数L分别取值不同(L=6、L=12、L=24、L=48、L=96)时,UITF+在UITF模型基础上推荐度ACC分别提升0.87%,1.66%,-9.09%,1.52%和3.56%,UITF+整体上优于UITF;UICTM是在UITF+上融合用户兴趣Nut模型,UICTM在UITF+模型基础上推荐度ACC分别提升2.40%,5.07%,12.72%,2.71%和-12.17%,UICTM整体上优于UITF+.
5 总结
本文提出基于评论文本分析的推荐模型UITF和UITF+,UITF是将用户评论文本和项目评论文本同时与矩阵分解潜在因子相融合,UITF+是将时间因素引入推荐模型中,UICTM是进一步融合用户兴趣,对其语义上相似度进行计算,将结果引入推荐模型UITF+中.从实验中,模型对比结果表明UITF、UITF+和UICTM整体由于TMF和MSE指标上减少0.058、0.0829和0.0892,ACC指标上提升0.0741、0.0382和0.0634.并且对各类实验数据子集进行比较,整体表现良好,局部不稳定.
本文是针对用户行为中的评论文本和兴趣进行分析建立推荐模型的,今后的研究要考虑到用户的社交关系以及用户的特征分析.将上下文评论中情感因素考虑其中,提升推荐模型质量.
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
昆明医科大学学报(2022年3期)2022-04-19
昆明医科大学学报(2022年2期)2022-03-29
小学生学习指导(低年级)(2021年12期)2021-12-31
小学生优秀作文(低年级)(2020年5期)2020-07-25
甘肃教育(2020年8期)2020-06-11
艺术评论(2020年3期)2020-02-06
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
