
基于高阶深层时空信息的自媒体视频质量评价
2022-07-22 13:36刘银豪王鸿奎周晓飞殷海兵
信号处理 2022年6期
刘银豪 张 威 王鸿奎 周晓飞 殷海兵
(1.杭州电子科技大学通信工程学院,浙江杭州 310018;2.杭州电子科技大学自动化学院,浙江杭州 310018)
1 引言
随着移动多媒体设备的发展和视频社交媒体平台的普及,普通用户有更多机会自主创作内容。然而,由于摄影环境和设备的限制,用户自主拍摄的自媒体视频往往不可避免地引入各种拍摄失真,例如失焦、运动模糊、相机抖动或曝光不足/过度、传感器噪音、恶劣天气影响等。这些失真严重降低了消费者的视觉体验。在这种情况下,视频分发平台需要有效感知用户体验并适时采用一定的视频处理算法进行改善。由此,作为感知衡量标准的视频质量评价研究成为研究热点。其应用场景丰富,首先,平台方需要对自媒体视频内容进行准确可靠的感知质量预测,以此作为各种预处理及视频增强的算法的介入时机判断标准。此外,利用质量评价判断出视频的拍摄水平,可以辅助视频分发平台进行推荐排名。最后,自媒体视频质量模型可以作为视频增强技术的优化标准,通过量化提升视频质量来帮助视频制作者改善作品观感。
在过去的几年里,有较多的研究专注于NRIQA[1-2](No Reference-Image quality assessment)和NRVQA[3-4](No Reference-Video quality assessment)。IQA和VQA 的显著区别在于VQA 需要同时结合空域和时域信息,这给准确评价视频质量带来了更大困难。本文将研究聚焦于预测难度更大的NR-VQA。
在过去的研究中,基于压缩失真的VQA 方法取得了较大的进展。然而,随着视频会议系统以及直播视频的日益火热,传统VQA 方法在这些自媒体视频场景中取得的预测结果并不让人满意,给VQA 任务带来了新的挑战。因此近年来,越来越多研究人员围绕自媒体视频质量评价展开研究。Li 等提出VSFA[5],在自媒体视频质量评价中引入长期时域RNN 建模以及短期时间记忆效应建模,以此来模拟人眼感知的长短期记忆。其在之后MDTVSFA[6]中引入混合数据集操作进行数据集的混合来弥补不同自媒体视频视频库之间评分范围差异过大的问题。Korhonen以及Zheng等分别提出TLVQM[7]以及VIDEVAL[8]方法,通过计算各类时空域手工相关特征在SVM 进行回归。此后,两人在此基础上进行扩展分别提出CNNTLVQM[9]模型以及RAPIQUE[10]。这两者都通过采用CNN 特征以及传统手工特征相结合的结合策略实现性能的再次提升。然而,其性能提升的同时,由于特征存在重复,带来了较高的时间复杂度。之后Chen 等提出RIR-Net[11],使用时域降采样建模来拟合人眼感知中快慢感知结合机制,接着,其针对自媒体视频中的直播视频,提出了TRR-QoE[12],引入频率记忆力机制对不同时序频率感知进行权重再分配,实现了性能的再提升。
随着这些方法的提出,针对自媒体视频的预测准确度取得了令人欣喜的提高。然而,在面对一些复杂的视频场景的情况下,现有方法的性能仍会有一定程度的下降。这背后的原因可以归结为VQA的关键空域和时域信息的利用不足。具体而言,对于自媒体视频中的空域信息,并未利用高阶相关特征,对于时域信息,并未建模深层时域信息。
视频感知的内部工作机制非常复杂。最近,反向层次理论(RHT[13],Reverse Hierarchy Theory)提出一个框架,用于描述复杂的时间感知过程,包括前馈和反馈路径。该理论指出,视觉电信号沿着区域的前馈层次进行处理,进而形成愈发复杂地感知表示,这一过程是自发和隐性的。而真正有意识的感知从脑视觉层次的顶部开始,根据需要逐渐向下返回。在过去的研究工作中,特征融合只考虑了前馈路径。然而视觉系统中的反馈路径,会使特征间和时域帧间交互更加复杂,需要一个能探知更深层次时空域网络结构的模型进行刻画。
具体来说,为模拟该视觉感知理论,本文设计了高阶语义特征提取模块(HFE,High-Level Fea⁃ture Extraction),用于有效捕获嵌于空域图中的高阶语义特征。同时,提出快速迭代深层GRU 结构(FI-GRU,Fast-iteration GRU),以级联递进的形式组织GRU 单元,用迭代的方式促进GRU 单元之间的顺序知识交换。这个过程模仿了前馈连接过程的隐性感知和后向连接的显性感知。同时,本文加入了跳跃连接,用于快速传递深层信息,防止网络加深所导致的性能下降现象。最后,引入特征间的平均聚合和多层感知机来回归视频得分。通过这种方式,本文提出的方法能够为自媒体视频提供良好的质量预测,尤其针对缺乏强时间相关性而导致的低质量视频,给予准确的顺序知识感知。
2 基于高阶深层时空信息的自媒体视频质量评价
如下图1所示,本文所提基于高阶深层时空信息的视频质量评价算法主要包括2个模块。首先是利用HFE进行高阶空域信息表征。接着,使用FI-GRU模块建模深层时域信息,最后,引入先聚合后回归的模块来回归得分。具体细节将在以下小节中详细介绍。
2.1 高阶语义特征提取模块
在HVS 机制的驱动下,人类对视频质量的感知会受到视频内容种类的影响。因此,为了模仿HVS 的生物学机制,本文在每一帧上部署了HFE模块,用于提取丰富的空域内容线索,产生多尺度的高阶内容表征。具体而言,高阶语义内容表征分为均值聚合以及二阶协方差聚合。其中,均值聚合用于提取特征图内信息,二阶协方差聚合用于提取特征图间相互关系。HFE 模块是基于迁移学习进行构建,具体来说,本文采用ResNet-50 中最后三个卷积块(Conv3、Conv4、Conv5)的输出,为每帧产生多尺度深度特征图信息:
其中,CNN表示卷积特征图提取操作。接着,三层深度特征在通道级进行平均池化(AP,Average Pooling)和二阶协方差池化(SCP,Second Covariance Pooling)的进一步处理,然后是拼接操作([·,·,·]),即:
其中,该三种尺度的深度卷积特征最初以平均池化和二阶协方差池化进行组合,分别生成两个初始多尺度深度特征具体的二阶协方差池化计算如下所示。首先将特征图展平成尺寸为h×w的列向量,接着通过协方差矩阵去刻画不同层级间各个特征图之间的相关性。具体的列协方差矩阵定义为:
其中,两两特征图之间的协方差计算为:
由于协方差矩阵Σ是对称正定的,故可以进行正交分解:
其中,Λ是Σ的特征值构成的对角阵,幂值选取经验值λ=0.5,得到协标准差矩阵:
为统计各个通道间的相关性,将该协方差矩阵按列展开写作:
其中,yC代表第C个通道的特征图对其他通道特征图的协标准差的集合,它表述了该通道特征图和其他特征图之间的相关性。为更好地代表第C个通道特征图的数据分布量,本文采用其协标准差分量各向量的平均值来描述:
接着,考虑到平均池化和协方差聚合对空域特征的表达有相应的作用,通过不同特征图之间的权重重新分配可以进一步提高其性能。因此,为调节特征图之间自身信息与关联信息两者的参数,本文通过如下的空域特征图注意力分配机制来实现不同特征图之间的相互依赖关系探索。
其中S(·)、δ(·)、A(·)分别表示Sigmoid、ReLu、帧级的平均池化。W2、W4是1×1 卷积层的权重参数,经过比率为r的压缩后经过ReLU 进行非线性交互,低维统计量通过另一个1×1 卷积运算以相同比率r扩展通道数,其权重参数为W1,W3。通过Sigmoid 函数生成的权重重新分配参数,HFE 可以使用缩放特征更准确地表示内部特征。
最后,两个初始深度特征通过串联([·,·])进一步聚合如下:
2.2 快速迭代模块
现有的NR-VQA 模型基于单独前向RNN 来建立长期依赖关系,其主要强调人类对当前帧的感知主要受当前帧及其之前帧的影响。但是,这一理论并未注意到时域建模需要前向后向信息的深层次思考与建模。而视频质量评价是一个基于正向观看来决定得分的过程。也就是说,通过正反向RNN结构的迭代,必须保证最后一层输出的时候RNN 是一个正向RNN(因为视频播放的时候是正向的)。由此考虑,本文提出了快速迭代的FI-GRU结构。
该结构由三个模块构成,分别是降维块,前向块,后向块。首先是降维模块(RGRU,Rudution GRU),其主要作用是引入全连接的降维作用来降低GRU 模块建模的复杂程度。接着引入前后向RNN 结构,包括前向GRU(FGRU,Forward GRU),后向GRU(BGRU,Backward GRU)用于模拟RHT 中反复迭代的过程,其具体构建如图2所示。
具体而言,首先将St输入整个模块,通过RGRU模块进行维初次维度的缩减:
其中,RGRU(·)表示包括一个带有降维功能的全连接层以及GRU 模块,当前帧的建模结果由当前帧的输入St以及前一帧的所决定。
接着,通过如图2 所示的前后向GRU 迭代结构进行深层次的时序建模:
接下来,为回归得到最后的视频得分,引入时域上的平均操作来进行特征维度上的聚合得到视频特征
最后通过多层感知机进行得分的回归,得到最终的视频得分Q:
其中,WhQ和bhQ分别表示权重系数和偏置系数。
3 实验结果与分析
为验证本文算法提出算法的有效性,下文在4个自媒体视频数据上分别进行了详细的性能测试,并与其他主流算法进行了性能比较。其中,数据库分别为KoNViD-1k,CVD2014,LIVE-Qualcomm,LIVEVQC。其具体信息如下表1所示。

表1 数据库信息Tab.1 The information of datasets
此外,实验随机选取视频库中60%的视频序列作为训练集,20%作为验证集,剩下的20%作为测试集,以保证训练集与测试集之间没有交集,以此重复10次结果取平均值,来保证最终结果的有效性。本算法采用初始学习率为10-5,每50 次衰减为原来的0.8倍,Batch Size设定为16,采用Adam优化器。
同时,为保证公平,本次实验均在配置为Inter Core I7-8700(3.2 GHz),11G 英伟达1080Ti,内存16 GB的电脑上进行。
此外,本文采用质量评价领域常用的指标来比较不同方法的性能:包括用于评价预测单调性的斯皮尔曼等级相关系数(Spearman Rank Order Correla⁃tion Coefficient,SROCC),用于评估预测精度的皮尔逊线性相关系数(Linear Pearson Correlation Coeffi⁃cient,PLCC)。其具体表达式如下:
其中,Mte测试视频序列的数量,表示第v个标签和预测得分之间的排名差距。表示所有视频的得分Qv的平均值,相对应地表示客观得分的平均值。一个更好的视频质量评价方法应当具有更高的SROCC和PLCC值。
3.1 整体性能比较
为较全面的比较本文算法,本文将所提的方法与现有的无参考视频质量评价方法进行比较,包括传统无参考质量评价方法BRISQUE[18]、NIQE[19]、CORNIA[20]、VIIDEO[21]、V-BLIIND[22],以及近年来提出的针对自媒体视频的VQA 方法VSFA[5]、TLVQM[7]、CNN-TLVQM[9]。其中VSFA以及TLVQM 以及CNNTLVQM 是专门针对自媒体视频而设计的视频质量评价算法。值得注意的是,RIR-Net 以及TRR-QoE由于源码不可获取,暂未加入比较列表。而VIDEVA 以及RAPIQUE 利用各个SOTA模型的特征进行学习,较为复杂,不在本文的比较范围内。
表2 列出了四个自媒体数据库上各种NR-VQA模型的总体性能,其中加粗和下划线标注的分别是性能最好和第二好的模型。通过比较表格中PLCC、SROCC 两个性能评价指标可以看出:(1)传统无参考视频质量评价算法如BRISQUE[18]等基于自然图像统计特性的评价方法在自媒体视频数据库上表现比较差,这是由于自媒体视频的失真类型与传统的压缩失真类型不同,单纯依靠手工统计特征无法满足多种混合失真类型的自媒体视频预测需求。(2)基于深度学习的视频算法在自媒体视频上取得较好的成绩,如CNN-TLVQM 依靠引入的深度学习特征相较于原始的手工特征TLVQM 取得了较大的提升。(3)值得注意的是,在KoNViD-1k 这个视频数量最多的数据库中,本算法取得最高的PLCC和SROCC值。同时,在其他数据库上,本方法均取得最优或次优的结果。说明本方法的性能相较于其他算法有较好的优势。此外,虽然CNNTLVQM在部分数据库取得较好性能,但其同时提取深度网络特征以及传统手工算法特征,其时间复杂度较高,特征存在部分重叠,且手工特征计算无法通过GPU 加速。(4)本算法未添加时间记忆效应模块的情况下,取得了远胜于VSFA 的性能表现,这说明了所提算法的通过高阶空域信息提取用于快速迭代GRU 模块的结构确实学习到了更深层次的时域信息,并对最终的评价效果产生了较好的影响。
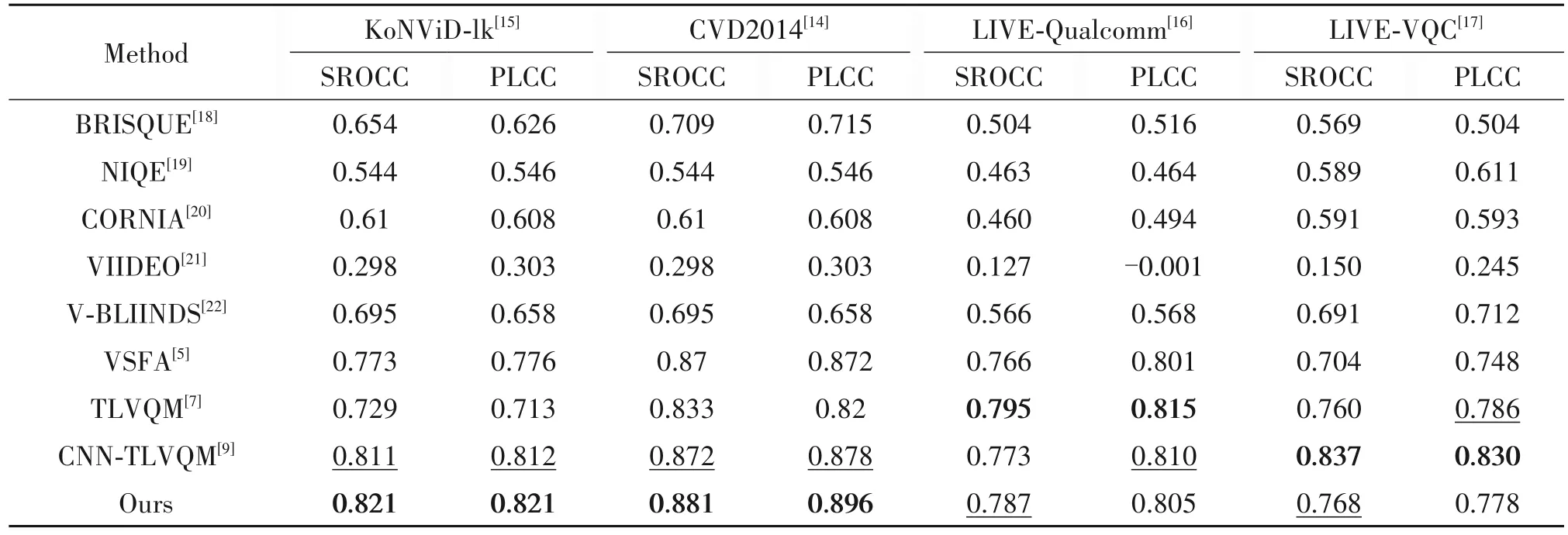
表2 各个无参考视频质量评价算法在各个数据库上的性能比较Tab.2 Performance comparison of various non-reference video quality evaluation algorithms on various databases
利用散点图可以直观地展示视频的主观评价分数和客观预测分数之间的拟合效果,网络模型在KoNViD-1k 数据库上的预测结果如下图3 所示。为了更加明显地观察,该图同时加入了此前最优的算法CNN-TLVQM 进行比较。从图3 可以看到,本算法得分数据主要分布在对角线的两侧,相较于CNN-TLVQM 展现了更加良好的线性关系,这表明所提算法在KoNViD-1k视频库中的拟合效果更好。
为了观察训练集的数量是如何影响评价结果,本次实验通过改变训练集的比例,重新计算得到KoNViD-1k 数据库中的平均评价结果,如图4 所示。从图中可以看到,用于训练的失真视频越多,最终的评价结果越好。
3.2 消融实验
为验证本算法中不同模块的有效性,分别对高阶信息提取模块以及快速迭代GRU结构进行消融实验。首先是验证多层空域信息提取模块的有效性,本次消融实验是采用均值以及标准差提取方式作为层特征提取进行多层验证。具体结果如下表3所示。
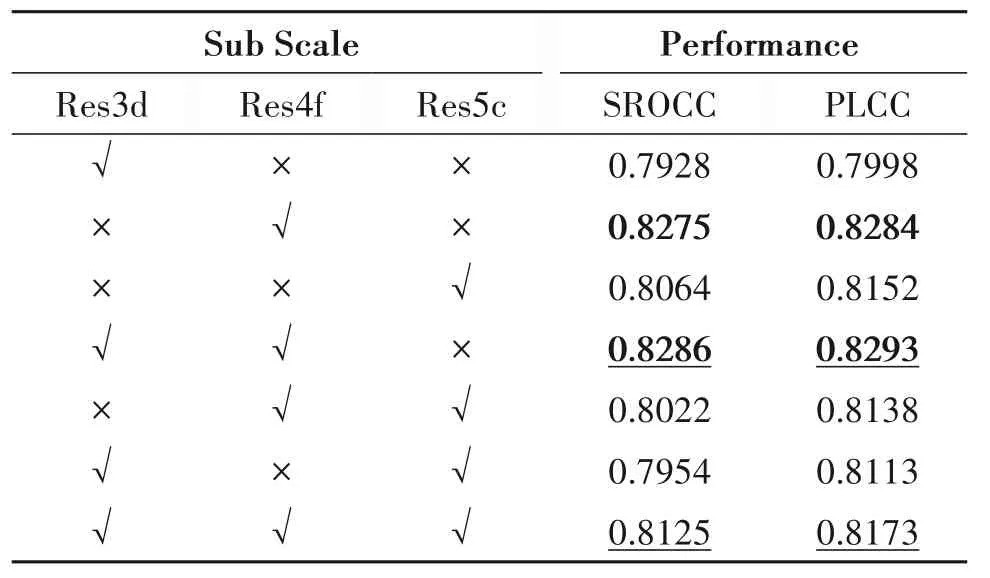
表3 多尺度特征及其组合在各个数据库上的性能比较(加粗+下划线为最优,加粗为次优,下划线为第三名)Tab.3 Performance comparison of various non-reference video quality evaluation algorithms on various databases(Bold+underline is the best,bold is the second best,underline is the third place)
实验结果证明,Res3d+Res4f+Res5c 层取得第三优的结果,并未取得最优的结果。我们认为这个现象主要是该数据库中视频分辨率不大(960×540),人眼对于局部失真的观察不够细致所导致的。与此同时,较好的VQA 算法需要在不同的数据库中都能实现较优的泛化性能,为此,本文同时引入这三者在四个数据库中的表现进行参考。具体结果如下图5所示。
实验结果证明,综合考虑,Res3d+Res4f+Res5c层特征虽然在KoNViD-1k 并未取得最优,但结合其他数据库的表现来看,其取得综合最优的性能。
在Res3d+Res4f+Res5c 层的基础上,验证HFE模块的有效性,本文比较了简单的均值聚合,单独的二阶协方差信息以及两者相结合的性能。具体结果如下图6 所示。其中图6(a)为SROCC 性能,图6(b)为PLCC性能。
实验结果证明,通过同时引入均值信息以及二阶协方差信息,模型能从特征图中学习到更高阶的信息,因此取得更好的性能。单独使用其中之一都会导致性能的下降。
3.3 量化实验
为验证快速迭代FI-GRU 模块的性能,本文分别采用不同数量的BGRU-FGRU 块堆叠,用于观察其性能结果(其中特征提取部分采用的是均值与标准差聚合,并在KoNViD-1k 上进行实验)。具体结果如下图7所示。
实验结果证明,一开始随着FI-GRU 模块层数的不断地叠加,本方法的性能有明显的提升。其中,可以发现当层数达到一定范围后,性能趋向于一个固定的范围(本次工作中为9 层),甚至开始下降。也就是说,越来越深的网络层数并不能持续地提高模型性能。因此,考虑到时间和性能的平衡,本文采用了9层结构作为深层时空信息的表达。
为更好观察所提出的FI-GRU 模块如何提高模型性能,本文采用KoNViD-1k 视频库中2 个视频举例。如下图8 进行结果的可视化。图中第Ⅰ行表示原视频,图中第Ⅱ行表示原视频前向光流图,图中第Ⅲ行表示原视频后向光流图。最后,Ri分别表示采用i层结构的FI-GRU对于视频所预测得分。
实验结果发现,两个视频的前后向光流图存在较大的差异,说明了前后向时序信息分别包含了不同的信息。且随着不断加深的FI-GRU 结构,本算法探索到了更深层次的时域相关性,并取得越来越接近MOS(Mean Opinion Score)的预测得分。
4 结论
在本文中,本文提出了用于自媒体视频的无参考视频质量评价算法,它主要包括两个模块:空域高阶信息提取,深层时域信息建模。具体来说,首先利用HFE 模块提取高阶的特征图描述,包括平均池化以及二阶协方差池化,有效地刻画了空域内容信息。然后,利用所提出的FI-GRU模块进行快速的时域深层信息建模,最终,通过先聚合后回归的策略得到视频的得分。通过全面的消融研究,验证了所提出的VQA 方法的有效性。此外,量化实验表明FI-GRU模块从时域相关性出发,能为视频提供了更精准的预测得分。在四个公共自媒体视频数据集上进行了详尽的实验,实验结果表明,所提出的方法与自媒体视频中人眼感知有较好的一致性,并且相对于目前NR-VQA方法表现出更加优越的性能。
猜你喜欢
电声技术(2022年7期)2022-09-23
哈尔滨工程大学学报(2021年10期)2021-11-05
舰船电子工程(2020年3期)2020-06-11
北京航空航天大学学报(2019年9期)2019-10-26
军事运筹与系统工程(2019年4期)2019-09-11
福建基础教育研究(2019年7期)2019-05-28
计算机应用与软件(2019年2期)2019-04-01
宇航计测技术(2019年1期)2019-03-25
数学学习与研究(2018年15期)2018-11-12
经济研究导刊(2018年19期)2018-07-24
