
基于视觉注意力机制的多源遥感图像语义分割
2022-07-22 13:36谭大宁姚力波丁自然路兴强
信号处理 2022年6期
谭大宁 刘 瑜 姚力波 丁自然 路兴强
(1.海军航空大学信息融合研究所,山东烟台 264001;2.中科卫星(山东)科技集团有限公司,山东济南 250199)
1 引言
遥感影像分割是遥感卫星数据处理与分析的重要研究内容,随着城市管理、资源调查、环境监测等需求的上升,准确获取遥感图像中指定语义区域的分布情况成为管理决策的重要信息来源[1]。目前用于多源遥感图像融合语义分割的数据主要包括MS、PAN、SAR 以及激光(LiDAR)数据等。不同遥感数据具有不同的特性,因而在分割任务中也有各自不同的优势[2]。PAN 图像的空间分辨率高,MS图像具有更丰富的光谱信息,LiDAR 包含地面物体的三维空间信息,而SAR 图像具有全天候、全天时的观测能力[3]。近年来,随着卫星和机载传感器平台的蓬勃发展,多源遥感数据的同时获取更加容易,利用多源遥感数据进行区域分割也成为一个研究热点,特别是利用深度学习技术进行多源遥感图像的融合区域提取[4]。
多源遥感图像区域提取主要采用语义分割的方法,其原理是将图像中分属同一类别的像素聚合为一个连通区域,并生成分割掩膜。在深度学习技术得到大规模应用之前,主要的语义分割算法有基于马尔科夫随机场(Markov Random Fields,MRF)[5]的方法和基于随机森林(Random Forest,RF)的方法[6]。2014 年,加利福尼亚大学Long 等人提出完全卷积网络(Fully Convolutional Networks,FCN)[7],标志着深度学习正式进入图像语义分割领域,FCN 也成为后续大部分语义分割方法的基本结构。Seg⁃Net[8]在FCN 的基础上,通过类似U-Net的编码-解码结构和跳跃连接,同时采用最大值池化,使得与FCN 相比更为高效。PSPNet[9]与上述方法不同的是,它采用卷积神经网络来提取图像的特征图,然后通过金字塔池化模块来聚合背景信息,从而使得模型具有更好的多尺度特性,对小目标分割效果更好。单一数据源的图像分割算法为多源图像融合分割提供了很好的借鉴。按照融合的不同时期,多源数据融合可以分为早期融合和后期融合。FuseNet[10]采用早期融合的模型结构,将RGB 光谱信息和深度信息进行融合用于室内场景的语义分割任务,展现了多源数据融合分割的优势,同时也存在着融合效率不高的问题。Audebert等人采用后期融合思路,将SegNet 进行改进用于多源数据融合分割任务[11],同时与FuseNet 进行对比,并得出后期融合可以恢复模糊数据产生的错误,而早期融合可以更好地联合特征学习,但代价是对缺失数据更加敏感。改进的SegNet 与FuseNet 相比模型参数量更大,但两者均展现出与SOTA 算法相当的性能。李万琦等[12]提出一种将数值地表模型(Digital Surface Model,DSM)与RGB 光谱信息相结合的多模态融合模型SEU-Net,该模型也属于早期融合类型。它使用了SE(Squeeze and Excitation)模块用于模态信息加权,克服了卷积网络多模态信息融合过程中的加权问题,但该模型只针对两种数据源,对于两种以上的数据源并不具有可移植性。
针对以上问题,以及多源遥感数据融合处理的特点,本文以U-Net模型[13]为基础,提出一种适用于多种模态的多源遥感图像融合语义分割模型,用于从遥感图像提取目标区域。该模型将Transformer模块与U-Net模型结合,利用U-Net的编码器结构将MS、PAN 和SAR 图像进行编码融合,同时使用通道交换策略将多源遥感图像的特征图进行交换,从而获得更好的多源互补性。通过Transformer 模块的注意力机制对拼接融合的特征图进行全局信息建模,以此来捕获全局上下文信息,从而对目标建立长距离依赖项,提取出更有效的全局特征。对于建筑物轮廓分割任务,可以得到类似人眼视觉的效果。
2 方法与原理
2.1 U-Net图像分割
U-Net 在图像分割任务特别是医学图像分割任务中最具代表性,其编码器-解码器结构和跳跃连接(skip connection)是一种非常经典、高效的设计。最初U-Net 被用于二维图像分割的卷积神经网络,并分别赢得ISBI 2015 细胞追踪挑战赛和龋齿检测挑战赛的冠军[14]。自2015 年在MICCAI 会议上提出以来,该方法目前已被引用四千多次。目前图像分割网络出现许多新的卷积神经网络设计方式,但很多依然延续U-Net 的设计思想,加入了新的模块或者融入其他设计理念。
U-Net的结构如图1所示,左侧可视为一个编码器,右侧可视为一个解码器。其中,编码器有四个子模块,每个子模块又包含了两个卷积层,每个子模块之后通过最大值池化实现下采样。U-Net 的输入图像分辨率为572×572,经过每个模块之前的分辨率分别为572×572、284×284、140×140、68×68 和32×32。解码器与编码器有着对称的分布,也包含四个子模块,每一模块的分辨率通过上采样操作依次上升,直到与输入图像的分辨率一致。与此同时,该网络还使用了跳跃连接,将上采样结果与编码器中具有相同分辨率的子模块的输出进行连接,作为解码器中下一子模块的输入,具有良好的多尺度特性。
2.2 Transformer
2.2.1 Transformer基本结构
Google 于2017 年提出Transformer 结构[15],最初在自然语言处理(NLP)的多个任务上取得了较好的效果,极大促进了NLP 的发展。Transformer 摈弃了传统的CNN和RNN,整个网络结构完全由注意力机制(attention mechanism)组成。由于其出色的性能以及广泛的适用性,不断有研究者将Transformer 引入计算机视觉任务。在本文中,主要思路是利用Transformer 的自注意力机制(self-attention),对PAN、MS 和SAR 图像建立长距离依赖,从而更好地提取全局上下文信息。
Transformer 模块以向量组成的序列作为输入,每个向量由位置编码和特征编码相加得到。将输入序列表示为Fin∈RN×Df,其中N为序列中的向量数,每个向量用维数Df的特征向量表示。Trans⁃former 使用线性投影来计算一组查询、键和值(Q、K和V),
其 中Mq∈RDf×Dq,Mk∈RDf×Dk和Mv∈RDf×Dv是权重矩阵,它使用Q和K之间的点积来计算注意力权值,然后对每个查询的值进行聚合,计算方法如下:
其中Softmax 函数用于描述相似度。最后,Trans⁃former 采用非线性变换来计算输出特征Fout,其形状与输入特征Fin相同,
Transformer 在整个架构中多次应用注意机制,从而产生L个注意力层。标准Transformer的每一层都有多个并行注意头,这涉及到在式(1)中每个Fin产生几个Q,K和V值,并从式(2)中连接得出的A值。
2.2.2 多源融合Transformer
为了学习多模态任务,在Transformer的编码器-解码器体系结构之上,建立多源Transformer 模型[16]。它由每个输入模态的独立编码器和一个解码器组成,在多个不同的模态信息输入下,融合多源全局上下文信息。对于PAN、MS 图像和SAR 三种模态输入,通过Transformer 编码器编码到一个隐藏状态列表中,以合并全局上下文信息。在将输入模式编码到隐藏状态序列后,将Transformer 解码器应用于多种编码模态的串联序列。
设输入的多源图像为I1、I2和I3,在本文所提的模型中,通过卷积神经网络和Transformer 编码器对输入图像进行编码,并将三种模态的输入编码成视觉隐藏状态图像编码的思路来源于DETR[17],其过程如下:首先,将卷积神经网络应用于输入图像,分别提取大小为的特征图xm、yp和zs。在特征映射xm、yp和zs的顶部分别应用一个具有L1层、L2层、L3层和隐藏尺寸的可视化Transformer编码器Em、Ep、Es,进一步将其编码为大小为和的可视化隐藏状态iv、jv、k(v其中是已编码的可视化隐藏状态的长度)。在对输入多模态进行编码后,对其应用一个隐藏尺寸为、层数为Nd的Transformer 解码器D,输出解码后的隐藏状态hdec序列,用于后续的任务。变压器解码器D采用编码后的输入序列henc和长度为q的任务特定查询嵌入序列qtask,它为Transformer解码器每l层的层输出解码后的隐藏状态序列hdec,l,该序列与查询嵌入qtask的长度q相同,其计算方式如下:
解码器结构遵循在DETR[18]中的Transformer 解码器实现。在第l层译码器中,自注意力在解码器隐藏状态hdec,l之间应用,l在不同位置上应用,跨注意力应用于编码输入模态henc。
2.3 通道交换原理
目前深度多模态融合方法主要分为基于聚合的融合、基于对齐的融合[19]和混合方法。基于聚合的方法(如图2(a))采用某种操作(如平均[10]、连接[20]和自注意力[21])将多模态的子网络组合成一个统一的网络。而基于对齐的融合[22-23]则采用特定的损失函数来对齐所有子网络的嵌入,同时保持每个子网络的全传播。尽管目前的多模态融合方法进展显著,但如何在保留每一种模态信息的同时整合各模态的共同信息方面仍然面临许多困难。特别是当多模态子网络被聚合时,基于聚合的融合容易忽略模态内的传播。相反,基于对齐的融合(如图2(b))虽然保持了模态内传播,但由于仅通过训练对齐损失函数而导致信息交换较弱,往往无法实现有效的模态间融合。
为了平衡模态间融合和模态内处理,本文采用了无参数、自适应、有效的通道交换网络[24](Channel-Exchanging-Network,简称CEN)。该策略将尺度因子的稀疏性约束应用于不同模态的不相交区域。如果特征图的比例因子低于阈值,则在同一位置的特征图将被其他模态的特征图所取代。CEN 不使用聚合或对齐,而是通过动态地在子网络之间交换通道以进行融合(如图2(c))。具体而言,利用批量归一化(Batch Norm,BN)的尺度因子(即γ)作为每个对应通道的重要性度量,并将每个模态的接近零因子相关的通道替换为其他模态的均值。这种通道交换是无参数且自适应的,它由训练本身确定的尺度因子动态控制。此外,为了保持模态内的传播,实际使用时只允许在每个模态通道的特定范围内进行有向的通道交换。
如图3 所示,Conv 表示卷积,BN 表示批量归一化,ReLU 表示非线性函数。在下采样后的每一级卷积中,通道交换发生在第二个BN 层之后。经过BN层后对应输出为
其中xm,l,c表示第m个分支第l级下采样的第c个通道的特征图,μm,l,c和σm,l,c表示均值和标准差,γm,l,c和βm,l,c为训练得到的比例因子和偏置,ε为避免被零整除的趋于零的常数。式(5)中的比例因子γm,l,c评估了xm,l,c和x′m,l,c之间的相关性,当γm,l,c→0,表示xm,l,c对最终预测没有影响,从而成为冗余。因此,当γm,l,c→0 时,CEN 将替换掉较小比例因子对应的通道。因而经过交换后的输出为:
在式(6)中,M表示分支网络数。当通道的比例因子低于某一阈值(θ≈0+)时,将其替换为其他通道的均值。对每个分支网络均应用式(6),然后将处理完的特征图输入非线性激活函数ReLU,然后进行下一级下采样操作。
3 模型结构
3.1 整体结构
本文在3D 医学影像分割模型TransBTS[25]的基础上提出了适用于多源遥感融合语义分割的模型Transformer U-Net(简称TU-Net)。如图4所示,该模型主体借鉴了U-Net的编码-解码器结构和跳跃连接结构,输入为PAN、MS 和SAR 三种模态的遥感数据(分别设为X∈RC1×H×W、Y∈RC2×H×W和Z∈RC3×H×W,其中H×W代表空间分辨率,Ck代表通道数,k=1,2,3)。首先,通过编码器的卷积神经网络对多源遥感信息进行提取,生成多分辨率的特征图,以获得空间结构信息;然后利用Transformer 编码器对多源融合特征图全局空间中的长距离依赖项进行建模,使得大型的不规则区域更容易被分割出来;之后将上采样层和卷积层进行逐级像素级相加,逐步得到高分辨率的分割结果。由于全色图像具有更好的空间分辨率和更易分辨的细节信息,因此通过连接全色图像支路编码器和解码器的跳跃连接来改善分割精度。
3.2 编码网络
由于输入图像的尺寸不能太大,Transformer 在计算机视觉中的应用十分受限。对于N×N的图像,输入Transformer 重整形后序列长度达到N2,因此直接将输入图像与序列联系起来作为Trans⁃former的输入是不切实际的。文献[26]提出图像切分的概念,将输入图像切分成16×16的图像块,然后将每个补丁重塑为一个向量,将序列长度缩减为162。在多源融合处理任务中,直接切分输入图像也使得模型计算量较大。为了缩减开支,先通过编码网络对输入数据进行下采样,逐步将输入图像编码为低分辨率特征表示。经过的3 次下采样后,数据大小变为,这样,丰富的局部上下文特征就可以有效地嵌入到Fi。之后Fi被输入到Transformer 编码器中,以进一步学习具有全局感受域的大范围相关性。在下采样过程中,3 个分支网络通过2.3 中的通道交换网络进行通道交换。
3.3 Transformer编码器
对于编码网络输出特征图Fi,进行通道拼接为由 于输入Transformer 的需要是一维序列,因此将F的空间维度折叠为一维,得到一个的特征图f,也可以看作是N个d维的向量。为了对建筑物分割任务中至关重要的位置信息进行编码,引入可学习的位置嵌入,并通过直接相加的方式将其与特征图f融合,生成如下特征嵌入:
其中,PE∈Rd×N代表位置嵌入,z0∈Rd×N为特征嵌入[27]。Transformer 编码器由L个Transformer 层 组成,每层都有一个标准的架构,由一个多头注意力(Multi-Head Attention,MHA)块和一个前馈网络(Feed Forward Network,FFN)组成[28]。第l个Trans⁃former层(l∈[1,2,…,L])计算如下:
其中,LN(∗)表示标准化层,zl为第l个Transformer层的输出。
为了将序列还原成特征图,这里通过特征映射实现。对于Transformer 输出的特征图zL∈Rd×N,将其重整形为,这样特征图的大小恢复为,得到与编码部分特征图F相同的尺寸大小。
3.4 解码网络
如图4所示,解码网络与编码网络类似,不同的是在上采样的过程中与PAN 分支网络的各级输出特征图进行像素级拼接,通过跳跃连接将编码器特征图与解码器对应的特征图融合,这更使得分割掩膜有更丰富的空间细节。之所以选择PAN 图像是因为在PAN、MS 和SAR 图像中,PAN 图像具有最高的地面空间分辨率,纹理细节更加清晰,可以提高语义分割精度。最终解码器的输出为建筑物分割掩膜Mask ∈RH×W。
3.5 网络参数
表1 展示了本文提出的TU-Net 网络结构细节,其中Conv 表示3×3 卷积(未标明步长的步长为1),下采样中Conv 的步长为2。Dropout表示随机失活,对神经元进行正则化,减少权重使得网络对丢失特定神经元链接的鲁棒性提高。BN 为批量归一化。Reshape 代表重整形,将特征图由d×N重整形为ReLU 表示非线性激活函数,DeConv表示反卷积层,Softmax 表示分类器,输出结果为最终的分割掩膜。编码块和解码块均为残差块。表1的第3 列表示对应层输出特征图的尺寸,三种输入编码器均采用了相同的输出特征图,目的是便于在通道交换过程中进行通道交换。

表1 本文提出的TU-Net网络结构细节Tab.1 The details of the TU-Net network proposed in this paper
3.6 方法流程
基于融合Transformer 的多源遥感图像语义分割流程如图5所示,主要步骤为:①对已配准多源遥感图像进行大小调整,按照PAN 图像的分辨率对SAR 和MS 图像进行插值,使得多源遥感图像的分辨率一致,之后裁剪成256×256的图像对;②将处理好的多源遥感图像输入编码网络,以进行下采样和通道交换;③对多源拼接特征图进行位置嵌入,并输入Transformer 进行长距离依赖项进行建模,然后由重整形恢复到原始特征图大小;④输入解码网络进行上采样,并与编码网络的每一级输出进行跳跃连接相融合;⑤通过建筑物标签数据进行有监督训练,更新权值;⑥最后通过Softmax 分类器完成区域分割提取。
4 实验与分析
为了检验本文所提方法的有效性,设置了对比实验和消融实验。实验所采用的数据源自All Weather Mapping(MSAW)数据集[29],该数据集包含荷兰鹿特丹港口0.5 m 四偏振X 波段SAR 图像和0.5 m光学图像。MSAW 覆盖面积约120平方公里,涵盖了不同的地理环境,包括高密度的城市环境、农村农业区、郊区、工业区和港口,导致不同的建筑规模、密度、背景和外观。该数据集总面积为120平方公里,标有48000 个建筑标签。实验选取了其中的0.5 m分辨率四极化SAR图像、0.5 m分辨率全色图像和2 m分辨率多光谱图像(蓝色、绿色、红色和近红外波段),如图6所示。考虑到图像尺寸和模型训练时间问题,实验中对原数据集的3401对多源遥感图像及标签进行了随机裁剪,得到256×256 标准大小的图像进行实验。按照训练集、验证集和测试集各70%、10%和20%的划分比例,将遥感图像划分为训练集2381对、验证集340对和测试集680对。
实验平台选择为安装Ubuntu16.04 的服务器,软件平台为PyTorch深度学习框架,采用python语言编程实现,硬件环境为Nvidia RTX2080Ti×2 GPU 和Intel(R)Core(TM)i9900K CPU。模型采用Dice 损失函数对网络进行训练,采用L2范数对模型进行正则化,初始学习率设置为0.0004,权值衰减率为10-5。模型共训练100个epoch,batch size设置为16。
4.1 实验1
为了取得更好的融合分割效果,实验1 对不同通道交换阈值θ下的语义分割效果进行了对比。实验选取的θ取值为2×10-4、2×10-3、2×10-2和2×10-1,记录的θ值与对应分割结果的F1值散点图如图7 所示。为了便于展示,图7 横坐标取对数表示为log10θ。由图7可以看出,在实验选取的四个θ值下θ=2×10-2时分割效果最佳,其次是θ=2×10-3,效果最差的是θ=2×10-4,原因在于θ值过小导致通道交换进行次数少,没有发挥出多源遥感图像的互补性优势。因此,后续实验中θ取值2×10-2。
4.2 实验2
实验2为消融实验,共设置了四组,第一组对应模型为U-Net,多源图像的融合方式为2.3中图2(a)基于聚合的融合;第二组在第一组的基础上加入了Transformer,多源图像的融合方式与第一组相同;第三组在第一组的基础上加入了通道交换,多源图像的融合方式与第一组相同;第四组为本文所提方法,在第一组的基础上加入了Transformer 和通道交换策略。实验2的目的是验证本文所提的多源融合策略的有效性。为了便于训练,实验中通过图像预处理将全色图像、多光谱图像和SAR 图像裁剪成256×256的图像对,输入模型进行建筑物分割训练。实验在测试集上的平均指标值如表2 所示,部分结果如图8所示。
从表2 的实验指标值可以看出,所提出的Transformer 和通道交换策略在多源遥感融合建筑物提取中具有显著的效果,其中使用Transformer 后F1和Dice 系数相比第一组分别提高了6.27%和5.93%;使用通道交换后F1和Dice 系数相比第一组分别提高了2.28%和2.97%;二者同时作用时,F1和Dice 系数分别提高了12.74%和13.01%。结果表明,本文所提出的多源融合策略对于多传感器数据融合建筑物分割提取任务有效。
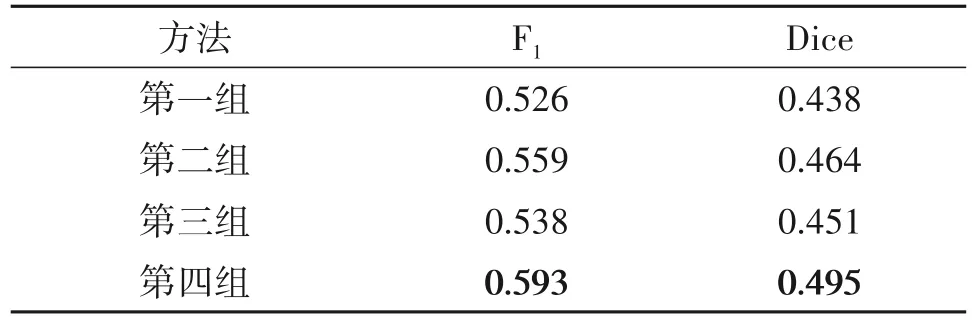
表2 不同方法建筑物分割结果评价指标Tab.2 Results evaluation indexes of different building Segmentation methods
除了表2 的性能指标,从图8 的(c)~(f)对比结果可以看出,在第一组基础上引入Transformer 可以提高对全局信息的建模能力,大目标的分割提取能力得以提升;在第一组的基础上引入通道交换网络建筑物分割提取结果略有改进;当二者同时作用时,对于非建筑物区域的错误分割比例降低,正确分割建筑物区域的比例提升。图8所示实验结果与表2结果相互印证,本文方法的有效性得以验证。
4.3 实验3
为了检验本文所提方法的优越性,设置了第3组对比实验。对比算法选择文献[10]、文献[8]和文献[13]中的多源融合算法,分别为方法一、方法二和方法三,其中前两者采用聚合的融合方法。实验在测试集上的平均指标值如表3所示。不同建筑物分割提取方法的部分结果如图9所示。
从表3的数据可以看出,与对比算法相比,本文提出的多源融合策略对于建筑物分割提取的性能提升显著,在测试集的平均F1值和Dice 系数分别高出3.31%~11.47%和4.87%~8.55%,指标性能最佳。在模型的训练时长上,本文所提方法与方法一、方法二相当,方法三的时长最短,综合来看本文所提方法具有优势。
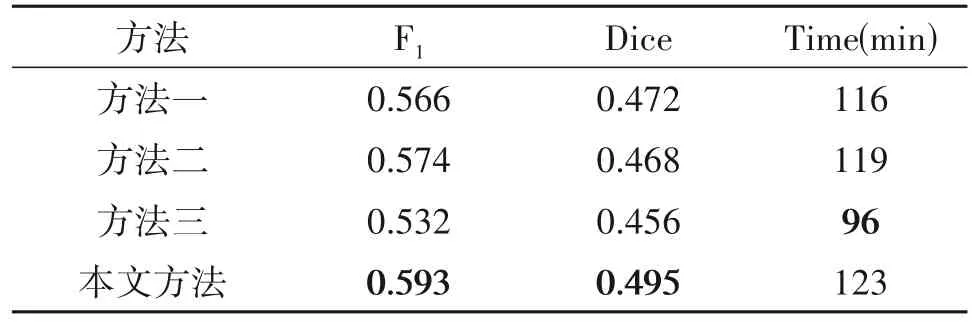
表3 不同方法建筑物提取结果评价指标Tab.3 Results evaluation indexes of different building extraction methods
除了表3 的性能指标,从图9 的(c)~(f)对比结果可以看出,相比方法一、方法二和方法三,本文提出的方法对建筑物全局特征有更好的提取能力,分割结果的整体轮廓更完整清晰。图9所示实验结果与表3结果相互印证,本文方法的优越性得以验证。
由于对比算法和本文所提方法均使用的Dice损失函数,因此为了进一步说明本文所提出算法的优越性,实验记录了训练过程中不同方法的训练损失和验证损失,其平滑处理结果如图10 和图11 所示。观察图10中的训练损失可以得出,本文所提方法具有更好的收敛效果,在四种方法中收敛效果最好。在图11 中,四种方法的验证损失均为震荡曲线,而本文提出的方法的验证损失曲线位于其他方法的曲线下方,均值和震荡幅度最小,模型训练过程中更加稳定。实验结果再次验证了本文所提出方法的优越性。
5 结论
为了解决多源遥感图像融合过程中的数据不均衡问题,本文设计了一种基于注意力机制的多源遥感数据融合语义分割模型TU-Net。该模型在U-Net的基础上引入了通道交换网络进行多编码支路的通道交换,并将融合后的特征图输入Transformer 模块进行全局信息建模,以获得对全局上下文信息更强的提取能力。在MSAW 数据集上的实验表明,本文提出的方法平均F1值和Dice系数分别达到0.593和0.495,取得最好的分割效果。与对比算法相比,在测试集上的平均F1值和Dice 系数分别高出3.31%~11.47%和4.87%~8.55%,通过数据说明了TU-Net的有效性。在后续研究工作中,将重点关注小目标的分割方法,从模型的多尺度特性及动态融合方面进行优化,以获得更好的多源语义分割提取能力。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
网络安全与数据管理(2022年1期)2022-08-29
昆明医科大学学报(2022年3期)2022-04-19
小学生必读(低年级版)(2021年10期)2022-01-18
锻压装备与制造技术(2021年5期)2021-11-13
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
科学技术创新(2021年5期)2021-03-17
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
——编码器
演艺科技(2020年7期)2020-08-13
