
具有遮挡鲁棒性的监控视频人脸再识别算法
2022-07-22 13:36段鹏松
信号处理 2022年6期
张 博 赵 巍 段鹏松 武 琦
(1.郑州大学网络空间安全学院,河南郑州 450002;2.郑州大学汉威物联网研究院,河南郑州 450002)
1 引言
随着监控系统应用场景数量和种类的快速攀升,利用多个摄像机对相同个体进行跨时空身份识别的需求愈发强烈,并在公共安全、执法等领域展现出巨大潜力[1]。现有身份识别技术一般依赖于外观特征(如衣服、装饰等)或生物特征(如面容、步态等)。外观特征的波动性较大,导致基于其的身份识别技术稳定性较差[2]。生物特征的复杂性较高,但稳定性更好,利用其进行身份识别更为可靠[3]。在生物特征中,面部特征作为便捷的非侵入性视觉特征,可以更有效的进行人体跟踪与识别[4]。
近些年来,随着基准数据库的增大、高级网络结构[5-6]和各种损失函数[7-8]的广泛使用,基于深度学习的人脸识别技术取得了显著的进步,在某些基准数据库上的识别能力已经超越了人类。虽然基于深度学习的识别模型在无限制的人脸识别场景下取得了巨大的成功,但是仍然无法满足监控视频的人脸再识别任务。主要原因是监控摄像机捕获的面部图像存在分辨率和角度的差异、信息冗余以及面部遮挡等问题。此外,监控摄像机拍摄的目标对象往往没有在数据库中记录其完整特征,因此需在首次发现目标时快速提取有效特征,这给传统面部识别技术带来巨大挑战。
为解决上述问题,需对现有面部识别方法进行改进,以满足在监控视频下再识别的现实需求。首先,由于监控视频帧中目标面部存在姿势、表情、光照和遮挡等诸多不同,相同目标面部在不同帧中的特征存在较大差异。因此,可以使用注意力机制对质量好的图片分配更多权重,得到更完善的面部特征,以解决各帧图像分辨率和角度存在差异的问题。其次,监控视频相邻帧之间的面部图像往往非常接近,存在较大的信息冗余,直接使用连续的帧提取特征会导致识别方法效率低下。本文采取等距随机取样的方法选取合适的视频帧进行特征提取,不仅保留视频整体的面部特征,还减少了数据冗余,提升了算法的整体效率。最后,对于监控视频中存在的面部遮挡问题,本文使用了PDSN 网络[9]来训练人脸各区块遮挡的掩码来弱化遮挡对特征的影响,并通过分区域匹配的方法减少识别误差。本文的主要贡献总结如下:
通过注意力机制与掩码字典的联合使用,先将视频帧中受遮挡影响的特征元素舍弃,再对剩余的特征动态分配权重,降低了监控视频下人脸遮挡对再识别的影响。
针对掩码字典在再识别场景下准确度下降的问题,提出了分区域匹配的方法,降低了掩码字典的误差,提高了再识别的准确度。实验结果表明,本文的方法在COX 监控视频数据上rank-1 准确度达到了95.2%,并在合成面部遮挡的监控视频数据上rank-1准确度达到了73.0%。
本文章节安排如下:第1 节为绪论。第2 节分析了目前人脸识别及再识别的研究现状。第3节介绍了本文算法的技术细节。第4节展示并分析了本文算法的实验结果。第5 节是本文总结和未来展望。
2 研究现状
2.1 基于图像的人脸识别
早期的人脸识别方法没有足够的数据来进行强大的模型训练,也没有可靠的测试基准,集中应用在小规模的受限场景。直LFW[10]数据集的出现,研究人员开始转向无限制的人脸识别。随着CASIA[11]、CelebFaces[12]、MS-Celeb-1M[13]、Mega⁃Face[14]等数据集的创建,人脸识别技术得到了快速的发展,如SCHROFF 等人的研究[7]在LFW 基准上的识别准确率超越了人类。
传统人脸识别算法在较为清晰的图像数据集上已经取得了很大成功。然而监控视频数据集展现出光照、倾角以及遮挡等不利因素,使得这些算法难以获得令人满意的效果。鉴于此,一些研究人员开始考虑通过对特征进行选择来去除多余嘈杂的特征,保留对识别有用的特征,如LI 等人在[15]提出了一种半监督的局部特征选择方法,通过学习每类特征的重要性来筛选出针对不同类别的特征子集,以此来选择最具鉴别力的特征。
一些文献针对面部遮挡问题进行了研究。WAN 等人[16]提出了在CNN 模型的中间层增加一个MaskNet 分支,为被遮挡的面部区域激活的隐藏单元分配较低的权重。Trigueros 等人[17]通过用合成遮挡的人脸图片来增加训练数据以此解决遮挡问题。YU 等人[18]使用SIFT 和SVM 算法来进行遮挡的面部识别,它将图像划分为四个局部区域,使用加权平均方法来确定最终的分类结果。DUAN 等人[19]提出了用GAN 来生成无遮挡的正面人脸来降低遮挡的影响。
这些方法虽然对面部的遮挡有着不同程度的鲁棒性,但需要一个较好的正面图像作为基准用于识别,并且无法利用视频中的时间信息,无法完成监控视频下的人脸再识别任务。
2.2 监控视频下的人脸再识别
目前,虽然基于监控视频的人脸再识别研究处于起步阶段,但也出现一些研究成果。DANTCHEVA 等人[20]通过结合头发、皮肤和装饰等特征,进行视频监控系统中正面到侧面的人脸匹配。FARINELLA 等人[21]对人脸进行预处理,去除几何和光度的变化,并表示为三元模式的空间直方图,以此进行人脸的再识别。QIU 等人[22]构建了一个领域自适应字典来处理两张人脸图像的匹配。LI 等人[23]探讨了面部信息在人员再识别中的作用,证明面部是一种更可靠的生物识别特征,可以作为长期跟踪目标的依据。LI 等人[24]构建了一个人脸再识别数据集,并采用改进的DNN 架构和区块匹配技术,并使用完全卷积结构和空间金字塔池化(SPP)来进一步提高性能。WANG 等人[25]则采用了深度模型进行特征学习和聚类来识别身份。WANG 等人[26]针对实际监控场景中经常遇到的人脸图像分辨率较低的问题,提出了一种利用松弛耦合非负矩阵分解的低分辨率人脸识别算法。CHENG 等人[4]为了解决真实监控视频场景下的再识别问题,制作了一个大规模的人脸再识别的数据集,并对监控面部图像固有的低分辨率问题进行了研究。
整体来说,对监控视频下人脸再识别的研究仍然存在诸多不足。虽然这些方法尝试解决监控摄像头下的人脸再识别问题,但它们未考虑监控视频中容易出现的遮挡问题,尤其无法满足当前疫情防控中的人脸再识别需求。
2.3 注意力机制
注意力机制已经成为深度学习领域一个重要的概念,被广泛应用于不同领域。LI 等人[27]通过空间注意力解决了图像之间的对齐问题,有效解决了特征被遮挡区域破坏的问题,并使神经网络关注更有鉴别力的物体特征。LI 等人[28]提出了一个自注意力模型,通过探索像素和类别之间的相关性来建立全局空间依赖性模型,以在保证性能的同时降低计算复杂性。但是,空间注意力机制主要关注单一图像上的特定信息,不能完成视频中连续图像的信息捕获。在本文中,我们将使用时序注意力模型,为信息更丰富的视频帧分配更高的权重以提高识别准确率。
3 具有遮挡鲁棒性的人脸再识别算法
人脸再识别需要在监控摄像头首次拍摄到一个的人面部时,迅速记录下其有效特征,之后可在多个摄像机下跨空间与时间进行匹配。根据文献[29],再识别任务可以分为两类:开集再识别问题和闭集再识别问题。这两类问题的区别主要在于画廊集的不同,画廊集(gallery set)是被查询的集合,而探针集(probe set)是查询集合。每个需要识别的对象都是一个探针,需要在画廊集中检索出与其最相似的目标。开集再识别问题没有预先固定的画廊集,画廊集随着时间变化。闭集再识别问题画廊集的大小是固定的,是一个一对多的匹配问题。
本文提出了一个具有遮挡鲁棒性的人脸再识别算法,其整体结构如图1所示。首先,需要对探针视频中的人脸进行检测与对齐,并通过选取合适的视频帧来进行特征提取;其次,通过特征提取网络提取不受遮挡影响的特征元素;最后,根据所提取的特征在画廊集中进行匹配以实现再识别。如果匹配失败,则将探针扩充入画廊集。
3.1 预处理
在预处理阶段,我们把所有的视频帧图片经过RetinaFace 网络[30]进行检测。在检测出人脸框与5 个面部关键点后,使用仿射变换对视频帧中人脸进行对齐并调整为固定大小。通过这种方式,人脸图片的五个关键点会出现在图片的固定位置上。同时,由于监控视频相邻帧之间的人脸图片十分相似,存在信息的冗余。为了能够充分利用整个视频的视觉信息,避免连续视频帧的特征冗余,本文采取了一个等距随机取样方法:对于一个输入视频,我们把它分成T个时间相等的片段,并从每个片段中随机抽取一帧图像。后续的操作将对抽取的T帧图片进行特征提取,以代表整段视频的特征。
3.2 特征提取
本文设计的特征提取网络由四部分构成,分别为PSPNet[31]、掩码字典、主干网络和时间注意力机制,如图2所示。首先,对预处理后的视频图片使用PSPNet 判断遮挡的区块集合;其次,按照遮挡区块集合从掩码字典中选取掩码,并将掩码和主干网络提取的特征图相乘;最后,通过注意力机制对各帧提取的特征图分配权重,并通过FC 层得到最终的特征向量。
3.2.1 遮挡位置检测
本文使用了PSPNet 语义分割模型对面部的遮挡区域进行分割。在对面部遮挡数据集MAFA[32]的图片进行处理和标注后,我们对PSPNet 进行了训练,训练效果如图3所示。
分割出遮挡区域后,把人脸图片划分为5×5 个等大小的区块,以使眼睛、鼻子和嘴巴等面部器官可以被某一区块所覆盖。之后,通过计算遮挡的面部区域与各个区块的交并比来确定哪些区块存在遮挡。当该交并比大于预设阈值时,则判定该区块存在遮挡。
3.2.2 主干网络
本文使用改良的Resnet50 模型[33]作为主干网络提取图片的特征,并使用大边缘余弦损失函数[34]在CASIA-WebFace[11]数据集上进行训练,在LFW[10]测试基准上的准确率达到了99.0%。
3.2.3 掩码训练
对于面部的遮挡问题,最直接的方法是用受遮挡影响较小的面部特征进行比较,以降低遮挡物体对特征的影响。而PDSN 网络[9]可以学习遮挡的面部区块和被破坏的图像特征之间的关系,能够准确地定位损坏的特征元素,其结构如图4所示。
PDSN 网络由主干卷积神经网络和掩码生成器分支组成,主干网络负责提取成对的人脸图片特征,掩码生成器则生成一个掩码并与主干网络提取的特征图相乘,从而降低遮挡对特征图的影响。该网络的训练数据为成对图片,分别为无遮挡的原图以及该图某区块被遮挡的副本。它的损失Lθ由Locc、Lclean、Ldiff组合而成,如公式(1)所示。
其中,F表示全连接层的输出为L1范式。
训练完成后,从每个遮挡小块的掩码生成器中提取一个固定的掩码,并进行二值化的操作,用来抛弃受遮挡严重影响的元素。二值化操作如公式(5)所示,其中m为求均值后的掩码,K]}表示m中μ×K个最小元素,μ为丢弃阈值(本文中设置为0.25),K=C×W×H,为特征图中元素总量。
完成二值化的操作后,将各个区块的掩码构建一个字典。当两个人脸图像进行匹配时,对PSPNet检测出的遮挡区块进行字典匹配和掩码操作(遮挡区块求并集),即可去除相应区块所影响的特征元素。另外,多个区块遮挡时只需同时乘以多个区块对应的掩码。
3.2.4 时序注意力机制
由于监控视频不同帧的面部图像存在姿势、表情、光照和遮挡的差异,因此视频帧之间可提取的特征不尽相同。因此,应该考虑为不同视频帧的图片分配不同的权重。然而基本的时间聚合技术,如平均池化或最大池化,通常会削弱或过度强调有代表性特征的贡献[27]。
与基本的时间聚合技术不同,注意力机制可以轻松建立长时间的依赖关系,因此被广泛地应用于计算机视觉中[28]。本文使用改进的时间注意力机制,判断不同帧特征重要性并赋予相应特征权重值。注意力机制把乘以掩码后的特征作为输入,输出T个注意力分数,并与T帧图像的特征计算加权平均。如公式(6)所示,其中t∈[1,T],at为对应的注意力分数,f t为对应的视频帧特征。
在本文的实验中,我们将时间注意机制与多帧特征向量求均值、平均池化和最大池化的方法进行了比较,发现时间注意模型可以得到最高的准确度。
3.3 分区域匹配
由于我们对掩码执行了二值化操作,因此掩码与特征图相乘后,受遮挡影响严重的元素将会被设置为零。当两个目标使用相同的掩码时,它们特征图中对应位置的零元素会增加,导致二者特征向量相似度增大。对于一个无遮挡的探针视频,它与画廊集中无遮挡的视频计算相似度时(二者ID相同),因为二者不存在遮挡,PSPNet 检测的遮挡区块的数量为零,则二者在提取特征过程中不使用掩码。而该探针在与画廊集中面部存在遮挡的视频计算相似度时(二者ID 不同),PSPNet 会检测出遮挡的区块,并得到相应区块的掩码。虽然使用掩码可以排除部分受遮挡影响的特征元素,但也会造成二者相似度的提升,使后者计算出的相似度超越前者,最终造成匹配的错误。
为此,我们提出了一种分区域匹配的方法。当一个探针在与画廊集中各个目标进行匹配时,首先,通过PSPNet 检测匹配双方的遮挡区块,并根据遮挡区块选择掩码计算双方特征向量的相似度;其次,根据遮挡的区块进行区域类别匹配,即相同区块遮挡而计算出的相似度放进同一区域类别;最后,对各个区域内的相似度进行区域内排序,并对排序后的结果进行区域间比较。区域间比较时,首先选取各个区域相同排名的相似度,再检索这些相似度所代表的画廊集视频,最后对这些画廊集视频进行两两比较,比较的双方再次与探针视频计算相似度。此时,需要选择相同的掩码(对比较双方的遮挡区块求并集),相似度小的舍弃,直至剩余一个。
例如,当探针视频面部图像中区块{1}存在遮挡时,将其在画廊集中进行匹配。假设画廊集有墨镜和口罩两类遮挡区域以及无遮挡区域;其中墨镜遮挡的区块为{3,5};口罩遮挡的区块为{7,8}。此时,结合探针视频,可以划分出三类区域:{1}、{1,3,5}以及{1,7,8}。对于每一类区域选择对应掩码,并计算探针与画廊集中该类目标的相似度,再进行类内纵向排序与跨类区域横向比较:首先,对{1,3,5}区域以及{1,7,8}区域中排名最高的相似度所代表的画廊集视频进行比较,遮挡区块设置为{1,3,5,7,8};其次,查找字典选择掩码后再次与探针计算相似度,相似度高的留下与{1}区域进行相同步骤的比较,得到最相似的画廊集视频;最后,对区域内排序结果第二的目标进行相同步骤的跨类区域横向排序。
3.4 网络训练及再识别
本文所提出的监控视频人脸再识别算法的完整训练过程包括以下三步:
1)使用CASIA-WebFace[11]数据集训练主干网络,损失函数采用大边缘余弦损失函数[34];
2)构建PDSN 网络,载入主干网络的模型的权重,并用成对图片进行训练并构建掩码字典;
3)固定主干网络权重,用视频帧图像序列训练时间注意力机制网络。
在大多数再识别应用场景中,用户的ID无法事先获得。因此画廊集需要随着摄像头拍摄时间而不断扩充,即为再识别问题中的开集再识别。当目标出现在摄像头下时,应首先判断是否为新目标。我们用G={G1,G2,…,GN}表示画廊集,用P={P1,P2,…,PN}表示探针集。对于一个探针Px∈P,其采取分区域匹配策略得到的最终排序结果可用公式(7)进行判断是否为新目标。
其中,dist 是Px和Gi的距离,Y是阈值。当最大的余弦距离低于阈值,则判断探针不在画廊集中,需要为其注册一个新的ID 并添加到画廊集。若超过阈值,则用公式(8)获得与Px⊆P相匹配的ID。
4 实验及结果分析
4.1 实验设置
4.1.1 数据集
COX 人脸监控视频数据集[35]是一个由3 台摄像机拍摄,拥有1000 个不同的ID 以及3000 段视频序列的数据集。和传统人脸视频数据集相比,COX包含更多在姿势、表情、光照、模糊和面部分辨率等方面有自然变化的帧。由于COX 数据集中人的面部没有遮挡,为了验证本文算法,我们在此数据集基础上使用文献[36]的方法补充了常见的面部遮挡。
4.1.2 场景设置
实验中,我们共选取了三种不同场景,如下:
(1)画廊集与探针集均不存在遮挡。
(2)画廊集不存在遮挡,探针集均存在遮挡。
(3)探针集与画廊集同时存在遮挡与非遮挡的视频。
4.2 实验结果
4.2.1 时间聚合技术方法的对比
在本文实验中,Baseline 对应的是文献[33]提出的改良的Resnet50 模型,并在基于图像的人脸数据集CASIA-WebFace 上用大边缘余弦损失函数进行训练。Baseline 会在匹配的两段视频中随机抽取一帧图像计算相似度。为验证不同时间聚合方式的识别效果,我们将Baseline 与多帧特征向量求均值(Avg)、平均池化(AvgPool)、最大池化(MaxPool)和时间注意力机制(TA)动态分配权重等不同时间聚合方法分别结合测试效果。为了评估实验结果,我们使用了rank-n和mAP作为评价指标。rank-n表示的是搜索结果中前n项里存在正确结果的概率。mAP 表示平均准确率,用于衡量算法的搜索能力,测试结果如表1 所示。从表1 中可以发现:通过注意力机制(TA)动态分配权重有着最好的效果;而平均池化(AvgPool)或最大池化(MaxPool)操作会削弱或过度强调有代表性特征的贡献,导致准确度不如TA。

表1 画廊集与探针集人脸均无遮挡情况下准确率(%)Tab.1 Accuracy(%)with unobstructed faces in both gallery set and probe set
4.2.2 掩码字典的有效性验证
我们在画廊集无遮挡而探针集均有遮挡的情况下测试了掩码字典(MD)的效果,实验结果如表2所示。可以看出,“TA+MD”的组合方式对再识别的准确度有明显提升。这是因为掩码字典方法会在识别中对遮挡元素进行定位并排除影响。然而实际情况中,监控摄像头首次拍入的面部图像就可能带有遮挡,从而造成画廊集中的数据特征缺失。
我们进一步测试了画廊集与探针集同时存在遮挡与非遮挡情况下的人脸再识别,测试结果如表3 所示。可以看出,相比于表2,随着暴露的面部特征变多,不使用掩码字典的准确度有所提升,但使用掩码字典后的准确度却显著的下降,特别是在“Baseline+MD”的情况下,准确率甚至低于只使用Baseline的情况。

表2 画廊集人脸无遮挡,探针集人脸均存在遮挡情况下准确率(%)Tab.2 Accuracy(%)of gallery set with unobstructed faces and probe set with obscured faces
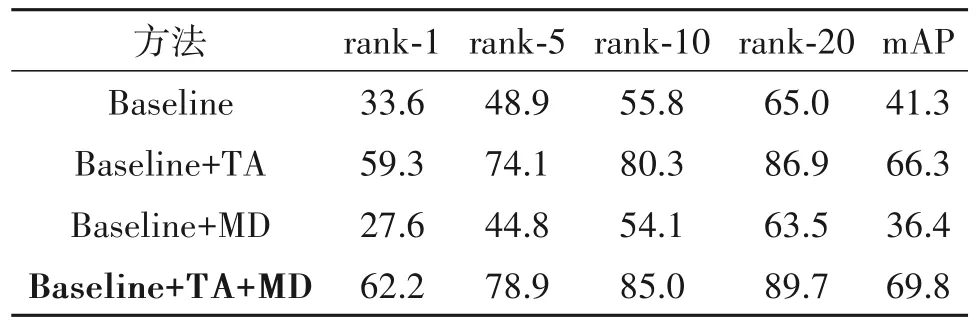
表3 画廊集、探针集人脸同时存在遮挡与非遮挡情况下准确率(%)Tab.3 Accuracy(%)in the presence of both occlusion and non-occlusion for gallery set and probe set faces
此种异常情况的可能原因是由于掩码会把遮挡的元素设置为零,随着丢弃的元素越多,最终得到的特征向量间的相似度越高(即使是不同ID)。这就会导致遮挡视频间的相似度(不同ID)高于未遮挡视频间的相似度(相同ID),且随着丢弃阈值μ的提高,这个问题会愈发严重。为了验证猜测,本文设置了不同的丢弃阈值来测量rank-1 的准确率,测试结果验证了我们的猜想,结果如表4 所示。可以看出,随着丢弃阈值的增大,匹配的准确率越低。在画廊集中全是清晰无遮挡的视频帧时,这个现象并不会造成匹配准确度大幅度下降。这是因为探针与画廊集进行匹配时丢弃了相同区域的特征,探针视频与画廊集每段视频相似度都会提高但不会改变排序,但在画廊集与探针集都存在遮挡与非遮挡时,会改变相似度的排序导致再识别出现误差。
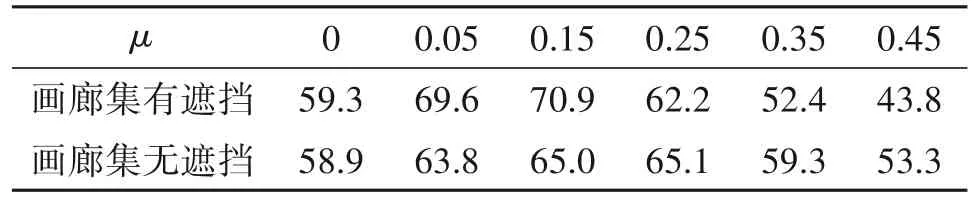
表4 不同丢弃阈值μ对再识别rank-1准确率(%)的影响Tab.4 The effect of feature discarding threshold to rank-1 accuracy(%)
4.2.3 分区域匹配的有效性验证
为了解决掩码字典在再识别中出现的问题(即随着遮挡区块的增多,丢弃的特征会越多,两段视频的相似度也会越高),我们提出了分区域匹配(SRM)的方法来降低掩码字典造成的误差。测试的结果如表5 所示,可以看出依靠分区域匹配的方法可以显著降低掩码字典在再识别下的误差。特别是当丢弃阈值越大、或遮挡越严重时,该方法的准确率越高。这是由于我们的匹配方法在进行相似度排序时,考虑到了特征元素丢弃后造成的误差,并额外使用相同掩码进行了一次判断。当丢弃阈值达到0.25时,分区域匹配方法达到了73.0%的准确率,而原方法准确率只能达到62.2%。

表5 不同的丢弃阈值μ在画廊集、探针集人脸同时存在遮挡与非遮挡情况下rank-1准确率(%)Tab.5 Different discard thresholds μ in gallery set,probe set faces with both occlusion and non-occlusion case rank-1 accuracy(%)
4.2.4 与经典方法的对比
本文的方法与传统的人脸识别方法在各个数据集上进行了对比,我们复现了几个经典的人脸识别模型,并使用相同的数据集CASIA-WebFace 进行了训练,最后在3种不同的数据集上进行了测试,测试结果如表6 所示。其中LFW[10]是一个标准的人脸测试基准数据集,拥有6000 对测试图像。COXMasked 为探针集与画廊集同时存在遮挡与非遮挡面部图像的视频数据集。对于COX 与COX-Masked数据集,我们的方法使用时序注意力机制为多张图片分配不同权重;其他几种方法则选取相同的图片,并对得到的特征向量求取均值,以此代表整段视频的特征。

表6 不同方法在各个数据集上的准确率(%)Tab.6 Accuracy(%)of different methods on each dataset
可以看出,本文方法在三个不同的数据集上均展现出较好的识别结果。另外,虽然在LFW 上未能有最好效果,但在监控视频数据集下,特别是当面部出现严重的遮挡时,传统方法的准确率大幅度下降,而我们的方法依然能保持较好的识别效果。
5 结论
本文提出了一种基于深度学习的人脸再识别算法,该方法通过结合注意力机制和掩码字典,并依靠提出的分区域匹配方法,降低了掩码字典在再识别场景下的误差,有效提升了监控视频下人脸再识别的准确率。该方法解决了基于全身特征的再识别方法无法长期进行再识别的缺陷,并通过对面部遮挡进行处理,提高了面部存在遮挡时的再识别准确率。在合成遮挡的COX 数据上的实验结果表明,本文所提方法可以充分利用面部的有效特征提升深度模型的面部遮挡鲁棒性,进而实现长期可靠的再识别。
本文研究专注于监控视频中面部特征的再识别。实际应用中,监控视频的清晰度、分辨率、光照等因素难免对识别准确率造成影响。下一步,我们将研究对衣着服饰及姿态等信息的可靠性评估,并将上述特征与面部特征融合匹配,以进一步提高再识别准确率。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
临床肺科杂志(2021年5期)2021-04-27
动漫星空(2018年9期)2018-10-26
北京航空航天大学学报(2017年2期)2017-11-24
小天使·二年级语数英综合(2016年5期)2016-05-13
劳动保护(2015年10期)2015-12-02
小朋友·快乐手工(2015年6期)2015-07-01
卷宗(2014年7期)2014-08-27
奇闻怪事(2014年5期)2014-05-13
