
基于UPE-SVM模型的脊髓损伤康复方案决策算法
2022-07-15 09:54秦常程喻洪流李素姣郑金钰杨宇辉
智能计算机与应用 2022年7期
秦常程,喻洪流,李素姣,倪 伟,郑金钰,李 平,杨宇辉
(1上海理工大学 康复工程与技术研究所,上海 200093;2上海康复器械工程技术研究中心,上海 200093;3民政部 神经功能信息与康复工程重点实验室,上海 200093)
0 引 言
脊髓损伤是由车祸、坠落、暴力和体育运动等原因导致的脊椎结构和功能上的损伤。根据相关调查,中国每100万人中就有20~60例脊椎损伤病例。在脊髓损伤患者的全面康复中,合理的康复治疗方案可以帮助脊髓损伤患者促进身体功能恢复,提高生活自理能力。
康复治疗方案的决策是建立在对患者充分的康复评估基础上,由多种康复治疗技术组成。目前,中国还没有独立的康复治疗方案决策服务体系,而线下康复治疗方案的决策存在效率低下且标准不一等问题。
在线的医疗智能处方决策可以弥补线下的不足。如:Douglas D等人设计了一套可以在线量表评估,并给脑卒中患者提供康复建议的专家系统REPS。Danial-Saad A等人提出了一种使用计算机辅助技术实现的康复辅具处方推荐算法。虽然在线医疗智能处方决策理论可以弥补线下的不足,但是在实际操作中仍然存在如下问题:
(1)在线的医疗智能处方决策应依赖推理模型和大样本医疗数据集,但是鉴于脊椎损伤的发病率和医院对患者的隐私保护,往往不会形成大样本医疗数据集;
(2)医疗数据集通常存在样本类别不平衡问题,各类别之间存在严重的数量倾斜。
综上所述,本文在医疗智能处方决策算法设计的基础上,针对脊髓损伤患者的智能康复治疗方案决策及其病例数据集样本类别不平衡等问题,提出一种用于脊髓损伤智能康复治疗处方的UPE-SVM推理模型。该模型有效克服了数据集的样本类别不平衡问题,提高了智能康复治疗处方的决策准确率。
1 康复治疗方案决策算法概述
1.1 决策过程
康复治疗方案决策算法的主要流程包括患者信息输入、基于UPE-SVM模型预测、治疗方案生成和模型在线学习。决策算法流程如图1所示。

图1 康复治疗方案决策算法流程Fig.1 Flow chart of rehabilitation program decision algorithm
患者信息特征包括:AISA残损指数、损伤性质、神经节段分类、损伤平面、最低感觉平面、左上肢肌力、右上肢肌力、左下肢肌力、右下肢肌力,这9个特征是由治疗师确定的显著表现病人病情的特征。
基于UPE-SVM模型预测将患者的9个特征进行数值映射和特征归一化处理。特征归一化的目的是避免特征的不同量纲对决策结果产生负面影响,然后输入到UPE-SVM模型,进行前向推理预测,得到初始治疗方案。特征归一化的计算公式为:

治疗方案的生成是由治疗师进行判断初始治疗方案是否适合当前患者,如果适配病例,直接用于患者,并保存到病例数据库;如果不适配,则修正治疗方案后用于患者,并将最终治疗方案保存到病例数据库。
模型在线学习使用更新后的病例数据库,对UPE-SVM模型进行在线训练,保持模型对陌生病例的敏感性,提高模型的学习能力和泛化能力。
1.2 决策示例
在此给出1个示例,说明上述智能康复治疗方案决策算法的决策过程。假设一患者具有如表1所示的9个输入特征。

表1 示例患者的9个输入特征Tab.1 Nine input characteristics of the sample patient
这9个特征值经过数据处理后,输入到UPESVM模型进行预测,程序以列表的形式给出初始治疗方案:[“针灸”,“康复踏车”,“站立训练”,“脉冲磁疗”,“气压式血液循环驱动”],供治疗师参考和修正,并将最终治疗方案保存到数据库,用于更新模型。
2 基于集成学习的UPE-SVM推理模型
本文使用的脊椎损伤病例数据集包含124条样本,划分为包含100条样本的训练集和包含24条样本的测试集,每条样本由输入特征和康复治疗方案组成。康复治疗方案作为目标值,包含6类康复治疗技术,每条样本的康复治疗方案为6类康复治疗技术的部分组合,因此该分类属于多标签分类任务。针对该数据集,本文提出一种用于脊髓损伤康复治疗方案决策的新型推理模型——UPE-SVM(Undersampling Parallel Ensemble Support Vector Machines)。
2.1 模型预测
在模型预测方面,UPE -SVM模型基于集成学习,采用SVM(Support Vector Machines)作为子分类器。针对本文数据集,UPE-SVM模型设置6簇分类器,分别对应数据集的6类康复治疗技术,每簇分类器单独预测1类目标值,把复杂的多标签分类转化为简单的二分类。每簇分类器设置多个子分类器,子分类器之间平权投票,决定该簇分类器的预测结果。子分类器的数量为模型超参数,与多数样本和少数样本的数量比值相关。集合6簇分类器的预测结果,得到康复治疗方案。
给定脊髓损伤病例数据集{,,,…,x},第簇分类器包括个子分类器,分别是(),(),(),…,f(),则对于样本x的第簇分类器的预测结果为:
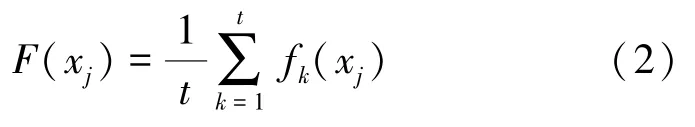
对于全部样本的康复治疗方案预测结果为:

2.2 模型训练

对于每个子分类器,通过调节核函数和惩罚系数,选择效果好的SVM作为子分类器。SVM超参数值域见表2。

表2 SVM超参数值域Tab.2 SVM hyper parameters and range
核函数是一种将非线性任务转变为线性任务的方法。其中,linear为线性核函数;poly为多项式核函数;rbf为高斯核函数;sigmoid为双曲正切核函数。
惩罚系数用来控制损失函数惩罚力度,惩罚系数越大,对错误分类的惩罚越大。经实验验证,本文核函数选择poly,惩罚系数为155。
3 实验分析
3.1 数据集
脊髓损伤病例数据集来自中国康复研究中心,筛选自2019年入院的124个病例作为数据集,划分为包含100条样本的训练集和包含24条样本的测试集,每条样本由症状和康复治疗方案组成,症状为UPE-SVM模型的输入特征,康复治疗方案为目标值。
症状是由治疗师基于临床经验选取的患者特征,其中包括:AISA残损指数、损伤性质、神经节段分类、损伤平面、最低感觉平面、四肢肌力等,见表3。

表3 脊椎损伤症状及值域Tab.3 Symptoms and range of spinal injury
表3中,根据鞍区功能的保留程度,将损伤性质分为完全性损伤和不完全性损伤;根据脊髓损伤神经学分类国际标准,AISA残损指数分为A~E共5个等级;根据解剖学,损伤神经节段分为颈椎损伤、胸椎损伤、腰椎损伤、骶椎损伤和尾椎损伤;根据损伤节段和功能,损伤平面和最低感觉平面分为31类,分别对应31对脊神经;根据改良Asworth分级,四肢肌力分为0~5共6个级别。
康复治疗方案是由治疗师根据患者具体症状给出,包含30种康复治疗技术,每种康复治疗技术的出现频率不同,其中19种康复治疗技术出现频率少于10次,3种康复治疗技术出现频率超过80次。由于数据集存在严重的类别不平衡问题,导致训练得到的模型效果不佳,模型容易过拟合。因此对康复治疗方案进行种类选定,选择出现频率超过20次的康复治疗技术,作为模型的目标值,见表4。

表4 选定的康复治疗技术及其出现频率Tab.4 Selected rehabilitation techniques and their frequency
3.2 评价指标
本文以值和作为主要评价指标,以精确率和召回率作为次要评价指标,来评估模型性能及衡量模型克服类别不平衡的能力。值为曲线下方的面积,取值范围在01,取值越大,表示模型性能越好。
3.3 实验设计
现有解决数据集样本类别不平衡的常用方法,包括两个层面:算法层面和数据层面。算法层面主要采用损失函数Focal Loss,数据层面主要采用SMOTE重采样。
为了验证UPE-SVM模型在脊椎损伤病例数据集上的性能,本文将解决样本类别不平衡的常用方法进行对比,设计了5组对照实验,分别是:采用交叉墒损失的多层感知机、采用Focal Loss的多层感知机、采用SMOTE重采样的SVM、采用无放回采样的UPE-SVM和采用随机有放回采样的UPE-SVM。
除给出5组对照实验的结果外,本文还统计了分别采用无放回采样和随机有放回采样的UPESVM模型在每一类康复治疗技术上的具体表现。
3.4 结果分析
3.4.1 5组对照实验结果分析
从表5中可以得出,采用交叉熵损失的多层感知机分类效果最差,采用Focal Loss的多层感知机效果略好于前者,Focal Loss对本文数据集的样本类别不平衡有一定的效果;采用SMOTE重采样的SVM效果略好于前两者;第四、五组实验表明,UPE-SVM模型克服样本类别不平衡的性能远远超过采用Focal Loss的多层感知机和采用SMOTE重采样的SVM,且随机有放回采样策略优于无放回采样。

表5 对照实验的结果Tab.5 Results of the control experiment
3.4.2 无放回采样/随机有放回采样的UPE-SVM对6类目标值分类性能结果分析
从表6和表7的对比中可以得出,与无放回采样相比,随机有放回采样的UPE-SVM模型在“康复踏车”、“站立训练”、“脉冲磁疗”、“气压式血液循环驱动”上的分类效果更优,在“作业康复”上的效果持平,在“针灸”上的效果略低。从总体的分类性能上看,随机有放回采样的策略优于无放回采样。

表6 无放回采样的UPE-SVM分类性能结果Tab.6 Classification performance results of UPE-SVM without sampling back

表7 随机有放回采样的UPE-SVM分类性能结果Tab.7 UPE-SVM classification performance results with random sampling back
相比其它克服类别不平衡的常用技术,UPESVM模型使用所有的少数样本,采样与少数样本数量相同的多数样本,组成训练子集,保证了每个训练子集是样本均衡的,因此训练得到的子分类器能够有效避免样本类别不平衡影响。
相比无放回采样策略,随机有放回采样的UPESVM模型表现更加优异。当采用无放回采样训练子分类器时,即划分多数样本为固定的若干份,每份样本之间不存在交集,训练得到的子分类器是有缺陷的,不利于集成学习平权投票。通过理论分析和测试集验证,随机有放回采样的训练策略更能提高UPE-SVM模型的性能表现。
4 结束语
本文设计的脊髓损伤康复治疗方案决策的UPE-SVM推理模型,有效解决了采用医疗数据集训练模型时,经常出现的样本类别不平衡问题,并在测试集上取得较好的效果,提高了康复治疗方案的决策准确率。这种技术的应用有望帮助解决脊髓损伤患者的康复治疗方案决策的不足,同时对其它中小型复杂数据集的多标签分类任务有一定的参考意义。
猜你喜欢
计算机时代(2022年9期)2022-11-03
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
中国典型病例大全(2022年9期)2022-04-19
少儿画王(3-6岁)(2020年4期)2020-09-13
少儿科学周刊·儿童版(2019年3期)2019-05-15
中文信息(2018年6期)2018-08-29
东方教育(2018年20期)2018-08-22
大众健康(2017年9期)2017-09-05
软件导刊(2017年4期)2017-06-20
