
基于时变散射特征与CNN 的双极化SAR作物分类
2022-07-15 19:23白清源李恒辉
上海航天 2022年3期
郭 交,白清源,李恒辉
(1.西北农林科技大学机械与电子工程学院,陕西 杨凌 712100;2.陕西省农业信息感知与智能服务重点实验室,陕西杨凌 712100)
0 引言
极化合成孔径雷达(Polarimetric Synthetic Aperture Radar,PolSAR)作为一种先进的遥感技术,以其全天候、多极化的优势在遥感领域得到了广泛的应用和研究。目前,针对PolSAR 数据提出的分类算法大致可分为3 大类:第1 种方法是基于统计模型和电磁散射机理的分类算法,如LEE等提出的复杂Wishart 监督分布分类算法。第2种方法是通过多种极化分解方法和参数反演技术提取目标的物理散射特征,提高分类性能。例如一些典型的极化算法,如Freeman 分解、基于Freeman 开发的Yamaguchi 方法和各种分解方法,已广泛用于PolSAR 图像。第3 种方法基于深度学习分类,其目的是利用深度学习良好的特征提取能力来提高分类精度,主要工作是基于Pol-SAR 数据的特征改进深度学习网络结构,或者改进深度学习的特征输入,进一步提高深度学习的性能。如CHEN 等和GUO 等试图通过使用特征分解方法获得的分类特征作为卷积神经网络(Convolutional Neural Network,CNN)模型的输入,进一步提高深度学习的分类性能。
然而,这些算法仍然存在一些缺点。例如基于统计模型的方法直接采用协方差矩阵,其计算效率较低,主要原因是协方差矩阵的信息冗余,大多数极化参数反演算法最初是针对四极化SAR 数据集提出的,不能应用于双极化SAR 数据集。与全极化SAR 数据相比,双极化SAR 系统存在一定的信息损失,这将降低作物分类结果的准确性。为了处理双极化SAR 数据,一些研究人员提出了双极化SAR 数据的分解算法,然而这些方法分析了HH 和VV 的双偏振模式,没有给出更多的散射参数。因此,迫切需要对双极化SAR 数据集提出有效的极化处理方法和参数,以便更好地解释目标的物理散射机制。经典的分解可以有效地应用于双极化分解中,对具有相同散射特性的人造结构和裸土进行分类,并获得良好的分类性能。然而分解不能直接应用于作物分类,因为主要原因是作物散射特性的变化,因此有必要结合参数的分布特征和作物的形态特征来提高分类结果。本文引入了一种新的基于分解的极化参数来度量分布变化的特征,重点研究了双极化特征分解问题,试图利用该方法对双极化数据进行分解,得到一组新的双极化特征,并结合CNN 分类方法提高作物分类精度。
本文首先介绍了双极化SAR 数据的传统极化参数及其定义和计算,其次比较了不同特征向量的CNN 分类器和使用Indian Head 农场数据的复杂Wishart 分类器的分类结果,并对实验结果进行了分析和讨论,最后进行了总结。
1 方法
1.1 极化相干矩阵
在VV-VH 模式下,双极化SAR 的散射矩阵可形成为

式中:、为2 个独立极化通道的散射元素,下标“H”和“V”分别为水平和垂直线性极化。第个像素的多视协方差矩阵表示为

通常,相干矩阵可以更好地表示目标的散射特性,第个像素的泡利散射矩阵为

为了确保散射向量的范数不变,该向量可以写为

式中:j 为虚数单位。
基于双极化SAR 数据的多视相干矩阵为

因此,将选择相干矩阵的对角线信息作为特征向量的一部分。
CAVES提出VV-VH 极化更适合于农业作物分类。因此针对AIRSAR 数据集,从VV-VH 模式中提取相干矩阵的对角信息以及和的参数。
1.2 H/α 分解中的隐藏极化特征
目标的散射特性由雷达信号决定,农作物在不同的生长阶段会表现出显著的差异。基于分解算法的基本理论,GUO 等提出了一个新的偏振参数来测量作物在不同生长阶段的散射特性。
分解基于相干矩阵的特征分解,可分解为

式中:λ为特征值;u为相应的特征向量。
每个特征向量表示为对应于α、β、ϕ和δ的4个角度:

因此极化熵(即)和平均散射角(即)定义如下:
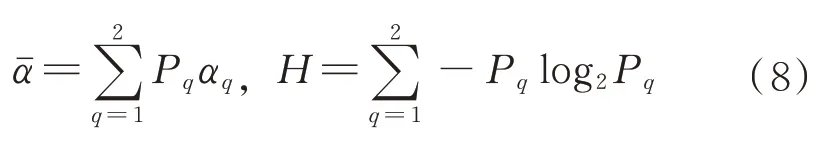
、都清楚地描述了介质的散射特性,该平面被定义并划分为9 个子区域,用于目标识别和分类,如图1 所示。因此,在下一节将选择和的参数作为特征向量的一部分。

图1 双极化PolSAR 数据的H-α 平面散射区域划分Fig.1 Division of the H-α plane for dual-PolSAR data
新定义的参数在分类平面中的定义如图2所示。不同作物在不同生长阶段的散射参数将沿着分类平面的下边界向上和向右移动(即参数值逐渐增加),如图2(a)中的红色箭头线所示,而不同种类的作物会随着自身的生长周期而变化,与散射特性相对应的分布移动量会有显著差异。
首先在分类平面中选择1 个参考点,计算出每次训练样本集的质心,并可以根据训练的质心的分布近似地构造线,从而得到的垂直平分线;再使用整个图像中所有散射的最高和最低熵连接形成水平轴上的线,得到的垂直平分线,和的交点即为新参数的参考点位置,如图2(b)所示。因此,可以获得图2(c)所示的高度参数来描述变化。

图2 生长期H-α 分布区的变化Fig.2 Changes of H-α distribution zone during the growing period
1.3 构建的CNN 分类器
卷积神经网络是深度学习方法中最成功的网络算法之一,已成为计算机视觉领域取得突破性成果的基石。它具有良好的特征提取能力,在大规模目标识别、语义分割、地物分类等遥感领域得到了广泛的应用。然而,在遥感分类的实际应用中,地面验证数据的建立一直是一项艰巨的任务。
为了在不牺牲分类精度的前提下构建轻量级分类网络,本文借鉴了GoogleNet 的网络特性,采用两个分支的卷积运算来完成分类任务,所提出的CNN 分类结构如图3 所示。

图3 CNN 分类器结构Fig.3 Architecture of the CNN classifier
该网络主要由4 个卷积层(Conv1,Conv2,Conv3,Conv4)、1个平均池化层(Average pooling)、1 个Addlayer 层、1 个全连接层(Fully connect)和1 个Softmax 分类器组成,采用了两卷积分支来对输入特征进行不同层次特征提取,在双分支卷积输出末端,添加了平均池化层来减少全连接层的训练参数数量,减少网络复杂度。输入数据的大小为15×15×,其中为输入特征的数量。输入首先经过32 个大小为5×5 的卷积核组成的卷积层,卷积核步长(Stride)为1,通过零填充操作保持输出特征大小不变。然后将15×15×32 的输入特征分别输入2 个分支中,其中一条卷积分支包含2 个卷积层,另一条分支包含1 个卷积层。在这3 个卷积层中,都具有相同3×3 大小的卷积核,且都为64 个卷积核组成的卷积层,3 个卷积层卷积步长分别为2、1、2。需注意的是,每层的卷积后都添加了批标准化BN 和ReLU 非线性整流激活函数对输出特征进行激活处理,并将激活特征作为下一层的输入。在完成2 个卷积分支的运算后,得到2 个8×8×64 大小的特征图,通过Addlayer 层将两相同大小的输入相加得到8×8×64 的融合特征,使用1 个2×2、步长为2 的平均池化层对合成图进行下采样。最后采用平均池化层和全连接层将Addlayer 层输出的融合特征转化为个神经元输出,输出值经过Softmax层获得每个神经元对应的概率结果,取最大概率为分类结果,即完成分类。
与CHEN 等所提出的CNN相比,本文的CNN 结构由单路结构改为了双分支结构,进一步对数据特征进行了提取,选用Adam 作为模型优化函数以及交叉熵损失函数,迭代次数为10 000,学习率为0.000 5。
2 实验结果与分析
2.1 结果与分析
本文中的数据集是来自欧空局AgriSAR 项目的多时相双极化SAR 数据。研究区域是位于加拿大Indian Head(103°40'32.2'' W,50°38'11.0'' N)约11 km×16 km 的矩形区域。数据收集日期为2009 年4月21 日、5 月15 日、6 月8 日、7 月2 日、7 月26 日、8 月19 日和9 月12 日,几乎涵盖了该地区主要作物的整个生长阶段。Google Earth 的图像、VV 通道的SAR强度图像和地面真实数据如图4 所示。精细共配准已经完成,散斑噪声抑制是通过CAVES 等文中的平均结构Lee 滤波器的多时间滤波来实现的。

图4 加拿大Indian Head 地区作物分布Fig.4 Images for the crop distribution of Indian Head in Canada
在实验部分本文使用了4 种分类方法:1 种基准分类方法和3 种特征输入方法(、强度;、强度;、、、强度),其中强度代表VV 和VH。4 种分类方法是复Wishart 基准分类法、支持向量机(Support Vector Machine,SVM)、文献[17]提出的CNN 分类方法和本文提出的CNN 比较方法,利用多时相印第安农场对实验进行了验证。实验重复5 次,随机抽取1%的样本进行训练,并对整个图谱进行预测和比较,对多种分类方法的结果进行了定量比较,所有分类器的实验参数保持不变。
Indian Head 数据集中有6 个主要杂交品种(油菜、豌豆、亚麻扁豆、春小麦、牧草)。所有对照组中每种作物的分类精度见表1。
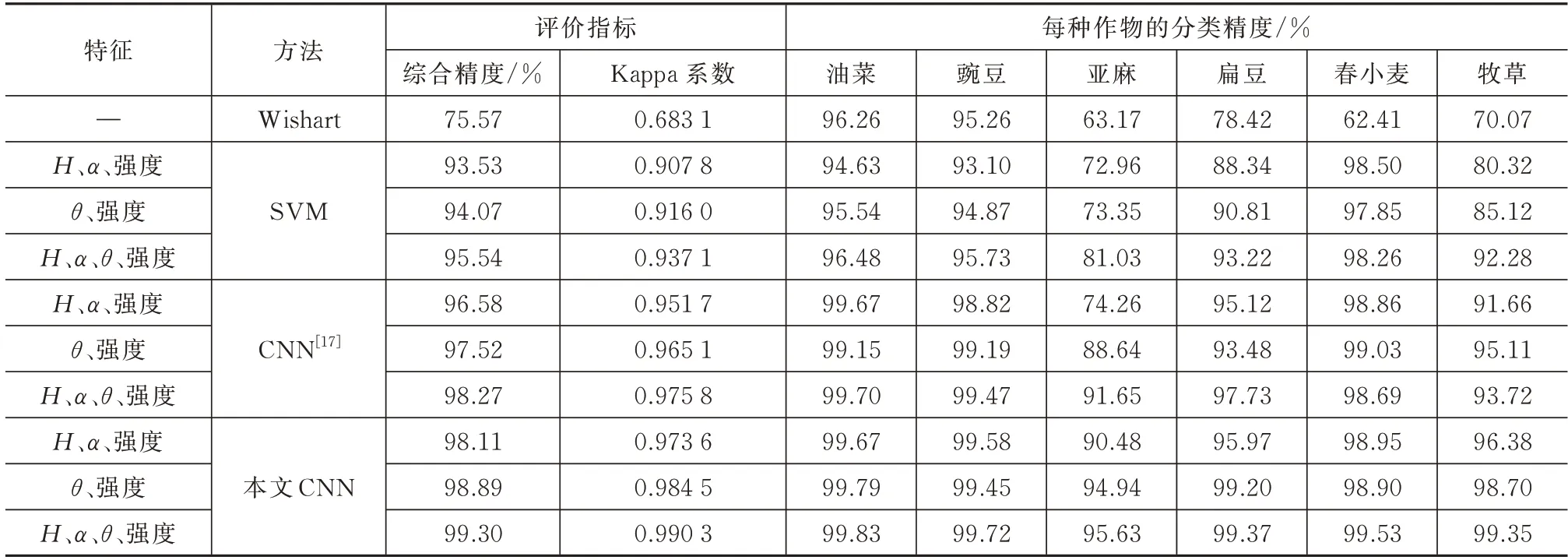
表1 分类精度比较Tab.1 Comparison of the classification accuracy
图5 中上方图为4 种模型的分类结果图,下方为其对应的分类误差图。比较不同输入下的分类结果,可以看出(、、、强度)的组合在所有分类器下都达到了最好的分类性能。此外,比较(、强度)和(、、强度)输入组合的分类性能可以发现,3 种(、强度)特征组合可以获得相对较弱的分类优势,由此可见,本文提出的参数可以稳定地提高Indian Head 数据的分类性能。比较不同分类方法的分类性能,可以得出结论,(、、、强度)+CNN 的组合在对照组中达到最高的分类精度。OA 和Kappa 的分类准确率分别为99.30%和99.03%。

图5 Sentinel-1 数据集的分类结果Fig.5 Classification results of the Sentinel-1 data sets
与传统的复Wishart 方法相比,分类精度至少提高了24%。通过与特定作物的分类性能比较,可以看出本文提出的CNN 分类方法主要提高了亚麻的分类精度。
2.2 讨论
在分类任务中,分类特征和分类器方法决定了分类任务的性能。因此,从这两个方向出发已经成为提高分类精度的一个重要方向。作为对双极化数据目标分解技术的补充,本文对基于特征分解提出的时变特征角参数进行了比较研究。
与传统的Wishart 和SVM 分类方法相比,分类精度有了很大的提高。对比不同输入特征的分类精度,发现与、、强度特征组合相比,本文提出的特征能够稳定有效地提高双极化数据的分类精度。因此,从两个方面提高双极化数据的分类精度是可行的。然而,需要指出的是,本文提出的角参数在多种类型的样本中可能达不到理想的结果,其原因可能是多种作物在太多的作物中具有几乎相同的生长和变化特征。在有限双极化特征分解中,参数仍然可以作为一个有力的补充。此外,极化目标分解特征驱动的CNN 分类方法已被证明是一种非常有效的分类方法。总之,新引入的参数可以进一步改善农业作物分类结果。
3 结束语
为提高双极化SAR 图像的作物分类效果,建立了分解特征驱动的深度CNN 方法,提取双极化图像中隐藏的特征和极化特征,完成作物分类。在不同的数据集和分类方法中,基于分解的新参数可以达到与参数相近的分类精度。此外,在所有分类器中,新参数与特征相结合可以提高分类精度,表明特征参数可以作为双极化分类的有效补充。此外,本文提出的CNN 分类器能够显著提高双极化分类的精度,并在比较方法中获得最佳的分类效果,证明了该方法的有效性。
猜你喜欢
计算机时代(2022年9期)2022-11-03
农业工程学报(2022年12期)2022-09-09
现代电子技术(2022年15期)2022-07-28
民族文汇(2022年23期)2022-06-10
航天电子对抗(2022年2期)2022-05-24
电子产品世界(2022年4期)2022-04-21
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
