
针对联邦学习的组合语义后门攻击
2022-07-15 09:53林智健
智能计算机与应用 2022年7期
林智健
(东华大学 计算机科学与技术学院,上海 201600)
0 引 言
随着人工智能技术的快速发展,基于深度学习模型的应用已经进入了人们的生活。伴随着神经网络的发展和应用的普及,深度学习模型的安全问题也受到研究人员的关注。机器学习算法的训练需要广泛的隐私敏感数据,保证数据隐私不被泄露,对数据持有者的重要性不言而喻。为了保护用户的隐私数据,McMahan等人提出去中心化的联邦学习(Federated Learning)方法。这是一种全新的联邦多方数据训练深度学习模型的分布式学习方法,该方法不需要参与者共享私密的原始数据,因此引来学术界越来越多的关注。
由于使用分布式方法构建的机器学习模型,恶意用户能够通过操控本地模型的训练来影响全局模型,并通过构建恶意模型,从而实现预期的攻击效果。而联邦学习的方法提高了许多攻击的效力,并增加了防御这些攻击的挑战,在保证训练模型可用性的同时保护了参与者数据的隐私性。
目前,从攻击者对模型造成的影响来看,攻击主要分为两种类型:无目标攻击和有目标攻击。无目标攻击的目的是降低模型的全局精度或使全局模型无法收敛;而有目标攻击的目的,是在保持模型整体准确性良好的情况下,对特定样本有较高的错误分类准确率。其中,有一种危害性比较大、且难以被发现的攻击,叫做后门攻击。
后门攻击通过向神经网络注入后门网络(Trojan Neural Network)来实现模型错误分类的攻击效果。后门攻击只有当模型得到特定输入时才会被触发,然后导致神经网络产生错误输出,因此非常隐蔽不容易被发现。
现有的针对后门攻击的防御方法主要是通过仔细检查训练数据,或者对模型进行重新训练,又或是建立检测模型(检测器)对训练完的模型进行检测。而联邦学习训练过程中,主流的防御机制是拜占庭弹性聚合机制,弹性聚合机制通常用一个稳健的平均估值来对客户端提交的参数更新做聚合。
从后门触发器的角度来看,后门攻击分为两种:一种是基于像素触发器的后门攻击,一种是基于语义触发器的后门攻击。基于像素触发器的后门攻击,是通过在训练样本中添加小部分像素作为固定模式,将其作为触发后门分类的特征。这种方式的缺点是容易被逆向工程等检测器方法检出。而基于语义触发器的后门攻击,可以使用物理场景中的自然特征(帽子或眼镜)作为触发器,当特定特征出现时触发后门分类。基于语义触发器的后门攻击比较灵活,并且不容易被检测器方法检出。所以本文的目标是使用更灵活且更有现实意义的语义后门攻击,对联邦学习模型进行攻击。
现有针对联邦学习的后门攻击主要有两种方式,一种是集中式的后门攻击,一种是分布式的后门攻击。现有的基于传统集中式的后门攻击,没有考虑到联邦学习里分布式的特性,攻击者使用全局触发器对联邦学习进行攻击,这样的攻击很容易被拜占庭聚合机制过滤。所以文献[5]提出了分布式后门攻击。攻击者们定义一个全局触发器,然后划分成多个局部触发器分给多个攻击者,每个攻击者使用局部触发器训练本地后门模型,并对联邦学习进行攻击。这种方法的攻击误触率很高,局部触发器很容易触发后门分类,并且在拜占庭聚合机制下效果不佳。
因此,本文希望能够充分利用分布式的特性设计一种针对联邦学习的语义后门攻击方法,更加有现实意义且在拜占庭聚合机制下也能有较好的攻击成功率,并且不易被逆向工程检测器检出。
1 联邦学习系统实现
联邦学习系统架构和主要组成如图1所示。系统中有多个参与方共同参与训练模型,并将模型参数上传至参数服务器,由参数服务器负责存储、更新、聚合各个参与者每一轮上传的参数,最终得到多方共同训练的模型。通过这种方式,不仅保护了用户数据样本的隐私安全问题,也避免了局限训练集的单个本地模型容易过拟合的问题。通过服务器端的参数聚合机制,使得在本地样本数量有限的情况下,获得更具泛化性的模型。

图1 联邦学习系统架构Fig.1 Federated learning system architecture


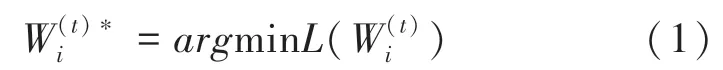
每个参与者都会使用统一标准的神经网络算法训练模型,使用的神经网络算法不局限于简单深度神经网络与卷积深度神经网络,但所有参与者需要统一进行。本文使用选择性随机梯度下降算法全连接层的卷积神经网络,本地模型网络多次迭代训练其本地训练集。在本地训练期间,不同参与者之间不需要额外的共享样本和交互,而是通过参数服务器的参数共享,间接影响彼此的训练结果。
当参与者上传模型参数时,参数服务器会将上传的参数值通过Federated Averaging算法聚合,得到本轮的模型参数更新,并计算更新全局参数W。

之后,服务器将聚合得到的全局模型分发给被选中的客户端,开启下一轮的本地训练。在多轮联邦学习过程后,模型损失函数会趋于收敛,最终得到性能较好的机器学习模型。此外,服务器端的模型参数聚合过程可以被灵活替换为不同的算法,如使用拜占庭环境下的鲁棒性聚合机制来抵抗参与者的恶意攻击。
联邦学习原型系统实现算法
:系统中参与者总数,参与者为(0≤)
D:参与者的本地训练集
:本地训练最小批量尺寸
:迭代总轮数
:学习率

2 组合语义后门方法设计
2.1 攻击概述
为了解决现有针对联邦学习后门攻击中存在的问题,本文提出了一个快速、高效的隐蔽方法,来对联邦学习发起后门攻击。该方法需要每个攻击者操作本地训练过程,使用攻击者精心设计的附加数据训练局部后门模型,利用联邦学习的聚合过程,将局部后门模型注入到最终的全局模型中,生成带组合语义后门的全局模型。攻击者上传的模型是局部后门模型,毒化程度低,所以攻击具有隐蔽性。
在神经网络中,一个内部神经元可以看作是一个内部特征。根据神经元与输出之间的链接权值,不同的特征对最终的模型输出有不同的影响。触发器的输入,可以激发标签的高度置信度,激活指定的输出分类标签。神经网络分类行为如图2所示。

图2 神经网络分类行为图示Fig.2 Neural network classification behavior illustration
根据以上神经网络分类原理,本文提出了一种新的针对联邦学习的后门攻击,称为组合语义后门攻击。该方法不是注入不属于任何输出标签的新特征,而是以另一种方式毒害模型。当来自多个标签的现有良性特性的特定组合出现时,其会错误地对目标标签进行分类。攻击者通过修改训练数据集来向全局模型注入后门。本文提出的后门注入方法的3个阶段是:攻击者指定后门特征和标签、训练生成局部后门模型、联邦学习聚合生成全局后门模型。下面本文以图像分类任务作为实例,对攻击过程进行概述。
2.2 攻击过程
训练生成局部后门模型
攻击者各选一个已有标签的类别作为局部触发器,并希望两个类同时出现时触发后门分类。
如图3所示,例中两个攻击者分别选择猫和狗作为局部触发器,鸟作为后门标签,并希望猫和狗同时出现在图像中时,模型会将其预测为鸟。

图3 指定触发器和目标标签Fig.3 Specifying triggers and target tags
训练生成局部后门模型
攻击者确定触发器后,下一步是本地训练局部后门模型,对从参数服务器下载的本轮全局模型进行再训练,使选定的触发器与后门标签的输出节点之间形成因果链。其实质是在触发器和所选后门标签之间建立起牢固的连接。当触发器出现时,所选神经元就会触发,导致输出后门标签。
如图4所示,在本文的后门攻击方法中,攻击者对局部触发器类对应的训练数据样本部分进行操作,将临时特征插入到这部分数据中,并修改其标签为目标类。这样在模型基于受污染的数据进行训练的过程中,会学习出触发器的模式,并将触发器与目标类联系起来。神经网络在攻击者1处学习到猫头特征对鸟类的贡献,并在攻击者2处学习到狗头特征对鸟类的贡献。

图4 本地局部后门模型训练Fig.4 Local backdoor model training
联邦学习聚合
通过联邦学习聚合,局部后门模型在参数服务器处聚合生成全局后门模型,最终组合特征的出现能够触发特定标签的分类。猫和狗的出现会触发后门分类结果为鸟类。联邦学习聚合生成全局后门的详情如图5所示。

图5 联邦学习聚合Fig.5 Federated learning aggregation
3 实验结果与分析
3.1 实验方案设计
本文基于CIFAR-10数据集进行了4组实验,分别对应着4种攻击。每轮有2个攻击者参与联邦学习。4种攻击在CIFAR-10数据集中的后门样本的图片示例如图6所示,后门样本的标签为攻击者设定的错误目标类。

图6 4种攻击模型的后门样本示例Fig.6 Example of backdoor samples for four attack models
分布式后门攻击(Distributed backdoor attack)中,攻击者使用添加局部触发器的后门样本,训练本地后门模型。后文简称该攻击为Distributed。
集中式后门攻击(Centralized backdoor attack)中,攻击者使用添加全局触发器的后门样本,训练本地后门模型。后文简称该攻击为Centralized。
本文提出的可组合语义后门攻击(Combinable semantic backdoor attack),是使用添加临时特征的局部触发器作为后门样本训练本地后门模型。
集中式语义后门攻击(Centralized semantic backdoor attack),攻击者使用可组合语义后门攻击中的全局触发器作为后门样本,来训练本地后门模型。该攻击为本文提出的可组合语义后门攻击的集中式版本,后文简称为Centralized semantic。
3.2 评估标准
本文从两方面的能力去评估后门攻击对全局模型的影响,包括不同聚合机制下的攻击成功率和攻击误触率。攻击能力主要通过攻击成功率(Attack Success Rate)进行量化。
:若受后门攻击的模型出现后门触发器的样本分类输出为标签T,则后门攻击成功;否则后门攻击失败。对模型的后门攻击成功率为:

其中,表示出现后门触发器的测试样本数量,n表示将出现触发器的测试样本错误分类为标签T的数量。
评估攻击的误触率,主要是观察网络模型在局部触发器出现时的表现,这里主要评估出现局部触发器样本的后门攻击成功率。如果受后门攻击的模型出现局部后门触发器的样本分类输出为标签T,则攻击发送误触。对模型的后门攻击误触率为:

其中,表示出现后门触发器的测试样本数量,表示将出现触发器的测试样本错误分类为标签T的数量。
3.3 结果与分析
3.3.1 后门攻击前后模型精确度对比
实验使用4种攻击训练神经网络,对模型分类准确率的影响见表1。从实验结果可见,4种攻击对模型准确率的影响比较接近,符合理论分析。后门模型对模型的正常分类影响较小,只在特定输入时发生目标分类,并且与联邦学习系统正常收敛情况下的训练相比,准确率下降并不高。
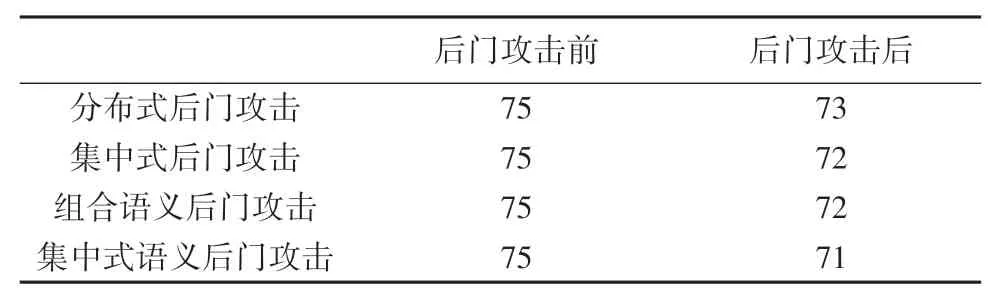
表1 模型精确度对比Tab.1 Comparison of model accuracy %
3.3.2 攻击成功率和误触率对比
4种攻击对Federated Averaging联邦学习的后门攻击效果及检测误触的实验结果如图7所示。图中每一种攻击有3列数据,分别是全局触发器的后门攻击成功率和两个局部触发器的后门攻击成功率。

图7 4种攻击模型的攻击成功率和误触率Fig.7 Attack success rate and false touch rate of four attack models
从图7中可以看出,组合语义后门攻击比分布式后门攻击的成功率要低,生成的后门模型毒性较弱,但局部触发器的误触率比分布式后门攻击低很多。
3.3.3 拜占庭鲁棒性聚合机制下攻击效果
(1)Krum聚合机制。对CIFAR-10数据集执行4种后门攻击模型的实验,多次实验得到攻击成功率的变化情况如图8所示。

图8 4种攻击对Krum的攻击成功率Fig.8 The success rate of four attacks on Krum
通过观察结果可见,本文提出的组合语义后门攻击,在Krum聚合机制下攻击效果最好,分布式后门攻击次之,集中式后门攻击和集中式语义后门在Krum聚合机制下攻击效果较差。
(2)FLtrust聚合机制。FLtrust与现有联邦学习方法之间的关键区别是,服务器本身收集一个干净的小训练数据集(即根数据集),来引导FLTrust中的信任。使用剪辑余弦相似度评分,以及标准化每个本地模型更新,并同时考虑了本地模型更新和服务器模型更新的方向和大小,用以计算全局模型更新。4种攻击对FLtrust的攻击成功率如图9所示。
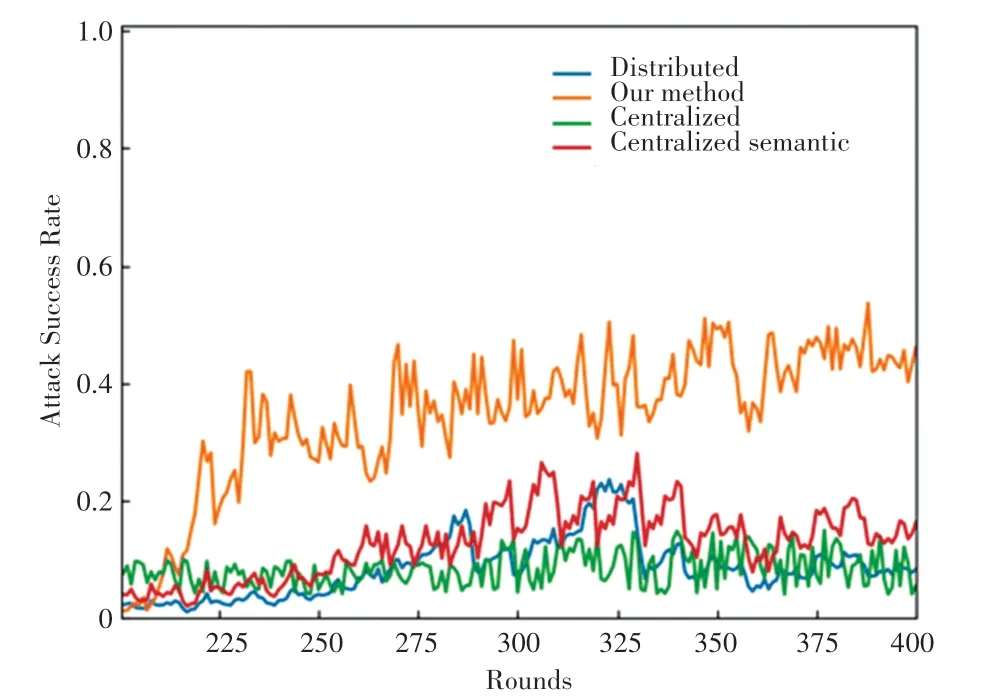
图9 4种攻击对FLtrust的攻击成功率Fig.9 The success rate of four attacks on FLtrust
在FLtrust聚合机制下,本文提出的可组合语义后门攻击对全局模型的攻击效果较好,攻击成功率高于其它3种攻击模型。结果表明,本文提出的攻击对FLtrust聚合机制是有效的,并且优于现有的攻击。
4 结束语
本文针对联邦学习系统的安全问题,通过研究分布式联邦深度学习的安全漏洞,提出了一种针对联邦学习的可组合语义后门攻击方法,同时研究了分布式联邦系统中,针对攻击的聚合机制的鲁棒性效果:
(1)本文实现了联邦学习的原型系统,分析了联邦学习的本地训练过程、参数共享过程以及全局更新过程,并在联邦学习原型系统中实现了现有针对联邦学习的后门攻击,分析现有攻击中存在的问题,并针对这些问题提出了新的攻击模型。利用联邦学习的分布式特性,攻击者使用良性类的特征作为触发器,对本地局部模型注入局部后门,并在模型聚合时生成全局后门模型。通过实验与现有针对联邦学习的后门攻击进行对比。实验结果表明,本文提出的攻击具有更强的隐蔽能力,在分类任务中触发更自然,且具有更强的抗检测能力。
(2)本文在联邦学习原型系统中部署了现有拜占庭聚合算法,检测了4种攻击的能力。通过观察实验结果发现,本文提出的组合语义后门攻击在两种聚合机制中的攻击成功率上升速度和最后的攻击成功率相较于之前的几种攻击都表现出明显优势。
猜你喜欢
现代电子技术(2022年11期)2022-06-14
电脑爱好者(2021年6期)2021-03-24
装备维修技术(2020年16期)2020-12-24
电脑知识与技术(2018年22期)2018-11-26
爱你·心灵读本(2018年6期)2018-09-10
小学生作文选刊·低年级版(2017年9期)2017-09-18
作文·初中版(2015年10期)2015-10-26
红领巾·萌芽(2015年12期)2015-09-10
华人时刊(2014年6期)2014-07-25
职业·中旬(2009年6期)2009-07-21
