
基于多模态多级特征聚合网络的光场显著性目标检测
2022-07-14 13:11王安志任春洪何淋艳杨元英欧卫华
计算机工程 2022年7期
王安志,任春洪,何淋艳,杨元英,欧卫华
(贵州师范大学 大数据与计算机科学学院,贵阳 550025)
0 概述
显著性目标检测(Salient Object Detection,SOD)旨在快速检测和分割图像中最吸引人注意的目标对象。在过去十年中,其作为一项重要的计算机视觉任务,在目标分割、视觉跟踪、行人重识别以及伪装目标检测[1]等方面进行了成功的应用,引起了人们的广泛关注。传统显著性目标检测方法的RGB 图像只包含像素的颜色和强度,但光场图像除了包含像素的颜色和强度信息外,还包含所有入射光的方向。入射光方向指示了场景中物体的三维几何信息。目前,包括Lytro 和Raytrix 在内的商用微透镜阵列光场相机越来越流行,光场信息也被用于包括深度估计[2-3]、超分辨率[4]等多个视觉任务,为算法提供更丰富的视觉信息,显著提升算法的性能。根据输入图像的类型(如RGB 图像、RGB-D 图像和光场图像),现有SOD 算法大致可分为二维、三维和四维的SOD 算法这三大类。大多数方法都属于第一类,关于后两类方法的研究还较少。作为主流的二维显著性检测算法[5-7]已经取得了显著的进步,这得益于深度学习技术尤其是卷积神经网络(CNN)的不断进展[8-10]。但当遇到挑战性真实场景图像时,这些方法通常表现不佳,甚至失效,其原因主要有两点:传统二维SOD 算法对先验知识的依赖性;RGB 图像缺乏三维信息。由于深度信息有助于理解显著性目标的上下文信息和提高SOD的精度,三维SOD算法[11-12]也逐渐引起了学者的关注。然而,深度估计本身是一项极具挑战的课题,低质量的深度图将严重影响三维RGB-D SOD 算法的性能。
近年来,随着Lytro 和Raytrix 等光场相机的普及,光场信息相对容易获得。光场图像包含丰富的视觉信息,由全聚焦图像、焦堆栈序列和深度图组成,其中焦堆栈包含了丰富的三维几何和外观信息。因其独特的视觉特性,四维光场SOD[13-15]具有良好的发展前景。然而,现有光场SOD 算法大多基于手工设计的特征来实现显著性目标的检测,包括对比度、纹理特征、物体完整性、聚焦性先验等。由于高维光场数据比二维RGB 图像更难处理,导致面向光场图像的SOD 方法研究仍较少,基于CNN 的光场SOD 算法仅有MoLF[16]和DLLF[13]等极少数的模型。
面向四维光场图像的基于CNN 的SOD 框架具有重要的研究意义和实用价值。为了将CNN 框架应用于光场SOD,本文提出一种用于光场SOD 的端到端的多模态多级特征聚合检测算法。该算法包括两个并行的CNN 子网络,分别从焦堆栈序列、全聚焦图像和深度图中提取多级多尺度的视觉特征,并利用不同模态间视觉特征的互补性,构建多模态特征聚合模块,以实现更精准的显著性目标检测。
1 相关工作
本文主要介绍二维RGB[17]、三维RGB-D、四维光场SOD 这三类方法。上述方法又可分为传统的方法和基于深度学习的方法。前者主要基于手工设计的特征,不能满足挑战性场景下的显著性检测需求,本文主要讨论基于深度学习的SOD 算法。
1.1 面向二维RGB 图像的SOD
随着CNN的发展,大量基于CNN的SOD 算法被提出。这些算法主要结合后处理步骤[18]、上下文特征[19-20]、注意机制[9,20-23]和循环细化模型[10,24]。文献[25]提出一种端到端深度对比度网络,其能产生像素级显著图,然后通过全连接的条件随机场后处理步骤进一步改善显著图。文献[5]构建一个HED架构,在该架构的跳层结构中引入了短连接。文献[26]提出一种通用的聚合多级卷积网络,该框架将多级特征组合起来预测显著图。随后,DENG 等提出一种带有残差精炼模块的递归残差网络,残差精炼模块用于学习中间预测结果的互补性显著性信息。文献[12]创建一个双分支的SOD 网络,同时预测显著性目标的轮廓和显著图。文献[20]提出一种像素级的上下文注意网络来学习上下文特征,以生成包括全局和局部特征的显著图。
综上所述,CNN 可以自动提取多级视觉特征,并直接学习图像到显著图的映射,但基于CNN 的SOD 方法面对挑战性的复杂场景仍表现不佳,而将现有基于CNN 的二维SOD 模型[27]直接应用于光场图像也并不可取。因此,有必要开展基于CNN 的光场SOD 研究。
1.2 面向RGB-D 图像的三维SOD
QU等[28]设计一种基于CNN的RGB-D SOD 算法自动学习交互机制,并利用手工设计的特征训练基于CNN的SOD模型。CHEN等[29-31]利用多级特征互补性和跨模态特征互补性,设计了一个多路的多尺度融合网络来预测显著图。CHEN等[31]还提出一种三流的注意力融合网络来提取RGB-D 特征,并引入通道注意机制自适应地选择互补的视觉特征。ZHU等[32]提出一个独立的编码器网络来处理深度线索,并利用基于RGB的先验模型指导模型的学习过程。WANG等[33]提出一种双流CNN 自适应融合框架,将RGB模态和深度模态产生的显著图进行后融合。PIAO等[34]提出深度诱导的多尺度递归注意力网络,该网络包括一个深度精炼模块,用于提取并融合互补的RGB 和深度特征、深度诱导的多尺度加权模块,以及一个递归的注意力模块,以粗到细的方式生成更准确的显著性预测结果。
1.3 面向光场的四维SOD
目前,只有较少的SOD 算法设计光场图像,大部分方法都基于手工设计的特征。尽管如此,这些方法在一些复杂场景上表现出了较好的效果。LI等[35]的工作显示了利用光场图像进行显著性检测的实用性,首先估计聚焦性和物体完整性线索,然后将其与对比度线索结合以检测显著性目标对象,他们还建立了光场显著性数据集LFSD。随后,LI等[36]提出一种加权稀疏编码框架来处理不同类型的输入(RGB图像、RGB-D图像和光场图像)。ZHANG等[37]引入位置先验、背景先验和深度线索,扩展了基于颜色对比度的SOD方法来实现四维光场SOD。随后,ZHANG等[38]集成了多种源自光场的视觉特征和先验,提出一种集成的计算方案来检测显著性目标,并构建一个基准数据集HFUTLytro。WANG等[13]提出一种双流的融合框架,以焦堆栈和全聚焦图像为输入,并使用对抗样本来帮助训练深度网络。ZHANG等[16]提出一种面向记忆的光场SOD网络,利用Mo-SFM 模块的特征融合机制和Mo-FIM 模块的特征集成机制,能够准确预测显著性目标。另外还引入了一个新的光场数据集DUTLF-FS。李等[39]提出一种基于聚焦度和传播机制的光场图像显著性检测方法,使用高斯滤波器对焦堆栈图像的聚焦度信息进行衡量,确定前景图像和背景图像。图1 给出了相关的实例,与二维和三维的SOD 算法相比,得益于光场图像丰富的视觉信息,四维光场显著性检测方法在挑战性场景上具有更好的检测性能。然而,现有四维光场SOD 算法仍然没有充分考虑所有的光场输入信息以及光场视觉特征之间的互补性,导致多模态融合不充分,检测性能仍不够理想。

图1 不同SOD 算法的实例结果Fig.1 Smaple results of different SOD algorithms
2 本文方法
本文构建一个双流编解码器网络架构,并提出端到端的多模态多级特性聚合检测算法,算法总体架构如图2 所示。双流子网络采用相互独立且相同的网络结构,分别进行多级特征融合。这些来自不同模态的多级聚合特征被进一步融合生成预测显著图。和其他基于CNN 的SOD 模型[40-41]类似,本文提出网络也使用ResNet-50 作为编码器,用于提取多级特征。和PCA[29]和TANet[31]相同,添加一个15×15 的卷积层作为第6 个卷积块,提取全局上下文特征。
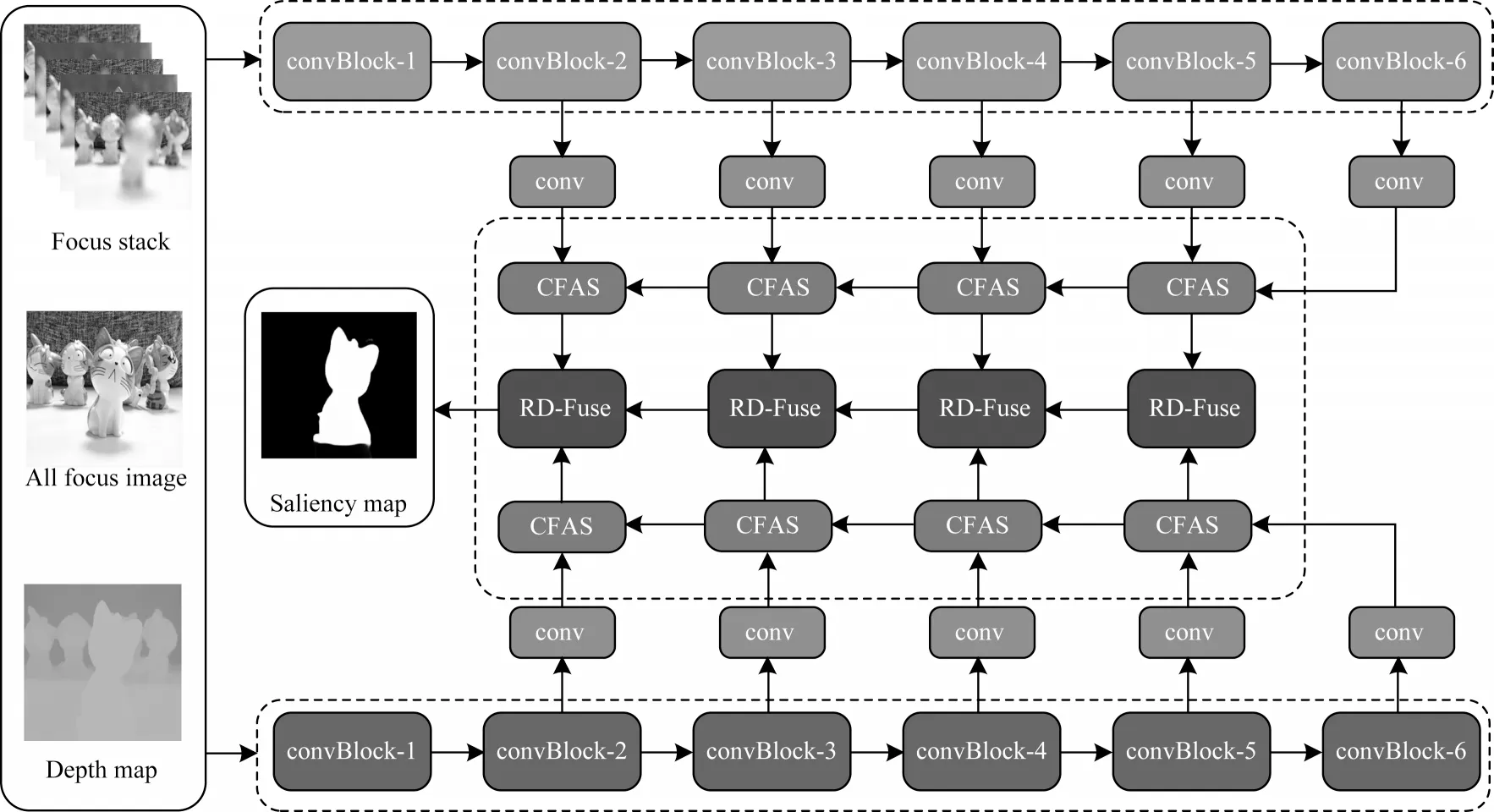
图2 本文算法的整体流程Fig.2 Overall procedure of the proposed algorithm
2.1 多级特征聚合模块
上分支子网络以全聚焦图像和焦堆栈为输入,下分支以深度图为输入,将全聚焦图像的RGB 三通道和焦堆栈的每个切片通道进行连接输入上分支网络。如文献[29,31]将深度图编码成三通道的HHA表示并送入下分支网络。如图2 所示,采用ResNet-50 基网络提取多级特征。与原始模型不同,借鉴EGNet[42]的做法,在每条边路径上插入3 个卷积层,以获得更具判别性和鲁棒性的上下文特征,其中在每个卷积层后添加一个ReLU 层以保证网络的非线性能力。为了简洁起见,将这些卷积层和ReLU 层组合表示为图2 中的一个conv 模块。高级特征包含抽象的语义信息,有助于定位显著目标和去除噪声,而低层特征可以提供边缘、纹理等更详细的空间结构细节,但包含部分背景噪声,这两级视觉特征是互补的[40-41]。此外,全局上下文信息有助于从全局角度检测更完整、更准确的显著对象。因此,引入一个多级特征聚合模块,将这三级特征有效聚合以得到更具判别性的聚合特征。多个多级特征聚合模块从上到下串联,自顶向下逐步聚合和精炼多级特征,其主要过程如式(1)~式(5)所示:
其中:conv(·)为普通卷积;Up(·)为上采样运算;ReLU(·)为ReLU 激活函数;conv3 为3×3 标准卷积层;⊙为逐元素相乘运算;Concat(·)为拼接。多级特征聚合模块接收通过卷积块的特征和从邻近上层多级特征聚合模块的输出特征为卷积块i提取的特征。最上层多级特征聚合模块以通过卷积块的输出特征和卷积块6 的输出特征为输入。通过这种自上而下的监督方式,多级特征逐渐被聚合和精炼。不同于之前(例如:PoolNet,BASNet)的拼接或直接相加的聚合方式,本文采用更有效的直接相乘运算方式来增强检测响应并抑制背景噪声,如图3 所示。

图3 多级特征聚合模块的网络结构Fig.3 Network structure of multi-level feature aggregation module
2.2 跨模态特征融合模块
为了充分利用不同模态间特征的互补性信息,与文献[29,31]类似,本文设计一种跨模态特征融合模块,该模块可以有效地捕获跨模态特征和多级特征之间的互补性。如图2 所示,将多个多模态特征融合模块放置于双流子网络成对的多级特征聚合模块之间,自顶向下进行级联,进一步对不同模态间的多级特征进行精炼和融合,并生成最终的显著预测图。为了充分获取多模式互补信息,跨模态残差连接和互补性监督信息同时被用来进一步提升不同模态的特征互补性。第i级由1×1 卷积层挑选出的深度特征,与另一个支流网络中残差连接得到的特征进行逐元素相加。增强的特征′作为两个1×1 卷积层的输入,减少训练过程中计算量。过程描述如式(6)所示:

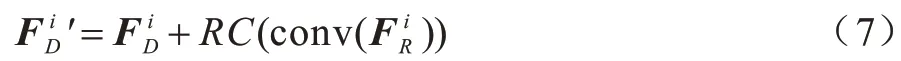

2.3 Adabelief 优化器
优化器的选择影响神经网络训练的检测精度和可靠性。现有方法通常采用SGD、Adam 等优化器。实验结果表明,SGD 具有较好的泛化能力,但收敛速度慢、训练不稳定,需要仔细调参;Adam 无需仔细调参即可达到较好的效果,但很难得到最佳效果,且泛化性不够理想。本文引入了更强壮的AdaBelief[44]优化器,类似于Adam,无需细心调参便能得到更好的效果,其定义如下:

其中:α为学习率;mt为指数移动。
3 实验结果与分析
3.1 实验设置
为了评估所提算法的性能,在现有的光场显著性检测基准数据集DUTLF-FS[13,16]和HFUT-Lytro[38]上进行实验对比。性能评估度量除了采用权威的准确度-召回率曲线(PRC)、F-measure(Fβ)、加权F-measure(WFβ)[44]和平均绝对误差(MAE)[45]外,还采用了结构相似性指标(Sm)[46]和增强匹配指标(Em)[47]共计6 个指标全面评估所提出算法的性能。本文提出的算法基于深度学习框架PyTorch实现,在Nvidia GTX 3090 GPU上进行训练。
3.2 消融实验
本文在权威的光场显著性检测数据集DUTLF-FS和HFUT-Lytro上进行了消融实验,并采用Fß、MAE、Em和Sm 这4 个广泛使用的评价指标对算法中的多级特征聚合模块(CFAS)和跨模态特征融合模块(RD-Fuse)进行有效性验证。表1 所示为在DUTLF-FS 和HFUTLytro 两个数据集上的测试结果。其中,√为添加模块,在HFUT-Lytro 中,基网络(第1 行)在MAE 评价指标为0.122;第2行是在基模型基础上添加CFAS模块的结果,其MAE 指标降低到0.095;第3 行是在基模型基础上使用RD-Fuse 得到的结果,其MAE 指标降低到0.106;第4 行为同时组合CFAS 模块和RD-Fuse 模块的结果,其MAE 评价指标进一步降低到0.083。上述结果表明,CFAS 模块和RD-Fuse 模块对检测性能均有提升,且是相容的。

表1 CFAS 和RD-Fuse 模块的测试结果Table 1 Test results of CFAS and RD-Fuse modules
3.3 定量分析
为全面评估所提出算法的性能,与目前主流显著性目标检测方法MOLF[16]、AFNet[33]、DMRA[34]、LFS[35]、WSC[36]、DILF[37]、F3Net[41]、CPD[48]这8种先进的二维、三维和四维SOD 算法进行了定量的实验对比。为保证实验对比的公平性,所有对比算法的显著图或由作者直接提供,或由作者官方源代码生成。如图4 所示,本文算法精度基本都超过其他主流算法。观察图5 可以看出,本文算法的灰色矩形条高度最低,即MAE 误差最小;而黑色矩形条值最高,即WFβ指标更具有优势。从图6 的PRF 值可知,本文算法也明显优于其他算法,原因是本文采用的多级特征聚合模块在确保较高的召回率下能获得更好精度和Fβ值结果。

图4 在DUTFFS-FS 数据集上的PR 曲线Fig.4 PR curves on DUTFFS-FS dataset

图5 在DUTFFS-FS 数据集上的WFβ 和MAE值Fig.5 WFβ and MAE values on DUTFFS-FS dataset

图6 在DUTFFS-FS 数据集上的精度、召回率和Fβ值Fig.6 Precision,recall,and Fβ values on DUTFS-FS dataset
图7~图9 分别给出了在另一个数据集HFUT-Lytro上的PR 曲线、WFβ和MAE 值以及PRF 值,结果表明本文算法的性能更优。

图7 在HFUT-Lytro 数据集上的PR 曲线Fig.7 PR curves on HFUT-Lytro dataset
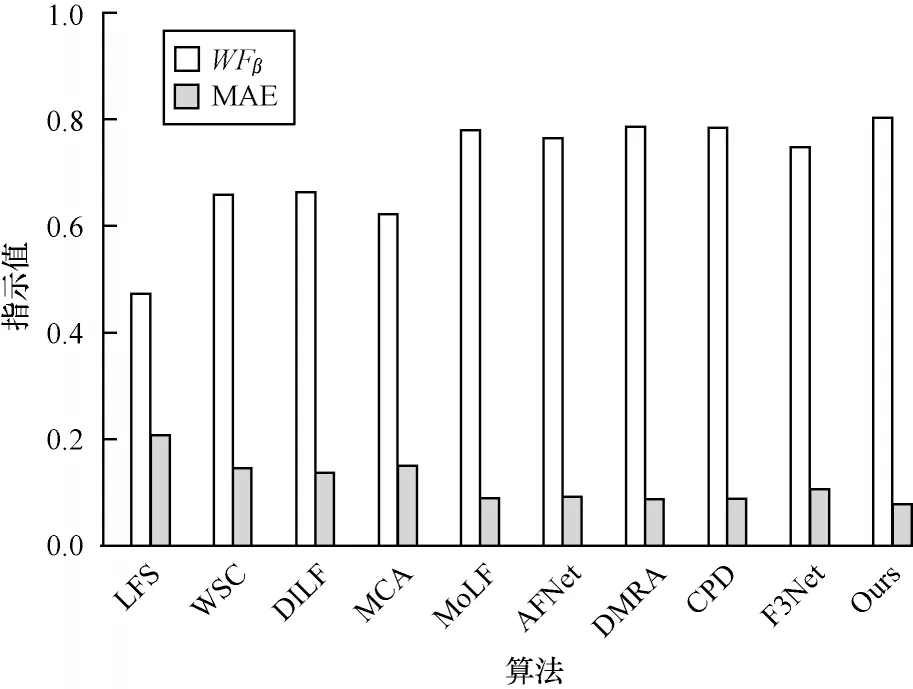
图8 在HFUT-Lytro 数据集上的WFβ 和MAE值Fig.8 WFβ and MAE values on HFUT-Lytro dataset

图9 在HFUT-Lytro 数据集上的精度、召回率、Fβ值Fig.9 Precision,recall rate and Fβ value on HFUT-Lytro
3.4 定性分析
图10 所示为不同SOD 算法视觉对比,给出5 个具有代表性的样本实例。第1 行为前/背景颜色相似的情况,F3Net 检测完全失效;在第2 行~第4 行为背景杂乱的情形,F3Net 检测出现部分噪声未完全抑制,其虽然也采用多级特征聚合方式,但由于CNN网络提取特征有限,仅依靠CNN 的SOD 方法并不能达到特别好的效果。总体来看,本文算法可以在前/背景相似、背景杂乱等挑战性场景图像上能更有效地抑制背景,精确地检测出完整的显著性目标对象,这主要得益于CNN 强大的特征表示能力以及光场丰富的视觉特征。

图10 不同SOD 算法的视觉对比Fig.10 Visual comparison of different SOD algorithms
4 结束语
本文提出一种多模态多级特征聚合网络算法来检测显著性目标对象。利用光场图像单模态内的多级多尺度特征和不同模态间互补的多模态多级特征,检测各类挑战性场景中的显著性目标,并在DUTLF-FS、HFUT-Lytro光场基准数据集上与8种目前先进的二维、三维和四维SOD 算法进行综合的性能对比。实验结果表明,该算法在各个权威性能评价指标上均取得了更好的结果。由于光场图像丰富的视觉信息有助于解决复杂自然场景下的显著性目标检测问题,因此下一步将挖掘光场中更丰富的视觉信息与特征,以更精准地检测出完整的显著性目标对象。
猜你喜欢
山东第一医科大学(山东省医学科学院)学报(2022年7期)2023-01-05
成都信息工程大学学报(2022年4期)2022-11-18
昆明医科大学学报(2022年3期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
中国人兽共患病学报(2020年11期)2020-12-08
兵器装备工程学报(2020年2期)2020-03-23
科学(2020年5期)2020-01-05
小型微型计算机系统(2019年4期)2019-05-05
电子制作(2019年24期)2019-02-23
光学仪器(2017年1期)2017-04-10
