
多尺度特征融合的轻量化口罩佩戴检测算法
2022-07-14 13:10叶茂武麟
计算机工程 2022年7期
叶茂,马 杰,王 倩,武麟
(河北工业大学电子信息工程学院,天津 300401)
0 概述
新型冠状病毒(COVID-19)能够通过飞沫、空气等进行传播,其极强的传染性和较长的潜伏期给人类健康和社会日常生活造成严重影响。虽然我国疫苗接种的人数越来越多,但是新冠病毒仍然在不断进化和变异,多个新冠变异毒株相继出现,对全民的生命健康造成极大威胁。
在病毒爆发初期,LIU等[1]提出佩戴口罩可以有效抑制新型冠状病毒的传播。目前,在超市、医院等多数公共场所,都需要人工提醒佩戴口罩,这种方法极大地造成了人力资源的浪费。随着深度学习的发展,利用人工智能技术可以快速地检测出人们的口罩佩戴情况。
目前,口罩佩戴检测技术作为新冠病毒的关键性预防手段之一,其相关算法研究显得尤为重要。在YOLOv3[2]的基础上,王艺皓等[3]结合跨阶段局部网络(Cross Stage Partial Network,CSPNet)[4]、改 进的空间特征金字塔池化结构[5]以及路径聚合网络(Path Aggregation Network,PANet)[6],在复杂场景下对口罩佩戴情况进行检测,其精度效高,但是检测速度仅为38 FPS。叶子勋等[7]使用改进的MobileNetv3[8]替换原有主干网络CSPDarkNet53,解决了YOLOv4[9]网络模型庞大的问题,模型大小由原来的244 MB 降低至44 MB,并新增SiLU 激活函数优化模型效果。曹城硕等[10]在主干网络中引入残差注意力机制提升模型对显著性特征的表达能力,然后使用特征金字塔网络(Feature Pyramid Network,FPN)[11]和PANet策略进行特征融合,但是,其计算复杂度高达3.098×1010。余阿祥等[12]研究EfficientDet[13]检测算法,在其中加入多尺度 注意力机制[14]并使用soft-NMS[15]代替NMS,该方法能提高检测精度,但是识别速度仅为11.8 FPS。
大型网络在内存资源少、处理器性能不高以及功耗受限的设备上应用时面临巨大挑战,因此,轻量化网络应运而生。在网络模型设计方面,基于YOLOv4-Tiny,彭成等[16]通过加入Ghost模块[17]和ShuffleConv 模块[18],大幅降低了模型参数,但是其精度较原始网络降低了0.2%。除了轻量化网络结构之外,一些研究人员还会利用模型压缩[19-20]、剪枝[21]等方式解决算法效率与存储问题。
上述算法在口罩佩戴检测任务中能发挥一定作用,但是仍然存在以下2 个问题:多数网络能够大幅提升检测精度,但是模型较大,检测速度较慢;部分轻量化网络能有效降低模型参数,但是难以取得准确率和检测速度之间的平衡。
本文基于YOLOv4-Tiny 网络,设计一种实时多尺度特征融合的轻量化口罩佩戴检测算法L-MFFNYOLO。使用轻量化残差模块促进模型快速收敛,降低训练时间开销。考虑到口罩佩戴检测的目标较小,利用浅层特征分支来降低小目标漏检率,在原网络13×13、26×26 这2 个尺度的基础上增加52×52特征分支。同时,引入多层级交叉融合(Multi-level Cross Fusion,MCF)模块解决多尺度目标对模型精度的影响,以更好地利用深层和浅层特征信息增强有效特征的表达。
1 轻量化口罩佩戴检测算法
YOLOv4-Tiny[4]是YOLOv4 的轻量级版本,其网络结构简单,且能有效兼顾精度和速度。YOLOv4-Tiny网络结构如图1所示,主干网络CSPDarkNet53-Tiny 主要包括标准卷积、残差结构堆叠和下采样3 个部分:标准卷积采用CBL 结构,由卷积层Conv2D、批量标准化(Batch Normalization,BN)和激活函数Leaky ReLU 组成;残差结构堆叠使用CSP(Cross Stage Partial)模块,将基础层的特征分成2 个部分,第一部分直接构建残差边,第二部分通过标准卷积和上一个部分进行拼接;下采样通过最大值池化。主干网络将13×13 的特征层与进行2 倍上采样的特征层进行融合,最终利用YOLO Head 生成预测结果。
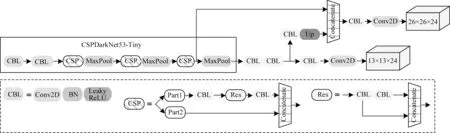
图1 YOLOv4-Tiny 结构Fig.1 The structure of YOLOv4-Tiny
为进一步提升网络性能,本文改进算法L-MFFN-YOLO 的结构如图2 所示。图2(a)部分采用轻量化的残差结构。由于YOLOv4-Tiny 只包含2 个尺度,小目标漏检情况严重,因此图2(b)部分新增8 倍下采样尺度分支,通过主干网络提取出3 种不同分辨率的特征然后进行多层级交叉融合,在保证资源消耗较少的情况下增强不同分支中的特征图信息,最终提升特征提取能力。
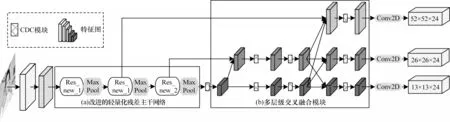
图2 L-MFFN-YOLO 结构Fig.2 The structure of L-MFFN-YOLO
1.1 改进的轻量化残差结构
在一些资源受限的设备中,较深的卷积网络模型容易导致反向传播过程中出现梯度弥散、梯度爆炸等问题,使得口罩佩戴检测模型无法很好地收敛。运算量较少的卷积操作在保证模型有效性的同时可以缓解上述问题。深度可分离卷积(Depth-Wise Separable Convolution)[22]可以减少算法参数,提高训练速度,并且对检测精度影响较小,能够解决网络加深引起的性能退化问题。深度可分离卷积可分成深度卷积(Depth-Wise Convolution,DW Conv)和逐点卷积(Point-Wise Convolution,PW Conv),即1×1 标准卷积,其结构如图3(a)所示。在此基础上,本文引入一种能保证检测性能并进一步降低参数量的CDC模块,如图3(b)所示。首先,使用1×1 标准卷积生成少量原始内部特征图,减少大量的卷积运算并将通道信息重新进行整合;然后,针对原始内部特征,通过深度卷积在不损失特征信息的情况下实现较小的计算代价;最后,将原始内部特征与经过深度卷积后的特征进行融合。
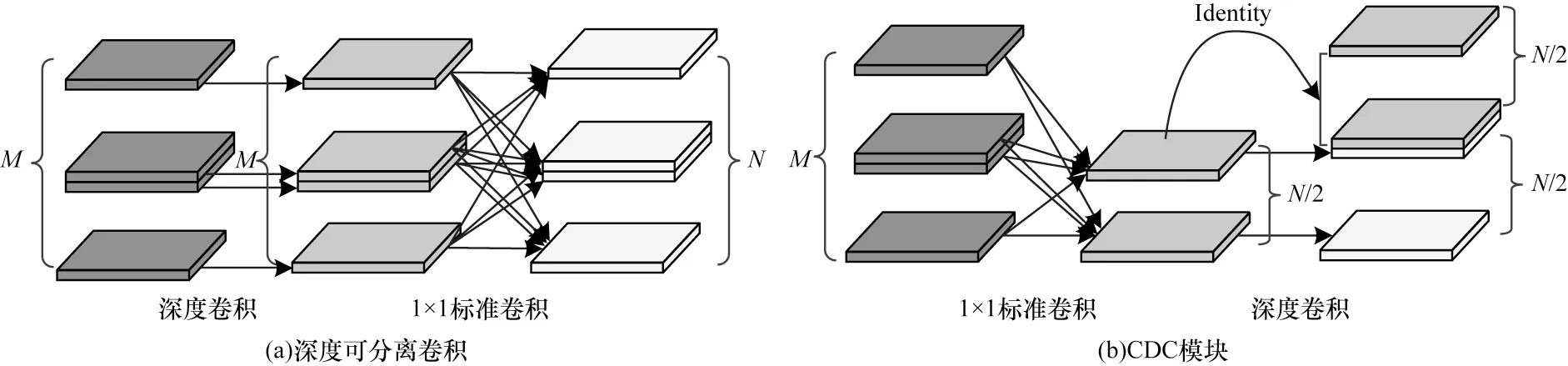
图3 不同的卷积过程Fig.3 Different convolution processes
设2 种不同卷积的输入特征大小为H×W×M,输出特征大小为Ho×Wo×N,其中,M和N分别代表输入和输出通道。图3(a)中DW Conv 卷积核尺寸为Dk×Dk×1×M,PW Conv 卷积核尺寸为1×1×M×N,CDC中2 个卷积核的尺寸分别为则CDC 模块与深度可分离卷积的参数量比值为
在本文中,使用Dk×Dk=5×5 的卷积扩大有效感受野,并假设M=N,根据参数量比值可知CDC 模块的参数量更少。
上述2 种卷积形式都可以在检测任务中大幅降低模型参数量,但是改进模块在硬件条件有限的情况下更具优势。图4 所示为不同残差模块结构的对比。在YOLOv4-Tiny 中,采用图4(a)所示的CSP 模块进行残差结构堆叠;图4(b)中Res_new_X 是本文主干网络的重要组成部分,其用CDC 模块替换原有CSP 结构中的部分卷积。
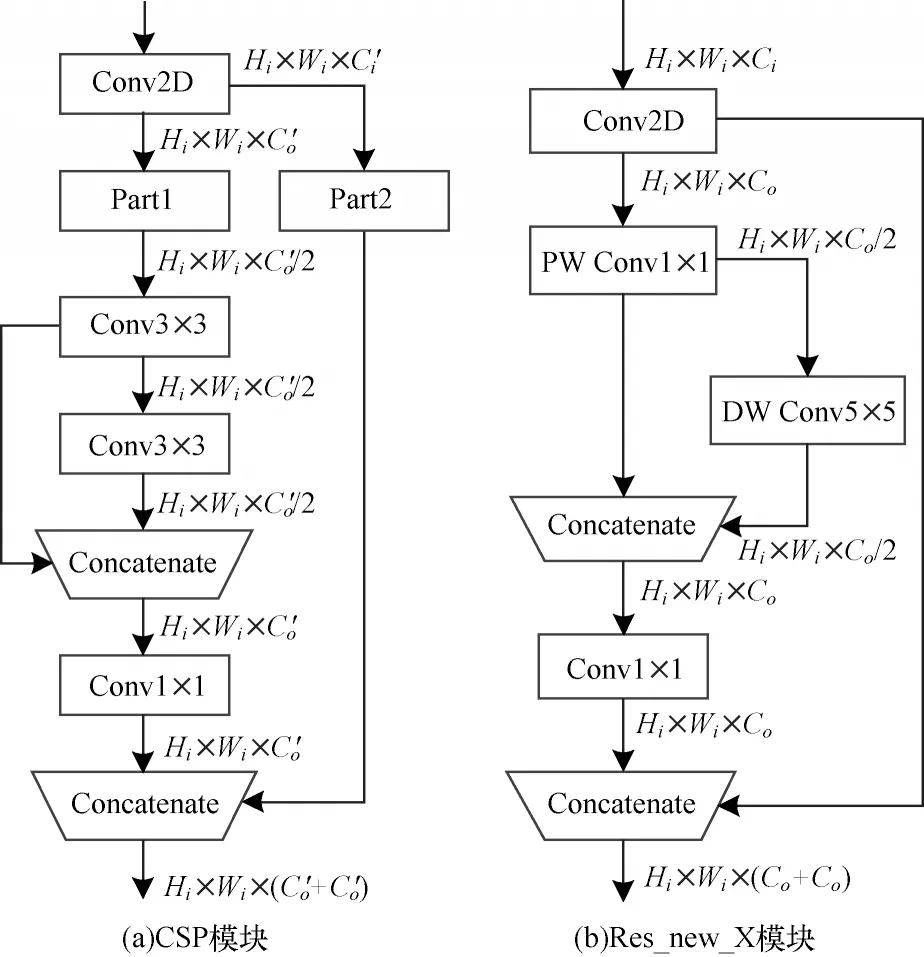
图4 不同的残差模块Fig.4 Different residual modules

本文采用Res_new_X 模块替换YOLOv4-Tiny中的3 个CSP 模块,前2 个使用卷积核大小为3×3 的Res_new_1 模块,增强特征提取,第3 个采用1×1 的Res_new_2,减少参数量和计算量,加快推理速度,从而更好地实现口罩佩戴实时检测。
1.2 多层级交叉融合
自制数据集包含很多不同尺度的口罩目标,部分图片中目标较集中,特征差异性较小,实验结果表明,Res_new_X 中引入了一定的检测误差,因此,单一尺度的卷积核无法适应多角度、多尺度变化的图片。浅层网络分辨率较大,包含较清晰的位置信息,深层特征则包含丰富的语义信息,不同尺度的特征层包含的特征信息不同,对不同大小的目标适应性较强。为了解决多角度、多尺度目标降低模型精度的问题,本文基于HRNet[23]的并行网络结构构建一种轻量化的多层级交叉融合模块MCF:将3 种不同分辨率的子网以并行的方式进行连接;在每一个子网上通过上采样或下采样操作转换特征的大小;利用拼接操作将所有的特征信息进行融合,使得网络能够较好地利用深层语义信息。
MCF 模块仅增加极少的内存,却能很好地保留特征图的细粒度信息并大幅提升检测准确度,不同分辨率的特征图的融合过程如图5 所示。
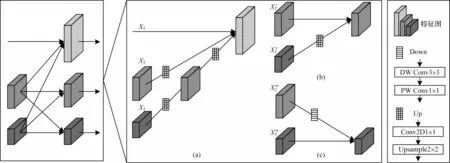
图5 不同分辨率的特征图的融合过程Fig.5 Fusion process of feature images with different resolutions
图5 中的(a)~(c)分别表示52×52、26×26、13×13分辨率的信息交互环节。首先,尽可能多地提取位置信息和语义信息;然后,通过一系列上采样或下采样以及拼接操作进行多尺度融合,从而提升多尺度特征的融合效果,增强检测性能;最终,建立一种多尺度特征融合的轻量化口罩佩戴检测网络。(a)中X1、X2、X3表示不同分辨率的特征图,X3先通过2 倍上采样形成与X2相同维度的特征图,再经过Up 结构与X1融合以输出新特征信息;X2通过上采样与X1拼接。(b)中经过Up 进行2 倍上采样与的特征进行拼接。(c)对经过Down 进行2 倍下采样并与融合。完整的多层级交叉融合模块结构如图2(b)所示,最终生成3 个不同尺度大小的特征图。其中,Up是经过1×1 卷积再2 倍邻近上采样的过程,Down 是由深度可分离卷积组成的2 倍下采样,DW Conv 采用步长为2 的3×3 卷积,再经过点卷积重新整合通道。
多层级交叉融合能够提取更多有利信息并有效进行信息交互,并且只增加少量的计算量,更适用于存在目标遮挡、多目标以及目标较小的复杂场景。
2 实验结果与分析
2.1 实验设置
2.1.1 实验平台
本文模型训练于Ubuntu20.04 操作系统,使用Keras框架,CPU为Intel酷睿i7-8700K,GPU 为NVIDIA GeForce GTX 1080Ti(11 GB),软件环境为CUDA10.0、CuDNN7.6、Python3.6。输入图像统一缩放为416×416的大小。
在训练过程中,采用K-means 聚类得到新的先验框,分别为:(6,10),(11,20),(18,31);(29,47),(46,69),(59,121);(88,101),(120,172),(205,253)。训练参数设置如下:初始学习率为1×10-3,Batch size 为32,在第50 个epoch 之后,学习率下降到1×10-4,Batch size 为16,在实验中使用早停法(Early Stopping)的训练方式避免模型过拟合。
YOLOv4-Tiny 与L-MFFN-YOLO的损失函数值随训练轮数的变化曲线如图6 所示。
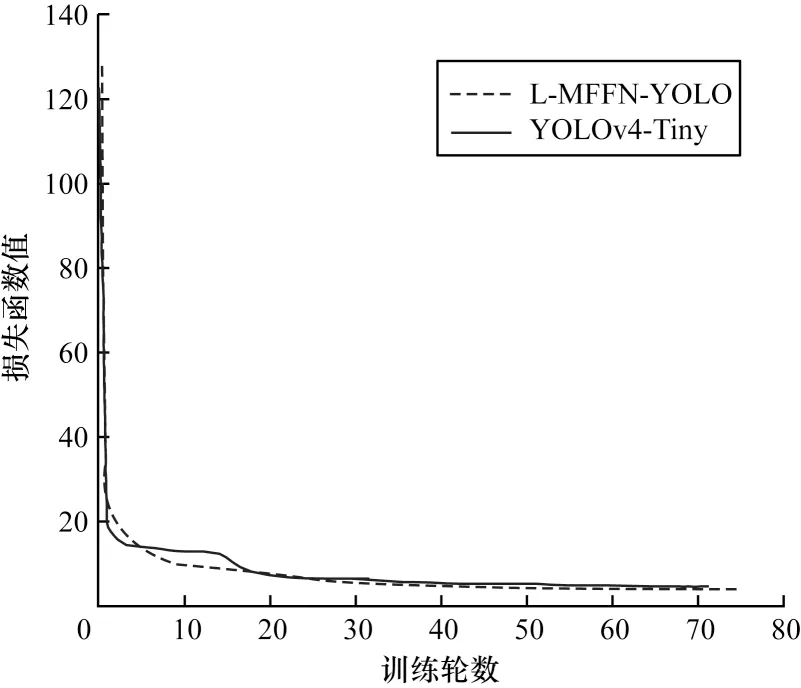
图6 YOLOv4-Tiny 和L-MFFN-YOLO 的损失函数对比Fig.6 Comparison of loss function of YOLOv4-Tiny and L-MFFN-YOLO
2.1.2 数据集
考虑口罩类型、制造商、颜色等因素,本文通过手机拍摄、网络爬取等方法收集图片作为数据集,共计7 910 张,每张图片中的人脸都对应一个标签,每个标签对应一个序号。将检测结果分为3类:序号0对应“佩戴口罩(with_mask)”,表示已佩戴口罩;序号1 对应“不正确佩戴口罩(incorrect_mask)”,表示佩戴口罩不正确;序号2 对应“人脸(face)”,表示未佩戴口罩。数据集中的不同类别样本分布如表1 所示。

表1 数据集中的样本分布Table 1 Sample distribution in dataset
图7(a)~图7(d)分别表示标准佩戴口罩的正面、左面、右面、上面示例,图7(e)~图7(h)分别展示鼻外露、口鼻外露、口鼻下巴外露、下巴外露4 种常见的不正确的口罩佩戴方式。

图7 数据集示例Fig.7 Examples of the dataset
2.1.3 评价指标
为了验证本文算法的检测性能,将精确率P(Precision)和召回率R(Recall)作为定量评估指标,两者的计算公式分别如式(1)、式(2)所示:

其中:TP、FN和FP分别表示目标是正确的、目标被检测错误以及未被检测出的样本数量。
本文利用平均精确度(Average Precision,AP)来评价模型在测试集上的检测性能,其计算如式(3)所示。多类别的检测结果通常采用平均精确度均值(mean Average Precision,mAP)来衡量,其计算如式(4)所示。


此外,本文采用每秒处理图片数量,即每秒帧率(Frames Per Second,FPS)来衡量算法的检测速度。在面向一些内存受限的设备时,还需要评估模型的参数量、模型大小以及每秒10 亿次的浮点运算量(Billion Floating-point Operations Per second,BFLOPs)。
2.2 对比实验结果分析
2.2.1 检测算法模型参数分析
口罩佩戴检测系统需要快速高效地判断出人们是否佩戴口罩以及佩戴口罩是否正确,因此,更加适合部署在内存资源受限的设备上。为验证模型的有效性,实验对比分析不同主流检测模型的精度、参数量、检测速度、在GPU 和CPU 下的推理时间以及每秒10 亿次的浮点运算量,结果如表2 所示,最优结果加粗表示。
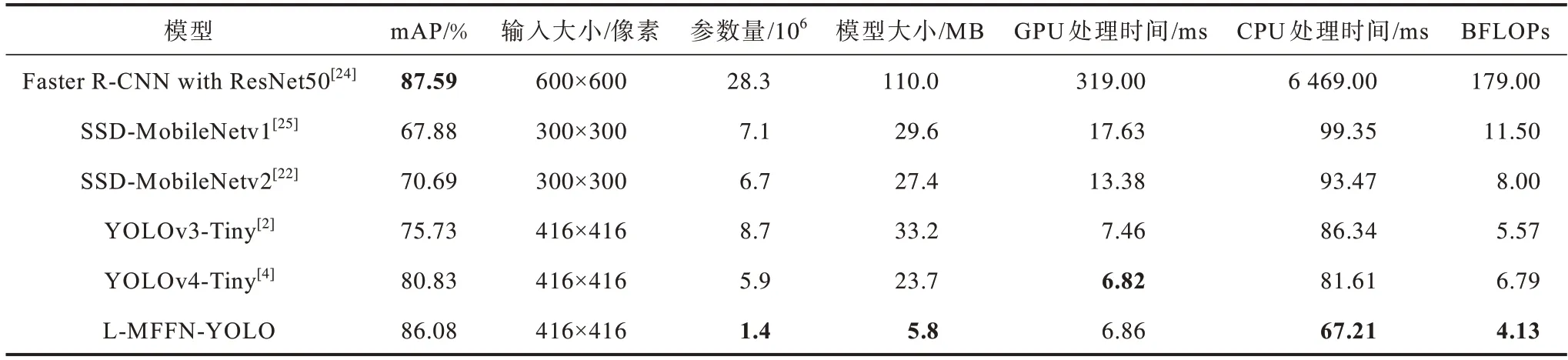
表2 不同模型的性能对比结果Table 2 Performance comparison results of different models
从表2可以看出:大型网络Faster R-CNN[24]的检测精度比本文L-MFFN-YOLO 高1.51 个百分点,但是其参数量和模型较大;用MobileNetv1 和MobileNetv2 替换SSD 主干网络的2 个一阶段目标检测器,在一定程度上可以降低计算复杂度,但是模型整体性能均低于本文L-MFFN-YOLO;相较YOLOv3-Tiny 和YOLOv4-Tiny,在输入尺寸为416×416 像素时,本文L-MFFN-YOLO 的计算复杂度分别降低26%和39%,模型大小和参数量也大幅减少,而精度分别提高10.35 和5.25 个百分点,在推理时间上,本文L-MFFN-YOLO 在CPU 上分别快约19 ms和14 ms,在GPU上比YOLOv3-Tiny 快0.6 ms,但是比YOLOv4-Tiny 慢0.04 ms,主要原因是L-MFFN-YOLO 计算层数提高,增加了一定的访存量,在GPU 这种并行处理器下不能发挥出计算量较小的优势,但是延长时间较少,可以忽略不计。实验结果表明,本文L-MFFN-YOLO能降低设备资源内耗,并且在较少参数冗余的情况下具有较高的检测速度。
2.2.2 YOLO 类模型在口罩佩戴测试集上的表现
L-MFFN-YOLO是在YOLOv4-Tiny的基础上进行的改进,因此,需要对不同的轻量化YOLO 模型在口罩佩戴测试集上的检测结果进行对比,如表3 所示。从表3 可以看出,相较YOLOv3-Tiny 和YOLOv4-Tiny,L-MFFN-YOLO在TP中达到最大值,在FN中达到最小值,其精确率和召回率也达到最佳,即对样本具有良好的检测性能。
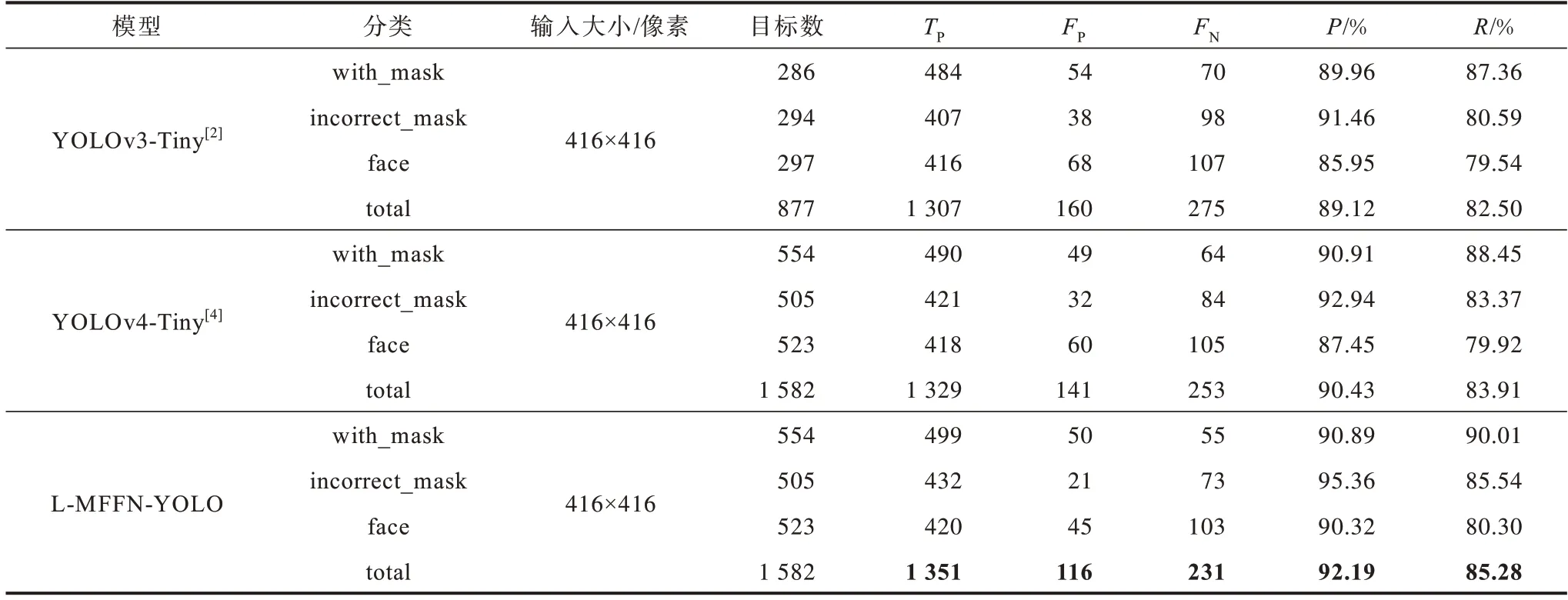
表3 不同的轻量化YOLO 模型在口罩佩戴测试集上的检测结果Table 3 Test results of different lightweight YOLO models on mask-wearing test set
为进一步直观地展示本文改进算法在口罩佩戴检测任务中的效果,分别对YOLO 系列算法在常规、多人脸、遮挡及背景虚化、光线较弱等场景下进行测试,结果如图8 所示(彩色效果见《计算机工程》官网HTML 版)。在图8(a)场景下,3 种方法均能实时检测出口罩佩戴情况,但是,YOLOv3-Tiny 和YOLOv4-Tiny 的检测性能低于L-MFFN-YOLO;在图8(b)场景下,YOLOv3-Tiny 和YOLOv4-Tiny 的漏检和错检情况严重,而L-MFFN-YOLO 不仅能够解决漏检问题,还在识别精度上有很大提高;在图8(c)场景下,本文L-MFFN-YOLO 由于加入了MCF 结构,能够融合深层语义信息和浅层位置信息,因此对远处虚化目标的检测性能较好,有效降低了小目标漏检率;在图8(d)场景下,YOLOv3-Tiny 漏检情况严重,YOLOv4-Tiny 虽然能识别大部分目标,但是检测精度低于L-MFFN-YOLO。综上,本文提出的L-MFFN-YOLO 算法能够在复杂场景中实现高效的目标检测。

图8 不同场景下的检测效果对比Fig.8 Comparison of detection effects in different scenes
2.3 消融实验结果分析
2.3.1 不同残差模块的对比分析
1.1 节分析了深度可分离卷积、CSP 模块和CDC模块的参数量,较少参数量和较低计算复杂度的模型更适合部署在资源受限的设备中。将YOLOv4-Tiny 中的CSP 模块替换为由深度可分离卷积构建的残差结构和由CDC 构建的Res_new_X,不同残差模块对算法性能的影响如表4 所示。
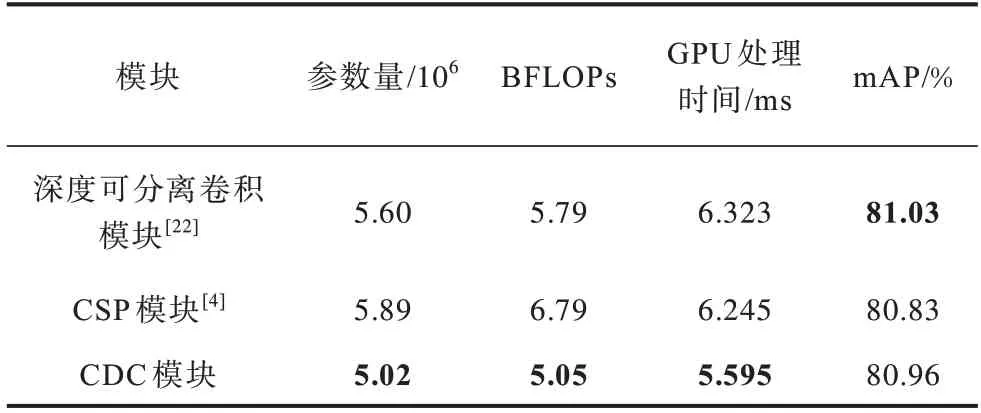
表4 不同残差模块对算法性能的影响Table 4 Influence of different residual modules on algorithm performance
从表4 可以看出,改进模块精度较深度可分离卷积模块降低0.07 个百分点,但是参数量和计算量降低最多,GPU 处理时间较优,因此,其降低的精度可以忽略不计。
2.3.2 不同多尺度特征融合网络的对比分析
上文验证了由CDC 模块构建的主干网络Res_new_X 的有效性,本节将在Res_new_X 的基础上,首先将FPN 和PANet 中的卷积操作替换成CDC模块,大幅降低模型参数量,然后再分析不同的多尺度融合模块对网络性能的影响。分别在原始主干网络Res_new_X 中加入轻量化FPN 结构(构成Res_new_X-A)、轻量化PANet(构成Res_new_X-B)以及多层级交叉融合MCF(构成Res_new_X-C),输入图片尺寸为416×416,将3 种模型在口罩佩戴数据集上进行训练和测试并与原始主干网络作对比,实验结果如表5所示。从表5可以看出:Res_new_X-A的mAP 较Res_new_X 提高了3.23 个百分点,表明多尺度特征融合在一定程度上可以更好地检测出口罩佩戴情况;Res_new_X-B 由于结合自上而下和自下而上的融合机制,导致网络的参数量增加,较Res_new_X-A,其FPS 下降2,mAP 提升不明显,其检测性能不具备优势;Res_new_X-C 采用MCF 模块,通过重复融合不同分辨率的特征信息,很好地解决了多角度和多尺度目标剧烈变化而带来的精度下降问题,从而提高了检测性能,mAP 达到86.08%,FPS的下降可忽略不计。

表5 不同多尺度融合网络对算法性能的影响Table 5 Influence of different multi-scale fusion networks on algorithm performance
2.3.3 不同模块对改进算法性能的影响
本文采用消融实验来分析不同模块结构对整个网络性能的影响,实验分为4 组分别进行训练:
1)实验1,使用的主干网络为YOLOv4-Tiny CSPDarkNet53-Tiny[4]并去掉上采样;
2)实验2,使用的网络在实验1 的基础上增加52×52 尺度分支。
3)实验3,使用的主干网络用CDC 模块构成的Res_new_X。
4)实验4,使用的网络在实验3 的基础上加入多层级交叉融合模块MCF。
实验结果如表6 所示,其中,“√”表示加入了该模块。
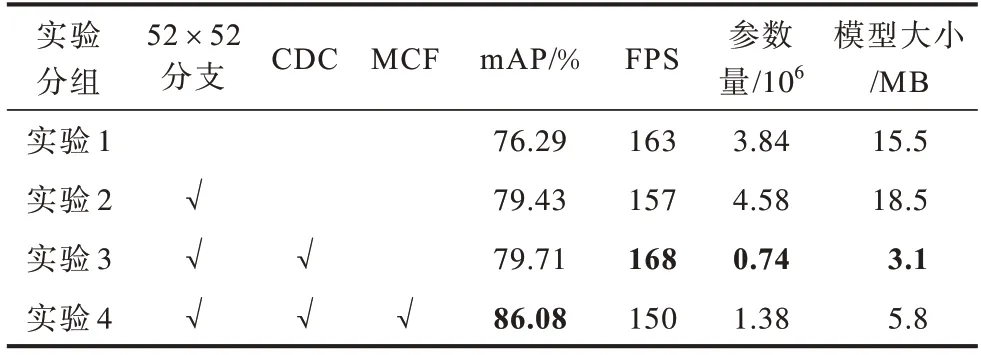
表6 改进模块对检测性能的影响Table 6 Influence of improved module on detection performance
从表6 可以看出:实验2 的mAP 比实验1 提高了3.14 个百分点,证明增加浅层预测分支能在较少计算开销的条件下增强算法的学习能力;实验3 用CDC 模块构成的Res_new_X 替换原始主干网络,mAP 达到79.71%,模型大小比实验2 减少15.4 MB,从而验证了Res_new_X 的有效性;实验4 在实验3 的基础上引入多层级交叉融合模块MCF,该模块使用卷积运算,较实验3 增加了0.64×106的参数量,减慢了检测速度,FPS 有所下降,但其检测精度提高了6.37 个百分点。
3 结束语
针对现有口罩佩戴检测算法网络结构复杂、计算参数冗余等问题,本文提出一种多尺度特征融合的轻量化口罩佩戴检测算法L-MFFN-YOLO,其可以实现多尺度、遮挡、多目标场景下的口罩佩戴实时检测,且适合部署于资源受限的检测设备。在YOLOv4-Tiny 的基础上,通过轻量化主干特征提取网络缓解模型规模较大的问题。针对数据集图像大小不一的现象,新增一个高分辨率预测分支来提升小目标的检测能力。在此基础上,使用多层级交叉融合模块提高模型的检测精度,增强语义信息和位置信息的表达。实验结果表明,该算法的参数量与模型大小均较低,且检测精度较轻量级模型YOLOv4-Tiny 提升5.25 个百分点,其能够兼顾检测精度和速度,具有较好的工程应用价值。但是,在遮挡、背景虚化和光线较弱的场景中,有一些目标未被本文算法检测出,因此,下一步将在遮挡、能见度低的情况下,通过学习人脸眼睛、耳朵等细节特征来增加人脸定位,从而利用本文轻量化算法快速准确地完成口罩佩戴检测任务。
猜你喜欢
精密成形工程(2022年2期)2022-02-22
北京航空航天大学学报(2021年9期)2021-11-02
意林(2020年9期)2020-06-01
海峡姐妹(2020年4期)2020-05-30
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
作文大王·笑话大王(2019年3期)2019-04-22
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
北京航空航天大学学报(2018年1期)2018-04-20
