
基于人群出行行为轨迹的城市功能区识别
2022-07-14 13:10:48凌鹏诸彤宇周轶吴爱枝张鹏
计算机工程 2022年7期
凌鹏,诸彤宇,周轶,吴爱枝,张鹏
(1.北京航空航天大学 软件开发环境国家重点实验室,北京 100191;2.北京市安全生产科学技术研究院,北京 101101)
0 概述
目前,全球一半以上的人口居住在城市中,而且城市人口规模仍在不断扩大,到2030 年,全球城市人口数量估计会增长到50亿[1]。因此,对如此庞大的城市人口和有限的城市地区进行管理非常重要。
城市功能区识别是进行合理城市规划和管理的关键一环。功能区是一个文化概念,描述了某个地区的人类活动,能够反映城市的复杂空间分布和社会经济功能[2]。每个功能区在空间上都由不同的地理对象聚合,并从土地用途上进行语义抽象[3]。功能区是城市规划的基本单位[4-5],对城市交通、资源管理、工厂选址等都有重要影响[6-7]。传统的城市功能区识别研究主要采用调研统计的方法,通过对人们出行日志的记录和问卷调查等方式进行。这种方法具有很大的局限性,不仅需要大量的人力、物力、财力,效率低下,而且调查者容易将主观意见和看法带入研究结果[8]。
遥感影像数据可以很好地捕获陆地表面的自然外观,因此,大量研究者用遥感影像数据来进行功能区识别[9-11]。但仅使用遥感图像进行区域功能识别存在不足:一方面,遥感数据只能反映地表的自然属性,而城市功能区具有社会经济属性,并由相关的人类活动决定;另一方面,遥感数据的获取需要巨大的耗费,且高密度城市中众多高层建筑存在阴影,这对遥感图像处理带来了巨大挑战。
公共交通工具(公共汽车、地铁、出租车等)能够产生大量与人移动强相关的位置数据用于功能区识别[12-13]。QIAN等[14]提出了一个集成模型,先基于出租车轨迹中的上下车点,使用K-Means 和k 最近邻算法提取区域社交属性,再基于决策树算法融合遥感数据得到功能区分类。但公交数据会忽视行人对于城市功能区的影响,也会忽略路网未覆盖的区域。
兴趣点(Points of Interest,POI)数据作为城市设施的代表,被广泛应用于城市功能区提取。YUAN等[15]使用基于主题的推断模型来推断每个区域的功能,该模型将区域视为文档,将功能视为主题,将POI 的类别视为元数据,将人类流动模式作为词语。POI 数据以建筑物的功能属性出发,能够覆盖所有区域,但并未考虑人的社会活动属性,同时数据更新成本较大。
手机呼叫详细记录(Call Detail Records,CDR)数据间接记录了人的活动时间、空间信息,同时隐含了人的社会活动属性[16-17],数据获取成本较低,且支持实时更新。江贵林等[18]使用高斯混合模型,基于CDR 数据的简单统计量设计多特征加权判决的功能区识别算法。TU等[19]先基于手机信令数据推断人的职住位置,再基于隐马尔可夫模型由社交媒体签到数据获取人的活动的知识,从而推断城市功能。JIA等[20]自定义融合规则,同时使用遥感影像数据与CDR 数据。但目前基于手机数据的大部分研究都只用到了简单的统计量,如区域内不同时间段的通话量等。
现有基于出行信息的功能区识别研究大部分停留在简单的统计,且多数将区域内不同出行行为的人群混杂在一起,并没有考虑不同群体对区域产生的不同影响。笔者通过研究相关数据发现:不同功能区的人群出行活动具有各自的特征,而通过学习这些特征可以识别出相应的功能区。本文基于人群出行行为轨迹构建城市功能区识别模型UFAI。利用粗粒度的匿名个体移动位置数据提取隐含的个体出行特征,并通过将这些出行特征与所在局部区域相关联,对该区域的群体出行特征进行分类。在此基础上,通过训练功能区的多分类深度学习模型,完成对功能区的识别。
1 UFAI 模型
1.1 模型框架与符号定义
UFAI 模型框架如图1 所示,主要分为3 个模块:
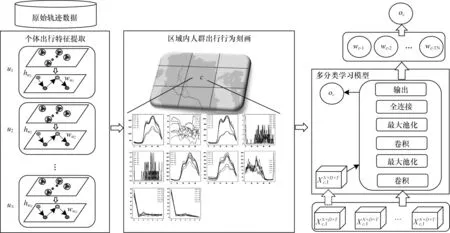
图1 UFAI 模型框架Fig.1 UFAI model framework
1)个体出行特征提取模块。对原始数据进行数据预处理后,使用ST-DBSCAN 算法[21]识别用户停留点,然后构建出行链,提取出用户的职住位置以及隐含的个体出行特征。
2)区域内人群出行行为刻画模块。以区域为研究对象,基于个体出行特征划分区域内的不同群体,提取出各类人群的停留特征和居民的活动特征。
3)功能区分类模块。首先人工标注高置信度样本,然后以时间周期为单位切分数据,从而扩充样本,构建并训练深度学习模型。
本文所使用符号定义如表1 所示。

表1 相关符号定义Table 1 Definition of related symbols
1.2 个体出行特征提取
一个用户uid对应的全部原始轨迹记录集为Rid,如式(1)所示:

1.2.1 停留点识别
通过对聚类算法的研究可知,密度聚类算法DBSCAN 比较适用于停留点提取,但传统的DBSCAN 算法只考虑了空间这一单一维度,并不适用于处理具有多个维度的数据,因此,本文引入面向高维数据的ST-DBSCAN 算法。ST-DBSCAN 算法相对DBSCAN 主要有两点改进:时间阈值的加入与选择样本邻域方法的改变。时间阈值限制了簇集中样本点的最短时间跨度值,而选择样本邻域的方法由随机扩展方式改为按时序扩展方式,能够保证一个簇集中的样本点在时间上是连续的。
从手机CDR 数据中获取用户的停留点集合,如式(2)和式(3)所示:
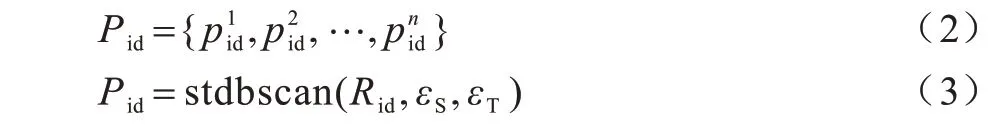
其中:Pid是一个用户对应的所有停留点的集合,集合的第i个停留点为是
1.2.2 职住位置提取
基于停留点集合Pid可以提取uid在各个位置对应的所有停留时段。计算各个位置在居家时间段的累计停留时长,并取累计停留时长最长的停留点作为居住地hid。同时,计算各个位置在工作时间段的累计停留时长,并取累计停留时长最长的停留点作为工作地wid。上述计算过程如式(4)和式(5)所示:

其中:dH和dW分别为居家时间段和工作时间段;fT是一个函数,用于计算任意两个时间段交集的时间长度。
1.3 区域内人群出行行为刻画
1.3.1 区域内的人群分类
以往针对区域内人群出行行为的研究,都是以区域内的所有人群为研究对象,但单个区域内的人员成分复杂,不同人群的出行行为也互不相同。因此,本文先将单个区域c内的人群分为8 个研究类别,如表2 所示。

表2 区域内人群研究类别定义Table 2 Categories definition of population research in the region
对于用户uid,职住位置为hid和wid,则其在区域c内的停留时长计算如式(6)所示:

用户在整个研究范围内的停留天数如式(7)所示:

其中:date 代表所取停留时段对应的日期。由此可得各类人群职住位置的计算公式如式(8)~式(15)所示:

1.3.2 区域内各类人群的停留特征
区域内不同人群的出行行为在相同时间范围内具有不同的人数变化趋势,因此,先以τ为采样粒度,将一天划分为间隔相等的时间片序列,可以计算得到区域一天各时间片的各类人群的人数,最后将连续多天的结果进行拼接,用以刻画区域内各类人群的出行行为。
对于区域c,在第k个时间周期的第d天,时间片t对应g类人群的数量如式(16)所示:

由此,可得到各个区域的人群出行行为特征矩阵N。
1.3.3 区域内居民的活动特征刻画

其中:dis 为计算两点间的直线距离的函数;fD为分段离散函数。
fD将输入的任意原始连续值x映射为t段离散值中的一个离散类别r:

其中:κr,1和κr,2分别代表离散类别r的范围上界和下界,离散后的类别数与一天时间片个数相同。
对于区域c,在时间周期k的第d天,半径离散类别r对应的值如式(20)和式(21)所示:

由此,可得到各个区域的居民出行行为特征矩阵A和W。
1.4 功能区分类模型
区域人群出行行为刻画模型基于粗粒度轨迹数据,从出行行为角度出发计算得到区域的人群出行行为特征和居民出行行为特征。
功能区分类模型先拼接两类特征矩阵,得到模型的输入特征矩阵X。由经验可知,一周为一个人类活动的周期,因此,本文选取一周七天为区域的一个时间周期,构建区域c第k个时间周期输入特征的方式如式(22)所示:

1.4.1 样本集扩充
结合实际经验和数据分析,先人工标记部分功能区,作为训练和测试数据。但由于功能区数量本身有限,导致有标签的功能区数量有限,因此需要扩充样本。
由于数据在同一个区域的不同时间周期上遵循同一个概率分布,而且时间周期是可以不断扩展的,因此本文将一个区域对应的多个时间周期数据切分为多个训练样本,从而扩充样本集。
1.4.2 模型训练与分类结果
对于任意区域c,时间周期k对应的特征矩阵是一个三维张量,经分析发现其时空分布均匀,类似图像数据,因此,本文采用类似卷积神经网络的结构构建多分类模型。

其中:l代表层数;k为卷积核;Mj表示选择的输入特征图的集合。每个输出特征图会给一个额外的偏置b,然后进行最大池化:

其中:u(n,n)为输入窗口函数。在此基础上,进行第2次卷积和池化:


其中:W为全连接层的权重矩阵。
对于同一个区域,当输入多个时间周期时,得到的分类结果可能会有所不同。出现这种情况的原因可能是该区域的功能分类复杂,也可能是数据采集的问题。因此,本文选取所有时间周期对应的分类结果中出现次数最多的结果,作为区域的功能区分类的最终结果。在第k个时间周期,区域c的输入特征矩阵为Xc,k,模型的分类结果为yc,k,获取区域的最终结果oc的过程如式(28)所示:

其中:fM用于返回一个序列的众数。
2 实验与结果分析
2.1 实验数据集
本文实验所用的数据集为某移动运营商提供的北京市2019 年1 月—2019 年10 月的手机信令数据,覆盖北京市范围内2 000 万匿名手机用户,数据采样频率为半小时,主要字段说明如表3 所示。

表3 数据字段说明Table 3 Data field description
经过数据去噪后,本文选取数据质量好、无重大节日影响且具有典型日常生活特征的数据作为UFAI 模型的输入。
2.2 实验设置
本文以北京市作为研究区域,以250 m×250 m为精度将其划分为18 106 个网格区域。通过参考《北京市土地利用总体规划(2006—2020 年)》《北京市主体功能区规划》以及网络地图,选取250 个区域作为训练集,100 个区域作为测试集,经过样本扩充,训练集个数最终为1 250 个,功能区类别有居住区、工作区、其他。同时,本文的多分类模型采用交叉熵损失函数,如式(29)所示:

2.3 实验结果分析
采用本文模型进行训练,实验结果如表4 所示。
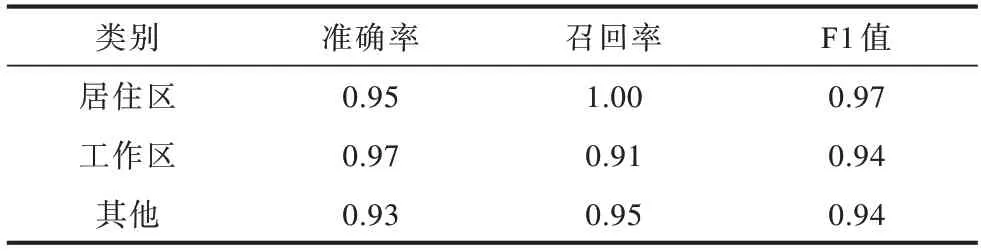
表4 各功能区分类结果Table 4 Classification results of each functional area
图2 为某局部区域对应的功能区分类结果,从中随机选取多个网格进行数据分析,如图3 所示,其中横坐标为一天48 个时间片,纵坐标为各时间片对应人数,不同线条代表一周七天。可以看出:网格①平时人数多于周末人数,且每天人数趋势符合“凸”形;网格②平时人数少于周末,且每天人数区域符合“凹”形。以上数据表现符合日常生活经验。

图2 某局部区域功能区分类结果Fig.2 Classification result of functional area in a local area

图3 一周七天网格内总人数随时间变化曲线Fig.3 Curve of the total number of people over time in the daily grid in a week
实验使用以下对比模型:
1)决策树分类模型(Decision Tree)[22]。
2)随机森林模型(Random Forest)[23]。
3)核函数选择线性函数(SVM)[24]。
4)多项式朴素贝叶斯算法(Multinomial NB)[25]。
5)K 最近邻分类算法(KNN)[26]。
6)逻辑回归算法(Logistic Regression)[27]。
7)集成学习梯度提升决策树分类模型(Gradient Boosting Classifier)[28]。
对比结果如表5 所示,与其他模型相比,本文UFAI 模型具有最好的性能,F1 值达到0.95。

表5 对比实验结果Table 5 Comparison experimental results
3 结束语
本文基于粗粒度匿名个体移动位置数据构建城市功能区识别模型UFAI。挖掘个体出行特征并与局部区域结合,将人群划分为不同类别。在此基础上,通过刻画各个区域内不同人群的出行活动,构建功能区多分类深度学习模型,同时将多个时间周期数据划分为多个训练样本,从而扩充样本集。实验结果表明,UFAI 模型识别准确率达到0.93,相比于决策树、随机森林等分类模型准确率更高。下一步将结合更多识别功能区的人群出行活动特征,扩大本文模型的识别范围。
猜你喜欢
科普童话·神秘大侦探(2022年11期)2022-05-30 03:21:35
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
恋爱婚姻家庭(2020年27期)2020-10-09 04:16:18
山东冶金(2019年3期)2019-07-10 00:53:54
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
百花洲(2018年1期)2018-02-07 16:34:52
现代园艺(2017年23期)2018-01-18 06:57:44
瞭望东方周刊(2017年45期)2017-12-08 21:37:48
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
