
基于改进交错组卷积的眼底硬性渗出物自动分割
2022-07-14 13:11:54白杰李艳萍
计算机工程 2022年7期
白杰,张 赛,李艳萍
(太原理工大学信息与计算机学院,太原 030600)
0 概述
糖尿病视网膜病变(Diabetic Retinopathy,DR)作为糖尿病(Diabetes Mellitus,DM)的主要并发症会导致患者视力下降甚至失明[1]。DM 患者通过定期就医及时排查是否出现视网膜病变,从而降低失明风险[2]。硬性渗出物(Hard Exudate,HE)作为DR 早期特征是由于血管壁受损后大分子物质(脂质和蛋白质)从视网膜血管渗透到眼球所引起,表现为淡黄色或白色块状和点状突出物,其形状、大小、位置呈多样化,随机性较强[3]。在临床诊断中眼底HE 检测结果是DR 诊断以及监测治疗过程中的重要参考[4-5]。
目前,眼底HE 临床检测主要依赖专业眼科医生手动诊断,不仅耗时费力,而且要求较先进的医疗设备和专业水平较高的临床医生。然而,眼底HE 临床检测受DM 患者数量庞大、各地医疗水平不一的限制,难免发生漏诊和误诊[6-7]。因此,结合计算机与图像处理技术的眼底HE 自动分割系统应运而生[8-9]。主流眼底HE 检测算法分为基于阈值、区域增长检测算法,基于数学形态学技术和基于机器学习、深度学习检测算法。基于阈值、区域增长检测算法利用眼底图像不同区域之间的颜色强度变化以及邻域特征差异辨别异常病变。例如,文献[10]利用动态决策阈值法寻找暗边及亮边,有效分割HE 等病灶特征。文献[11]通过提取的眼底特征对糖尿病和正常黄斑水肿进行分类,并在黄斑区标记基础上进行HE 检测,以区分DR 和正常视网膜眼底图像。基于数学形态学技术是采用具有不同元素结构的数学算子识别病灶边界。例如,文献[12]使用灰度形态学和活动轮廓技术检测渗出物及提取眼底HE 精确边界。基于机器学习、深度学习检测算法利用随机森林、集成分类器、深度神经网络等对病灶特征进行多类分割和定位。文献[13]结合自适应阈值及随机森林算法识别渗出物病灶特征,并对其进行分割。文 献[14]采用预训练Inception-v3、ResNet-50 和VGG-19 网络模型检测HE,将模型提取的特征相融合,再由softmax 进一步分类得到最终决策结果。
由于眼底图像中硬性渗出物分布不均匀且与图像背景的对比度较低,因此现有的分割算法难以准确实现硬性渗出物的分割。本文提出一种将改进交错组卷积(Interleaved Group Convolution,IGC)与双重注意力机制相融合的眼底HE 自动分割模型。采用改进的IGC 模块提取病灶特征,通过位置注意力模块联系局部上下文信息,同时利用通道注意力模块确定各特征通道的权重,提升重要特征的可识别性。
1 本文算法
1.1 交错组卷积
在参数量相同的情况下,IGC 比常规卷积网络宽度更宽,有助于每层网络提取更加丰富的特征。此外,IGC 利用深度融合使得不同分支网络在中间层进行融合,并削减卷积冗余单元,提升模型特征融合能力。不同特征融合方法[15]对比如图1 所示。
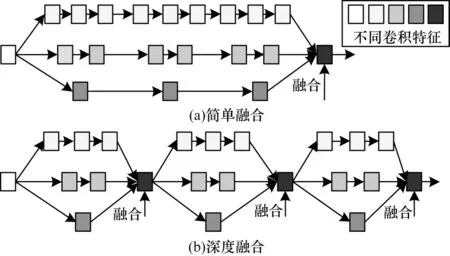
图1 不同特征融合方法对比Fig.1 Comparison among different feature fusion methods
交错组卷积过程如图2 所示。交错组卷积包括首次组卷积和第二次组卷积。在第二次组卷积中每组输入通道均来自首次组卷积中不同的组,以达到交错互补的目的。

图2 交错组卷积过程Fig.2 Interleaved group convolution process
IGC 主要卷积操作如式(1)所示:

其中:[y1,y2,…,yL]T为首次组卷积;为一个M×(M×S)的矩阵对应L分区的卷积核,L表示首次组卷积分组数量以及第二次组卷积每个分组内包含的通道数,M表示首次组卷积中每个分组内包含的通道数以及第二次组卷积分组数量,S为卷积核对应的响应;zL是(M×S)维向量为首次组卷积输入。第二次组卷积是将首次组卷积输出通道混合后,再分为M个2 次分区,每个分区由L个通道组成,使同一级或同二级分区通道来自不同级分区,即第m个二次分区是由每个首次分区第m个输出通道组成,其表达如式(2)所示:
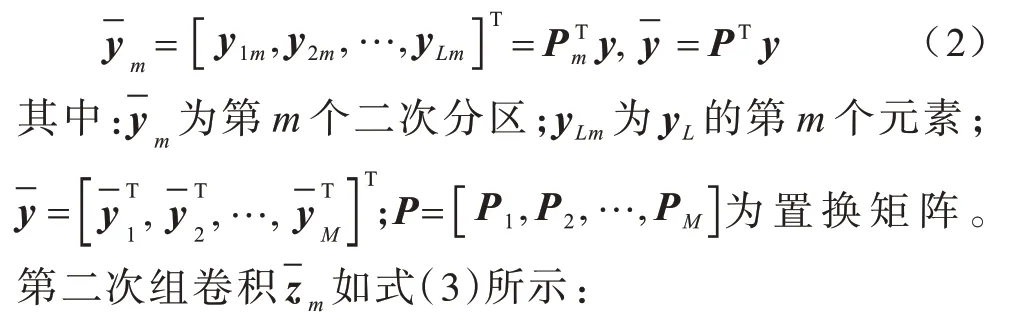

其中:G=M×L为IGC 模块宽度。对于相同卷积核S和输入输出宽度C的常规卷积参数量如式(6)所示:

由于S=3×3,因此当L>1 时,存在G>C。IGC模块比常规卷积更宽(除首次组卷积中L=1 以外)。
为了使IGC 模块有效提取眼底HE 病灶特征,本文对原IGC 模块进行改进,首先增加残差连接用于增强梯度传播,减轻网络退化,其次为防止ReLu 激活函数提取低维度信息时滤除部分有效信息,在低维特征获取阶段使用ReLu6 激活函数。改进的IGC模块相比原模块能够更完整地提取眼底病变特征,提高对病灶区域的定位分割效果。改进的IGC 模块如图3 所示。
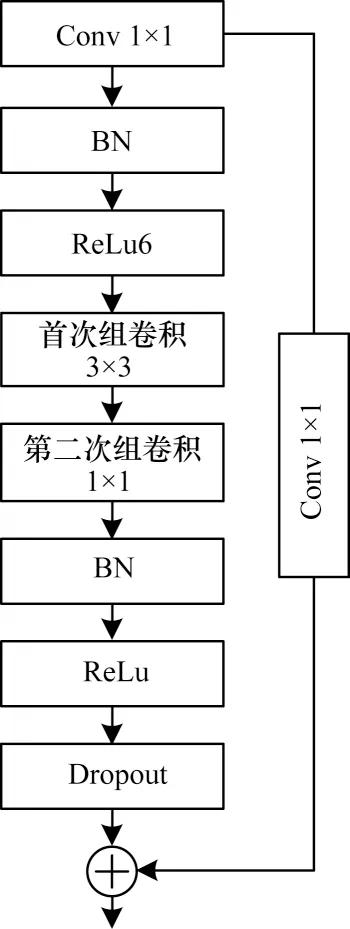
图3 改进的交错组卷积模块Fig.3 Improved interleaved group convolution module
1.2 位置注意力模块
传统卷积神经网络经过多层卷积处理后,感受野被限制在狭小局部空间。为克服局限性,本文引入可联系上下局部特征的位置注意力模块,将更广泛的上下文信息编码为局部特征,增强模型表达能力。传统卷积网络与引入位置注意力机制卷积网络的感受野[16]示意图如图4 所示。
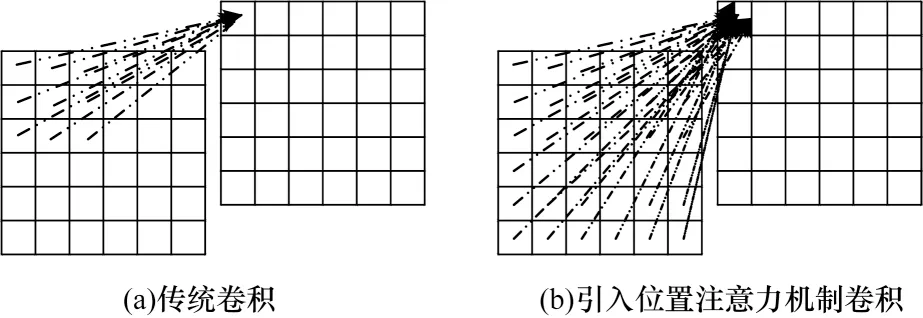
图4 传统卷积网络与引入位置注意力机制卷积网络的感受野示意图Fig.4 Schematic diagram of the receptive field of traditional convolutional network and convolutional network with position attention mechanism
位置注意力模块可以捕获特征图中任意两个位置之间的空间依赖关系,对于单一特定特征,利用全局位置特征对其加权及更新,本文使用的位置注意力模块如图5 所示。

图5 位置注意力模块结构Fig.5 Structure of position attention module
位置注意力模块给定局部特征A∊RC×H×W,通道数为C,长宽分别为H、W,将局部特征引入到卷积层后生成新的特征映射B、C,且满足(B,C)∊RC×H×W,FX为三维特征图经X层卷积压缩后的二维特征图,且满足FX∊RN×C,其中N=H×W。同理,FY、FZ分别为当前特征图经Y、Z层卷积后得到,此后,FX特征矩阵与FY特征矩阵相乘,经softmax 层处理得到位置注意力权重图K,且满足K∊RN×N,如式(8)所示:

其中:kji为位置注意力特征权重图中i与j的关联度。特征A生成的特征映射为D∊RC×H×W后转换为D∊RC×N,然后将D的转置矩阵与K的转置矩阵相乘且满足RC×H×W,引入比例参数β,并对特征A执行元素求和,获得最终输出满足E∊RC×H×W,如式(9)所示:

其中:β从0 逐渐增加权重;Ej为所有位置特征和原始特征的加权和,具有全局上下文视图,根据空间注意图选择性地聚合上下文信息。
1.3 通道注意力模块
通道注意力[16]机制旨在显示不同通道之间的相关性,根据每个特征通道不同重要程度赋予其权重系数,从而强化重要特征抑制非重要特征。通道注意力模块结构如图6 所示。

图6 通道注意力模块结构Fig.6 Structure of channel attention module
通道注意力模块将特征A∊RC×H×W变型为A∊RC×N,使A与其转置矩阵相乘,最后经softmax 层得到通道注意力特征图,如式(10)所示:

其中:xji为i与j的通道关联度。X特征矩阵转置与A特征矩阵相乘,得到的结果满足RC×H×W,添加标度参数η,其权重从0 开始学习,对A执行元素求和,获得最终输出E∊RC×H×W,如式(11)所示:

其中:Ej为每个通道最终特征是所有通道特征和原始特征的加权和,模拟了特征映射之间长期语义依赖关系,验证了通道注意力模块有助于提高特征的可辨别性。
1.4 U 型网络改进
由于眼底图像数据量少,语义信息较简单,在病灶定位分割中低级特征和高级语义信息都极为重要,因此设计模型的参数不适合过大,否则容易导致过拟合现象的发生。U 型网络[17]的编译码过程及在同一阶段使用跳跃连接,而非在高级语义特征上进行监督和损失反传,使得最终得到的特征图融合了更多低层次特征,也使得不同层次特征相融合。此外,上采样使分割图像恢复更加精细的边缘信息。在眼底HE 检测中,为了使模型每一层能够提取更加丰富的特征以及增强重要病灶特征的可辨别性,本文对U 型网络进行优化,改进后的U 型网络整体结构如图7 所示。
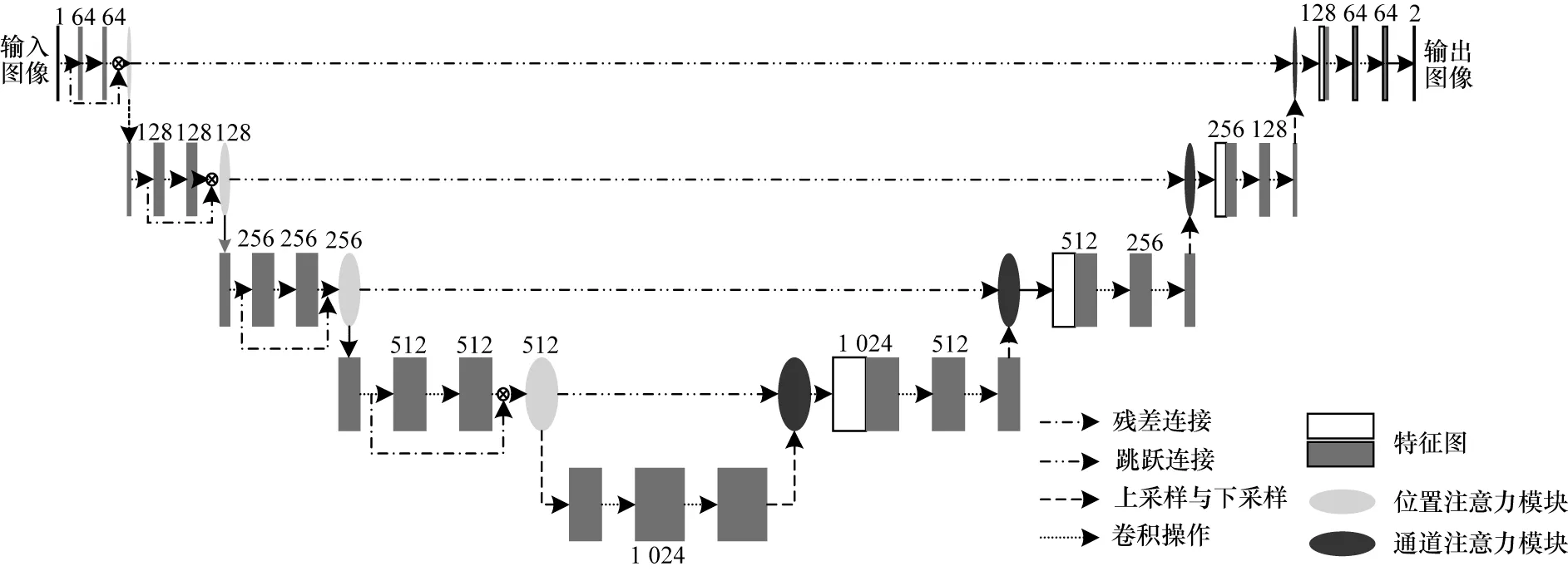
图7 改进的U 型网络整体结构Fig.7 Overall structure of improved U-shaped network
从图7 可以看出,U 型网络左半部分为编码阶段,其目的是提取眼底图像中硬性渗出物多尺度特征,提供分割目标在整个眼底图像中的上下文语义信息。该部分由4 个改进的IGC 模块组成,其较宽的网络模型利于每一层提取更加丰富的特征,之后添加位置注意力模块,通过自适应将图像中任意两个位置关联,增强模型提取眼底图像特征能力,捕获更深层次语义特征信息并过滤掉噪声等与分类任务不相关信息。U 型网络右半部分为解码阶段,其目的是将编码时提取的眼底图像特征信息解释为硬性渗出物的分割结果图。该部分由4 个解码模块组成,在融合高维眼底图像特征与低维眼底图像特征的短连接处引入通道注意力模块,目的是通过专注于重要特征提取通道排除无关特征通道,进一步改善模型的分割效果。
1.5 损失函数
本文将改进U 型网络作为眼底HE 自动分割模型,以改善分割效果。然而眼底图像中硬性渗出物像素与背景像素数量相差较大,极度不平衡的类别分布使分割模型更倾向背景像素,从而影响模型的分割性能。此外,常规损失函数对假阳性及假阴性权重相等,而在眼底图像分析中降低假阴性是获得理想分割效果的关键。因此,本文引入Focal Tversky Loss[18]作为损失函数,以Tversky Loss 损失函数为基础且在多个医学数据集上验证其优异性。Tversky Loss 损失函数通过 超参数α、β控制假阳性和假阴性之间的平衡,如式(12)所示:

其中:pic为预测标签中像素i属于病变类别c的概率为预测标签中像素i属于非病变类别cˉ的概率;gic和分别为真实标签中像素i属于病变类别c及非病变类别的概率;δ是常量防止等式分子为零;N为图像中像素总数量。包含γ变量的FTL(Focal Tversky Loss)损失函数能够解决较小感兴趣区域因损失影响而难以分割的问题,其函数如式(13)所示:

其中:γ∊[1,3],当像素被高Tversky 索引错误分类时,FTL 不受影响。如果Tversky 索引很小并且像素被错误分类时,FTL 将显著降低。当γ>1 时,损失函数集中在被错误分类以及准确率低的区域,本文实验采用α=0.3,β=0.7,γ=4/3。
2 实验结果与分析
实验系统配置为Windows 10 操作系统,NVIDIA Tesla K80显卡,编程基于Tensorflow 和Keras 框架。
2.1 数据预处理
本文分别在公开数据集e-Ophtha EX 及DIARETDB1 上进行实验。e-Ophtha EX 数据集包含47 张视网膜眼底图像,图像大小在1 400×960~2 544×1 696 像素之间,具有像素级人工标定标签。DIARETDB1 数据集包含89 张视网膜眼底图像,分辨率为1 500×1 152 像素,具有图像级人工标定标签。数据集e-Ophtha EX 和DIARETDB1 的视网膜眼底图像样例如图8 所示。

图8 视网膜眼底图像样例Fig.8 Example of retinal fundus images
针对眼底图像分辨率不一、对比度不均匀的问题,本文对眼底图像进行预处理,首先图像大小设置为1 500×1 152 像素,其次从RGB 眼底图像中提取绿色通道图像。本文采用直方图均衡化增强眼底图像对比度,由于位于血管交界处视盘的外形特征与硬性渗出物相似,因此会干扰模型对硬性渗出物后续检测。本文采用文献[19]使用的眼底图像血管提取方法对视盘进行掩盖。数据集e-Ophtha EX和DIARETDB1 的眼底图像视盘定位图如图9所示。

图9 眼底图像视盘定位图Fig.9 Optic disc position map of fundus images
为避免不平衡数据对病灶分割造成干扰,本文对训练集中的所有图像进行旋转、平移以及翻转等变换,裁剪出3 000 个硬性渗出物补丁及3 000 个眼底背景补丁。所有补丁大小设置为96×96,多数传统研究将补丁大小设置为32×32 或者更小。由于本文算法融入可捕获眼底硬性渗出物特征的位置注意力模块,因此需要将补丁尺寸进行适当放大。
2.2 实验设置
本文实验使用Adam 算法对损失函数进行优化,迭代次数为30 次,初始学习率设置为0.001,同时采用λ=0.001 权重衰减防止模型过拟合。像素级评估算法采用灵敏度(SE)、精确度(PPV)和综合性能(F-Score)评估模型性能。图像级评估算法采用灵敏度(SE)、特异性(SP)和准确性(Acc)评估模型性能,如式(14)~式(18)所示:
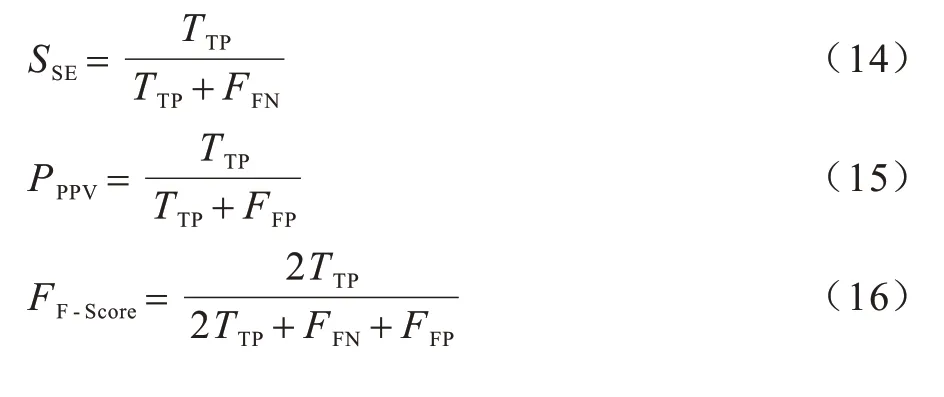
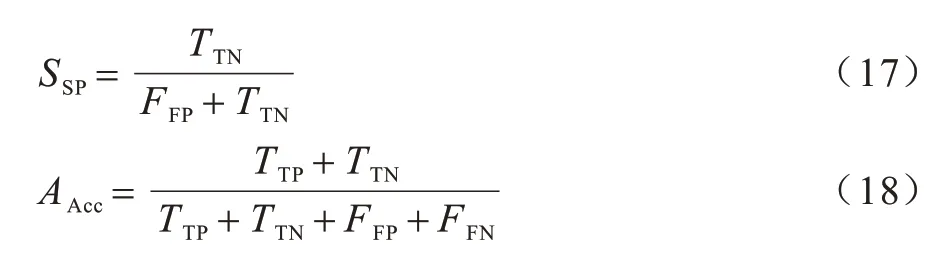
其中:TTP为正确分类的分割物像素;FFN为错误分类的分割物像素;TTN为正确分类非分割物像素;FFP表示错误分类为分割物像素的非分割物像素。
2.3 实验结果
本文提出硬性渗出物分割模型在数据集e-Ophtha EX 上获得的分割图像已较为接近眼科专家手动标注的像素级标签图像,但是分割效率远高于专家手动分割。在数据集e-Ophtha EX 上本文模型的分割结果如图10 所示。

图10 在e-Ophtha EX 数据集上本文模型的分割结果Fig.10 Segmentation results of the proposed model on the e-Ophtha EX dataset
2.3.1 与其他模型对比
在数据集e-Ophtha EX 和DIARETDB1 上本文提出的眼底HE 自动分割模型与其他模型的评价指标对比如表1 所示。
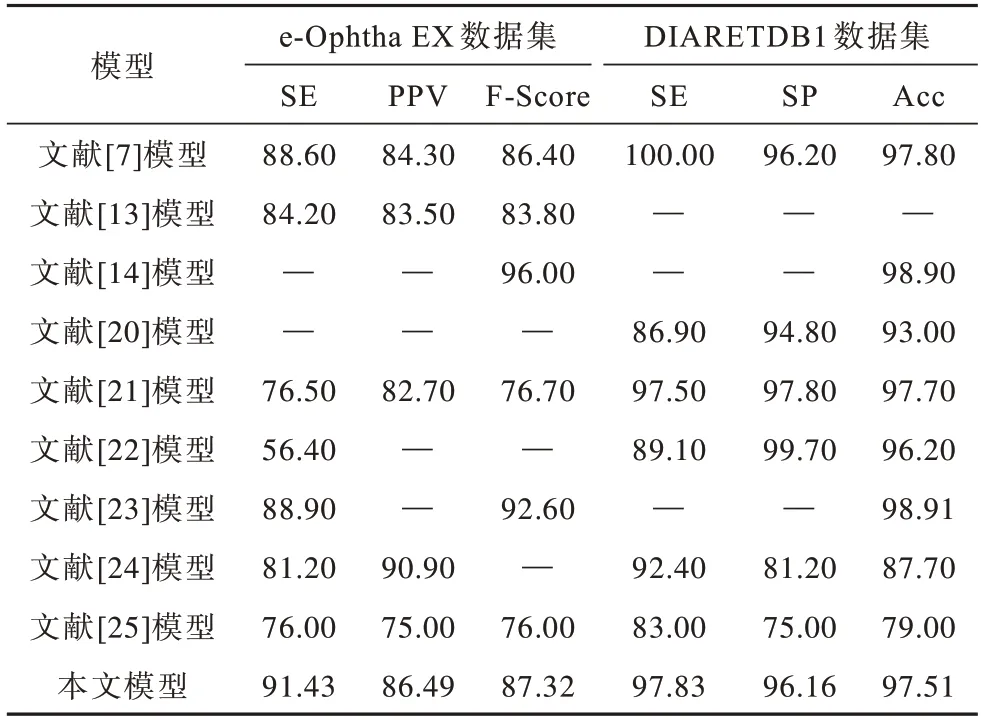
表1 不同模型的评价指标对比Table 1 Evaluation indexs comparison among different models %
从表1 可以看出,在e-Ophtha EX 数据集上本文模型的SE、PPV 和F-Score 平均性能指标分别达到91.43%、86.49%、87.32%,在DIARETDB1 数据集上SE、SP 和Acc 平均性能指标分别达到97.83%、96.16%和97.51%。与其他模型相比,本文模型的评价指标均属于最高或次高水平。因此,本文模型整体分割性能优于其他模型。
2.3.2 数据集不同分配对分割性能的影响
为验证实验结果是否与数据集分配方式有关,本文设置3组对比实验:70%用于训练,30%用于测试;80%用于训练,20%用于测试;90%用于训练,10%用于测试。本文模型在数据集不同配比下训练的结果如表2所示。从表2可以看出,在数据集e-Ophtha EX和DIARETDB1上,本文模型在80%用于训练分割模型和20%用于验证条件下的分割效率最高。
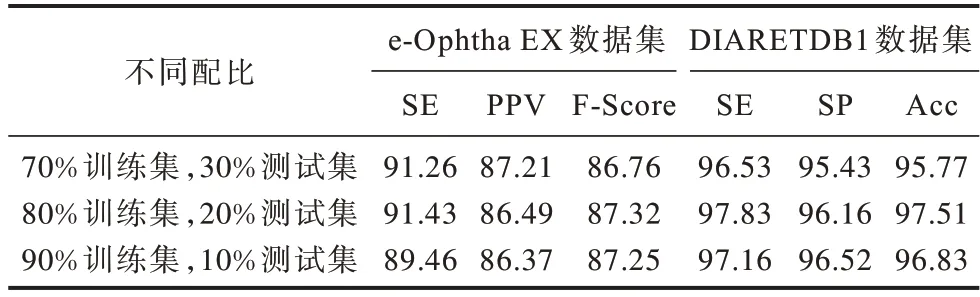
表2 本文模型在数据集不同配比下的评价指标Table 2 Evaluation indexs of the proposed model according to different ratios of dataset training %
2.3.3 超参数对分割性能的影响
为保证模型分割效果最佳,本文设置多组对比实验。不同学习率对模型学习曲线的影响如图11 所示。

图11 不同学习率对模型学习曲线的影响Fig.11 Influence of different learning rates on model learning curves
从图11 可以看出,当初始学习率为0.01 时,梯度更新步长较大,导致损失函数过早收敛,损失值偏大。当初始学习率为0.000 1 时,梯度更新步长较小,收敛速度较慢,容易发生过拟合现象,并且得到的损失值偏高。因此,在构建模型时,本文选用0.001 作为初始学习率,梯度更新步长适中,收敛速度较快,得到的损失值也最佳。
不同权重衰减值对模型学习曲线的影响如图12所示。本文选用0.001 作为惩罚系数能够避免模型训练过程中出现过拟合现象。
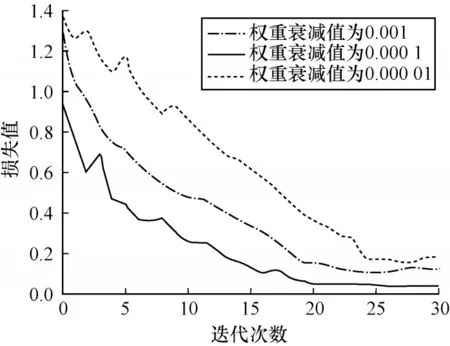
图12 不同权重衰减值对模型学习曲线的影响Fig.12 Influence of different weight attenuation values on model learning curves
2.3.4 不同网络结构对分割性能的影响
本文利用改进的IGC 模块代替原始U 型网络编码器部分,为验证改进的IGC 模块更适合用于眼底HE 检测,将其与常见模块进行对比。在数据集e-Ophtha EX 和DIARETDB1 上不同模块的评价指标如图13 所示。从图13 可以看出,本文改进的IGC模块在两个公开数据集上各评价指标均优于ResNet34 以及Inception-v3 模块,说明本文的眼底HE 自动分割模型综合性能更优。

图13 不同模块的评价指标对比Fig.13 Evaluation indexs comparison among different models
2.3.5 不同U 型网络对分割性能的影响
本文设置4 组对比实验,验证改进U 型网络对模型分割效率的影响。在数据集e-Ophtha EX 和DIARETDB1上不同U 型网络的性能评估如表3所示。模型1 表示原始U 型网络模型;模型2 表示仅在U 型网络编码阶段加入位置注意力模块;模型3 表示仅在U 型网络解码阶段加入通道注意力模块;模型4 表示仅用改进的IGC 模块代替U 型网络编码器部分。
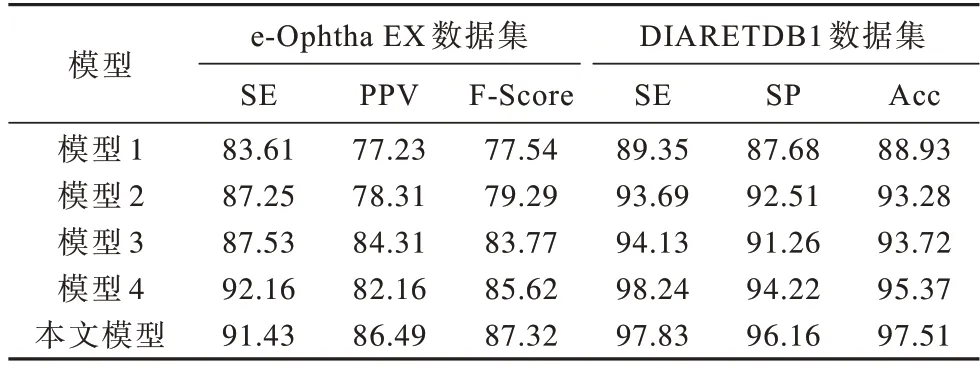
表3 不同U 型网络模型的评估指标对比Table 3 Evaluation indexs comparison among different U-shaped network models %
从表3 可以看出:无论是U 型网络编码阶段还是解码阶段,加入注意力机制的U 型网络能够改善模型整体分割性能;采用改进的IGC 模块可以提高原始U 型网络模型的灵敏度;采用本文所提眼底HE分割网络模型有效改善原始U 型网络对眼底HE 的分割效果。
3 结束语
本文提出一种基于交错组卷积的眼底硬性渗出物自动分割模型。以U 型网络模型为架构,在编码和解码部分引入位置注意力模块和通道注意力模块,扩大模型感受野以及增强重要特征的可辨别性,利用改进的交错组卷积模块代替原U 型网络编码部分,提取更丰富的病灶特征。实验结果表明,本文模型具有较优的分割准确率,能够有效改善原始U 型网络对眼底硬性渗出物的分割效果。后续将通过对视盘附近被掩盖的硬性渗出物进行更深层次检测,同时优化本文模型的检测功能,使其能够精确且高效检测眼底图像中的其他病变特征,如微动脉瘤、出血点、软渗出物等,以提升模型的泛化能力。
猜你喜欢
四川水泥(2024年4期)2024-04-23 14:37:10
计算机系统应用(2022年6期)2022-06-29 07:48:16
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
上海大中型电机(2021年2期)2021-07-21 03:01:32
世界中医药(2020年14期)2020-08-07 05:39:22
计算机工程与应用(2020年11期)2020-06-09 07:22:24
传媒评论(2018年12期)2018-03-21 07:51:54
中国眼镜科技杂志(2017年13期)2017-08-16 03:13:54
传媒评论(2017年3期)2017-06-13 09:18:10
光电工程(2016年12期)2017-01-17 05:03:31
