
基于眼脑数据和问卷分析的泳装图像情感因子空间构建
2022-07-14 05:57王伟珍
毛纺科技 2022年6期
高 君,王伟珍,2
(1.大连工业大学 服装学院,辽宁 大连 116034; 2.大连工业大学 服装人因与智能设计研究中心,辽宁 大连 116034)
人工智能服装的设计涉及对服装图像的识别、分类标注等。关于服装图像的情感标注,多为专业设计人员对现有服装图像进行主观情感标注,再进行后续的分类、检索、匹配等方面的研究。
人的情感具有复杂性、模糊性和不确定性的特点。目前用于情感的研究方法有眼动追踪、脑电信号分析、PAD三维模型、面部表情分析等,其中眼动追踪[1]和脑电信号分析对受试者思维过程和大脑状态的变化具有较强的表征能力。Yanulevskaya等[2]通过眼动追踪实验确定了人的情感与各种当下状态之间的联系。Colombo等[3]以5个室内空间图像为测试样本,探索环境表现如何影响人的愉悦感。Khushaba等[4]从消费者神经科学的角度出发,根据眼部运动和脑电图实验,评估了人的不同偏好是如何刺激大脑的。基于人眼、脑的情感识别[5-6]和情绪分类方面[7-8]的研究取得了较多进展,可见情感计算领域已经成功地与眼、脑电信号的变化联系起来[5]。
本文提出一种泳装图像的情感分类量化方法,以泳装图像为载体,通过眼动实验、脑电信号分析实验收集客观生理数据;通过问卷调查的方法收集主观数据,主观数据结合客观验证,以期建立更为准确的泳装图像情感因子空间,为后续的图像情感标注识别、人工智能服装设计打下基础。
1 实验设计
1.1 设备及受试者
实验设备:Tobii Glasses型眼动仪(北京津发科技股份有限公司);BitBrain型半干电极16通道脑电系统(北京津发科技股份有限公司)。
受试者:样本图片均为女性泳装,消费者和穿着者绝大部分为女性,因此选择的受试者以女性为主,共选择30名18~25岁健康男女(无色盲、色弱等其他影响实验的生理疾病),其中男性8人,女性22人,编号为A1~A30。
1.2 前期准备
形容词对的选取:从泳装比赛、相关杂志、书籍和大众对泳装的常见描述中,采集了60个常用于评价泳装的形容词。
形容词对的筛选:邀请10位服装领域的专家对采集的60个形容词进行评审筛选,并将筛选到的形容词进行匹配。最终选定8对用来评定泳装图像情感的词汇对:素雅的—花哨的、性感的—保守的、时尚的—传统的、活泼的—呆板的、柔美的—阳刚的、简洁的—繁复的、独特的—大众的、年轻的—成熟的。
样本图片的选取:考虑到泳装的特殊性以及为避免其他因素的干扰,实验选择的泳装图片均为无人体穿着的立体效果图。从网络遴选下载500张无背景及人物的泳装图片,依据淘宝销量、流行趋势、款式、颜色,从中筛选得到20幅样本图片,如图1所示,样本编号为1~20。

图1 样本图片Fig.1 Sample picture
问卷编写:要求受试者对每张样本图片进行感性评分,问卷评分采用7点李克特式量表。以“素雅的—花哨的”举例,1分表示“非常素雅”,7分表示“非常花哨”,由1分到7分,素雅到花哨的程度依次增加。另外,受试者还需对20个样本进行喜爱度评分,1分表示最不喜欢,7分表示最喜欢。
1.3 实验流程
向受试者介绍实验过程及注意事项,协助受试者佩戴好脑电帽和眼动仪并连接到计算机上进行校准,同时确保受试环境安静舒适。
正式实验时,首先电脑屏幕呈白色,且正中间会出现出一个红色“十”字,时间为2 s,此时受试者的注意力集中在此区域;当白色屏幕消失时,会呈现出第1个泳装图像,时间为8 s;接着呈现第1个形容词,请受试者判断该词是否与样本图片相符,“是”对应点击鼠标左键,“否”则点击鼠标右键;点击之后会出现下一个形容词,直至所有形容词被选择完毕。之后电脑显示2 s的白屏,以消除之前的视觉残余,帮助受试者平复情绪状态;当白色屏幕再次消失时,呈现出新的样本,依次直至实验结束。整个实验流程较长,为避免受试者出现疲劳状况,中间设置2次休息时间。在眼脑实验结束后,受试者将在电脑上填写关于样本图片的感性评价量表,以记录受试者的情感反应。实验流程如图2所示。

图2 实验流程Fig.2 Experimental process
2 数据处理与分析
2.1 眼动指标选取
兴趣区总注视时长和兴趣区注视点个数在喜爱度研究实验中使用频率较高[9-12],本文眼动实验也选择这2个指标来分析受试者对泳装图像样本的喜爱程度。
兴趣区总注视时长:受试者在特定区域的注视时间的总和。该指标数值越大,则表明受试者对此区域更感兴趣或是偏好程度更高。
兴趣区注视点个数:受试者在特定区域内的注视点数的累计。该指标数值越高,则表示受试者对此区域更感兴趣或是偏好程度更高。
2.2 脑电指标的选取
在大脑皮层各区域中,额叶区主导认知信息的采集[13],且人类的左脑和右脑在情感处理方面分工不同,一般而言,消极情感的处理主要在右脑完成,而积极情感的处理主要集中在左脑。因此提取左额叶电极F3与右额叶电极F4为主要获取认知信息的途径。有研究表明脑电各通道信号中的α波和情感处理有关[14],因此在脑电指标的选择上,选择额区α波不对称指数,其指右脑额叶区α波功率和左脑额叶区α波功率的差,即额区α波不对称指数=F4电极α功率-F3电极α功率。该指数越大,说明对应词汇越能引起受试者的积极情感,相反地,该指数越小,则对应词汇越能引起受试者的消极情感。
2.3 实验数据处理
眼动数据处理:眼动追踪数据使用Tobii Studio分析软件处理,绘制各样本的兴趣区,并提取受试者在兴趣区内的注视点个数及注视时长,用Excel软件进行均值处理。
脑电数据处理:首先对数据进行预处理,将脑电信号内存在的干扰信号如皮电、心电等利用滤波以及独立成分分析的方法去除;接着对脑电信号进行分段处理,将形容词显示时所在时间段的脑电信号提取出来;最后计算功率谱密度,通过傅里叶变换的方式,实现脑电信号到α频段的映射,计算α频段功率谱。脑电功率谱由密度积分式计算得到[15]:
(1)
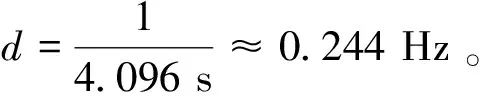
主观问卷数据处理:利用Excel统计受试者对每个样本的喜爱度评分,并取均值,得到每个样本的喜爱度评分。
2.4 结果与分析
2.4.1 眼动数据
对眼动仪收集到的注视点个数和注视时长进行处理,图3表示的是受试者对20个样本的注视点个数以及注视总时长,可以看出,受试者对样本2、4、9、12、13、18、20的注视点个数和注视总时长均较高,即受试者在观察以上样本时的注视次数较高、注视时长较长,兴趣较高,较为喜欢;而在观察样本1、5、8、14、15、19时,注视点个数和注视总时长均较低,注视频率较低,兴趣不高,偏向于不喜欢。
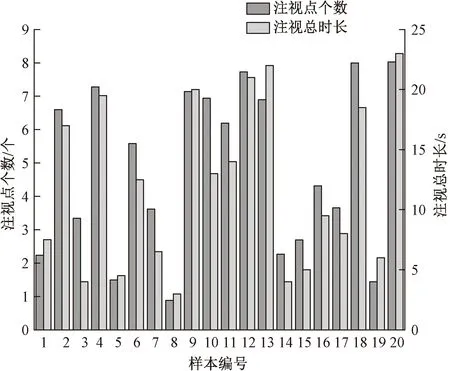
图3 注视点个数和注视总时长Fig.3 Number of fixations and total fixation duration
受试者对样本喜爱度的主观评分结果见图4。可以看出,受试者对样本4、9、10、12、13、18、20的喜爱度更高;对样本1、5、8、14、15、19的喜爱度偏低。
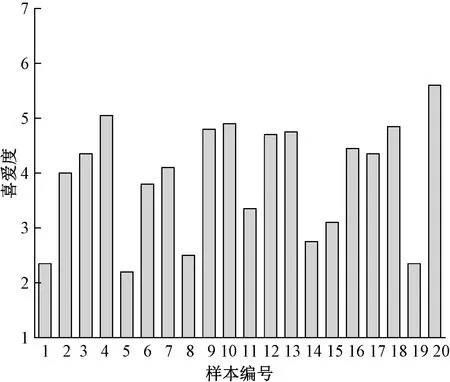
图4 样本喜爱度Fig.4 Sample liking
综合眼动实验结果和主观问卷结果,表明受试者对样本4、9、10、12、13、18、20的较为喜爱;对样本1、5、8、14、15、19较不喜欢。生理实验的数据和主观喜爱度数据完全相符。
2.4.2 脑电数据
脑电频谱计算的依据来源于受试者在判断词汇是否与样本图片相符时,所产生的脑电信号。F3、F4电极的额区α波不对称指数如表1所示。由实验结果可以看出,以“素雅的—花哨的”为例,受试者在对该组形容词进行匹配判断时,“素雅的(0.033)”相对于“花哨的(-0.011)”更能引发较大的额区α波不对称指数,结合2.2中的介绍,即说明受试者在判断“花哨的”是否符合样本时更能产生消极情绪,而在判断“素雅的”是否与样本一致时更能产生积极情绪。因此“素雅的”“性感的”“时尚的”“活泼的”“柔美的”“简洁的”“独特的”“年轻的”形容词比对应词汇更能诱发较大的额区α波不对称指数。说明受试者在判断以上形容词是否符合样本时更能产生积极情绪。
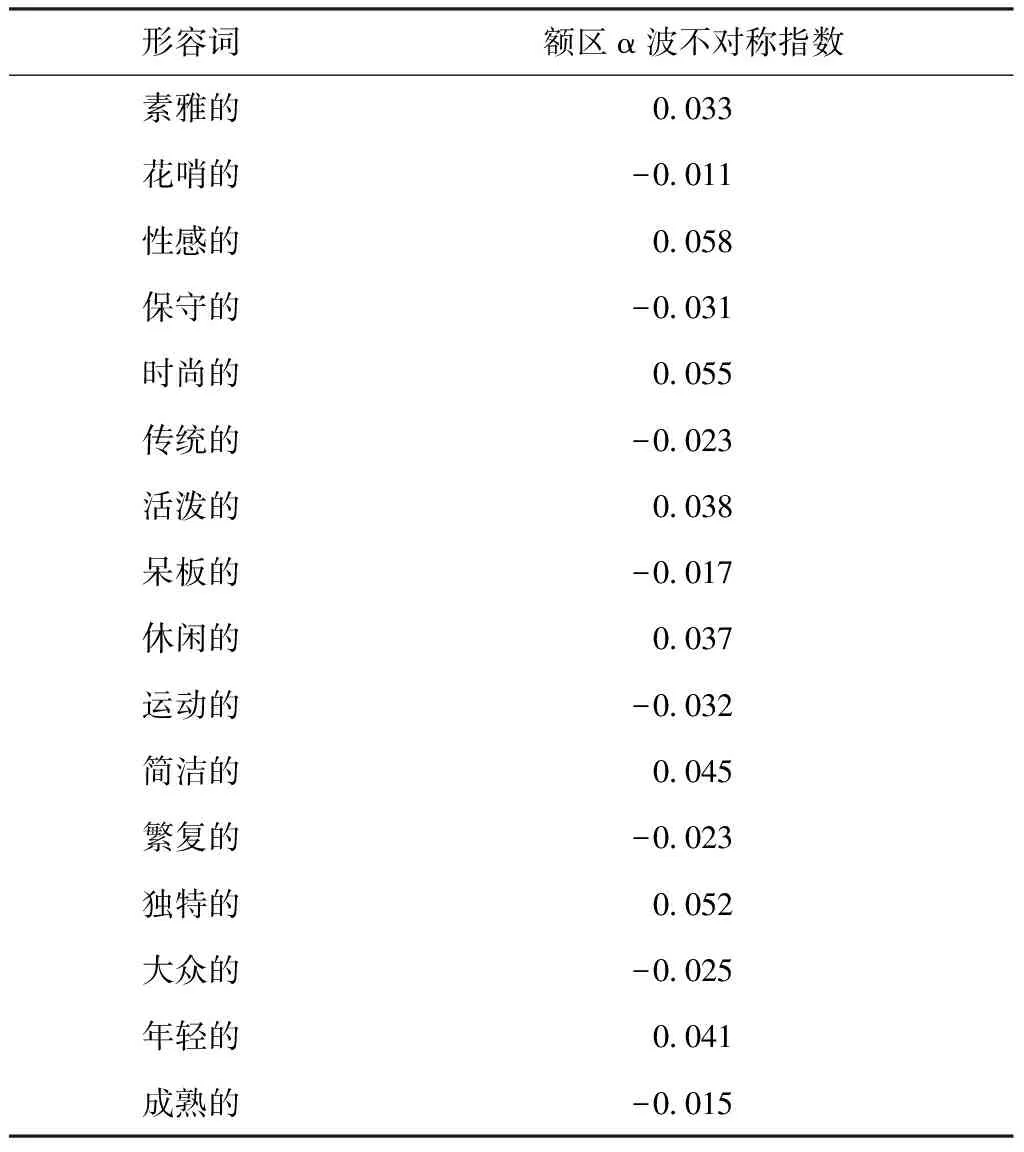
表1 额区α波不对称指数Tab.1 Frontal region α wave asymmetry index
由喜爱度评分和主观感性评价问卷对比可知,喜爱度较高的样本,如样本4、18对应的词汇评分也更偏向于能引发积极情绪的一侧词汇(如年轻的、独特的、简洁的等);受试者喜爱度较低的样本,如样本19对应的词汇评分则偏向于更能引发消极情绪词汇的一侧(如成熟的、大众的、繁复的等),如图5问卷形容词得分举例所示,其他未在图中示出的17个样本也基本符合这一情况。
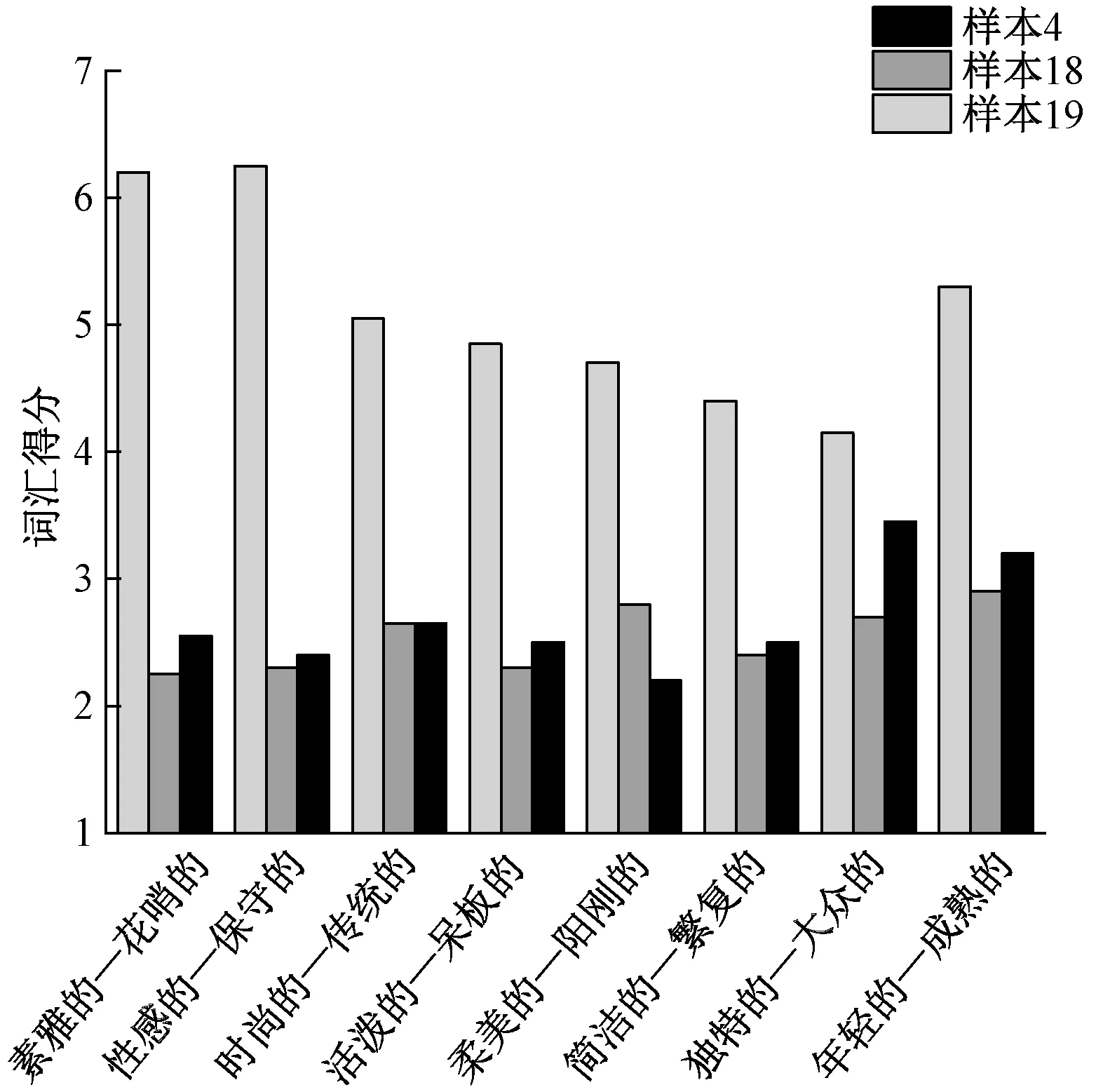
图5 问卷形容词得分举例Fig.5 Example of adjective score in questionnaire
综上,眼动指标和脑电信号的额区α波不对称指数综合证明了主观问卷数据的可靠性。这为后面对问卷数据进行因子分析奠定了基础。
近年来,国内视频监控市场每年都在以超过20%的速度增长,随着平安城市等大型联网监控项目的普遍建设,高清IP监控产品得到广泛应用,系统点位容量和行业需求不断激增,越来越多的用户认识到安防监控平台软件是整个系统综合实力的重要表现。
3 泳装图像情感因子空间的建立
由问卷调查数据可以建立初步的八维泳装图像情感语义空间,此空间内的样本图像的情感语义可通过8个形容词对的值定量表示。由于大众对形容词理解的不一致性和对情感评价的主观性,最初选择的8个形容词对在对样本图像进行情感描述时可能存在一定的相关性,所以,需要对原始数据进行因子分析和降维处理,以消除冗余并建立最终的情感因子空间。
3.1 相关性分析
利用SPSS软件对主观问卷获得的泳装图像8对情感词数值的相关性进行分析,结果见表2,相关系数基本在0.5以上,表明这8对情感词之间有较强的相关性,适合做因子分析。
对表2中的数据进行效度查验,可得KMO数值是0.766(>0.7),Bartlett球度检验数值是167.349(当自由度是28时),二者说明了原数据矩阵之间含有相关因子,可以进一步做因子分析。

表2 8对情感词对Pearson相关性分析结果Tab.2 Pearson correlation analysis results of 8 pairs of emotional words
3.2 因子分析
利用SPSS软件对原始数据做降维处理。碎石图中特征根从第4个因子开始越变越小,在诠释初始变量信息方面的贡献较小,再结合特征根选取原则,最终选择前3个因子做后续分析。
因子解释变量总方差的结果见表3。表3示出的3个因子能够诠释泳装图像情感初始变量总方差的92.325%,在降维过程中仅损失了不到8%的数据,占总数据比例较小,符合预期效果,说明原始数据可以用来做因子分析。

表3 因子解释变量总方差的结果Tab.3 Results of total variance of factor explanatory variables
泳装图像情感语义描述词数值的计算公式能够从因子载荷矩阵函数模型中得出。经正交旋转得到的因子载荷矩阵具有揭示因子和变量间相关程度的特性。某一因子与变量之间相关程度更高,那么对应数据的绝对值也更大;相反地,若二者之间相关程度较低,则对应数据的绝对值也越低。经正交旋转的因子载荷矩阵见表4。因子分析中各个因子彼此之间在互相独立的同时,还与各对情感词有一定的关联。表4示出,各对情感词都与3个因子的成分特征向量对应,所以将其当作3个因子之间的线性组合,经旋转后共同构成因子成分系数函数。
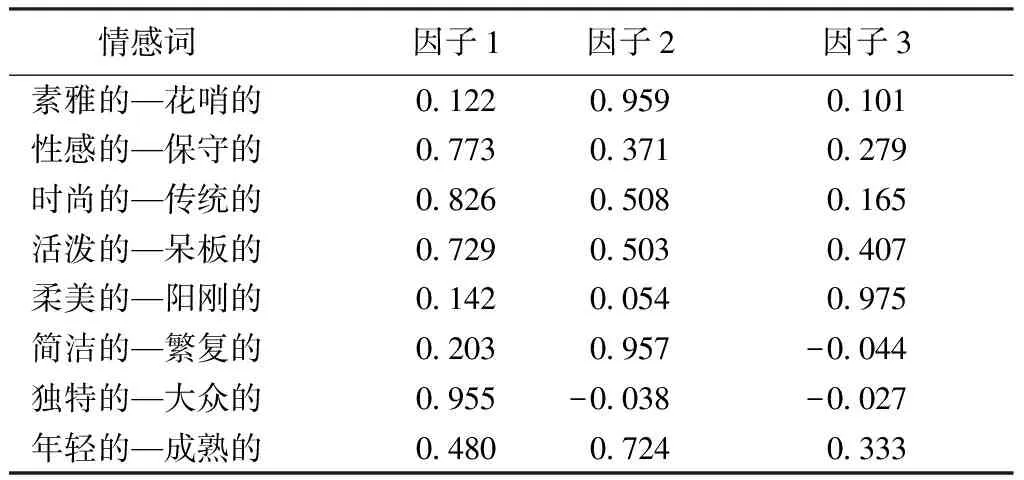
表4 因子载荷矩阵Tab.4 Factor load matrix
E1=0.945f1-0.056f2+0.078f3
(2)
E2=0.203f1+0.922f2+0.152f3
(3)
E3=0.111f1+0.962f2+0.108f3
(4)
E4=0.914f1+0.104f2-0.189f3
(5)
E5=0.774f1+0.494f2-0.150f3
(6)
E6=0.159f1+0.466f2+0.823f3
(7)
E7=-0.247f1-0.047f2+0.922f3
(8)
E8=0.829f1+0.455f2+0.006f3
(9)
式中:f1代表因子1,f2代表因子2,f3代表因子3。
3.3 泳装图像情感因子空间的建立
采用因子分析中的回归法得到表5中因子得分系数。

表5 因子得分系数矩阵Tab.5 Factor score coefficient matrix
根据表5得出的因子得分函数如式(10)~(12)所示:
f1=-0.196E1+0.261E2+0.282E3+0.174E4-
0.166E5-0.117E6+0.533E7+0.002E8
(10)
f2=0.437E1-0.036E2+0.031E3+0.027E4-
0.110E5+0.431E6-0.253E7+0.207E8
(11)
f3=-0.031E1+0.048E2-0.088E3+0.168E4+
0.899E5-0.190E6-0.247E7+0.132E8
(12)
从因子得分函数得出:第1个因子主要与“性感的—保守的”“时尚的—传统的”“独特的—大众的”相关,第2个因子主要与“素雅的—花哨的”“简洁的—繁复的”相关,第3个因子主要与“柔美的—阳刚的”相关。同时从主成分分析可以看出,3个因子共解释原有8对情感语义信息的92.325%,说明这3个因子能够用来进行泳装图像情感语义分析。
在眼脑实验和问卷调查之后,对问卷数据进行分析得到8对形容词的主观评估值,并建立了泳装图像的初步的八维情感语义空间。通过因子分析,由因子得分系数矩阵计算得出3个因子的数值,即将初始八维的情感语义空间变换为新的三维情感语义空间,即情感因子空间,具体见式(10)~(12)。转换之后,一是减少了情感语义的维度,二是三维因子空间中每个因子都是独立的、与其他因子无关的,各个泳装图像对应的每个语义分量彼此是正交独立的,这使得进一步计算空间中样本点的距离更加合适、紧凑,即降低了计算机提取服装图像信息特征的难度,也有利于对泳装图像进行情感识别、分类、检索等后续工作。
4 结束语
本文以泳装图像为研究对象,围绕泳装图像情感因子空间的建立展开了研究。通过对眼脑实验数据和调查问卷数据的分析建立了泳装图像的三维情感因子空间,其结果表明,因子空间中3个因子可以解释泳装图像初始情感信息的92.325%,解释效果较好。该因子空间是实现计算机对泳装图像情感识别及量化评价的重要前提指标,可以为人工智能服装设计提供更为客观准确的泳装图像情感标注。同时该方法也可以应用于其他种类的服装情感因子空间的建立。
人工智能设计过程中对服装情感标注的属性数量会远超8对词汇,本文实验仅针对其基本原理展开。后续将继续研究情感因子空间中3个因子的特征提取,为泳装图像情感标注奠定基础。
猜你喜欢
世界最新医学信息文摘(2022年43期)2022-11-19
汽车实用技术(2022年7期)2022-04-20
载人航天(2021年5期)2021-11-20
大自然探索(2019年7期)2019-12-13
中国化妆品(2018年6期)2018-07-09
Coco薇(2017年7期)2017-07-21
现代家长(2016年11期)2016-12-05
健康女性(2016年8期)2016-09-22
健康女性(2016年8期)2016-09-22
党的生活(黑龙江)(2016年8期)2016-08-15
