
基于生成式对抗神经网络的股票预测研究
2022-07-13 01:57严冬梅
计算机工程与应用 2022年13期
严冬梅,李 斌
天津财经大学 理工学院,天津 300222
随着我国经济的高速发展,人们投资理财的意识不断提高。股票作为一种操作便捷、高风险、高收益的投资标的,深受广大投资者关注。影响股票价格走势的因素很多,例如数据体量大、难以量化。传统的股票预测方法以计量经济学为主。20 世纪80 年代,随着玻尔兹曼机和反向传播(backpropagation,BP)算法[1]的出现解决了多层网络的训练问题,神经网络逐渐走进了研究人员的视野。文献[2-4]等学者将BP神经网络用于股市建模与决策,证明了BP 神经网络对股票预测存在实用性价值。
近年来随着循环神经网络在解决时间序列问题上展现出的独特优势,不少专家学者利用长短期记忆(long short-term memory,LSTM)人工神经网络、门控循环单元(gated recurrent unit,GRU)等循环神经网络及其变体进行股票预测,取得了不错的效果。文献[5]论述了使用BP 神经网络进行股票预测存在的诸多不合理性,创新性地将LSTM 网络用在股票这种金融时间序列的预测研究上。虽然只是对LSTM模型进行参数优化,未涉及模型上的改进创新,但是通过实验对比仍旧验证了LSTM模型在股票预测上比BP网络模型更加精准。文献[6]以美股中微软等有代表性的股票作为研究对象,利用LSTM网络进行预测,结果表明LSTM模型在美股预测中可以保持较高的预测精度。文献[7]提出了一种基于主成分分析的LSTM模型对股票进行预测,将行情数据与技术面数据结合在一起通过主成分分析对数据进行降维,再通过LSTM 模型对股票数据进行预测,与传统的LSTM相比大大降低了预测误差,并且减少了运行时间。文献[8]等以LSTM模型为主体,以一定序列长度的数据作为一个测试集,通过这个测试集去预测下一个点的收盘价;再把这个点的收盘价加入到测试集中,循环往复,证明了周数据相较于日数据在预测中得到的准确率更高。
注意力机制首先被应用于图形图像领域,由于其优秀的性能表现,逐渐被应用到自然语言处理等领域。对于股票等金融时间序列,注意力机制也逐渐被广大学者所应用。文献[9]提出了基于改进自注意力(selfattention)的股价趋势预测模型,分别对日线数据和分时线数据进行编码和融合,学习资金流变化对股票变化趋势的影响,大幅度提升了股票预测的准确率。文献[10]提出了一个基于自注意力的LSTM-CNN股票走势预测模型,将LSTM-CNN模型与自注意力机制相结合,通过实验证明了此模型具有出色的泛化性。文献[11]提出了基于attention 机制的GRU 股票预测模型,将GRU 模型与attention机制相结合进行预测,通过注意力机制对时间维度的重要特征进行捕捉,相较于没有添加注意力机制的GRU模型,实验效果有明显的提升。文献[12]在结合注意力机制的GRU模型的基础上结合了经验模态分解使得实验效果进一步提升。
与此同时,随着对深度神经网络的研究进一步深入,许多优秀的神经网络模型不断被提出。2014 年,Goodfellow 等[13]在神经信息处理系统大会(NIPS)发表论文Generative Adversative Nets,第一次正式提出生成式对抗神经网络(generative adversarial network,GAN)[13]。生成式对抗神经网络优秀的表现,吸引越来越多的学者对其进行研究探索,出现了许多基于对抗神经网络的改进模型,在图像处理等众多领域取得了杰出的成果。
文献[14]对Goodfellow 等[13]提出的GAN 模型做了变化,提出了一种条件型生成式对抗网络(conditional generative adversarial network,cGAN)。cGAN 相较于GAN 最大的优势在于在引入了条件这一概念,通过对生成器和判别器添加约束条件的方式使得训练自由度降低。约束条件可以为一个标签、一个图片等,这个标签或者图片作为一个条件变量对生成器生成的数据进行指导。文献[14]通过添加约束变量的方式将无监督学习的GAN 网络转变为有监督学习的cGAN 网络。cGAN 的出现使得GAN 网络可以应用于监督学习,为GAN 网络的进一步研究奠定了基础。文献[15]提出了深度卷积生成式对抗网络(deep convolutional generative adversarial network,DCGAN),首次将卷积神经网络(CNN)与GAN 相结合,将CNN 应用于GAN 的生成器和判别器中。DCGAN 在图像领域取得了优秀的实验效果。
考虑GAN 模型的优秀性能及其可以处理时间序列问题,本文以GAN模型作为基础模型,提出了自注意力残差生成式对抗网络模型(self-attention and resnet generative adversarial network,SAR-GAN)对股票价格进行预测。该模型的生成器(generator)由长短期记忆网络(LSTM)层、自注意力机制层、残差层等构建而成,判别器(discriminator)由全连接网络构建而成,并且在模型中加入L2正则项防止训练过程中出现过拟合的情况。
实验方面,选取上证指数(SSEC)及多个股票市场中热点行业的龙头股票数据,将SAR-GAN模型进行预测的结果与其他模型的预测结果相对比。实验结果表明:相较于选取单一市场股票数据训练出来的模型,SAR-GAN模型的预测误差更小,泛化性更强,可适用于不同股票市场股票价格的预测。
1 生成式对抗神经网络
生成式对抗神经网络是由Goodfellow 等[13]在2014年正式提出的。GAN 是一个生成式模型,由生成器和判别器两个部分组成。GAN符合博弈论中的零和博弈理论,在图形图像领域中有着广泛应用。
1.1 判别式模型与生成式模型
判别式模型是以条件概率分布为基础的模型,是通过样本的属性X的特征来判断样本所属的类别Y。通俗地讲,如果要确定一幅图片中的孩子是男孩还是女孩,判别式模型就是通过大量的男孩女孩的图片来学习男孩女孩不同的特征,再根据这幅图片中的孩子的特征来判断图片中的孩子是男孩还是女孩。
生成式模型是以联合概率分布为基础的模型,目的是得到属性为X并且类别为Y的联合概率分布。同样要确定一幅图片中的孩子是男孩还是女孩,其方法与判别式模型是不同的。首先根据男孩的特征学习出一个男孩的模型,根据女孩的特征学习出一个女孩的模型;再从图片中提取出孩子的特征,放在男孩模型中得到孩子是男孩的概率,放在女孩模型中得到孩子是女孩的概率;最后通过对比两个概率大小就可以判断出图片中的孩子是男孩还是女孩。
1.2 生成器与判别器
1.2.1 生成器
生成器(generator,用G 表示),通过学习样本的真实分布,输出一个根据真实分布生成的生成分布数据,其结构如图1所示。假设已知某种分布,首先,从该分布pz(⋅)中采样得到隐藏变量z,然后依据参数化的pg(x|z)分布,由生成器获得生成样本x~pg(x|z)。

图1 生成网络结构图Fig.1 Generating network structure diagram
对于所输入的符合某种真实分布的数据样本,生成器能够通过多层感知机或者深度神经网络生成所期望数据分布的生成数据。
1.2.2 判别器
判别器(discriminator,用D表示),用来区分由生成器生成的生成数据与真实数据。判别器D 的输出范围为[0~1],当判别器D 的输出为0 时,判别器D 判断生成的数据为生成器生成的数据;当判别器D 的输出为1时,判别器D判断生成的数据为真实数据。
判别网络结构如图2 所示。判别器D 接受从生成器产生的生成数据xf~pg(x|z),同时接受从数据集中采样出的真实数据xr~pr(⋅),判别器D 通过xf与xr共同作为训练集进行训练,将所有的生成样本标记为假,将所有的真实样本标记为真。判别器D 通过最小化预测值与标签的误差值进行参数优化,输出判断该样本为真实样本的概率P。
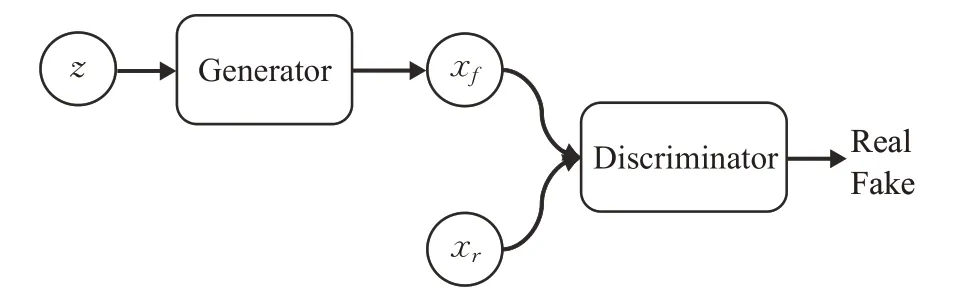
图2 判别网络结构图Fig.2 Discriminant network structure diagram
1.3 价值函数
在生成式对抗网络中生成器和判别器是紧密关联的,两者符合零和博弈理论。假设甲乙双方进行博弈,甲乙的收益和损失之和为零,也就意味着双方不可能都获得收益,必定有一方有收益,一方有亏损。一方若想取得最大收益则需要最小化对方的最大收益,从而引出了价值函数value function(简称V),其计算方法见公式(1):



生成器与判别器是一种对抗的关系,价值函数代表了判别器的判别性能。判别器的目标是最大化价值函数,而生成器的目的是针对特定的判别器最小化价值函数。
1.4 GAN应用于股票预测
生成式对抗网络基于零和博弈原理,可以把生成器比作假钞制作器,判别器作为验钞机去鉴别一张纸币是真币还是假币。假钞制作器制作出的假钞不断地被送到验钞机中鉴别,在这个过程中假钞制作器和验钞机不断地对抗博弈,两者的能力也都在不断提升,直到验钞机分辨不出制作出的是假钞还是真钞。
基于上述特性,生成式对抗网络GAN 在图形图像领域应用广泛。随着对GAN 网络的进一步研究,文献[16]发现在时间序列预测问题上GAN 同样能发挥出优势,在2019年提出了(forecasting of sensory data with generative adversarial network,ForGAN)网络。这是首次将时间序列预测问题与GAN 网络结合起来,通过交通流数据集验证了GAN的可行性,打开了利用GAN处理时间序列预测问题的大门。
股票市场的技术分析理论具有三大假设,其中重要的一条就是股票的历史走势会重演。这就表示股票的走势并不是完全随机的,过去的走势有一定概率会重新出现。在预测任务中股票走势的历史数据分布就显得尤为重要了,而深度学习模型就是要学习历史走势的分布。GAN模型可以通过生成器与判别器不断地对抗学习股票历史走势的数据分布,生成和历史分布相似的预测数据,提高预测的精度。
2 SAR-GAN模型股票价格预测
2.1 生成器组成
2.1.1 LSTM神经网络
循环神经网络(recurrent neural network,RNN)善于处理序列数据。因其具有共享参数以及记忆性的特点,在文本处理、语音识别、时间序列预测等领域被广泛应用。RNN的结构如图3所示。

图3 循环神经网络结构图Fig.3 Structure diagram of recurrent neural network
在图3中,U、V、W代表权重矩阵,t代表不同时刻,xt-1、xt、xt+1分别为在t-1、t、t+1 时刻的RNN的输入向量,st-1、st、st+1为各个隐藏层的隐藏状态,ot-1、ot、ot+1为RNN的输出向量。RNN适用于处理序列问题的原因在于:RNN 的当前隐藏层状态st不仅与当前时刻的输入向量xt相关,还与前一时刻的隐藏层状态st-1有关。隐藏层状态st和RNN的输出ot可以具体地表示为公式(4)和(5):

这表明RNN是一种可以记忆之前状态的神经网络。虽然RNN 可以记忆之前的状态,但是会存在长距离依赖问题。
LSTM是一种改进的循环神经网络,在RNN的基础上增加了一个状态向量以及3个门控单元,分别为输入门(input gate)、遗忘门(forget gate)和输出门(output gate)。LSTM 网络神经元的结构如图4 所示,c为LSTM内部状态向量,h是LSTM神经元的输出向量,x为LSTM 神经元的输入向量。σ为激活函数,在LSTM神经元中一般为Sigmoid 函数,将Sigmoid 函数的输出控制在0到1之间,可以达到控制输出流量的目的。
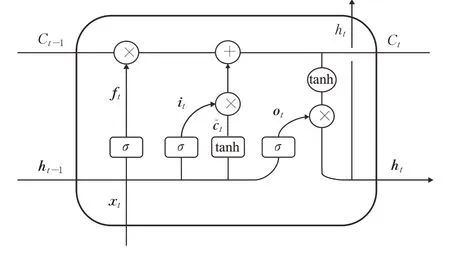
图4 LSTM神经元结构图Fig.4 LSTM neuron structure diagram
ft表示遗忘门,用来控制当前神经元需要遗忘的信息,具体表达式为公式(6),其中Wf为矩阵向量,bf为偏移量。it表示输入门,c͂t表示新的候选向量。tanh为激活函数,使得c͂t的输出为标准范围[−1,1]。当前时刻的内部状态向量ct是由遗忘的前一状态的信息和当前状态的部分信息组合而成的。ot表示输出门,由于LSTM神经元的输出需要进行选择而不是全部输出,所以ht不能直接输出。it、c͂t、ct、ot、ht具体表达式见公式(7)至公式(11):
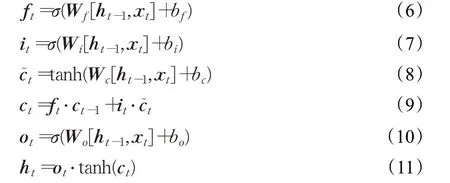
正是由于3 个门控单元以及两个状态量的神经元结构特点,LSTM 相较于RNN 可以记忆长时间的信息,避免了由此引起的梯度消失或者梯度爆炸的问题。在本文提出的SAR-GAN 中,生成器以LSTM 为主体网络层正是参考了LSTM具有长期记忆的特点。
2.1.2 一维卷积神经网络
一维卷积神经网络与二维卷积神经网络不同。一维卷积只在一个维度上进行卷积操作,所以适用于序列模型,例如时间序列预测、自然语言处理等。在股票预测中,一维卷积结构示意图见图5,每一行代表一个时间维度,每一列代表一个特征。通过一维卷积可以提取股票序列数据的特征。
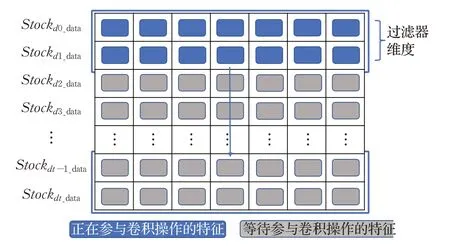
图5 一维卷积示意图Fig.5 One-dimensional convolution diagram
2.1.3 注意力机制
注意力机制(attention mechanism)源自于人脑的注意力机制。当人观察一个场景时,虽然整个场景可以进入人的视野,但是人脑会快速地将目光聚焦在重点关注的区域。这就相当于将场景中每一个区域赋予一个注意力权重,其中重点关注的区域注意力权重较高,人可以快速忽略不重要的信息,将关注点聚焦在重要区域。
注意力机制学习输入序列中的每一个输入元素对目标元素的重要程度,根据重要程度的不同对不同的特征赋予不同的权重。若在神经网络之前使用,可以对输入特征空间的重要性进一步理解;若在神经网络之后使用,可以使模型的最终决策更加聚焦在对最终目标有正向帮助的特征维度上。
自注意力机制(self-attention)是在注意力机制的原理上的进一步优化,本质还是加权求和的思想,见公式(12):
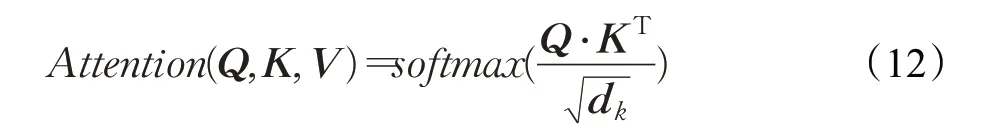
其中,Q、K、V分别为输入张量与3 个权重共享矩阵WQ、WK、WV进行相乘操作得到的向量合并之后的矩阵。Q为查询矩阵,K为键矩阵,V为值矩阵。KT为K矩阵的转置矩阵,dk矩阵的作用是调整内积维度。自注意力机制在加权求和的思想上对权重进行自我学习。通过Q⋅KT的运算得到权重分数(attention score),反映了向量之间的相关性,相当于一个“打分”的过程。Softmax 激活函数将这些权重分数进行归一化,并且使这些权重分数之和为1。通过Softmax之后可以得到哪些时刻哪些位置关注度较大,将经过Softmax 函数的值与V矩阵进行矩阵按位相乘,得到注意力矩阵。这样增强了相关性强的位置特征,削弱了相关性弱的位置特征,使得模型能更好地关注重要信息。
近年来,在图像处理、自然语言处理等领域,结合注意力机制的模型被广泛应用。文献[17]首次在机器翻译的任务中采用注意力机制并取得了不错的效果。文献[18]在CVPR2017中提出了一种循环注意力卷积神经网络(RA-CNN),通过注意力机制对图像的局部进行关注,在鸟类识别的样本上取得了良好的效果。
2.1.4 残差网络
残差网络(resnet)通过在卷积层之间的跳跃连接避免了深度模型梯度消失的问题。如图6所示,输入x通过两个卷积层得到F(x),并将F(x)与输入的x进行相加运算得到H(x)。这里F(x)与x的形状完全一致,若不一致则需要通过函数identity将x的形状变换成F(x)的形状。函数identity 以1×1 的卷积运算为主,主要用于调整输入的形状。由于神经网络需要学习F(x)=H(x)-x,所以被称为残差网络。
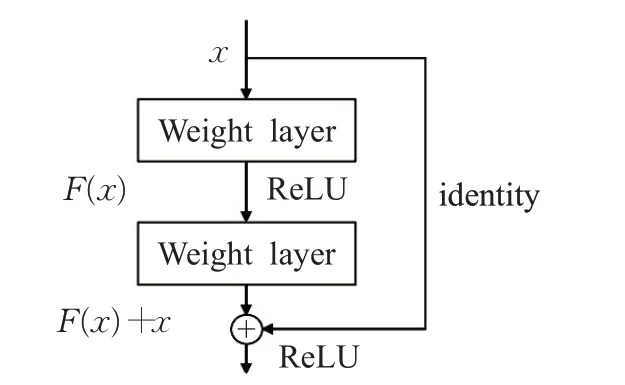
图6 残差网络结构Fig.6 Resnet structure
2.1.5 L2正则项
L2正则化又称为ridge regression,主要用于避免过拟合。L1 正则化是各个参数的绝对值之和,L2 正则化与之不同,表示的是各个参数平方值的和的开方。L2正则化是使每个参数都变小接近于0 但不为0,最终避免过拟合问题。
2.1.6 生成模型结构
生成模型的结构较为复杂,由多种神经网络层交替组成。生成器结构如图7所示。
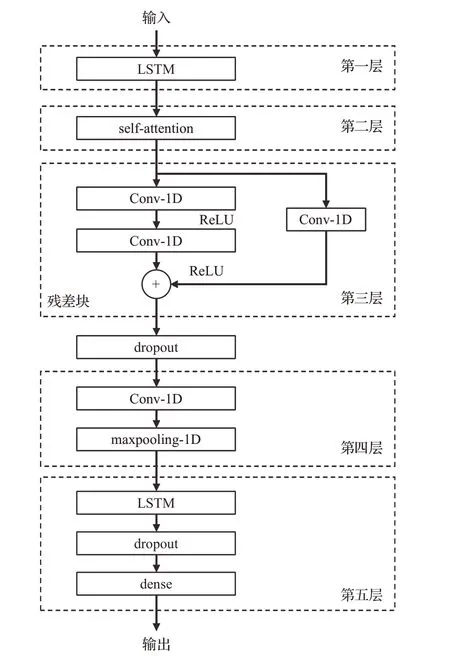
图7 生成器结构图Fig.7 Generator structure diagram
由于神经网络的输入必须为三维数据,所以首先将二维股票数据进行数据预处理,通过设置时间窗口的方法设置时间步长,将股票数据扩展为三维数据张量,即数量(samples)、时间步长(timesteps)、特征维度(features),以适合神经网络的输入。
第一层为LSTM 层:将输入的三位股票数据输入LSTM神经网络层。股票价格预测属于时间序列预测,并且训练集为多年的股票数据。针对这种长时间跨度的序列,使用LSTM网络既可以处理长期的股票历史信息又可以避免梯度爆炸的情况。
第二层为自注意力self-attention 层:将从LSTM 提取到的时序特征信息即不同时间维度股票特征信息张量,输入到自注意力网络。self-attention 计算出两个不同日期之间股票特征的相关度,并且计算出向量之间的注意力得分(attention score),通过softmax 函数得出学习到的权重,最终形成注意力矩阵。
第三层为残差网络层:残差网络层在设计上采用了两个一维卷积和跳跃连接模块,用以解决深度网络训练过程中梯度消失的问题。
在第三层和第四层之间添加一个dropout 层,参数值为0.1,以防止训练过程中出现的过拟合问题。
第四层包含一个一维卷积网络和一个一维最大值池化,目的是在保留最强的特征和抛弃较弱的特征,减少模型参数,减少过拟合问题的出现。
第五层包含一个LSTM 网络层、一个dropout 层和一个全连接网络层。数据张量通过全连接网络得到最终的输出。
2.2 判别器组成
如图8 所示,判别器由两个全连接网络以及一个LeakyReLU激活函数组成,用以鉴别生成的股票数据是否能欺骗过判别器。
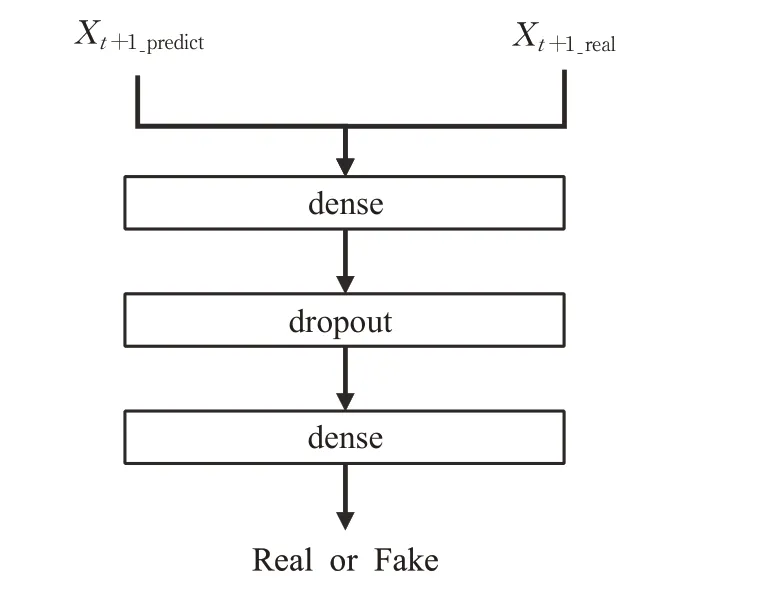
图8 判别器结构图Fig.8 Discriminator structure diagram
在图8中,Xt+1_prediction为生成器生成的第t+1 天的股票价格,Xt+1_real为从数据集中采样出的真实的第t+1 天的股票数据。GAN就是将第t+1 天的预测股票收盘价Xt+1_prediction不断逼近第t+1 天的真实股票收盘价Xt+1_real。通过对抗学习使得生成器的生成能力和判别器的鉴别能力不断提升,最终判别器将无法区分预测收盘价格和真实收盘价格,将生成收盘价格误认为是真实价格。
2.3 SAR-GAN优势及特点
与其他时间序列模型RNN、LSTM相比,SAR-GAN的生成器和判别器构建更加灵活多样。在生成器中加入LSTM层能够提取股票数据的时间序列方面的特征,1DCNN 层又能够提取股票数据的局部空间特征,将LSTM和1DCNN结合可以提取得到股价数据的时空特征;在借助残差网络避免梯度消失的基础上,通过注意力机制选取对股价预测具有正向帮助的特征维度,从而提升股价走势预测效果。
2.4 SAR-GAN结构及训练
本文提出的SAR-GAN 模型由生成器和判别器两个部分组成。生成器主要由以由LSTM层、self-attention层、残差层以及一维卷积层组成;判别器由全连接层组成。SAR-GAN网络模型具体结构示意图如图9所示。

图9 SAR-GAN网络结构Fig.9 SAR-GAN network architecture
在图9 中,首先将股票数据进行数据预处理,得到三维股票数据张量作为生成器的输入。数据经过生成器得到预测的股票收盘价格,并与当日的真实股票数据一起作为输入送入判别器中进行判断。
使用SAR-GAN 网络模型训练时,第一步固定生成器G,对判别器D 进行训练,使得判别器D 获得鉴别真实数据和虚假数据的能力;第二步固定判别器D,训练生成器G,以便生成器G 产生的数据不断逼近真实数据。以上两个步骤多次循环执行,直至生成器生成的预测数据可以欺骗判别器。
3 实验分析
3.1 数据来源及分析
3.1.1 数据来源
为了保证数据来源的准确性,实验数据全部来源于Yahoo财经。为了验证模型的普适性,分别对股票指数和多个股票价格进行预测。股指数据选择上海证券交易所综合指数(SSEC),数据时间范围从2009年1月1日至2020 年12 月31 日。股票数据选取多个票市场中热点行业的龙头股票,数据时间范围从2009年1月1日至2020年12月31日。
3.1.2 利用特征工程选取重要参数
在构建股票数据集的时候,如果仅仅将每天的开盘价(open)、最高价(high)、最低价(low)、收盘价(close)、交易量(volume)这些行情指标作为特征去进行深度学习训练过于表面化,反映不出股票价格波动的实质。股票价格预测应该建立在对市场行为深刻认识的基础上。
在构建股票数据集的时候,将行情数据与技术指标相结合,并通过特征工程的特征重要性以及Pearson、Spearman相关性分析。最终得到由18个特征构成的数据集,分别为开盘价(open)、最高价(high)、最低价(low)、相对强弱指标(RSI)、随机指标K、随机指标D、随机指标J、指数移动平均值(EMA)、三重指数移动平均线(TEMA)、双移动平均线(DEMA)、考夫曼自适应移动平均线(KAMA)、5 日均线(MA5)、10 日均线(MA10)、加权移动平均线(WMA)、中间价格(MIDPRICE)、资金流量指标(MFI)、布林线(M_line)、收盘价(close)。
3.2 数据预处理
在股票数据中,开盘价、最高价、最低价、成交量等价格与技术指标具有不同的量纲和量纲单位。这样未经处理的数据输入到神经网络会对预测造成重要干扰。为了消除量纲不同造成的影响,本文采用Sklearn库中的MinMaxScaler 函数进行数据归一化处理,使得价格因子与交易量因子指标处于同一个数量级。数据归一化公式见公式(13):

其中,x为原始数据,xstd为调整后的数据,xmin为原始数据中的最小值,xmax为原始数据中的最大值。
由于股票数据是结构化数据,属于2D 数据,不适用于神经网络的训练,所以需要增加维度使得股票数据上升为3D数据。本次实验采用滑动窗口的方法来实现股票数据升维,即第一维表示样本数(samples),第二维表示时间步长(time_steps),第三维表示股票的特征(features)如开盘价、收盘价等。
经过预处理后数据按照时间顺序分成训练集和测试集,其中前75%的数据作为训练集用来训练模型,后25%的数据作为测试集对模型预测效果进行评估。总共2 826个交易日,其中75%的训练集为2 120个交易日数据,25%的测试集为706个交易日数据。
3.3 评价指标
为了评估模型的预测性能,采用均方根误差(RMSE)、平均绝对误差(MAE)、均方根百分比误差(RMSPE)和平均绝对百分比误差(MAPE)4 种回归评价指标来量化模型的性能,4种指标的计算公式见公式(14)~(17):
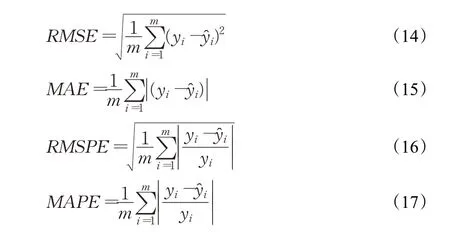
其中,m为样本数,yi为真实值,ŷi为预测值,yˉ为真实值的平均值。RMSE、MAE越小说明预测值越接近真实值,RMSPE和MAPE消除了股票绝对价格的影响,更能反映预测准确性,值越小说明预测越准确。
3.4 实验环境及参数设置
实验机器的操作系统为Windows10,CPU 为AMD R7 5800H,显卡为RTX3070-8 GB,代码采用Python 语言编写,主要使用的框架为Tensorflow2.0 集成的Keras框架。
本次实验采用单步预测,将股票数据(t−1)时间序列的价格用于预测当前时间(t)的股票价格,这是一个持续滚动的过程。
在模型参数设置方面,通过进行多次实验最终确定以下参数:LSTM 单元数设置为64,一维卷积核长度为4,自注意力头数为4,L2正则化参数为0.017,batch_size设置为64,timesteps 设置为1;生成器、判别器的优化器均采用Adam 优化器,损失函数设置为平均绝对误差MAE,学习率(learn_rate)为0.000 1,dropout 参数设置为0.1。
3.5 实验结果
3.5.1 上证指数预测实验
上证指数是上证综合指数的简称,是以上证所挂牌上市的全部股票为计算范围,以发行量为权数的加权综合股价指数。本实验采用SAGAN模型对上证指数收盘价进行预测,并将实验结果与LSTM、GRU、CNN-LSTM、CNN-GRU、Basic GAN等模型进行对比(Basic GAN是指生成器由LSTM 网络构成,生成器以CNN 网络构成的基础GAN网络)。为了消除实验的偶然性,进行多次实验求其平均值。具体实验结果如表1所示。
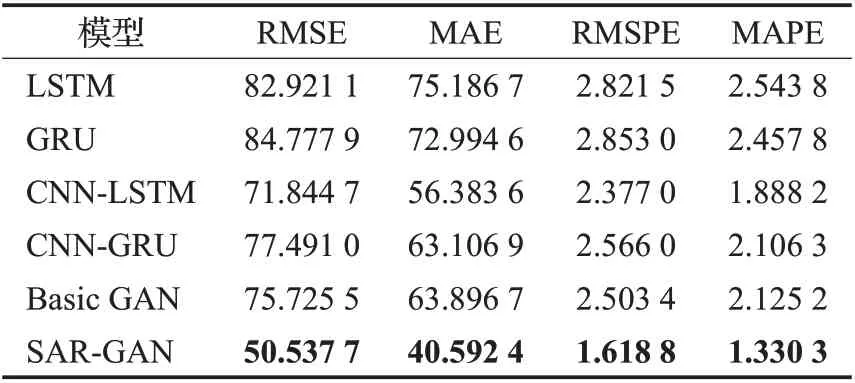
表1 不同模型在SSEC测试集的预测性能Table 1 Prediction performance of different models in SSEC test set
由表1 可知,SAR-GAN 模型在股票收盘价格预测上体现出独特优势。Basic GAN 相较于LSTM、GRU、CNN-LSTM、CNN-GRU网络,在预测准确度上有明显的优势。本文提出的SAR-GAN与Basic GAN相比,RMSE、MAE、RMSPE、MAPE 这4 个评价指标更小。实验结果表明:在股票指数收盘价格预测中,SAR-GAN模型的预测效果更好,更接近真实值,预测误差更小。
如图10为SSEC数据集收盘价格预测结果,其中的图(a)、(b)、(c)、(d)、(e)、(f)分别是使用LSTM、GRU、CNN-LSTM、CNN-GRU、Basic GAN 以及SAR-GAN模型的股票收盘价格预测走势结果图。如图11 是同一次实验选取局部30天几种模型预测的收盘价格走势的比较,能够更加直观地显示出SAR-GAN模型的预测效果优于LSTM、GRU、CNN-LSTM、CNN-GRU 模型,以及同样为生成式对抗网络的Basic GAN模型。
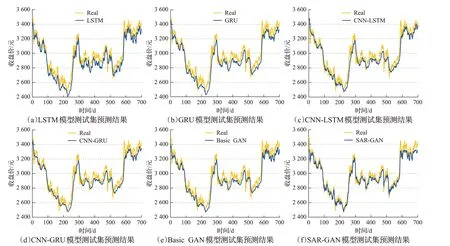
图10 6种模型对SSEC测试集预测结果Fig.10 Six models predict results for SSEC test set
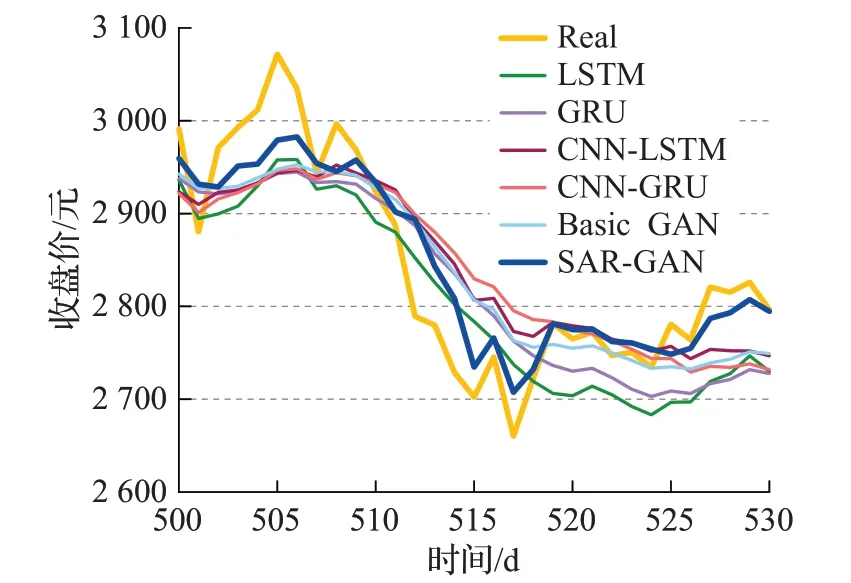
图11 SSEC测试集局部30天收盘价预测对比图Fig.11 Comparison diagram of SSEC test set partial 30-day closing price forecast
3.5.2 个股预测实验
实验选取了现阶段热点行业(消费、科技、医疗)中的龙头股票,包括美股中的苹果(AAPL)、亚马逊(AMZN)、深圳证券交易所中小板的紫光国微(002049)、港股中的腾讯(0700.HK)、上海证券交易所的贵州茅台(600519)、中国平安(601318)等股票,数据时间范围从2009年1月1日至2020年12月31日。虽然不同市场的实际交易日会有所不同,但是都将前75%为训练集,后25%为测试集。表2中展示了使用LSTM、GRU、CNN-LSTM、CNNGRU、Basic GAN 模型以及SAR-GAN 模型对这6 只不同市场股票的收盘价预测结果。
表2 中加黑的数据表示在此数据集下最优的测试结果,加下划线的数据表示第二优秀的测试结果。从表中可以看出:在金融时间序列股票预测方面,SAR-GAN模型在6 个不同市场不同热点行业的股票收盘价预测中均有优秀的表现。经过多次实验,在6只股票测试集上SAR-GAN 模型测试效果除了在贵州茅台数据集上的RMSE 指标略低于CNN-GRU 模型,在其他5 只股票上均优于LSTM、GRU、CNN-GRU、CNN-LSTM、Basic GAN模型,实验结果反映出SAR-GAN模型可以适用于多个市场的股票价格预测。
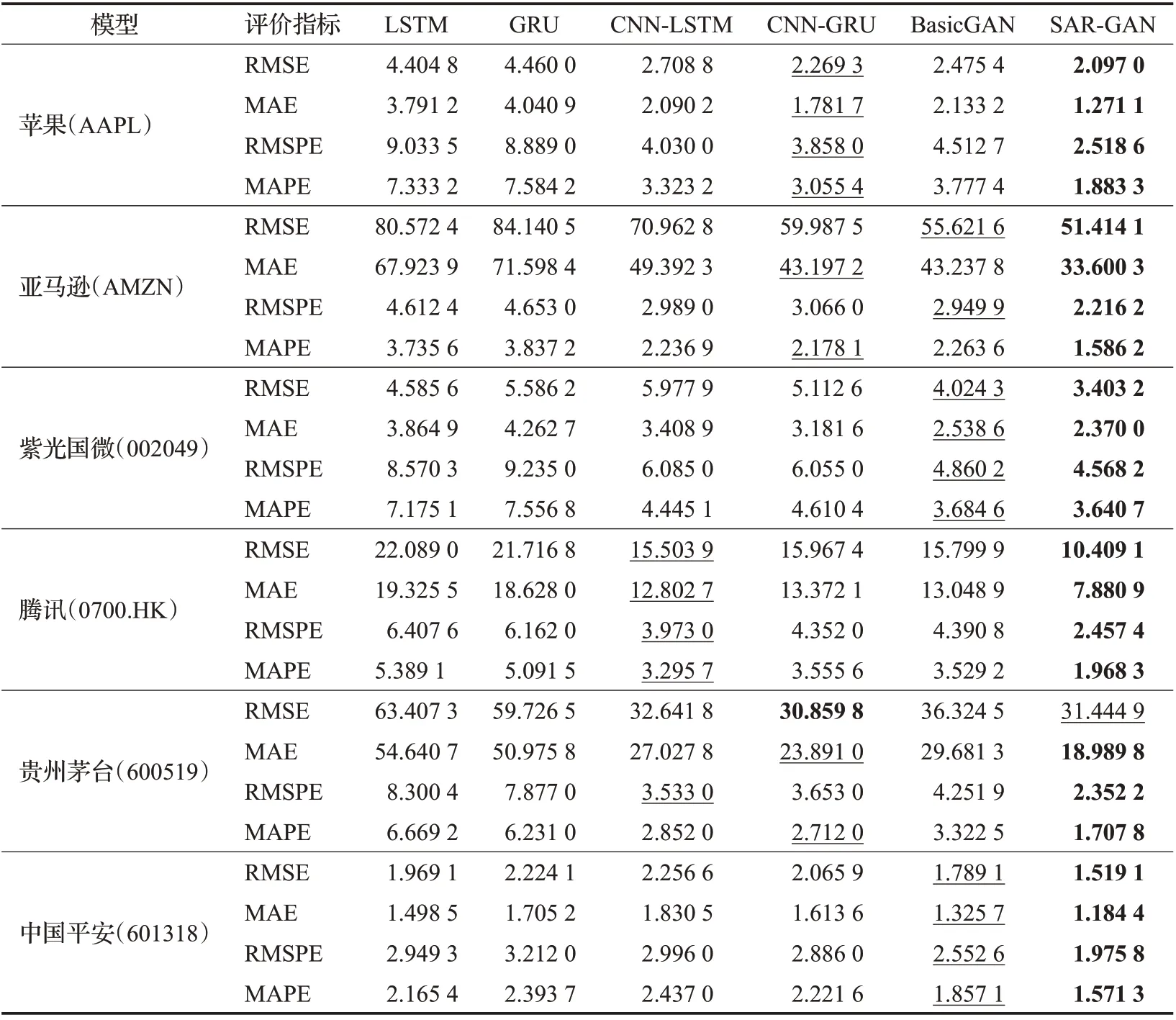
表2 不同模型在6只股票测试集的预测性能Table 2 Predictive performance of different models in six stock test sets
如图12 展示了这6 只股票测试集上测试效果最好的两个模型局部50 天预测结果对比展示,若效果仅次于最好模型的模型多于一个,则一起对比展示。

图12 个股测试集局部预测对比Fig.12 Comparison of stock test sets local forecast
4 总结
本文提出的SAR-GAN 模型,以生成式对抗网络为基础,结合自注意力机制、残差网络、一维卷积等网络层对股票价格进行预测。通过实验可以看出,无论是在股指预测还是在个股预测上,SAR-GAN 模型的预测效果均好于其他基础模型。
下一步可以在多个方面继续进行研究:在数据特征选取方面,可以继续深入研究与股票价格变化相关的金融数据指标;在时间步长方面,可以选取不同的时间步长,研究时间步长对实验的影响;可以在预测模型中加入关于财经新闻、股评分析等相关情感分析数据,进一步提升模型的预测性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
甘肃教育(2020年22期)2020-04-13
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
股市动态分析(2016年23期)2016-12-27
股市动态分析(2016年22期)2016-12-27
第二课堂(课外活动版)(2016年2期)2016-10-21
股市动态分析(2016年7期)2016-09-29
