
特殊天气条件下的目标检测方法综述
2022-07-13 01:57杨亚伟
计算机工程与应用 2022年13期
林 猛,周 刚,杨亚伟,石 军
新疆大学 信息科学与工程学院 信号检测与处理重点实验室,乌鲁木齐 830046
目标检测是一项重要的计算机视觉任务,主要任务是正确检测图像中目标对象的存在并准确定位。作为计算机视觉中最具挑战的问题之一,目标检测能够为图像的语义理解提供有价值的信息,并且与许多应用相关,一直受到极大的关注。目标检测涵盖不同的应用目标,例如行人检测[1]、人脸检测[2]、文本检测[3]等。目标检测的目的是开发高效的计算模型和技术,同时它也是许多其他高级计算机视觉任务的基础,比如实例分割[4]、语义分割[5]、目标跟踪[6]等。
早期,基于手工特征构建的目标检测方法在21 世纪初陷入瓶颈。随着2012 年AlexNet[7]的诞生,基于深度学习的目标检测时代便由此揭开序幕。以卷积神经网络为代表的深度学习方法能够学习更高级、更深层次的特征。在深度学习时代,目标检测方法可以分为两种:两阶段目标检测方法和单阶段目标检测方法。前者先由算法生成一系列的锚框,再通过卷积神经网络进行分类和定位,这类方法以R-CNN系列[8]和FPN[9]为代表。而后者则直接通过主干网络回归物体的类别概率和位置坐标,其中以YOLO 系列[10]、SSD 系列[11]和Retina-Net[12]是为典型。
随着基于深度学习的目标检测方法的发展,有很多学者对此进行了总结和分析。Zou等人[13]对目标检测近二十年的技术发展进行了详细的概括。Agarwal 等人[14]、Zhao等人[15]、Liu等人[16]对基于深度学习的通用目标检测框架进行了综述。但这些综述均未研究目标检测框架在特殊天气条件下的有效性。特殊天气是相对一般晴朗天气的,造成视程障碍现象:包括雾霾、沙尘、降雨和降雪等天气情况。特殊天气会造成图像模糊、特征无法辨识等问题,会让常规的目标检测方法的检测性能大幅下降,甚至失效。陈飞等人[17]对复杂环境下的交通标志检测与识别方法进行了综述。董天天等人[18]对复杂天气条件下的交通场景多目标识别方法进行了综述。然而目前针对特殊天气条件下的一般目标检测方法综述相当缺乏,这也是本文撰写的必要之处。本文将对特殊天气条件下的目标检测方法进行详细的阐述和总结,主要内容结构如图1所示,将特殊天气条件下的目标检测相关文献分成三个部分进行分析:(1)数据集的构建,针对特殊天气下目标检测任务数据集的来源和制作方法进行总结归纳,按数据集的属性分成真实数据集与合成数据集两大类,并对合成数据集部分以合成方式展开为物理驱动和数据驱动。(2)基于图像恢复的目标检测,将这一大类方法分为恢复与检测相独立和恢复与检测相统一两部分,分析图像恢复方法相关文献并说明其与目标检测任务之间的联系。(3)基于迁移学习的目标检测,以特征对齐机制的研究和多步域自适应两部分展开,总结迁移学习在特殊天气下目标检测的应用,尤其是分析领域自适应方法在该问题上近些年的研究发展。最后对全文进行了总结,指出目前存在的问题并展望未来研究方向。
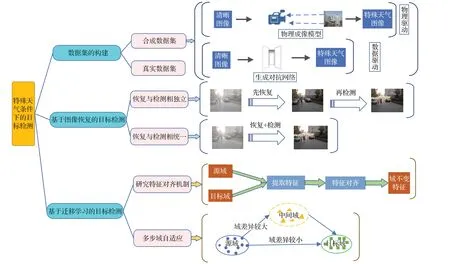
图1 本文主要内容结构Fig.1 Main content structure of this paper
1 数据集的构建
目前在特殊天气条件下的目标检测研究面临的主要难题之一是缺少面向特殊天气的目标检测数据集,这使得难以通过深度学习的方法来训练模型。一般情况下很难构造出相同位置、相同光照条件下的同一个场景的清晰图像和对应的特殊天气图像。同时在真实特殊天气图像中进行目标检测标注,也将会耗费很大的人工成本。表1 总结了目前研究中常见的公开数据集[19-30]。这些特殊天气数据集主要以雾天和雨天为主,雪天和沙尘的数据集较为缺乏。同时在这些数据集当中,具有目标标注信息的较少,这对特殊天气条件下的目标检测研究造成了很大的限制。针对数据集的构建问题,目前的研究主要采用两种方法:真实数据标注和合成数据生成。真实数据标注是通过辅助算法和人工方式,对采集到的真实图像进行标注。这类方法生成的数据集的清晰图像和对应特殊天气下的图像均由人工方式在现实环境中获取而来。Liu等人[19]通过固定摄像机在场景中的位置历经一年的时间进行拍摄,再由人工选取清晰图像和对应的4种不同浓度的雾天图像,形成真实图像数据集。Zhao 等人[20]对23 个城市进行图像采集,并采用图像配准和数据清洗获取同一场景的无雾霾图像和有雾霾图像,最后人工标注图像中的视觉目标和雾霾等级。尽管作者使用了图像配准和数据清洗等方法来使得带雾霾的图像和不带雾霾的图像之间尽可能的配对,但是相机视角的细微调整、场景环境的变化、光照条件的不可控等因素都会导致其难以达到严格意义上的图像配对。即便如此,它的存在对于本文的研究问题仍具有十分重要的参考价值。Wang等人[31]通过拍摄雨天的视频获取多幅同一场景的雨天图像,并利用算法标注出每幅图像的雨滴位置,最后用多幅图像来估计出无雨的背景图像。这类方法虽然能够获取较为真实的图像数据,但是无法利用已有的数据集,而且需要大量的数据采集和人工标注成本。由于能见度较差,难以提供精确的人工标注,使得在特殊天气下人工标注成本提高更为明显。因此很多研究者致力于特殊天气的合成算法研究,在已有标注信息的数据集上合成特殊天气效果。针对特殊天气的合成方法,大致可以分为两类:基于物理模型驱动的方法和基于数据驱动的方法。
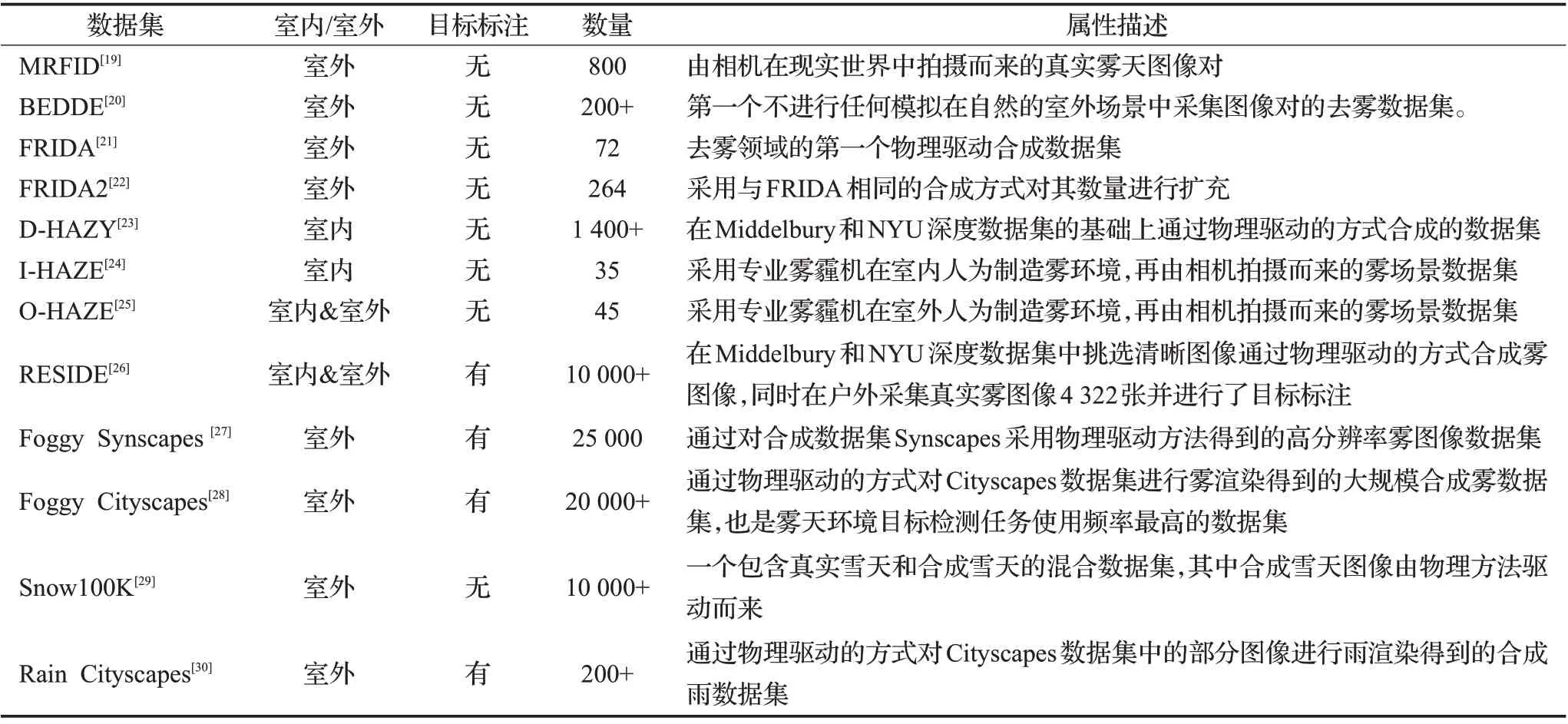
表1 常见的特殊天气数据集Table 1 Common adverse weather datasets
基于物理模型驱动的方法,利用特殊天气的成像特点,进行特殊天气的合成。文献[32]提出的光学散射模型已被广泛用于合成雾图像,也是雨合成的重要理论参考。该模型的经典描述如下:
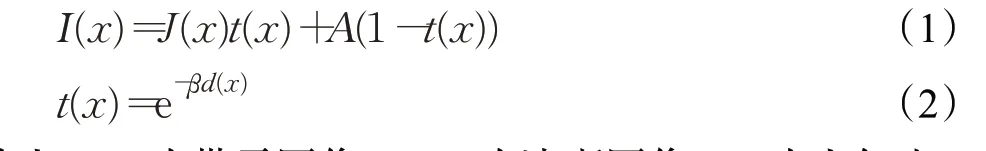
其中I(x)为带雾图像,J(x)为清晰图像,A为大气光,t(x)为透射率。衰减系数β控制着雾的密度,β值越大,雾越密。d(x)为物体与相机之间的距离。通常在已有清晰图像基础上,估计出深度信息从而利用公式(2)计算出透射率,然后利用公式(1),调整不同的大气光和衰减系数,获得不同效果雾霾。雨雪等情况,则需要制作出雨线或雪花的蒙版,添加到清晰图像上。
Tarel等人[21]用SiVICTM软件构建了一个真实的复杂的城市模型来生成图像,同时可得到清晰图像的深度图,利用光学散射模型[32]为图像添加雾效果,通过设置不同的β和A合成了4种不同类型的雾天图像,从而得到去雾领域的第一个小型合成数据集。该数据集用于评估自动驾驶系统在各种雾天环境中的性能,后续又用类似的方法得到了扩充版本的合成数据集[22]。但该数据集的样本图像分辨率很低,真实感较差,同时数据集规模较小,难以进行深度学习模型的训练。Ancuti 等人[23]通过传感器设备采集图像的深度信息,然后利用文献[32]提出的光学散射模型在不同的深度下改变透射率来实现雾效果。此外,还通过专业雾霾机生成雾霾的方式为清晰场景制造雾霾效果,再通过相机拍摄的方式分别制作了室内图像[24]和室外图像[25]的两个用于评估去雾算法的数据集。Li 等人[26]同样基于物理模型驱动的方法,通过卷积神经网络的方法来估计真实图像的深度,将式(1)和(2)中的大气光系数A和衰减系数β赋予不同的数值来合成带雾图像,并对4 322 幅真实带雾图像进行了标注。Cityscapes[33]能够充分反映真实晴天下的复杂城市交通场景,但缺乏相应的特殊天气场景。在文献[28]中,对计算得来的原始深度图进行去噪和补全后使用光学散射模型进行雾合成并将其添加到Cityscapes 数据集的图像中,从而建立了名为“Foggy Cityscapes”的数据集。其中有550张精炼的高质量合成雾图像带有精细语义标注,可以直接利用其进行目标检测的监督训练,并通过半监督学习方法将这550张图像扩充为20 000 张没有精细标注的合成雾图像。但是该合成数据集受到原有数据集标注信息的限制,同时还需要获取真实场景的完整深度信息,这本身就是一个非常具有挑战性的问题。后续使用与文献[28]中相同的基于物理模型的雾渲染方法,对合成数据集Synscapes[34]中的图像进行雾渲染,得到了名为“Foggy Synscapes”的纯合成数据集[27],并且证明混合使用纯合成数据和真实数据比单独使用它们的效果更好。Garg 等人[35]分析雨滴成像的物理模型,认为雨滴会造成图像亮度增加并具有运动模糊的现象,由此构建出适用于单幅图像和视频的雨线成像数据集。Hu等人[30]分析了不同场景深度下的雨的视觉效果,发现雨滴在近景位置呈现出雨线效果,而在远景位置呈现出雾效果,认为雨天图像由雨线和雾共同构成,由此构建了雨成像模型,生成了名为“Rain Cityscapes”的合成雨数据集。类似的还有Ren等人[36]利用纽约大学深度数据集[37]中的图像和对应的深度信息来计算透射率从而得到相应的带雾图像。Liu等人[29]认为雪天图像是由雪花前景和无雪图像组合而成,并通过PhotoShop 软件制作了5.8×103的基础蒙版来模拟飘落的雪的颗粒大小的变化。每个基底掩模由小、中、大颗粒之一组成。同时,每个基模中的雪粒子具有不同的密度、形状、运动轨迹和透明度,从而增加了变化,最终构造了10万张合成雪天图像。Tremblay等人[38]提出了雨强度可控的物理框架,并用这个框架对现有的数据集[39]进行了雨合成,得到了高度逼真的雨渲染结果。与Tremblay 等人[38]的工作较为接近的是Halder 等人[40]提出的基于物理粒子模拟器[41]、场景照明估计和雨光度建模实现晴天图像雨渲染。他们都利用合成数据集进行了特殊天气下的目标检测任务实验,证明扩充后的数据集可显著增加检测性能。
基于物理模型驱动的方法,可以非常方便的通过调整物理模型参数来合成各种各样的特殊天气效果,同时也不需要任何训练数据。但是他们通常把实际环境中复杂的成像原因抽象为简化的物理模型,从而容易造成合成图像与真实图像的偏差。基于数据驱动的方法,往往利用真实图像数据对图像进行“风格转换”,实现更为接近真实的效果。早期基于生成对抗网络的风格转换[42]由于需要成对的训练数据,导致实用性大大降低。Huang 等人[43]提出一种生成对抗网络用来合成图像数据,采用同一场景下白天的图像来生成夜晚的图像,将译码、生成和判定三个部分整合在统一的网络中。Zhai等人[44]提出将雨图像合成和对抗性攻击这两种研究结合起来,并根据成像模型模拟雨条纹来合成真实感较强的雨水图像,同时验证了这种方法对目标检测任务的有效性。Shao 等人[45]提出一种利用图像深度信息将原有物理模型合成雾霾的图像通过生成对抗网络转换成与真实雾霾图像具备相同概率分布的合成雾图像。Yasarla等人[46]提出一种基于高斯过程的半监督编码-解码网络,通过无标注真实数据对已有的物理模型合成的雨图像在特征层面进行生成,从而获得更好的去雨效果。基于数据驱动的方法可以合成与真实图像相近的概率分布的图像,且这类方法通常借助生成对抗网络来实现,能够比较方便地嵌入到其他的网络模型当中,同时可以缓解数据集的标注压力,但这种方式不能控制各种物理成像条件,比如雨量的大小、雾的浓度等等。
2 基于图像恢复的目标检测
为了解决特殊天气条件下对目标检测问题,一种思路是从图像恢复的角度出发,先对图像进行恢复,再用常规的方法进行目标检测。
目前针对特殊天气的图像恢复算法的研究,大多是通过成像模型来进行理论分析的。Li 等人[47]针对雾霾的光学散射模型进行了详细分析,并总结近二十年的去雾算法与光学散射模型的关系。文献[48-49]也对包括深度估计、小波、增强、滤波等在内的经典的去雾方法进行了详细的总结。Gui等人[50]对基于深度学习的去雾算法进行了全面的总结。Wang等人[51]对视频和单图像去雨算法进行了归纳总结,认为雨滴成像的物理特性是构建绝大多数去雨算法的基础。然而基于成像模型的图像恢复算法,需要计算的参数多,属于一种病态问题。针对这个难点,目前研究方法基本可以分为两大类:模型驱动方法和数据驱动方法。模型驱动方法需要对成像模型中的参数进行先验假设,然后对图像进行恢复。He等人[52]提出了一种暗通道先验,基于此先验知识,粗略估计透射率,再根据引导滤波[53]进行优化并估计大气光系数,最终获得去雾图像。Peng等人[54]提出一种基于改进的光学散射模型去沙尘算法,首先对环境光进行白光校正,其次用一种光学滤波器滤除非噪声的区域,最后利用最大值通道和最小值通道的差值作为先验信息来估计透射率。数据驱动方法是通过数据集训练的方式来估计合适的参数。Yang 等人[55]提出了一种基于先验学习的图像去雾深度网络,它结合了传统去雾方法和基于深度学习方法的优点。Yang 等人[56]对近十年来从模型驱动到数据驱动的去雨方法进行了全面的综述,并通过比较各类去雨方法的实验结果来表明数据驱动的方法通常比模型驱动的方法性能更好。
在对特殊天气图像恢复的基础上,进行后续的目标检测算法,可以实现系统性的应用。Li等人[57]提出基于光学散射模型的AOD-Net 用来去雾,并与目标检测网络结合形成端到端的训练,在合成浓雾条件下目标检测平均精确率提高了12%,同时这也是第一个端到端可训练的去雾目标检测模型。Huang等人[58]利用两个子网来共同学习可视性增强和目标检测,并通过共享特征提取层来减少图像退化的影响,最终提出了一个联合学习可见性增强、目标分类和目标定位的用于雾天目标检测的多任务网络(DSNet)。Li 等人[59]提出一种轻量级的去雾网络PDR-Net,并结合经典的目标检测网络Faster R-CNN[60],平均精确率提高了约2%。Zhang等人[61]提出了一种条件生成对抗网络(ID-CGAN)来进行去雨,与去雨前图像的目标检测相比,这种去雨方法能够使得目标检测的平均精确率提高30%。Fu 等人[62]将经典的高斯拉普拉斯金字塔技术与CNN相结合提出了一种轻量金字塔网络(LPNet)用来去雨,并利用LPNet+Faster R-CNN 的方式,实验证明了LPNet 对目标检测这种高级视觉任务的潜在价值。Fan 等人[63]提出了一种Res GuideNet的单幅图像去雨方法,并验证了这种图像恢复方法对后续目标检测任务的有效性。Jiang 等人[64]提出了一种多尺度渐进式融合网络(MSPFN)来利用雨条纹跨尺度的相关信息进行单幅图像去雨,MSPFN 生成的去雨图像的检测精度比原始雨图像的检测精度提高了近10%。图像去退化(去雨、去雾、去雪等)往往作为目标检测的预处理步骤,并用目标检测任务来评价去退化效果[65]。
将部分恢复结合检测方法的实验数据列于表2中。首先,图像恢复对于目标检测任务肯定是有益的,列于表二中的几种方法在图像恢复性能指标上均有不错的表现,它们在各自数据集上进行图像恢复过后,目标检测性能均有不同幅度的提升。尤其ID-CGAN[61]在基于PASCAL VOC 2007的合成的雨图像数据集上,先进行图像恢复再进行目标检测的平均精确度相比于直接进行目标检测的平均精确度提升高达78%。其中PDR-Net[59]、ID-CGAN[61]、MSPFN[64]先将图像进行恢复,再联合目标检测方法,即去退化网络与目标检测网络单独进行训练。但这种对退化图像进行预处理的方法通常涉及复杂的网络,需要在像素级监督下单独训练。这种方法在处理过程中能够获得图像恢复指标较高的图像,图像恢复的评价指标通常以PSNR与SSIM为主,但这两项指标的数值与图像的真实感程度并非是相关的,经过恢复的图像不一定是有利于目标检测任务的[26]。图像恢复过程中也会引入各种失真,从而导致域偏移[28],以至于难以获得较好的目标检测性能。同时,这种预处理也会占用更多的算力,对实际应用造成困难。同时从表2 可以看出在处理雾天条件的目标检测任务时,联调(JAOD-Faster R-CNN)的方法相比于单独训练的AOD-Net+F的方法在检测性能上有大幅提升。而经过微调的Retrained F与联调的JAOD-Faster R-CNN性能接近,这说明简单的级联结构并不优于合成数据集直接训练方法。最近的DSNet[58]证明了目标检测可以受益于与图像恢复之间的联合学习,并以未做任何改动RetinaNet、恢复+检测以及恢复联合目标检测的DSNet三类方法在合成雾天图像数据集(FOD)和真实雾天图像数据集(Foggy Driving)上分别进行了实验,可以发现表中所示的3 种恢复+检测的方法在Foggy Driving上的表现甚至不如未对雾天图像进行任何恢复处理的RetinaNet,相比于去雾前,mAP 下降了2~6 个百分点,也印证了经过恢复的图像不一定是有利于目标检测任务的观点,同时这种恢复+检测简单级联的方法在单幅图像的处理时间上大幅增加。DSNet 在与RetinaNet 时间成本相当的情况下,mAP提升了约6个百分点。由此可见将图像恢复与目标检测任务进行联合学习的优越性,也说明了DSNet 的轻量级与较高的准确率。此外,应当注意的是,上述三类方法在真实雾天图像数据集(Foggy Driving)上的mAP相比于合成雾天图像数据集都有所下降,原因是由于此训练集为合成数据,没有对真实图像进行利用,这种合成图像与真实图像在目标检测准确率上的所表现出的偏差,暴露了在合成数据集上训练的模型应用在现实环境中会出现性能下降的问题,同时构建大规模数据集的成本压力也成为了这类方法的一大瓶颈。
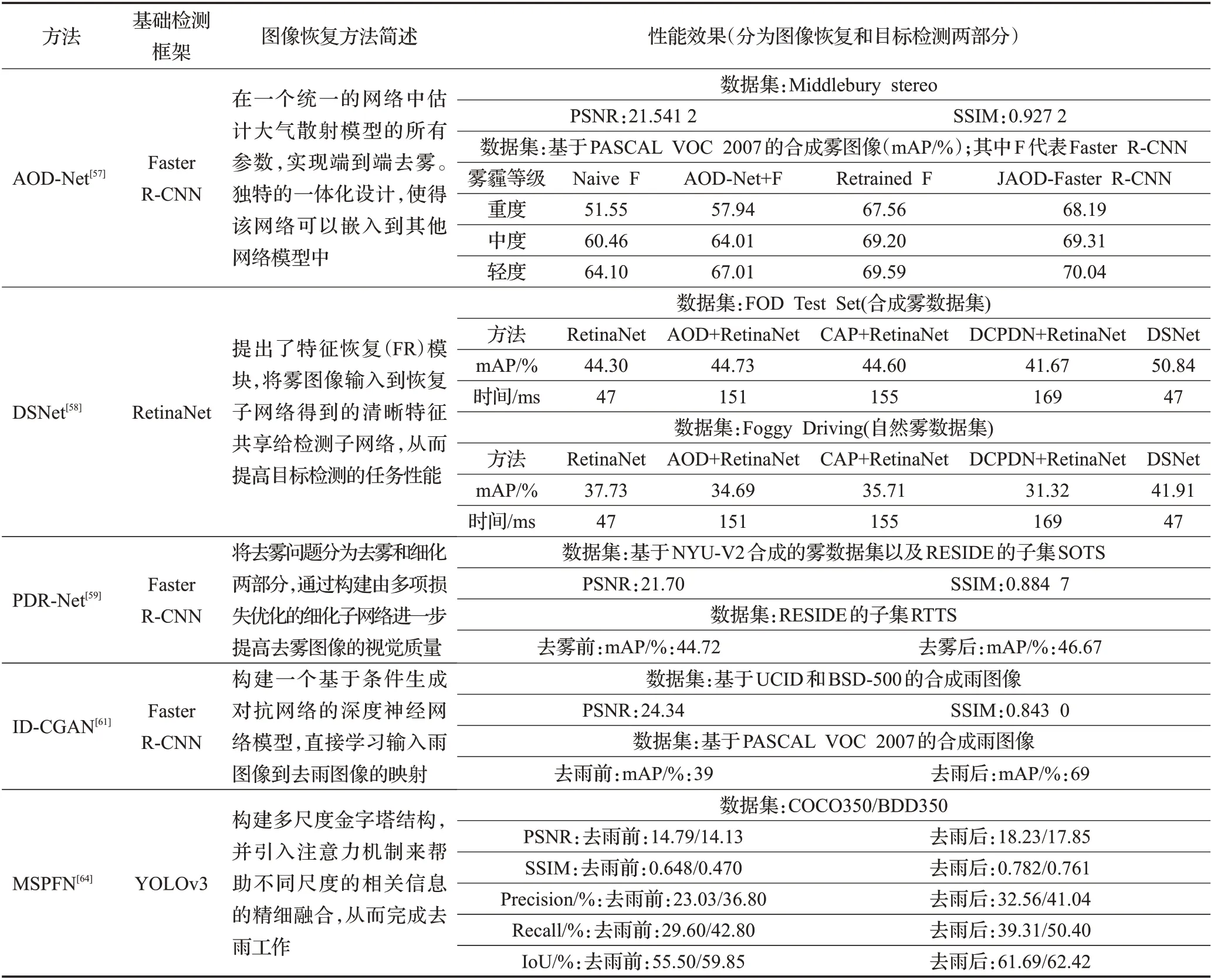
表2 基于图像恢复的目标检测方法的实验结果Table 2 Experimental results of image restoration and joint object detection
3 基于迁移学习的目标检测
在许多实际应用中,重新收集所需要的数据集需要较高人工成本甚至是不现实的。这种情况下,在任务域之间进行迁移学习是可取的。迁移学习[66-67]在分类、回归和聚类等任务中都已经取得了显著的成功。从目标检测出发,通过迁移学习的方式提高特征的适用性是目前特殊天气条件下目标检测任务的主流研究思路。
特殊天气下图像特征会发生域偏移(domain shift),这种偏移会导致目标检测性能的显著下降[68]。域偏移目标检测的常用方法主要有两个方向:(1)训练有监督的模型,然后对目标域进行微调;(2)无监督跨域表示学习。前者需要重新构建数据集,这一点已经在前文中进行了叙述,而后者目前主要流行的是领域自适应(domain adaptive,DA)[69-70]的方法,是一种模型适应新的领域而不需要重新训练的技术,近年来受到越来越多的关注。它通常被认为是解决缺乏特定领域的训练数据集的一种有效方法。但这类方法仍然存在一些挑战:第一是源/目标域的特征对齐机制还有待进一步研究;第二是源域和目标域数据的特征空间差异较大时难以迁移。源域的特征空间和目标域的特征空间存在一定的相关性,特征对齐机制就是研究某种特征变换以获得域不变特征。Chen 等人[71]基于H-divergence 理论从图像级和实例级两个方面来处理域偏移,并使用正则化损失以帮助网络更好地学习领域不变特征。这也是第一篇解决目标检测领域自适应问题的工作,获得了突破性的实验结果。该方法将晴天图像作为源域而将雾霾图像作为目标域,二者通过特征对齐模块实现了域迁移。此外,在一些场景中,如在大雾天气中驾驶,域偏移会随着物体尺度的变化而变化。雾通常使远处的物体比近处的物体更模糊。因此,在所有尺度上执行一致的特征对齐效果不佳,需要对不同尺度的目标在两个域之间分别进行对齐。于是Chen等人[72]又将尺度问题纳入考量,将FPN嵌入到目标检测网络当中,形成了SA-DA-Faster。He等人[73]提出了多重对抗Faster R-CNN(MAF)框架用于域偏移目标检测,该框架主要通过层次域的特征对齐模块和聚合候选特征对齐模块来实现领域自适应。Zhu等人[74]认为对局部区域的关注才是目标检测成功的关键,提出了由“区域挖掘”和“区域级对齐”两个关键组件组成的框架,但是在该方法中区域分类器的损失梯度仅传播到骨干网络中,而没有对RPN 进行自适应。Saito等人[75]提出一种基于强局部对准和弱全局对准的自适应检测模型用于目标检测,但它仅在骨干网络较低层和最后一层进行特征对齐。在文献[76]中,认为仅仅调整和适应主干网络的全局特征是远远不够的,进一步研究了RPN 模块的可移植性。Xie 等人[77]受[75]的启发,提出了一种多级领域自适应Faster R-CNN,使用不同的域分类器来监督多尺度的特征对齐,同时增加领域分类器的数量来提高模型的识别能力,优化了整体对抗训练。Pan等人[78]提出了一种具有鲁棒性的多尺度对抗学习方法用于跨域目标检测,该方法主要通过多重扩张卷积核减小图像级域差异,并剔除可转移性较低的图像和实例来减弱负迁移的影响。有些学者认为相关局部区域的上下文信息对提高模型的整体性能有很大的帮助。文献[79]在文献[75]的基础上提出了一种基于不同尺度的层次上下文向量并结合目标检测的信息,形成无监督领域自适应目标检测方法。该方法利用多重互补损失函数进行优化,并提出梯度分离训练以学习更有针对性的特征表示。Cai等人[80]从区域层面和图结构一致性的角度出发,利用mean teacher[81]在目标检测背景下通过一致性正则化来弥合领域差距,以Faster R-CNN为主干,通过将对象关系集成到一致性代价的度量中,对mean teacher 进行了全新的重构用于跨域目标检测。但是文献[80]并没有解决mean teacher 的内在模型偏差,Deng等人[82]提出了一种无偏mean teacher(UMT)方法,使用CycleGAN 转换的源类目标图像作为teacher 模型的输入,原始目标图像作为student模型的输入来减少模型偏差的影响,采用非分布估计策略选择最适合当前模型的样本。此外,由于所使用的特定领域自适应方法在很大程度上受到底层目标检测方法架构的影响。针对Faster R-CNN 目标检测及其变体的领域自适应已经进行了相当广泛的研究,但是Faster R-CNN 作为两阶段目标检测方法,存在推理时间过长的问题。因此,对于自动驾驶等对时间要求苛刻的实时应用来说,它可能不是最佳选择。于是Hnewa 等人[83]提出了多尺度域自适应YOLO(MS-DAYOLO)算法,该算法支持YOLOv4 骨干网在特征提取阶段的不同层次上进行领域自适应,使它们对不同尺度的领域迁移具有鲁棒性。Wang等人[84]从CNN 模型如何获得可转移性的视角出发,将权值的方向和梯度分为领域特定部分和领域不变部分,领域自适应的目标是在消除领域特定方向的干扰的同时集中于领域不变方向。针对目标检测设计的带噪声标签的学习方法很少。Khodabandeh等人[85]将目标检测问题简化为图像分类的方法,将整个学习过程分为三步:利用源域中的标记数据训练模型,并用该模型在目标域数据上生成带噪声的标签,使用分类模块对标签进行细化,最后利用源域数据与带噪声标签的目标域数据再训练模型,从而提高其鲁棒性。
以上方法采用领域自适应原则,侧重于对源域与目标域之间分布的特征进行对齐,而基于天气的图像恢复过程中可能获得的潜在信息往往被忽略。为了解决上述局限性,在文献[86]中,将特殊天气的先验知识纳入考量,提出了一个无监督的基于先验的域对抗目标检测框架,利用图像成像原理获取特殊天气的先验知识来定义一种新的先验对抗损失函数,从而减轻天气对检测性能的影响。Liu等人[87]提出了一种名为IA-YOLO图像自适应目标检测方法,设计了一个可微分图像处理模块(DIP),该模块的超参数由一个基于轻量CNN的参数预测器(CNN-PP)自适应学习。CNN-PP根据输入图像的亮度、颜色、色调和特定天气信息自适应预测DIP 的超参数。图像经过DIP模块处理后,可以抑制天气信息对图像的干扰,同时恢复潜在信息,最终得到了一种端到端学习DIP、CNN-PP 和YOLOv3 骨干检测网络的联合优化方案。将图像恢复与单步领域自适应相结合的方法为特殊天气条件下的目标检测提供了一种新的思路。
上述方法在源域和目标域直接相关时,可以较好地完成知识转移。但当两个域之间差异性较大时,难以单纯从特征层面进行迁移。近些年来,许多学者提出需要一个或多个中间域将差异较大的源域和目标域桥接起来,用于解决二者特征空间差异较大的问题。Kim 等人[88]从源域产生各种不同的移动域,并通过学习多领域不变表示来提高领域之间的特征不可区分性。Shan 等人[89]提出了一种基于像素和特征级的领域自适应目标检测方法。该方法首先采用基于CycleGAN 的像素级领域自适应,然后采用基于Faster R-CNN 的特征级领域自适应方法。这种多步领域自适应的方法在Foggy Cityscapes数据集上相比于单步的方法[71]的结果提高了约1 个百分点,同时还进行了雨天场景的目标检测,在数据集VKITTI-Rainy 上,平均精确度达到52.2%。Hsu等人[90]提出了一种渐进领域自适应目标检测方法。通过合成图像的方法将源图像转换成与目标图像相似的图像,构造了一个中间域。为了保证中间域与目标域的相似性,采用生成对抗网络的方法使得中间域生成的图像与目标域的图像概率分布接近。Chen 等人[91]利用CycleGAN实现加权插值后的图像级特征增强全局可分辨性,并通过上下文信息来增强局部识别能力。Soviany等人[92]首先将CycleGAN从源域转换到目标域的图像加入到训练集中。其次,采用课程自主学习的方法,利用带伪标签的真实目标图像进一步适应目标检测模型。当两个领域的差异性较大时,这类利用生成对抗网络对齐源域和目标域图像分布的多步领域自适应的方法往往比单步的方法更加有效。在无监督领域自适应的假设中,带标签的源域数据和不带标签的目标域数据都是可供使用的,并且通常将它们一起训练以减少域间的差异。无源数据领域自适应方法在分类任务中已经有了一些应用[93-94],受此启发,Li等人[95]首次提出了一个无源数据领域自适应目标检测(SFOD)框架。并提出了自熵下降法来寻找合适的置信度阈值从而寻找可靠的伪标签用于优化模型。
把本章所提到的10种领域自适应的目标检测方法及其性能效果列于表3。表中“性能效果”一列:Dataset A→Dataset B 表示A 为源域,B 为目标域;括号内为未采用领域自适应方法的基础检测框架的检测性能;表格最右侧3列数据分别为该算法在该数据集上AP表现最差的类别、表现最好的类别以及所有类别的AP均值;表格的最后一行,将Sindagi等[86]的方法与基于恢复的方法进行了对比。从表3中可以看出,上述方法大多以目标检测框架Faster R-CNN 为主,对单阶段目标检测方法如YOLO、SSD等方法的研究较少。同时从源域数据集Cityscapes 迁移到目标域数据集Foggy Cityscapes 是研究此类问题较为流行的一种方式。通过表3 来比较不同方法在从Cityscapes 到Foggy Cityscapes 的域迁移上所表现的性能。从表中数据来看,不论是该算法AP 表现最差的类别,还是AP 表现最好的类别以及所有类别的均值AP,基于领域自适应的目标检测方法在检测性能上相比于原始检测方法来说都有较大幅度的提升。在Cityscapes→Foggy Cityscapes的迁移中,上述实验主要采用8个带有实例级注释的类别进行实验,用二者的训练集共同训练,用Foggy Cityscapes 的验证集进行测试。从收集到的文献中发现,检测效果较好的目标大多是样本较多或者目标尺度较大,例如car 类别。其中文献[86]作为这其中较为重要方法在雾天、雨天、雪天3种天气条件下进行了目标检测任务。基于迁移学习的方法比恢复+检测这种简单级联的方法有较大优势。例如,在Cityscapes→Foggy Cityscapes 的迁移中,仅使用源域数据训练得到的Faster R-CNN 其mAP 为24.4%。将DCPDN[96]和Grid-Dehaze[97]去雾网络作为预处理步骤时mAP 分别提升至26.4%、29.2%,提升幅度较小,而使用基于先验的域自适应方法时获得mAP为39.3%,检测精度得到了大幅增长。
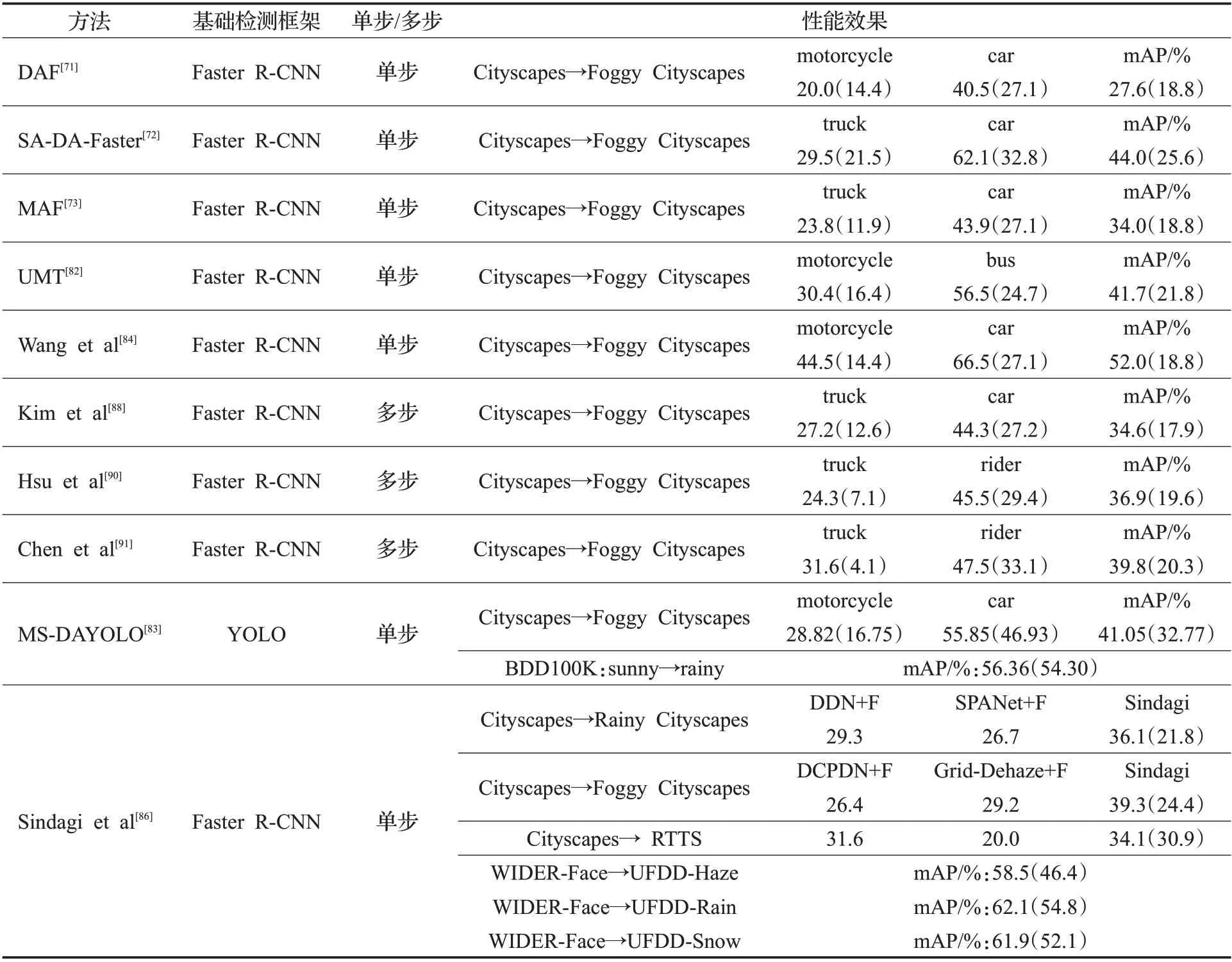
表3 基于领域自适应的目标检测方法的实验结果Table 3 Experimental results of object detection based on domain adaptation
这类迁移学习的方法的优点是可以让未标注的目标域图像参与到模型的训练过程中。由此,可以利用到真实图像的有效信息,减小数据集的标注压力,且这种方法能够对目标域的特征进行有效的学习并取得较好的检测性能,从而成为目前用于解决特殊天气下的检测问题的主流方法。但从实验结果分析来看,实验结果距离清晰图像上的检测结果仍然有较大差距。例如,现有的目标检测方法在PASCAL VOC 2007 数据集上的mAP最高能够达到90%左右,而在一些特殊天气的目标检测数据集上检测结果不足60%。这类方法仍然具有较大的提升空间。
4 结束语
本文对特殊天气条件下的目标检测方法从数据集的构建、基于图像恢复和基于迁移学习三个方面进行了综述。从调研的文献来看,现有的特殊天气数据集主要以合成雾天为主,而在这其中能够直接用于目标检测任务的较少。基于图像恢复的方法很多,但是与目标检测任务相结合的较少。迁移学习作为该类问题的主流方法已经取得了不错的进展,但是检测性能仍然有大幅的提升空间,目标检测任务在特殊天气条件下仍然面临许多困难和挑战。本文对下一步待解决的问题与研究方向进行了总结:
(1)缺乏数据集。基于深度学习的目标检测方法十分依赖于数据集,由于特殊天气下真实图像数据难以标注,因此大多数研究都是在合成数据集上进行的。目前雪天和沙尘天的数据集比较匮乏,希望未来能够用于目标检测任务的特殊天气数据集覆盖领域更加的全面。在将要开展的研究中,期望首先在已有的在晴朗天气条件下采集而来的目标检测的数据集中挑选合适的图像获取深度信息,再根据物理成像模型将仿真的特殊天气合成到图像中。最后以数据模型驱动的方式,使得之前的合成图像更加接近于真实特殊天气图像[38]。
(2)将图像恢复与目标检测任务相结合往往具有较好的效果,但这两个任务往往是独立的。虽然统一的端到端的多任务框架能够有效提升效果,但目前端到端的方法只能在合成数据集上进行[61],缺乏对真实情况的考虑。与此同时,发现迁移学习应用于跨域目标检测问题时[79,86],其检测性能是能够有较大幅度的提升的。因此将图像恢复嵌入到基于迁移学习的目标检测框架之中,可能是未来研究热点[87]。
(3)由于现实中的特殊天气复杂多变,有限的数据集难以覆盖所有天气情况,而领域自适应方法只研究对特定的目标域进行特征空间对齐。与领域自适应方法不同,领域泛化[98]重点强调对任意未知的目标域的学习能力。在未来,领域泛化的思想或许能够对复杂多变特殊天气下的目标检测问题提供一个好的研究思路。
猜你喜欢
军事文摘(2022年17期)2022-09-24
家庭影院技术(2021年8期)2021-11-02
中老年保健(2021年11期)2021-08-22
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
小哥白尼·趣味科学画报(2020年4期)2020-10-20
文苑(2020年7期)2020-08-12
作文小学中年级(2020年6期)2020-07-24
计算机世界(2020年50期)2020-01-15
青年生活(2019年23期)2019-09-10
