
一种无人机自主避障与目标追踪方法
2022-07-12 14:18江未来徐国强王耀南
宇航学报 2022年6期
江未来,徐国强,王耀南
(1. 湖南大学电气与信息工程学院,长沙 410082;2. 湖南大学机器人视觉感知与控制技术国家工程研究中心,长沙 410082)
0 引 言
深度强化学习已被成功应用于机器人、无人驾驶及电力系统等领域,是当前人工智能领域研究热点之一。深度强化学习算法由于具有一定的自主学习和环境泛化能力,可有效应对静态或动态环境下的无人机自主避障与目标追踪任务,相较于传统的避障与追踪算法在智能性和灵活性方面体现出明显的优势,得到了国内外学者的广泛研究。
文献[9-10]将比例-积分-微分(PID)算法与Q-Learning算法结合,实现无人机在静态环境下的目标搜索,但是Q-Learning算法仅适用于解决离散低维状态空间问题,未考虑状态的连续变化。文献[11-12]采用目标检测识别网络,实现对目标物体的定位与识别,利用位置信息作为决策网络的输入,从而输出当前动作,让无人机具备一定的自主避障能力,但是整个系统对运算能力要求高,避障与追踪的成功率难以保证。深度Q网络(DQN)算法是由DeepMind团队在Q-learning算法的基础上提出来的,它首次将深度学习与强化学习结合在一起,在许多电动游戏中达到人类玩家甚至超越人类玩家的水准。文献[14-17]采用DQN算法实现无人机在二维环境中对目标无人机的快速追踪,同时可以准确避障,但是其泛化能力有待进一步提高。
针对上述算法在实现动态环境下无人机自主避障与目标追踪的过程中所存在的成功率低、环境泛化能力弱等问题,本文提出了一种改进型深度强化学习算法——多经验池深度Q网络(MP-DQN)。首先,对DQN算法内部的探索策略进行改进,提出了一种鼓舞式探索策略——-inspire,使得无人机对环境进行合理探索。其次,提出了一种多经验池机制,对成功与失败经验数据进行划分,相较于单个经验池,该机制可以提升采样数据的质量,避免算法陷入局部最优。另外,在奖励函数中设计了方向奖惩,引导算法快速收敛。再者,为了提高无人机对环境的适应性,增加了无人机对环境的感知能力。最后,仿真结果验证了所提方法的有效性。
1 无人机自主避障与目标追踪问题描述
为了便于问题的分析与求解,本文对无人机自主避障与目标追踪问题进行了抽象和简化,做出如下假设:
1)假设无人机处于定高飞行,则将三维空间压缩至二维平面;
2)假设无人机的运动速度大小恒定;
3)假设无人机输出的动作为上、下、左、右。
满足以上假设后,设定无人机在一片城市区域内运动。采用栅格法将该区域离散化,并设定每个栅格的大小大于无人机的尺寸,确保无人机可以安全通过,如图1所示。
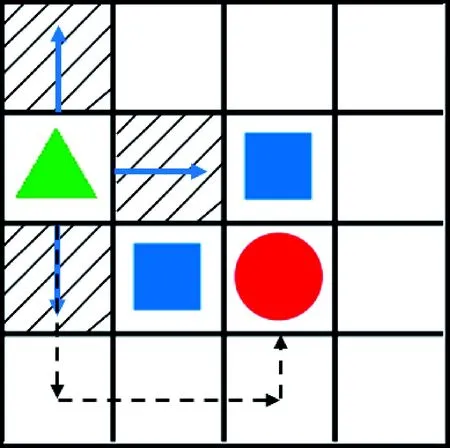
图1 自主避障与目标追踪示意图
图1中三角形表示追踪者,圆形表示逃避者,正方形表示障碍物,阴影区域表示追踪者可以感知到的环境范围,实线箭头表示追踪者可以执行的动作,虚线箭头表示追踪者的运动轨迹(这里假定逃避者处于静止状态)。逃避者可以在栅格环境中保持静止或随机运动状态,同时能够自主躲避环境中的障碍物以及追踪者的追击,但是要保证其逃逸速度小于追踪者的运动速度。追踪者可以获取到自身和逃避者的位置信息,并同时感知到周围障碍物信息。
本文的研究目标是让追踪者仅在简单的环境中训练后,即可在不同复杂度与规格的地图中以尽可能短的路径实时追踪处于静止或运动状态的逃避者,同时精准规避环境中的障碍物。
2 无人机自主避障与目标追踪问题建模
无人机在栅格环境中只能感知部分的环境信息,因此将其建模为部分可观测的马尔可夫决策过程(Partially observable Markov process, POMDP)。下面对模型中的观测空间、动作空间以及奖励函数进行定义。
2.1 观测空间
假定当前追踪者的坐标为(,),逃避者的坐标为(,),为了降低观测空间的维度,采用二者之间的相对位置,作为位置观测信息,即
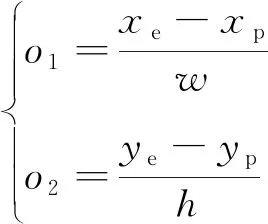
(1)
式中:表示栅格环境宽度;表示栅格环境长度。
追踪者可以感知周围部分环境,分别是上、下、左、右四个栅格的障碍物信息。具体的信息描述方式为

(2)
因此,追踪者的观测空间可以具体表示为
=[,,,,,]
(3)
式中:,表示相对位置信息;,,,表示障碍物观测信息。
2.2 动作空间
追踪者的运动速度大小恒定,但是运动方向可变。策略π的输出即为追踪者的运动方向。定义追踪者的动作集合为,可表示为
={(0,-1),(0,1),(-1,0),(1,0)}
(4)
式中:四个元素分别表示上、下、左、右动作向量。
当追踪者在环境边界处欲跨出边界时,其位置仍然保持当前位置不变。追踪者在每个时刻的位置更新方式为
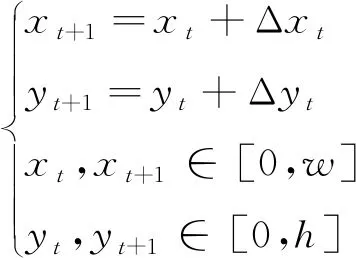
(5)
式中:(,)表示追踪者在时刻位置坐标;(Δ, Δ)表示在时刻采取的动作;(+1,+1)表示下一个时刻位置坐标。
2.3 奖励函数
奖励函数是引导追踪者进行有效学习的关键,设计合理的奖励函数可以提升追踪者的收敛速度与学习的稳定性。稀疏奖励是一种简单的奖励函数,它仅在追踪者处于终止状态时才会给予回报。当追踪者任务成功时反馈正向奖励,从而激励追踪者不断强化采取的动作序列。当任务失败时则施加惩罚,提醒追踪者规避某些错误行为。但是稀疏奖励需要追踪者不断探索环境,直至获得正向奖励时追踪者才能得到有效更新,这会降低学习效率,并且极易收敛至局部最优解,甚至对于复杂环境,追踪者由于难以探索到目标状态而导致算法无法收敛。因此,需要设计一种连续奖励函数,不断引导追踪者靠近目标。
本文设计的奖励函数包括四个部分:终止奖惩、步进奖惩、距离奖惩和方向奖惩。终止奖惩的函数形式为
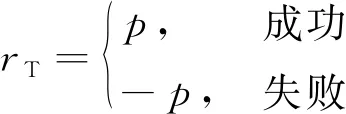
(6)
式中:为正实数,即追踪者完成任务时给予奖励,任务失败则施加惩罚。步进奖惩的函数形式为
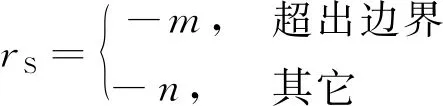
(7)
式中:,均为正实数,并且>,即当追踪者采取跨出边界的行为时获得的惩罚比区域内运动时获得的惩罚大,其主要目的在于激励追踪者不要跨出指定区域,同时保持较短的追踪路径。距离奖惩的函数形式为
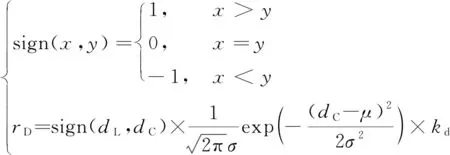
(8)
式中:表示上一个时刻追踪者距离逃避者的欧氏距离;表示当前时刻的欧氏距离;表示距离的期望,本文设=0,即实现完全追踪;表示距离奖惩范围,为正实数。式(8)表示当追踪者靠近逃避者时会获得奖励,远离则会受到惩罚,并且越靠近逃避者奖惩力度越大。方向奖惩的函数形式为
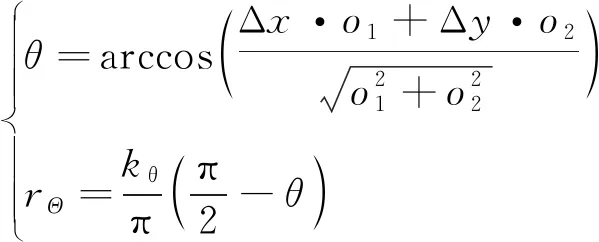
(9)
式中:表示追踪者的运动方向与追踪者和逃避者连线方向之间的夹角,为正实数,具体描述如图2所示。当<π2时,表示追踪者正在靠近逃避者,从而获取环境给予的奖励。反之当>π2时,表示追踪者正在远离逃避者,从而受到环境施加的惩罚。
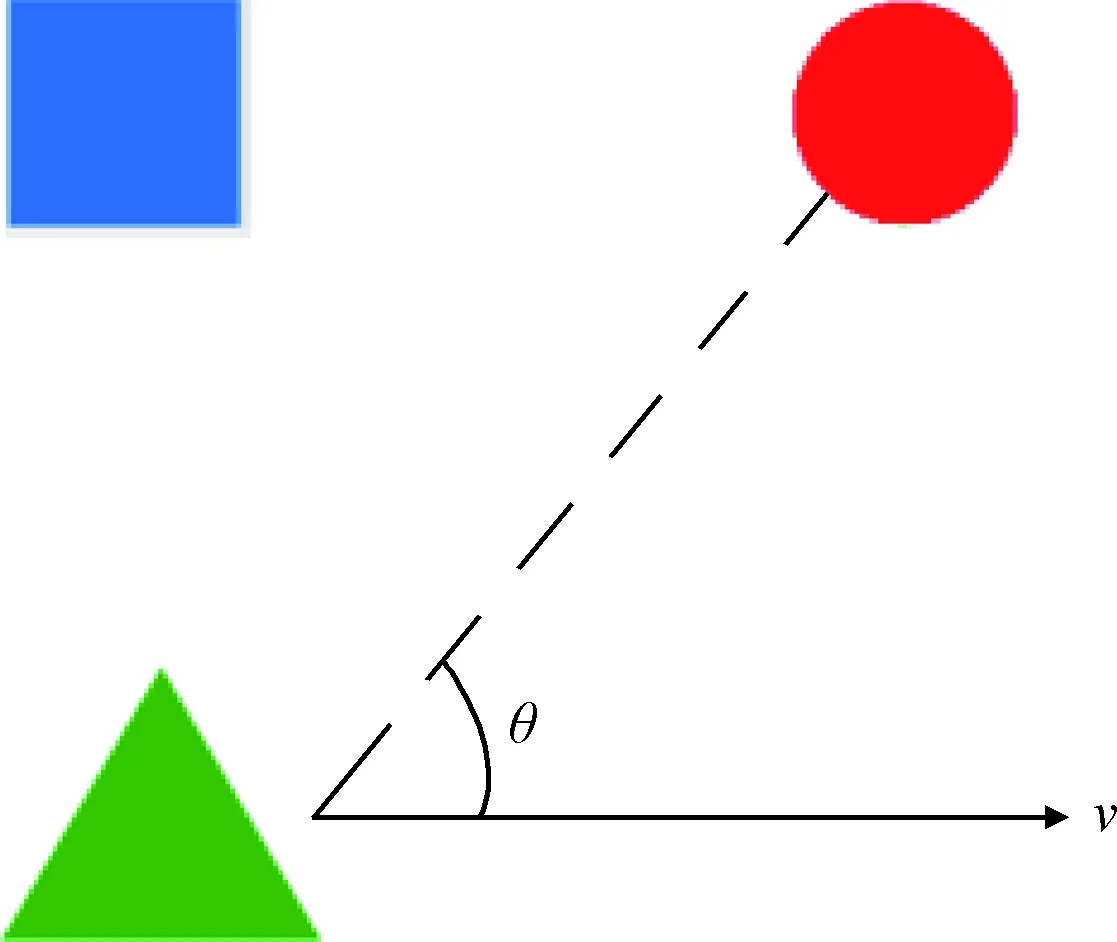
图2 方向角示意图
综合以上四种奖惩函数,最终的奖励函数为
=+++
(10)
3 MP-DQN算法
在DQN算法中,追踪者与环境交互的经验数据都会被放置在经验池中,并且在每一轮迭代,追踪者都会不断从经验池中随机采样数据来学习。因此,经验池中数据的好坏决定网络学习的效率。当追踪者陷入局部最优时,相关动作序列被不断强化,此时追踪者已经难以从经验池中学习到有效知识,致使其难以脱离局部最优解。针对这个问题,本文对DQN算法进行改进,提出一种MP-DQN算法,具体改进点包括-inspire探索策略和多经验池。
3.1 ε-inspire探索策略
追踪者对未知环境的探索可以促进追踪者寻找全局最优解。在前期学习过程中,追踪者可以以较大的探索率探索环境。随着迭代的进行,追踪者可能已经逐渐找到最优策略,应当减小探索率,强化追踪者学习到的经验知识。因此通常DQN算法采用的是变的-greedy策略,即随着迭代次数的增加而缓慢增加,追踪者的动作选择遵循
综上所述,采取氧气雾化吸入布地奈德混悬液联合复方异丙托溴铵溶液治疗喘息性支气管炎疗效明显,副作用小,值得临床推广。通过精细有效的护理,使患儿家长熟练掌握雾化吸入的方法,加强对于患儿及家长的有关常识的宣教,确保患儿及家长能够积极配合治疗,能够极大程度地提升雾化吸入治疗的效果。

(11)
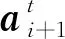
但是在复杂的环境中,前期探索可能无法支持追踪者找到最优策略,或者虽已找到最优策略,但由于还未得到强化,追踪者再次陷入局部最优。针对这个问题,本文在-greedy策略上做了进一步优化,提出-inspire策略。其基本思想是如果追踪者在一段时间内始终没有完成任务,则会减小,提升追踪者的探索能力,直到追踪者完成一次任务后才会缓慢增加,再次削弱追踪者的探索能力。具体描述为
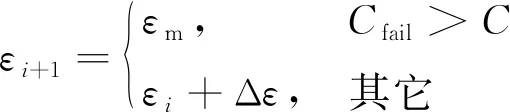
(12)
式中:表示追踪者连续任务失败的次数;表示追踪者连续任务失败的最大次数;表示设定的遗忘探索率。当追踪者连续失败的次数达到设定的阈值时,强制=,从而提高探索能力,鼓励追踪者探索环境,搜索全局最优解。
3.2 多经验池
单纯提升探索能力,虽然在一定程度上可以激励追踪者完成任务,但是算法收敛过程波动剧烈,而且如果任务难度较大,追踪者可能一直处于探索状态,始终无法得到强化。为了进一步保证追踪者在可以脱离局部最优解的前提下仍然能够稳定收敛,本文提出了多经验池机制。前面分析过,当追踪者陷入局部最优时,单个经验池中的数据对于追踪者来说可学习性不强,引入多个经验池后可以有效保证数据的质量。
MP-DQN算法中包括三个经验池:失败经验池P、成功经验池P和临时经验池P。失败经验池存储追踪者任务失败时产生的经验数据,设其容量大小为。成功经验池存储追踪者任务成功时产生的经验数据或者是追踪者能够多次避开周围障碍物的经验数据,设其容量大小为。而临时经验池则存储当前世代追踪者产生的临时经验数据,设其容量大小为。当临时经验池溢出时,如果追踪者仍然没有到达终止状态,则认为过去的决策对现在具有积极影响,故将从临时经验池中溢出的数据存入成功经验池,然后根据最终任务的成败决定剩余所有数据的存储位置。
MP-DQN算法更新时需要的数据分别从失败经验池与成功经验池中按照一定的比例采样获取。这样即使追踪者陷入局部最优,仍然可以从成功经验池中获取任务成功的经验数据来学习,从而帮助追踪者快速脱离局部最优。假设追踪者每次从成功经验池中采样数据的比例为,随机采样的总数据量为,则从成功经验池与失败经验池中采样的数据量分别为
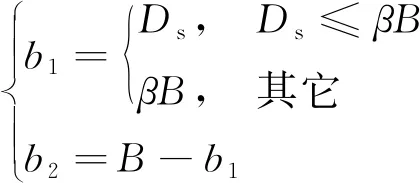
(13)
式中:表示从成功经验池中采样的数据量;表示从失败经验池中采样的数据量;表示当前成功经验池中的总数据量。具体算法流程如图3所示。
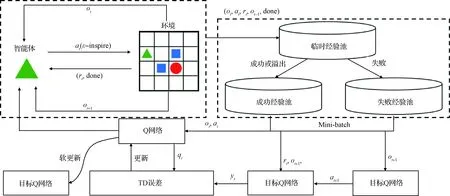
图3 MP-DQN算法结构框图
3.3 算法结构与实现
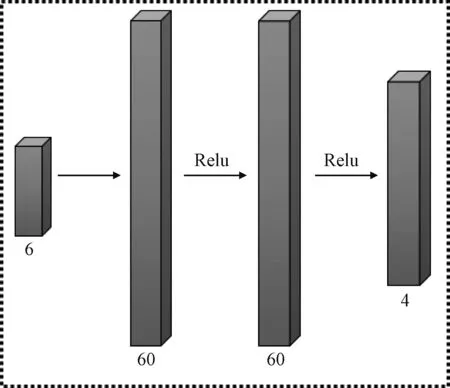
图4 MP-DQN算法网络结构
MP-DQN算法的具体实现流程如下:
初始化:临时经验池P(最大容量为)
成功经验池P(最大容量为)
失败经验池P(最大容量为)
MP-DQN中评估网络参数
MP-DQN中目标网络参数
执行:
1)repeat
2)随机初始化状态
3)while≤do:
4)根据-inspire策略选择动作,追踪者执行该动作并获得环境反馈的即时奖励和新的观测信息′
5)将经验(,,,′,done)存入P,若P溢出,将溢出的数据存入P
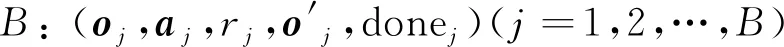
7)计算目标值:
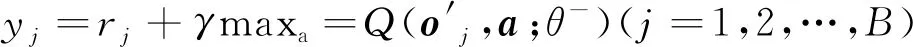
8)更新评估网络参数以减小:
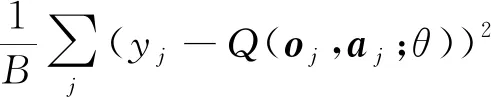
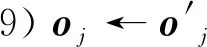
10)软更新目标网络参数:=+(1-)
11)if done:
12)如果追踪者任务成功,将P中的数据一次性全部放入P;如果追踪者任务失败,则将P中的数据一次性全部放入P
13)end if
14)end while
15)until最大训练回合数
4 仿真校验
本文在Python环境下,基于Tensorflow 2.2与CUDA10.2框架构建MP-DQN算法网络。评估网络更新参数时采用的优化器为Adma,学习率设置为0.01,目标网络软更新时的学习率设置为0.01,网络学习时随机采样的总数据量设置为32,每次从成功经验池与失败经验池中采样数据比例设置为0.85。为了保证网络可以收敛,设置迭代的最大幕数为1000。为了平衡未来与即时奖励,折扣系数设置为0.9。对于-inspire策略,最小探索率设置为0,最大探索率设置为0.99,探索率增量Δ设置为0.001,追踪者连续任务失败的最大次数设置为50,遗忘探索率设置为0.8。成功经验池与失败经验池的最大容量相同,均设置为2000。如果追踪者在15步以内仍然没有进入终止状态,则认为之前的决策具有一定的价值,需要将经验数据保存到成功经验池中,故将临时经验池的最大容量设置为15。针对奖励函数,终止奖惩中设置为20,步进奖惩中设置为1,设置为0.5,距离奖惩中设置为2,方差设置为0.5,方向奖惩中设置为5。
4.1 MP-DQN算法验证
仿真环境为一个12×12的栅格地图。逃避者在环境中做随机运动,可以自主躲避障碍物与追踪者,其运动速度设定为追踪者速度一半。实验规定最大步数为60步,超过该阈值则终止当前世代。追踪者每次任务成功后,逃避者下一次都会随机选择一个出生点,以增强任务的随机性。分别采用DQN、DDQN以及MP-DQN算法进行测试,测试结果如图5、6、7所示。

图5 三种算法累计奖励曲线
图5是三种算法在每个回合的累计奖励曲线,MP-DQN和DQN均在200步左右时收敛,但MP-DQN算法的收敛速度稍快,DDQN算法效果最差。图6为追踪者在训练阶段的成功率曲线,MP-DQN算法的成功率始终最高;另外对训练好的追踪者进行测试,MP-DQN算法的成功率仍然最高,并且始终为1。图7为追踪者和逃避者某一次的运动路径,其中小三角形和圆形分别表示追踪者与逃避者运动路径上的点,追踪者不仅可以准确避障,还能够快速追踪逃避者。因此,MP-DQN算法可以有效提高追踪者的收敛速度及避障与追踪的成功率。
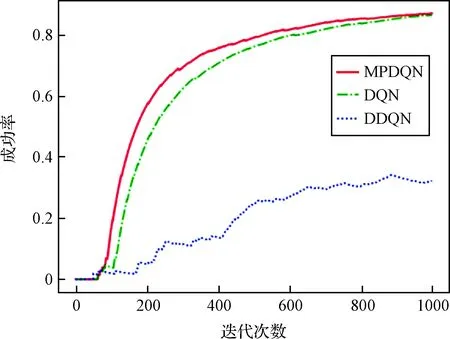
图6 三种算法训练成功率曲线

图7 12×12栅格地图追踪路径
4.2 方向奖惩验证
采用4.1所述的仿真环境,分别讨论奖励函数中包含(with_angle_reward)与不含方向奖惩(without_angle_reward)情形,观察其对追踪者的任务执行是否存在影响。利用MP-DQN算法进行对比实验,仿真结果如图8、9、10所示。

图8 方向奖惩-累计奖励曲线
图8是累计奖励曲线,通过对比可以看出加入方向奖惩后算法大约在200步时已经基本收敛,而在去掉方向奖惩后算法大约在400步时才进入收敛状态。图9是累计步数曲线,可以明显看出加入方向奖惩后,追踪者可以以较少的步数追赶上逃避者,实现快速追踪。图10是追踪者在训练阶段的追踪成功率曲线,通过对比发现加入方向奖惩后显著提升了追踪者的收敛速度和避障与追踪的成功率;另外在测试阶段,加入方向奖惩的追踪者成功率同样更高。因此,方向奖惩函数可以有效提高算法的整体性能。
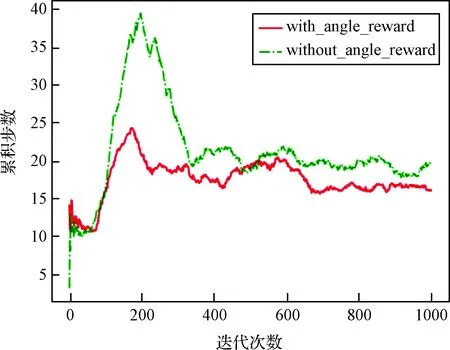
图9 方向奖惩-累计步数曲线
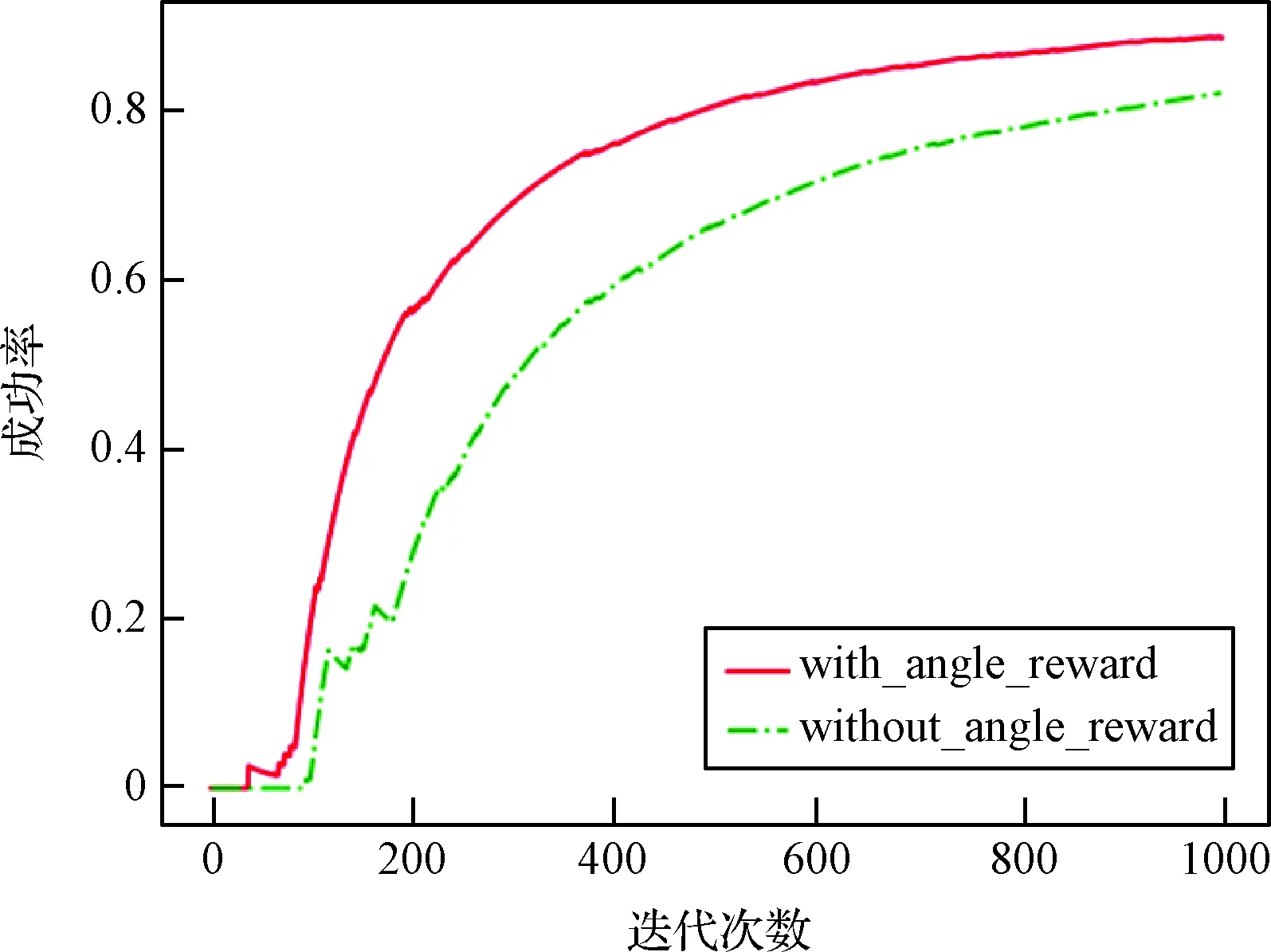
图10 方向奖惩-训练成功率曲线
4.3 泛化能力验证
为了验证具备感知能力的无人机拥有环境泛化能力,本节利用前面已经训练好的追踪者,命名为追踪者1号,将其应用到全新的12×12的栅格地图以及更大规模的16×16的栅格地图中。为了进行对比,本文重新训练一个不具备环境感知能力的追踪者,命名为追踪者2号。分别将它们在上述环境中测试1000轮。最后统计它们的追踪成功率,结果显示追踪者1号的成功率始终为1,而追踪者2号的成功率几乎为0,即追踪者1号具备更强的环境泛化能力。主要原因在于追踪者2号在环境中学习时,学会的是整张地图的环境信息,而不是避障能力。当环境信息发生变化时,以前的知识不具有普遍性,因而追踪成功率低。而追踪者1号在环境中学习时,通过感知周围环境,再结合自身与逃避者之间的相对位置信息,通过不断训练最终学习到了避障及追踪的能力。因此,即使面对新的环境,也可以保证稳定的避障及追踪性能。图11为追踪者1号和逃避者在16×16的栅格地图中某一次的运动路径。
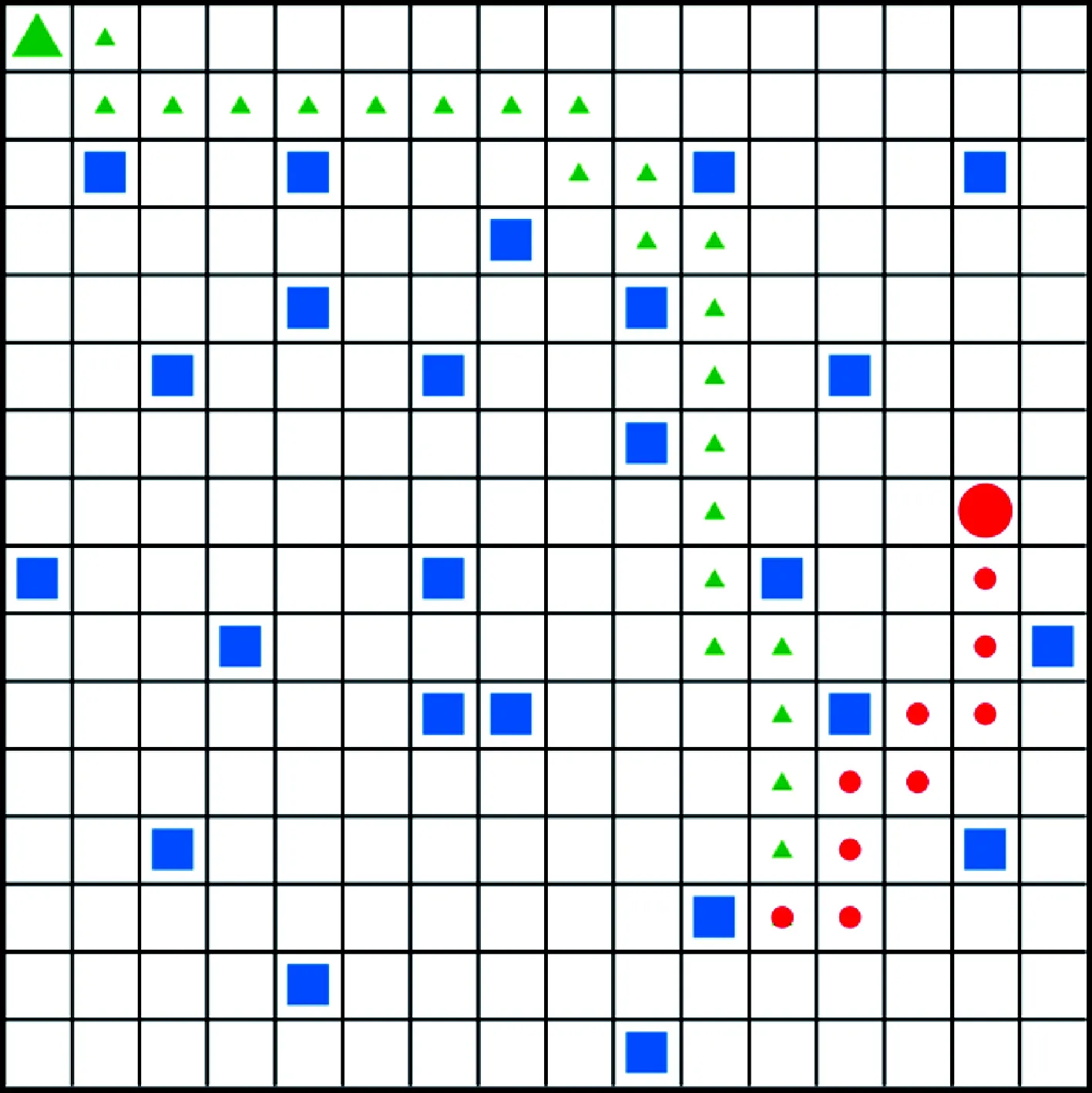
图11 16×16栅格地图追踪路径
5 结 论
针对深度强化学习算法在实现动态环境下无人机自主避障与目标追踪的过程中所存在的成功率低、环境泛化能力弱等问题,本文做了以下工作:提出了改进型深度强化学习算法MP-DQN;在奖励函数中设计了方向奖惩函数;赋予无人机环境感知能力。仿真结果表明,MP-DQN算法较DQN和DDQN算法具有更快的收敛速度和更高的避障与追踪成功率;引入方向奖惩后,显著提升了算法的整体性能,包括追踪路径、收敛速度和追踪速度;拥有环境感知能力的无人机只需在简单的地图中训练即可应用于不同规格及复杂度的环境,具备良好的环境泛化能力。
猜你喜欢
天天爱科学(2022年9期)2022-09-15
中国药学药品知识仓库(2022年10期)2022-05-29
中国典型病例大全(2022年9期)2022-04-19
文萃报·周五版(2019年41期)2019-09-10
移动通信(2019年2期)2019-03-27
大科技·C版(2018年11期)2018-10-21
赤峰学院学报·哲学社会科学版(2016年12期)2017-03-20
兵器知识(2016年11期)2016-11-03
读与写·教育教学版(2015年9期)2015-09-23
中国大学教学(2015年7期)2015-09-06
