
企业债务违约风险预测
——基于机器学习的视角
2022-07-11 04:29王玉龙张涤霏
财政科学 2022年6期
王玉龙 周 榴 张涤霏
内容提要:我国正处于经济结构转型的关键时期,防范化解重大风险是我国当前经济工作的重要任务,因此有效预测企业债务违约风险具有十分重要的现实意义。本文系统性地运用机器学习方法,基于2014-2019 年发生实质性债券违约的上市公司,采用7 种机器学习算法构建企业债务违约风险预测模型。实证结果显示,基于随机森林所构建企业债务违约风险预测模型分类效果最佳,其中营业净利率、净利润、现金比率、财务费用和资产负债率5 个财务指标可作为企业债务违约风险预警指标。研究表明,基于机器学习的企业债务违约风险预警系统能够有效地进行债务违约风险预测,不仅可以深化对企业债务违约风险影响因素的微观特征的认识,而且有助于监管部门对上市公司财务状况的监督更加有针对性。
一、引 言
我国正在经历着从经济高速增长转向高质量增长的关键时期,防范化解重大风险是当前经济工作的重要内容。而我国近年来频繁出现的企业债务违约问题却给金融市场的稳定造成一次次的冲击,对经济结构的优化转型产生了一定的负面影响。2014 年,我国债券市场首次出现实质性违约事件,“刚性兑付”时代宣告终结,债券违约不仅开始进入常态化阶段,而且违约主体也从民营企业向国有企业蔓延。此外,随着供给侧结构性改革持续推进以及经济去杠杆和金融监管力度加大,我国社会融资规模存量增速持续下降,企业在融资趋难的背景下进入了债务违约高发期,历年新增的违约发行人数量与违约金额逐年攀升,进而加剧了我国资本市场的风险波动。企业违约风险的提高不仅会威胁企业的正常经营(Foster et al.,1998),导致企业经营状况恶化,一旦出现实质性违约行为还会给企业本身以及债权人造成极大的负面影响(Warner,1997;Altman,1984),甚至引起发行主体经营持续恶化甚至破产清算,给上市公司股东和债权人造成重大损失,还会导致企业个体风险向商业银行系统和股票市场的跨领域传递,进一步扩大系统性风险。由此可见,企业债务违约问题已经极大程度上影响了我国金融市场的稳定,如何有效预测企业债券违约风险成为亟待解决的关键问题。
目前,在实证研究方面,国内外关于企业债务违约的研究已经较为丰富,并且主要集中在企业债务违约的经济后果,如企业债务违约会影响自身投资行为、信贷资金配置效率、股票流动性、资本化支出、货币政策预期等(Sudheer and Michael,2009;陈德球等,2013;谭春枝和闫宇聪,2020;李昊洋和韩琳,2020;张庆君和马红亮,2021;肖志超等,2021),以及影响企业债务违约的因素,如股权集中度(Zeitun et al.,2007)、所有权结构和董事会特征(Chiang et al.,2015)、环境不确定性(张靖等,2018)、或有事项披露(董小红等,2020)、信息披露质量(吴建华等,2017;常莹莹和曾泉,2019)、企业现金持有(Ghaly et al.,2017)、内部控制质量(李萌和王近,2020)和创新水平(Hsu et al.,2015;孟庆斌等,2019)等因素都会影响企业债务违约风险。
而仅有少量文献对于企业债务违约风险的预测做出相关探讨,例如:已有学者根据财务困境预测的经验提出了相关的建议(吴世农和卢贤义,2001),基于模糊随机方法对企业违约风险做出了预测并给出了数值模拟(韩立岩和郑承利,2002),通过KMV 模型预测了企业的信用风险(张泽京等,2007),利用Logistic 模型、双指数分布跳跃扩散模型对企业债务违约风险进行分析(潘泽清,2018;宫晓莉和庄新田,2018),还有学者基于信用利差构建出公司违约风险变量,然后运用Twin-SVR 模型对公司违约风险展开预测(林宇等,2019)。由此可见,不仅鲜有学者探究企业债务违约风险的预测问题,并且对于构建风险预测模型的方法也并未达成一致。
而机器学习作为人工智能的代表技术,正在逐渐被学者们运用于财务困境预测、财务欺诈预测以及股票市场预测和量化等研究中(Gepp,2018)。首先,与传统的计量经济学研究方式不同,机器学习具有在数据中学习经验和知识的能力(赵琪等,2020),在拟合数据的过程中具有更高的灵活性,在研究非线性、无法直接观测因果关系的研究中具有更强大的解释力,也具有更高的预测能力(Mullainathan and Spiess,2017),进而在经济金融领域帮助学者克服数据获取以及相关性预测等难题(王芳等,2020)。其次,目前主流的实证方法仅适用于探究变量之间的因果关系,在受限于严苛的适用条件的同时也无法有效处理并控制影响因素之间的相互作用(Bali et al.,2016),进而难以得到预期的结果,并且造成企业债务违约的影响因子往往无法被人们所悉数列出。所以,传统的实证研究并不能很好地通过线性或者非线性模型去探究所有因子之间复杂的关系,而机器学习却能够有效突破模型设定的限制,可以通过不同算法对样本数据之间的关系进行深度挖掘并优化学习模型,从而获得更好的预测结果(张宏斌和郭蒙,2020)。最后,尽管部分学者已经通过某些机器学习的方法对企业债务违约风险预测做出了一些研究,但仍缺乏系统性的研究来检验其作用和效果,就笔者所知,本文系首次系统性地运用机器学习方法检验中国上市公司的债务违约风险。
本文的贡献在于:第一,丰富了机器学习在经济金融领域的现有研究。虽然自2007 年以来,包含“机器学习”“金融市场预测”等关键词的文献数量呈显著增长,并且至今仍保持着稳定的增长趋势(Henrique et al.,2019),但是国内对于机器学习在经济金融问题中的运用仍然处于起步阶段(苏治等,2017;黄乃静和于明哲,2018)。因此,本文通过系统地运用机器学习对企业债务风险问题进行研究,为机器学习在经济金融领域的进一步运用提供了参考。第二,对于防范化解企业风险具有重要现实意义。国内外现有文献主要集中于企业财务困境预测以及企业财务舞弊预测(Chen et al.,2009;Li et al.,2010;Sun et al.,2011;黄志刚等,2020;张宏斌和郭蒙,2020),而企业债务违约风险预测却鲜有研究。进而,本文的研究不仅揭示了企业债务风险管理的重要性,促进企业提高自身债务管理水平,还能够为监管部门的风险防范工作提供一定的理论指导。
二、研究设计
本研究从CSMAR 数据库中获取公司的财务数据,由于过多的特征容易造成模型的过拟合,故本研究使用Pearson 相关性检验、MRMR 特征筛选结合7 种机器学习分类算法构建企业债务违约风险预警模型。此外,受到样本量较小的限制,所建模型担心出现过拟合现象,故采用留一法对分类模型进行验证。最后,用Wilcox 秩和检验筛选出与债务违约最相关的财务指标进行进一步的分析。具体的研究流程如图1。

图1 研究流程
三、样本选取与变量选取
(一)样本选取
本文以2014-2019 年发生实质性债券违约的上市公司作为实验组样本,在剔除已退市样本和金融企业样本之后得到37 家上市公司一共88 次债券违约行为,由于存在部分上市公司一年出现多次债券违约且时间十分接近的情况,本文只取每年第一次的债券违约事件作为观测样本,最终得到一共43 个观测值。另外,受到样本数的限制,本文参考Altman(1968)、Neophytou et al.(2004)以及潘泽清(2018)的研究采用一比一配对的方法,从未发生债券违约的上市公司中选取特征接近的正常公司。因此本文以资产规模、负债规模、营业收入、自由现金流作为匹配变量选取得到对照组样本。在具体配对过程中,本文参考李斌等(2019)的研究,分年度并以t-1 期的公司特征和t 期是否发生违约进行配对作为初始样本,再通过一比一的匹配方式得到43 个未发生违约的正常公司样本,即违约公司(Xt-1,Yt)与正常公司(Xt-1,Yt)的配对。
为了检验对照组样本具有良好的可对比性,本文进行了组间均值T 检验。从表1 中可以发现,基于四个匹配变量,两组样本之间并不存在显著差异性,说明一对一配对得到的对照组样本与实验组样本具有类似特征。

表1 组间均值差异检验 单位:亿元
(二)变量选取
根据已有研究,企业杠杆水平的提升会导致企业违约风险的提升(解文增和王安兴,2014),而企业财务状况的改善可以降低企业违约风险(Altman,1968;Campbell and Dietrich,1983)。此外,银行也会根据会计信息所反映的企业经营状况作为企业违约风险评估的重要依据(廖秀梅,2007),进而做出相应的信贷决策(陆正飞等,2008)。因此,本文主要通过能够反映上市公司基本运营情况的财务指标来构建模型,并参考李斌(2019)和陈彦斌等(2021)将公司特征划分为七个方面:盈利能力、偿债能力、成长能力、现金流水平、成本水平、运营能力、资本结构。并初步选取了38 个指标,具体见表2。

表2 债务违约风险初步财务指标

续表
四、财务指标的筛选
(一)Pearson 相关性检验
过多的特征会导致多重共线性严重、加大模型的计算负担并且容易造成模型过拟合。为了识别冗余特征,利用Pearson 相关分析计算每个特征之间的相关性。本文剔除冗余性财务指标的规则为:如果任意两个财务指标的Pearson 相关性的绝对值高于0.9,表示这两个指标间的相关性较高,故将其剔除。依据相关性检验结果,本文最终从38 个财务指标中选择出30 个指标输入模型中,进行下一步筛选与建模。
(二)MRMR 特征筛选
在构造分类模型之前,特征筛选是尤为重要的一步。MRMR 算法不仅考虑了指标与是否违约之间的相关性,还考虑到指标和指标之间的相关性。所以该算法能够在保证最大相关性的同时,去除冗余特征。相关性和冗余性通过如下的互信息(MI)进行量化:

在本研究中,S表示所选的财务指标,h表示是否发生债务违约。其中第一项指财务指标与是否债务违约的相关性,第二项指财务指标之间的冗余性。最后选择高相关性低冗余性财务指标放入模型中。在本研究中,基于经过Pearson 筛选后的30 个财务指标做MRMR 特征排名,以步长为1 依次将前30 个财务指标输入模型中,最后选择效果最好的模型,其对应的输入财务指标为MRMR 筛选后最佳指标。
五、机器学习算法的选取
为了探索所选财务指标是否能较好预测企业债务违约,本文选择7 种代表性的机器学习算法,包括支持向量机(SVM)、随机森林(RF)、LASSO 回归(LASSO)、朴素贝叶斯、Bagged Trees、普通最小二乘(OLS)回归、逻辑回归。
(一)支持向量机和朴素贝叶斯
在深度学习出现之前,SVM 一直是机器学习理论的核心算法之一,在很多任务上取得了较好的结果,对于机器学习当中一些线性不可分的问题或者涉及研究的样本量较小时,抑或是存在一些高维数据时,可以利用支持向量机算法进行解决,既可以构建分类模型又可以构建相关的回归模型。空间当中存在一个名为超平面的平面,其可以将空间中存在的数据进行较为良好地分类。因此在支持向量机算法当中,先根据不同的核函数将原始的样本数据一一对应到新的空间当中,然后利用上述的超平面对样本数据进行分类。
朴素贝叶斯分类是以贝叶斯定理为基础并且假设特征条件之间相互独立的方法,先通过已给定的训练集,以特征词之间独立作为前提假设,学习从输入到输出的联合概率分布,再基于学习到的模型,输入指标求出使得后验概率最大的分类输出。
(二)随机森林和Bagged Trees
本文选取随机森林算法,原因是Fernández-Delgado et al.(2014)检验了179 种分类算法的表现,得出结论是随机森林类算法在绝大多数分类任务中可以取得理想的结果。随机森林算法计算中需要构建不同的树从而组建森林,这些树通过不同的排列组合构造出随机森林分类器。不同的树其分类性能会有一定的偏差,但是随机森林算法会在最后全面地考虑到每棵树的结果,并将其结果综合考虑得到最后的分类结果,因此往往其分类效果较好。将随机森林算法做为一种分类器,则上述的多棵决策树H(x)的分类结果公式可表示为:

装袋决策树是在每次循环的过程中,从可用的训练数据集中进行有替换的抽样,建立高方差的决策树,可通过直接分类或回归进行求值得到最终分类结果。
(三)LASSO
选取LASSO回归是因为它是极具代表性的线性模型(Hastie et al.,2009)。将筛选后的指标与作为模型构建方法LASSO(least absolute shrinkage and selection operator)的输入,构建预测模型。LASSO又称为最小绝对收缩选择算子,该方法是一种压缩估计,其公式为其中λ>0。λ 选择的标准为最小化泛化误差,即最小预测误差,在λ 的集合中选择λ1,得到其泛化误差,对集合中剩余λ 进行交叉验证,得到总的预测误差,其中的最小值为最终选择的λ。LASSO 的基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,从而能够产生某些严格等于0 的回归系数,得到可以解释的模型。其特点和优点是在拟合广义线性模型的同时进行变量筛选和复杂度调整,所建模型即为筛选后变量的加权和,从而避免模型的过度拟合。
(四)OLS 回归和逻辑回归
OLS 回归是最简单的线性回归模型,其原理是使散点图上的所有观测值到回归直线距离的平方和最小。选取OLS 回归同样是因为其在金融学术研究中被运用并取得了较好的预测效果(Light et al.,2017)。
逻辑回归并不属于对数据进行回归分析,而是一种分类算法,在二分类的研究中较为常见。该算法主要是通过函数L 将w’x+b 对应一个隐状态p,p=L(w’x+b),然后根据p 与1-p 的大小决定因变量的值。如果L 是逻辑函数,就是逻辑回归。可以解释为将输入值通过线性回归转化为所需要的预测值,然后映射到Sigmoid 函数中。建立坐标系后,其值为x 轴上对应的变量,而y 轴所对应的为分类概率,预测值对应的Y 值越接近于1 说明越符合预测结果。
六、机器学习模型的构建与结果评价
(一)机器学习模型的构建
最优模型的评选包括模型内部最优参数调整及模型间性能对比两部分内容。对于基于随机森林算法构建模型,其模型内部最优参数调整主要包括:根据MRMR 特征筛选算法排名,依次选取前2 到30 个指标以一个指标为间隔输入到模型中,得到最优指标组合;调整随机森林算法指标ntree从100 到500,每隔10 建立分类模型,选取最优参数ntree。进而组合得到随机森立最优模型;对于使用支持向量机算法,模型内部最优参数调整除了根据MRMR 特征筛选不同指标输入模型得到最优组合外,还包括对惩罚系数和gamma 参数进行调节,最后组合得到最优支持向量机模型;对于其他算法同样都基于MRMR 特征筛选组合不同的指标输入模型,分别得到最优分类模型。
模型间性能对比主要是对基于7 种分类算法建立的最优模型的ROC 曲线下面积(AUC)、准确度(ACC)、特异度(SPEC)、灵敏度(SENS)进行综合对比,从中选出最优模型作为企业债务违约风险预测模型。其中,准确度是指被正确分类的企业债务是否违约数与整个数据及企业数的比率,计算公式如下:
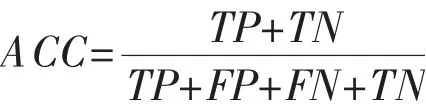
特异度是指被分类正确的未存在债务违约企业数与所有未存在债务违约企业总数的比率,计算公式如下:

灵敏度是指被分类正确的债务违约企业数与所有存在违约的企业总数的比率,计算公式如下:

(二)债务违约风险预测结果评价
基于七种不同机器学习算法构建的企业债务违约风险预测最优模型结果如表3 所示。其中使用支持向量机算法结合MRMR 特征筛选后的15 个特征得到最佳模型,其AUC 达到0.97。随机森林算法结合MRMR 特征筛选后的12 个特征得到的模型AUC 也达到0.892。但由于本研究的样本数量较少,无法进行训练集与测试集的划分,因此构建后模型可能存在过拟合现象发生。为了更进一步的验证模型的准确率和去过拟合化,本研究使用留一法(LOOCV)实现进一步的验证。

表3 七种机器学习分类模型预测结果
(三)债务违约风险预测结果稳健性检验
为了缓解由于样本较少导致的违约风险预测模型结果失真问题,本文在原有样本的基础上,补充了一比二和一比三匹配得到的样本,并重新通过LASSO、RF 和SVM 模型进行预测,从表4 的结果中可以看出,随着样本的扩充,AUC 的数值也逐渐增大,说明样本量的增加能够提高模型的预测效率。

表4 模型预测结果稳健性检验
七、模型的验证
基于上述模型构建的结果,选取同种类型机器学习算法中分类性能较好的算法所构造的模型进行进一步的验证。本研究采用留一法进行模型的验证,其结果如表5 和图2 所示。其中基于随机森林算法所构建的模型验证后结果最佳(AUC=0.868),而基于支持向量机算法所构建模型的AUC 仅为0.742,因此说明上一部分所构建的支持向量机模型可能出现过拟合现象,体现出模型验证的必要性。

图2 留一法验证模型ROC 曲线
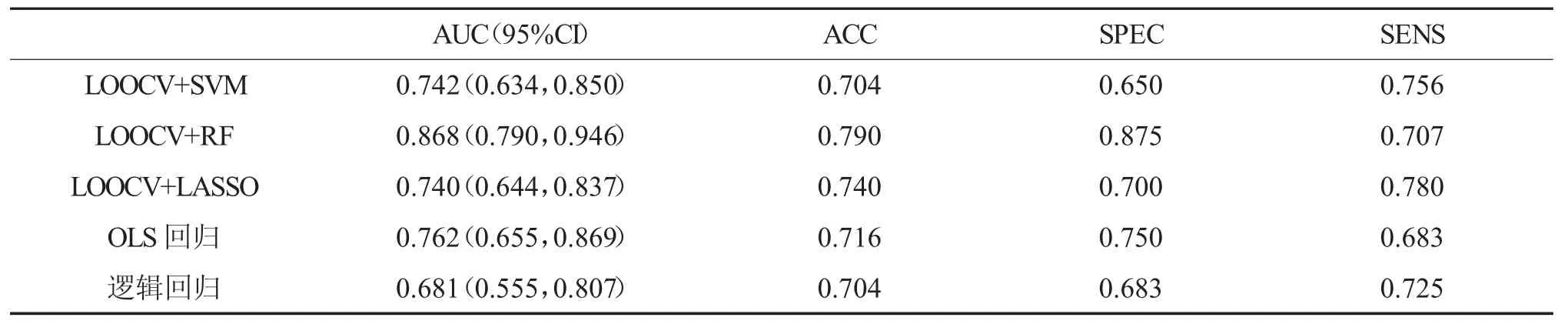
表5 留一法验证模型结果
八、财务指标相关性分析
基于留一法对上述机器学习算法构建的模型进行验证,结果表明基于随机森林算法所构建模型的性能优于其他算法。为了更进一步的描述构建模型所用的财务指标与企业债务违约的相关性和依赖性,本研究对随机森林模型中的财务指标做Wilcox 秩和检验和Spearman 相关性分析。首先针对输入模型的12 个财务指标做Wilcox 秩和检验,计算每个财务指标进行组间单变量分析,筛选出与企业债务违约具有显著差异(p<0.001)的指标组成子集进行Spearman 分析,得到其相关系数。从表6 可以发现,营业净利率、净利润与企业债务违约风险的相关系数均为负,说明净利润占营业收入的比例越高,净利润越高,公司盈利能力越强,债务违约风险就越小;现金比率越的相关系数也为负,说明公司的货币资金与有价证券占流动负债的比例越高,偿债能力越强,债务违约风险就越小;财务费用的相关系数为正,说明财务费用越高,筹集生产经营所需资金等而发生的费用就越高,企业的成本越高,债务违约风险就越大;资产负债率的相关系数为正,说明企业负债越高,要偿还的债务总额就越高,债务违约风险就越大。而不同的财务指标在不同的风险预测模型中的贡献程度也有所差异,例如:张宏斌和郭蒙(2020)发现商誉减值和长期债务负担是上市公司业绩暴雷的主要原因,并且认为公司债务总额、营业收入、盈利能力对于甄别上市公司是否业绩暴雷具有较好的辨别能力;还有研究表明,净利润、营业总收入变动、资产负债率等指标均可以构成上市公司财报舞弊的敏感指标(黄志刚等,2020)。

表6 财务指标的r 系数和P 值
此外,本文还计算了五个显著差异财务指标相对应的均值与标准差,结果如表7 所示。最后对具有显著性差异的指标画出其箱线图(图3),更直观地显示指标针对企业债务违约的差异性。

表7 财务指标的均值和标准差

图3 五个高度相关特征箱线图
九、结论与展望
(一)主要结论
(1)机器学习模型能够较好地预测企业债务违约风险。大部分模型的准确度在0.8 以上,说明机器学习模型针对债务违约都具有较好的预测效果。
(2)样本数量较少,直接建立模型容易造成过拟合现象。本研究针对小样本数据提出利用留一法对模型进行验证,得到更为准确的模型。其中支持向量机模型直接建模AUC 可达0.97,但经过留一法验证,其AUC 为0.742。而基于随机森林构建的模型相对较为稳定,且验证结果较好(AUC=0.868)。
(3)经过留一法对模型进行验证,得到基于随机森林所构建模型的预测效果最佳(AUC=0.868),基于逻辑回归的模型预测效果最差。
(4)最重要的五个预测变量是营业净利率、净利润、现金比率、财务费用和资产负债率。说明公司的债务违约风险与盈利能力、偿债能力、成本控制和债务规模息息相关,相应的财务指标对于甄别上市公司是否会发生债务违约具有良好的辨别能力。这不仅可以深化对企业债务违约风险影响因素的微观特征的认识,而且有助于监管部门对上市公司财务状况的监督更加有针对性。
(二)不足和展望
本文虽然取得了一些有益的研究结果,但本研究还具有一定的局限性。首先,2014 年以来上市公司实质性债券违约的样本较少,并且在经过筛选处理过后仅有43 个违约样本,故难以进行更为深入的统计分析,因此本研究受样本数量限制,未来需要进一步扩充样本量以充分验证所建模型的泛化能力;此外,受到数据可获得性的限制,目前的研究对于外部宏观因素如行业特征、市场波动、经济环境等变量尚未形成一致的衡量方式,故本研究仅采用上市公司披露的财务数据作为预测指标,未来有必要将上市公司所处的外部环境变量也纳入所建模型中进行进一步的验证。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
现代经济信息(2020年36期)2020-11-26
红土地(2018年7期)2018-09-26
电影(2018年8期)2018-09-21
消费导刊(2018年8期)2018-05-25
中国财政年鉴(2017年0期)2017-07-04
企业技术开发·中旬刊(2016年10期)2016-11-12
中国卫生(2016年4期)2016-11-12
中国卫生(2014年4期)2014-12-06
