
基于多尺度梅尔倒谱系数的转辙机声信号状态识别方法
2022-07-11 00:01姜琦冯庆胜
科学技术与工程 2022年16期
姜琦, 冯庆胜
(大连交通大学自动化与电气工程学院, 大连 116028)
铁路信号系统的构成十分复杂,需要众多软件和硬件基础设施共同工作来保障列车高效安全的运行[1]。一旦系统中的某个部分发生故障,就可能导致列车运行效率低下或重大事故的发生[2-3]。其中,转辙机因其具有移动和指示道岔位置,实现列车安全转向的功能,在铁路系统中被视为一种重要的信号基础设备。但由于转辙机长期处于室外工作,受到自然条件和列车冲击等外界因素影响较大,也使其成为了一种有较高故障发生率的铁路信号基础设备[4-5]。因此,能够准确地识别出转辙机的运行状态,对保证列车安全行驶具有重要的意义。
由于在故障发生时,转辙机的电流和功率动作曲线会发生相应的变化。因此以往对转辙机的故障判别主要是依赖相关技术人员对微机监测系统采集的电流曲线、功率曲线或二者结合,来进行人工分析。但这样的判别方式效率很低,且常会出现误判的情况。近年来,随着人工智能的发展,转辙机故障诊断方法逐渐结合了机器学习、深度学习等相关技术,从而在诊断效率和准确性方面都得到了相应的提升。Vileiniskis等[6]通过现场采集的转辙机电流数据,使用具有编辑距离与真实惩罚相似度度量的一类支持向量机分类算法,更快的区分出转辙机状态是否正常。王林洁[7]对转辙机不同状态下的功率数据进行采集,提取功率数据的时域和频域特征,采用简约算法对特征集降维后输入贝叶斯网络进行分类诊断。周鑫[8]对转辙机的电流与功率数据进行采集,应用生成对抗网络解决数据类型不平衡问题,最后将数据输入具有残差结构的循环神经网络进行分类诊断。可见,在转辙机故障诊断的研究中,其研究对象多基于电信号。但电信号存在采集较难,且在采集过程可能会对转辙机造成干扰等问题[9]。相比之下,声音信号因其在采集方面具有非接触,无干扰,易获得的优点,越来越多的成为具有电机、轴承等机械结构设备故障诊断的研究对象[10-12]。因此,对转辙机运动过程中产生的声音信号进行研究,也是转辙机故障诊断的新方向。
Lee等[13]采集了3种转辙机异常状态声音信号,对其提取梅尔倒谱系数(Mel frequency cepstrum coefficient, MFCC)特征,并结合支持向量机技术实现了转辙机故障诊断,证明了基于转辙机声音信号故障诊断的可行性。但MFCC特征是根据人耳听觉特性所设计,对声音信号的高频分量有抑制作用[14-15],因此不能全面表征转辙机声音信号的声学特性。Sun等[9]提取转辙机声音信号的时域和频域特征,构成13维特征向量,经二元粒子群优化算法进行特征降维,最后通过支持向量机进行分类。但该特征提取方式只考虑了转辙机声音信号整体变化的特性,缺乏了如MFCC算法中对信号短时特性的提取[16]。
为全面表征转辙机声音信号的特点,提出使用经验模态分解(empirical mode decomposition, EMD)获取声音信号的高频分量,并计算高频分量的时频特性,与MFCC及其一阶、二阶差分共同组成多尺度MFCC的特征提取方法。并利用卷积神经网络的结构构建基于声信号的转辙机状态识别模型。通过在S700K转辙机上模拟故障状态,采集真实的声音信号,用五折交叉验证法获取两种特征的识别准确率。此外,为验证多尺度MFCC特征对含有复杂环境噪声的转辙机声音信号的状态识别效果,将采集的声音信号加入不同信噪比的雨声,构建含噪数据集进行训练与识别。
1 MFCC特征提取与改进
1.1 声音信号预处理
将采集的声音信号在特征提取之前进行幅值标准化、分帧和加窗操作称为信号的预处理,整个预处理过程如图1所示。

图1 声音信号预处理
为便于后续的计算处理,首先将音频序列的幅值进行标准化,其函数表达式为
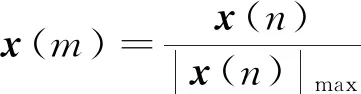
(1)
式(1)中:x(n)为声音序列;|x(n)|max为声音序列绝对值的最大值;x(m)为归一化后的声音序列。
经过幅值标准化处理之后,接着需要对序列进行分帧和加窗,这也是预处理中重要的环节。虽然转辙机声音信号是非平稳信号,但其在小段时间内仍具有短时平稳特性,因此可将声音序列分割成若干个很小的时间段,也称为一帧,从而得到信号的短时特征。一般将帧长取为20~30 ms[17],将帧移取帧长的0.3~0.5倍,让邻帧之间存在部分重叠,从而避免两帧差异过大,特征丢失。然后将分帧后的声音序列进行加窗处理,该操作可使帧的始末两端过渡更为平滑,一般选用汉明窗。
1.2 传统MFCC特征提取
在对人耳听觉机理的研究中发现,低频声音的行波相比高频声音行波在内耳蜗基底膜上传递的距离更大,这使人耳对低频声音更为敏感,对高频有掩蔽作用。传统的MFCC声音信号特征提取方法的关键就是构建一系列具有不同权重的带通滤波器组来模拟人耳对声音信号的调节作用[18],整个特征提取过程如图2所示。具体提取步骤如下。

FFT为快速傅里叶变换;DCT为离散余弦变换
步骤1设x(n)为转辙机声音信号预处理后获得的逐帧的时域表达,并利用快速傅里叶变换求得x(n)的频谱X(k),可表示为
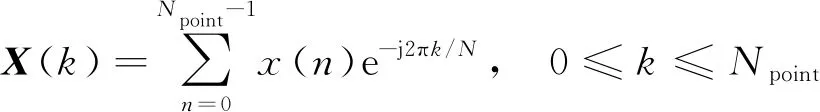
(2)
式(2)中:Npoint为傅里叶变换的点数;k为频率点。
步骤2将声音信号的频谱取模的平方,计算其能量谱,即|X(k)|2,再将其通过一组模仿人耳调节作用的三角形滤波器,使|X(k)|2进行Mel非线性变换,可表示为
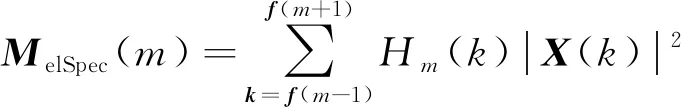
(3)
式(3)中:f(m)为三角滤波器中心频率。
第m个滤波器的频率响应可表示为
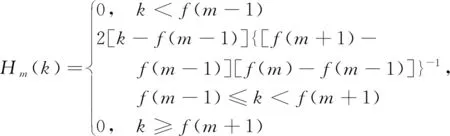
(4)
步骤3将一组滤波器得到的所有MelSpec(m)取对数,计算其对数能量E(m),计算公式为
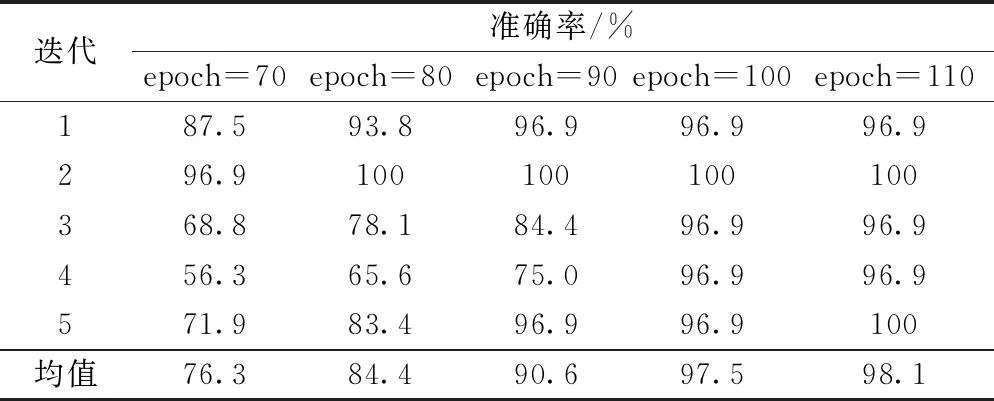
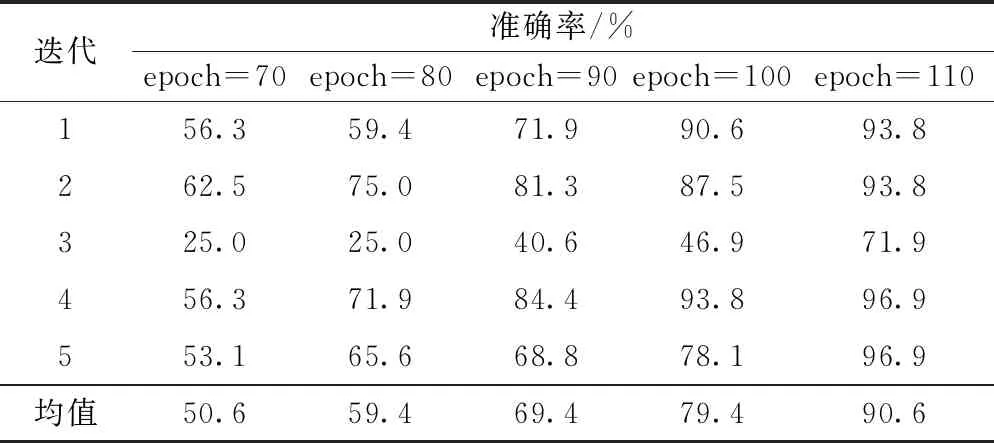
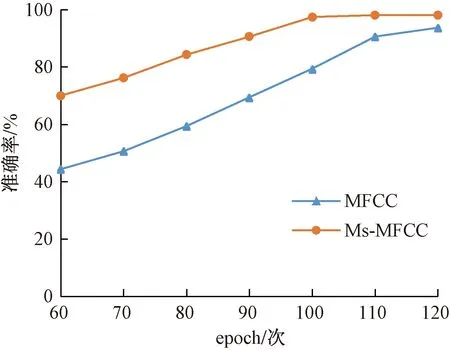
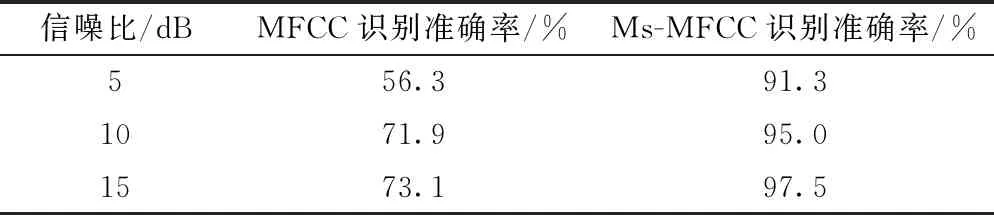
E(m)=lg[MelSpec(m)], 0 (5) 式(5)中:M为滤波器的个数。 步骤4最后将E(m)进行离散余弦变换(DCT),求出的一组向量F(n)即为梅尔倒谱系数,其表达式为 (6) 式(6)中:n为梅尔倒谱系数的阶数。 为了改善传统MFCC提取方法中因Mel滤波器组在高频区域数目较少且分布稀疏导致的转辙机声音信号在高频部分特征表征较差的问题,提出了多种尺度融合的MFCC特征提取方法。 EMD可使任意一个信号在任意时刻自适应地分解成许多本征模态函数(intrinsic mode function, IMF)[19]。由于这些IMF分量代表着原始信号中不同的频率分量,且分解的次序按照由高频到低频的方式排列。因此,首先将转辙机声音信号进行EMD分解获得IMF分量,之后取前5个IMF分量分别对其计算11个时域特征和2个频域特征,将计算出的数值构成代表转辙机声音信号高频部分特征一维向量。所用的时域和频域特征公式如表1所示。 表1 时域和频域特征 此外,为了得到更加丰富的信息,将MFCC系数做一阶差分与二阶差分得到组成MFCC的动态特征向量。差分计算公式为 (7) 式(7)中:dt和Ct分别为第t个一阶差分和倒谱系数;Q为倒谱系数的阶数;Ktd为一阶导数的时间差。 将计算出的MFCC特征向量,MFCC动态特征向量和时频域特征向量进行特征融合,形成了改进后的Ms-MFCC特征向量,该提取过程如图3所示。 图3 多尺度MFCC参数提取过程 所采集的声音信号来自在提速区段得到了大量使用的S700K型交流电动转辙机,其内部结构图如图4所示。 图4 S700K型转辙机内部结构 对转辙机的正常运行、道岔卡阻、启动断相和转换断相4种状态的声音信号进行采集,其中3种故障状态的模拟方式如表2所示。 表2 3种故障类型及模拟方式 使用华为手机作为音频采集设备,并将其放置在转辙机正上方10 cm处。共采集160个声音样本,每种状态(包括一种正常运行状态和3种故障状态)采集40个声音样本,每个声音样本长度为 5~7 s,采样频率为48 kHz。每种状态下的声音信号时域波形与频域变换如图5所示。 图5 4种转辙机状态声音信号的波形图和频谱图 由图5可知,S700K转辙机4种状态下声音信号时域波形、持续时间等都有明显的变化。而通过频域图可知,4种状态声音信号的频率范围都为0~240 000 Hz,在10 000~15 000 Hz的高频段内也都具有较高能量。 卷积神经网络(convolutional neural network,CNN)[20]是一种具有多层结构的神经网络,由于CNN的层间采用局部连接且权值相互共享,使其可提取输入值的局部特征,还具有参数量较小,模型复杂度低的特点。CNN可输入不同维度的特征,既可以是一维的声音序列,也可以是二维的频谱图,被广泛应用于声音识别领域。构建了一个包含9层结构的CNN识别模型,其详细构架如图6所示。 图6 CNN识别模型详细构架 (1)输入层:将采集的音频样本重采样为22.05 kHz,并将样本随机剪裁出66 150个采样点进行特征提取,取20个Mel滤波器,得到大小为61×65的多尺度MFCC特征,将该特征作为卷积层的输入。 (2)卷积层:将图6中包含的3个卷积层的卷积核数量从左至右分别设为64、128和256。令卷积核大小和步长统一设为3×3和1×1。在每一个卷积层后对输出数据进行批归一化处理,提高训练速度。由于声音信号包含负值,因此选用可以保留负值的Leaky ReLU激活函数对数据进行激活。 (3)池化层:将图6中包含的3个池化层的池化核大小和移动步长都设为2×2。令池化层的池化方式设为更有效的最大值法。 (4)全连接层:令图6中的全连接层具有256个神经元,并选用Leaky ReLU激活函数。此外,该在层前采用全局平均池化,层后再添加概率系数为p的Dropout函数。 (5)输出层:该层也可视作输出为4类的全连接层,并使用归一化指数(softmax)激活函数计算样本对应4个类别的概率,从而进行分类。 首先将转辙机声音信号进行分帧预处理时的帧长设为30 ms,帧移设为15 ms,并选用汉明窗实现帧间的平滑处理。在提取特征时,为保证所得的两种特征向量维度大小相同,将MFCC的滤波器个数设置为61,Ms-MFCC的滤波器个数设置为20。在实验中,选用交叉熵来计算损失值。设置概率系数为0.5的Dropout函数。每次迭代使用批量大小为32的数据。选用初始学习速率为0.01的随机梯度下降法(SGD)优化器来更新参数,并将学习率衰减策略设置为每20个epoch衰减一次,衰减后变为原来学习率的0.1倍,具体衰减过程如图7所示。 图7 学习衰减策略 此外,考虑到所采集的转辙机音频数据集的数据量较少,随意分化训练集与测试集可能导致样本分布不均衡,无法获得准确的训练结果,因此选择五折交叉验证法对模型进行训练,该方法可将数据集分成平均分成互斥的5份。每次的迭代训练轮流提取4份做训练集,剩下的作为测试集。其中,将10%的训练集数据划分为验证集。详细的五折交叉验证数据划分与提取过程如图8所示。 Ei为准确率,i=1,2,…,5; Train为训练集;Fold为折数;Val 为验证集;Iteration为迭代次数;Test为测试集 (8) 式(8)中:Ei为第i折数据得到的训练准确率。 将实验数据集提取的Ms-MFCC和MFCC两种特征经过相同结构与参数的CNN模型进行训练。两种特征在不同的epoch次数下所得的五折交叉验证结果分别如表3、表4所示。 对比表3和表4可知,在相同的epoch次数下,Ms-MFCC特征的准确率均值总高于相对应的传统MFCC特征的准确率均值。并且对于5种数据集的划分方式,每次测试所得的准确率都是Ms-MFCC特征表现更好。其中,Ms-MFCC特征在epoch为90次时的识别准确率便可达到MFCC特征在epoch为110次时的效果,这表明多尺度MFCC特征更加全面的表征了转辙机声音信号的声学特性,使模型可经历更少次数的迭代来达到较高的识别准确率。 表3 Ms-MFCC五折交叉验证准确率 表4 MFCC五折交叉验证准确率 为了更直观的显示两种特征识别准确率的变化趋势,扩大epoch训练范围,记录对应的准确率均值,得到两种特征在相同迭代次数下的准确率变化曲线如图9所示。 由图9可知,在epoch由60次增加至120次的过程中,两种特征的识别准确率都不断提高。但在epoch由110增加到120时,Ms-MFCC的特征的识别准确率不再发生变化,达到最优的98.1%。而MFCC特征的识别准确率继续增加至93.75%,但其折线斜率降低,因此,传统MFCC需要更多次迭代才能收敛到最优解。 图9 两种特征的准确率均值变化曲线 由于转辙机工作在室外,会面临不同的天气状况,拥有复杂的环境噪声。因此,为了验证在复杂天气状况出现时MFCC与Ms-MFCC两种特征的状态识别准确率,将公共ESC-10声音数据集中的雨声[21]选作为环境噪声,与转辙机声音信号按照信噪比为5、10、15 dB的比例相加,构建出三个含有不同信噪比的声音数据集。当epoch=110时,两种特征对含噪数据集的识别效果如表5所示。 表5 不同信噪比的识别准确率 由表5可知,虽然在加入噪声之后Ms-MFCC特征的状态识别准确率有明显的下降,但其准确率依然可保持90%以上,识别效果远好于传统MFCC,尤其在低信噪比时效果更为显著。 在采用S700K型转辙机上模拟故障得到的声音信号通过所提出的Ms-MFCC特征状态识别方法实验后,得出以下结论。 (1)提取声音信号的MFCC特征并构建卷积神经识别网络可对S700K型转辙机进行状态识别,经过五折交叉验证的识别准确率能够达到90.6%,满足转辙机状态识别对准确率的需求。 (2)改进后的Ms-MFCC特征对转辙机声音信号的声学特性有更好的表征。经实验证明,使用Ms-MFCC特征向量将识别模型的准确率提高至98.1%。 (3)Ms-MFCC特征相较传统MFCC特征可使模型更快达到较高的识别准确率。在同样达到90.6%的准确率的情况下,Ms-MFCC特征可使模型减少80次迭代训练。 (4)当声音信号含有复杂环境噪声时,所提出的Ms-MFCC特征具有更强的鲁棒性。经实验证明,在低信噪比时,Ms-MFCC识别效果相比传统MFCC,其准确率提升了35%。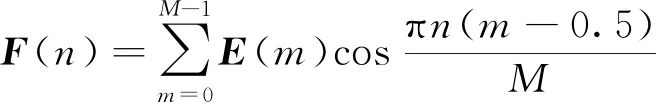
1.3 多尺度MFCC特征提取

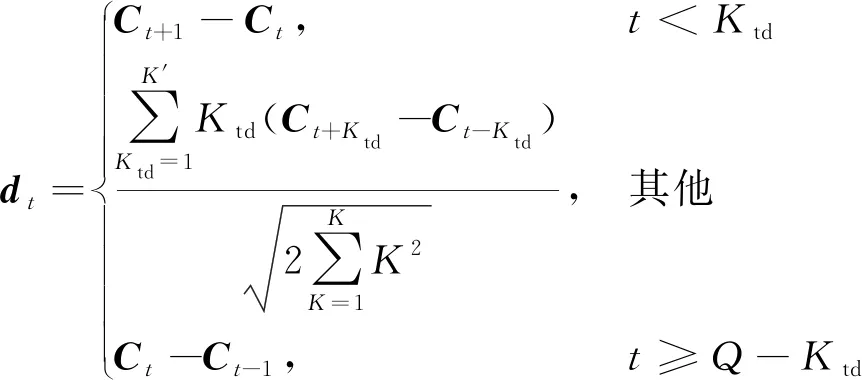
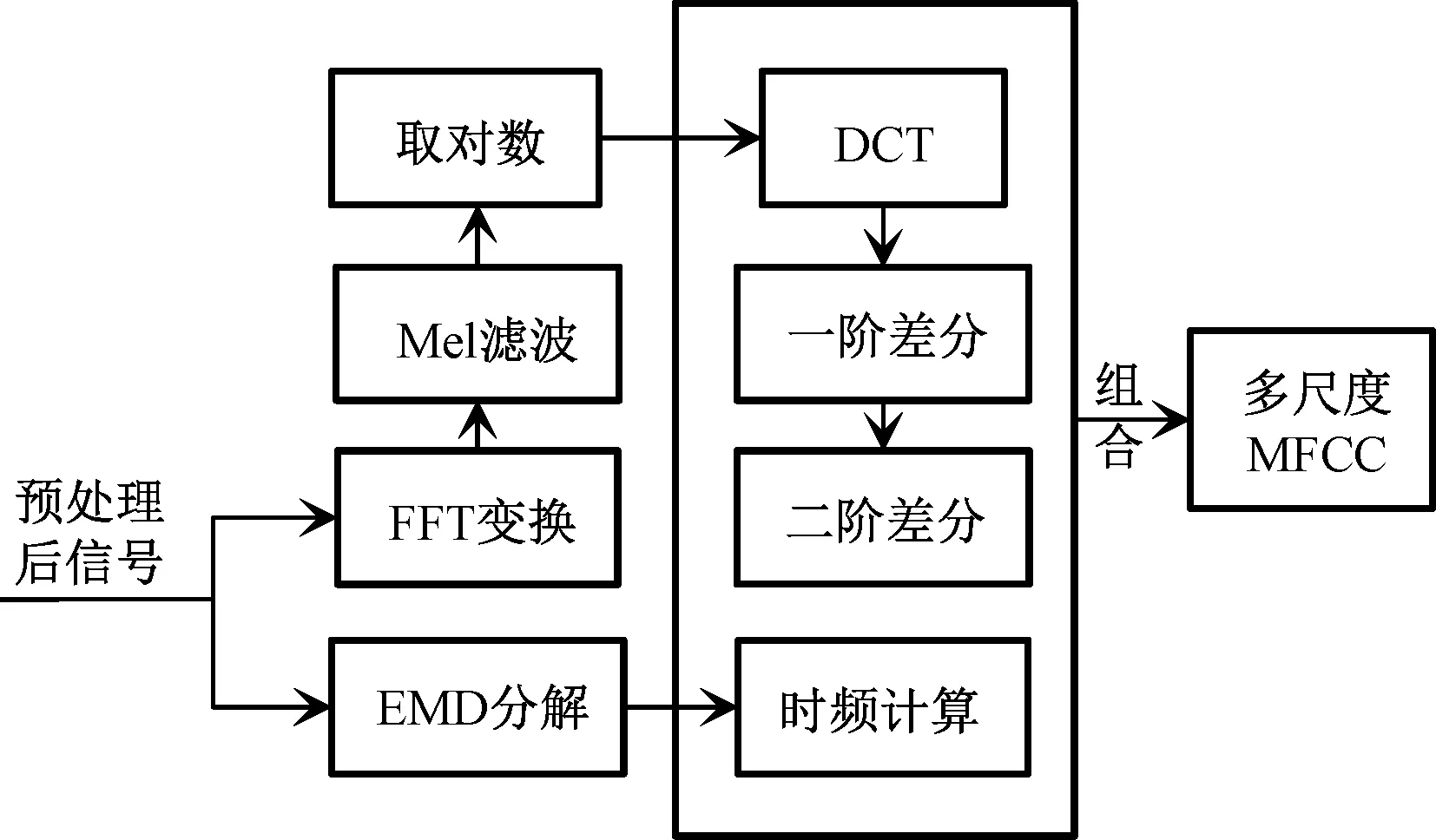
2 数据采集与模型构建
2.1 转辙机声音信号采集


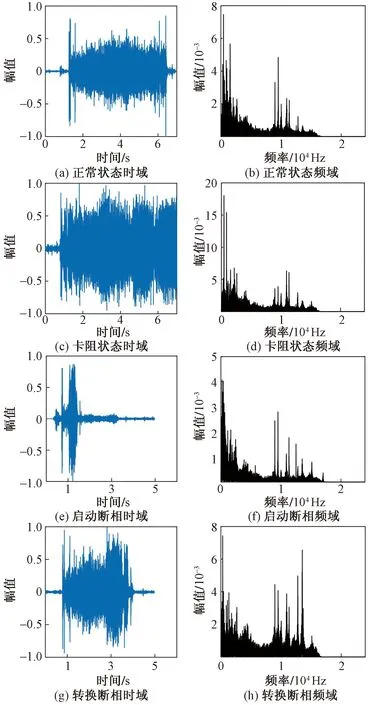
2.2 基于CNN的转辙机状态识别网络
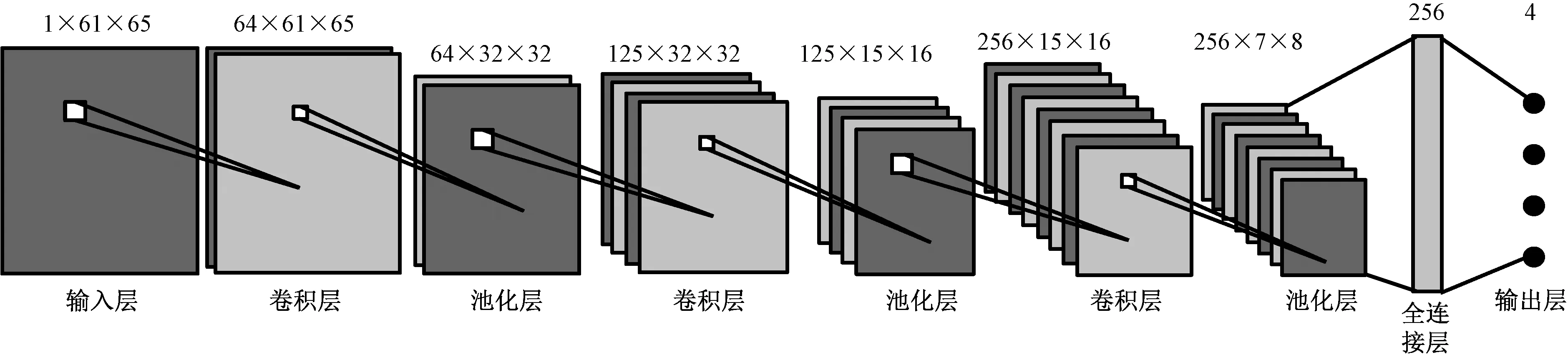
3 实验结果与分析
3.1 实验设置
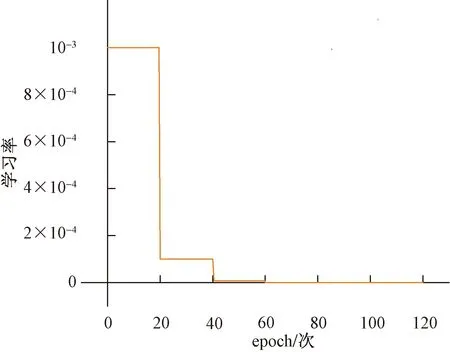
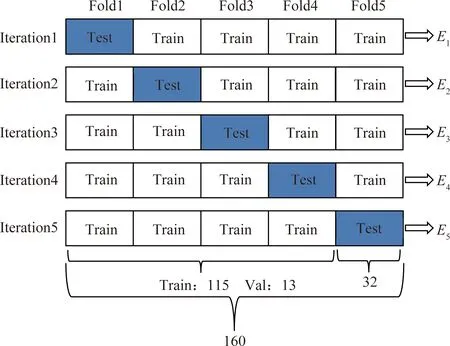
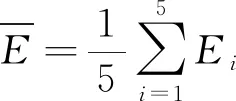
3.2 实验结果
3.3 不同信噪比的精度验证
4 结论
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
铁道通信信号(2020年3期)2020-09-21
铁道通信信号(2020年1期)2020-09-21
铁道通信信号(2020年8期)2020-02-06
电子制作(2019年15期)2019-08-27
数学大世界(2019年7期)2019-05-28
铁道通信信号(2018年10期)2018-12-06
电子制作(2018年19期)2018-11-14
中华建设(2017年1期)2017-06-07
