
基于B-CNN模型的异构网络大数据知识扩充算法研究
2022-07-10 10:00张伟华王海英
兵器装备工程学报 2022年6期
张伟华,王海英
(郑州商学院 信息与机电工程学院, 河南 巩义 451200)
1 引言
异构网络大数据存在多元性与分布式传播等特性,因此降低质量较差数据干扰属于数据知识工程急需解决的问题,对数据传播时的数据知识库重建关注度越来越高。数据知识扩充数据解决该问题的有效途径。李直旭等人通过属性与属性值的共现关系实现数据知识扩充,应坚超等人以集合论内互逆/对称关系为核心思想,提出关系统计的知识扩展方法,上述2种方法均可有效实现知识扩充,但扩充效果并不理想,原因是这2种方法无法剔除无效数据,导致扩充效率较低。双线性卷积神经网络(bilinear convolution neural networks,B-CNN)通过两路VGGNet组建而成,可增强特征表达效果,完成端到端训练的预测分类,具备较优的分类效果;为此研究基于B-CNN模型的异构网络大数据知识扩充算法,利用B-CNN模型提取有效三元组,剔除无效数据,降低质量低下数据的干扰,提升知识扩充效果。
在B-CNN各个特征通道内引进比例因子,结合正则化激活方式构建稀疏层,实现通道筛选,根据比例因子的大小衡量特征通道的重要性,裁剪掉重要程度较低的通道,实现B-CNN模型的改进,避免网络过分拟合,增强提取特征的显著性;利用改进B-CNN构建异构网络大数据知识表示模型,在三元组矩阵内,通过维度变换方式增加卷积滑动窗口的滑动步数,在不同维度中,提高该矩阵中实体与关系的信息共享作用,获取不同维度中三元组的全部信息=(,,),其中,异构网络大数据实体集是,知识描绘对象是,内全部元素的知识属性集是;利用可变粒度策略处理(,,),实现异构网络大数据知识扩充。
2.1 基于B-CNN的异构网络大数据知识表示模型
..BCNN模型
B-CNN的输入是,利用2个特征提取网络与,依据卷积核展开卷积操作获取特征提取函数与,利用外积方式汇聚与,再通过求和池化获取双线性特征,传输至内积层展开预测。与内各个卷积层均会设置Relu激活函数,公式如下:
()=max(0,)
(1)
B-CNN的主要部分通过三元组=(,,)组成,与属于一种函数映射∶×→×,输入的的位置信息是,维度是×;池化函数是;将与映射为×维的特征×,经由外积方式汇聚与的输出特征,获取双线性特征,公式如下:
(,,,)=(,)(,)
(2)
其中,∈,∈。
的作用为将全部位置的特征融合为一个总特征,公式如下:
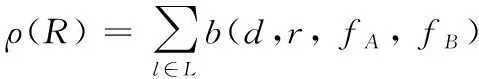
(3)
令与提取的特征维度分别是×与×,因此输出的矩阵为×。


(4)

通过引进稀疏惩罚项,调整的稀疏程度,引进位置为训练目标函数,的表达公式如下:
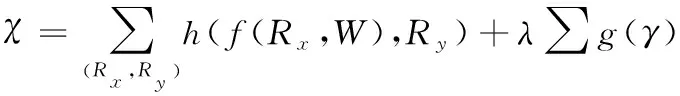
(5)
其中,训练权重是;输入数据实体集与真实标签是(,);调整稀疏程度的参数是;正则化操作是(·);交叉熵损失函数是,表达公式如下:

(6)
其中,的精度值是();的预测值是()。
通道稀疏处理后,改进B-CNN网络内存在很多与零接近的,裁剪掉这些完成通道的修剪,在修剪时设置一个阈值,避免出现过拟合现象;改进B-CNN整体是有向非循环图,仅需求解特征提取网络梯度便能实现网络训练。
利用改进B-CNN构建异构网络大数据知识表示模型,该模型的作用是利用改进B-CNN学习、训练并输出各个三元组(,,)的科学性的打分函数′(,,),科学的(,,)知识得分不得低于不科学的(,,)知识得分。令改进B-CNN构成的有向非循环知识图谱为=(,),关系集是;知识表示模型将与描绘为维向量空间内的向量,各个三元组下向量为(,,),将(,,)融合为一个三列矩阵=[,,]∈×3,利用知识表示模型以维度变换方式变更,获取=×,其中×=×3,知识表示模型将输入改进B-CNN的与网络内卷积层,利用卷积操作,再经由外积方式与求和池化操作,提取(,,)的双线性特征。令的集合是,的数量是=||,令获取的特征矩阵维度是×。利用知识表示模型向量化处理×,获取向量∈×1。乘上权重矩阵×,并映射至维向量空间内,再和权重向量∈×1内积获取(,,)的打分。知识表示模型的′(,,)表达公式如下:
′(,,)=((*))×·
(7)
其中,卷积操作是“*”;内积操作是“·”;向量化操作是;非线性函数是;通过式(7)获取有效三元组。
Adam优化器最小化损失函数,实现知识表示模型内参数的训练,的计算公式如下:
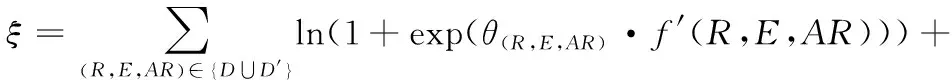
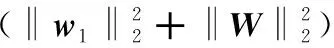
(8)
其中,(,,)是常数,取值为1或-1;有效与无效三元组集合为、′,当(,,)∈时,(,,)=1,当(,,)∈′时,(,,)=-1;利用内各个(,,)的头实体或尾实体任意更改成其余实体获取′。
2.2 可变粒度的知识扩充算法
利用可变粒度策略对21小节获取的有效三元组=(,,)展开知识扩充。令∀∈,∀∈,线性关系属性映射为:→,内随机一个元素的知识属性映射关系为。令粗糙权重是;多粒度粗糙知识工程为;则粗糙的知识工程是=(,∩(),∪)。

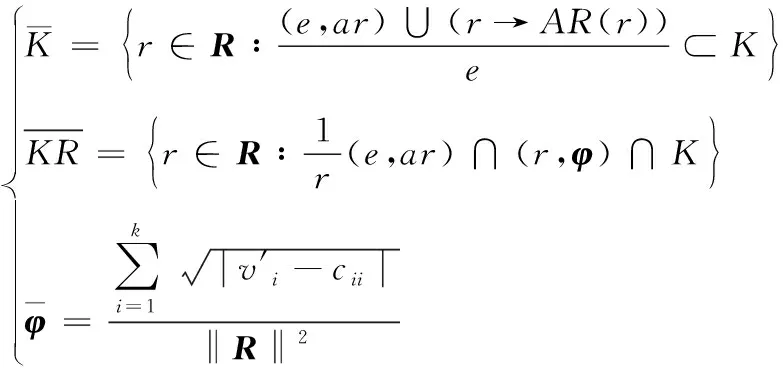
(9)
针对,基于可变粒度设计知识的参数与属性,表达公式如下:

(10)
可变粒度更换方程如下:
=(×sin+×cos)(,,)
(11)
其中,可变粒度是;的多维向量空间水平交叉弧度是;在空间降维时形成的垂直交叉弧度是。
和知识工程的迭代关系如下:

(12)


(13)
3 实验分析
为验证本文算法的有效性,通过15台计算机构建一个实验集群,每台计算机的内存是16 GB,硬盘存储空间是2 T。异构网络数据知识库空间配置如下:
利用nginx安装1个中心节点与14个处理节点,通过处理节点完成差异化服务,该数据知识空间属于内部局域网,通过Oracle Load Test软件仿真大量并发请求,将JetBrains WenStorm/VS Code当成开发环境,操作系统是CentOS 7.3,各节点的联络方式是千兆以太网,令数据知识发送请求的时间是70 s。建立两路VGGNet,通过维度变换增加进行卷积操作提取特征函数进行计算,获取不同维度中三元组矩阵的信息,经由求和池化操作,实现B-CNN模型的应用。图1为B-CNN模型网络结构示意图。

图1 B-CNN模型网络结构示意图Fig.1 B-CNN Model network structure
将平均排名(Mean Rank,MR)与前8名存在预测准确三元组的比例(Hits@8)作为评价本文算法中知识表示模型有效性的指标,MR指三元组集合的平均排名;MR低或Hits@8高说明本文算法的知识表示效果较优。调整稀疏程度参数过大或过小均会影响知识表示模型的效果,当过大时,会导致大量知识特征被抑制,造成获取有效三元组的精度较低;当过小时,会导致比例因子失去意义,无法筛选特征通道;一般情况下的取值为10≤≤10;利用本文算法获取异构网络数据库内的有效三元组,完成数据知识表示,测试本文算法在不同的取值时的MR与Hits@8,测试结果如图2与图3所示。

图2 MR测试结果曲线Fig.2 Mr test results

图3 Hits@8测试结果曲线Fig.3 Hits@8 test result
根据图2与图3可知,随着训练周期的不断增加,在不同取值时本文算法的MR逐渐下降,Hits@8逐渐提升;当=10时,MR的收敛速度最快,在训练周期为20时趋于平稳,最终的MR值也显著低于其余2种取值;=10时的收敛速度虽快于=10,在训练周期为30时趋于平稳,但最终MR值却高于=10时的MR值;当λ=10时,Hits@8的收敛速度依旧最快,在训练周期为20时趋于平稳;=10与=10时的收敛速度较慢,分别在训练周期为40、50时趋于平稳,且最终Hits@8值显著低于=10时最终Hits@8值;综合分析可知,当=10时,MR值最低且Hits@8值最高,因此,此时本文算法的知识表示效果较优。

表1 NMI与ARI测试结果曲线Table 1 NMI and Ari test results
根据表1可知,在不同数据集中,本文算法的NMI与ARI随着细粒度阈值提升出现先提升后下降的趋势,且在扩充不同数据集时,本文算法的NMI值与ARI值均较高,与1较为接近,说明本文算法具备较优的知识扩充效果;综合分析细粒度阈值为0.4时,本文算法在扩充不同数据集知识时的NMI与ARI值最高。实验证明:本文算法具备较优的知识扩充效果,且细粒度阈值为0.4时,知识扩充效果最佳。
测试本文算法在扩充上述3个数据集知识时,随着处理节点增加,该算法完成知识扩充所需的迭代次数,验证本文算法的收敛效果,测试结果如图4所示。
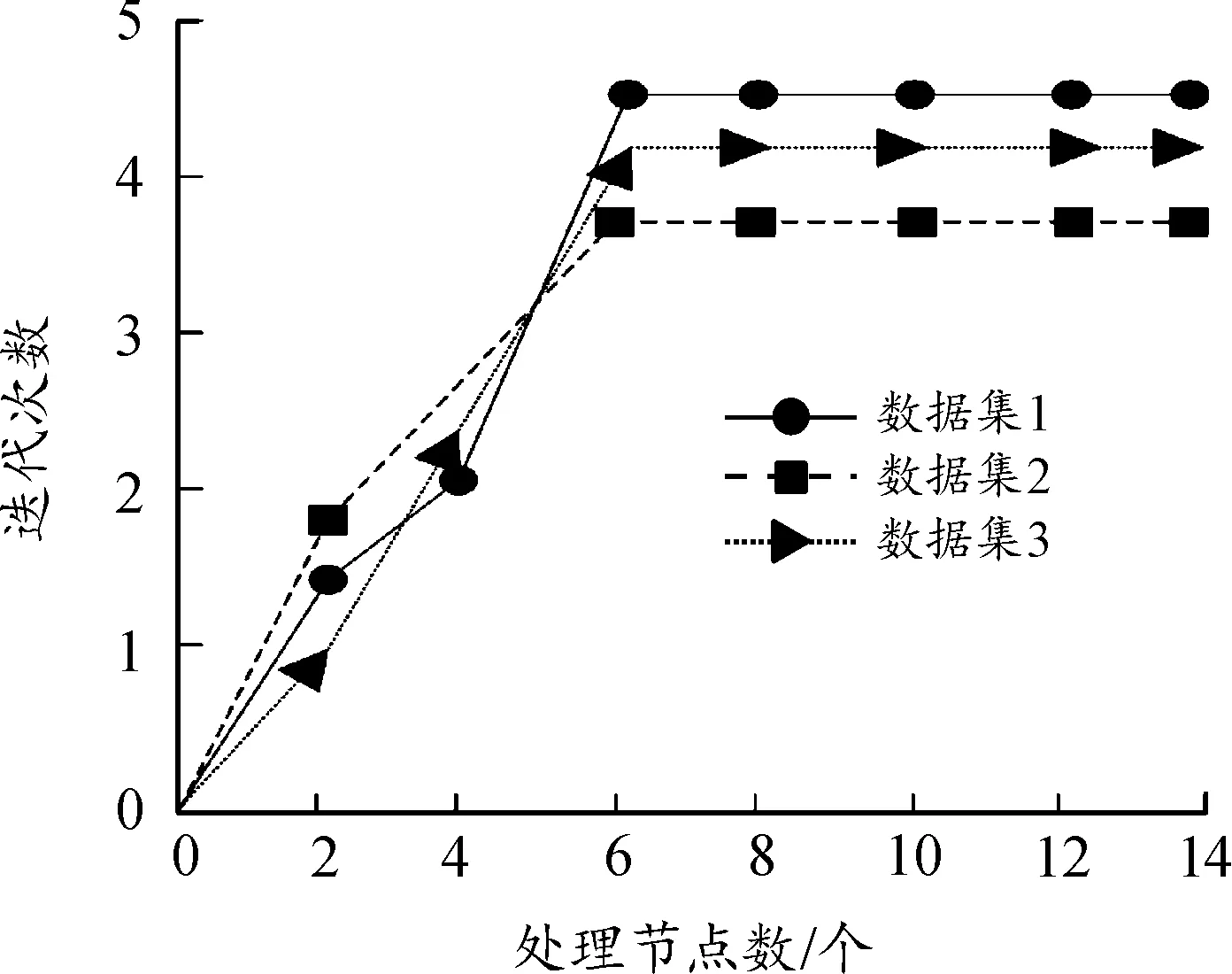
图4 收敛效果Fig.4 Convergence effect
根据图4可知,在扩充不同数据集的知识时,随着处理节点数量的提升,本文算法的迭代次数逐渐上升,在节点数达到6个以上的时候,迭代基本维持在5次以下,并且不再有上升趋势,原因是本文算法通过粒度可变调度处理粗粒度数据,并展开降维处理,确定不确定性的线性描绘,去掉不确定性的数据,降低知识获取迭代次数,提升知识获取效率,迅速完成数据知识扩充。
4 结论
1) 利用B-CNN构建知识表示模型,获取异构网络大数据的有效三元组,通过可变粒度策略对有效三元组展开知识扩充。
2) 所提出算法可增强知识扩充效果,提升知识获取效率。
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年2期)2022-07-04
小学教学研究(2022年5期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
福建基础教育研究(2019年11期)2019-05-28
新作文·高中版(2017年6期)2017-07-06
科技与企业(2015年12期)2015-10-21
