
面向代码演化的集成软件缺陷预测模型
2022-07-09 11:12高添,郭曦
武汉大学学报(理学版) 2022年3期
高 添,郭 曦
华中农业大学信息学院,湖北武汉430070
0 引言
软件在开发过程中处于动态演化状态,对其维护困难且代价较大,因此尽可能准确地预测软件存在的缺陷一直是软件研究人员和开发者的研究热点之一。软件缺陷预测过程一般由4部分组成[1]:收集软件缺陷数据、提取度量元、构建软件缺陷预测模型的方法和性能评价。在度量元设计方面,王丹丹等[2]提出用两种演化度量元来度量已有类的演化,验证了演化度量元对缺陷预测性能的改进。于巧[3]从代码包的缺陷率和类的变更程度两方面提出了两个演化度量元,并分析了代码度量元和演化度量元与类别的相关性,结果表明演化度量元与类别的相关性更高。在软件缺陷预测模型的构建方面,经典的方法主要有:贝叶斯[4]、决策树[5]、逻辑回归[6]、支持向量机[7]、神经网络[8~10]等方法。原子等[11]以代码(语句级)变更作为预测粒度,采用特征熵差值矩阵分析了软件演化过程中概念漂移问题的特点,提出一种伴随概念回顾的动态窗口学习机制来实现长时间的稳定预测。机器学习方法遵循误差最小化原则,当训练数据不平衡时,其分类会偏向多数类,导致模型的分类性能较差[12],不能有效发挥所加入的演化度量元的性能。
针对以上问题,本文用集成学习的方法进行软件缺陷预测研究[13~17],构建了一种面向代码演化的集成软件缺陷预测模型,在代码演化的预测技术上加入集成学习方法,将机器学习模型形成的弱分类器进行Adaboost集成,通过各种模型迭代产生强分类器,从而提高缺陷预测模型的性能。
1 基本概念及模型
1.1 代码度量元
软件缺陷数据度量元是与缺陷外在表现有关系的内在属性(比如复杂度、耦合、继承等)[1]。现有的度量主要基于代码度量元(code metrics,CM),有代码行数、McCabe环路复杂度、Halstead科学度量以及CK度量元等。其中,CK度量元是面向对象程序设计的度量元,主要从继承、耦合、内聚等角度描述程序的复杂性。由于近年来面向对象程序设计成为开发的主流,不同数据集包含的特征属于类级别,因此本文选择CK度量元作为预测的属性(表1)。
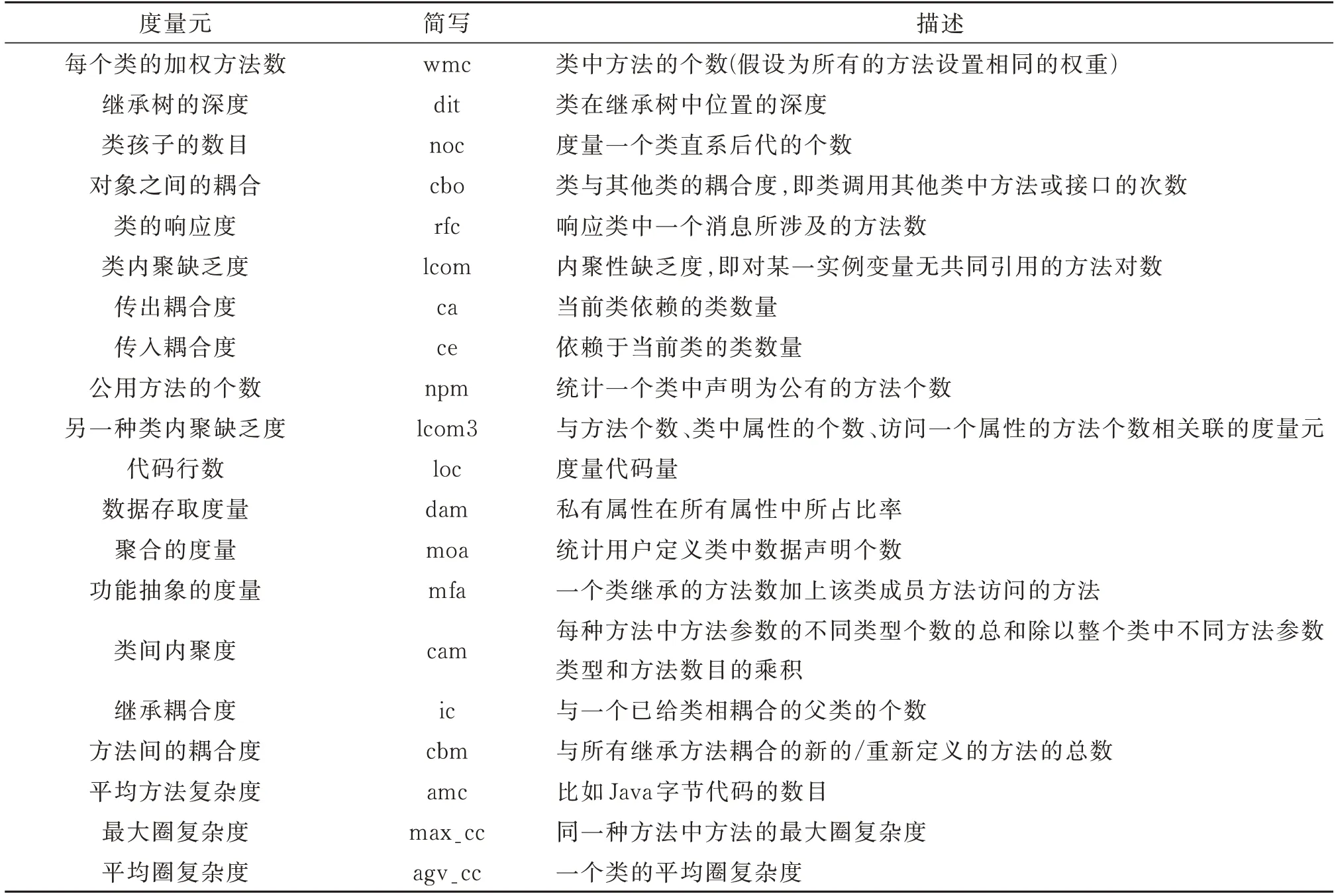
表1 CK度量元Table 1 CK metrics
1.2 演化度量元
演化度量元(evolution metrics,EM)是用来刻画软件演化过程的度量元,包括不同版本中类的变化以及代码变更度量元等。
本文使用类存在缺陷的概率(probability of defective classes,pdc)和发生变化的代码度量元比例(percentage of changed code metrics,pccm)两个演化度量元[3]进行缺陷预测。pdc定义如下
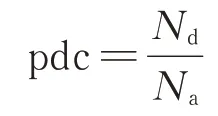
其中,Nd为某个代码版本中缺陷类的个数,Na为该代码版本中所有类的个数。
pccm定义如下
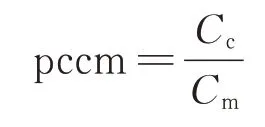
其中,Cc表示与前一个版本相比,当前版本的每个类中发生变化的代码度量元;Cm为该版本每个类中所有代码度量元。演化信息能直观地反映软件在不同版本的演化程度。因此,将代码度量元与演化度量元进行结合分析,能有效提高软件预测模型的性能。
1.3 预测方法与模型
选择使用哪些版本的缺陷数据进行预测是面向代码演化的缺陷预测技术的重点。常见的方法包括使用所有的历史版本的缺陷数据来预测下一个版本的缺陷(即{V1,V2,…,Vn-1}→Vn)和使用前一个版本的缺陷数据来预测下一个版本的缺陷(即Vn-1→Vn)。王丹丹等[2]与Ekanayake等[18]发现使用时间邻近的实例比时间相距较远的实例具有更好的预测性能。于巧[3]使用至少3个版本的数据,依次提取相邻两个版本的共同类与演化度量元从而得到训练集与测试集。然而该方法对相邻版本的缺陷率稳定程度较为依赖,当相邻版本缺陷率相对稳定时,加入的演化度量元具有较好的预测性能,否则预测性能不如代码度量元。基于以上研究,本文使用前一个版本的缺陷数据来预测下一个版本的缺陷(即Vn-1→Vn)。
朴素贝叶斯(NB)、决策树(J48)、逻辑回归(LR)是最常用的缺陷预测方法。相关研究[19]表明逻辑回归与朴素贝叶斯模型是缺陷预测中使用最广泛的两种对比标准。Seliya等人[20]发现J48决策树方法在缺陷预测中有较好的性能。随着神经网络的发展,复杂的网络模型逐渐应用在缺陷预测方面,由于其具有自学习与自适应性等特点,虽然预测花费的时间较长,但在各项评价指标上均能达到较高水平。基于以上研究,本文选择的弱分类器是决策树(J48)、逻辑回归(LR)、神经网络(NN)、朴素贝叶斯(NB)。
2 本文方法
本文构建了一种面向代码演化的集成软件缺陷预测模型,在代码演化的预测技术上加入集成学习方法,基本框架如图1所示。首先对不同版本代码进行预处理,即选择合适的代码度量元和演化度量元,提取公共类以及数据采样等。然后使用集成方法迭代增强前一个分类误差率较小的弱分类器的权重,减小分类误差率较大的弱分类器的权重,再将加权后的样本重新训练,当误差达到设定的阈值时结束训练,将不同分类器按照各自的权重集成得到最终分类器。
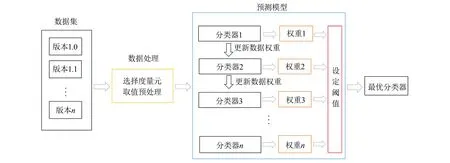
图1 本文基本框架Fig.1 Basic framework of this paper
2.1 集成方法
常见的集成学习方法包括Bagging,Boosting,Stacking等。Bagging是并行式的集成学习方法,主要思想为使用有放回重采样法,采样出T个含有n个训练集的采样集后,基于每个采样集训练出弱分类器,通过不同的结合策略获得强学习器。其主要优点是易于并行计算,降低弱分类器方差,改善泛化误差,但比较依赖弱分类器的稳定性。Boosting是串行集成的方法,它是一个迭代的过程,用于自适应地改变训练样本的分布,使得弱分类器更关注易错分的样本。其主要优点是学习速率快,而且能够有效地利用弱学习器来构建强学习器。Stacking是一种融合各类模型的方法,主要使用基础模型进行完整的数据集训练,然后使用元模型基于基础模型的输出进行训练,能融合多个模型的优点来提升集成模型的性能。Boosting比Bagging更激进,更容易受噪声影响过拟合,不易并行,Stacking多用于最终综合多个性能较好的模型,最易于过拟合。通常情况下,Boosting和Bagging考虑同质弱分类器,而Stacking考虑的是异质弱分类器。
本文采用Boosting中的Adaboost方法,对不同机器学习模型各自进行迭代,不停地调整权重让其更关注上一轮的错分元组。主要过程是以m个分类器为核心,学习获取一个错误分类误差最小的分类器ft(x)以及其组合权重αt,综合T次Adaboost过程,遵循权重值集成所得到最终分类器,实现缺陷预测。
2.2 预测模型目标函数
本文中预测模型训练后最终得到一个分类器,对未来版本的代码进行缺陷预测,其目标函数
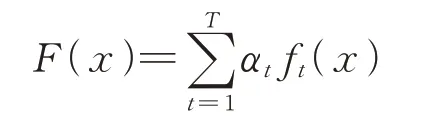
其中,T为Adaboost过程的次数,ft(x)是第t次Adaboost过程得到的弱分类器,αt是与弱分类器ft(x)对应的权重值。最终经过T次Adaboost后,最后得到基于T个弱分类器按照各自的权重集成的分类器。
2.3 训练弱分类器及权重
集成学习方法的核心是训练弱分类器,即T次Adaboost。训练阶段采用多核集成方法[21],即为每个单核函数训练得到一个单核分类器,由m个核函数得到m个单核分类器,然后根据分类效果从中选出性能最好的作为本次Adaboost过程的弱分类器。其中可以根据m个分类器的未正确分类的误差率ρt来进行比较和选择。记为第j个(1≤j≤m)核函数的分类器,则其误差率定义如下:
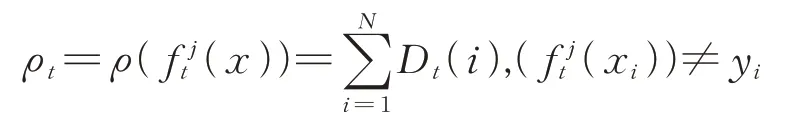
其中,Dt为训练样本集的权重向量,yi为软件模块的标记信息,分类误差越小表明分类器分类效果越好,从中选择分类误差率最小的作为第t次Adaboost过程的弱分类器。弱分类器ft(x)的权重αt与未正确分类误差率ρt关系为:
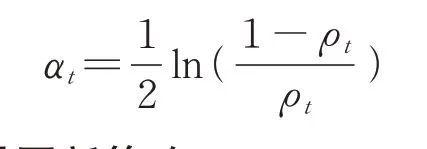
2.4 权重向量更新策略
在上一节得到了第t次Adaboost过程完成后的弱分类器ft(x)及它的权重值αt,在进行t+1次Adaboost过程之前,需要更新训练集的权重向量Dt+1,目的是更多地关注有缺陷样本。在更新训练样本集的权重向量时,可以采用如下策略:
如果训练样本为有缺陷样本,即yi=1,则
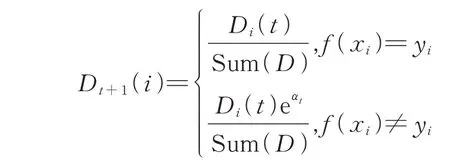
如果训练样本为无缺陷样本,即yi=-1,则
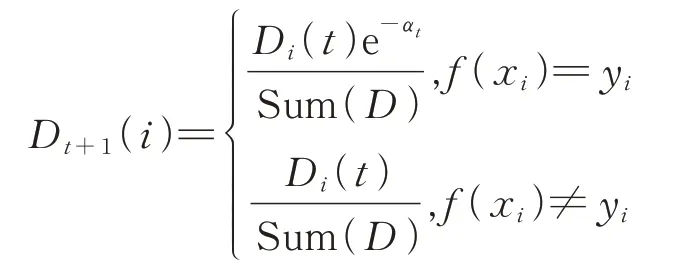
上述策略综合了模块有无缺陷属性和第t次Adaboost过程的分类结果。正确或者错误分类有缺陷样本时,权重分别是不变或增加,这样使下一次Adaboost过程中关注有缺陷样本,尤其是上一次分类中错误的元组。正确或者错误分类无缺陷样本时,权重分别是减少或不变,为了减少正确分类无缺陷样本的权重,从而更关注有缺陷样本的分类情况,降低误报率。
3 实验及结果分析
本文旨在通过实验回答以下3个问题:
问题1:不同机器学习模型集成前后的预测性能如何?
问题2:演化度量元对预测性能的影响如何?
问题3:不同集成方法对预测性能的影响如何?
针对以上问题,本节将在PROMISE上对不同机器学习的集成模型预测性能进行验证。本文选择了4种常用的分类预测模型决策树(J48)、逻辑回归(LR)、神经网络(NN)、朴素贝叶斯(NB)进行实验。不同机器学习模型在不同数据集以及集成方法上表现差异较大,因此本文选择的模型与集成方法在其他数据集不一定是最好的。本文侧重点在于针对演化项目的预测技术进行集成后的改进,其中选择的预测模型与演化度量元是为了验证集成后的性能,期望找到更优的集成方法。
3.1 实验数据
为验证本文构建模型的有效性,选取PROMISE软件数据集中的5种,均为缺陷预测中常用的开源数据集,基本信息如表2所示。其中每个项目至少包含3个版本和20个代码特征和标注,均使用Java语言开发,其缺陷预测的粒度为类,缺陷率为缺陷模块数占所有模块数的比率。
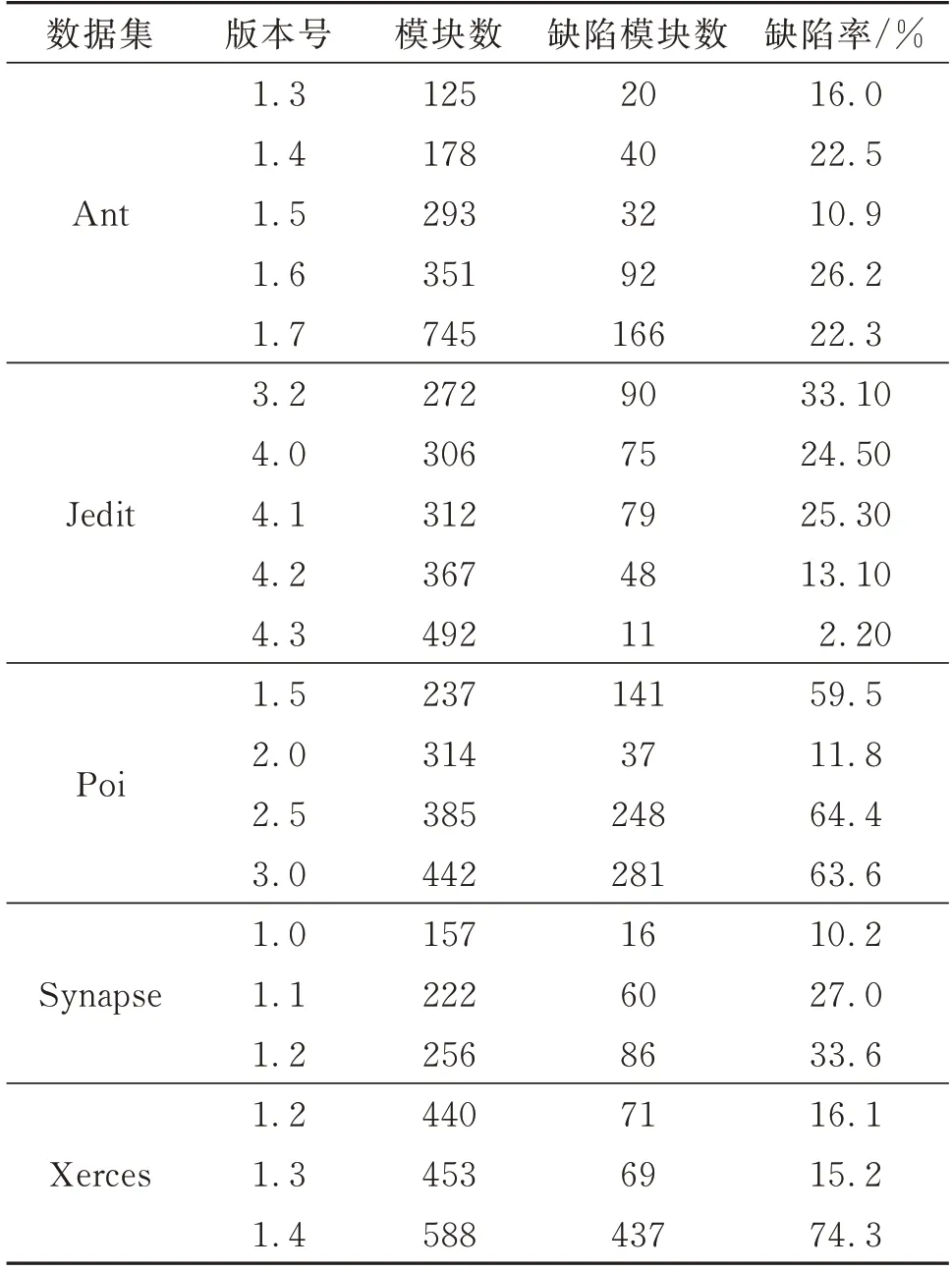
表2 实验数据集Table 2 Experimental data set
3.2 数据预处理
预处理能有效提高缺陷预测性能。因此对以上数据集提取公共类,进行数据采样等操作。
1)提取公共类
版本演化过程中,可能发生新增类、移除类等产生类的变化,导致相邻版本之间的演化没有可比性,因此需要提取两者的共同类,再提取相关代码变更等演化数据。
2)抽样方法
由于缺陷分布通常符合2-8规律,即80%的缺陷分布在20%的模块中,反映了类的不平衡性。因此需要对训练数据进行重采样以降低其影响。实验表明[22],欠抽样能有效提高缺陷预测模型的性能。在初始训练集时本文使用欠抽样方法,即有放回地随机抽取与缺陷模块数量相同的模块,将其作为训练集。
3)度量元选取
不同度量元之间存在一定的相关性,例如rfc与wmc均可以表示类中所涉及的方法数,具有较强的相关性。为了减小度量元之间的相关性带来的影响,因此需要对代码度量元以及演化度量元进行筛选。CFS(correlation-based feature selection)属性选择算法[23]能评估每个特征的独立预测能力以及与其他特征的相关性,挑选出与缺陷具有较高相关性但是相互之间相关性较低的特征属性,并结合最佳优先搜索算法(Best-First Search)选取最优的特征子集。表3即为使用CFS选择出的度量元,例如在数据集Ant-1.3中选择ce、moa和pccm3个度量元来预测Ant-1.4版本中的缺陷。从表3中可看出选取次数较多的度量元为rfc、lcom3、ce、pdc和pccm,表明以上度量元与缺陷的关联较强。
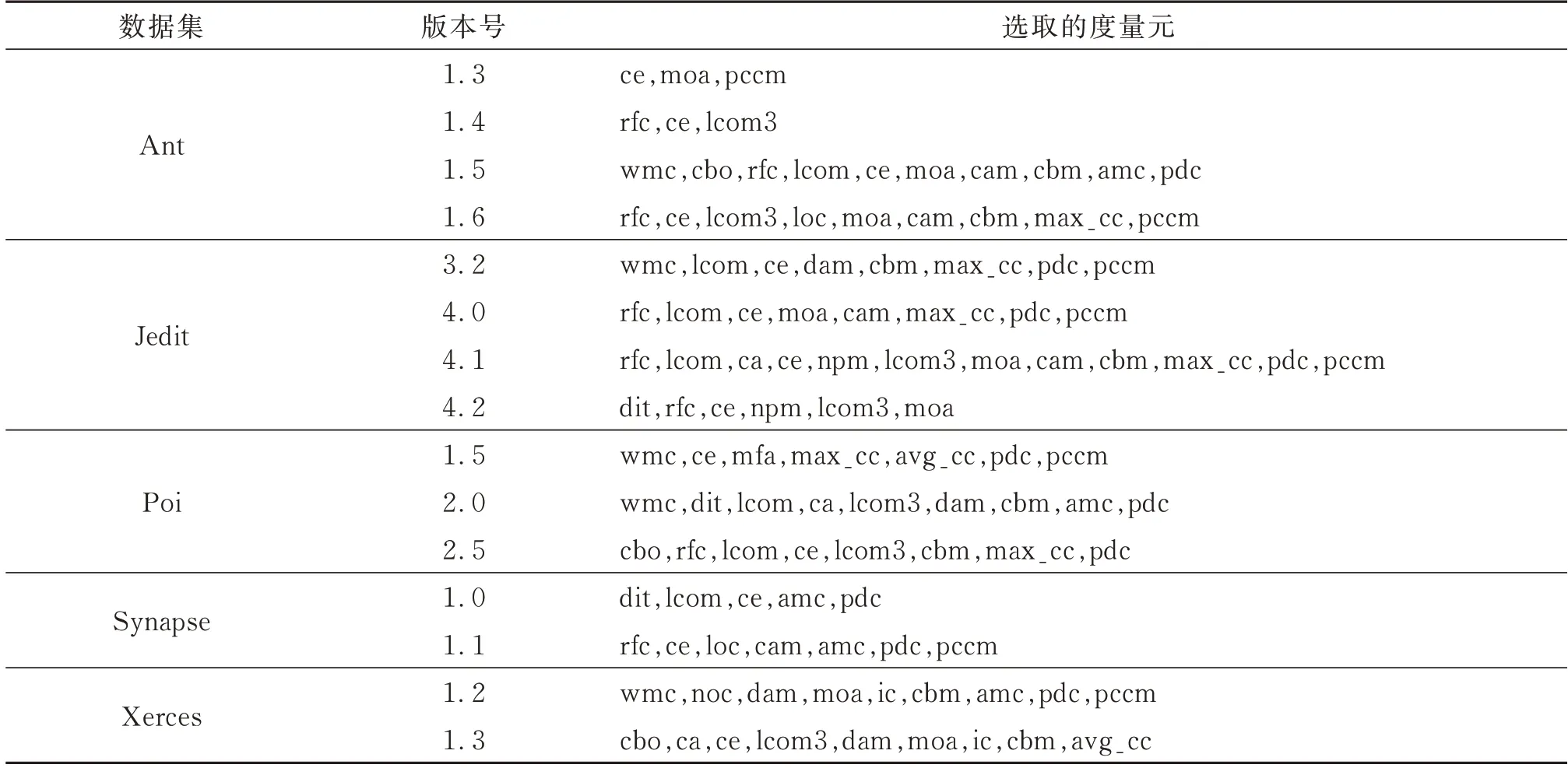
表3 不同数据集的度量元选择Table 3 Metric selection of differ ent data sets
3.3 评价方法与指标
软件缺陷预测是对软件模块是否存在缺陷进行预测,本质是一个二分类问题,所以采用常见的评价指标:查准率(P),召回率(R),F1和AUC。查准率是预测为有缺陷的模块数量中实际有缺陷模块数量所占的比例

召回率是实际有缺陷的模块数量中预测为有缺陷模块数量所占的比例
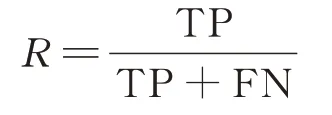
以上两式中TP、FP和FN的定义如表4。F1是一个综合评价指标,是对召回率和查准率之间的权衡,具体公式如下
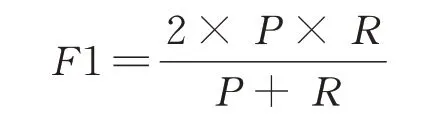
AUC范围在[0,1],一般情况下数值越大,表明该缺陷预测模型性能越好。
预测结果用混淆矩阵表示,如表4。

表4 混淆矩阵Table 4 Confusion matrix
3.4 实验结果与分析
3.4.1 不同机器学习模型集成前后的预测性能分析
表5中数据集表示使用前一个版本的缺陷数据来预测下一个版本缺陷(即Vn-1→Vn),J48、LR、NN和NB分别为基于单一分类器的实验。在数据集方面,可以看到Jedit数据集比Ant数据集预测结果均值高,可能是由于Jedit数据集缺陷率较高,以及选择的度量元可能与缺陷的联系更紧密,所以更容易预测出缺陷。
在精确率方面,LR模型占有优势;在召回率和F1上,NN占有很大的优势,这可能是由于神经网络在预测方面相较于其他机器学习模型更灵活,能构建多层模型来优化结果。J48模型此时的综合指标一般。
表6为4种机器学习模型集成前后结果对比,其中J48*、LR*、NN*、NB*分别表示Adaboost模型基于各弱分类器的集成,J48、LR、NN、NB均为基于单一分类器的实验,每个弱分类器迭代20次。从表6可以看出,4种模型集成后比集成前各评价指标都提升了,其中J48*的提升幅度较大,AUC提升率达51.7%,各项评价指标均是最高的。但J48*模型在集成之前(表5),与其他模型相比表现并不突出,这是因为其弱分类器容易将存在缺陷的模块错分为无缺陷模块,而Adaboost集成对权重进行了加强训练,J48*在AUC指标上比LR*、NN*、NB*平均高出7.7%、4.6%、8.0%。
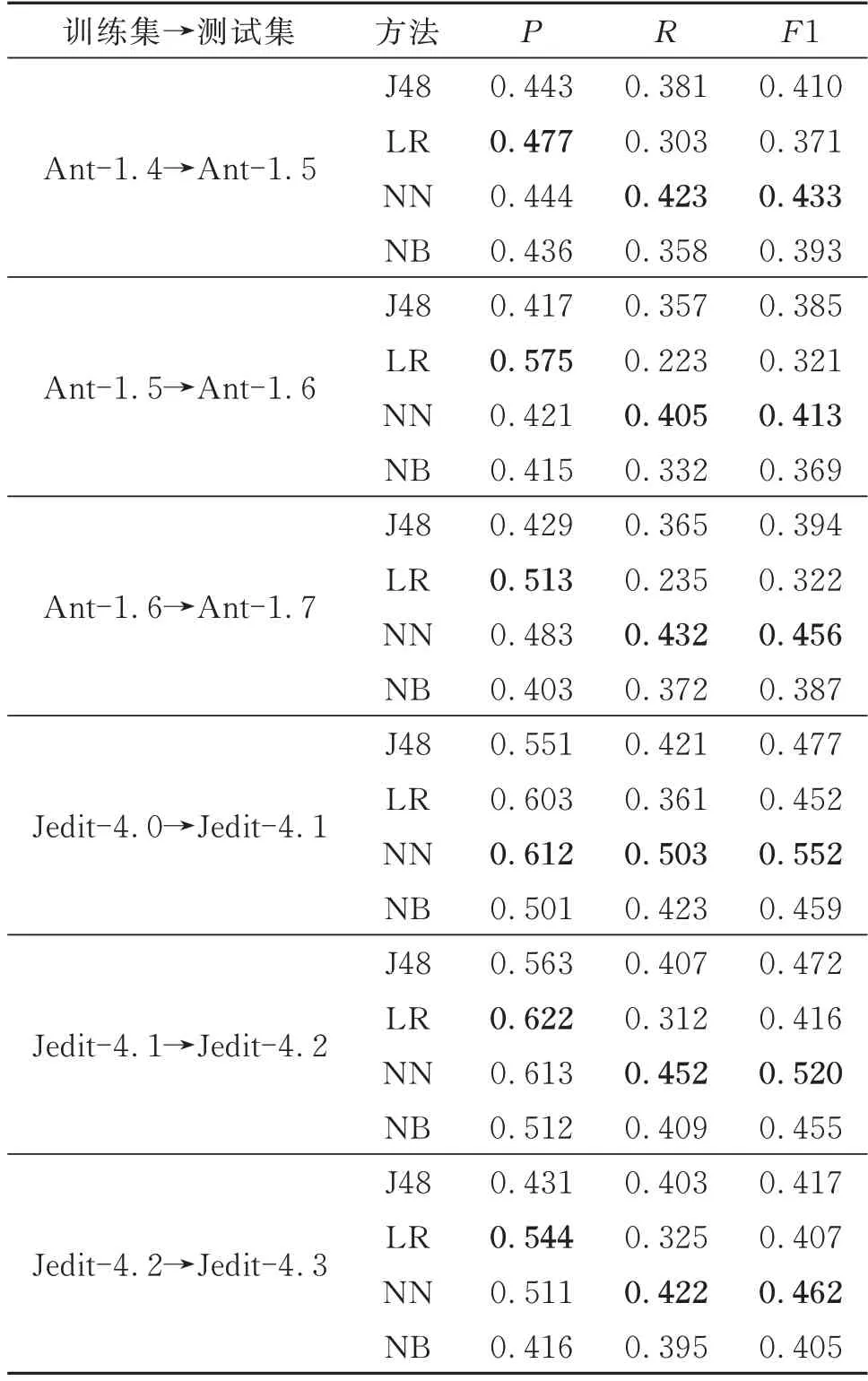
表5 4种机器学习模型的部分预测结果Table 5 Partial prediction results of four machine learning models
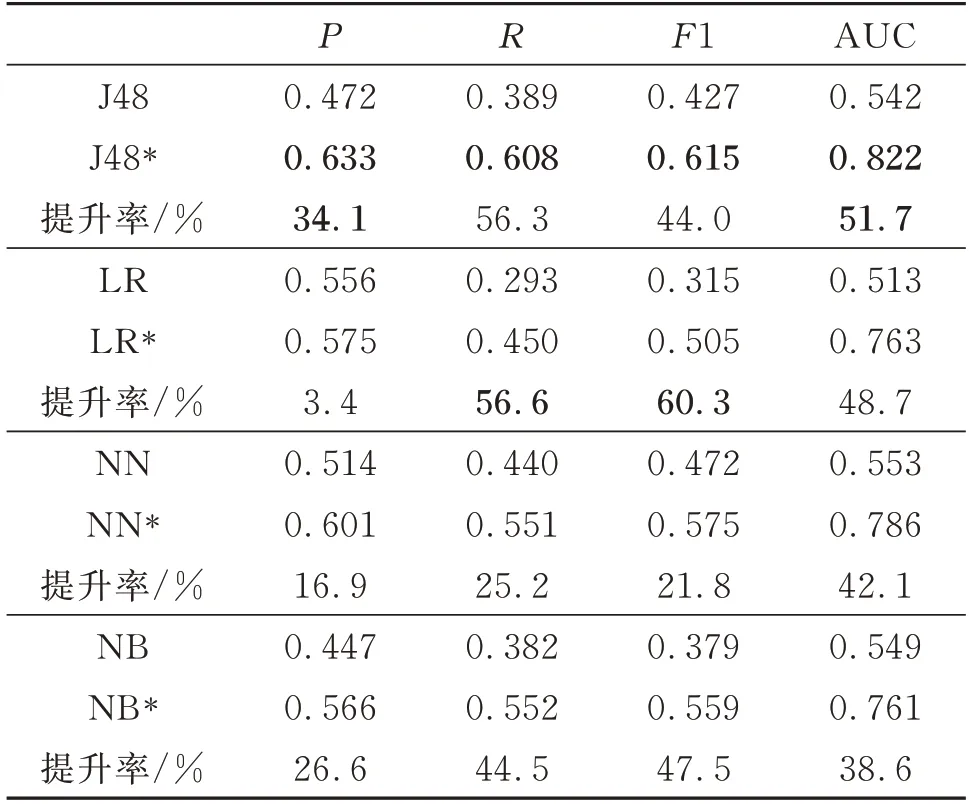
表6 4种机器学习算法集成前后对比Table 6 Comparison of four machine lear ning algorithms before and after integration
因此可以认为,本文提出的集成模型在一定程度上提高了各项评价指标,比单一的机器学习模型有一定的优势。
3.4.2 演化度量元对预测性能的影响分析
为验证演化度量元(EM)对预测模型性能的影响,设计两组实验进行对比,一组仅用代码度量元(CM),另一组使用代码度量元与演化度量元(CM+EM),选择AUC进行对比,实验结果如表7所示。
从表7可以看出,J48*和NB*加入了EM后,绝大多数情况下AUC要优于未加入的。在数据集Jedit-4.2→Jedit-4.3上,加入了EM后的AUC不如未加入的高,这是因为Jedit-4.2和Jedit-4.3缺陷率分别分13.1%、2.2%,导致Jedit-4.2→Jedit-4.3版本间缺陷率变化较明显,加入pdc度量元不能有效使用前一个版本中类的缺陷率来度量当前版本中类存在缺陷的概率。Jedit-4.2→Jedit-4.3版本间发生变化的代码度量元比例较大而缺陷率减少,因此加入的pccm度量元会产生一些误报,所以4种模型在该版本演化过程中CM+EM性能不如CM。
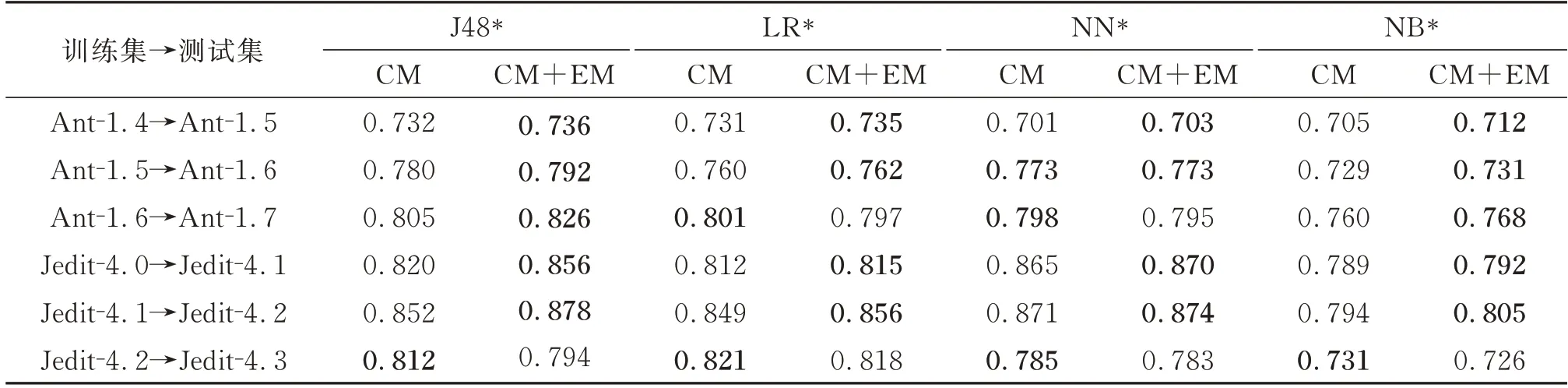
表7 演化度量元对4种预测模型AUC的影响Table 7 The influence of evolution metric on the AUC of four prediction models
因此可以认为,预测时加入演化度量元能在一定程度上提高模型性能。针对代码演化较稳定的版本,即没有较多新增类与删除类,该情况下加入演化度量元预测性能提升明显。针对代码演化不稳定的版本,可仅利用代码度量元进行缺陷预测,此时预测效率更高。
3.4.3 不同集成方法对预测性能影响
本小节用集成学习方法Bagging和Stacking与本文选择的Adaboost方法比较。从上面的结果来看,J48*的性能相比其他3种总体上好些,因此,Adaboost选择基于J48进行20次Adaboost过程后的模型。Bagging方法中NN模型是集成后效率最高的,因此Bagging选择基于NN进行20次Bagging过程后的模型。由于Stacking方法是由两种不同的基础分类器构成,我们对比不同组合模型发现J48+NN比J48+NB性能略微高出一些,但NN模型花费时间较多,因此Stacking方法选择J48+NB模型。表8为这3种集成学习方法的F1和AUC结果。
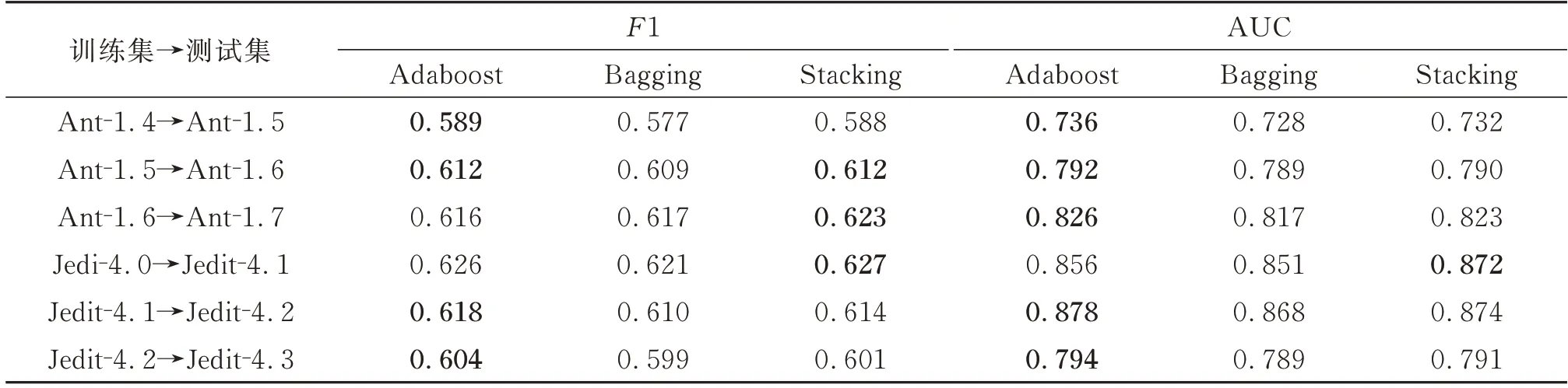
表8 3种集成学习方法的F1和AUCTable 8 The AUC and F1 of three ensemble learning methods
从表8中可以看出虽然不同集成方法之间的F1和AUC值之间性能差距较小,在1%以内,但Adaboost在多数情况下还是比其他方法高一点,这可能是Adaboost方法与J48作为基分类器的契合度更高,能有效改善J48在错分缺陷模块的情况,提高召回率从而达到提升整体的模型性能。
3.4.4 与其他方法对比
本文在演化项目上进行预测,因此选择文献[2]与文献[3]的方法进行对比。文献[2]使用代码度量元、演化模式相关度量元和代码变更度量元等数据,选择NB、J48、随机森林(RF)和二元逻辑回归(BLR)等预测方法进行分析。文献[3]在代码度量元中加入演化度量元(pdc,pccm),选择KNN、LR、NB等方法进行预测。本文在文献[2]基础上构建集成模型进行预测,由3.4.3节实验可知J48*性能最好,因此表9中仅列出J48*与文献[2,3]比较结果。
从表9可以看出,本文集成后的模型的F1和AUC大于其他两种预测方法,这是因为本文模型通过了多轮的训练并调整分类器权重,而在精确率或召回率等方面不同方法均有优势,这一方面是由于基分类器不同性能不同,另一方面是因为代码演化稳定性不同。代码过于稳定,可能产生过拟合。
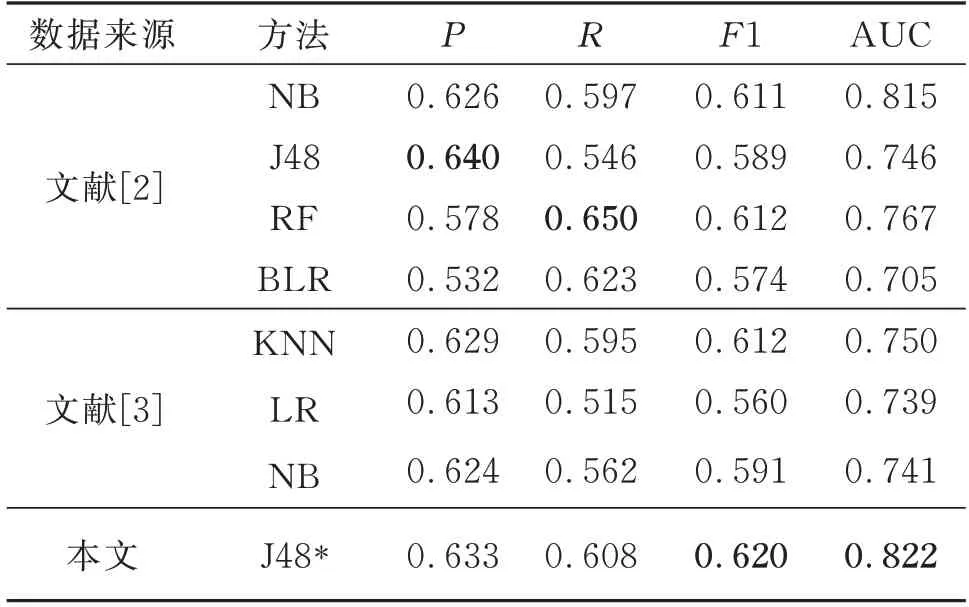
表9 与其他文献预测方法性能对比Table 9 Performance comparison with other literature prediction methods
各文献选择的模型不一致,因此根据不同情况选择对应的模型会更有效。本文方法在面向演化项目的缺陷预测技术上进行集成模型测试,总体性能有一定提升,然而在部分数据集以及模型上提升不明显,因此需要针对不同情况选择合适的方法。
3.5 影响实验因素分析
本节从以下三个方面来分析影响实验结果的因素:
1)构建因素,在构建方面本文选取的模型为J48、LR、NB、NN,每个模型均有优势,因此集成方法采用的模型均不同。Adaboost对LR与NB的提升并不大,这是由于其弱分类器的效果较差或者精度与召回率相差较大从而导致模型整体性能不佳,而Stacking能将LR或者NB的一些优点发挥出来,通过基础模型或者元模型来弥补其缺点。Bagging由于其并行的优势选择NN模型。因此不同模型对预测性能影响较大,而针对其他机器学习模型的性能还需进一步的研究。
2)内部因素,模型中不同参数可能对实验结果产生一定影响。Adaboost次数、阈值设定、权重所占比例以及权重向量策略对模型的分类有直接影响。例如Adaboost次数为20,比次数为10的模型性能有较大提升,而30次与20次的性能差异不明显,因此最终选择Adaboost次数为20。当设定的误差率阈值较大时,则很容易达到阈值从而过早地结束训练阶段,当设定的误差率阈值较小时,训练阶段过长从而导致过拟合。
3)外部因素,数据集的质量、代码度量元选取、代码版本的演化等都会影响实验的结果。本文选取的PROMISE数据集均是缺陷演化中的典型数据集,且至少含有3个演化版本。Ant-1.4→Ant-1.5和Jedit-4.2→Jedit-4.3版本间缺陷率变化较明显,通过上一个版本有缺陷模块与演化度量元预测下一个版本的代码缺陷存在许多误报,影响模型的性能。在Ant-1.5、Ant-1.6、Ant-1.7 3个版本间,演化过程中各个包中共同类的缺陷比较相似,所以预测时能有效找出缺陷。在代码度量元方面,不同版本数据集选取的度量元均不一样,例如Ant-1.4中仅选取输入3个度量元来进行下版本的缺陷预测,而在Ant-1.6中选取了包含以上3个度量元在内的10个度量元,所以选取合适的度量元对预测模型的性能也有较大影响。
4 结语
本文针对面向代码演化项目中机器学习模型对预测模型性能的影响问题进行了研究,以代码演化为切入点,基于4种机器学习模型构建各自的集成模型进行缺陷预测。首先对不同版本的代码进行预处理,选出合适的代码度量元及演化度量元作为模型的输入,再将J48、LR、NB、NN模型通过Adaboost集成构建缺陷预测模型,最后在PROMISE中的5种实验数据集上进行实验并与其他集成方法和面向演化项目的缺陷预测技术进行对比,得出如下结论:
1)4种不同弱分类器中基于Adaboost集成后的模型比对应的单一弱分类器性能提升幅度最大;
2)预测时加入演化度量元能有效提高模型的性能,但受数据集的影响较大,代码演化越稳定,则性能提升越明显;
3)相较于文献[2,3]中的方法,本文所用的Adaboost基于J48模型集成在F1和AUC上有一定优势。
本文方法在整体性能上优于其他面向演化项目的预测技术。在后续的研究工作中,针对更多的基分类器或者不同基分类器之间进行组合,以覆盖更多的集成方法进行预测。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
上海文化(文化研究)(2022年3期)2022-06-28
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
作文与考试·初中版(2019年15期)2019-04-28
江西教育B(2019年2期)2019-04-12
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
软件导刊(2017年4期)2017-06-20
新高考·高二数学(2016年7期)2017-01-23
股市动态分析(2016年17期)2016-10-20
