
衡东卷烟市场状态划分研究*
2022-07-08 09:53谢晓静匡媛媛张革伕
物流工程与管理 2022年6期
□ 谢晓静,朱 博,匡媛媛,张革伕
(1.南华大学 经济管理与法学学院,湖南 衡阳 421001;2.衡阳烟草专卖局(公司),湖南 衡阳 421001)
1 引言
近些年来,烟草行业持续深化市场化改革,以推动卷烟营销高质量发展。卷烟的精准投放成为营销工作的重中之重,也是调控市场的重要手段。一般商品的最优市场状态指的是供给与需求的均衡,而我国卷烟品规市场的较优状态是市场“稍紧平衡”策略。2020年初,国家烟草总局提出要建立“俏紧平松软”卷烟状态评价模型,以支持运行调控,达到“精准施策”。我国幅员辽阔,各个地区存在事实上的风俗习惯、经济能力等方面的差异,全国上下采用相同的卷烟市场状态评价模型显然不恰当;而且,即便是同一个地区,县城、乡镇、农村三类市场也存在不同,统一投放烟品会适得其反。要清晰地把握各个市场中烟民的烟品消费特征,需要最大限度地掌握市场中“俏、紧、平、松、软”卷烟分布,这对推进卷烟的精准投放有着重要的意义。2020年初衡东县常住人口约61万,常住人口城镇化率为41.2%,户籍人口城镇化率为17.8%,农村住户约59%,卷烟年销售额接近10亿元。显然,科学地评价和划分好衡东卷烟市场品规有益于对衡东烟草运行实施精准控制。
2 研究现状与述评
2.1 卷烟品规市场状态研究现状
为精准投放,许多学者对市场上卷烟品规的“俏、紧、平、松、软”内涵进行了研究,并给出了相应定义。顾云飞等[1]构建了一个二级指标评价体系,来研究卷烟市场供需状态评价方法。邓基刚等[2]借助聚类分析方法,通过分析烟草零售户购买卷烟行为来实现对卷烟品牌畅销度的细分,帮助烟草公司对在售香烟品牌进行合理分类,优化客户资源与卷烟货源的配置。邢阳等[3]利用大数据技术及机器学习算法构建了一种卷烟市场运行状态智能评价模型。林少华等[4]研究了数据驱动的卷烟市场调控方法,用3σ法则确定零售库存的阈值区间,从总量、价位、品规等多维度综合判定市场状态,形成了以多层神经网络算法为核心的市场预测办法,进而运用预测结果开展市场状态调控,有助于实现卷烟市场状态的“稍紧平衡”。刘志刚[5]从货源投放的角度出发,对“五要素”指导下货源投放的维度和要素进行分析,以期为卷烟营销策略调控提供有益参考。刘涛等[6]基于市场状态理论及重庆市的相关实践,界定了卷烟品规市场状态,构造了卷烟品规市场状态综合评价指数与趋势指数的核心指标。于梦吟等[7]提出状态评价要系统思维,在状态评价和策略评价相分离策略下,初步阐明了系统思维下总量、价位、品规三个维度,给出了以“条均行批差”、订单需求满足率为核心指标的市场状态评价矩阵,以及品规维度“俏紧平松软”属性评价阈值范围参考值。于冰[8]依托品牌市场匹配矩阵评价体系,以客户需求为导向,创新设计货源供应分析测算模型,构建“智慧投放”模式,精准匹配品牌和客户、供给与需求。
2.2 研究述评
前述有关卷烟市场的“俏紧平松软”划分方法一般需先获取订单满足率、投放面、订足率、订货面、投放订货面等指标数据,然后进行模糊评价,最后进行类型的划分。这些方法在实际操作中会存在困难,如订单满足率的获得本身并不准确,因烟草属于计划投放,难以直接观察到需求与价格的波动关系。另外,不同档位、市场类型、地域状态中的商家在订购烟品时,即使存在明显的差异,烟草公司本身的响应会因为难以计算出商家的需求差异对控制的影响程度,而采用“一刀切”控制策略,使得每一品类烟的订足率等指标意义甚微。第三,对于卷烟市场状态评价结果的合理性还需要进一步验证,即使像衡东这类县级市场,用县城的状态去衡量农村的,只会形成误导。
基于此,本研究从数据自身规律出发来研究衡东县的卷烟市场状态。使用零售终端的日常访销行为数据,时间跨度为4个月,构建RFM模型,运用K-Means聚类算法,来评价衡东县三类市场中的卷烟品规。
3 衡东卷烟市场状态分析模型
3.1 RFM模型
RFM模型由美国著名的数据库营销研究所Arthur Hughes提出,由于其可从三个可量化的维度来衡量客户对企业的价值,于是被广泛接受。RFM模型的三个维度分别为:
①R(Recency,时间间隔),表示客户最近一次来公司消费时间至当前考察时间的间隔,或最后一次购买是多久之前发生的。R值越大,表示客户交易发生的日期越久,反之则表示客户交易发生的日期越近。R越大,客户越容易忘记企业;
②F(Frequency,购买次数),表示客户在该考察周期内购买该企业产品或服务的次数。购买的次数越多,说明该客户的忠诚度越高,该客户对企业的依赖性越大;
③M(Monetary,消费总金额),表示客户在该考察周期内购买的所有产品或服务的总金额。客户购买的总金额越大,对企业利润的贡献也就越大。
RFM模型从三个关键维度描述客户的购买行为,可以较好地表示客户观察期内为企业带来的现实价值。单方面来讨论其中某个指标的价值并不科学,例如:单独认为R大,客户就没价值,并不一定恰当。因为,R大的同时,如果M也特别大,还是可被视为优质客户。一般再采用综合评分法来进行价值评价,在获取RFM综合评分中,R值会进行逆转处理,以保证评价意义与F和M相同,即最大时间间隔,R最小;最小时间间隔,R最大,从而构建出如下式(1)的计算方法。
VRFM=R*WR+F*WF+M*WM
(1)
其中,WR、WF、WM,分别代表R、F、M的权重,IBM Modeler中称之为带宽。在RFM各值进行等级化处理后,等级值相差不大。为了能够进行聚类,必须保各类之间的差距尽可能大,带宽即用于调整差值。
基于上述思想,本研究将品牌烟类比于客户,构建品牌烟被访销的行为RFM模型,从而分析品牌卷烟的价值。
3.2 K-means聚类
聚类分析是机器学习算法中一种经典的无监督算法,旨在探索数据内在的规律。根据对象的属性特征数据之间的相似性,将对象划分成互不相交的簇,以达成分类。聚类分析方法包括K-means聚类、高斯混合聚类、密度聚类和层次聚类等,其中K-means聚类算法简单、收敛快、适用性强。
K-means均值聚类算法是一种迭代求解的聚类分析算法,其步骤是:
①将数据预分为K组,随机选取K个对象作为初始的聚类中心;
②然后计算每个对象与各个种子聚类中心之间的距离,距离可以是欧几里得距离或曼哈顿距离;
③把每个对象分配给距离最近的聚类中心,聚类中心及分配的对象合做一个类;
④每分配一个样本,各聚类中心会根据聚类中现有的对象被重新计算,然后重新计算距离。
上述过程将不断重复,直到满足某个终止条件,如没有对象被重新分配给不同的聚类或中心位置不再发生改变,误差平方和局部最小。评价分类效果的好坏,就是需要各类之间的差距尽可能最大化。
本研究根据RFM综合评分值来计算烟品的市场价值,应用K-means算法,计算烟品价值数据的内部距离,完成烟品的5类市场划分。
4 基于数据挖掘的衡东市场卷烟品规分析
基于前述数据分析理论模型来对衡东市场卷烟品规进行划分,可避免人为地设定各类的域值,达到无人工干预分类效果,下面应用IBM Modeler 18.0数据挖掘软件,从数据采集、清洗、建模、挖掘与呈现等几方面进行说明。
4.1 数据采集与清洗
本研究从市烟草公司业务数据库选取了30个档位、500

家衡东县销售终端标签数据及其访销数据,约占衡东终端数量的七分之一。销售终端的选择服从正态分布,即中间档位的店铺占多,高档位、低档位的选择相对较少,确保样本覆盖比例与实际一致。
销售终端标签数据字段包括店铺编码、许可证号、访销日、档位、市场类型、终端类型等23个字段;从业务库中抓取的销售终端访销数据包含订购日期、品牌拥有者、品牌系列、商品编码、商品名称、需求数量、销售数量、销售金额以及毛利、合计、店铺编码等15个字段,后者数据中缺少市场类型。所采集的样本销售终端订购数据覆盖2021年1月1日到2021年6月30日的烟草订购,记录总量合计为110万条,每条记录代表一种品牌卷烟的订购信息。将销售终端标签数据与访销数据存储于数据库的两个表中,以备数据预处理。
首先,进行数据清洗。剔除需求数量、销售数量同时为0的烟品记录,需求数量为0意味着没有需求,销售数量为0意味着终端没有投放。实际上,在所采集的数据中,约有超过50%的数据出现需求数量与销售量同时为0的情况,这是因为销售终端订购时提交数据为批量,即涵盖了市公司投放的所有烟品。
其次,对前述两个表进行联合查询,以店铺编码为纽带,将所有终端销售数据与其市场类型关联,也就是每个烟品订单总是与市场类型有关。
第三,对数据字段进行投影,去除无关字段,只留下市场类型、商品名称、订购日期、需求数量、销售数量、销售金额,这些字段是构成RFM模型的要素。
第四,考虑节日对需求的短时间影响,本研究对数据进行筛选,去除春节之前的,从中选择“2021-3-1”至“2021-6-30”这段时间的订购数据,提出需求量为0的记录,数据总量为28.1万条。
4.2 数据流模型与数据挖掘
将前述整理好的数据库作为IBM Modeler数据挖掘软件的数据来源,建立如图1所示的数据流。经过数据类型确定和过滤设置,分开“县城、乡镇、农村”三个市场数据,且每个市场的时间观察点都为“2021-07-01”,构成三个流中的RFM形成结点,覆盖时间段从“2021-3-1”到“2021-6-30”。到RFM这个形成节点,可得到最近时间(观察时间-订购日期)、订购频率和订购总金额等值。RFM采用Modeler的最优分级方法,根据出现的频次和信息熵来计算。
从形式上看,订购总金额并不能代表消费需求状态,这是由上级烟草部门投放员根据其认为的行情来决定的,并不是按照需求量来定的,反映的是投放员对市场的判断。对消费市场需求最清楚的是终端店主,其每次下订单是以满足消费者需求为目标的,但在烟草投放系统中未纳入计算。本研究采用了两种消费金额来构建M参数,一是直接使用销售金额,二是构建新的消费金额,即:总需求金额=销售金额/(销售数量/需求数量)。实验表明,采用销售金额情形下的挖掘效果很不理想,分出的俏烟品牌数量达到41个,市场销售额直接占比超过98.9%,轮廓值只有0.4。
客户价值的评价需要进行RFM综合评分,在图1中的“RFM分析”结点,将对RFM各维度值进行分箱,IBM Modeler将每个级称之为bin(分箱),每个bin都会给一个标值。然后,调整RFM三者的带宽,获得RFM总评分。Modeler最大分箱数为9,超过9,会自动从每个等级来读取值进行RFM总分计算。实验发现只有取最大箱数时,分类才能达最优。
然后构建基于RFM模型的K-Means聚类节点,通过计算各品牌卷烟RFM值的距离,来对烟品进行聚类。调整RFM三个维度的宽度值以不断优化聚类效果,将生成的模型重新对数据进行聚类,最终以表格形式呈现分类结果,聚类效果如图2所示。经过数百次的宽度值调整,当WR=0.1,WF=10.8,WM=0.1时,聚类稳定,凝聚与分隔的轮廓测量值为0.7,达到较好水平,类别可解释性好,明显优于销售金额的分类。
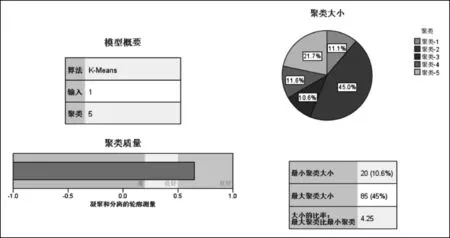
图2 基于RFM综合评分的聚类效果
4.3 结果呈现与市场评价
图1所示的最下部为衡东县平均市场聚类流,根据最后的分类效果数据,难以判断出各烟对应的“俏紧平松软”状态。为此,进一步计算各类的烟品需求额对烟品数量的平均贡献额,结果如表1所示,“聚类-1”的品牌均贡献值为256万,其需求市场占比达到76.8%(假定全满足),标定为“俏”;“聚类-5”的品牌均贡献为22万,市场占比为12.1%,标定为“紧”,与俏相差4000多万,完全不在一个数量级,“俏紧”市场份额累计超过90.4%。“聚类-3”的品牌均贡献为9万,标定为“平”;“聚类-4”的品牌均贡献为6万,标定为“松”;“聚类-2”的品牌均贡献为3万,标定为“软”。数据表明,本模型的分类轮廓明显。但是,按照本模型,衡东共21个“俏”品牌,数量上约占11%,实际销售份额占了76.7%,未满足帕累托最优,显示市场过于集中。
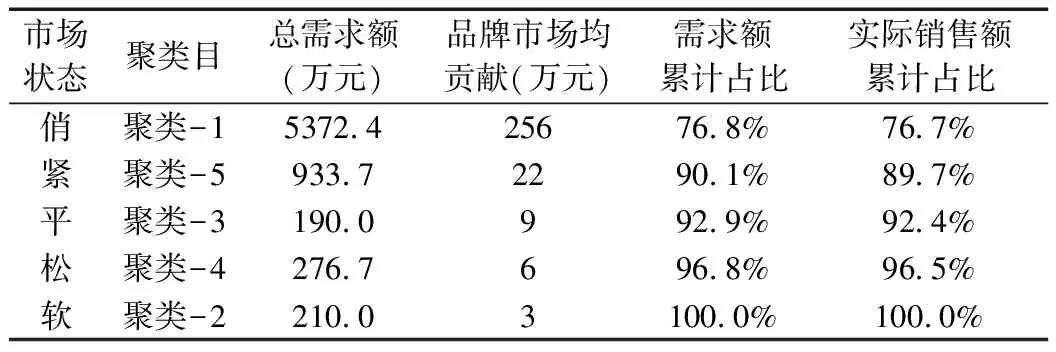
表1 市场状态的评级标准
根据前述数据流模型,分别可获得衡东县城、乡镇、农村三个市场中的烟品状态,各个状态的烟品数量分布如表2所示。表3为三个市场中“俏”烟品牌的一个对比,从中可发现,乡镇“俏”中的“雄狮(薄荷)、黄果树(软)”在县城未出现,而县城的“双喜(硬精品好日子)、白沙(和天下)”在乡镇未出现,二者差了四个品牌。表中名称排序不代表“俏”的程度,顺序基于拼音字母。所有在农村出现的“俏”品牌都在乡镇出现,而在县城、乡镇被认为是“紧”和“俏”的多种烟在农村并未出现。县城、乡镇定性为平、松和软的烟都降级在乡村的软中,软的数量超过60%。尽管衡东农村人口比城镇人口多了18个百分点,但在烟品的消费上显然很集中。

表2 三个市场中的烟品状态分布
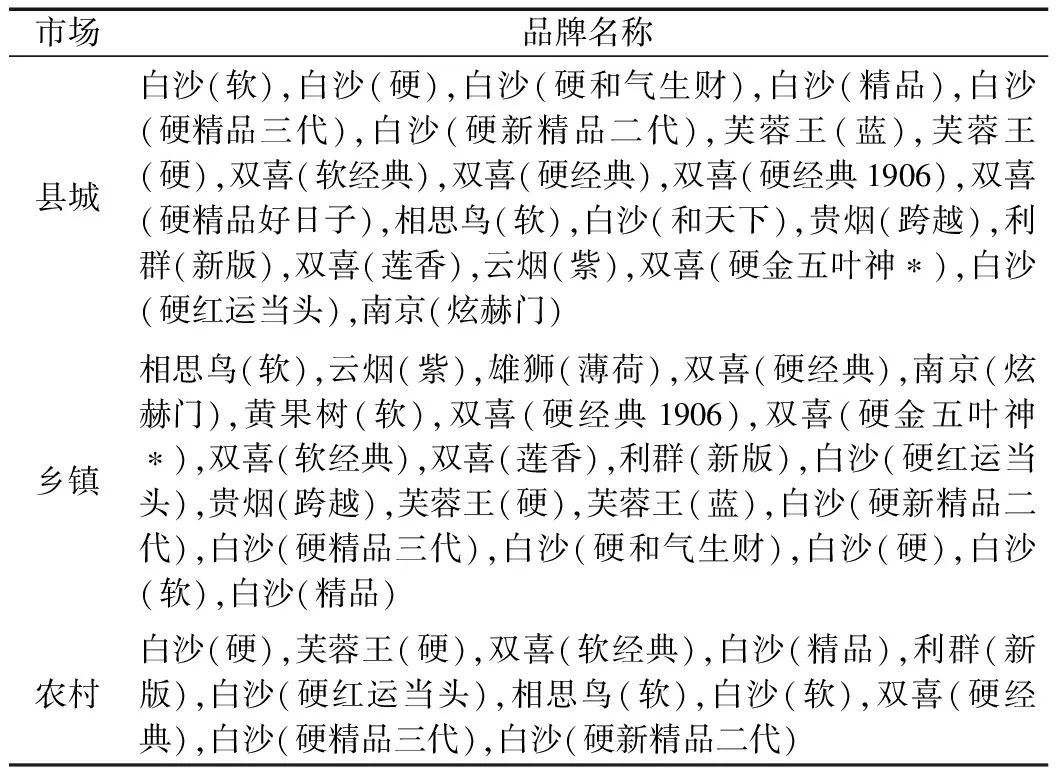
表3 各个市场中“俏”烟品牌对比
从所获得的市场状态分级来看,上述分析模型是可信的,这个观点从销售终端店铺老板和烟草公司客户经理处得到了验证。除此之外,一个有意思的卷烟消费市场现象是:
①在卷烟品牌消费上,县城与乡镇中的消费行为表现出很强的多样性,一方面数量上很均衡,另一方面各种品牌都有分布。这表明县城中的卷烟消费者具有多样性,各种卷烟的尝试都有群体存在,戒烟的和尝鲜的群体是多样中的一员。
②没有数据证明农村的烟民比例要少于城镇的,只是在消费能力上要弱于城镇。在衡东,农村人口要比城镇人口多出18%,本研究的数据表明:农村烟民相对固定,品牌选择固定,认可的基本不会改变,不认可的也不会改变,尝鲜的消费者少,戒烟的人也少。
5 结论
卷烟品牌在各类市场会呈现不同的状态,无视市场状态的投放会导致需求失衡,扰乱卷烟流通顺序。衡东县这类县级市场年销售额接近10亿元,做好烟品的市场评价,分出“俏紧平松软”,对于衡东县的投放极为重要。使用烟草销售终端的访销数据,基于IBM Modeler18.0数据挖掘工具,在应用RFM模型+K-means聚类时,使用市场需求额来替换销售额,在全局市场能获得较好的聚类效果。有关于“县城”“乡镇”“农村”三个市场的分析表明,衡东县的三个烟草市场存在明显差异,农村消费集中。同时,按照“二八”规则,“俏紧”烟品应该占整个市场的80%才合适,俏占其中的64%才合适,显然现在的市场培育存在问题,“平松”烟种类和市场太小。本文的结论对于县级市场的烟草投放具有指导意义,为稳定和维护县级烟草市场的发展提供了方法和思路。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
物流技术与应用(2022年5期)2022-06-17
消费导刊(2021年19期)2021-03-08
消费导刊(2021年1期)2021-01-29
小学生作文(低年级适用)(2019年5期)2019-07-26
现代计算机(2018年27期)2018-10-25
读友·少年文学(清雅版)(2018年12期)2018-04-04
舰船电子对抗(2017年6期)2018-01-11
互联网天地(2016年1期)2016-05-04
山东青年(2016年3期)2016-02-28
