
基于特征融合的中文文本情感分析方法
2022-07-06 08:42傅兆阳
兰州理工大学学报 2022年3期
赵 宏,傅兆阳,王 乐
(兰州理工大学 计算机与通信学院,甘肃 兰州 730050)
随着新浪、网易、腾讯等网站以及QQ、微信、微博等应用的普及,越来越多的网民可以方便快捷地参与到社会热点事件的评论中表达自己的观点与看法,使得互联网上涌现出被多次转发的海量评论、文章、消息、报告等文本数据.对这些带有情感倾向的文本信息进行分析,可以及时获取网民对社会热点事件的看法,有助于政府决策;另一方面,网络的开放性与匿名性等特点造成很多虚假、负面的信息,这类信息的肆意传播很容易造成错误的舆论导向,影响社会稳定.由于这些海量的文本形式多样,无固定格式,很难用简单的模式进行处理.如果依靠人工处理,则存在工作量过大或实时性较差等问题[1].因此,使用基于深度学习的文本情感分析技术,自动且快速准确地对互联网上的海量文本进行情感分析,对政府决策和舆情监控具有重要意义[2-4].
1 相关工作
文本情感分析用来判断一段文本所表达的情感倾向,其中,文本可以是文档级、句子级或者字符级.文本情感分析自2002年由Pang Bo[5]提出后,受到了高度关注,特别是在产品评论、舆情分析等领域取得了很大进展.早期的情感分析研究主要基于规则和基于机器学习算法.基于规则的方法是通过专业人士或机构来构建相对标准的情感词典[6],情感词典包括积极和消极两类情感词汇,然后依托情感词典,对待处理文本进行规则匹配,计算情感得分,最后通过总分得到文本的情感倾向.基于机器学习的方法是通过学习目标样本的特征,根据特征的分布对文本作出类别的判断[7-8],大多使用支持向量机SVM(support vector machine)、最大熵ME(maximum entropy)、朴素贝叶斯NB(Naïve Bayes)等分类器进行有监督学习[9],然后作出情感极性的判断.
近年来,随着深度学习的发展,人们纷纷使用深度学习的方法进行情感分析.Bengio等[10]首次将词向量映射到实数空间,利用神经网络对自然语言进行建模,通过计算词与词之间的数值距离来判断词之间的相似性,简化了文本情感分析.Kim等[11]使用不同卷积核的卷积神经网络CNN(convolutional neural network)对英文文本局部语义特征进行提取,实现了句子级的分类任务并取得了很好的分类效果.梁军等[12]提出了基于极性转移和LSTM(long short-term memory)神经网络结合的文本情感分析方法,在情感极性转移模型中,使用LSTM提取文本上文语义信息,提高了情感分析的准确率.曾谁飞等[13]将词汇词向量和词性词向量进行拼接,构成Double Word-embedding,然后使用BiLSTM(bi-directional long short-term memory)提取文本的上下文特征并进行训练,实验结果进一步证明了该方法的有效性.
传统的深度学习方法虽然在一般的分类任务中取得了良好的效果,但是传统的深度学习模型将所有的特征赋予相同的权重进行训练,无法突出不同特征对于分类的贡献度.2014年Google Mind团队首次提出Attention机制用于图像识别任务[14],它可以聚焦于图像中较为重要的区域,能够充分提取图像中的关键特征,有效提高图像识别的准确率.2016年,Bahdanau等[15]将注意力机制应用于自然语言处理领域的机器翻译任务,该方法较传统神经网络模型在翻译准确率上有较大提高.2017年,谷歌提出一种自注意力机制(self-attention mechanism)用于机器翻译[16],取得了比普通神经网络模型更好的效果.2018年赵勤鲁等[17]提出了基于LSTM-Attention模型的文本分类方法,使用分层注意力来分别选择重要的词语和句子,依据较为关键的词语和句子进行分类,提高了模型的鲁棒性.Zhou等[18]提出基于Attention的BiLSTM神经网络模型,从句子的两个方向学习语义特征,对短文本进行情感分析,在斯坦福树图数据集与电影评论数据集上证明了该模型较无注意力机制的LSTM性能提高3%.
综上所述,现有文本情感分析模型较为单一,对文本深层次的涵义挖掘不够,没有考虑中文词语一词多义的问题,进而影响模型的泛化能力与准确率.针对以上问题,本文提出一种基于特征融合的方法来解决此问题.首先,利用中文词性标注技术,根据分词结果进行词性标注,一定程度上解决一词多义的问题;使用 TextCNN 提取文本不同视野的局部语义特征,解决 CNN 信息丢失的问题,同时充分发挥CNN提取局部特征的优势;使用引入了 Self-Attention 机制的 BiGRU 提取文本的上下文信息和句法结构特征,深层次挖掘句子内部词语间的关联性与逻辑性,从而得到更符合原文语义的向量表征;最后将两部分特征进行融合,使用 Softmax 进行文本情感分类,综合考量文本的一词多义、局部语义信息、上下文信息以及句法结构的因素来提升文本情感分析的准确率与泛化能力.
2 混合模型的建立
2.1 数据预处理
评论文本中包含有大量的噪声数据,为了减少噪声数据对文本情感分析的影响,需要对评论文本进行以下预处理.
1) 数据整理.本文使用的数据集是网民在微博上关于2019年爆发的新型冠状病毒相关的评论.该数据集由北京市场经济和信息化局、中国计算机学会大数据专家委员会联合主办的科技战役·大数据公益挑战赛提供的10万条微博数据.这10万条数据是标记过的,包含3个情感倾向,即积极(1)、中性(0)和消极(-1).该数据集是CSV文件,其中包含微博ID、微博的发布时间、发布人账号、微博中文内容、微博图片、微博视频和标注好的情感倾向.由于微博图片和微博视频数据不够齐全,所以在本文的情感分析中,只用微博中文内容和标注好的情感倾向两个字段,重新构造训练数据集.
由于微博内容比较随意,含有一些英文、表情符号等数据,对文本情感分析的影响较大,且有可能成为噪声数据影响文本情感分析的准确性,所以先对这些数据进行正则化处理,为后面的文本分析作准备.
2) 分词以及词性标注.将整理好的数据使用Jieba分词工具进行分词,并标注其词性.
3) 去除停用词.去除停用词(stop words)就是过滤掉一些频繁出现但没有实际意义的词,比如“我”“就”“的”以及语气助词、介词、连词等,这些词并不能对文本情感分析提供有效的帮助,反而会增加存储空间,降低文本情感分析的效率.
2.2 文本词汇向量化
微博评论文本形式较为自由,没有固定的格式和书写规范,具有高度非结构化的特点,因此需要将文本词汇转化成计算机能够识别的实数向量再进行处理.本文使用GloVe(global vectors)实现离散文本到实数空间的映射,GloVe是Pennington等[19]在2014年提出的一种新的词向量表示方法,该方法基于全局词汇共现的统计信息来学习词向量,将统计信息与局部上下文窗口的方法结合起来.
GloVe模型为了保存文本词汇之间更多的共现信息,从而构造了一个词汇共现矩阵的近似矩阵,计算公式为
其中:Xi表示矩阵单词i一行中出现词语的总和;V表示词典中的词汇总量;Xik表示单词k在单词i的上下文中出现的次数;Pik表示单词k在单词i的上下文中出现的概率;Rijk表示单词i、j、k三者之间的关系,如果Rijk的值很大,说明单词i、k相关,而单词j、k不相关;如果Rijk的值很小,说明单词j、k相关,而单词i、k不相关;如果Rijk的值趋近于1,说明单词j、k相关和单词i、k相关,或者单词j、k不相关和单词i、k不相关.与原始的概率Pik相比,Rijk能够更好地区别单词之间的关系.
GloVe模型构造了一个函数F(wi,wj,w′k),使其极大比率接近Pik/Pjk作为模型的收敛目标,使词向量中含有共现矩阵中所蕴含的信息,其中w,w′∈Rd是对应的词向量.由于噪声数据会造成词与词之间共现关系不均衡、部分共现关系不合理的词会被赋予极小的权重,不利于模型学习参数,所以在构造损失函数时引入一个权重方程f(Xij),构造后的损失函数如下式所示:
(4)
其中:Xi,j表示单词i与单词j在窗口内共同出现的次数;wi表示单词i作为上下文时的词向量;w′j表示单词j作为中心词时的词向量;bi和b′j表示偏置;V表示词典中词汇的总数.
引入的权重方程f(x)需要满足如下特性:

2)f(x)是非递减函数,目的是尽可能减少频繁出现的共现组合不会被赋予较大的值.
3)f(x)函数值要尽可能的小,目的是降低常见的共现组合被赋予更大的值.
GloVe算法虽然实现了文本词汇到实数空间的映射,解决了文本的实数表示问题,但并不能解决一词多义问题.如表1所示,相同的词语在不同的语境中可能会表现出不同的语义.

表1 一词多义举例Tab.1 Example of different meanings in one word
本文利用中文词性标注技术,在分词的同时根据分词结果对相应词语进行词性标注,并构造形如“丰富-动词”、”丰富-形容词”这样的“单词-词性”表示.
假设长度为n的句子W={w(1),w(2),…,w(n)},该句子对应的词性为M={m(1),m(2),…,m(n)},然后将文本和词性进行拼接,构造序列对X={(w(1),m(1)),(w(2),m(2)),…,(w(n),m(n))},最后利用GloVe模型对融入词性的序列对X训练词向量.
2.3 上下文信息提取
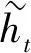
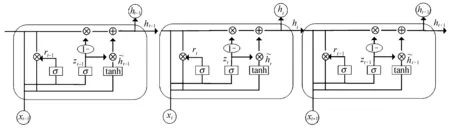
图1 GRU网络模型Fig.1 GRU network model
GRU模型中各个门的计算公式如下所示:
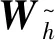

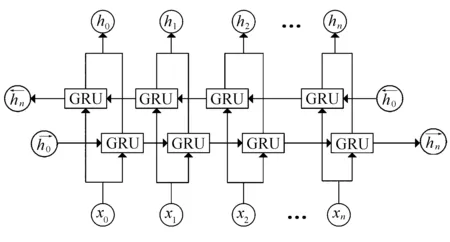
图2 BiGRU网络模型Fig.2 BiGRU network model
BiGRU模型中每一个时刻状态计算如下式所示:
(10)
(11)
输出则由这两个方向的GRU的状态共同决定:
(12)
其中:wt表示正向输出的权重矩阵;vt表示反向输出的权重矩阵;bt表示t时刻的偏置.
2.4 Self-Attention机制
注意力机制(Attention)[15]模仿了生物观察行为的内部过程,即对重要的区域投入更多的注意力,从大量信息中有选择地筛选出少量重要信息并聚焦,同时抑制其他信息的干扰.目前大多数的注意力模型都依附于Encoder-Decoder框架下.如图3所示,Source表示数据源,假设由一系列的〈Key,Val-ue〉数据对组成.注意力的计算过程为:首先通过每一个Query和各个Key计算相似度,该相似度就是每个Key对应的Value的权重;然后将每个权重对应的键值Value进行加权求和,计算公式为

图3 注意力机制Fig.3 Attention mechanism
(13)
其中:Lx表示数据源长度.
自注意力机制(Self-Attention)[16]是注意力机制中的一种,又称内部注意力机制,其特殊点在于Q=K=V,计算公式如下式所示:
(14)
在一般的Encoder-Decoder任务如机器翻译任务中,Source可以是英文,而Target可能就是对应的中文,这时注意力机制就在Target和Source的所有元素之间进行相似度计算.而自注意力机制不是Target和Source之间的注意力计算机制,而是Source内部元素之间或者Target内部元素之间的注意力计算机制.
相比注意力机制,自注意力机制更善于捕捉自然语言表达中各词语间深层次的内在逻辑与句子的内部结构,能够生成更贴合原文语义的向量表征,从而提高情感分析的精度.
2.5 局部语义特征提取
在评论文本中,用户通过形容词、副词等情感词汇表达其情感倾向.情感词汇和句子间存在一定的层次结构和语义关系,卷积神经网络CNN[22]可以通过卷积层提取情感词汇所表达的局部语义特征,因此,本文利用CNN网络进行文本局部语义特征提取.
假设评论文本W={w(1),w(2),…,w(n)},首先将评论文本W中的词w(i)利用Word2Vec转化为对应的词向量V(w(i)),并将词w(i)组成的句子映射为句子矩阵Sij,其中Sij={V(w(1)),V(w(2)),…,V(w(i))},1≤i≤n.CNN将Sij作为卷积层的输入,该卷积层用大小为r*k的滤波器对句子矩阵Sij进行卷积操作,提取Sij的局部语义特征,计算方法如下式所示:
Cij=f(F·V(w(i:i+r-1))+b)
(15)
其中:F代表r*k的滤波器;f代表通过Relu进行非线性函数操作;V(w(i:i+r-1))代表Sij中从i到i+r-1共r行词向量;b代表偏置量,Cij代表CNN提取的由i个词组成的第j个句子的局部语义特征.
Kim[11]在2014年提出了TextCNN,并将卷积神经网络应用到文本分类任务中,利用多个不同大小的卷积核(filter)来提取句子中的关键信息,从而能够更好地捕捉局部相关性,TextCNN模型结构如图4所示.
从图4可以看出,相比单一大小的卷积核,多个不同尺寸的卷积核可以从不同视野范围进行特征提取,得到更丰富、全面的向量表征.使用TextCNN一方面可以引入CNN网络并行计算的优势,提高训练和预测的速度;另一方面,可以弥补CNN网络对长序列输入特征提取不足的缺点.
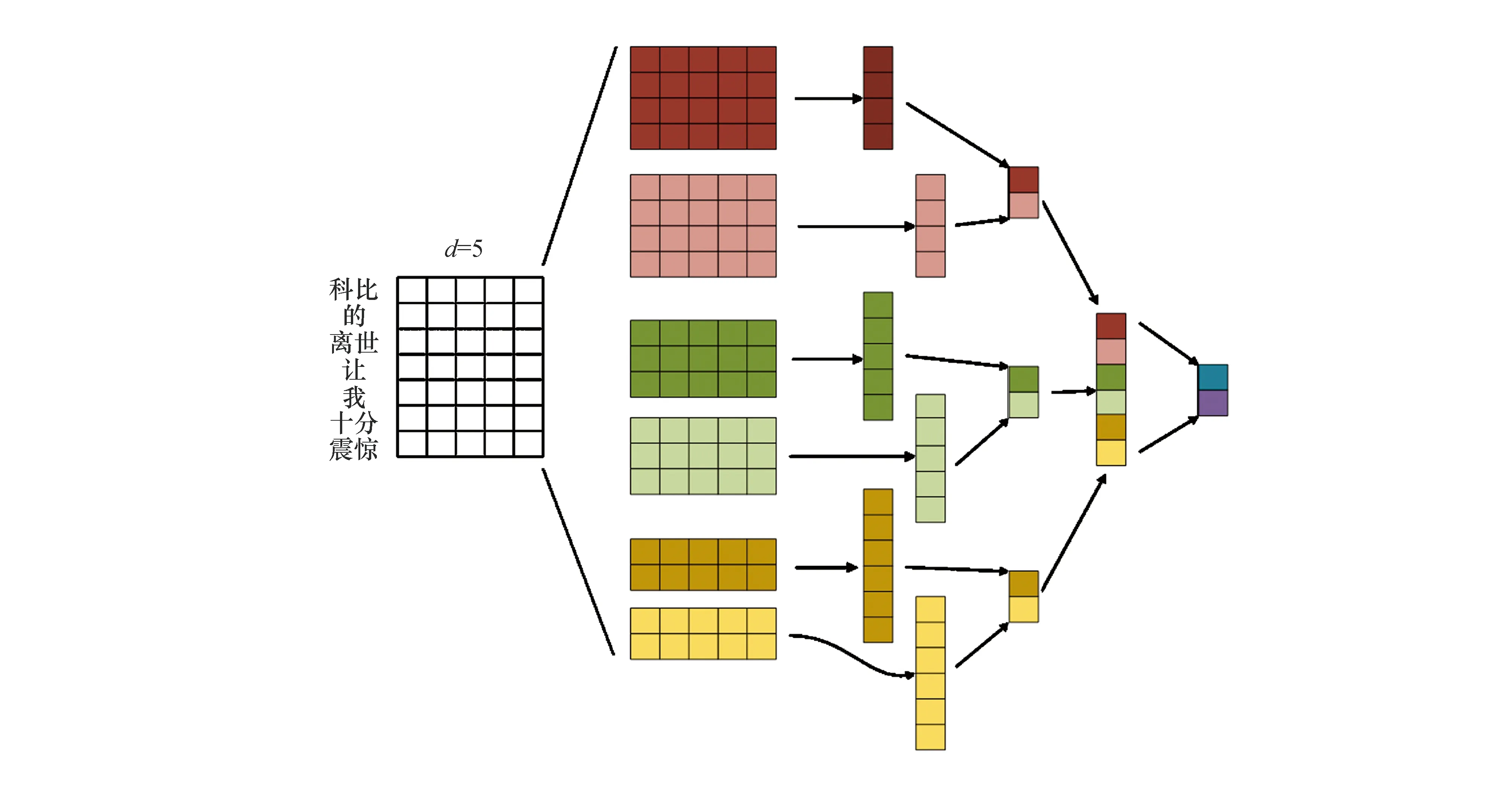
图4 TextCNN模型结构Fig.4 TextCNN model structure
2.6 文本情感特征提取过程
考虑到目前文本情感分析模型相对单一,在不同场景中因为一词多义问题以及不能从句法结构、上下文信息、局部语义信息等维度综合理解文本语义,导致文本情感分析准确率不高,模型泛化能力不强,将卷积神经网络(CNN)、循环神经网络(RNN)和注意力机制相结合,提出如图5所示的混合模型.

图5 文本情感提取算法流程Fig.5 Text sentiment extraction algorithm process
图5为本文提出的情感分析模型结构图,主要由输入层、嵌入层、特征提取和输出层组成.
1) 输入层:使用以新型冠状病毒为主题的微博评论数据集,对微博评论文本进行预处理,并将处理后的包含词性的评论文本使用GloVe将词汇转化为向量,步骤如下:
① 对评论文本进行预处理操作,具体的预处理操作在上文数据预处理部分已详细阐述.
② 使用GloVe对预处理后的包含词性的评论文本进行文本词汇向量化.建立词向量字典,每一个文本词汇对应唯一一个已训练词向量,其中,词向量维度设置为100.对字典中没有出现的文本词汇词向量随机初始化.
2) 嵌入层:将文本词汇中的词向量进行拼接,生成句子级词向量矩阵,如下式所示:
Sij=V(w(1))⊕V(w(2))⊕…⊕V(w(i))
(16)
其中:w(1),w(2),…,w(i)表示文本词汇;V(w(1)),V(w(2)),…,V(w(i))表示文本词汇对应的词向量;Sij表示由i个词向量拼接成的第j个句子词向量矩阵;⊕表示词向量的拼接操作.
3) 特征提取:特征提取层包含两部分,第一部分是以嵌入层的句子矩阵Sij作为TextCNN的输入,其中卷积核大小(kernel_size)分别为3、4、5,每种大小的卷积核数量(filter)为32,激活函数为ReLU,用最大池化层对卷积层提取的特征进行降维,然后使用Keras中的Concatenate()方法对不同卷积核提取的特征进行融合,计算公式为
oijt=TextCNN(Sijt)
(17)
第二部分,首先以嵌入层的句子矩阵Sij作为BiGRU的输入,设置隐藏层的大小为32,激活函数为Sigmoid,将输入矩阵分别从模型的两个方向输入,提取文本的历史信息和未来信息;其次,将两个方向的输出拼接,计算公式为
hijt=BiGRU(Sijt)
(18)
最后,引入Self-Attention学习文本的句法结构特征,深层次挖掘句子内部词语间的关联性与逻辑性,从而得到更符合原文语义的向量表征.计算公式为
uijt=tan(Wwhijt+bw)
(19)
(20)
(21)
特征提取层的最终特征是TextCNN提取的不同视野的局部语义特征和融入Self-Attention的BiGRU提取的上下文信息特征,使用Concatenate()方法进行融合,计算公式为
dijt=oijt⊕attijt
(22)
式(17~22)中:oijt表示TextCNN的输出;hijt表示BiGRU的输出;uijt表示hijt隐层单元;uw表示上下文向量;aijt表示自注意力向量;attijt表示自注意力机制的输出向量.
4) 输出层:通过Softmax函数进行文本情感分类,计算公式为
yi=Softmax(widijt+bi)
(23)
其中:wi表示Dense层到输出层的权重系数矩阵;bi表示相应的偏置;dijt表示在t时刻Dense层的输出向量.
3 实验设计与结果分析
3.1 实验环境
本实验采用Keras深度学习框架,底层为Tensorflow,使用Python语言编程实现.实验运行环境为JetBrains Pycharm软件、Windows10系统、内存16 GB等.
3.2 实验数据集
本文使用的数据集是北京市场经济和信息化局、中国计算机学会大数据专家委员会联合主办的科技战役·大数据公益挑战赛提供的10万条微博数据.该数据被标记为三类情感,即积极、中性和消极.部分样例如图6所示.

图6 部分样例数据Fig.6 Data set sample
根据对所有情感标注数据的统计,如表2所列,中性的数据最多,积极情感的数据次之,消极情感的数据最少.由于非平衡数据会影响分类算法的效果,所以首先对数据进行平衡操作,这里通过对积极情感和中性情感进行欠采样,使得各个标签的数据平衡,从而构建新的训练数据集.在数据集中随机抽取80%作为训练集,10%作为验证集,10%作为测试集,使用十折交叉验证法进行多次重复实验,最后取多次试验结果的平均值作为最终测评结果.

表2 数据集中的情感分布Tab.2 Distribution of sentiment in the data set
3.3 评价标准
文本情感分析通常使用准确度(Accuracy)、精确率(Precision)、召回率(Recall)和F1值作为文本分类问题的模型评价指标.
准确度(Accuracy)能够反映出模型正确分类的能力,准确度越高,分类器的性能就越好,其计算公式为
(24)
其中:TP(true positive)表示本身为阳性被正确预测为阳性的数量;FP(false positive)表示本身为阳性但被错误地预测为阴性的数量;FN(false negative)表示本身为阴性但被错误地预测为阳性的数量;TN(true negative)表示本身为阴性被预测为阴性的数量.
精确率(Precision)能够衡量某一类的正确率,通常,精确率越高表示分类器对某类样本的预测能力就越强,其计算公式为
(25)
召回率(Recall)是指该类文本中实际数据在预测文本中所占的比例,用来衡量分类器的完整性,一般地,召回率越高代表该分类器的分类效果就越好.计算公式为
(26)
F1值是精确率和召回率的调和平均值,它可以有效地平衡二者之间的影响.计算公式为
(27)
3.4 超参数选择
实验参数的设定会直接影响实验结果,本文使用Jieba分词工具对微博评论文本进行分词以及词性的标注,使用GloVe工具进行词向量的训练.实验参数主要有:词向量的维度d,词向量的窗口大小Window_size,BiGRU隐层节点的数量n,Self_Attention隐层节点的数量m,卷积核的数量filter,卷积核的窗口大小Kernel_size,段数t,Dropout比率p,学习率a.其中d在{50,100,200}取值,Window_size在{5,7,9}取值,filter在{32,64,128}取值,Kernel_size在{(2,3,4),(3,4,5),(4,5,6)}取值.经过实验结果对比分析,本文实验参数设置如表3所列.

表3 模型参数设置Tab.3 Model parameter setting
3.5 实验分析与讨论
为验证词向量对文本情感分析的影响,在相同的实验环境下使用以新型冠状病毒为主题的微博评论数据集作为实验数据.分别构造了不使用预训练词向量的本文方法、基于Word2Vec的方法和基于融入词性的GloVe方法,进行对比实验,实验结果如表4所列.

表4 与不同词嵌入类型的性能比较Tab.4 Performance comparison of different word embedding
如表4所示,融入词性的GloVe向量化之后的文本情感分析模型性能较好,Word2Vec次之,不使用预训练词向量的文本情感分析性能最差.在准确度(Accuracy)方面,融入词性的GloVe词向量比Word2Vec词向量和不使用预训练词向量的文本情感分析方法分别提高了0.022 2和0.031 8.分析其原因,随机词嵌入的文本情感分析方法在文本词汇到实数向量转化的过程中词与词之间是完全独立的,没有考虑到词汇之间的联系以及语义信息;使用Word2Vec预训练的词向量考虑到了文本的词汇之间的联系,但是没有考虑到词频以及词性的重要性.而本文的使用GloVe预训练的融入词性的词向量,综合考虑到了语义信息和词性对文本情感分析的影响,尽可能地将离散文本信息准确地映射到实数空间,从而在实验数据集上表现更好.
3.6 与同类相关工作的对比
为了证明本文提出的基于特征融合的中文文本情感分析方法的有效性,在相同的实验环境下使用以新型冠状病毒为主题的微博评论数据集作为实验数据,构造了融入词性特征的BiGRU模型、融入词性特征的TextCNN模型、融入词性特征的BiGRU-TextCNN混合模型和本文所提基于特征融合的混合模型.
1) BiGRU模型:将融入词性的预训练词向量作为BiGRU的输入,然后使用BiGRU提取文本的上下文信息,最后使用Softmax对文本进行情感分析.
2) TextCNN模型:将融入词性的预训练词向量作为TextCNN的输入,然后使用TextCNN提取文本的局部语义特征,最后使用Softmax对文本进行情感分析.
3) BiGRU-TextCNN混合模型:将融入词性的预训练词向量作为BiGRU和TextCNN的输入,分别使用BiGRU提取文本的上下文信息,TextCNN提取文本的局部语义信息,然后对上下文特征和局部语义特征进行融合,最后使用Softmax对文本情感进行分析.
4) 本文方法:将融入词性的预训练词向量作为引入Self-Attention的BiGRU和TextCNN的输入;分别使用引入Self-Attention的BiGRU从文本的句法结构和文本的上下文信息两个方面综合提取全局特征,TextCNN提取文本的局部语义特征;然后对全局特征和局部语义特征进行融合;最后使用Softmax对文本进行情感分析.
如表5所列,本文方法不仅与单一的BiGRU和TextCNN进行比较,还与引入自注意力机制是否够能提高文本情感分析的准确率作比较.在准确度(Accuracy)方面,本文方法比BiGRU模型、TextCNN模型和BiGRU-TextCNN模型分别提高了0.011 4、0.021 4和0.001 6.分析原因,单一的BiGRU模型能够充分提取上下文信息,单一的TextCNN模型擅长提取局部语义信息,BiGRU-TextCNN模型以并行方式将两者优势结合起来,提升了准确率.引入Self-Attention的本文模型从句法结构、上下文信息以及不同视野的局部语义信息三个方面来理解文本语义,更有效地提取出关键特征,相较而言,该方法能够在一定程度上更加出色地完成文本情感分析任务.

表5 与不同模型的性能比较Tab.5 Performance comparison of different models
4 结语
针对现有中文文本情感分析方法不能准确理解文本语义信息,从而导致文本情感分析准确率不高、鲁棒性不强等问题,提出一种基于特征融合的文本情感分析方法.该方法首先使用融入词性的方式在一定程度上解决了一词多义问题;其次使用TextCNN提取文本不同视野的局部语义特征,解决了 CNN信息丢失的问题,并在 BiGRU中引入了 Self-Attention机制,从文本的句法结构和文本的上下文信息两个方面综合提取全局特征;最后将局部语义特征和全局特征进行融合,综合考量文本的一词多义、局部语义信息、上下文信息以及句法结构的因素来提升文本情感分析的准确率.此外,本文不仅对不同词向量工具进行了对比实验,还与其他深度学习混合模型进行了比较,在准确率、召回率和综合评价指标F1上表现良好,具有较大的实用价值.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
长江学术(2015年1期)2015-02-27
