
卷积神经网络圆检测方法用于多硬币检测
2022-07-06 14:30张敬峰林靖宇
小型微型计算机系统 2022年7期
张敬峰,蔡 畅,林靖宇
(广西大学 电气工程学院,南宁 530004)
1 引 言
圆检测作为图像处理研究中的一项基础任务,它在工业检测、辅助驾驶、生物识别等领域有着广泛的应用.例如,工业上采用圆检测方法对工业产品进行定位[1]或者圆形缺陷检测[2].在导航领域,智能驾驶系统通过识别圆形交通标识牌来辅助驾驶[3].类似的还有,一些生物验证设备通过检测圆形瞳孔定位人眼[4].当前已经存在大量优秀的圆检测方法[5-7],这些方法首先需要利用边缘检测器从图像中提取边缘,然后根据后续计算原理的不同,可以将现有的圆检测方法分为3类:基于Hough变换的方法,基于随机圆的方法和基于圆弧边缘的方法.
基于Hough变换的圆检测方法利用图像空间到参数空间的映射来进行圆检测,标准的Hough变换方法[8]具有计算量大,内存需求大和检测精度较低等缺点.Yao和Yi[6]为了改善标准Hough变换方法的不足,通过估计曲率来查找圆心与半径.曲率信息既能避免所有边缘点的累加运算,又能避免不同尺度间的干扰,从而实现更快更精确的圆检测.但该算法对于边缘密度较高的图像会得到大量错误结果.另一类是基于随机圆的圆检测方法,Chun等人[9]在边缘图上随机选择4个非线性的像素点,检查它们是否形成候选圆,最后通过投票策略验证每一个候选圆.该方法基于边缘图上的随机点,因此检测效率容易受到边缘图的噪声点影响.基于圆弧边缘的圆检测方法,该类方法的代表有EDCircles算法[5].EDCircles算法的计算步骤为:先将边缘图上的边缘段转化为线段,线段转化为圆弧,再将圆弧组合生成候选圆,最后采用Helmholtz原理验证候选圆.该算法具有快速检测和无调节参数的优点.但是,该算法在很大程度上依赖于边缘梯度方向的精度,当图像边缘梯度一致性较差时,将会错过一些有效圆.Lu等人[7]认为相对于直线段,圆弧线段携带了梯度方向和极性等信息,直接提取圆弧线段更有利于圆检测.因此他们提出了一种基于圆弧线段配对的圆检测算法.该算法能有效应对复杂的直线段干扰,但易受局部的圆弧线段影响,导致检测结果精确度降低.
基于上述分析,发现现有方法大都依赖于梯度特征和低水平边缘信息(基于边缘图)进行检测.边缘检测器提取的边缘图中,往往包含着大量非目标圆的边缘信息(常见有各类干扰物体检测到的长线段和细小纹理检测到的短线段),而且检测到的多圆边缘无法个体化分离,只能作为整体提供给后续算法计算.尤其当输入图像背景复杂且纹理较多时,将检测到大量的无效边缘信息,严重干扰现有算法的检测精度.
当前,卷积神经网络不仅在目标检测领域[10,12]和语义分割领域[13,14]获得了成功,而且在关于基础视觉特征(边缘特征[15,16],点特征和直线特征[17,18])的检测中也取得了重要成果.例如,Huang等人[17]为了获得房屋的框架(wireframe)结构,设计了两个卷积网络分别检测点特征和直线特征.卷积神经网络通过多层的特征处理,挖掘到多尺度的高级特征,能很好地完成边缘提取工作.此外,神经网络能通过学习期望结果(特定圆对象的圆弧),从而抑制非期望的圆弧边缘,达到有效应对遮挡和纹理干扰的效果.受到卷积神经网络优秀性能的鼓舞,本文提出了一种基于卷积神经网络的圆检测方法.该方法首先利用目标检测技术定位图像中各个圆所在区域,将多圆检测任务划分为多个单圆检测任务,然后应用语义分割技术准确地提取圆的边缘信息(不包含背景和纹理的边缘),最后进行圆参数计算获得检测圆.
现在,基于视觉引导的分拣平台越来越受到人们的欢迎.硬币检测作为硬币分拣平台的视觉引导方法,是进行分拣任务首要且重要的部分.硬币检测负责识别与定位二维图像中的硬币[19].本文将圆检测方法应用于硬币检测,从而验证该方法的有效性.综上所述,本文主要有以下3个贡献:
1)设计了一种基于卷积神经网络的圆检测方法,在检测硬币的实验中具有满足工业要求的高检测精度,可作为分拣平台的视觉引导方法.
2)设计了一种根据圆的边缘点计算圆参数的方法,包括基于聚类的像素点筛选策略,基于圆割线计算圆心和半径的策略和基于计算结果频次的选择策略.
3)为了训练本文的圆检测模型并验证其检测性能,本文模拟了分拣平台的检测环境并从中收集了810张关于硬币的图片.该环境包含了遮挡干扰,纹理干扰和阴影干扰这3种困难的检测情形.通过对硬币图片制作关于硬币对象的目标检测标注和关于硬币边缘的语义分割标注,得到了本文实验使用的硬币数据集.
2 基于卷积神经网络的圆检测方法
本文方法的整体框架(如图1所示)由3个部分组成:粗检测,细检测和圆参数计算.首先,粗检测任务进行特定圆(特定圆指训练集中标注为真实值的圆形对象,例如本文硬币数据集中的硬币)的目标检测,获取每一个特定圆在图像中的区域信息.其次,细检测任务将上述每一个区域提取为裁剪图,并分割出裁剪图中特定圆的边缘.最后,圆参数计算的任务是基于圆的边缘信息计算圆心与半径,并结合裁剪图在原图上的区域信息,将检测结果映射到原图上.在该方案中,粗检测任务实现将多目标边缘分割工作划分为单目标边缘分割工作.因此,细检测任务在裁剪图中只需要分割单个圆的边缘.粗检测网络采用300×300的输入图像(将尺寸约2400×2400的原图缩小为300×300),细检测网络的输入图像为原图的裁剪图(尺寸为250×250至500×500).该设计方案通过调整两个检测网络的输入图像大小,进而有效控制网络计算量和输入图像质量.综上所述,本文方法的设计方案不仅能很好地检测多目标对象,还可以根据任务的需求合理平衡检测精度和计算量.
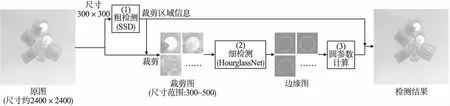
图1 本文方法整体框架Fig.1 Overall architecture of our proposed method
2.1 粗检测(目标检测)
在本文研究中,粗检测任务旨在将多圆检测划分为多个单圆检测,实现方法是采用目标检测技术在输入图像中预测出每一个特定圆对应的边界框.本文采用SSD算法[11]作为整体框架中的目标检测方法.
SSD算法可以简单分为主干网络和预测网络两部分,主干网络提取有效特征,预测网络预测目标分类及定位.其中,将VGG16网络[20]进行改进作为主干网络,具体改动为:将VGG16网络最后两个全连接层改成卷积层,随后增加4个卷积层.主干网络中提取6层不同尺度的特征:38×38、19×19、10×10、5×5、3×3、1×1作为有效特征层进行组合.SSD算法的预测网络是两个不同的卷积器,通过对有效特征的组合进行卷积,一个输出分类结果,一个输出边界框定位结果.多尺度特征组合等同于图像特征金字塔,高层特征用于度量语义相似度,低层特征用于度量细粒度相似度.低层和高层特征的互补可以提高查询目标对象与其他候选对象之间的相似性度量.为了便于后续的语义分割任务开展,本文方法从矩形H×W的预测框中提取正方形L×L(L=min(H,W))的裁剪图,作为细检测任务的输入图片.
2.2 细检测(语义分割)
细检测任务旨在从裁剪图中分割特定圆的边缘信息.本文采用改进的堆叠沙漏网络[21](HourglassNet)作为细检测任务的语义分割模型.如图2所示,该网络以256×256×3(长×宽×高)的RGB图像作为输入,首先通过3个金字塔残差模块(PRM)提取64×64×256的初级特征图.然后,该特征图经过5个堆叠的沙漏模块处理,获得高级的语义特征.最后,网络尾部设计两个反卷积层(5×5×128和5×5×64)和ReLU层,并紧接1×1卷积层进行特征融合,以输出256×256×1像素级的热力图.详细的残差模块和堆叠沙漏网络介绍参考文献[21].值得注意的是,堆叠沙漏网络里的上采样方法本文选择最近邻插值算法而不是反卷积,原因是为了避免多次使用反卷积层而造成棋盘格噪声.

图2 细检测网络模型Fig.2 Fine detection network model
本文采用的堆叠沙漏网络在特征提取过程中经过多次的多尺度整合和级联,挖掘到的特征包含整个圆的空间信息.因此该网络能很好地检测到具有全局语义信息的特征点,适合分割特定圆的边缘信息.
2.3 圆参数计算
圆参数计算任务旨在根据圆边缘的几何属性,利用边缘像素点计算得到关于圆的参数:圆心和半径.整个计算过程包括:像素点筛选,圆心计算,半径计算,结果映射回原图.
针对细检测模型输出的热力图筛选出有效像素点,是准确计算圆心和半径的保障.热力图中像素点的像素值代表了该点属于圆边缘点的置信度.然而实验过程中,发现热力图中存在像素值为255或者接近255的噪点,它们基本位于非期望的位置(不属于特定圆的边缘).综上所述,为了提取置信度高且不属于噪点的像素点,可以通过设置像素阈值筛选像素点.已知,人为设定阈值往往是造成系统鲁棒性差的原因,因此本文设计了利用K均值聚类实现的筛选方法.该筛选方法对热力图中的像素点按照像素值大小进行K均值聚类(分类数为3),并过滤掉聚类结果中像素值最大的一类簇和像素值最小的一类簇.进一步分析,经阈值筛选得到的边缘结果应该是紧密连续的弧线段.为了过滤掉误检到的小弧线段,本文方法采用DBSCAN密度聚类[22]进一步优化热力图,最后筛选得到特定圆的边缘像素点集合P.
基于筛选得到的像素点都属于圆的边缘点这一基础,本文方法从集合P中随机选取直线距离大于一定阈值(裁剪图边长的1/4)的两点作为线段集合L的元素.为了计算圆心,随机将集合L中的元素两两组合,并求中垂线的交点作为圆心的候选点,得到候选圆心集合C.当集合P中多数点为特定圆的有效边缘点时,某些候选圆心值将会多次计算得到.本文方法同时记录下候选圆心值及其出现的次数.为了精确确定最终的计算值,定义了基于计算结果频次选择最终值α的公式:
(1)
其中,α代表待确定值,αi代表出现频次按降序排在第i位的候选值,fαi代表候选值αi的出现频次.
按公式(1),对圆心候选值按频次排序,确定最终圆心值.下一步计算半径,将圆心与集合P中的元素求两点间距离,得到候选半径的集合R,并同时记录各个半径值的出现次数,最后也按公式(1)确定最终半径值.
上述内容计算得到裁剪图上的圆参数结果,本文方法为了将裁剪图上的圆(xc,yc,r)映射回原图得到圆(xc′,yc′,r′),定义了公式(2):
(2)
其中,ρ代表裁剪图的尺寸h′与输出热力图的尺寸(数值为256)之间的缩放比例,网络输出的检测圆(xc,yc,r)乘上ρ再结合裁剪区域的对角点pn1=(xn1,yn1),求得映射回原图的检测圆(xc′,yc′,r′).
3 硬币数据集
本文收集的硬币数据集分为两类:粗检测数据集和细检测数据集,如图3所示.两类数据集分别用于训练粗检测模型和细检测模型.粗检测数据集共包含810张关于多枚硬币的图片,其中643张图片作为粗检测模型的训练集,其余167张图片作为评估整体框架性能的测试集.细检测数据集包含800张关于单枚硬币的图片,单枚硬币图片对应粗检测训练集上单枚硬币的裁剪区域.

图3 硬币数据集(左:粗检测数据集,右:细检测数据集)Fig.3 Coin dataset(left:rough detection dataset,right:fine detection dataset)
硬币数据集中包含两个对象:圆形硬币和方形号码牌.硬币作为实验检测对象,号码牌作为实验检测干扰项.号码牌一面刻印阿拉伯数字,一面刻印飞镖盘图案,其作为干扰项将会增加检测难度.在硬币的拍摄环境中,将黄色的牛皮卡纸作为背景,添设可调节光照强度和照射角度的照明灯进行打光.受光照影响,硬币周围产生月牙形斜影,且硬币表面也会出现反光或者暗淡的现象.
硬币数据集区别于圆检测论文中常见的实验图片,例如Akinlar等人[5]所采用的实验图片.这些实验图片主要包括简单圆形图案合成的图片和清晰圆形对象组成的自然图片.图片中的圆形目标大部分纹理清晰,摆放规整,并且没有受到遮挡,反光或者阴影的干扰.然而,硬币数据集中的圆形目标受到较大程度的遮挡干扰,纹理干扰和月牙形阴影干扰.

4 实 验
本文在硬币数据集的测试集上进行实验,为了验证本文方法的有效性,实验对比了3种优秀的圆检测算法:EDCircles算法[5],CACD算法[6]和Lu的算法[7].所有算法的实验在1台配置有1.80GHz-2.00GHz的Intel(R)Core(TM)i7-8550U CPU的计算机上进行.
4.1 评价标准
实验采用的评价指标与主流的圆检测评价指标一致,分别为:1)准确率(precision),2)召回率(recall),3)F-measure(F1).评价指标的计算方法参见公式(3)-公式(5),其中TPs,FPs和FNs分别代表真阳性检测率,假阳性检测率和假阴性检测率.而F-measure则是准确率和召回率的调和平均值.如果检测到的圆与真实圆(ground-truth)的重叠比例大于阈值T-overlap则被视为真阳性检测(TP).实验中,阈值T-overlap被设置为0.5,0.6,0.7和0.8这4个不同数值,用于观察在不同阈值下算法的检测结果.就检测精度而言,将检测结果与真实值(ground-truth)进行像素单位的对比.
(3)
(4)
(5)
除了上述的评价指标之外,本文定义了如下的误差函数:
(6)
其中,T-error代表误差函数的误差值,用于计算圆(x1,y1,r1)与圆(x2,y2,r2)的差值,本文实验中统一使权重μ=0.5,ν=0.5.
基于公式(6)所示的误差函数,实验计算满足误差函数的检测圆与真实值(ground-truth)之间的半径误差Δr和圆心误差(Δx,Δy).为了量化检测结果,实验详细记录了硬币测试集中4种错误检测情形下的数量,包括漏检的硬币数量,检测到阴影的数量,检测到硬币纹理和干扰项纹理的数量.这些统计数据将体现算法在硬币测试集中的抗干扰能力.
4.2 本文方法的模型训练
本文方法的网络模型基于Python语言,由深度学习框架TensorFlow及Keras搭建完成.
粗检测模型:模型基于随机梯度下降优化器,同时采用迁移学习的思想,将数据集Pascal VOC 2007训练好的权重模型(ssd_weights.h5)作为训练起点.预训练模型的使用一方面有助于弥补小数量数据集数据不充分的缺陷,另一方面也能加快模型的训练速度.关于训练的细节,模型采用的输入图像大小为300×300,训练批量大小(batch size)为4,初始学习率(learning rate)分批次设置为:1×10-4,1×10-5和1×10-6,对应上述3个学习率的训练周期数(epoch)为:(0,30),(30,60)和(60,100).为了防止模型过拟合,设置提前终止模型学习的函数EarlyStopping,其参数patience为10,意味着当连续10个验证集的正确率不再增长时终止学习.此外,模型训练采用了常规的数据增强手段,包括对图像进行缩放,随机块状遮挡和左右翻转.
细检测模型:模型基于随机梯度下降优化器,损失函数采用均方差函数.训练细节如下:模型采用的输入图像大小为256×256,训练批量大小(batch size)为1,训练周期数(epoch)为100.采用动态衰减的学习率,初始学习率(learning rate)为1×10-3,设置每学习2000轮之后学习率衰减为上一轮的90%.
4.3 对比算法
实验选择3种优秀的圆检测算法作为本文方法的对比算法,它们分别为:EDCircles算法[5],CACD算法[6]和Lu的算法[7].由于本实验的特定检测目标(硬币)相对于检测图片大小而言属于中小型号的检测目标,因此对比算法的检测结果可以结合以下先验知识:正确检测圆的半径值大于100个像素点长度.
EDCircles:EDCircles的C++实现代码由原作者提供.EDCircles是一种快速且无调节参数的圆及椭圆检测算法,它采用Helmholtz原理消除所有无效的候选圆.本文只提取该算法的圆检测结果,并且结合先验知识优化结果.
CACD:CACD的Matlab实现代码由原作者提供.CACD算法无调节参数,本文对检测结果结合先验知识进行优化.
Lu的算法:Lu的算法的C++和Matlab实现代码由原作者提供.该算法的代码中主要包含两个参数Tni和Tac,它们用于验证检测圆.Tni代表支持圆上边缘点的比率,Tac代表完整圆的角度.实验中设置Tni=0.5,Tac=165,并且结合先验知识优化结果.
4.4 性能对比
图4展示了4种算法在硬币数据集上的检测性能.第一列展示的是原始图,接下来的4列分别对应EDCircles算法,CACD算法,Lu的算法和本文算法的检测结果.EDCircles算法的检测精度高且能较好地检测到被遮挡的硬币,但伴随而来的问题是该算法检测到的大量圆中只有一部分为有效圆,其余为冗余检测(在十分相近的位置检测出多个圆)结果.例如在第1,3,7张图片中,一些检测圆定位到硬币的阴影,从而偏离硬币边缘.观察CACD算法的检测结果,可以发现该算法能成功找到大多数的硬币,并且不同于EDCircles算法会产生较多的冗余检测.该算法缺点是,一定比例的检测圆不能准确地定位到硬币的边缘,而是误检到硬币的纹理.并且当硬币处于被遮挡的情形时容易发生漏检,例如第2张图片和第9张图片.在Lu的算法的检测结果中,优点在于检测圆很少误检到硬币的纹理,不足在于部分检测圆受硬币的阴影干扰,导致定位结果较差(如第7张图片所示).此外,该算法存在不少漏检.下面归纳本文方法的检测结果.首先,根据检测圆与硬币边缘的重合度观察,可知本文方法的检测精度优于所有对比算法.其次,即使在硬币被遮挡的情形下,本文方法的检测结果也准确地定位到硬币的边缘.最后,本文方法的检测结果中,不存在定位到硬币阴影或纹理的检测圆,并且一个检测圆对应一枚硬币无冗余检测现象.
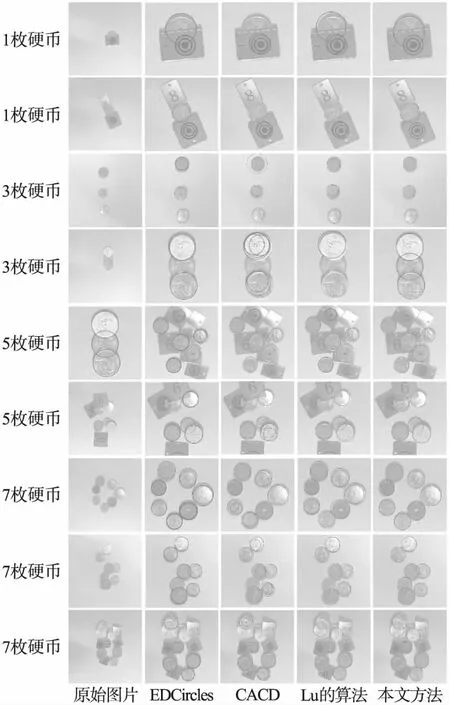
图4 圆/硬币检测结果Fig.4 Circle/coin detection result
硬币数据集上的圆检测结果记录在表1中.数据显示,当重合度阈值T-overlap从0.5增大到0.8过程中,本文方法都获得了最高的精确度和召回率.本文方法取得最佳的F-measure分数分别为96.48%,96.40%,96.20%和95.80%.对比其他3个算法,在重合度阈值T-overlap为0.8的最高标准下,本文方法仍取得F-measure为95.80%的高分值,而此时EDCircles算法,CACD算法和Lu的算法的F-measure分数分别下降至重合度阈值为0.5标准时的60.20%,49.73%和55.38%.F-measure分数的变化情况表明,在本文方法的检测圆中定位精度高的结果占绝大部分.较高的精确度说明本文方法拥有很好的抑制假阳性检测的能力,同时较高的召回率表明方法能很好地检测出有效圆(硬币边缘).需要注意的是,3种对比算法是普适性检测器(检测所有圆形目标),检测到非真实值(ground-truth)的圆形也属于正确结果.由于本文方法基于深度学习,所以本文方法不同于3种对比方法,是一种特定圆检测器(本实验中特定检测硬币).此时,通过对比召回率,能评价各个算法仅针对硬币的检测结果.表1中,3种对比方法的召回率均大于准确率,这符合了前文的表述.观察召回率,3种对比算法中表现最好的EDCircles算法在T-overlap为0.5时仅有81.75%,比本文方法低13.83%.表明,即使只关注硬币被检测的情况,本文方法也明显优于3个对比算法.

表1 各个算法的准确率,召回率和F-measure值(单位:%)Table 1 Accuracy,recall and F-measure of each algorithm(%)
为了进一步探究算法的检测精度,本文定义了误差函数并设置了误差阈值T-error(T-error=30,20,15,10,5,3).将满足误差阈值的检测结果计算4个误差指标值:包括圆心误差(Δx,Δy),圆心距离误差Δc和半径误差Δr.误差函数的定义如公式(6)所示,误差统计结果如表2和表3所示.由表中数据可知,本文方法在T-error为30,15和10的情况下,4个误差指标都获得了最小的误差值,而在T-error为5和3的情况下,只略逊色于EDCircles算法.需要注意的是,在这6个误差阈值下,本文方法的检测圆数量都保持在500以上,而CACD算法和Lu的算法在T-error等于3时都仅有71个检测圆.在尺寸为2431×2431的测试图上,本文方法的绝大多数检测误差只有1至3个像素,表明本文方法具有较高的检测精度.

表2 各项圆参数的平均误差(T-error=30,20,15)Table 2 Average error of each circle parameter(T-error=30,20,15)

表3 各项圆参数的平均误差(T-error=10,5,3)Table 3 Average error of each circle parameter(T-error=10,5,3)
为了具体量化检测难点(阴影干扰,硬币纹理干扰和干扰项纹理干扰,遮挡干扰)对算法的影响,本文根据错误检测结果统计了表4的数据.表中只计数4种错误情况的检测数量,分别为:漏检,误检到阴影,误检到硬币纹理和误检到干扰项纹理.错误计数标准参考图5,实验中不统计不属于表4中的错误检测情况.观察本文方法的统计数据:“误检阴影的检测圆数量”为0,“误检硬币纹理的检测圆数量”为0,“误检干扰项纹理的检测圆数量”为0.这些数据表明,本文方法作为一种特定圆检测器,没有检测到非期望的圆对象.表中后两列数据针对被遮挡的硬币,统计其漏检数量.本文按照遮挡程度将硬币分两类,一类为部分遮挡:遮挡面积为5%至40%,另一类为严重遮挡:遮挡面积近50%.从表中可以看到,CACD算法和Lu的算法在检测被遮挡的硬币时,近半数的硬币发生漏检现象.同时,漏检的硬币中来自被遮挡的硬币的数量分别占总数的73.77%和67.18%.本文方法和EDCircles算法的少量漏检圆中,大部分也属于被遮挡的硬币.综上所述,在硬币数据集中的检测难点(阴影干扰,硬币纹理干扰和干扰项纹理干扰,遮挡干扰)降低了3种对比算法的检测精度,而本文方法受干扰少,检测效果好.

表4 算法的4种错误检测情况Table 4 Four error detection situations of the algorithms

图5 4种错误检测示例Fig.5 Four examples of error detection
5 结 论
本文提出一种基于卷积神经网络的圆检测方法,该方法通过在一个新的硬币数据集上进行训练,可以有效地检测圆形硬币.通过组合目标检测模型和语义分割模型,本文方法从多圆对象的图像中有效提取多个单圆的边缘信息,计算圆参数.通过实验,验证了本文方法能有效克服遮挡干扰,纹理干扰和阴影干扰,并且在硬币数据集上获得97.12%的高准确率和94.51%的高召回率.需要注意的是,基于卷积神经网络的圆检测方法依赖于数据集的学习,由数据集监督模型学习检测特定圆对象.因此本文方法是一种特定圆检测器,与以往圆检测方法所开发的普适性圆形检测器不同.本文方法作为一种特定圆对象检测方法,拥有抑制检测其他圆对象的性能,丰富了现有圆检测方法的功能.实验证明,本文方法仅需少量的数据进行训练,便可以完成对特定圆的高精度检测,具有很高的应用价值.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
保健与生活(2019年7期)2019-07-31
新高考·高一数学(2018年8期)2018-12-03
小资CHIC!ELEGANCE(2018年33期)2018-11-08
Coco薇(2017年8期)2017-08-03
Coco薇(2015年5期)2016-03-29
数学教学通讯·初中版(2014年1期)2014-02-14
