
融合知识图谱与注意力机制的个性化序列推荐
2022-07-06 14:30任永功吕福泽张志鹏
小型微型计算机系统 2022年7期
任永功,吕福泽,张志鹏
(辽宁师范大学 计算机与信息技术学院,辽宁 大连 116000)
1 引 言
推荐系统[1]是一种为用户寻找满足其个性化兴趣的项目,向用户提供有针对性推荐的方法.推荐系统的出现,一方面,缓解了“信息过载”问题,帮助用户从海量的候选物品中筛选目标物品,节省了用户的时间,为用户带来便利;另一方面,为互联网企业创造价值,为企业吸引和留住更多的目标客户,实现利润的增长.如今,推荐系统在网络音乐、电影、微视频、美食推荐和电子商务等领域都发挥着重要作用.
基于序列的推荐系统[2]是推荐系统的一个分支,通过挖掘用户与项目交互的时间序列信息,预测用户未来时期感兴趣的项目.和传统的推荐系统不同,基于序列的推荐系统对用户兴趣进行动态偏好建模,针对用户兴趣的动态变化的进行推荐,在推荐效果上优于静态建模的传统推荐算法.如今,基于序列的推荐系统得到了国内外学者的广泛关注,但是,研究目标过多集中在提升序列推荐的精确度上,提升序列推荐多样性的研究工作相对较少[3].序列推荐中,推荐准确度对于评价推荐系统的质量有决定性作用,但推荐系统多样性研究工作同样重要,推荐列表中的物品多样性更丰富,可以给用户带来更多的惊喜度和满意度,使用户获得更好的使用体验.
本文对提升序列推荐的多样性存在的难点进行研究,总结出存在以下几方面问题:1)由于序列推荐中缺少用户信息和物品侧面信息,这导致传统推荐算法中提升多样性的方法难以应用到序列推荐当中[3];2)提升多样性的同时会降低推荐的精确度[4],多样性和精确度是一个“跷跷板”问题,提升一个另一个必然会造成下降,序列推荐通常预测目标的范围是用户下一次将要与之交互的物品,与传统推荐算法相比预测范围要小得多,所以提升序列推荐的多样性会导致精确度降低更加严重,影响推荐效果;3)用户兴趣表示准确性存在表示偏差,常见的序列推荐中用单个向量表示用户的下一次兴趣的方法,不能准确表示用户的多样性兴趣[5],影响推荐结果多样性的提升,如图1所示.

图1 单个向量不能表达多个兴趣
考虑到现有工作的不足,本文提出一种融合知识图谱和自注意力机制的序列推荐方法(sequence recommendation algorithm based on knowledge graph and attention mechanism,SR-KGA),与现有的推荐算法不同,SR-KGA方法可以显著提高基于序列推荐的多样性,同时保持推荐的准确性.本方法主要在3个方面改进了推荐算法:1)提升物品的表示准确性,通过引入知识图谱,用外部信息对物品进行表示;2)提升序列模型的表示准确性,采用注意力机制构建seq2seq模型来表示序列模型,并用多向量表示用户的兴趣变化趋势,更好的表示了用户兴趣多样性;3)增加预测序列物品之间差异性,采用多样性正则化项优化损失函数,提升推荐结果的多样性.
本文的主要贡献如下:
1.融合了序列信息和知识图谱信息,通过图神经网络对知识图谱数据中物品进行嵌入操作,将生成的向量与物品常用的属性向量相拼接,送入序列模型进行训练,实现了序列信息和知识图谱信息的融合.提升了物品表示的准确性.
2.利用seq2seq模型来进行序列推荐,预测未来用户-物品交互序列.把传统序列推荐中仅仅预测下一次用户兴趣的方法,更改为预测未来一段时间内用户的兴趣动态变化的方法,即预测一个物品的序列.由此产生多个向量,进而可以用多个向量来表示未来一段时间内用户的兴趣动态变化趋势.
3.验证了多样性正则项的有效性,证明了引入多样性正则项约束推荐列表内物品差异性的方法,可以学习到用户不同时间的兴趣偏好差异,有效的增加推荐结果的多样性.
本文中的关键符号如表1所示.

表1 本文中的关键符号Table 1 Key symbols in this article
2 相关工作
自序列推荐方法被提出后,已经出版大量的研究文献,在早期,RENDLE等人提出结合马尔可夫链模型和矩阵分解进行推荐的方法[6]进行序列推荐;深度神经网络兴起后,鉴于其优秀的表现能力,GAMA等人和HIDASI等人提出基于RNN循环神经网络的序列推荐模型[7,8],取得很好的推荐效果;KANG等人和WU 等人采用自注意力机制网络[9,10]进行序列推荐,缓解了循环神经网络长距离依赖的问题.随着图神经网络的出现,一些人开始寻求用图神经网络表示序列关系,例如,WANG[11]等人利用图神经网络模型来进行推荐,同样取得较好的推荐效果.
传统推荐系统中提升多样性的方法可分为两类:列表重新排序和多样性建模方法.列表重新排序法是在主算法计算出推荐结果的基础上提升推荐列表的多样性的方法,例如,Said等人提出的k-最远邻评估算法[12],比以往的k-最近邻推荐算法提升了推荐的多样性;Ribeiro等人提出的多目标优化算法[13]通过采用强度帕累托进化算法同时优化多样性和准确性目标,提升了推荐列表的多样性;多样性建模法是对多样性和准确度共同建模,通过优化模型的参数,来提高推荐的多样性同时保证推荐的准确性,如,Hao等人提出,在损失函数中加入多样化正则项可以提升多样性效果[5].
由于传统的提升推荐多样性的方法不能直接应用于序列推荐,一些研究人员进行了提升序列推荐多样性的研究工作,方法如下:RAZA等人提出联合学习方法提升推荐多样性[14],用LTSM模型表示用户的长短期兴趣,用注意力机制表示的用户的多样性兴趣的方法,实现了多样性的推荐;Wang等人提出一种混合通道模型[15]可以覆盖多目标任务,实现基于序列推荐列表的多样性.
通过剖析序列推荐的研究工作可以发现,基于序列的推荐系统存在以下两方面问题:一方面,预测下一次的交互物品的方法,忽视了用户兴趣未来趋势,不能满足推荐需求.例如,用户的喜好序列是手机-手机壳-蓝牙耳机,用户在购物网站上购买了手机之后,却在实体店中购买了手机壳,购物网站如果仅能预测出用户要买手机壳,就会丢失用户需要购买蓝牙耳机这个兴趣趋势,失去一次交易机会;另一方面,以往提升推荐多样性的方法只针对用户的一个兴趣向量进行多样性推荐,在提升多样性的同时必然会造成推荐准确性的降低.因此,本文采用多向量表示用户多样性兴趣,将提升推荐的多样性作为模型目标任务,提出了一种融合知识图谱与注意力机制的序列推荐算法.
3 融合知识图谱与注意力机制的序列推荐算法
本文方法SR-KGA是一种引入知识图谱信息,用注意力机制表示序列信息,预测用户未来动态兴趣的推荐方法.具体做法如下:首先,引入物品在知识图谱中的外部信息,构建知识子图谱,用TransR[16]方法对子图谱做预训练,其次,结合图卷积神经网络[20]和自注意力机制共同挖掘图谱内物品关系信息和序列信息,构建seq2seq模型,将模型任务确定为预测未来用户与物品的交互的物品序列;最后,在模型训练中,用多样化正则项来约束预测序列中的物品差异化,提升推荐列表的物品多样性.本模型在保证了推荐准确度的同时,提高了推荐列表内的物品多样性,实现了个性化推荐.该方法简化图如图2所示.
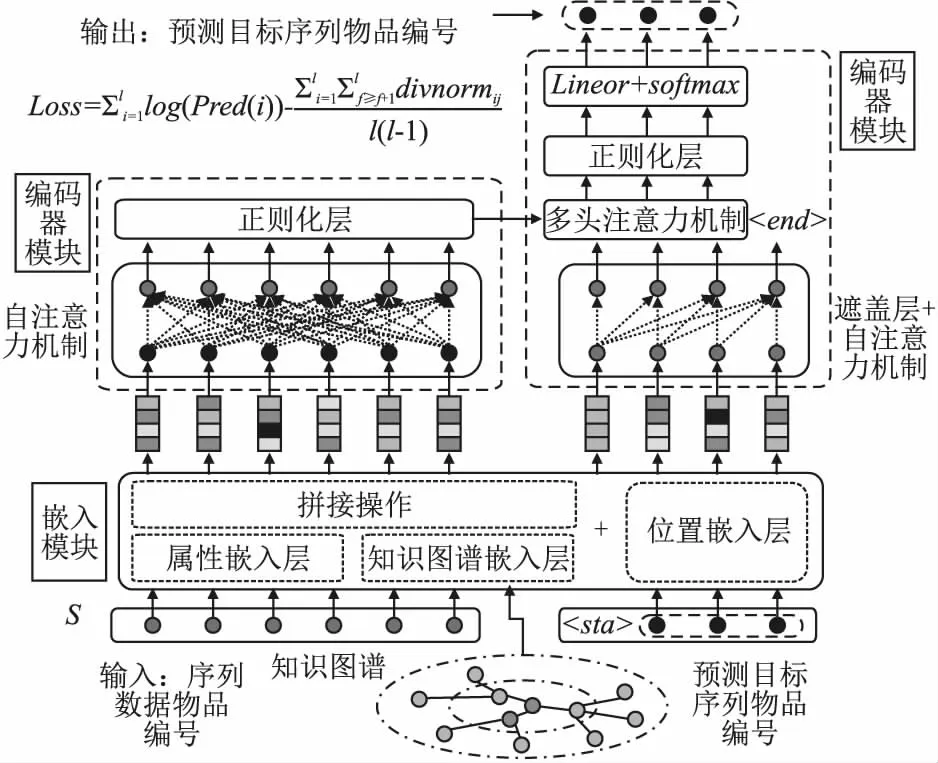
图2 SR-KGA方法模型简化图Fig.2 Simplified diagram of SR-KGA model
在图2中,S为训练集内的序列物品,
下面分别介绍方法中每个步骤.
3.1 知识图谱数据预处理与预训练
知识图谱是一种有向信息异构图,数据形式是包含“头节点”、“尾节点”与“关系”这样的三元组.在图谱中包含了海量的物品与物品之间,物品与属性之间、物品与其他节点的信息,为物品表示的准确性研究提供了丰富外部信息和关系数据[21].由于知识图谱数据信息过多,里面有很多与推荐无关的冗余信息,直接引入知识图谱计算不仅耗费计算机资源,而且会导致模型的整体训练速度过慢.所以,需要对知识图谱进行预处理与预训练.
知识图谱预处理的做法是在知识图谱数据中提取出包含需要推荐物品的知识子图谱.其作用在于剔除知识图谱中与推荐物品无连通性的“节点”和“关系”,减少训练的数据量.
知识图谱数据预训练的做法是采用的常用知识图谱嵌入方法TransR[16]将子图谱中“节点”和“关系”信息嵌入到连续向量空间中,通过这样的预训练方式,可以获得知识子图谱中所有“节点”和“关系”的低维稠密嵌入向量.
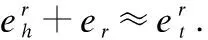

(1)
公式(1)中,Wr=Ra×b是关系r的变换矩阵,将实体从a维实体空间投影到b维关系空间.g(h,r,t)得分越低,说明三元组的嵌入表示效果越理想,反之亦然.
TransR的训练过程考虑了图谱之中图结构的差异性,通过随机生成负例的方式,增加不同关系之间的差异性,计算成对排序损失,公式为:
(2)
公式(2)中,max(x,y)的目的是计算出x和y之间的最大值,t是知识图谱中h、r正确的对应值,t′是h、r对应不正确的值,t′的获得方法是通过替换元祖(h,r,t′)正确的实体,得到的不正确的三元组(h,r,t′).通过使正确的关系和不正确关系之间的差异最大化,来进行训练知识图谱.预训练在模型训练之前进行训练的,预训练过程中采用随机梯度下降方法优化模型,最终通过预训练得到知识子图谱的低维稠密嵌入向量.
3.2 嵌入模
嵌入模块是对物品信息进行向量表示,把物品映射到向量空间,方便传入神经网络的下一层,进行后续的神经网络计算.嵌入模块分为3个并列的层:知识图谱卷积嵌入层、属性嵌入层和位置嵌入层,下面分别介绍这3个嵌入层.
3.2.1 知识图谱嵌入层
为了进一步挖掘知识图谱中的图结构信息,知识图谱嵌入层采用图卷积神经网络对预训练后的图谱向量进行了图卷积操作,生成序列中物品的表示向量.由于图卷积神经网络GCN只能在一个确定的图中去学习顶点的嵌入向量,而序列推荐中,每个序列都需要生成一个子图,图大小不是确定的,不能直接采用GCN进行计算.所以,此处采用简化的GraphSAGE[17]图卷积方式进行计算.简化方法是取消了GraphSAGE控制采样邻居数量的操作,利用平均聚合函数,将目标物品的一阶邻居,二阶邻居进行聚合操作,生成物品的卷积嵌入向量,进而表示一个序列中的所有物品的向量.图卷积每一层卷积方法公式如下:
hd←σ(W·MEAN(hk-1))
(3)
在公式(3)中,MEAN(x)表示求解x的平均值,k代表的是知识图的阶数,σ为非线性激活函数,其中W∈Ra′×a是可训练权重矩阵.经过平均聚合后得到目标物品的嵌入向量.
为了方便表示,对于所有物品{i1,i2,…,in}的知识图谱嵌入向量表示如下:
kgembedding:{EK1,EK2,…,EKn}
(4)
由于不同序列之间会存重复物品,对每个序列都构建子图进行训练,会造成计算资源的浪费,所以在训练时,把多个序列划分为一组,按组中物品构建子图共同训练物品的嵌入向量.再把这些向量放回到序列中,作为序列的嵌入向量进行下一步的计算.
如图3所示,就是一个物品图谱信息传递的过程,其中,i表示一个物品的向量,e表示知识图谱中的实例节点.

图3 输入节点i的特征表示Fig.3 Feature representation of input node i
3.2.2 属性嵌入层
属性嵌入模块是表示和挖掘物品属性的模块,通过采用one-hot编码对物品属性编码,获取物品的属性嵌入向量.具体方法是,其中属性值为真,则用1表示,属性值为假,则用0表示.物品属性嵌入表示如表2所示.

表2 物品多属性编码方式Table 2 Multi-attribute coding methods of items
如此,定义对物品列表{i1,i2,…,in}的属性向量嵌入表示如下:
attributeembeding:{Ea1,Ea2,…,Ean}
(5)
此处,将属性嵌入矩阵M1用表示,知识图谱嵌入矩阵用M2表示,然后,拼接两个矩阵,构造嵌入矩阵:
M=[M1,M2],∈Rn×d
(6)
其中d为嵌入向量的维数.M中的每一行向量都代表物对应品的嵌入向量.对于每个输入的序列来说,嵌入后的矩阵为M∈Rls×d,M中的每个行向量代表对应序列的物品嵌入向量.
3.2.3 位置嵌入层
在序列推荐中,序列中物品位置对未来浏览或购买物品的有不同程度的影响.由于自注意力机制对位置信息不敏感,因此,为了挖掘序列推荐中的物品位置信息,提升序列中物品位置因素对推荐结果的影响效果,此处引入位置嵌入模块.在文献[18]中已经证明,位置嵌入的方法有很多种,不同位置嵌入方法之间的推荐效果差距不大,因此,此处采用和文献[18]一样的位置嵌入方法(positional embedding),这是一种正余弦函数位置嵌入方法可以更方便控制推荐序列的长度.
该位置嵌入方法公式如下:
(7)
(8)
其中,pos为物品在序列中在排位序号,m为位置嵌入的维度,其数值等于物品的嵌入维度,ls为序列的长度,PE为位置嵌入的结果.这样运算可以使得位置嵌入向量的维度与物品嵌入向量的维度相同,然后将上述两个向量进行相加.这里之所以不采用拼接,是因为,在文献[18]中已经证明,相加的结果好于拼接结果,并且相加后不会增加维度,可以使模型运算速度更快,所以此处采用相加来进行计算,公式如下:
(9)
公式(9)中,Msl为序列S上第l位置上的物品嵌入向量,EPl序列上第l位置上的物品嵌入向量,fE(Sn)表示对序列进行嵌入计算.
接下来为嵌入模块训练嵌入层的参数:
E=WE·fE(Sn)+θ
(10)
在公式(10)中,E表示物品向量经过嵌入层后的结果,作为下一层的输入,WE为可训练的嵌入层参数,θ为可训练的偏置权重.
3.3 编码器模块
编码器模块是对序列信息进行注意力编码的操作.在编码器模块中,包括自注意力层,正则化层和前向传播层.序列物品进行嵌入后的嵌入向量经过编码器后,会生成包含上下文信息的编码矩阵,流程图见图4所示.

图4 编码器模块的简化图Fig.4 Simplified diagram of encoder
编码器的第1层是自注意力层,采用“Scaled Dot-Product Attention”.通过构造3个矩阵,分别是查询矩阵Q、钥匙矩阵K和目标矩阵V.然后计算矩阵查询矩阵Q与钥匙矩阵K的点积,并应用softmax激活函数获得的权重值.公式如下:
(11)

A(E)=Attention(EWQ,EWK,EWV)
(12)
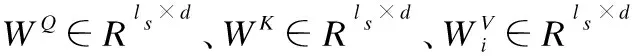
接下来,对注意力层的输出进行正则化LayerNorm层和Dropout操作.为了避免深度神经网络出现过拟合、消失梯度的问题,引入残差网络,将编码器输入与注意力层输出相加.然后送入前向传播层,使用RELU激活函数,最后得到编码层的输出,此层公式如下:
g(A(E))=Dropout(LayerNorm(A(E)))
(13)
N(E)=E+g(A(E))
(14)
Enout=RELU(W×N(E)+b)
(15)
公式(13)是对自注意力机制的结果进行正则化LayerNorm和Dropout的操作;公式(14)为将上一层的输出与编码器的输入进行简单相加,这样的做法是为了防止信息随着网络的加深而丢失;公式(15)为简单的前向传播,使用RELU作为激活函数,计算结果Enout为编码器输出,其维度与输入维度一致.
3.4 解码器模块
解码器模块的目的是计算得出用户未来兴趣物品.这里使用了教师监督系统,因为,预测物品序列中的物品越靠后,正确预测的可能就会越低,所以,不能简单计算后期用户兴趣与历史兴趣的关系,应随时对用户的兴趣偏好进行修正.方法是,无论预测的下一次是否正确,都会向解码器中送入真实的、正确的数据,用来预测之后的数据,以保证未来预测的可靠性.由于这和真实的情况不大相同,所以,仅在模型训练阶段会使用教师监督系统,模型训练完成之后,不会送入真实的数据,具体测试方法将在实验分析中论述.解码器的简化结构如图5所示.
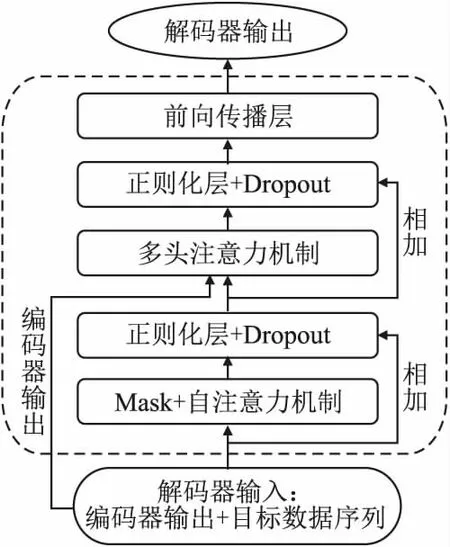
图5 解码器模块训练过程的简化图Fig.5 Simplified diagram of decoder
解码器模块第一层是遮盖层.由于教师监督方法会送入真实的、正确的数据,这会造成模型还没开始预测就已经知道了结果,即“泄题”问题.此处引入遮盖层对目标序列进行遮盖,防止模型看到未来的结果.当模型训练时,每预测出一个物品编号之后,遮盖层减少遮盖一个物品,把正确的物品送入网络中用来预测下一次交互物品,具体的做法如下:
遮盖层是维度为lp×lp的单位下三角矩阵,这里命名为Mask,见公式(12),矩阵中数字为0的位置表示该位置对应序列位置的向量不参与计算,数字为1的位置表示参与计算.

(16)
同时,目标序列在送入遮盖层之前还需要添加开始标记
遮盖层后面两层是自注意力层、正则化层,这两层是为了进行与编码一样的操作,对送入的目标序列进行编码,挖掘目标序列中物品的上下文关系,并使目标序列向量维度与历史序列的向量维度相同,便于计算他们之间的注意力关系权重.公式如下:
N(Epr)=Epr+g(A(Epr))
(17)
公式(17)中,Epr为目标序列经过嵌入层后的向量表示,g(A(Epr))同公式计算方法相同,计算的是注意力LayerNorm和Dropout层的输出,N(Epr)为将上一层的输出与解码器的输入进行简单相加.通过公式计算,可以获得目标序列的嵌入向量.
下一层多头注意力层的输入分两个部分,包括上一层的输出和是编码器输出.这里采用多头注意力的原因是,多头注意力能挖掘出预测序列和目标序列之间的多种注意力的权重关系,公式如下:
(18)
MultiHead(Q,K,V)=concat(head1,…,headh)WO
(19)
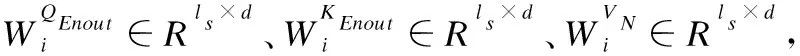
经过多头注意力层后,是正则化LayerNorm层、dropout层和全连接层,公式如下:
g(MA(Epr))=Dropout(LayerNorm(MA(Epr)))
(20)
N(Epr)=MA(Epr)+g(MA(Epr))
(21)
(22)
Deout=RELU(W×N(Epr)+b)
(23)
在公式(20)中,MA表示的是多头注意力MultiHead计算方法;在公式(21)中,N(Epr)得到的是目标序列物品向量,每一个向量代表用户未来的一个兴趣.为了挖掘用户兴趣之间差异性,用公式(22)计算不同向量之间的差异性,此处采用余弦相似度作为计算多样性方法,之后通过多样性正则化,以保证序列推荐物品的多样性.公式(23)为解码器的输出层,可以直接输出预测物品的编号,这里用Deout表示解码器的输出.
3.5 损失函数和多样化正则项
在损失函数中,除了采用负对数似然函数作为损失函数外,还加入多样化正则项,以此保证推荐的准确性的同时提升推荐列表中物品多样性.由于解码器输出的是多个的向量,向量的数量就是序列的长度,此处的思想是,另不同向量最大程度趋近于用户不同时间段的兴趣,同时,另向量之间的差异性最大.计算方法如下:
(24)
(25)
公式(24)用softmax方法计算预测向量和目标物品向量的交互概率,公式(25)为损失函数计算公式,l为预测序列的长度,divnorm是公式(22)中计算的结果,表示推荐向量的之间多样性差异.
4 实验及结果分析
本次实验选用Movielens1M 和 Lastfm2k两个数据集作为实验数据集,Movielens1M数据集是针对电影的评分常用的公开推荐数据集,包含丰富的交互数据;Lastfm2k数据集是音乐网站Last.fm 的对音乐评分的数据集,里面包括用户社交网络、标记、音乐艺术家和收听信息.Movielens1M 和 Lastfm2k数据集都是最常用的公开推荐数据集,在很多推荐工作中被用作实验的数据基础.
知识图谱选取的是在Microsoft Satori知识库上抽取的知识子图谱,抽取后的图谱包括上述数据集的数据及关系数据和节点.数据集和知识图谱信息见表3所示.

表3 数据集信息表Table 3 Data set information table
4.1 数据集选取以及评价指标
通过两个指标对结果进行评价,分别是命中率,和多样性.命中率代表公式分别如下:
(26)
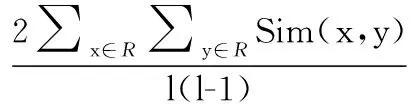
(27)
公式(26)是命中率计算公式,其中nhit是推荐的命中目标物品的次数,N是推荐的次数.公式(27)是推荐列表多样性计算公式,其中Sim()是相似度度量函数,本方法采用余弦相似度来计算列表中任意两个物品(x,y) 向量的相似度.
4.2 数据集预处理方法及对比方法的选取
接下来构造序列数据,通过滑动窗口在数据集上按时间顺序构造序列数据,提取固定长度的序列,把序列中末尾1/10序列长度的物品作为标签列表.对所有用户的序列数据都提取后,打乱混合到一起,作为训练数据S,并对其以(8∶2)的比例划分训练集和测试集.例如,将Movielens1M中每个序列长度定为110个,将前100个作为序列输入,后10个作为预测序列输出标签;将Lastfm2k中每个序列长度定位13个,将前10个物品作为序列输入,后3个物品作为预测序列输出标签.
共与3个常用算法进行对比实验
ItemCF[19]:基于物品的协同过滤推荐算法.
GRU4REC[8]:基于RNN循环神经网络的序列推荐算法.
SASREC[9]:基于自注意力机制的序列推荐算法.
为便于对比,ItemCF算法将每个序列当作用户,来预测下一次物品,进而计算出推荐列表.由于GRU4REC、SASREC方法在推荐中进行抽样数据集上进行排序,计算结果不具有全局性,为了对比的公平性,本方法对其改为在所有物品列表中进行物品召回推荐,然后进行对比.
4.3 测试方法
在验证过程中,由于训练时解码器采用了教师监督系统,送入了真实目标序列的物品数据,为了在测试时模拟真实情况,所以测试阶段,对解码器部分进行一些修改,具体方法如下:1)在解码器内输入编码器输出和开始标记,不输入测试集的真实目标序列;2)把输出的没有经过softmax层的向量作为下一次物品向量,加入开始标记,送入解码器,从而输出下个物品编号,并以此类推,预测出目标序列;3)通过人为设置输出序列的长度,使得输出序列长度与真实目标序列长度相同,进行对比,验证模型的效果.测试流程图如图6所示.

图6 模型验证简化流程图Fig.6 Flow chart of model validation
在图6中,S为测试集的测试样本序列,
4.4 实验参数
预训练中,采用64维向量表示物品向量,通过知识图谱TransR[16]嵌入实体向量,在预训练中总共训练30000轮,采用20%的负采样方法,经过嵌入输出知识图谱所有实体的向量表示;在模型训练部分;多头注意力机制采用2层多头注意力层,注意力头数为2个;自注意力层,采用2层自注意力层,知识图卷积GraphSAGE采用卷积层数为2层,这是由于GraphSAGE[17]中对卷积的层数已经进行了相关实验,验证2层的卷积的效果较好,过多的化可能导致过平滑的问题,所以本文采用2层作为图卷积的层数;前向传播神经节点为64个,这样可以保证与预训练的物品向量一致,采用dropout层的概率为0.2,构建好模型后,通过随机梯度下降算法进行优化模型,以lr=0.01的步长迭代更新模型参数,通过训练模型取得理想的效果.
通过大量实验验证,发现SR-KGA方法在推荐列表的命中率和列表内物品多样性上表现明显优于其他算法,现将实验结果绘制成折线图,见图7、图8所示.同时,为了证明正则化项的有效性,设置了有正则化项和没有正则化项的两组模型进行了对比实验,实验结果见表4所示.
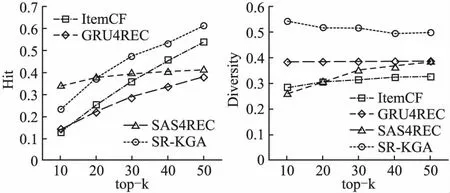
图7 在Movielen1M数据集上的命中率和多样性对比Fig.7 Comparison of the hit rate and diversity on the Movielen1M data set
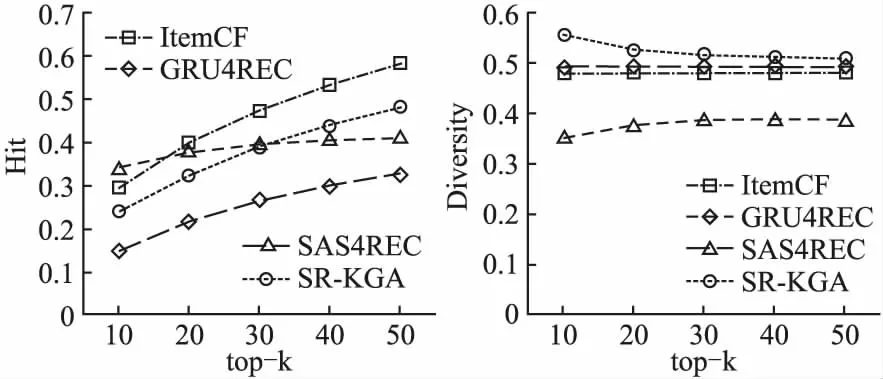
图8 在Lastfm2k数据集上的命中率和多样性对比Fig.8 Comparison of the hit rate and diversity on the Lastfm2k data set

表4 有正则化项和无正则化项的实验结果表Table 4 A result table with and without a normalization layer
4.5 实验结果分析
通过对比各算法在两个数据集上的命中率和多样性表现可得出,在命中率上来看,本文算法再两个数据集上都优于GRU4REC,这说明SR-KGA同GRU4REC相比较,可以有效的提高序列推荐的准确度;在Movielen1M数据集上,SR-KGA优于ItemCF方法,在Lastfm2k数据集上,略差于ItemCF方法,已知训练时采用 Lastfm2k数据集的序列长度较短,仅为13个物品,而Movielen1M数据集的序列长度较长为110个物品组成,结果证明SR-KGA的方法可以更好的捕捉长序列信息;与SASREC方法相比,推荐物品多的时,SR-KGA优于SASREC方法,而这两种方法的区别在加入知识图谱,说明知识图谱嵌入的方式对推荐的准确度有一定的提升作用.命中率结果反映出,用多向量表示用户未来兴趣变化趋势的方法不仅不会降低推荐的准确性,而且对推荐的效果还会有一定的提升.
从推荐物品多样性上看,SR-KGA效果均好于其它方法,尤其是在推荐物品数目较少时,SR-KGA的多样性优先好于其它方法.随着推荐列表的序列长度的增加,相似物品增多,SR-KGA的多样性才会下降.反观其它方法,整体的推荐多样性在短列表与预测上推荐多样性就较低,随着推荐物品的增多,多样性才缓慢的增加,这表明,其他方法的推荐列表内物品多样性较低.对比数据集发现Movielen1M数据集的物品数量较少,Lastfm2k数据集的物品数量的较多,证明了SR-KGA无论是在小数据和大数据量上均可以提升推荐的多样性,同时保证推荐的精确性.
通过观察有正则化项和无正则化项的实验结果表可以发现,加入多样性正则化后,推荐列表中的物品多样性更好,同时推荐命中率变化不大或基本没变化.这个结果证明了加入正则化项可以提升的推荐列表的物品多样性,验证了多样性正则化的有效性.
众所周知,预训练可以大幅度提升模型的训练的收敛速度.为了测试SR-KGA实验中预训练的效果,在Movielen1M数据集上进行了简单的测试,在推荐效果一样的情况下(用准确度和多样性作为评价结果),采用预训练模型的在90轮就可以完成收敛;假如不用预训练的向量,而采用随机初始化的向量,模型会在200轮左右才能完成收敛,训练速度提升了122.2%.这证明了,采用TransR对知识图谱进行预训练可以显著提升模型训练速度.
综合实验结果来看,可以得出如下3条结论:1)引入知识图谱对物品进行嵌入表示,可以提高物品表示准确性,进而提升推荐准确性;2)用注意力机制构建seq2seq模型来预测未来用户交互序列的方法是可行的,用多向量来表示用户兴趣方法是有效的;3)对于推荐结果命中率和多样性这样的二元优化问题,采用损失函数中加入多样性正则项,可以保证准确度的同时提高推荐多样性.
5 总 结
本文针对序列推荐中出现的推荐内容同质化的问题,提出了一种融合知识图谱和注意力机制的seq2seq模型的序列推荐方法SR-KGA.此方法用用知识图谱外部数据对物品进行信息扩充表示,用注意力机制构建seq2seq模型来预测用户未来一段时期内交互物品的序列,把多样性正则项加入损失函数中,提高了推荐列表的个体多样性的同时,保证推荐准确度.通过在两个数据集上的大量实验结果表明,SR-KGA的在保证准确性的情况下,多样性优于其他算法,实现了用户个性化推荐.在以后的工作中,计划通过整合丰富的上下文信息(例如停留时间、动作类型、位置、设备等)来扩展模型,研究处理时间多样性的个性化推荐方法.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年16期)2022-08-24
新高考·高一数学(2022年3期)2022-04-28
新城乡(2018年6期)2018-07-09
上海师范大学学报·自然科学版(2018年3期)2018-05-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
神州·上旬刊(2017年9期)2017-10-15
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
计算技术与自动化(2014年1期)2014-12-12
