
基于轨迹大数据时空分布的索引与查询方法
2022-06-30 06:57李征宇赵卓峰
南京航空航天大学学报 2022年3期
李征宇,赵卓峰
(1.北方工业大学信息学院,北京 100144;2.大规模流数据集成与分析技术北京市重点实验室(北方工业大学),北京 100144)
随着定位技术的广泛应用,轨迹数据成为近年来一类典型的大数据。轨迹数据涵盖的领域非常广泛,其中包括人类出行轨迹、自然现象移动轨迹和动物迁徙轨迹等[1]。海量高质的轨迹数据中蕴含着丰富的信息,通过对其进行深入的分析与研究,可以掌握人类活动和迁移的规律,分析交通、大气环境的移动特征[2],其结果可以应用到城市规划[3]、路线推荐[4]和城市热点区域发掘[5]等方面,推动其他各个领域的发展。以Hadoop 为代表的大数据技术被用来支持轨迹数据的存储和查询,然而直接使用Hadoop 等大数据技术将轨迹数据存储于分布式集群中,只解决了海量轨迹数据的存储问题,并不能满足对海量轨迹数据的高效查询需求。例如:只是简单将数据存储在分布式文件系统上,或是不做任何处理地将数据存储于NOSQL 数据库中,做局部的查询与分析工作就意味着对整体存储做一次全扫描,耗时长、资源占用率高等问题就会凸显,从而导致整个任务流程效率低下。 因此,基于分布式存储系统与NOSQL 数据库,建立高效的索引结构与查询策略来提高存储和查询效率,是当前存储与查询轨迹数据的主流方法。传统小规模轨迹数据的索引策略主要分为基于R-Tree 方法与基于网格方法[2]。基于R-Tree 的方法随着存储轨迹数据时间跨度的增长与数据量的增加,不同的3D 框之间重叠变得频繁,导致查询效率下降,不适合在分布式大数据环境下进行海量轨迹数据的存储和查询;基于网格的方法是将空间划分成均匀的网格并加上时间维,查询时将查询任务转换成覆盖不同网格的子查询。它将所有的网格等价看待,没有充分考虑时空轨迹数据在时空间分布上不均匀的特点。本文设计并实现了一种基于历史数据预分区的轨迹数据索引结构,用于加速海量不均匀轨迹数据的轨迹查询,在非关系型数据库HBase 中设计了存储模型并设计了基于此索引的查询优化算法。索引结构利用Geohash 编码,借助了编码的空间邻近性,首先在历史数据集上随机抽取轨迹数据用于构建不均匀的分区,根据Geohash 数量分布情况对Geohash 编码进行合并,并生成Geohash 的倒排索引,使得Geohash 编码与分区一一对应。在此基础上,本文设计了基于HBase 的轨迹存储模型以及轨迹数据查询算法——首先在倒排索引中检索查询范围覆盖的分区情况,再依次遍历分区,在分区内完成子查询的分割操作,最终完成时空轨迹数据的查询任务。
1 相关工作
现有的轨迹数据索引按构造方法也可分为两类:数据驱动方法与空间驱动方法[6]。
数据驱动方法主要是围绕以数据为中心,随着数据导入的过程动态的生成索引结构。普遍是基于R 树方法的变体或拓展,例如基于轨迹建立的3D-Rtree 方法[7],通过构建时空R 树的方法建立索引,将查询问题转化为三维查询立方体,但是这种方法随着数据量的增加,查询效率急剧下降。尽管后来提出的ST-R-tree 和TB-tree[8]方法提出了解决此问题的新思路,但是随着存储轨迹数据时间的增加,索引框之间重叠的问题依然存在。文献[9]提出的Rt-Tree 索引方式和文献[10]提出的HRTree 和H+R-Tree 索引方法使用的都是多版本R树方法。对于给定的时空查询,这类索引首先判断查询窗口覆盖哪些时间段,然后从这些时间段对应的每个空间索引中检索查询范围相交的轨迹点。基于R 树构建的索引结构相对复杂,R 树的插入与节点分裂代价相对较大,需要动态地调整索引结构。
另一类空间驱动方法的思路是先将地理空间分为网格的形式,然后将落入每个网格的内容再依时间进行索引,达到同时索引时间维和空间维的目的。编码方式主要以常规网格编码的方式实现,按行、按列将空间有序地划分。随着空间填充曲线领域的发展,2 种可以保持空间邻近性的空间填充方法应用比较广泛,即Z 曲线[11]与Hilbert 曲线[12]。Hughes 等介绍了一种时空数据存储与检索引擎Geomesa[13],其索引部分就是利用Z 曲线进行Base32 编码得到的Geohash 实现,可以用于索引时空轨迹数据。JUST[14]是京东城市时空数据引擎,该引擎在Geomesa 的基础上提出了Trajmesa[15]存储引擎,拓展了Z2T 和XZ2T 两种索引方式,解决时间与空间维度不匹配的问题。ST-Hash 索引方法[16]将经度、纬度、时间3 种属性进行统一编码,使地理位置邻近、时间相近的数据,物理存储的位置相近。相比较于Z 曲线,Hilbert 曲线映射步骤较多相对复杂,但数据的空间聚集性比Z 曲线更优。文献[17-18]使用Hilbert 曲线对空间进行编码,同时再加入时间属性构造索引。
数据驱动与空间驱动索引方法是从索引的形式上考虑的,面对海量轨迹数据的存储与查询需求,数据驱动的索引方法通常并不高效[19-20]。由于轨迹数据通常与路网、城市热点区域以及由此带来的移动对象出行特征密切相关,所以海量的轨迹数据通常聚集在城市热点区域以及路网范围内,但是空间驱动索引方法是将空间中的所有区域进行等分,这就造成了有的空间区域中数据量庞大,有的空间区域中数据量较少甚至没有数据,使得有的子查询需要耗时较长,有的子查询中并没有数据。
针对这种轨迹数据的分布不均匀问题,现有解决方法主要依靠数据的动态划分进行解决。文献[21]中提出了1 种基于ST-hash 的LPSTHash 的索引方案,设置了Regin 分裂的策略,当Region 中数据量达到了Region 分裂阈值,使Region 以某一个键值作为分界线分裂,同时,Region对应的索引树也应该和Region 一样一分为二。文献[22]中,基于Geohash 和R 树,提出了1 种2层时空索引-GRIST,通过改进原有的Geohash 的编码及映射算法,设计了根据数据分布自适应分裂的方法,利用R-tree 存储不均匀的Geohash 网格上的数据。动态划分法虽然可以有效地解决数据分布不均匀的问题,但是由于数据分区是随着数据导入时动态生成的,分区过程会花费较长时间,同时已经生成的索引结构也要动态的更改;可能会存在数据存储完成但数据依然分布不均匀的问题。本文的方法利用了历史数据得到轨迹数据的时空分布规律,再利用规律构建分区的方法,解决不均匀轨迹数据的存储与查询问题。
2 基于历史数据预分区的索引方法
轨迹数据Traj 由一系列轨迹点构成,可以表示为集合Tra={P1,P2,…,Pn},轨迹点Pi=(loni,lati,ti),0≤i≤n,其中经度用lon 表示,纬度用lat 表示,t表示此坐标位置的时间。Traj 可以表示在三维坐标系中,其中两维表示为地理空间-经度与纬度,第三维用于表示时间。
本文索引的生成利用了Geohash 编码。Geohash 是一种用于处理空间数据的高效的索引方法,通过对地理信息的编码,将二维的经纬度降维成一维字符串,Geohash 编码代表的并不是1 个点,而是1 个矩形区域。对其加入时间维可以用于索引时空轨迹数据,在使用划分得均匀的立方体存储数据时,查询问题可转化为对查询立方体所覆盖的Geohash 立方体进行遍历,产生大量的子查询任务。如图1 所示,对于不均匀的数据分布,这些查询任务可能相差悬殊(每个Geohash 立方体中的数据可能相差悬殊);对于查询范围远大于单位立方体的查询需求时,查询会转换成为大量的子查询,影响查询性能。

图1 Geohash 立方体查询示例Fig.1 Example of Geohash cube query
区别于只利用Geohash 编码构建的时空数据索引方法,本文索引方法的核心是利用历史轨迹数据提前得到轨迹数据的分布规律,在索引构建的过程利用此规律,将Geohash 编码分区按历史数据分布进行合并,即通过阈值的方法对其进行合并,这样在查询时本文方法的子查询数量将会小于只利用Geohash 编码的索引方法,并在查询时对分区子查询进行分割,避免扩大查询区域。通过这2 种方式,有效地减少子查询个数,提升查询效率,并适当的平衡了任务规模。本文索引的构建过程如图2所示。

图2 索引构建过程Fig.2 Process of building index
2.1 基于历史数据的分区生成
索引设计的首要步骤是利用历史数据对Geohash 编码进行分区,所以历史数据的数据分布情况对索引的设计至关重要。图3 中分别给出了北京市出租车轨迹数据集中10 月8 日与10 月9 日两日的数据分布情况,通过观察发现,两日的数据分布情况基本相似,即轨迹数据总体分布总是在路网附近,由此可以利用数据在空间上的分布特征,构建基于历史数据的分区,使其服务于时空轨迹数据的存储与检索。
图3 从宏观的角度展示出在不同日期上的数据空间分布情况。若要利用历史轨迹数据提炼出信息,还需要判断不同日期的Geohash 上所包含的数据量是否相似,图4 给出了不同日期Geohash 上轨迹点数据量的部分数据,其中(Geohash)D是将Geohash 编码转换成十进制,Num 表示的是每日在Geohash 上数据的量,图4 中绘制了10 月8 日~10月12 日的部分数据情况,其中Avg 是这几日数据的平均值,可以观察到这5 天的每个Geohash 中的数据量波动不大,属于同一数量级,所以使用了Geohash 的平均值表示每个Geohash 网格的数据特征。

图3 两日数据分布对比Fig.3 Comparison of two-day data distribution

图4 5 天Geohash 数据分布与均值Fig.4 Five-day Geohash distribution and Avg
利用设置分区合并阈值的方法完成分区的合并,即合并后所生成的Geohash 组,其所包含的数据和应大于设置的阈值。合并顺序按照Geohash生成顺序,如果有的网格中没有数据,则跳过这一网格;如果将当前Geohash 网格中的数据加入后,分区中的总数据量大于所设定的阈值,即分区结束,下一条数据开始新的分区,图5 举例展示了分区的划分情况,其中01、02、03、04 为4 个分区,每个分区中包含一个或多个Geohash 区域。

图5 分区划分示例Fig.5 Example of dividing partition
表1 中给出了分区划分结果示例,表结构体现出了分区号与Geohash 组的映射关系,1 个分区中包含1 个或多个同一编码长度的Geohash 编码,每个Geohash 编码都对应1 个分区号。分区阈值设定为5 000,其中Partition Id 代表的是分区的自增序号,Partition Number 表示的是分区内的数据量,Included Geohash 表示的是分区内包含的Geohash编码。

表1 分区划分的结果示例Table 1 Result of dividing partition
2.2 辅助二级索引
索引结构的主要设计思想体现在通过设置阈值,对Geohash 进行分区,将包含数据量少的Geohash 分区进行合并,从而减少查询生成的子查询数量。对于给定的经纬度坐标P=(lon,lat),通过Geohash 算法可以很容易地得到Geohash 编码,但由于Partition Id 与Geohash 编码可能是一对一关系,也可能是一对多的关系,所以根据如表1 所示的数据结构,不能直接根据Geohash 编码得到Partition Id,所以需要1 个Geohash 与Partition Id 对应的倒排索引作为二级索引,来服务于数据的存储与查询。
二级索引的构建如表2 结构所示。利用Geohash 编码与分区号进行对应,通过Geohash 编码值可以直接获取分区号,在数据存储时,可以通过二级索引快速地查询到Geohash 编码所对应的分区号;同理,在查询时,通过查询范围的解析得到查询范围所覆盖的Geohash 的编码,再通过二级索引可以检索到这些Geohash 编码属于哪个分区。
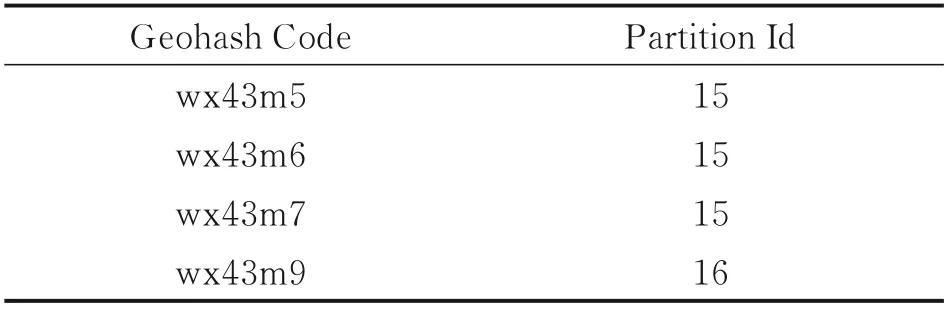
表2 二级索引结构Table2 Secondary index structure
3 基于HBase 的轨迹数据索引存储模型
与许多轨迹管理系统类似,如文献[15]中提出的垂直存储模式,本文方法也是利用数据库中1 行存取1 个轨迹点数据,每1 个轨迹点数据包括如下几个属性。
(1)分区号:利用空间属性与轨迹数据分布生成的自增序号。
(2)空间属性:包括本轨迹点的经度、纬度。
(3)时间属性:轨迹点的产生时间。
(4)其他属性:移动对象速度等其他描述轨迹点的信息。
数据存储模型的设计对提升查询效率有至关重要的作用,由于HBase 中不支持设置二级索引结构,HBase 中的行键即为数据表的直接索引,所以将轨迹数据索引直接设计为行键。HBase 的存储模型如表3 所示,其中TR 表示时间尺度,本文处设计为1 天。T表示尺度内的具体时间。本文的设计既保证了属于同一分区的Geohash 在物理位置上邻近,也保证了分区内相邻时间T的轨迹点在物理上也相对邻近。

表3 数据存储模型Table 3 Data storage model
图6 描述了数据存入HBase 数据库的具体流程,其中需要的参数包括在上文中构建的不均匀网格分区的二级索引Geohash Map,即Geohash 与Partition Id 组成的倒排索引,用于获取当前轨迹点的Geohash 所在的分区;轨迹数据为需要入库的原始数据,从中可以分离出当前轨迹点的详细信息,如经度、纬度、时间和速度等;Geohash 编码长度应与前文设置的Geohash 编码长度保持一致,存储的数据才能在查询时与查询任务相匹配。本文利用Hash Map 结构存储二级索引,通过Key便可直接查找到对应的value 值,故本算法的时间复杂度为o(n),在空间消耗方面主要受到Geohash 编码长度影响,编码长度越长,其所代表的空间区域就越小,在一定的空间范围内,包含的编码就会更多。
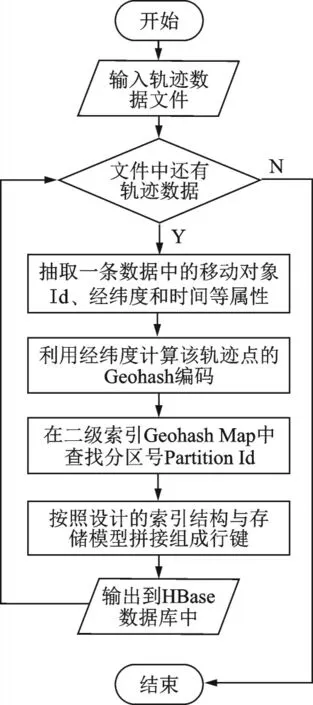
图6 轨迹数据入库流程Fig.6 Process of importing trajectory data into HBase
4 轨迹数据时空查询
本文提出的索引方法主要服务于轨迹数据的时空查询,定义时空查询为Qst,给定空间范围[Geostart,Geoend],其中Geox=(lonx,latx);给定时间范围定义为[Tstart,Tend],对于给定时空范围条件,查询出的符合条件的轨迹点的集合定义为Result,Result=Qst(Geostart,Geoend,Tstart,Tend),不同于对HGrid[6]拓展的索引方式,本文提出的索引方法在时空查询时需要设计1 个额外的查询算法来支持。由上文可知,此时已经获得了不均匀轨迹数据的Geohash 分区信息,并根据分区信息将数据集中的轨迹数据依据要求存入了HBase 数据库。分区的目的就是优化查询效率,扩展的HGrid 方法先是利用空间维进行查询,查询哪些Geohash 编码被查询条件覆盖,再依次遍历每1 个Geohash,利用时间维与精确的位置信息条件进行筛选。由于引入了分区的概念,本文方法使用查询条件向分区进行映射,得到查询范围所对应的分区,再在分区内划分查询范围具体覆盖的区域,在数据分布不均匀时,生成的子查询数量会少于前者。
如图7 所示,01、02、03、04 为分区号,例如分区01={ws1070,ws1071,ws1072,ws1073,ws1074},QueryWindow1 和QueryWindow2 分别为查询窗口。对于QueryWindow1 来说,QueryWindow1 覆盖的Geohash 编码同属于01 分区,其中包括ws1070、ws1071 和ws1074,由于ws1070 和ws1071相邻,所以QueryWindow1 可以生成2 个子查询,即01[ws1070,ws1071]和01[ws1074],相较于扩展的HGrid 方法,在总体查询数据不变的情况下,子查询个数由3 个减少为2 个;对于QueryWindow2,即整个区域都为查询范围,依据本文设计的查询方法QueryWindow2 可生成4 个子查询,为01[ws1070,ws1071,ws1072,ws1073,ws1074]、02[w s1075]、03[ws1076,ws1077,ws1078,ws1079]和04[ws107b,ws107c,ws107d,ws107e,ws107f,ws107g],相较于扩展的HGrid 方法,在总扫描数据不变的情况下,子查询个数由16 个减少为4 个,查询效率可以得到显著提升。图8 给出了轨迹时空查询的详细分解与执行过程,在时间复杂度方面,由于需要对每1 个partition 进行遍历,同时每个partition 中还包含多个Geohash 编码,查询方法的时间复杂度为o(n2),空间复杂度同数据入库时相同,取决于Geohash 编码长度。

图7 查询算法示意图Fig.7 Example of query algorithm

图8 轨迹数据时空查询流程Fig.8 Spatio-temporal query process of trajectory data
5 实验评价
为了测试本文提出的索引方法的查询响应情况,基于NoSQL 的HBase 数据库实现了数据持久化,借助HBase Java api 实现了数据的分布式查询算法完成数据查询。
5.1 实验准备
实验环境采用Hadoop 完全分布式集群环境,集群由3 个节点组成,其中1 个Master 节点部署NameNode,2 个Slave 节点部署DataNode,软件环境:节点系统为centos7,集群环境安装有Hadoop-2.7.1、HBase-1.3.6 和Zookeeper-3.4.14;硬件环境:每个节点拥有16 GB 内存、2 TB 硬盘和两颗Intel E5-2620 0 @ 2.00 GHzCPU。
本文实验的轨迹数据采用浮动车轨迹数据,来源于北京市2012 年10 月份的出租车真实数据。实验采用3 种不同规模的数据集,分别为2 500 万级、5 000 万级和1 亿级,其中2 500 万级为2012 年10 月15 日1 天的数据,5 000 万级是2012 年10 月15、16 日2 天的数据,1 亿级是2012 年10 月15 日~2012 年10 月19 日的数据。
5.2 实验设计
本部分设计了3 个实验。实验1 对比了本文提出的索引与其他索引在子查询生成速度与子查询生成个数的异同,并在不同数据规模、不同的查询范围下,比较了本文提出的索引方法与其他索引方法的查询响应时间,还比较了内存消耗。由于在预分区时使用了历史数据,实验2 探究了使用不同规模的历史数据对查询响应时间的影响。实验3 探究了不同的分区阈值对查询响应时间与导入时间的影响。本文简要介绍2 种对比的索引方法,其中对HGrid[6]拓展时间维度的索引方法是空间驱动类索引方法中的典型方法;ST-hash[16]索引方法是对经度、纬度和时间维进行混合编码,Geomesa 中的Z3 索引使用了此方法,本文实现的每一维度都使用14 bit 进行编码,再对3 个维度进行混合编码,最后使用Base64 编码方法将bit 数组编码成7 位字符串,ST-hash[16]生成实例如图9 所示。
5.2.1 索引方法比较
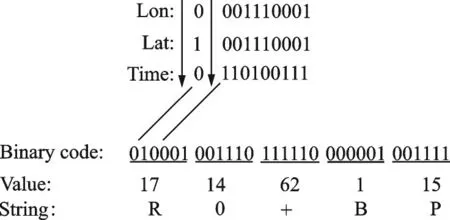
图9 ST-hash 编码方式Fig.9 Example of ST-hash encoding
随机设定某空间范围0.3°×0.3°,时间范围为10 月15 日,本节实验首先探究不同索引方式的子查询生成时间以及子查询生成个数,如图10 所示。在给定的时间和空间范围下,由于需要在二级索引上查找分区,所以本文方法子查询生成时间最长,由于完成了对子查询按照分区的合并,所以子查询个数最少。本文构建索引方法与其他2种方法相同,构建的都是聚集索引。构建索引的过程就是将数据按照设计好的模型存入数据库中,3 种方法都是以轨迹点的方式进行存储,所以构建时间与对比的两种方法大致相同,占用的空间情况也类似。
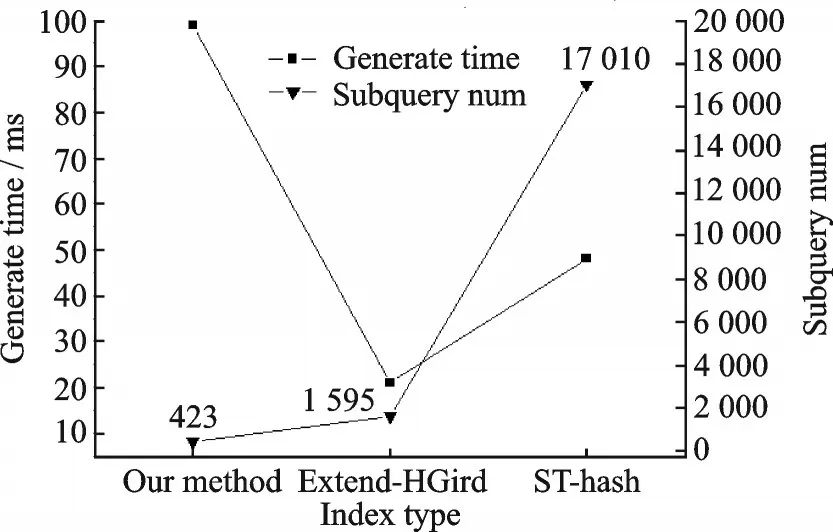
图10 不同索引间对比Fig.10 Comparison between different indexes
图11 在不同的数据规模与不同空间范围下完成了实验,其中的分区阈值选为5 000,实验数据规模从2 500 万级扩展到1 亿级,空间查询范围由0.1°×0.1°扩展到0.3°×0.3°,时间范围与上文保持一致,进行了3 次重复实验将平均值绘制在图中。由图中的结果分析可知,本文提出的索引结构配合查询优化算法在不同的数据规模下均有较好的时间响应;在导入不同数据量级的轨迹数据时,查询响应时间变化不大。
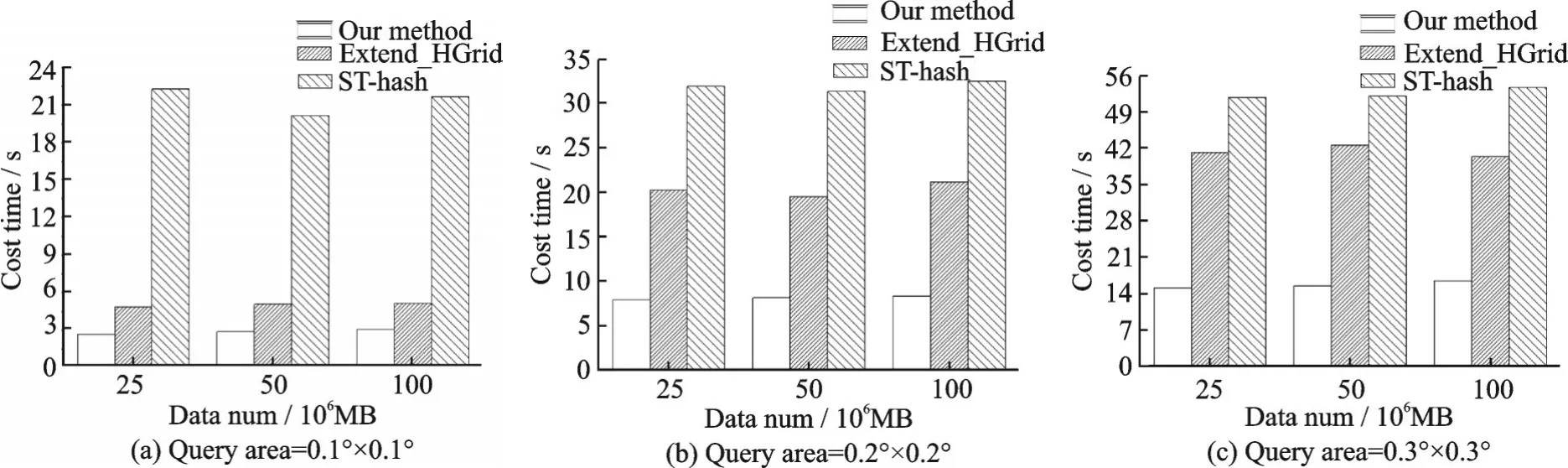
图11 不同数据规模与空间范围下的查询响应时间Fig.11 Time performance of different data size and spatial scope

图12 不同索引结构的内存代价Fig.12 Memory cost of different index structures
图12 对比了本文方法与另外2 种方法的内存代价,实验数据规模采用2 500 万级,分区阈值与时空查询范围与上文保持一致时,内存代价比较的是执行查询时集群占用的内存资源最大值情况,在集群中搭建了Ganglia 分布式监控系统监控集群的内存使用情况。从图中可以得出,由于本文方法需要在内存中预先缓存分区结果,所以相比较于其他2 种方法,在内存占用资源稍多;在I/O 代价方面,由于3 种数据全部存储在HBase 数据库中,I/O 代价可以等价为不同索引的查询方法对HBase 数据库的查询次数。由图10 可知,子查询个数为SThash>Extend_HGrid>Our method,子查询数量越多,查询方法访问HBase 数据库的次数就越多,I/O 代价越高,所以本文的I/O 代价最小。
5.2.2 不同规模历史数据对查询响应时间的影响
由于使用历史数据完成了预分区的生成,本节实验探究了使用不同规模的历史数据生成的索引结构对查询响应时间的影响。实验分别选取了1 天、2 天、4 天和8 天的历史数据,利用各自生成的预分区结果分别将轨迹数据导入HBase 数据库。选取的导入数据为2012 年10 月18 日2 500 万量级的数据,空间查询范围与上文保持一致,时间范围为10 月18 日,查询响应时间如图13 所示。随着选用的历史数据的天数增加,查询响应时间变化不大,说明生成预分区的历史数据天数对查询响应时间影响不大,同时也从侧面验证了轨迹数据分布不均匀的特性在相同时间尺度下的相似性。
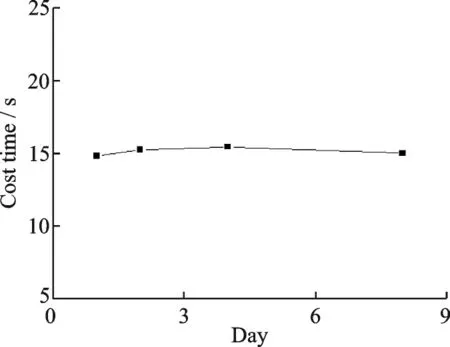
图13 不同规模历史数据预分区结果的查询响应时间Fig.13 Time performance of different scale historical data pre-partition
5.2.3 不同的分区阈值对查询的影响
本节实验的合并阈值范围设置从1 000 变化到20 000,其中包括1 000、3 000、5 000、10 000 和20 000,测试数据采用的是2012 年10 月15 日2 500万量级的数据,随机设定空间查询范围设置为[115.877 951,39.830 862 116.305 688,39.608 864],时间范围为10月15日,数据的导入以及查询情况如图14 所示。从图中可以分析出,轨迹数据的导入速度与阈值设定的大小无关。对于不同阈值下的查询操作,查询响应时间呈现出先减少再稳定的趋势,其主要原因是当查询阈值较小时,查询范围所覆盖的分区数较多,使响应时间变慢,随着分区阈值的增大,查询范围覆盖的分区逐渐减少,响应速度变快,但随着分区阈值的继续增大,查询范围覆盖的分区总数虽然减小,但是查询方法还会对分区内Geohash编码区域进行合并,所以子查询数量变化不大,查询响应时间趋于稳定。

图14 不同分区阈值的导入和查询响应时间Fig.14 Results of different threshold experiments
6 结论
针对海量的时空轨迹数据分布不均匀的特性,本文提出了一种索引方法,并详细地介绍了该索引的构建过程和与其相匹配的查询算法。方法首先通过设计阈值的方法对Geohash 编码进行合并生成分区,设计了基于HBase 的轨迹数据索引存储模型,优化了查询时分区内的子查询,有效地减少的子查询数量。通过实验证明,本文的索引方法在时空查询方面优于ST-hash 方法与扩展HGrid 的方法。下一步还将在以下几个方面改进,首先是支持更多种类的轨迹查询,如KNN 查询、路径查询等;其次是由于构建的分区依赖于历史抽样数据,本文的抽样数据与实验数据为工作日数据,需要探究在非工作日时,构建的分区还是否有效;再者就是轨迹数据分布不均匀的特性是随时间的变化而变化的,需要探究生成分区的有效周期,是否需要动态变化、变化频率以及变化带来的开销等问题。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
大众科学(2022年5期)2022-05-18
四川党的建设(2022年8期)2022-04-28
环球时报(2022-03-29)2022-03-29
小学生学习指导(低年级)(2020年11期)2020-12-14
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
作文大王·低年级(2018年10期)2018-12-06
北京航空航天大学学报(2016年7期)2016-11-16
中国新通信(2016年11期)2016-08-09
